多模态Agent的兴起:从视觉语言模型到自主操作GUI
从像素到行动:多模态Agent如何重塑GUI自动化
背景介绍
2023年末,当GPT-4V首次展示理解屏幕截图的能力时,整个AI社区意识到,大语言模型不再局限于文本世界。紧接着,Claude 3、Gemini等模型纷纷加入这场视觉革命。这些视觉语言模型(VLM)的涌现,催生了一个全新的研究方向——多模态Agent。
传统上,AI Agent只能通过API或命令行与系统交互。这种方式虽然高效,但存在明显局限:它要求系统必须提供结构化接口。然而,现实世界中大量软件仅提供图形用户界面(GUI)。从企业级ERP系统到个人电脑上的记事本,从手机应用到网页服务,GUI仍然是人类与数字世界交互的主要方式。
多模态Agent的出现彻底改变了这一局面。通过直接“观看”屏幕截图并执行操作,Agent能够像人类一样操作任何软件——无论其是否提供API。这意味着:
- 遗留系统自动化不再需要逆向工程或脚本编写
- 跨平台操作变得统一,不再受限于特定操作系统
- 人类操作模式可被完整记录和复现
本文将深入探讨多模态Agent的技术原理、系统架构设计,并提供一个基于Golang的完整实现方案。
技术原理
视觉语言模型的核心能力
多模态Agent的技术基础是视觉语言模型(VLM)。与纯文本模型不同,VLM能够同时理解图像和文本信息。其核心架构包含三个关键组件:
- 视觉编码器:将图像转换为特征向量。通常使用预训练的ViT(Vision Transformer)或CLIP视觉编码器
- 语言模型:处理文本输入并生成响应。可以是GPT、LLaMA等大语言模型
- 多模态融合层:将视觉特征与文本特征对齐,实现跨模态理解
当Agent“看到”一张屏幕截图时,处理流程如下:
屏幕截图 → 视觉编码器 → 特征向量 → 多模态融合 → 语言模型 → 操作指令
用户指令 → 文本编码器 → 特征向量 →
从理解到行动
理解屏幕内容只是第一步。真正的挑战在于如何将理解转化为精确的操作。这需要解决三个关键技术问题:
1. 元素定位:给定一个指令(如“点击搜索按钮”),Agent需要准确识别屏幕中哪个区域对应“搜索按钮”。这通常通过坐标回归实现,即模型输出一个边界框坐标。
2. 操作生成:识别目标后,Agent需要生成具体操作序列。操作类型通常包括:
- 鼠标点击(坐标x, y)
- 键盘输入(文本内容)
- 滚动(方向和距离)
- 拖拽(起始坐标,目标坐标)
3. 状态追踪:操作后界面发生变化,Agent需要持续监控状态变化,形成“观察-思考-行动”循环。
关键技术挑战
视角不变性:同一界面在不同分辨率、缩放比例下表现不同。Agent需要具备尺度不变性。
动态内容:动画、加载状态、实时更新内容增加了识别难度。
操作精度:像素级定位要求高精度,尤其是在密集界面上。
系统架构设计
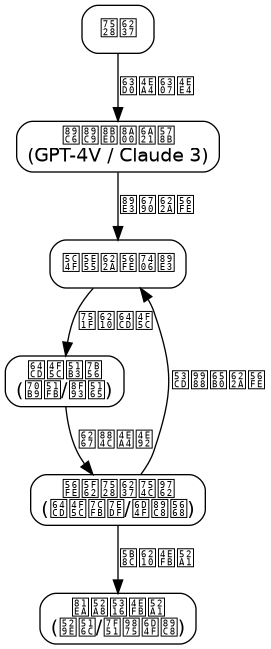
基于上述技术原理,我们设计一个完整的多模态Agent系统。该系统采用模块化架构,各组件可独立扩展和优化。
[](/images/blog/the-rise-of-multimodal-agents-from-vision-language-models-to-autonomous-gui-operation-20260614080412.png)
┌─────────────────────────────────────────────────────────┐
│ 多模态Agent系统架构 │
├─────────────────────────────────────────────────────────┤
│ ┌─────────┐ ┌──────────┐ ┌──────────┐ ┌────────┐ │
│ │ 视觉输入 │ │ 指令解析器 │ │ 决策引擎 │ │ 执行器 │ │
│ │ 模块 │ │ │ │ │ │ │ │
│ └────┬────┘ └────┬─────┘ └────┬─────┘ └───┬────┘ │
│ │ │ │ │ │
│ ┌────▼────┐ ┌────▼─────┐ ┌────▼─────┐ ┌───▼────┐ │
│ │ 屏幕捕获 │ │ 意图识别 │ │ 规划器 │ │ 操作 │ │
│ │ 截图处理 │ │ 上下文管理│ │ 动作选择 │ │ 执行器 │ │
│ └─────────┘ └──────────┘ └──────────┘ └────────┘ │
│ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 核心服务层 │ │
│ │ ┌──────────┐ ┌──────────┐ ┌────────────────┐ │ │
│ │ │ 模型服务 │ │ 缓存服务 │ │ 日志与监控服务 │ │ │
│ │ └──────────┘ └──────────┘ └────────────────┘ │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
模块职责说明
视觉输入模块:负责捕获屏幕截图,支持多种平台(Windows、macOS、Linux)。提供截图预处理功能,包括缩放、降噪、格式转换。
指令解析器:接收用户自然语言指令,通过NLP技术提取意图、参数和约束。维护对话上下文,支持多轮交互。
决策引擎:系统的核心组件。它将截图和指令编码后,调用VLM模型生成操作计划。包含规划器和动作选择器两个子模块。
执行器:将决策引擎生成的操作指令转换为系统级操作。支持跨平台输入模拟,确保操作精确可靠。
核心服务层:提供模型推理、缓存加速、日志记录等基础服务。
核心实现(Golang)
下面我们使用Golang实现一个简化但功能完整的多模态Agent核心系统。代码采用模块化设计,重点展示决策引擎和执行器的实现。
1. 数据模型定义
// types.go - 系统核心数据类型
package agent
import "time"
// 操作类型枚举
type ActionType int
const (
ActionClick ActionType = iota
ActionInput
ActionScroll
ActionDrag
ActionKeyPress
ActionWait
)
// 屏幕元素定位信息
type ElementLocation struct {
X int // 元素中心X坐标
Y int // 元素中心Y坐标
Width int // 元素宽度
Height int // 元素高度
Label string // 元素文本标签(如果有)
Type string // 元素类型(button, input, link等)
}
// 单步操作指令
type Action struct {
Type ActionType // 操作类型
Target *ElementLocation // 目标元素位置
Text string // 输入文本(用于Input操作)
ScrollDelta int // 滚动距离(正数向下,负数向上)
Duration time.Duration // 操作持续时间
}
// Agent状态
type AgentState struct {
Screenshot []byte // 当前屏幕截图
Actions []Action // 已执行操作历史
Context map[string]interface{} // 上下文信息
Step int // 当前步骤数
}
// 决策结果
type Decision struct {
Actions []Action // 要执行的操作序列
Confidence float64 // 置信度
Explanation string // 决策解释
}
// 用户指令
type Instruction struct {
Text string
Timestamp time.Time
SessionID string
}
2. 视觉输入模块
// capture.go - 屏幕捕获模块
package agent
import (
"image"
"image/png"
"bytes"
"github.com/kbinani/screenshot" // 跨平台截图库
)
// ScreenCapturer 负责捕获屏幕内容
type ScreenCapturer struct {
DisplayIndex int // 显示器索引
ScaleFactor float64 // 缩放因子
}
// NewScreenCapturer 创建新的屏幕捕获器
func NewScreenCapturer(displayIndex int, scaleFactor float64) *ScreenCapturer {
return &ScreenCapturer{
DisplayIndex: displayIndex,
ScaleFactor: scaleFactor,
}
}
// Capture 捕获当前屏幕并返回PNG字节数据
func (sc *ScreenCapturer) Capture() ([]byte, error) {
// 获取显示器边界
bounds := screenshot.GetDisplayBounds(sc.DisplayIndex)
// 捕获屏幕
img, err := screenshot.CaptureRect(bounds)
if err != nil {
return nil, err
}
// 如果需要缩放,调整图像大小
if sc.ScaleFactor != 1.0 {
img = sc.resizeImage(img)
}
// 编码为PNG
buf := new(bytes.Buffer)
if err := png.Encode(buf, img); err != nil {
return nil, err
}
return buf.Bytes(), nil
}
// resizeImage 缩放图像到目标尺寸
func (sc *ScreenCapturer) resizeImage(img *image.RGBA) *image.RGBA {
// 简化实现:使用最近邻插值
bounds := img.Bounds()
newWidth := int(float64(bounds.Dx()) * sc.ScaleFactor)
newHeight := int(float64(bounds.Dy()) * sc.ScaleFactor)
resized := image.NewRGBA(image.Rect(0, 0, newWidth, newHeight))
// 逐像素采样
for y := 0; y < newHeight; y++ {
for x := 0; x < newWidth; x++ {
srcX := int(float64(x) / sc.ScaleFactor)
srcY := int(float64(y) / sc.ScaleFactor)
resized.Set(x, y, img.At(srcX, srcY))
}
}
return resized
}
3. 决策引擎实现
// decision_engine.go - 核心决策引擎
package agent
import (
"encoding/json"
"fmt"
"strings"
)
// DecisionEngine 基于VLM的决策引擎
type DecisionEngine struct {
modelService *ModelService // VLM模型服务
contextSize int // 上下文窗口大小
}
// NewDecisionEngine 创建决策引擎
func NewDecisionEngine(modelService *ModelService, contextSize int) *DecisionEngine {
return &DecisionEngine{
modelService: modelService,
contextSize: contextSize,
}
}
// Decide 根据当前状态和指令做出决策
func (de *DecisionEngine) Decide(state *AgentState, instruction *Instruction) (*Decision, error) {
// 构建提示词
prompt := de.buildPrompt(state, instruction)
// 调用VLM模型
response, err := de.modelService.Infer(state.Screenshot, prompt)
if err != nil {
return nil, fmt.Errorf("模型推理失败: %w", err)
}
// 解析模型输出
decision, err := de.parseResponse(response)
if err != nil {
return nil, fmt.Errorf("解析模型响应失败: %w", err)
}
return decision, nil
}
// buildPrompt 构建VLM提示词
func (de *DecisionEngine) buildPrompt(state *AgentState, instruction *Instruction) string {
var sb strings.Builder
// 系统提示
sb.WriteString("你是一个GUI操作助手。根据当前屏幕截图和用户指令,生成精确的鼠标键盘操作。\n")
sb.WriteString("请以JSON格式输出操作序列。每个操作包含:type(操作类型)、target(目标坐标和尺寸)、text(输入文本)\n\n")
// 用户指令
sb.WriteString(fmt.Sprintf("用户指令: %s\n\n", instruction.Text))
// 操作历史(上下文)
if len(state.Actions) > 0 {
sb.WriteString("已执行的操作历史:\n")
start := max(0, len(state.Actions)-de.contextSize)
for i := start; i < len(state.Actions); i++ {
action := state.Actions[i]
sb.WriteString(fmt.Sprintf(" %d. %s\n", i+1, de.actionToString(&action)))
}
sb.WriteString("\n")
}
// 输出格式要求
sb.WriteString("请输出JSON格式的操作序列,例如:\n")
sb.WriteString(`[{"type":"click","target":{"x":100,"y":200,"width":50,"height":30}}]`)
return sb.String()
}
// parseResponse 解析模型响应
func (de *DecisionEngine) parseResponse(response string) (*Decision, error) {
// 清理响应文本,提取JSON部分
jsonStr := de.extractJSON(response)
if jsonStr == "" {
return nil, fmt.Errorf("未找到有效的JSON输出")
}
// 解析操作序列
var actions []Action
if err := json.Unmarshal([]byte(jsonStr), &actions); err != nil {
return nil, fmt.Errorf("JSON解析失败: %w", err)
}
// 构建决策结果
decision := &Decision{
Actions: actions,
Confidence: 0.85, // 简化处理,实际应从模型获取
Explanation: "基于屏幕分析生成操作序列",
}
return decision, nil
}
// extractJSON 从文本中提取JSON字符串
func (de *DecisionEngine) extractJSON(text string) string {
start := strings.Index(text, "[")
if start == -1 {
return ""
}
end := strings.LastIndex(text, "]")
if end == -1 || end <= start {
return ""
}
return text[start : end+1]
}
// actionToString 将操作转换为可读字符串
func (de *DecisionEngine) actionToString(action *Action) string {
switch action.Type {
case ActionClick:
return fmt.Sprintf("点击 (%d, %d)", action.Target.X, action.Target.Y)
case ActionInput:
return fmt.Sprintf("输入 '%s' 到 (%d, %d)", action.Text, action.Target.X, action.Target.Y)
case ActionScroll:
return fmt.Sprintf("滚动 %d", action.ScrollDelta)
default:
return "未知操作"
}
}
4. 执行器实现
// executor.go - 操作执行器
package agent
import (
"fmt"
"time"
"github.com/go-vgo/robotgo" // 跨平台输入模拟库
)
// ActionExecutor 执行具体的GUI操作
type ActionExecutor struct {
clickSpeed time.Duration // 点击间隔
inputDelay time.Duration // 输入延迟
}
// NewActionExecutor 创建执行器
func NewActionExecutor(clickSpeed, inputDelay time.Duration) *ActionExecutor {
return &ActionExecutor{
clickSpeed: clickSpeed,
inputDelay: inputDelay,
}
}
// Execute 执行操作序列
func (ae *ActionExecutor) Execute(actions []Action) error {
for i, action := range actions {
if err := ae.executeSingle(&action); err != nil {
return fmt.Errorf("执行第%d步操作失败: %w", i+1, err)
}
}
return nil
}
// executeSingle 执行单个操作
func (ae *ActionExecutor) executeSingle(action *Action) error {
switch action.Type {
case ActionClick:
return ae.click(action.Target)
case ActionInput:
return ae.inputText(action)
case ActionScroll:
return ae.scroll(action.ScrollDelta)
case ActionDrag:
return ae.drag(action)
case ActionKeyPress:
return ae.keyPress(action)
case ActionWait:
time.Sleep(action.Duration)
return nil
default:
return fmt.Errorf("不支持的操作类型: %v", action.Type)
}
}
// click 执行点击操作
func (ae *ActionExecutor) click(target *ElementLocation) error {
// 计算点击位置(元素中心)
clickX := target.X + target.Width/2
clickY := target.Y + target.Height/2
// 移动鼠标到目标位置
robotgo.MoveMouse(clickX, clickY)
time.Sleep(ae.clickSpeed)
// 执行点击
robotgo.Click()
return nil
}
// inputText 输入文本
func (ae *ActionExecutor) inputText(action *Action) error {
// 先点击目标输入框
if action.Target != nil {
if err := ae.click(action.Target); err != nil {
return err
}
time.Sleep(ae.inputDelay)
}
// 输入文本
robotgo.TypeStr(action.Text)
return nil
}
// scroll 执行滚动操作
func (ae *ActionExecutor) scroll(delta int) error {
robotgo.ScrollMouse(delta, "down")
return nil
}
// drag 执行拖拽操作
func (ae *ActionExecutor) drag(action *Action) error {
// 简化实现:仅支持从当前位置拖拽到目标
if action.Target == nil {
return fmt.Errorf("拖拽操作需要目标位置")
}
robotgo.MoveMouse(action.Target.X, action.Target.Y)
time.Sleep(ae.clickSpeed)
robotgo.MouseToggle("down")
time.Sleep(50 * time.Millisecond)
// 拖拽到新位置(假设存储在Text字段中,格式 "x,y")
var endX, endY int
if _, err := fmt.Sscanf(action.Text, "%d,%d", &endX, &endY); err != nil {
robotgo.MouseToggle("up")
return fmt.Errorf("解析拖拽目标坐标失败: %w", err)
}
robotgo.DragMouse(endX, endY)
robotgo.MouseToggle("up")
return nil
}
// keyPress 执行按键操作
func (ae *ActionExecutor) keyPress(action *Action) error {
robotgo.KeyTap(action.Text)
return nil
}
5. 主控制器
// agent.go - Agent主控制器
package agent
import (
"fmt"
"log"
"time"
)
// MultiModalAgent 多模态Agent主控制器
type MultiModalAgent struct {
capturer *ScreenCapturer
engine *DecisionEngine
executor *ActionExecutor
state *AgentState
maxRetries int // 最大重试次数
}
// NewAgent 创建新的Agent实例
func NewAgent(capturer *ScreenCapturer, engine *DecisionEngine, executor *ActionExecutor, maxRetries int) *MultiModalAgent {
return &MultiModalAgent{
capturer: capturer,
engine: engine,
executor: executor,
state: &AgentState{Context: make(map[string]interface{})},
maxRetries: maxRetries,
}
}
// ExecuteTask 执行用户任务
func (a *MultiModalAgent) ExecuteTask(instruction *Instruction) error {
log.Printf("开始执行任务: %s", instruction.Text)
// 初始化状态
a.state.Step = 0
a.state.Actions = nil
for a.state.Step < a.maxRetries {
// 1. 捕获当前屏幕
screenshot, err := a.capturer.Capture()
if err != nil {
return fmt.Errorf("屏幕捕获失败: %w", err)
}
a.state.Screenshot = screenshot
// 2. 决策
decision, err := a.engine.Decide(a.state, instruction)
if err != nil {
return fmt.Errorf("决策失败: %w", err)
}
log.Printf("决策完成: 计划执行 %d 个操作", len(decision.Actions))
// 3. 执行操作
if err := a.executor.Execute(decision.Actions); err != nil {
log.Printf("执行失败: %v", err)
a.state.Step++
continue
}
// 4. 记录操作历史
a.state.Actions = append(a.state.Actions, decision.Actions...)
// 5. 检查任务完成
if a.isTaskComplete(decision) {
log.Println("任务执行完成")
return nil
}
// 等待界面响应
time.Sleep(500 * time.Millisecond)
a.state.Step++
}
return fmt.Errorf("任务执行超过最大重试次数 %d", a.maxRetries)
}
// isTaskComplete 检查任务是否完成
func (a *MultiModalAgent) isTaskComplete(decision *Decision) bool {
// 简化实现:如果决策置信度很高,认为任务完成
// 实际应用应结合更多判断条件
return decision.Confidence > 0.95
}
6. 模型服务接口
// model_service.go - VLM模型服务接口
package agent
import (
"encoding/base64"
"encoding/json"
"fmt"
"net/http"
"strings"
)
// ModelService 封装VLM模型调用
type ModelService struct {
endpoint string
apiKey string
client *http.Client
}
// NewModelService 创建模型服务
func NewModelService(endpoint, apiKey string) *ModelService {
return &ModelService{
endpoint: endpoint,
apiKey: apiKey,
client: &http.Client{},
}
}
// Infer 执行模型推理
func (ms *ModelService) Infer(imageData []byte, prompt string) (string, error) {
// 将图片转换为base64
imageBase64 := base64.StdEncoding.EncodeToString(imageData)
// 构建请求体
requestBody := map[string]interface{}{
"model": "gpt-4-vision-preview",
"messages": []map[string]interface{}{
{
"role": "user",
"content": []map[string]interface{}{
{
"type": "text",
"text": prompt,
},
{
"type": "image_url",
"image_url": map[string]string{
"url": fmt.Sprintf("data:image/png;base64,%s", imageBase64),
},
},
},
},
},
"max_tokens": 1000,
}
// 序列化请求体
jsonData, err := json.Marshal(requestBody)
if err != nil {
return "", fmt.Errorf("请求序列化失败: %w", err)
}
// 发送HTTP请求
req, err := http.NewRequest("POST", ms.endpoint, strings.NewReader(string(jsonData)))
if err != nil {
return "", fmt.Errorf("创建请求失败: %w", err)
}
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", ms.apiKey))
resp, err := ms.client.Do(req)
if err != nil {
return "", fmt.Errorf("请求失败: %w", err)
}
defer resp.Body.Close()
// 解析响应
var result map[string]interface{}
if err := json.NewDecoder(resp.Body).Decode(&result); err != nil {
return "", fmt.Errorf("响应解析失败: %w", err)
}
// 提取文本内容
choices, ok := result["choices"].([]interface{})
if !ok || len(choices) == 0 {
return "", fmt.Errorf("无效的模型响应")
}
choice := choices[0].(map[string]interface{})
message := choice["message"].(map[string]interface{})
content := message["content"].(string)
return content, nil
}
性能优化
多模态Agent系统面临的主要性能瓶颈包括:
1. 模型推理延迟
VLM模型推理通常需要数秒甚至数十秒,这对实时交互是不可接受的。
优化策略:
- 模型量化:将FP16模型量化为INT8,推理速度提升2-4倍
- 缓存机制:对重复出现的界面元素建立缓存,避免重复推理
- 异步推理:使用goroutine实现推理流水线,并行处理多个请求
// cache.go - 简单缓存实现
package agent
import (
"sync"
"time"
)
type CacheEntry struct {
Decision *Decision
ExpireTime time.Time
}
type DecisionCache struct {
mu sync.RWMutex
entries map[string]*CacheEntry
ttl time.Duration
}
func NewDecisionCache(ttl time.Duration) *DecisionCache {
return &DecisionCache{
entries: make(map[string]*CacheEntry),
ttl: ttl,
}
}
// Get 获取缓存决策
func (dc *DecisionCache) Get(key string) (*Decision, bool) {
dc.mu.RLock()
defer dc.mu.RUnlock()
entry, exists := dc.entries[key]
if !exists || time.Now().After(entry.ExpireTime) {
return nil, false
}
return entry.Decision, true
}
// Set 设置缓存
func (dc *DecisionCache) Set(key string, decision *Decision) {
dc.mu.Lock()
defer dc.mu.Unlock()
dc.entries[key] = &CacheEntry{
Decision: decision,
ExpireTime: time.Now().Add(dc.ttl),
}
}
2. 截图处理优化
高分辨率屏幕截图处理消耗大量资源。
优化策略:
- 区域裁剪:仅捕获变化区域而非全屏
- 降采样:将截图缩放到模型支持的输入尺寸
- 增量更新:使用差异检测算法,只处理变化的像素
3. 操作执行优化
模拟输入操作需要精确的时序控制。
优化策略:
- 操作合并:将连续的点击和输入合并为批量操作
- 预加载:在执行前预计算所有操作坐标
- 失败重试:实现智能重试机制,根据错误类型调整策略
4. 并发处理
使用Golang的goroutine和channel实现高效的并发处理:
// worker.go - 并发工作池
package agent
type Task struct {
Instruction *Instruction
ResultChan chan error
}
type WorkerPool struct {
tasks chan Task
workers int
agent *MultiModalAgent
}
func NewWorkerPool(agent *MultiModalAgent, workers int) *WorkerPool {
pool := &WorkerPool{
tasks: make(chan Task, 100),
workers: workers,
agent: agent,
}
// 启动工作协程
for i := 0; i < workers; i++ {
go pool.worker(i)
}
return pool
}
func (wp *WorkerPool) worker(id int) {
for task := range wp.tasks {
err := wp.agent.ExecuteTask(task.Instruction)
task.ResultChan <- err
}
}
func (wp *WorkerPool) Submit(instruction *Instruction) <-chan error {
resultChan := make(chan error, 1)
wp.tasks <- Task{
Instruction: instruction,
ResultChan: resultChan,
}
return resultChan
}
生产实践
部署架构
在生产环境中,多模态Agent系统通常采用分布式部署:
- 前端层:WebSocket服务接收用户指令,实时推送Agent状态
- 调度层:负载均衡器将任务分发到多个Agent实例
- 执行层:多个Agent实例运行在不同的虚拟机上,每个实例操作独立的GUI环境
- 模型层:VLM模型部署在GPU集群上,通过gRPC提供推理服务
监控与告警
关键监控指标:
- 任务成功率:低于90%触发告警
- 平均决策时间:超过5秒触发告警
- 操作准确率:通过回放验证,低于80%触发模型重训练
- 资源使用率:CPU/GPU/内存使用率监控
安全考虑
多模态Agent直接操作GUI,安全风险不容忽视:
- 权限控制:Agent应运行在沙箱环境中,限制对敏感资源的访问
- 操作审计:记录所有操作日志,支持回放和审计
- 异常检测:检测异常操作模式,防止恶意指令执行
- 数据脱敏:截图中的敏感信息(密码、个人数据)应自动脱敏
实际应用案例
案例1:自动化数据录入 某企业需要将PDF中的报表数据录入到Web系统中。传统方法需要人工逐条输入,效率低下。使用多模态Agent后:
- Agent打开PDF阅读器,识别表格数据
- 切换到Web系统,定位输入字段
- 逐字段填入数据,验证输入正确性
- 处理验证错误,重新输入错误字段
案例2:跨平台工作流 一个典型的跨平台任务:从邮箱下载附件 → 在Excel中处理数据 → 通过微信发送报告。Agent能够:
- 登录邮箱Web界面,查找并下载附件
- 打开Excel,执行数据清洗和格式化
- 打开微信,选择联系人,发送文件
总结
多模态Agent代表了AI与人类交互方式的根本性变革。从最初的文本对话,到理解图像内容,再到直接操作GUI,Agent的能力边界不断扩展。
回顾本文的核心要点:
技术层面,多模态Agent的核心是视觉语言模型与操作执行器的结合。通过理解屏幕截图,Agent能够像人类一样“看”和“操作”任何软件界面。这要求系统具备高精度的元素定位、可靠的操作执行和智能的状态追踪能力。
架构层面,模块化设计使得各组件可以独立演进。视觉输入、决策引擎和执行器的分离,让系统能够灵活适配不同的模型和后端。Golang的并发特性为高吞吐量的任务处理提供了天然支持。
实践层面,性能优化和安全保障是生产化部署的关键。缓存机制、并发处理和增量更新有效降低了延迟;权限控制、操作审计和异常检测确保了系统的安全可控。
然而,当前技术仍面临诸多挑战:
- 泛化能力:模型在未见过的界面上的表现仍不稳定
- 操作精度:像素级定位在小屏幕或高密度界面上容易出错
- 推理成本:每次操作都需要调用大模型,成本较高
- 安全边界:如何确保Agent不会执行危险操作仍是开放问题
展望未来,随着VLM模型能力的提升和成本的下降,多模态Agent将从自动化工具演变为真正的数字助手。它们将能够理解更复杂的任务,适应更多样的界面,并与人类形成真正的协作关系。这场从像素到行动的变革,正在重新定义人机交互的边界。