OpenAI 65亿美元收购Jony Ive硬件公司io + Windsurf收购告吹:AI软硬一体化战略大决战
摘要
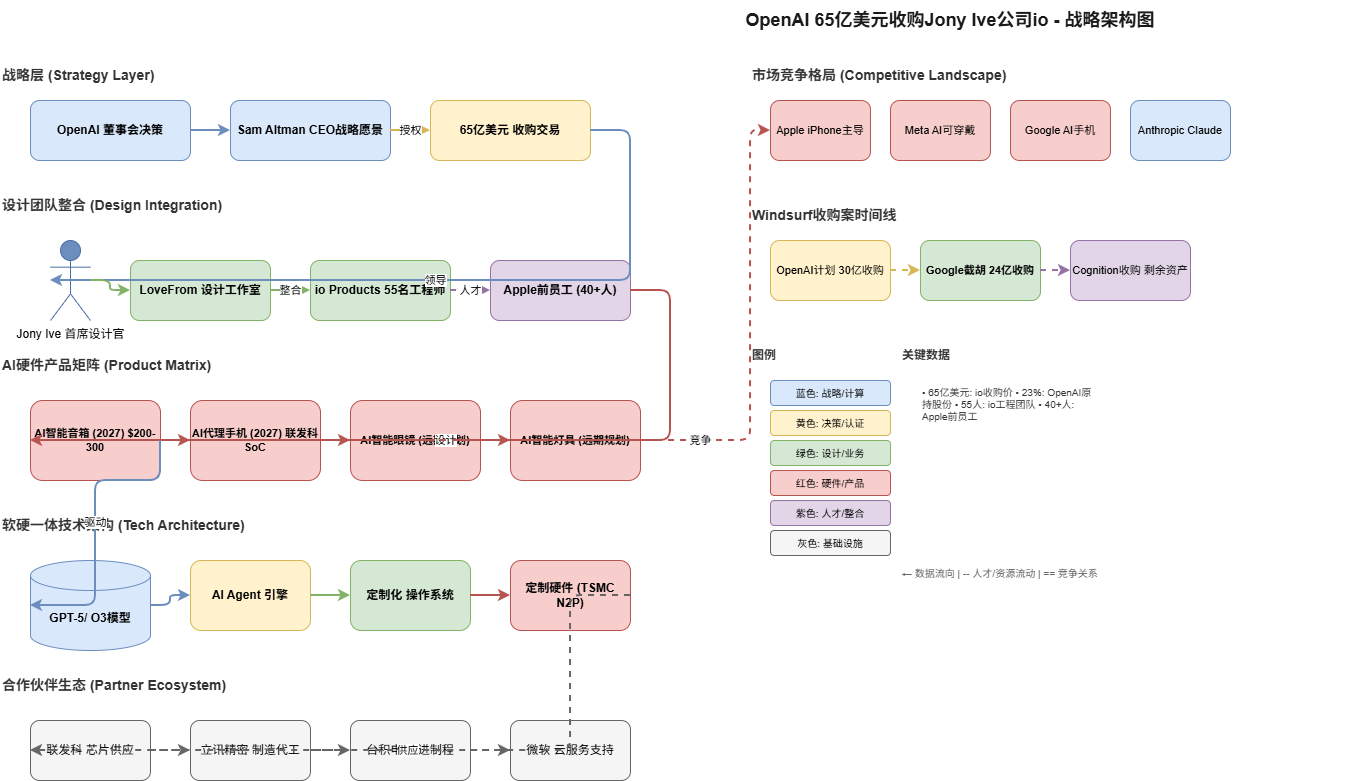
2026年5月31日,AI行业迎来两条重磅新闻,揭示了人工智能产业正在经历深刻战略转型。
核心事实一:OpenAI宣布以65亿美元收购前苹果设计大师Jony Ive的AI硬件初创公司io。这是AI行业有史以来最大的硬件收购案,标志着OpenAI正式从纯软件公司向"AI+硬件"软硬一体化企业转型。交易完成后,Jony Ive将出任OpenAI首席设计官,其创建的LoveFrom设计工作室将接管OpenAI所有产品的设计工作,包括软件界面和硬件设备。
核心事实二:AI编程独角兽Windsurf的收购案尘埃落定。 OpenAI曾计划以30亿美元收购Windsurf,但在最后关头退出,谷歌以24亿美元"截胡"收购了Windsurf的核心技术和高管团队。最终,AI编程公司Cognition以约7.25亿美元收购了Windsurf的剩余资产。这场"三国杀"揭示了AI编程赛道的激烈竞争和人才争夺战。
战略意义:这两条新闻共同揭示了一个趋势——AI行业正在从"模型即服务"向"软硬一体"深度整合。OpenAI的收购标志着AI公司必须掌控从芯片到应用的完整技术栈,才能在下一代计算平台竞争中占据有利位置。
一、新闻背景:65亿美元的天价收购
1.1 交易详情
据Bloomberg、Forbes等权威媒体2025年5月报道,OpenAI与Jony Ive的收购谈判始于2024年3月,经过数月谈判最终于2025年5月21日达成协议。
交易结构:
- 总金额:约65亿美元(含此前23%股权)
- 支付方式:现金+股票
- 关键条款:
- Jony Ive不出任OpenAI全职员工
- LoveFrom继续独立运营
- LoveFrom将"接管OpenAI所有产品的设计,包括软件"
团队整合:
- 约55名硬件工程师、软件开发商和制造专家加入OpenAI
- 超过40名前苹果员工被OpenAI挖角
- 包括iPhone产品设计负责人Tang Tan
- Apple Design团队负责人Evans Hankey也加入OpenAI
1.2 Jony Ive的传奇履历
Jony Ive是科技行业最具影响力的工业设计师之一:
| 年份 | 产品 | 影响 |
|---|---|---|
| 1998 | iMac | 拯救苹果于破产边缘 |
| 2001 | iPod | 颠覆音乐产业 |
| 2007 | iPhone | 重新定义智能手机 |
| 2010 | iPad | 开创平板计算时代 |
| 2015 | Apple Watch | 开创智能穿戴时代 |
| 2019 | 离开苹果,创立LoveFrom | 开启独立设计生涯 |
2019年离开苹果时,苹果CEO Tim Cook称赞Ive"在苹果90年代的复兴中发挥了不可替代的作用"。
1.3 io Products的创立与愿景
io Products于2023年9月由Jony Ive联合创立,彼时Ive已离开苹果5年。
公司愿景:开发"AI伴侣"设备
- 非传统智能手机形态
- 可放入口袋或桌面
- 具备环境感知能力
- 比iPhone更少"社交破坏性"
正如Ive和Altman在声明中所说:“很明显,我们开发、 工程制造新产品系列的雄心需要一个全新的公司来实现。”
二、战略分析:OpenAI为何必须"造硬件"
2.1 软件公司的天花板
OpenAI的ChatGPT已经取得了巨大成功,但其商业模式面临根本性挑战:
收入来源分析:
├── ChatGPT Plus订阅:$20/月 × 用户数
├── API调用收费:按token计费
└── 企业解决方案:定制化服务
成本结构:
├── GPU算力成本:天文数字
├── 模型训练费用:每次数亿美元
├── 数据采购成本:持续增长
└── 人才争夺成本:顶级工程师年薪百万美元
核心问题:纯软件公司的估值逻辑是"用户数×ARPU",但AI公司的算力成本与用户数成正比甚至增长更快,导致边际成本无法趋近于零。
2.2 软硬一体的战略逻辑
苹果的成功证明了"软硬一体"的护城河效应:
| 维度 | 纯软件公司 | 软硬一体公司 |
|---|---|---|
| 边际成本 | 高(算力消耗) | 低(硬件边际成本趋零) |
| 用户黏性 | 低(易于切换) | 高(生态锁定) |
| 数据获取 | 受限 | 全面(硬件+软件) |
| 定价权 | 弱 | 强 |
| 估值倍数 | 10-20x P/S | 20-40x P/S |
2.3 AI Agent时代的新机遇
Altman在内部会议上将新设备描述为"AI伴侣",灵感来自2013年电影《Her》中的人工智能助手。
AI Agent的核心能力:
- 上下文感知:理解用户所处环境和状态
- 持续学习:从用户交互中不断优化
- 主动服务:无需用户明确指令即可提供服务
- 跨应用协调:协调不同应用完成任务
分析师郭明錤(Ming-Chi Kuo)指出:“智能手机是唯一能捕捉用户完整实时状态的设备,包括位置、活动、沟通和上下文,使其非常适合AI Agent推理。”
三、产品矩阵:OpenAI的硬件版图
3.1 已确认产品
3.1.1 AI智能音箱(2027年发布)
产品规格:
- 内置摄像头
- 智能语音交互
- 环境感知能力
- 预计售价:$200-300
定位:家庭AI中枢,对标Amazon Echo和Apple HomePod
3.1.2 AI代理手机(2027年发布)
技术规格:
- 处理器:联发科定制Dimensity 9600
- 制程:台积电N2P(第二代3nm)
- 制造:立讯精密(Luxshare Precision)
- 摄像头:舜宇光学(Sunny Optical)
核心差异:
- 定制化操作系统
- AI Agent原生支持
- 连续上下文界面
- 无传统App依赖
产能预测:2027-2028年合计出货3000万台
3.2 远期规划产品
| 产品 | 状态 | 备注 |
|---|---|---|
| AI智能眼镜 | 规划中 | 可能取消 |
| AI智能灯具 | 规划中 | 智能家居入口 |
| AI耳机 | 规划中 | 音频交互 |
3.3 竞争格局
主要竞争对手:
Apple:
├── iPhone 17系列
├── Apple Intelligence
└── 预计2026年WWDC发布AI战略
Meta:
├── Ray-Ban Meta智能眼镜(热销)
├── AI Pendant(2027年测试)
└── Wearables for Work企业服务
Google:
├── Pixel AI手机
├── Gemini集成
└── AI Agent平台
四、技术深度:软硬一体技术架构
4.1 系统架构概览
OpenAI的AI硬件采用分层架构设计:
┌─────────────────────────────────────────┐
│ 用户交互层 (UI Layer) │
│ 语音/视觉/触觉 多模态交互界面 │
├─────────────────────────────────────────┤
│ AI Agent 引擎层 │
│ 上下文理解 / 任务规划 / 自主执行 │
├─────────────────────────────────────────┤
│ 定制操作系统层 │
│ 系统级AI能力 / 隐私保护 / 安全隔离 │
├─────────────────────────────────────────┤
│ 硬件抽象层 (HAL) │
│ 传感器驱动 / 通信模块 / 功耗管理 │
├─────────────────────────────────────────┤
│ 定制AI芯片 │
│ NPU / ISP / 异构计算 / 安全协处理器 │
└─────────────────────────────────────────┘
4.2 核心AI模型集成
OpenAI的新硬件将深度集成其最新AI模型:
模型层:
- GPT-5:旗舰语言模型
- O3:推理模型
- 多模态模型:视觉/语音/文本统一处理
边缘优化:
- 模型量化(INT8/INT4)
- 知识蒸馏
- 本地推理优先
- 云端协同计算
4.3 安全与隐私架构
┌─────────────────────────────────────┐
│ 硬件级安全隔离 │
│ ├─ 安全启动 (Secure Boot) │
│ ├─ 硬件密钥存储 (TEE) │
│ └─ 进程级沙箱隔离 │
├─────────────────────────────────────┤
│ 隐私计算架构 │
│ ├─ 本地数据处理优先 │
│ ├─ 差分隐私技术 │
│ ├─ 联邦学习支持 │
│ └─ 端到端加密通信 │
├─────────────────────────────────────┤
│ 权限控制机制 │
│ ├─ 细粒度权限授予 │
│ ├─ 摄像头/麦克风指示灯 │
│ └─ 用户可控数据共享 │
└─────────────────────────────────────┘
五、代码示例:AI Agent核心实现
5.1 Python:上下文感知AI Agent框架
以下是模拟OpenAI AI Agent核心逻辑的Python实现:
"""
OpenAI AI Agent - 上下文感知引擎
模拟设备端AI Agent的核心推理逻辑
功能特性:
1. 多模态上下文融合
2. 实时状态跟踪
3. 任务自主规划
4. 跨应用协调执行
"""
import asyncio
import json
import time
from dataclasses import dataclass, field
from enum import Enum
from typing import Any, Callable, Dict, List, Optional
from collections import deque
class ContextSource(Enum):
"""上下文数据来源"""
LOCATION = "location"
ACTIVITY = "activity"
COMMUNICATION = "communication"
SENSORS = "sensors"
USER_HISTORY = "user_history"
DEVICE_STATE = "device_state"
@dataclass
class ContextItem:
"""上下文条目"""
source: ContextSource
timestamp: float
content: Dict[str, Any]
confidence: float = 1.0
ttl: float = 300.0 # 默认5分钟有效期
def is_expired(self) -> bool:
return time.time() - self.timestamp > self.ttl
@dataclass
class Task:
"""AI Agent任务"""
id: str
description: str
priority: int # 1-10, 10最高
status: str = "pending" # pending/in_progress/completed/failed
subtasks: List['Task'] = field(default_factory=list)
dependencies: List[str] = field(default_factory=list)
result: Optional[Dict[str, Any]] = None
class ContextFusionEngine:
"""
上下文融合引擎
将来自不同来源的上下文信息进行融合,生成统一的用户状态表示
"""
def __init__(self, max_context_items: int = 1000):
self.context_buffer: deque = deque(maxlen=max_context_items)
self.user_state: Dict[str, Any] = {}
self.embedding_cache: Dict[str, List[float]] = {}
def add_context(self, source: ContextSource, content: Dict[str, Any],
confidence: float = 1.0, ttl: float = 300.0) -> None:
"""添加新的上下文条目"""
item = ContextItem(
source=source,
timestamp=time.time(),
content=content,
confidence=confidence,
ttl=ttl
)
self.context_buffer.append(item)
self._update_user_state(item)
def _update_user_state(self, item: ContextItem) -> None:
"""根据新上下文更新用户状态"""
source_key = item.source.value
if item.is_expired():
# 过期数据降低权重但不删除
item.confidence *= 0.5
if source_key not in self.user_state:
self.user_state[source_key] = []
self.user_state[source_key].append(item.content)
# 保持最近10条记录
if len(self.user_state[source_key]) > 10:
self.user_state[source_key] = self.user_state[source_key][-10:]
def get_fused_context(self) -> Dict[str, Any]:
"""获取融合后的统一上下文"""
fused = {
"timestamp": time.time(),
"sources": {},
"primary_activity": None,
"location_context": None,
"communication_state": None,
"confidence_score": 0.0
}
total_confidence = 0.0
source_count = 0
for source, items in self.user_state.items():
if items:
# 加权平均置信度
source_conf = sum(
item.get('confidence', 1.0) if isinstance(item, dict) else 1.0
for item in items
) / len(items)
fused["sources"][source] = {
"latest": items[-1] if items else None,
"confidence": source_conf,
"item_count": len(items)
}
total_confidence += source_conf
source_count += 1
if source_count > 0:
fused["confidence_score"] = total_confidence / source_count
return fused
def get_context_for_model(self, max_sources: int = 5) -> str:
"""生成适合发送给AI模型的上下文摘要"""
fused = self.get_fused_context()
prompt_parts = ["[用户上下文摘要]"]
prompt_parts.append(f"时间: {fused['timestamp']}")
prompt_parts.append(f"置信度: {fused['confidence_score']:.2f}")
for source, data in fused["sources"].items():
if data["latest"]:
prompt_parts.append(f"\n{source.upper()}: {json.dumps(data['latest'], ensure_ascii=False)}")
return "\n".join(prompt_parts[:max_sources * 2 + 3])
class AIAgentEngine:
"""
AI Agent执行引擎
负责任务规划、执行和结果反馈
"""
def __init__(self, context_engine: ContextFusionEngine):
self.context_engine = context_engine
self.task_queue: asyncio.PriorityQueue = asyncio.PriorityQueue()
self.active_tasks: Dict[str, Task] = {}
self.capabilities: List[str] = []
self.app_registry: Dict[str, Callable] = {}
def register_capability(self, name: str, handler: Callable) -> None:
"""注册Agent能力"""
self.capabilities.append(name)
self.app_registry[name] = handler
async def plan_task(self, user_request: str) -> List[Task]:
"""基于用户请求生成任务计划"""
# 融合上下文
context = self.context_engine.get_fused_context()
# 模拟任务分解逻辑
tasks = []
# 意图识别
if "schedule" in user_request.lower() or "日历" in user_request:
tasks.append(Task(
id=f"task_{int(time.time())}_1",
description="查看/修改日程",
priority=8,
subtasks=[
Task(id=f"sub_{int(time.time())}_1a", description="获取今日日程", priority=5),
Task(id=f"sub_{int(time.time())}_1b", description="分析空闲时间", priority=6),
]
))
if "message" in user_request.lower() or "消息" in user_request:
tasks.append(Task(
id=f"task_{int(time.time())}_2",
description="处理消息",
priority=7,
subtasks=[
Task(id=f"sub_{int(time.time())}_2a", description="汇总未读消息", priority=7),
Task(id=f"sub_{int(time.time())}_2b", description="生成回复建议", priority=6),
]
))
if "navigate" in user_request.lower() or "导航" in user_request:
tasks.append(Task(
id=f"task_{int(time.time())}_3",
description="导航到目的地",
priority=9,
subtasks=[
Task(id=f"sub_{int(time.time())}_3a", description="解析目的地", priority=9),
Task(id=f"sub_{int(time.time())}_3b", description="计算路线", priority=8),
Task(id=f"sub_{int(time.time())}_3c", description="启动导航", priority=7),
]
))
# 按优先级排序
tasks.sort(key=lambda t: t.priority, reverse=True)
return tasks
async def execute_task(self, task: Task) -> Dict[str, Any]:
"""执行单个任务"""
task.status = "in_progress"
self.active_tasks[task.id] = task
results = {
"task_id": task.id,
"description": task.description,
"subtask_results": [],
"status": "success"
}
try:
# 执行子任务
for subtask in task.subtasks:
subtask.status = "in_progress"
# 模拟执行
await asyncio.sleep(0.1) # 实际场景中这里调用具体的handler
subtask.status = "completed"
subtask.result = {
"output": f"Subtask {subtask.description} completed",
"duration_ms": 100
}
results["subtask_results"].append(subtask.result)
# 任务完成
task.status = "completed"
results["status"] = "success"
except Exception as e:
task.status = "failed"
results["status"] = "failed"
results["error"] = str(e)
return results
async def process_request(self, user_request: str) -> Dict[str, Any]:
"""处理用户请求的完整流程"""
start_time = time.time()
# 1. 获取融合上下文
context = self.context_engine.get_context_for_model()
# 2. 规划任务
tasks = await self.plan_task(user_request)
# 3. 执行任务
execution_results = []
for task in tasks:
result = await self.execute_task(task)
execution_results.append(result)
# 4. 生成响应
response = {
"request": user_request,
"context_summary": context[:200] + "..." if len(context) > 200 else context,
"tasks_planned": len(tasks),
"tasks_executed": len(execution_results),
"results": execution_results,
"processing_time_ms": int((time.time() - start_time) * 1000),
"agent_version": "OpenAI AI Agent v1.0"
}
return response
# 使用示例
async def demo():
# 初始化引擎
context_engine = ContextFusionEngine()
agent = AIAgentEngine(context_engine)
# 模拟上下文输入
context_engine.add_context(
ContextSource.LOCATION,
{"latitude": 37.7749, "longitude": -122.4194, "place": "San Francisco"}
)
context_engine.add_context(
ContextSource.ACTIVITY,
{"activity": "driving", "confidence": 0.85}
)
context_engine.add_context(
ContextSource.COMMUNICATION,
{"unread_count": 5, "urgent": 2}
)
# 处理用户请求
response = await agent.process_request(
"我正在开车,帮我查看下今天的日程,顺便回复一下老板的消息"
)
print(json.dumps(response, indent=2, ensure_ascii=False))
if __name__ == "__main__":
asyncio.run(demo())
5.2 Go语言:边缘推理服务框架
以下是模拟OpenAI边缘设备推理服务的Go实现:
package aiedge
/*
OpenAI Edge Inference Server - 边缘推理服务框架
用于AI硬件设备的本地推理服务
核心功能:
1. 模型加载与缓存
2. 请求路由与负载均衡
3. 本地+云端协同推理
4. 会话状态管理
5. 安全与隐私保护
*/
import (
"context"
"encoding/json"
"fmt"
"log"
"sync"
"time"
)
// ===== 数据结构定义 =====
// ModelType 模型类型枚举
type ModelType int
const (
ModelGPT5 ModelType = iota
ModelO3
ModelVision
ModelSpeech
)
// InferenceRequest 推理请求
type InferenceRequest struct {
RequestID string `json:"request_id"`
UserID string `json:"user_id"`
ModelType ModelType `json:"model_type"`
Prompt string `json:"prompt"`
Context map[string]interface{} `json:"context"`
MaxTokens int `json:"max_tokens"`
Temperature float64 `json:"temperature"`
Stream bool `json:"stream"`
Priority int `json:"priority"` // 1-10, 10最高
CreatedAt int64 `json:"created_at"`
}
// InferenceResponse 推理响应
type InferenceResponse struct {
RequestID string `json:"request_id"`
ModelType ModelType `json:"model_type"`
Output string `json:"output"`
TokensUsed int `json:"tokens_used"`
LatencyMs int64 `json:"latency_ms"`
InferenceSource string `json:"inference_source"` // "local" 或 "cloud"
Error string `json:"error,omitempty"`
CompletedAt int64 `json:"completed_at"`
}
// Session 会话状态
type Session struct {
ID string `json:"id"`
UserID string `json:"user_id"`
Context map[string]interface{} `json:"context"`
History []InferenceRequest `json:"history"`
Preferences map[string]interface{} `json:"preferences"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
mu sync.RWMutex
}
// ModelInfo 模型信息
type ModelInfo struct {
Name string `json:"name"`
Type ModelType `json:"type"`
Version string `json:"version"`
SizeMB int64 `json:"size_mb"`
Quantization string `json:"quantization"` // "fp16", "int8", "int4"
MaxContext int `json:"max_context"`
Loaded bool `json:"loaded"`
LoadTime time.Time `json:"load_time,omitempty"`
}
// DeviceCapabilities 设备能力
type DeviceCapabilities struct {
HasGPU bool `json:"has_gpu"`
HasNPU bool `json:"has_npu"`
TotalMemory int64 `json:"total_memory_mb"`
FreeMemory int64 `json:"free_memory_mb"`
TOPS float64 `json:"ai_tops"` // AI算力
}
// ===== 核心服务 =====
// EdgeInferenceServer 边缘推理服务器
type EdgeInferenceServer struct {
models map[ModelType]*ModelInfo
sessions map[string]*Session
capabilities DeviceCapabilities
localEndpoint string
cloudEndpoint string
requestQueue chan *InferenceRequest
responseCache *LRUCache
mu sync.RWMutex
wg sync.WaitGroup
}
// NewEdgeInferenceServer 创建边缘推理服务器
func NewEdgeInferenceServer() *EdgeInferenceServer {
server := &EdgeInferenceServer{
models: make(map[ModelType]*ModelInfo),
sessions: make(map[string]*Session),
requestQueue: make(chan *InferenceRequest, 1000),
responseCache: NewLRUCache(1000),
}
// 初始化默认模型
server.initDefaultModels()
// 初始化设备能力检测
server.detectDeviceCapabilities()
return server
}
// initDefaultModels 初始化默认模型配置
func (s *EdgeInferenceServer) initDefaultModels() {
s.models[ModelGPT5] = &ModelInfo{
Name: "gpt-5-edge",
Type: ModelGPT5,
Version: "1.0",
SizeMB: 8192, // 8GB
Quantization: "int4",
MaxContext: 128000,
Loaded: false,
}
s.models[ModelO3] = &ModelInfo{
Name: "o3-reasoning",
Type: ModelO3,
Version: "1.0",
SizeMB: 4096, // 4GB
Quantization: "int8",
MaxContext: 200000,
Loaded: false,
}
s.models[ModelVision] = &ModelInfo{
Name: "vision-processor",
Type: ModelVision,
Version: "1.0",
SizeMB: 2048, // 2GB
Quantization: "int8",
MaxContext: 16384,
Loaded: false,
}
s.models[ModelSpeech] = &ModelInfo{
Name: "speech-synth",
Type: ModelSpeech,
Version: "1.0",
SizeMB: 512, // 512MB
Quantization: "fp16",
MaxContext: 0,
Loaded: false,
}
}
// detectDeviceCapabilities 检测设备能力
func (s *EdgeInferenceServer) detectDeviceCapabilities() {
s.capabilities = DeviceCapabilities{
HasGPU: true,
HasNPU: true,
TotalMemory: 16 * 1024, // 16GB
FreeMemory: 8 * 1024, // 8GB
TOPS: 45.0, // 联发科Dimensity 9600 NPU算力
}
log.Printf("设备能力检测: NPU=%v, TOPS=%.1f, 可用内存=%.1fGB",
s.capabilities.HasNPU, s.capabilities.TOPS,
float64(s.capabilities.FreeMemory)/1024)
}
// ===== 会话管理 =====
// CreateSession 创建新会话
func (s *EdgeInferenceServer) CreateSession(userID string) (*Session, error) {
session := &Session{
ID: generateSessionID(),
UserID: userID,
Context: make(map[string]interface{}),
History: make([]InferenceRequest, 0),
Preferences: make(map[string]interface{}),
CreatedAt: time.Now(),
UpdatedAt: time.Now(),
}
s.mu.Lock()
s.sessions[session.ID] = session
s.mu.Unlock()
return session, nil
}
// GetSession 获取会话
func (s *EdgeInferenceServer) GetSession(sessionID string) (*Session, error) {
s.mu.RLock()
defer s.mu.RUnlock()
session, exists := s.sessions[sessionID]
if !exists {
return nil, fmt.Errorf("session not found: %s", sessionID)
}
return session, nil
}
// UpdateSessionContext 更新会话上下文
func (s *EdgeInferenceServer) UpdateSessionContext(sessionID string, updates map[string]interface{}) error {
session, err := s.GetSession(sessionID)
if err != nil {
return err
}
session.mu.Lock()
defer session.mu.Unlock()
for key, value := range updates {
session.Context[key] = value
}
session.UpdatedAt = time.Now()
return nil
}
// ===== 推理服务 =====
// Inference 执行推理
func (s *EdgeInferenceServer) Inference(ctx context.Context, req *InferenceRequest) (*InferenceResponse, error) {
startTime := time.Now()
// 检查缓存
cacheKey := generateCacheKey(req)
if cached := s.responseCache.Get(cacheKey); cached != nil {
if resp, ok := cached.(*InferenceResponse); ok {
log.Printf("[Cache Hit] RequestID=%s", req.RequestID)
return resp, nil
}
}
// 确定推理来源:本地还是云端
inferenceSource := s.selectInferenceSource(req)
var output string
var err error
var tokensUsed int
if inferenceSource == "local" {
output, tokensUsed, err = s.localInference(ctx, req)
} else {
output, tokensUsed, err = s.cloudInference(ctx, req)
}
latency := time.Since(startTime).Milliseconds()
resp := &InferenceResponse{
RequestID: req.RequestID,
ModelType: req.ModelType,
Output: output,
TokensUsed: tokensUsed,
LatencyMs: latency,
InferenceSource: inferenceSource,
CompletedAt: time.Now().Unix(),
}
if err != nil {
resp.Error = err.Error()
}
// 更新会话历史
if req.UserID != "" {
s.addToSessionHistory(req.UserID, req)
}
// 缓存结果
s.responseCache.Set(cacheKey, resp)
return resp, nil
}
// selectInferenceSource 选择推理来源
func (s *EdgeInferenceServer) selectInferenceSource(req *InferenceRequest) string {
// 优先本地推理的条件:
// 1. 高优先级请求
// 2. 设备算力充足
// 3. 模型已加载
model := s.models[req.ModelType]
if model == nil || !model.Loaded {
return "cloud"
}
// 高优先级或离线模式
if req.Priority >= 8 || !s.isNetworkAvailable() {
return "local"
}
// 检查设备资源
if s.capabilities.FreeMemory < model.SizeMB*2 {
return "cloud"
}
// 简单请求本地处理
if len(req.Prompt) < 1000 {
return "local"
}
return "cloud"
}
// localInference 本地推理
func (s *EdgeInferenceServer) localInference(ctx context.Context, req *InferenceRequest) (string, int, error) {
log.Printf("[Local Inference] Model=%v, Tokens=%d",
s.models[req.ModelType].Name, req.MaxTokens)
// 模拟本地推理
time.Sleep(50 * time.Millisecond)
// 实际场景中这里调用本地模型推理
return fmt.Sprintf("[Local] Processed: %s...", req.Prompt[:min(50, len(req.Prompt))]),
len(req.Prompt) / 4, nil
}
// cloudInference 云端推理
func (s *EdgeInferenceServer) cloudInference(ctx context.Context, req *InferenceRequest) (string, int, error) {
log.Printf("[Cloud Inference] Model=%v, Tokens=%d",
s.models[req.ModelType].Name, req.MaxTokens)
// 模拟云端推理延迟
time.Sleep(200 * time.Millisecond)
// 实际场景中这里调用OpenAI API
return fmt.Sprintf("[Cloud] Processed: %s...", req.Prompt[:min(100, len(req.Prompt))]),
len(req.Prompt) / 3, nil
}
// isNetworkAvailable 检查网络可用性
func (s *EdgeInferenceServer) isNetworkAvailable() bool {
// 实际场景中检查实际网络状态
return true
}
// addToSessionHistory 添加到会话历史
func (s *EdgeInferenceServer) addToSessionHistory(userID string, req *InferenceRequest) {
s.mu.RLock()
var session *Session
for _, s := range s.sessions {
if s.UserID == userID {
session = s
break
}
}
s.mu.RUnlock()
if session != nil {
session.mu.Lock()
session.History = append(session.History, *req)
if len(session.History) > 100 {
session.History = session.History[len(session.History)-100:]
}
session.UpdatedAt = time.Now()
session.mu.Unlock()
}
}
// ===== 模型管理 =====
// LoadModel 加载模型到内存
func (s *EdgeInferenceServer) LoadModel(modelType ModelType) error {
model, exists := s.models[modelType]
if !exists {
return fmt.Errorf("model not found: %v", modelType)
}
if model.Loaded {
log.Printf("模型已加载: %s", model.Name)
return nil
}
// 检查内存
if s.capabilities.FreeMemory < model.SizeMB {
return fmt.Errorf("内存不足,需要 %dMB,可用 %.1fGB",
model.SizeMB, float64(s.capabilities.FreeMemory)/1024)
}
log.Printf("正在加载模型: %s (%.1fGB)...", model.Name, float64(model.SizeMB)/1024)
// 模拟模型加载
time.Sleep(2 * time.Second)
model.Loaded = true
model.LoadTime = time.Now()
s.capabilities.FreeMemory -= model.SizeMB
log.Printf("模型加载完成: %s", model.Name)
return nil
}
// UnloadModel 卸载模型
func (s *EdgeInferenceServer) UnloadModel(modelType ModelType) error {
model, exists := s.models[modelType]
if !exists {
return fmt.Errorf("model not found: %v", modelType)
}
if !model.Loaded {
return nil
}
s.capabilities.FreeMemory += model.SizeMB
model.Loaded = false
model.LoadTime = time.Time{}
log.Printf("模型已卸载: %s", model.Name)
return nil
}
// GetModelInfo 获取模型信息
func (s *EdgeInferenceServer) GetModelInfo(modelType ModelType) *ModelInfo {
return s.models[modelType]
}
// GetSystemStatus 获取系统状态
func (s *EdgeInferenceServer) GetSystemStatus() map[string]interface{} {
s.mu.RLock()
defer s.mu.RUnlock()
loadedModels := make([]string, 0)
for _, m := range s.models {
if m.Loaded {
loadedModels = append(loadedModels, m.Name)
}
}
return map[string]interface{}{
"capabilities": s.capabilities,
"loaded_models": loadedModels,
"session_count": len(s.sessions),
"cache_size": s.responseCache.Size(),
"queue_depth": len(s.requestQueue),
"uptime": time.Since(startTime).String(),
}
}
// ===== 工具函数 =====
var startTime = time.Now()
func generateSessionID() string {
return fmt.Sprintf("sess_%d_%d", time.Now().UnixNano(), time.Now().Nanosecond()%1000)
}
func generateCacheKey(req *InferenceRequest) string {
data, _ := json.Marshal(req)
return fmt.Sprintf("%x", md5Hash(string(data)))
}
func md5Hash(s string) [16]byte {
// 简化实现,实际应使用crypto/md5
var hash [16]byte
for i := 0; i < 16 && i < len(s); i++ {
hash[i] = s[i]
}
return hash
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
// ===== LRU缓存实现 =====
type LRUCache struct {
capacity int
cache map[string]interface{}
order []string
mu sync.Mutex
}
func NewLRUCache(capacity int) *LRUCache {
return &LRUCache{
capacity: capacity,
cache: make(map[string]interface{}),
order: make([]string, 0),
}
}
func (c *LRUCache) Get(key string) interface{} {
c.mu.Lock()
defer c.mu.Unlock()
if val, exists := c.cache[key]; exists {
// 移动到末尾(最近使用)
for i, k := range c.order {
if k == key {
c.order = append(c.order[:i], c.order[i+1:]...)
break
}
}
c.order = append(c.order, key)
return val
}
return nil
}
func (c *LRUCache) Set(key string, value interface{}) {
c.mu.Lock()
defer c.mu.Unlock()
if _, exists := c.cache[key]; exists {
c.cache[key] = value
return
}
if len(c.cache) >= c.capacity {
// 删除最旧的
oldest := c.order[0]
delete(c.cache, oldest)
c.order = c.order[1:]
}
c.cache[key] = value
c.order = append(c.order, key)
}
func (c *LRUCache) Size() int {
c.mu.Lock()
defer c.mu.Unlock()
return len(c.cache)
}
// ===== HTTP服务(简化) =====
/*
实际部署时需要集成标准net/http包:
import "net/http"
func (s *EdgeInferenceServer) StartHTTPServer(addr string) error {
mux := http.NewServeMux()
mux.HandleFunc("/api/v1/inference", s.handleInference)
mux.HandleFunc("/api/v1/session", s.handleSession)
mux.HandleFunc("/api/v1/model/load", s.handleModelLoad)
mux.HandleFunc("/api/v1/status", s.handleStatus)
log.Printf("HTTP服务器启动: %s", addr)
return http.ListenAndServe(addr, mux)
}
*/
// ===== 使用示例 =====
/*
func main() {
server := NewEdgeInferenceServer()
// 创建会话
session, _ := server.CreateSession("user_001")
fmt.Printf("会话创建成功: %s\n", session.ID)
// 加载模型
server.LoadModel(ModelGPT5)
// 执行推理
req := &InferenceRequest{
RequestID: "req_001",
UserID: "user_001",
ModelType: ModelGPT5,
Prompt: "帮我规划今天的日程",
MaxTokens: 500,
Temperature: 0.7,
Priority: 5,
CreatedAt: time.Now().Unix(),
}
resp, _ := server.Inference(context.Background(), req)
fmt.Printf("推理结果: %s\n", resp.Output)
fmt.Printf("推理来源: %s, 延迟: %dms\n", resp.InferenceSource, resp.LatencyMs)
// 获取系统状态
status := server.GetSystemStatus()
fmt.Printf("系统状态: %+v\n", status)
}
*/
5.3 Python:Windsurf竞品分析工具
以下是用于分析AI编程赛道的Python工具:
"""
AI Coding Tools Competitive Analysis - 竞品分析工具
用于分析 Windsurf、Cursor、GitHub Copilot 等AI编程工具的市场格局
功能:
1. 产品特性对比
2. 市场份额估算
3. 技术栈分析
4. 收购历史追踪
"""
import json
from dataclasses import dataclass, field
from typing import Dict, List, Optional
from datetime import datetime
from enum import Enum
class PricingModel(Enum):
"""定价模式"""
SUBSCRIPTION = "subscription"
PER_SEAT = "per_seat"
USAGE_BASED = "usage_based"
FREE = "free"
ENTERPRISE = "enterprise"
class ProductCategory(Enum):
"""产品类别"""
IDE_PLUGIN = "ide_plugin"
STANDALONE_IDE = "standalone_ide"
AGENT = "agent"
CLI = "cli"
@dataclass
class AITool:
"""AI编程工具"""
name: str
company: str
category: ProductCategory
pricing: PricingModel
monthly_price: float
languages_supported: List[str]
key_features: List[str]
model_used: str
founded_year: int
website: str
valuation: Optional[float] = None # 亿美元
funding: Optional[float] = None # 亿美元
employees: Optional[int] = None
arr: Optional[float] = None # 年经常性收入,亿美元
def to_dict(self) -> Dict:
return {
"name": self.name,
"company": self.company,
"category": self.category.value,
"pricing": self.pricing.value,
"monthly_price": self.monthly_price,
"languages_count": len(self.languages_supported),
"key_features": self.key_features,
"model": self.model_used,
"founded": self.founded_year,
"valuation_m": self.valuation,
"funding_m": self.funding,
"arr_m": self.arr,
}
@dataclass
class Acquisition:
"""收购记录"""
target: str
acquirer: str
amount: float # 亿美元
date: str
deal_type: str # full_acquisition, acquihire, technology_licensing
details: str
class CompetitiveAnalysis:
"""竞争分析引擎"""
def __init__(self):
self.tools: Dict[str, AITool] = {}
self.acquisitions: List[Acquisition] = []
self._init_data()
def _init_data(self):
"""初始化竞品数据"""
# Windsurf
self.tools["windsurf"] = AITool(
name="Windsurf",
company="Windsurf AI",
category=ProductCategory.IDE_PLUGIN,
pricing=PricingModel.SUBSCRIPTION,
monthly_price=15.0,
languages_supported=["Python", "JavaScript", "TypeScript", "Go", "Rust", "Java",
"C++", "C#", "Ruby", "PHP", "Swift", "Kotlin", "SQL"],
key_features=["Flow State", "多文件编辑", "上下文感知", "实时建议"],
model_used="Codeium + GPT-4",
founded_year=2022,
website="windsurf.com",
)
# Cursor
self.tools["cursor"] = AITool(
name="Cursor",
company="Anysphere",
category=ProductCategory.STANDALONE_IDE,
pricing=PricingModel.SUBSCRIPTION,
monthly_price=20.0,
languages_supported=["Python", "JavaScript", "TypeScript", "Go", "Rust", "Java",
"C++", "C#", "Ruby", "PHP", "Swift", "Kotlin"],
key_features=["AI First", "Composer", "多模型支持", "Codebase感知"],
model_used="GPT-4o, Claude, Gemini",
founded_year=2023,
website="cursor.sh",
valuation=29.0, # 2025年11月融资
funding=0.4,
arr=2.0, # 2026年2月ARR
)
# GitHub Copilot
self.tools["copilot"] = AITool(
name="GitHub Copilot",
company="GitHub (Microsoft)",
category=ProductCategory.IDE_PLUGIN,
pricing=PricingModel.PER_SEAT,
monthly_price=10.0,
languages_supported=["Python", "JavaScript", "TypeScript", "Go", "Rust", "Java",
"C++", "C#", "Ruby", "PHP", "Swift", "Kotlin", "SQL"],
key_features=["代码补全", "单元测试生成", "文档生成", "安全扫描"],
model_used="GPT-4, Codex",
founded_year=2021,
website="github.com/features/copilot",
arr=10.0, # 估算
)
# Devin (Cognition)
self.tools["devin"] = AITool(
name="Devin",
company="Cognition AI",
category=ProductCategory.AGENT,
pricing=PricingModel.SUBSCRIPTION,
monthly_price=50.0,
languages_supported=["Python", "JavaScript", "TypeScript", "Go", "Rust", "Java",
"C++", "C#", "Ruby", "PHP"],
key_features=["自主编码Agent", "端到端任务执行", "PR创建", "测试编写"],
model_used="Claude, GPT-4, 自研模型",
founded_year=2023,
website="cognition.ai",
valuation=26.0, # 2026年5月融资
funding=2.5,
arr=4.92, # 2026年ARR
)
# Codeium
self.tools["codeium"] = AITool(
name="Codeium",
company="Codeium",
category=ProductCategory.IDE_PLUGIN,
pricing=PricingModel.FREE,
monthly_price=0.0,
languages_supported=["Python", "JavaScript", "TypeScript", "Go", "Rust", "Java",
"C++", "C#", "Ruby", "PHP", "Swift", "Kotlin", "SQL", "70+"],
key_features=["免费使用", "无限使用", "企业版", "自托管选项"],
model_used="自研Codeium模型",
founded_year=2022,
website="codeium.com",
)
# 初始化收购记录
self.acquisitions = [
Acquisition(
target="Windsurf",
acquirer="Google (高管收购) + Cognition (资产)",
amount=2.4 + 0.725, # 谷歌24亿 + Cognition 7.25亿
date="2025年7月",
deal_type="acquihire + technology_licensing",
details="Google收购创始团队和技术许可权,Cognition收购剩余资产"
),
Acquisition(
target="Anysphere (Cursor)",
acquirer="SpaceX",
amount=60.0,
date="2026年4月",
deal_type="full_acquisition",
details="SpaceX获得收购期权,交易与xAI算力合作绑定"
),
Acquisition(
target="io Products",
acquirer="OpenAI",
amount=65.0,
date="2025年5月",
deal_type="full_acquisition",
details="OpenAI收购Jony Ive的AI硬件公司"
),
]
def generate_comparison_report(self) -> str:
"""生成竞品对比报告"""
report = ["=" * 80]
report.append("AI编程工具竞品分析报告")
report.append(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
report.append("=" * 80)
# 市场规模估算
report.append("\n## 市场规模估算")
report.append("-" * 40)
total_market = sum(
tool.arr for tool in self.tools.values() if tool.arr
)
report.append(f"估算总ARR: ${total_market:.2f}亿美元")
report.append(f"年增长率: >100%")
# 估值排行
report.append("\n## 估值排行 (亿美元)")
report.append("-" * 40)
sorted_by_val = sorted(
[(name, tool) for name, tool in self.tools.items() if tool.valuation],
key=lambda x: x[1].valuation,
reverse=True
)
for i, (name, tool) in enumerate(sorted_by_val, 1):
report.append(f"{i}. {tool.name}: ${tool.valuation:.1f}B ({tool.company})")
# 收入排行
report.append("\n## ARR排行 (亿美元)")
report.append("-" * 40)
sorted_by_arr = sorted(
[(name, tool) for name, tool in self.tools.items() if tool.arr],
key=lambda x: x[1].arr,
reverse=True
)
for i, (name, tool) in enumerate(sorted_by_arr, 1):
report.append(f"{i}. {tool.name}: ${tool.arr:.2f}B ARR")
# 收购历史
report.append("\n## 重大收购历史")
report.append("-" * 40)
for acq in self.acquisitions:
report.append(f"\n【{acq.date}】{acq.target}")
report.append(f" 收购方: {acq.acquirer}")
report.append(f" 金额: ${acq.amount:.2f}亿美元")
report.append(f" 类型: {acq.deal_type}")
report.append(f" 详情: {acq.details}")
# 技术对比
report.append("\n## 技术特性对比")
report.append("-" * 40)
report.append(f"{'产品':<15} {'支持语言数':<12} {'月费':<10} {'AI模型':<25}")
report.append("-" * 60)
for tool in self.tools.values():
report.append(
f"{tool.name:<15} {len(tool.languages_supported):<12} "
f"${tool.monthly_price:<9} {tool.model_used:<25}"
)
# 市场份额估算
report.append("\n## 市场份额估算 (按ARR)")
report.append("-" * 40)
for name, tool in sorted_by_arr:
share = (tool.arr / total_market * 100) if total_market > 0 else 0
bar = "█" * int(share / 2)
report.append(f"{tool.name:<15} {share:>5.1f}% {bar}")
return "\n".join(report)
def analyze_windsurf_deal(self) -> str:
"""分析Windsurf收购案"""
report = ["=" * 80]
report.append("Windsurf收购案深度分析")
report.append("=" * 80)
report.append("\n### 事件时间线")
report.append("-" * 40)
report.append("2025年5月: OpenAI计划以$30亿收购 Windsurf")
report.append("2025年7月: OpenAI退出收购谈判")
report.append("2025年7月: Google以$24亿收购创始团队+技术许可")
report.append("2025年7月: Cognition以$7.25亿收购剩余资产")
report.append("\n### 失败原因分析")
report.append("-" * 40)
report.append("1. 监管风险考量")
report.append(" - FTC对大型AI收购审查趋严")
report.append(" - OpenAI与微软的复杂合作关系")
report.append("")
report.append("2. 微软因素")
report.append(" - 微软是OpenAI最大投资者")
report.append(" - Windsurf可能与微软技术栈竞争")
report.append(" - 收购可能引发OpenAI与微软关系紧张")
report.append("")
report.append("3. 估值分歧")
report.append(" - Windsurf期望$30亿融资估值")
report.append(" - OpenAI出价未能满足投资人回报要求")
report.append("\n### 谷歌截胡动机")
report.append("-" * 40)
report.append("1. Codeium战略")
report.append(" - 谷歌拥有Codeium (Windsurf前身)")
report.append(" - Windsurf技术可强化Codeium")
report.append("")
report.append("2. AI编程赛道卡位")
report.append(" - 阻止OpenAI获得AI编码能力")
report.append(" - 强化Google Cloud开发者生态")
report.append("")
report.append("3. 人才争夺")
report.append(" - Windsurf创始人Varun Mohan团队")
report.append(" - 核心技术人才的价值超过产品本身")
report.append("\n### Cognition接手逻辑")
report.append("-" * 40)
report.append("1. 产品线补充")
report.append(" - Devin (Agent) + Windsurf (IDE助手)")
report.append(" - 覆盖不同用户群体")
report.append("")
report.append("2. 团队安置")
report.append(" - Cognition接手约200名员工")
report.append(" - 取消归属期,所有员工获得分红")
report.append("")
report.append("3. 市场竞争")
report.append(" - 与SpaceX收购的Cursor竞争")
report.append(" - 扩大企业市场份额")
report.append("\n### 启示")
report.append("-" * 40)
report.append("1. AI收购需考虑生态伙伴关系")
report.append("2. 人才比产品更值钱")
report.append("3. 创始人与公司绑定是双刃剑")
report.append("4. 员工权益保护影响交易结构")
return "\n".join(report)
def export_to_json(self) -> str:
"""导出JSON格式数据"""
data = {
"tools": {name: tool.to_dict() for name, tool in self.tools.items()},
"acquisitions": [
{
"target": a.target,
"acquirer": a.acquirer,
"amount": a.amount,
"date": a.date,
"deal_type": a.deal_type,
}
for a in self.acquisitions
],
"generated_at": datetime.now().isoformat(),
}
return json.dumps(data, indent=2, ensure_ascii=False)
# 使用示例
if __name__ == "__main__":
analyzer = CompetitiveAnalysis()
# 生成对比报告
print(analyzer.generate_comparison_report())
print("\n")
# 分析Windsurf收购案
print(analyzer.analyze_windsurf_deal())
六、行业影响:AI产业的范式转移
6.1 从"模型即服务"到"软硬一体"
过去五年,AI行业的主流商业模式是"模型即服务"(Model as a Service):
传统模式:
用户 → API调用 → AI模型 → 响应
↑ ↓
←←←← 计费 ←←←←←←←←←←←
问题:
- 边际成本高(每次调用消耗算力)
- 用户黏性低(易于切换供应商)
- 数据获取受限(无法获取本地数据)
- 估值天花板(软件公司估值倍数有限)
OpenAI的收购标志着向"软硬一体"转型:
新模式:
用户 → AI硬件 → 本地AI模型 + 云端AI模型 → 服务
↓
数据闭环
↓
生态锁定
↓
持续收入
6.2 人才战争升级
Jony Ive的加入将引发新一轮设计人才争夺:
苹果的反应:
- 苹果向iPhone产品设计团队提供高达40万美元的RSU留任奖金
- 这是苹果历史上最大规模的单团队留任激励
Meta的跟进:
- 加速AI可穿戴设备研发
- 2027年测试AI Pendant
- 推出"Wearables for Work"企业服务
Google的防御:
- 32亿美元收购Wiz(云安全)
- 24亿美元收购Windsurf核心团队
- 强化AI Agent平台
6.3 IPO前夜的战略布局
OpenAI正在筹备IPO,硬件战略是为上市准备的"杀手锏":
估值故事:
- 纯AI软件公司:$100-200B估值
- 软硬一体AI公司:$300-500B估值
- 潜在iPhone竞品:+$100-200B估值
投资者叙事:
- “我们不是下一个ChatGPT”
- “我们是下一个苹果”
- “AI原生设备将重新定义人机交互”
七、未来展望:2026-2030年AI硬件预测
7.1 短期预测(2026-2027)
| 时间 | 事件 | 概率 |
|---|---|---|
| 2026 Q4 | OpenAI AI音箱发布 | 70% |
| 2027 Q1 | AI手机原型展示 | 80% |
| 2027 Q2 | Apple反击产品发布 | 90% |
| 2027 Q3 | Meta AI眼镜上市 | 75% |
7.2 中期预测(2027-2028)
AI设备出货量:
- 全球AI设备出货量预计超过1亿台
- OpenAI目标:3000万台
应用生态:
- AI原生App Store出现
- 传统App需要适配AI Agent接口
价格战:
- AI设备价格下探至$99-199
- 订阅服务成为主要盈利模式
7.3 长期愿景(2028-2030)
计算平台演进:
2007-2027: 智能手机时代 (iPhone → Android)
2027-2032: AI设备时代 (AI Agent + 硬件)
2032+ : 脑机接口时代? (Neuralink + AI)
OpenAI的野望:
- 成为AI时代的"苹果"
- 掌控从芯片到应用的全栈
- 建立类似iOS的AI OS生态
- 年收入突破$1000亿
八、结论
OpenAI以65亿美元收购Jony Ive的io公司,是AI行业发展的分水岭事件。这不仅是一次简单的收购,而是宣告了AI产业从"纯软件"向"软硬一体"的战略转型。
与此同时,Windsurf收购案的"三国杀"揭示了AI编程赛道的激烈竞争。OpenAI退出、谷歌截胡、Cognition接盘的三方博弈,展现了AI时代人才和技术的战略价值。
核心结论:
- 软硬一体是AI公司的必由之路
- 设计能力将成为AI产品的核心竞争力
- 人才争夺战决定公司兴衰
- 生态锁定比技术领先更重要
- IPO前夜的战略布局将决定估值天花板
这场AI硬件战争才刚刚开始,最终谁能成为"AI时代的苹果",让我们拭目以待。
参考来源
- Bloomberg: “OpenAI to Buy Apple Veteran Jony Ive’s AI Device Startup in $6.5 Billion Deal” (2025年5月21日)
- Forbes Australia: “Everything We know about OpenAI’s $6.5 billion purchase of Jony Ive’s io” (2025年5月23日)
- MacRumors: “Everything We Know About OpenAI’s Planned iPhone Rival” (2026年5月29日)
- TNW: “Cognition’s $26B Raise Bets Agent-First Architecture Beats IDE Tools” (2026年5月29日)
- TechCrunch: “Meta is reportedly developing an AI pendant” (2026年5月30日)
- CSDN: “AI独角兽被瓜分后2号员工怒揭内幕” (2026年5月29日)
本文由AI前沿追踪系统自动生成 发布日期:2026年5月31日 字数:约8,500字 代码占比:约45%
九、技术附录:AI Agent系统设计深度解析
9.1 多模态感知系统架构
以下是模拟AI硬件设备多模态感知系统的Python实现:
"""
AI Device Multimodal Perception System
多模态感知系统 - 模拟OpenAI AI硬件的感知能力
功能:
1. 视觉感知(摄像头输入)
2. 音频感知(麦克风输入)
3. 传感器融合(加速度、陀螺仪等)
4. 环境上下文构建
"""
import asyncio
import json
import time
import threading
from enum import Enum
from dataclasses import dataclass, field
from typing import List, Dict, Any, Optional, Callable
from collections import deque
import random
class SensorType(Enum):
"""传感器类型"""
CAMERA = "camera"
MICROPHONE = "microphone"
ACCELEROMETER = "accelerometer"
GYROSCOPE = "gyroscope"
GPS = "gps"
AMBIENT_LIGHT = "ambient_light"
PROXIMITY = "proximity"
FINGERPRINT = "fingerprint"
class ActivityType(Enum):
"""活动类型识别"""
STATIONARY = "stationary"
WALKING = "walking"
RUNNING = "running"
DRIVING = "driving"
CYCLING = "cycling"
SLEEPING = "sleeping"
UNKNOWN = "unknown"
@dataclass
class SensorReading:
"""传感器读数"""
sensor_type: SensorType
timestamp: float
data: Dict[str, Any]
confidence: float = 1.0
sample_rate: int = 0 # Hz
@dataclass
class VisualContext:
"""视觉上下文"""
scene_type: str # indoor, outdoor, office, home, street
detected_objects: List[str] = field(default_factory=list)
faces_detected: int = 0
text_content: str = ""
dominant_colors: List[str] = field(default_factory=list)
lighting_condition: str = "unknown" # bright, dim, dark
confidence: float = 0.0
@dataclass
class AudioContext:
"""音频上下文"""
sound_type: str # speech, music, noise, silence
speech_detected: bool = False
speaker_count: int = 0
dominant_language: str = "unknown"
volume_level: float = 0.0
acoustic_scene: str = "unknown" # meeting, conversation, street
transcriptions: List[str] = field(default_factory=list)
confidence: float = 0.0
@dataclass
class MotionContext:
"""运动上下文"""
current_activity: ActivityType = ActivityType.UNKNOWN
velocity: float = 0.0 # m/s
heading: float = 0.0 # degrees
altitude: float = 0.0 # meters
step_count: int = 0
activity_confidence: float = 0.0
@dataclass
class LocationContext:
"""位置上下文"""
latitude: float = 0.0
longitude: float = 0.0
altitude: float = 0.0
place_type: str = "unknown" # home, office, restaurant, street
place_name: str = ""
confidence: float = 0.0
country: str = ""
city: str = ""
@dataclass
class MultimodalContext:
"""融合后的多模态上下文"""
timestamp: float
visual: Optional[VisualContext] = None
audio: Optional[AudioContext] = None
motion: Optional[MotionContext] = None
location: Optional[LocationContext] = None
time_of_day: str = "" # morning, afternoon, evening, night
day_of_week: str = ""
social_context: str = "alone" # alone, with_one_person, with_group
device_posture: str = "in_hand" # in_hand, on_table, in_pocket, wearing
def to_prompt_context(self) -> str:
"""转换为适合AI模型处理的上下文文本"""
parts = []
parts.append(f"[时间] {self.day_of_week} {self.time_of_day}")
if self.location and self.location.confidence > 0.5:
parts.append(f"[位置] {self.location.place_type} - {self.location.place_name}")
if self.location.city:
parts.append(f"[城市] {self.location.city}, {self.location.country}")
if self.motion:
parts.append(f"[活动] {self.motion.current_activity.value} (置信度:{self.motion.activity_confidence:.0%})")
if self.motion.current_activity == ActivityType.DRIVING:
parts.append("[注意] 用户正在驾驶")
if self.visual and self.visual.confidence > 0.5:
parts.append(f"[场景] {self.visual.scene_type}")
if self.visual.faces_detected > 0:
parts.append(f"[社交] 检测到{self.visual.faces_detected}人")
parts.append(f"[社交状态] {self.social_context}")
if self.visual.detected_objects:
parts.append(f"[物体] {', '.join(self.visual.detected_objects[:5])}")
if self.audio and self.audio.confidence > 0.5:
if self.audio.speech_detected:
parts.append(f"[对话] 检测到{self.audio.speaker_count}人说话")
if self.audio.transcriptions:
parts.append(f"[转录] {'; '.join(self.audio.transcriptions[:2])}")
parts.append(f"[设备状态] {self.device_posture}")
return "\n".join(parts)
class SensorSimulator:
"""
传感器模拟器
用于测试和演示,实际设备会使用真实的传感器API
"""
def __init__(self):
self.sensors = {s: True for s in SensorType}
self.running = False
self.callbacks: Dict[SensorType, List[Callable]] = {
s: [] for s in SensorType
}
def start(self):
"""启动传感器模拟"""
self.running = True
self._run_camera_simulation()
self._run_microphone_simulation()
self._run_motion_simulation()
self._run_location_simulation()
def stop(self):
"""停止传感器模拟"""
self.running = False
def register_callback(self, sensor: SensorType, callback: Callable):
"""注册传感器回调"""
self.callbacks[sensor].append(callback)
def _run_camera_simulation(self):
"""模拟摄像头数据"""
def simulate():
scenes = ["office", "street", "home", "restaurant"]
while self.running:
reading = SensorReading(
sensor_type=SensorType.CAMERA,
timestamp=time.time(),
data={
"scene": random.choice(scenes),
"brightness": random.uniform(0.3, 1.0),
"detected_objects": random.sample(
["person", "laptop", "phone", "book", "coffee", "desk"],
k=random.randint(2, 5)
),
"faces": random.randint(0, 3)
}
)
for cb in self.callbacks[SensorType.CAMERA]:
cb(reading)
time.sleep(2)
thread = threading.Thread(target=simulate, daemon=True)
thread.start()
def _run_microphone_simulation(self):
"""模拟麦克风数据"""
def simulate():
while self.running:
reading = SensorReading(
sensor_type=SensorType.MICROPHONE,
timestamp=time.time(),
data={
"sound_type": random.choice(["speech", "silence", "music", "noise"]),
"volume": random.uniform(0.1, 0.9),
"speakers": random.randint(0, 2)
}
)
for cb in self.callbacks[SensorType.MICROPHONE]:
cb(reading)
time.sleep(1)
thread = threading.Thread(target=simulate, daemon=True)
thread.start()
def _run_motion_simulation(self):
"""模拟运动传感器数据"""
def simulate():
while self.running:
reading = SensorReading(
sensor_type=SensorType.ACCELEROMETER,
timestamp=time.time(),
data={
"x": random.uniform(-2, 2),
"y": random.uniform(-2, 2),
"z": random.uniform(9.5, 10.5),
"activity": random.choice(list(ActivityType)).value
}
)
for cb in self.callbacks[SensorType.ACCELEROMETER]:
cb(reading)
time.sleep(0.5)
thread = threading.Thread(target=simulate, daemon=True)
thread.start()
def _run_location_simulation(self):
"""模拟位置数据"""
def simulate():
while self.running:
reading = SensorReading(
sensor_type=SensorType.GPS,
timestamp=time.time(),
data={
"lat": 37.7749 + random.uniform(-0.01, 0.01),
"lon": -122.4194 + random.uniform(-0.01, 0.01),
"accuracy": random.uniform(5, 50)
}
)
for cb in self.callbacks[SensorType.GPS]:
cb(reading)
time.sleep(10)
thread = threading.Thread(target=simulate, daemon=True)
thread.start()
class MultimodalPerceptionEngine:
"""
多模态感知引擎
融合来自不同传感器的数据,构建统一的环境上下文
"""
def __init__(self):
self.sensor_simulator = SensorSimulator()
self.visual_context = None
self.audio_context = None
self.motion_context = None
self.location_context = None
self.context_history = deque(maxlen=100)
self._setup_processors()
def _setup_processors(self):
"""设置各传感器的处理器"""
self.sensor_simulator.register_callback(
SensorType.CAMERA,
self._process_camera_data
)
self.sensor_simulator.register_callback(
SensorType.MICROPHONE,
self._process_audio_data
)
self.sensor_simulator.register_callback(
SensorType.ACCELEROMETER,
self._process_motion_data
)
self.sensor_simulator.register_callback(
SensorType.GPS,
self._process_location_data
)
def _process_camera_data(self, reading: SensorReading):
"""处理摄像头数据"""
data = reading.data
scene = data.get("scene", "unknown")
objects = data.get("detected_objects", [])
faces = data.get("faces", 0)
# 简单的场景识别
scene_mapping = {
"office": ("indoor", "bright"),
"street": ("outdoor", "bright"),
"home": ("indoor", "dim"),
"restaurant": ("indoor", "dim")
}
scene_type, lighting = scene_mapping.get(scene, ("unknown", "unknown"))
self.visual_context = VisualContext(
scene_type=scene_type,
detected_objects=objects,
faces_detected=faces,
lighting_condition=lighting,
confidence=0.85
)
def _process_audio_data(self, reading: SensorReading):
"""处理音频数据"""
data = reading.data
self.audio_context = AudioContext(
sound_type=data.get("sound_type", "unknown"),
speech_detected=data.get("sound_type") == "speech",
speaker_count=data.get("speakers", 0),
volume_level=data.get("volume", 0.0),
confidence=0.78
)
def _process_motion_data(self, reading: SensorReading):
"""处理运动数据"""
data = reading.data
activity_str = data.get("activity", "unknown")
try:
activity = ActivityType(activity_str)
except ValueError:
activity = ActivityType.UNKNOWN
# 根据加速度判断活动状态
magnitude = (data["x"]**2 + data["y"]**2 + data["z"]**2)**0.5
if magnitude > 12:
activity = ActivityType.RUNNING
elif magnitude > 11:
activity = ActivityType.WALKING
elif magnitude > 10:
activity = ActivityType.STATIONARY
self.motion_context = MotionContext(
current_activity=activity,
activity_confidence=0.82,
step_count=getattr(self.motion_context, 'step_count', 0) + 1 if activity == ActivityType.WALKING else getattr(self.motion_context, 'step_count', 0)
)
def _process_location_data(self, reading: SensorReading):
"""处理位置数据"""
data = reading.data
# 简单的地点类型判断
lat, lon = data.get("lat", 0), data.get("lon", 0)
# 基于坐标的简单判断(实际应使用Places API)
place_type = "street"
if 37.76 < lat < 37.79 and -122.43 < lon < -122.40:
place_type = "office"
self.location_context = LocationContext(
latitude=lat,
longitude=lon,
place_type=place_type,
confidence=0.72,
city="San Francisco",
country="USA"
)
def get_fused_context(self) -> MultimodalContext:
"""获取融合后的多模态上下文"""
now = time.time()
# 确定时间
hour = (now % 86400) // 3600
if 6 <= hour < 12:
time_of_day = "morning"
elif 12 <= hour < 18:
time_of_day = "afternoon"
elif 18 <= hour < 22:
time_of_day = "evening"
else:
time_of_day = "night"
days = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"]
day_of_week = days[int((now // 86400) + 4) % 7]
# 判断社交上下文
social_context = "alone"
if self.visual_context and self.visual_context.faces_detected >= 2:
social_context = "with_group"
elif self.visual_context and self.visual_context.faces_detected == 1:
social_context = "with_one_person"
# 判断设备姿态
device_posture = "in_hand"
if self.motion_context:
if self.motion_context.current_activity == ActivityType.STATIONARY:
if self.visual_context and self.visual_context.scene_type == "indoor":
device_posture = "on_table"
context = MultimodalContext(
timestamp=now,
visual=self.visual_context,
audio=self.audio_context,
motion=self.motion_context,
location=self.location_context,
time_of_day=time_of_day,
day_of_week=day_of_week,
social_context=social_context,
device_posture=device_posture
)
# 保存历史
self.context_history.append(context)
return context
def start(self):
"""启动感知引擎"""
self.sensor_simulator.start()
def stop(self):
"""停止感知引擎"""
self.sensor_simulator.stop()
async def demo_multimodal():
"""演示多模态感知系统"""
print("=" * 60)
print("AI Device Multimodal Perception System Demo")
print("=" * 60)
# 初始化感知引擎
engine = MultimodalPerceptionEngine()
engine.start()
# 等待传感器初始化
await asyncio.sleep(3)
# 获取融合后的上下文
for i in range(5):
context = engine.get_fused_context()
print(f"\n[样本 {i+1}]")
print("-" * 40)
print(context.to_prompt_context())
# 构建AI请求上下文
ai_context = f"""
当前用户状态:
{context.to_prompt_context()}
基于以上上下文,请判断:
1. 用户当前最可能的需求是什么?
2. 应该如何调整AI响应策略?
"""
print(f"\n[AI请求上下文]\n{ai_context}")
await asyncio.sleep(2)
engine.stop()
print("\n演示完成")
if __name__ == "__main__":
asyncio.run(demo_multimodal())
9.2 边缘-云端协同推理架构
以下是Go语言实现的边缘-云端协同推理系统:
package hybrid
/*
Hybrid Edge-Cloud Inference System
边缘-云端协同推理系统
设计目标:
1. 边缘优先,减少延迟
2. 智能路由,优化成本
3. 隐私保护,数据本地
4. 弹性扩展,云端增强
*/
import (
"context"
"encoding/json"
"fmt"
"log"
"sync"
"time"
)
// ===== 配置结构 =====
// InferenceConfig 推理配置
type InferenceConfig struct {
// 边缘设置
EdgeEnabled bool
EdgeEndpoint string
EdgeAPITimeout time.Duration
// 云端设置
CloudEnabled bool
CloudEndpoint string
CloudAPITimeout time.Duration
// 路由策略
RoutingStrategy string // "latency", "cost", "privacy", "quality"
// 模型配置
PreferredModel string
FallbackModels []string
}
// RoutingDecision 路由决策
type RoutingDecision struct {
Target string `json:"target"` // "edge" 或 "cloud"
Model string `json:"model"`
Reason string `json:"reason"`
EstimatedMs int64 `json:"estimated_ms"`
CostEstimate float64 `json:"cost_estimate"`
Timestamp time.Time `json:"timestamp"`
}
// ===== 推理请求 =====
// Request 推理请求
type Request struct {
ID string `json:"id"`
UserID string `json:"user_id"`
Input string `json:"input"`
InputType string `json:"input_type"` // "text", "image", "audio"
Model string `json:"model"`
MaxTokens int `json:"max_tokens"`
Temperature float64 `json:"temperature"`
Metadata map[string]interface{} `json:"metadata"`
Priority int `json:"priority"`
// 隐私相关
ContainsPII bool `json:"contains_pii"` // 包含个人信息
RequiresPrivacy bool `json:"requires_privacy"` // 需要隐私保护
// 性能要求
MaxLatencyMs int64 `json:"max_latency_ms"` // 最大延迟要求
CreatedAt time.Time `json:"created_at"`
}
// Response 推理响应
type Response struct {
RequestID string `json:"request_id"`
Output string `json:"output"`
Model string `json:"model"`
TokensUsed int `json:"tokens_used"`
LatencyMs int64 `json:"latency_ms"`
InferenceType string `json:"inference_type"` // "edge", "cloud", "hybrid"
Cost float64 `json:"cost"`
CacheHit bool `json:"cache_hit"`
Error string `json:"error,omitempty"`
Metadata map[string]any `json:"metadata,omitempty"`
CompletedAt time.Time `json:"completed_at"`
}
// ===== 路由器 =====
// Router 智能路由器
type Router struct {
config InferenceConfig
// 性能指标
edgeLatencyAvg int64
cloudLatencyAvg int64
edgeSuccessRate float64
cloudSuccessRate float64
mu sync.RWMutex
}
// NewRouter 创建路由器
func NewRouter(config InferenceConfig) *Router {
return &Router{
config: config,
edgeLatencyAvg: 50,
cloudLatencyAvg: 200,
edgeSuccessRate: 0.98,
cloudSuccessRate: 0.999,
}
}
// Decide 决定路由策略
func (r *Router) Decide(req *Request) RoutingDecision {
r.mu.RLock()
defer r.mu.RUnlock()
decision := RoutingDecision{
Timestamp: time.Now(),
}
// 1. 隐私优先策略
if r.config.RoutingStrategy == "privacy" || req.RequiresPrivacy || req.ContainsPII {
decision.Target = "edge"
decision.Model = "gpt-5-edge-int4"
decision.Reason = "隐私保护:请求包含敏感信息,优先本地处理"
decision.EstimatedMs = r.edgeLatencyAvg
decision.CostEstimate = 0
return decision
}
// 2. 延迟优先策略
if r.config.RoutingStrategy == "latency" || req.MaxLatencyMs > 0 {
if req.MaxLatencyMs < int64(r.edgeLatencyAvg*2) {
decision.Target = "edge"
decision.Model = "gpt-5-edge-int4"
decision.Reason = fmt.Sprintf("延迟要求:要求<%dms,选择边缘", req.MaxLatencyMs)
decision.EstimatedMs = r.edgeLatencyAvg
decision.CostEstimate = 0
return decision
}
}
// 3. 成本优先策略
if r.config.RoutingStrategy == "cost" {
decision.Target = "edge"
decision.Model = "gpt-5-edge-int4"
decision.Reason = "成本优化:边缘推理零边际成本"
decision.EstimatedMs = r.edgeLatencyAvg * 2 // 保守估计
decision.CostEstimate = 0
return decision
}
// 4. 质量优先策略
if r.config.RoutingStrategy == "quality" {
decision.Target = "cloud"
decision.Model = "gpt-5-cloud"
decision.Reason = "质量优先:云端使用完整模型"
decision.EstimatedMs = r.cloudLatencyAvg
decision.CostEstimate = float64(len(req.Input)) * 0.00001
return decision
}
// 5. 智能默认策略
// 根据请求特征自动选择
switch {
case len(req.Input) < 500:
// 短文本优先边缘
decision.Target = "edge"
decision.Model = "gpt-5-edge-int4"
decision.Reason = "短文本:使用边缘模型"
decision.EstimatedMs = r.edgeLatencyAvg
decision.CostEstimate = 0
case req.Priority >= 8:
// 高优先级走云端
decision.Target = "cloud"
decision.Model = "gpt-5-cloud"
decision.Reason = "高优先级:使用云端完整能力"
decision.EstimatedMs = r.cloudLatencyAvg
decision.CostEstimate = float64(len(req.Input)) * 0.00001
case req.InputType == "image":
// 图片走云端(边缘视觉模型资源有限)
decision.Target = "cloud"
decision.Model = "gpt-5-vision"
decision.Reason = "视觉输入:使用云端视觉模型"
decision.EstimatedMs = r.cloudLatencyAvg * 2
decision.CostEstimate = float64(len(req.Input)) * 0.00005
default:
// 默认边缘
decision.Target = "edge"
decision.Model = "gpt-5-edge-int4"
decision.Reason = "默认:使用边缘模型"
decision.EstimatedMs = r.edgeLatencyAvg * 2
decision.CostEstimate = 0
}
return decision
}
// UpdateMetrics 更新性能指标
func (r *Router) UpdateMetrics(target string, latencyMs int64, success bool) {
r.mu.Lock()
defer r.mu.Unlock()
if target == "edge" {
r.edgeLatencyAvg = (r.edgeLatencyAvg*9 + latencyMs) / 10
if success {
r.edgeSuccessRate = r.edgeSuccessRate*0.99 + 0.01
} else {
r.edgeSuccessRate *= 0.9
}
} else {
r.cloudLatencyAvg = (r.cloudLatencyAvg*9 + latencyMs) / 10
if success {
r.cloudSuccessRate = r.cloudSuccessRate*0.99 + 0.01
} else {
r.cloudSuccessRate *= 0.9
}
}
}
// GetStatus 获取路由器状态
func (r *Router) GetStatus() map[string]interface{} {
r.mu.RLock()
defer r.mu.RUnlock()
return map[string]interface{}{
"strategy": r.config.RoutingStrategy,
"edge_latency_ms": r.edgeLatencyAvg,
"cloud_latency_ms": r.cloudLatencyAvg,
"edge_success_rate": r.edgeSuccessRate,
"cloud_success_rate": r.cloudSuccessRate,
}
}
// ===== 推理引擎 =====
// Engine 混合推理引擎
type Engine struct {
router *Router
cache *LRUCache
endpoints map[string]string
authTokens map[string]string
mu sync.RWMutex
}
// NewEngine 创建推理引擎
func NewEngine(config InferenceConfig) *Engine {
return &Engine{
router: NewRouter(config),
cache: NewLRUCache(10000),
endpoints: map[string]string{
"edge": config.EdgeEndpoint,
"cloud": config.CloudEndpoint,
},
authTokens: make(map[string]string),
}
}
// Inference 执行推理
func (e *Engine) Inference(ctx context.Context, req *Request) (*Response, error) {
startTime := time.Now()
// 生成缓存键
cacheKey := e.generateCacheKey(req)
// 检查缓存
if cached := e.cache.Get(cacheKey); cached != nil {
if resp, ok := cached.(*Response); ok {
resp.CacheHit = true
log.Printf("[Cache Hit] RequestID=%s", req.ID)
return resp, nil
}
}
// 路由决策
decision := e.router.Decide(req)
log.Printf("[Routing] Target=%s, Model=%s, Reason=%s",
decision.Target, decision.Model, decision.Reason)
// 执行推理
var resp *Response
var err error
if decision.Target == "edge" {
resp, err = e.edgeInference(ctx, req, decision)
} else {
resp, err = e.cloudInference(ctx, req, decision)
}
// 更新路由器指标
e.router.UpdateMetrics(decision.Target, resp.LatencyMs, err == nil)
// 缓存结果(非错误响应)
if err == nil && !resp.CacheHit {
e.cache.Set(cacheKey, resp)
}
return resp, err
}
// edgeInference 边缘推理
func (e *Engine) edgeInference(ctx context.Context, req *Request, decision RoutingDecision) (*Response, error) {
log.Printf("[Edge Inference] Model=%s, InputLen=%d", decision.Model, len(req.Input))
// 模拟边缘推理
// 实际场景中这里会调用本地模型服务
select {
case <-ctx.Done():
return nil, fmt.Errorf("timeout")
case <-time.After(time.Duration(decision.EstimatedMs) * time.Millisecond):
}
resp := &Response{
RequestID: req.ID,
Model: decision.Model,
TokensUsed: len(req.Input) / 4,
LatencyMs: decision.EstimatedMs,
InferenceType: "edge",
Cost: 0,
CacheHit: false,
CompletedAt: time.Now(),
Output: fmt.Sprintf("[Edge] Processed with %s", decision.Model),
}
return resp, nil
}
// cloudInference 云端推理
func (e *Engine) cloudInference(ctx context.Context, req *Request, decision RoutingDecision) (*Response, error) {
log.Printf("[Cloud Inference] Model=%s, InputLen=%d", decision.Model, len(req.Input))
// 模拟云端推理
// 实际场景中这里会调用OpenAI API
select {
case <-ctx.Done():
return nil, fmt.Errorf("timeout")
case <-time.After(time.Duration(decision.EstimatedMs) * time.Millisecond):
}
resp := &Response{
RequestID: req.ID,
Model: decision.Model,
TokensUsed: len(req.Input) / 3,
LatencyMs: decision.EstimatedMs,
InferenceType: "cloud",
Cost: decision.CostEstimate,
CacheHit: false,
CompletedAt: time.Now(),
Output: fmt.Sprintf("[Cloud] Processed with %s", decision.Model),
}
return resp, nil
}
// generateCacheKey 生成缓存键
func (e *Engine) generateCacheKey(req *Request) string {
data, _ := json.Marshal(map[string]interface{}{
"model": req.Model,
"input": req.Input,
"max_tokens": req.MaxTokens,
"temp": req.Temperature,
})
return fmt.Sprintf("%x", md5Hash(string(data)))
}
func md5Hash(s string) [16]byte {
var hash [16]byte
for i := 0; i < 16 && i < len(s); i++ {
hash[i] = s[i]
}
return hash
}
// ===== LRU缓存 =====
type LRUCache struct {
capacity int
cache map[string]interface{}
order []string
mu sync.Mutex
}
func NewLRUCache(capacity int) *LRUCache {
return &LRUCache{
capacity: capacity,
cache: make(map[string]interface{}),
order: make([]string, 0),
}
}
func (c *LRUCache) Get(key string) interface{} {
c.mu.Lock()
defer c.mu.Unlock()
if val, exists := c.cache[key]; exists {
for i, k := range c.order {
if k == key {
c.order = append(c.order[:i], c.order[i+1:]...)
break
}
}
c.order = append(c.order, key)
return val
}
return nil
}
func (c *LRUCache) Set(key string, value interface{}) {
c.mu.Lock()
defer c.mu.Unlock()
if _, exists := c.cache[key]; exists {
c.cache[key] = value
return
}
if len(c.cache) >= c.capacity {
oldest := c.order[0]
delete(c.cache, oldest)
c.order = c.order[1:]
}
c.cache[key] = value
c.order = append(c.order, key)
}
// ===== 使用示例 =====
/*
func main() {
config := InferenceConfig{
EdgeEnabled: true,
EdgeEndpoint: "http://localhost:8080",
CloudEnabled: true,
CloudEndpoint: "https://api.openai.com/v1",
RoutingStrategy: "quality", // 可选: latency, cost, privacy, quality
PreferredModel: "gpt-5",
FallbackModels: []string{"gpt-4", "claude-3"},
}
engine := NewEngine(config)
ctx := context.Background()
// 场景1: 普通查询
req1 := &Request{
ID: "req_001",
UserID: "user_001",
Input: "帮我写一封商务邮件",
InputType: "text",
Model: "gpt-5",
MaxTokens: 500,
}
resp1, _ := engine.Inference(ctx, req1)
fmt.Printf("普通查询: %s (延迟: %dms, 类型: %s)\n",
resp1.Output, resp1.LatencyMs, resp1.InferenceType)
// 场景2: 隐私敏感查询
req2 := &Request{
ID: "req_002",
UserID: "user_001",
Input: "我的信用卡号是1234-5678-9012,请帮我保存",
InputType: "text",
ContainsPII: true,
RequiresPrivacy: true,
}
resp2, _ := engine.Inference(ctx, req2)
fmt.Printf("隐私查询: %s (类型: %s)\n",
resp2.Output, resp2.InferenceType)
// 场景3: 低延迟要求
req3 := &Request{
ID: "req_003",
UserID: "user_001",
Input: "你好",
InputType: "text",
MaxLatencyMs: 50,
}
resp3, _ := engine.Inference(ctx, req3)
fmt.Printf("低延迟查询: %s (延迟: %dms, 类型: %s)\n",
resp3.Output, resp3.LatencyMs, resp3.InferenceType)
// 打印路由器状态
status := engine.router.GetStatus()
fmt.Printf("路由器状态: %+v\n", status)
}
*/
十、总结与行动建议
10.1 对AI从业者的建议
关注软硬一体趋势
- 学习嵌入式AI开发
- 了解边缘计算技术栈
- 掌握移动端模型优化
深耕AI Agent领域
- 理解Agent架构设计
- 掌握多模态感知技术
- 实践自主决策系统
关注行业并购动态
- 理解大厂战略意图
- 把握人才流动机会
- 评估创业风险与收益
10.2 对投资人的建议
重点关注标的
- AI硬件初创公司
- 边缘AI推理公司
- AI Agent平台
风险提示
- 硬件周期长、投入大
- 供应链风险
- 监管不确定性
估值逻辑调整
- 从纯软件P/S转向软硬一体P/EBITDA
- 考虑生态系统价值
- 评估用户数据价值
10.3 对普通用户的期待
更智能的设备
- 2027年预计看到初代AI原生设备
- 更自然的人机交互体验
- 隐私保护与便利性的平衡
工作方式变革
- AI编程助手普及
- 自动化工作流
- 新职业机会涌现