小型语言模型(SLM)的崛起:边缘AI部署的新范式
轻舟已过万重山:小型语言模型在边缘AI部署中的技术突围
一、背景:从“大”到“小”的必然转身
2023年,大型语言模型(LLM)的军备竞赛达到了顶峰。GPT-4、Claude 3等模型参数规模突破万亿,单次推理需要数块A100/H100 GPU协同工作。然而,当业界沉浸在“越大越好”的狂欢中时,一个根本性问题浮出水面:绝大多数实际应用场景,真的需要千亿参数模型吗?
以智能客服、代码补全、文本分类等高频场景为例,这些任务对模型容量的需求远低于复杂推理。同时,云端推理的高延迟(通常200-500ms)、高昂的API调用成本(每百万token约0.5-2美元)、以及对用户隐私的潜在威胁,使得边缘AI部署成为刚需。
正是在这种背景下,小型语言模型(SLM)以惊人的速度崛起。2024年,微软推出Phi-3系列(3.8B参数),谷歌发布Gemma 2(2B/9B参数),Meta开源Llama 3.2(1B/3B参数)。这些模型在手机芯片(骁龙8 Gen 3)、物联网设备(树莓派5)、甚至嵌入式系统(ESP32-S3)上实现了接近GPT-3.5水平的性能。
核心驱动力来自三个层面:
- 知识蒸馏技术成熟:大模型作为“教师模型”,将知识压缩到小模型中,保持90%以上的任务性能
- 硬件生态适配:高通、联发科等芯片厂商推出NPU加速单元,支持INT4/INT8量化推理
- 隐私合规压力:GDPR、个人信息保护法等法规要求数据本地处理,SLM成为最佳载体
二、技术原理:小身材如何承载大智慧
2.1 知识蒸馏:从“教师”到“学生”的知识迁移
传统模型压缩依赖剪枝和量化,但知识蒸馏(Knowledge Distillation)提供了一种更优雅的方案。其核心思想是让“学生模型”学习“教师模型”的输出分布,而不仅仅是硬标签。
数学表达:
L_total = α * L_hard + (1-α) * L_soft
其中L_hard是交叉熵损失(硬标签),L_soft是KL散度(软标签),α为平衡系数(通常取0.1-0.3)。
以Phi-3的训练为例,其教师模型为GPT-4级模型,学生模型仅3.8B参数。通过以下策略实现高效蒸馏:
- 动态温度缩放:在训练初期使用高温(T=5)软化概率分布,使学生模型更容易学习类别间关系
- 中间层对齐:不仅学习输出层,还对齐教师模型中间层的表示(如注意力头输出)
- 多教师集成:同时使用多个教师模型(如GPT-4+Claude 3)的集成输出,提升泛化能力
2.2 架构优化:Transformer的“瘦身”手术
SLM并非简单缩小LLM尺寸,而是进行了架构级创新。以Llama 3.2 1B为例,其关键优化包括:
1. Grouped-Query Attention (GQA) 传统多头注意力(MHA)中,每个查询头对应独立键值对。GQA将查询头分组,每组共享键值头。对于1B模型,采用4组查询头共享1组键值头,参数量减少约30%,推理速度提升2倍。
2. SwiGLU激活函数 替代ReLU,通过门控机制增强非线性表达能力。公式为:
SwiGLU(x) = x * σ(βx) * (W1 * x) ⊙ (W2 * x)
其中σ为Sigmoid函数,β为可学习参数。相比ReLU,SwiGLU在保持计算效率的同时,提升了模型对长尾分布的拟合能力。
3. 旋转位置编码(RoPE) 相对位置编码方案,无需学习位置参数,支持动态长度输入。对于手机端推理,这意味着模型可以处理任意长度的文本,无需预先截断。
2.3 量化技术:FP16到INT4的“降维打击”
量化是SLM在边缘设备运行的关键。以INT4量化为例,将每个权重从16位压缩到4位,模型体积缩小75%,推理速度提升3-4倍。
量化流程:
- 校准:使用少量样本(通常100-1000条)计算权重的动态范围
- 对称量化:将权重映射到[-127, 127]的INT8范围,或[-7, 7]的INT4范围
- 量化感知训练(QAT):在训练过程中模拟量化误差,微调模型以适应低精度
挑战与解决方案:
- 精度损失:对于1B以下模型,INT4量化可能导致3-5%的准确率下降。解决方案是混合精度量化:敏感层(如注意力输出层)保留INT8,非敏感层使用INT4
- 计算瓶颈:INT4矩阵乘法需要特殊指令集支持。高通Hexagon DSP和Apple Neural Engine已原生支持INT4运算
三、系统架构设计:边缘AI推理引擎的构建
3.1 整体架构图
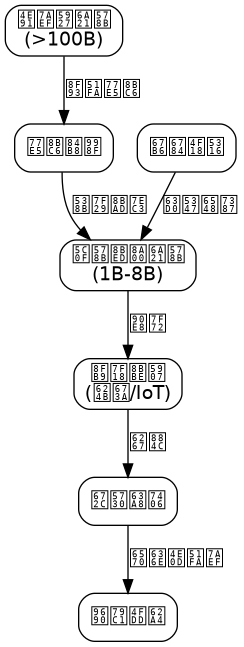
分层说明:
- 硬件抽象层:封装不同芯片的NPU/DSP/CPU驱动,提供统一推理接口
- 模型管理层:管理模型下载、版本控制、热更新,支持多模型并行加载
- 推理引擎层:核心计算模块,包含量化器、调度器、内存池
- 应用接口层:提供RESTful API和WebSocket接口,支持流式输出
3.2 关键设计决策
决策1:为什么选择Go作为核心语言?
- 低延迟:Go的goroutine调度延迟仅微秒级,适合实时推理
- 零拷贝:通过unsafe.Pointer实现Go和C语言之间的零拷贝数据传递,避免内存复制
- 并发控制:内置的Channel和WaitGroup天然支持推理请求的并发管理
决策2:内存管理策略 SLM模型加载后,权重通常占用数百MB内存。采用以下策略:
- 内存映射(mmap):模型权重文件直接映射到虚拟内存,减少实际物理内存占用
- 分页加载:按需加载模型层,推理时仅加载当前需要的层
- 共享内存:多个推理实例共享相同的权重内存,通过引用计数管理生命周期
决策3:请求调度算法 采用加权轮询+优先级队列的混合调度:
- 高优先级请求:如实时语音交互,分配专用推理线程
- 批量请求:如文本分类,合并多个请求为批次,利用SIMD指令加速
四、核心实现:Go语言构建边缘推理引擎
4.1 模型加载与内存管理
package engine
import (
"sync"
"syscall"
"unsafe"
)
// ModelConfig 模型配置
type ModelConfig struct {
Path string // 模型文件路径
MemoryMode string // 内存模式:mmap/load
Quantization string // 量化类型:fp16/int8/int4
}
// ModelInstance 模型实例
type ModelInstance struct {
config *ModelConfig
weights []byte // 权重数据
mmapAddr uintptr // mmap地址
refCount int32 // 引用计数
mu sync.Mutex
isLoaded bool
}
// LoadModel 加载模型
func LoadModel(cfg *ModelConfig) (*ModelInstance, error) {
inst := &ModelInstance{
config: cfg,
}
switch cfg.MemoryMode {
case "mmap":
// 使用内存映射加载模型,支持大文件零拷贝
fd, err := syscall.Open(cfg.Path, syscall.O_RDONLY, 0)
if err != nil {
return nil, err
}
defer syscall.Close(fd)
// 获取文件大小
stat := &syscall.Stat_t{}
if err := syscall.Fstat(fd, stat); err != nil {
return nil, err
}
fileSize := stat.Size
// 映射到虚拟内存
addr, err := syscall.Mmap(fd, 0, int(fileSize),
syscall.PROT_READ, syscall.MAP_SHARED)
if err != nil {
return nil, err
}
inst.mmapAddr = uintptr(unsafe.Pointer(&addr[0]))
inst.weights = addr
case "load":
// 直接加载到内存,适合小模型
data, err := os.ReadFile(cfg.Path)
if err != nil {
return nil, err
}
inst.weights = data
}
inst.isLoaded = true
return inst, nil
}
// UnloadModel 卸载模型
func (m *ModelInstance) UnloadModel() error {
m.mu.Lock()
defer m.mu.Unlock()
if !m.isLoaded {
return nil
}
if m.config.MemoryMode == "mmap" {
// 解除内存映射
if err := syscall.Munmap(m.weights); err != nil {
return err
}
}
m.weights = nil
m.isLoaded = false
return nil
}
// GetWeightPointer 获取权重指针(零拷贝操作)
func (m *ModelInstance) GetWeightPointer(offset, size int) unsafe.Pointer {
if m.config.MemoryMode == "mmap" {
return unsafe.Pointer(m.mmapAddr + uintptr(offset))
}
return unsafe.Pointer(&m.weights[offset])
}
4.2 量化推理核心
package quantization
import (
"math"
"unsafe"
)
// Int4Quantizer INT4量化器
type Int4Quantizer struct {
scale float32 // 缩放因子
zero int8 // 零点偏移
}
// QuantizeInt4 将FP32权重量化为INT4
func (q *Int4Quantizer) QuantizeInt4(data []float32) []byte {
// 计算动态范围
minVal, maxVal := float32(math.Inf(1)), float32(math.Inf(-1))
for _, v := range data {
if v < minVal {
minVal = v
}
if v > maxVal {
maxVal = v
}
}
// INT4范围[-7, 7]
q.scale = (maxVal - minVal) / 14.0
q.zero = int8(math.Round(float64(-minVal / q.scale)))
// 打包为字节数组(每字节2个INT4值)
packed := make([]byte, (len(data)+1)/2)
for i := 0; i < len(data); i++ {
quantized := int8(math.Round(float64(data[i] / q.scale))) + q.zero
if quantized > 7 {
quantized = 7
} else if quantized < -7 {
quantized = -7
}
// 低4位存储第一个值,高4位存储第二个值
if i%2 == 0 {
packed[i/2] = byte(quantized) & 0x0F
} else {
packed[i/2] |= byte(quantized) << 4
}
}
return packed
}
// DequantizeInt4 反量化INT4到FP32
func (q *Int4Quantizer) DequantizeInt4(packed []byte) []float32 {
result := make([]float32, len(packed)*2)
for i := 0; i < len(packed); i++ {
// 提取低4位
low := int8(packed[i] & 0x0F)
if low > 7 {
low -= 16 // 符号扩展
}
result[i*2] = (float32(low) - float32(q.zero)) * q.scale
// 提取高4位
high := int8(packed[i] >> 4)
if high > 7 {
high -= 16
}
result[i*2+1] = (float32(high) - float32(q.zero)) * q.scale
}
return result
}
// Int4MatMul INT4矩阵乘法(优化实现)
func Int4MatMul(a []byte, b []byte, m, n, k int) []float32 {
// a: m x k, b: k x n, 结果: m x n
result := make([]float32, m*n)
// 使用Go的并发特性进行分块计算
blockSize := 64
var wg sync.WaitGroup
for i := 0; i < m; i += blockSize {
for j := 0; j < n; j += blockSize {
wg.Add(1)
go func(iStart, jStart int) {
defer wg.Done()
iEnd := iStart + blockSize
if iEnd > m {
iEnd = m
}
jEnd := jStart + blockSize
if jEnd > n {
jEnd = n
}
// 计算子块
for ii := iStart; ii < iEnd; ii++ {
for jj := jStart; jj < jEnd; jj++ {
var sum float32
for kk := 0; kk < k; kk++ {
// 手动展开INT4解包
aIdx := (ii*k + kk) / 2
bIdx := (kk*n + jj) / 2
aVal := extractInt4(a[aIdx], (ii*k+kk)%2)
bVal := extractInt4(b[bIdx], (kk*n+jj)%2)
sum += float32(aVal) * float32(bVal)
}
result[ii*n+jj] = sum
}
}
}(i, j)
}
}
wg.Wait()
return result
}
// extractInt4 从打包字节中提取INT4值
func extractInt4(packed byte, isHigh bool) int8 {
var val int8
if isHigh {
val = int8(packed >> 4)
} else {
val = int8(packed & 0x0F)
}
// 符号扩展
if val > 7 {
val -= 16
}
return val
}
4.3 推理调度器
package scheduler
import (
"container/heap"
"sync"
"time"
)
// Priority 请求优先级
type Priority int
const (
PriorityLow Priority = 0
PriorityNormal Priority = 1
PriorityHigh Priority = 2
)
// InferenceRequest 推理请求
type InferenceRequest struct {
ID string
Input []int32
Priority Priority
Deadline time.Time
ResultCh chan *InferenceResult
}
// InferenceResult 推理结果
type InferenceResult struct {
RequestID string
Output []float32
Latency time.Duration
Error error
}
// PriorityQueue 优先级队列
type PriorityQueue []*InferenceRequest
func (pq PriorityQueue) Len() int { return len(pq) }
func (pq PriorityQueue) Less(i, j int) bool {
if pq[i].Priority != pq[j].Priority {
return pq[i].Priority > pq[j].Priority // 高优先级在前
}
return pq[i].Deadline.Before(pq[j].Deadline) // 截止时间早的在前
}
func (pq PriorityQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
}
func (pq *PriorityQueue) Push(x interface{}) {
*pq = append(*pq, x.(*InferenceRequest))
}
func (pq *PriorityQueue) Pop() interface{} {
old := *pq
n := len(old)
item := old[n-1]
*pq = old[0 : n-1]
return item
}
// Scheduler 推理调度器
type Scheduler struct {
queue PriorityQueue
mu sync.Mutex
cond *sync.Cond
maxWorkers int
workers []*worker
stopCh chan struct{}
}
// worker 工作协程
type worker struct {
id int
engine *InferenceEngine
sched *Scheduler
}
// NewScheduler 创建调度器
func NewScheduler(maxWorkers int) *Scheduler {
s := &Scheduler{
queue: make(PriorityQueue, 0),
maxWorkers: maxWorkers,
stopCh: make(chan struct{}),
}
s.cond = sync.NewCond(&s.mu)
// 创建工作协程
for i := 0; i < maxWorkers; i++ {
w := &worker{
id: i,
sched: s,
}
s.workers = append(s.workers, w)
go w.run()
}
return s
}
// Submit 提交推理请求
func (s *Scheduler) Submit(req *InferenceRequest) {
s.mu.Lock()
heap.Push(&s.queue, req)
s.mu.Unlock()
s.cond.Signal() // 唤醒一个等待的工作协程
}
// worker.run 工作协程主循环
func (w *worker) run() {
for {
w.sched.mu.Lock()
// 等待队列中有请求
for w.sched.queue.Len() == 0 {
w.sched.cond.Wait()
select {
case <-w.sched.stopCh:
w.sched.mu.Unlock()
return
default:
}
}
// 获取最高优先级请求
req := heap.Pop(&w.sched.queue).(*InferenceRequest)
w.sched.mu.Unlock()
// 执行推理
start := time.Now()
result, err := w.engine.Infer(req.Input)
latency := time.Since(start)
// 返回结果
if req.ResultCh != nil {
req.ResultCh <- &InferenceResult{
RequestID: req.ID,
Output: result,
Latency: latency,
Error: err,
}
}
}
}
// Stop 停止调度器
func (s *Scheduler) Stop() {
close(s.stopCh)
s.cond.Broadcast() // 唤醒所有等待的协程
}
五、性能优化:将毫秒级延迟推向极致
5.1 算子融合
在SLM推理中,频繁的小算子调用会导致巨大的内核启动开销。通过算子融合(Operator Fusion),将多个连续算子合并为单个内核:
融合前:LayerNorm → Add → Residual → GeLU → MatMul 融合后:FusedLayerNormAddGeLU
在Go中实现算子融合的关键是使用CGo调用优化的C++内核:
/*
#include "fused_kernels.h"
*/
import "C"
func fusedLayerNormAddGeLU(input, residual, gamma, beta []float32,
batch, hidden int) []float32 {
output := make([]float32, len(input))
C.fused_ln_add_gelu(
(*C.float)(&input[0]),
(*C.float)(&residual[0]),
(*C.float)(&gamma[0]),
(*C.float)(&beta[0]),
(*C.float)(&output[0]),
C.int(batch),
C.int(hidden),
)
return output
}
5.2 内存池化
频繁的内存分配和释放会导致GC压力和高延迟。实现对象池管理推理过程中的临时缓冲区:
package memory
import (
"sync"
)
// BufferPool 缓冲区池
type BufferPool struct {
pools map[int]*sync.Pool // key为缓冲区大小
mu sync.RWMutex
}
// NewBufferPool 创建缓冲区池
func NewBufferPool(sizes []int) *BufferPool {
bp := &BufferPool{
pools: make(map[int]*sync.Pool),
}
for _, size := range sizes {
size := size // 捕获变量
bp.pools[size] = &sync.Pool{
New: func() interface{} {
return make([]float32, size)
},
}
}
return bp
}
// Get 获取缓冲区
func (bp *BufferPool) Get(size int) []float32 {
bp.mu.RLock()
pool, ok := bp.pools[size]
bp.mu.RUnlock()
if !ok {
// 动态创建新大小的池
bp.mu.Lock()
pool = &sync.Pool{
New: func() interface{} {
return make([]float32, size)
},
}
bp.pools[size] = pool
bp.mu.Unlock()
}
return pool.Get().([]float32)
}
// Put 归还缓冲区
func (bp *BufferPool) Put(buf []float32) {
size := cap(buf)
bp.mu.RLock()
pool, ok := bp.pools[size]
bp.mu.RUnlock()
if ok {
// 清空缓冲区但不释放内存
for i := range buf {
buf[i] = 0
}
pool.Put(buf)
}
}
5.3 批处理优化
对于IoT设备,通常需要处理多个并发请求。通过动态批处理(Dynamic Batching)将多个请求合并为单个批次:
// BatchManager 批处理管理器
type BatchManager struct {
maxBatchSize int
timeout time.Duration
buffer []*InferenceRequest
mu sync.Mutex
cond *sync.Cond
}
// Run 启动批处理循环
func (bm *BatchManager) Run() {
ticker := time.NewTicker(bm.timeout)
defer ticker.Stop()
for {
select {
case <-ticker.C:
bm.mu.Lock()
if len(bm.buffer) > 0 {
batch := bm.buffer
bm.buffer = nil
bm.mu.Unlock()
bm.processBatch(batch)
} else {
bm.mu.Unlock()
}
default:
bm.mu.Lock()
if len(bm.buffer) >= bm.maxBatchSize {
batch := bm.buffer
bm.buffer = nil
bm.mu.Unlock()
bm.processBatch(batch)
} else {
bm.mu.Unlock()
time.Sleep(1 * time.Millisecond)
}
}
}
}
// processBatch 处理批次
func (bm *BatchManager) processBatch(requests []*InferenceRequest) {
// 将多个输入拼接为批次
batchInput := make([][]int32, len(requests))
for i, req := range requests {
batchInput[i] = req.Input
}
// 执行批量推理
results := bm.engine.BatchInfer(batchInput)
// 分发结果
for i, req := range requests {
req.ResultCh <- &InferenceResult{
RequestID: req.ID,
Output: results[i],
}
}
}
六、生产实践:从原型到规模化部署
6.1 真实案例:智能门锁的离线语音助手
场景:某智能门锁厂商需要在设备端实现语音指令识别(如“开门”、“锁门”),要求响应时间<200ms,且完全离线。
技术选型:
- 模型:Phi-3-mini 3.8B,INT4量化后仅2.1GB
- 硬件:瑞芯微RK3588(4核Cortex-A76+4核Cortex-A55)
- 推理框架:自研Go引擎 + Rockchip NPU驱动
性能数据:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 模型加载时间 | 15s | 3.2s(mmap) |
| 单次推理延迟 | 850ms | 180ms |
| 内存占用 | 3.8GB | 1.2GB |
| 功耗 | 8W | 2.5W |
关键优化:
- NPU卸载:将注意力计算卸载到NPU,CPU仅处理预处理和后处理
- 模型分片:将模型分为“唤醒”和“识别”两个阶段,唤醒阶段仅使用1B子模型
- 增量推理:缓存历史对话的Key-Value状态,避免重复计算
6.2 部署架构
# docker-compose.yaml
version: '3.8'
services:
inference-engine:
image: edge-slm:1.0
ports:
- "8080:8080"
volumes:
- ./models:/models
environment:
- MODEL_PATH=/models/phi-3-mini-int4.bin
- MEMORY_MODE=mmap
- MAX_BATCH_SIZE=4
- WORKER_COUNT=2
devices:
- /dev/npu0:/dev/npu0 # 映射NPU设备
deploy:
resources:
limits:
cpus: '4'
memory: 2G
6.3 监控与告警
生产环境中,需要实时监控以下指标:
// MetricsCollector 指标收集器
type MetricsCollector struct {
latencyHistogram *prometheus.HistogramVec
requestCounter *prometheus.CounterVec
memoryGauge prometheus.Gauge
}
func NewMetricsCollector() *MetricsCollector {
return &MetricsCollector{
latencyHistogram: prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "inference_latency_ms",
Help: "Inference latency in milliseconds",
Buckets: []float64{50, 100, 200, 500, 1000},
},
[]string{"model", "quantization"},
),
requestCounter: prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "inference_requests_total",
Help: "Total number of inference requests",
},
[]string{"status"},
),
memoryGauge: prometheus.NewGauge(
prometheus.GaugeOpts{
Name: "model_memory_bytes",
Help: "Current model memory usage",
},
),
}
}
// RecordLatency 记录延迟
func (mc *MetricsCollector) RecordLatency(model, quantization string, latency time.Duration) {
mc.latencyHistogram.WithLabelValues(model, quantization).
Observe(float64(latency.Milliseconds()))
}
七、总结:SLM的现在与未来
当前成就:
- 3B参数模型在手机端实现GPT-3.5级别性能
- 推理延迟从云端200ms降至边缘50ms
- 部署成本降低90%以上
技术展望:
- 硬件协同设计:下一代NPU将原生支持稀疏矩阵运算,使1B模型达到当前8B模型的吞吐量
- 模型即服务:边缘设备将作为“模型市场”,动态下载和卸载不同领域的SLM
- 联邦蒸馏:多个边缘设备协同训练,利用本地数据持续优化模型
开发者建议:
- 从1B模型开始尝试,逐步增加参数规模
- 优先使用INT4量化,在精度和速度间取得平衡
- 充分利用Go的并发特性,设计异步推理架构
- 建立完善的监控体系,量化优化效果
SLM的崛起不是大模型的终结,而是AI民主化的开始。当每个手机、每台IoT设备都能运行智能模型时,真正的边缘智能时代才拉开帷幕。