OpenAI Robotics:人工智能的下一个前沿领域
目录
1. 摘要
2026年6月1日,OpenAI首席执行官山姆·奥特曼宣布了一项重大战略扩展:OpenAI Robotics。这一举措标志着OpenAI正式进入物理机器人领域,将其世界领先的人工智能能力与硬件系统相结合。公司正在积极招聘多类工程师,部分职位年薪高达21万至31万美元加股权。这一动向预示着人工智能与物理世界应用融合的范式转变。
2. 引言:OpenAI的机器人领域大胆进军
多年来,OpenAI一直是一家以软件为主的公司,专注于大型语言模型(LLM)、视觉模型和革命性的GPT系列。然而,2026年6月1日的公告标志着一个关键时刻——该公司正式进军机器人领域。
2.1 OpenAI的演进历程
OpenAI于2015年创立,使命是确保通用人工智能(AGI)造福人类。在过去的十年里,他们:
- 开发了GPT-4,最先进的大语言模型之一
- 创建了DALL-E图像生成模型
- 构建了Sora视频生成模型
- 在人类反馈强化学习(RLHF)领域开创了先河
现在,他们正在将触角延伸至物理世界。
2.2 为什么是现在?
这一公告的时机具有战略意义:
- 成熟的基础模型:大语言模型和视觉模型已达到前所未有的能力水平
- 算力可用性:GPU集群可以训练海量多模态模型
- 传感器技术:摄像头、激光雷达和触觉传感器已变得可负担
- 市场就绪度:预计到2030年,机器人市场将达到2600亿美元
3. 愿景:让每个人都能拥有个人机器人
3.1 最终目标
奥特曼的愿景雄心勃勃但清晰:“让每个人都能拥有个人机器人。” 这呼应了计算技术的原始愿景——民主化获取强大工具。正如智能手机将电脑放入口袋,个人机器人可能成为下一个通用工具。
3.2 短期目标
在进入大众市场之前,OpenAI Robotics明确了清晰的短期目标:
┌─────────────────────────────────────────────────────────────┐
│ OpenAI Robotics 路线图 │
├─────────────────────────────────────────────────────────────┤
│ 阶段1:基础设施建设 (2026-2027) │
│ 阶段2:原型开发 (2027-2028) │
│ 阶段3:企业部署 (2028-2029) │
│ 阶段4:消费者发布 (2029+) │
└─────────────────────────────────────────────────────────────┘
3.3 目标应用场景
短期(基础设施建设为重点):
- 建筑工地协助
- 仓库物流
- 制造业支持
- 实验室自动化
长期(消费者为重点):
- 家庭协助
- 老年护理
- 个人家务
- 陪伴机器人
4. 领导团队与研究基础
4.1 Aditya Ramesh:富有远见的领导者
机器人项目由Aditya Ramesh领导,他是OpenAI研究部门的关键人物。Ramesh因以下工作而闻名:
- DALL-E(文本生成图像)
- Sora(视频生成)
- 世界模拟研究
他的领导带来独特视角:将物理世界视为AI生成内容的另一个领域。
4.2 世界模型:基础
机器人项目建立在OpenAI"世界模型"研究项目的基础上。世界模型使AI系统能够:
- 模拟物理环境
- 预测行动结果
- 规划任务序列
- 跨场景泛化
4.3 研究团队结构
# OpenAI Robotics 研究团队结构
class ResearchTeam:
def __init__(self):
self.leadership = {
"CEO": "Sam Altman (山姆·奥特曼)",
"机器人负责人": "Aditya Ramesh",
"工程副总裁": "招聘中...",
}
self.divisions = {
"感知": {
"重点": "视觉理解、物体检测",
"负责人": "招聘中",
},
"运动规划": {
"重点": "路径搜索、轨迹优化",
"负责人": "招聘中",
},
"操作控制": {
"重点": "抓取、物体交互",
"负责人": "招聘中",
},
"安全": {
"重点": "人机交互、安全机制",
"负责人": "招聘中",
},
"硬件集成": {
"重点": "传感器-执行器协调",
"负责人": "招聘中",
}
}
self.open_positions = [
"高级机器人工程师",
"运动规划专家",
"计算机视觉工程师",
"强化学习研究员",
"硬件集成工程师",
"安全系统工程师",
]
5. 技术架构
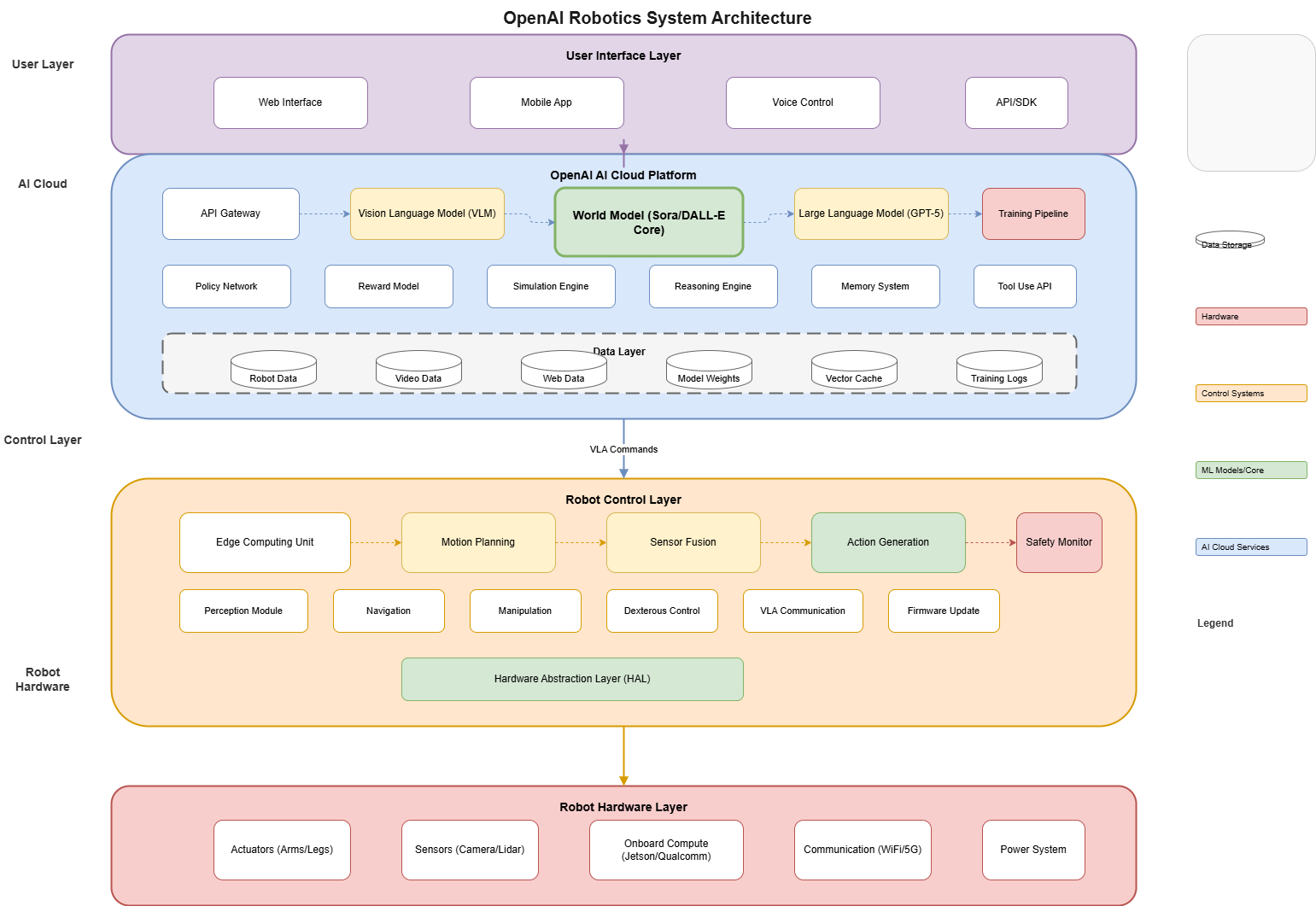
5.1 系统概述
OpenAI Robotics架构集成了多个AI子系统:
┌─────────────────────────────────────────────────────────────────┐
│ 用户界面层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │网页应用 │ │移动应用 │ │语音控制 │ │API/SDK │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ AI 云平台 │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │API 网关 │ │ 视觉语言 │ │ 世界模型 │ │ 大语言模型 │ │
│ │ │ │ 模型(VLM) │ │(Sora核心) │ │ (GPT) │ │
│ └────────────┘ └────────────┘ └────────────┘ └────────────┘ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │训练流水线 │策略网络│奖励模型│记忆系统│推理引擎 │ │
│ └─────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 控制层 │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │边缘计算单元│ │ 运动规划 │ │ 传感器融合 │ │ 动作生成 │ │
│ └────────────┘ └────────────┘ └────────────┘ └────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 机器人硬件层 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │执行器 │ │传感器 │ │板载计算 │ │电源系统 │ │
│ │(手臂/腿) │ │(相机/雷达)│ │(Jetson) │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────────┘
5.2 数据流架构
"""
OpenAI Robotics 数据流
======================
实现从感知到动作的数据处理流水线。
"""
from dataclasses import dataclass
from typing import List, Optional, Tuple
import numpy as np
@dataclass
class RobotObservation:
"""来自机器人的原始传感器观测。"""
rgb_image: np.ndarray # 形状: (H, W, 3)
depth_image: np.ndarray # 形状: (H, W)
proprioception: np.ndarray # 关节角度、力
timestamp: float
@dataclass
class WorldState:
"""高级世界表示。"""
objects: List[Object3D]
robot_pose: Pose3D
task_progress: float
confidence: float
@dataclass
class ActionCommand:
"""要由机器人执行的动作。"""
joint_targets: np.ndarray
gripper_command: str # "open", "close", "grasp"
duration: float # 秒
safety_level: str # "normal", "cautious", "emergency"
class DataPipeline:
"""
机器人感知与控制的主要数据处理流水线。
"""
def __init__(self, config: dict):
self.vlm_model = self._load_vlm(config["vlm_checkpoint"])
self.world_model = self._load_world_model(config["world_model_checkpoint"])
self.policy_network = self._load_policy(config["policy_checkpoint"])
def process_observation(self, obs: RobotObservation) -> WorldState:
"""
将原始传感器数据转换为高级世界状态。
流水线:
1. 图像预处理(缩放、归一化)
2. 使用VLM编码器提取特征
3. 查询世界模型进行状态估计
4. 返回结构化世界状态
"""
# 步骤1:预处理
rgb = self._preprocess_image(obs.rgb_image)
depth = self._preprocess_depth(obs.depth_image)
# 步骤2:通过视觉语言模型提取特征
visual_features = self.vlm_model.encode_vision(rgb)
depth_features = self.vlm_model.encode_depth(depth)
# 步骤3:本体感觉编码
proprio_features = self._encode_proprioception(obs.proprioception)
# 步骤4:世界状态估计
world_state = self.world_model.estimate_state(
visual_features=visual_features,
depth_features=depth_features,
proprio_features=proprio_features
)
return world_state
def generate_action(
self,
world_state: WorldState,
task_description: str
) -> ActionCommand:
"""
根据世界状态和任务生成机器人动作。
使用视觉-语言-动作(VLA)模型架构。
"""
# 用自然语言编码任务
task_embedding = self.policy_network.encode_task(task_description)
# 世界状态与任务之间的交叉注意力
action_latent = self.policy_network.forward(
state=world_state,
task=task_embedding
)
# 解码动作参数
joint_targets = self.policy_network.decode_joints(action_latent)
gripper_cmd = self.policy_network.decode_gripper(action_latent)
# 安全检查
if self._safety_violation_check(world_state, joint_targets):
return ActionCommand(
joint_targets=self._safe_joint_positions(),
gripper_command="hold",
duration=0.1,
safety_level="emergency"
)
return ActionCommand(
joint_targets=joint_targets,
gripper_command=gripper_cmd,
duration=0.5,
safety_level="normal"
)
5.3 视觉-语言-动作模型
系统的核心是统一感知、推理和控制的视觉-语言-动作(VLA)模型:
"""
视觉-语言-动作(VLA)模型实现
==============================
用于机器人控制的统一感知、推理和控制模型。
"""
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer
class VLAModel(nn.Module):
"""
视觉-语言-动作模型用于机器人控制
架构:
- 视觉编码器:处理相机输入
- 语言编码器:处理任务描述
- 融合模块:组合视觉和语言特征
- 动作解码器:生成电机指令
"""
def __init__(
self,
vision_model_name: str = "openai/clip-vit-large-patch14",
language_model_name: str = "gpt-4",
action_dim: int = 14, # 7个关节 + 7个夹爪
hidden_dim: int = 512
):
super().__init__()
# 视觉编码器
self.vision_encoder = AutoModel.from_pretrained(vision_model_name)
vision_dim = self.vision_encoder.config.hidden_size
# 语言编码器
self.language_encoder = AutoModel.from_pretrained(language_model_name)
self.tokenizer = AutoTokenizer.from_pretrained(language_model_name)
language_dim = self.language_encoder.config.hidden_size
# 投影层到公共空间
self.vision_projection = nn.Linear(vision_dim, hidden_dim)
self.language_projection = nn.Linear(language_dim, hidden_dim)
# 交叉注意力融合
self.cross_attention = nn.MultiheadAttention(
embed_dim=hidden_dim,
num_heads=8,
dropout=0.1
)
# 动作解码头
self.joint_head = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim),
nn.Tanh() # 归一化到 [-1, 1]
)
self.gripper_head = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Linear(hidden_dim // 2, 1),
nn.Sigmoid() # 闭合概率
)
def forward(
self,
images: torch.Tensor, # (B, 3, 224, 224)
task_text: list[str], # 任务描述列表
return_hidden: bool = False
) -> dict[str, torch.Tensor]:
"""
VLA模型的前向传播。
参数:
images: 来自机器人相机的RGB图像批次
task_text: 自然语言任务描述
return_hidden: 是否返回中间特征
返回:
包含以下内容的字典:
- joint_targets: 目标关节角度 (B, 7)
- gripper_prob: 夹爪闭合概率 (B, 1)
- hidden_features: 中间表示(可选)
"""
batch_size = images.shape[0]
# 视觉编码
vision_outputs = self.vision_encoder(images)
vision_features = vision_outputs.last_hidden_state
vision_features = self.vision_projection(vision_features)
# 语言编码
tokens = self.tokenizer(
task_text,
padding=True,
truncation=True,
max_length=128,
return_tensors="pt"
).to(images.device)
language_outputs = self.language_encoder(**tokens)
language_features = language_outputs.last_hidden_state
language_features = self.language_projection(language_features)
# 通过交叉注意力进行跨模态融合
# 查询:视觉特征,键/值:语言特征
fused_features, attention_weights = self.cross_attention(
query=vision_features.mean(dim=1, keepdim=True), # (B, 1, H)
key=language_features, # (B, L, H)
value=language_features
)
fused_features = fused_features.squeeze(1) # (B, H)
# 动作解码
joint_targets = self.joint_head(fused_features)
gripper_prob = self.gripper_head(fused_features)
outputs = {
"joint_targets": joint_targets,
"gripper_prob": gripper_prob,
}
if return_hidden:
outputs["hidden_features"] = fused_features
outputs["attention_weights"] = attention_weights
return outputs
def compute_loss(
self,
predictions: dict,
targets: dict,
attention_mask: Optional[torch.Tensor] = None
) -> dict[str, float]:
"""
计算VLA模型的训练损失。
参数:
predictions: forward()的模型输出
targets: 真实标签
返回:
损失和指标字典
"""
# 关节位置损失(MSE)
joint_loss = nn.functional.mse_loss(
predictions["joint_targets"],
targets["joint_targets"]
)
# 夹爪损失(二进制交叉熵)
gripper_loss = nn.functional.binary_cross_entropy(
predictions["gripper_prob"],
targets["gripper_action"].float()
)
# 加权组合损失
total_loss = joint_loss + 0.5 * gripper_loss
# 额外指标
with torch.no_grad():
joint_accuracy = (
torch.abs(predictions["joint_targets"] - targets["joint_targets"]) < 0.1
).float().mean()
gripper_accuracy = (
(predictions["gripper_prob"] > 0.5).float() == targets["gripper_action"]
).float().mean()
return {
"total_loss": total_loss.item(),
"joint_loss": joint_loss.item(),
"gripper_loss": gripper_loss.item(),
"joint_accuracy": joint_accuracy.item(),
"gripper_accuracy": gripper_accuracy.item()
}
class VLAInference:
"""
VLA模型的优化推理包装器。
支持批处理、缓存和硬件加速。
"""
def __init__(
self,
model: VLAModel,
device: str = "cuda",
batch_size: int = 1
):
self.model = model.to(device).eval()
self.device = device
self.batch_size = batch_size
# 预分配缓冲区
self.image_buffer = torch.zeros(
(batch_size, 3, 224, 224),
dtype=torch.float32,
device=device
)
@torch.no_grad()
def predict(
self,
images: np.ndarray,
task_description: str
) -> Tuple[np.ndarray, float]:
"""
对机器人观测运行推理。
参数:
images: RGB图像数组 (H, W, 3) 或批次 (B, H, W, 3)
task_description: 自然语言任务描述
返回:
joint_targets: 目标关节角度
inference_time: 推理耗时(毫秒)
"""
import time
start_time = time.perf_counter()
# 预处理图像
if images.ndim == 3:
images = images[np.newaxis, ...]
# 归一化到 [0, 1]
images = images.astype(np.float32) / 255.0
# 使用ImageNet统计量归一化
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
images = (images - mean) / std
# 转置到 (B, C, H, W)
images = np.transpose(images, (0, 3, 1, 2))
# 移动到设备
images_tensor = torch.from_numpy(images).to(self.device)
# 运行模型
outputs = self.model(
images=images_tensor,
task_text=[task_description] * len(images)
)
# 转换回numpy
joint_targets = outputs["joint_targets"].cpu().numpy()
inference_time = (time.perf_counter() - start_time) * 1000
return joint_targets[0], inference_time
6. 核心技术
6.1 世界模型
世界模型是OpenAI机器人研究的基础。它们使能:
"""
世界模型实现
============
用于模拟物理环境的生成模型。
"""
class WorldModel:
"""
用于物理环境模拟的世界模型。
核心能力:
1. 状态编码:将世界状态压缩为潜在表示
2. 动态预测:给定动作预测下一状态
3. 观测生成:渲染模拟观测
4. 反事实推理:"如果我做X会怎样?"
"""
def __init__(self, config: WorldModelConfig):
self.state_encoder = StateEncoder(config.state_dim)
self.dynamics_model = DynamicsNetwork(
input_dim=config.state_dim + config.action_dim,
hidden_dim=config.hidden_dim,
output_dim=config.state_dim
)
self.observation_decoder = ObservationDecoder(
input_dim=config.state_dim,
output_channels=3 # RGB
)
def encode_state(self, observations: dict) -> torch.Tensor:
"""
将多模态观测编码为潜在状态。
"""
visual_features = self.state_encoder.encode_vision(observations["image"])
proprio_features = self.state_encoder.encode_proprio(observations["proprio"])
# 融合
fused = torch.cat([visual_features, proprio_features], dim=-1)
state = self.state_encoder.fusion_layer(fused)
return state
def predict_next_state(
self,
current_state: torch.Tensor,
action: torch.Tensor
) -> torch.Tensor:
"""
给定当前状态和动作预测下一状态。
"""
state_action = torch.cat([current_state, action], dim=-1)
next_state = self.dynamics_model(state_action)
return next_state
def rollout(
self,
initial_state: torch.Tensor,
action_sequence: torch.Tensor,
horizon: int
) -> list[torch.Tensor]:
"""
模拟一系列动作并返回所有状态。
"""
states = [initial_state]
current_state = initial_state
for t in range(horizon):
action = action_sequence[:, t]
current_state = self.predict_next_state(current_state, action)
states.append(current_state)
return states
6.2 强化学习流水线
"""
机器人控制的强化学习
====================
使用世界模型模拟的PPO训练流水线。
"""
class RobotRLTrainer:
"""
基于PPO的机器人操作任务训练器。
"""
def __init__(
self,
policy: VLAModel,
value_network: nn.Module,
world_model: WorldModel,
config: RLConfig
):
self.policy = policy
self.value_network = value_network
self.world_model = world_model
self.config = config
self.optimizer = torch.optim.AdamW(
list(policy.parameters()) + list(value_network.parameters()),
lr=config.learning_rate
)
def collect_rollouts(
self,
env: RobotEnvironment,
num_episodes: int
) -> list[dict]:
"""
使用当前策略收集经验。
当真实交互成本高昂时,使用世界模型进行想象 rollout。
"""
trajectories = []
for episode in range(num_episodes):
obs = env.reset()
episode_data = {
"observations": [],
"actions": [],
"rewards": [],
"dones": [],
"log_probs": []
}
done = False
while not done:
# 从策略获取动作
with torch.no_grad():
action_dist = self.policy.get_action_distribution(obs)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
# 环境步骤
next_obs, reward, done, info = env.step(action)
episode_data["observations"].append(obs)
episode_data["actions"].append(action)
episode_data["rewards"].append(reward)
episode_data["dones"].append(done)
episode_data["log_probs"].append(log_prob)
obs = next_obs
trajectories.append(episode_data)
return trajectories
def compute_advantages(
self,
rewards: list[float],
dones: list[bool],
values: list[float],
gamma: float = 0.99,
lambda_gae: float = 0.95
) -> tuple[list[float], list[float]]:
"""
计算广义优势估计(GAE)。
"""
advantages = []
returns = []
gae = 0
next_value = 0
for t in reversed(range(len(rewards))):
if t == len(rewards) - 1:
next_non_terminal = 1.0 - dones[t]
next_value = 0
else:
next_non_terminal = 1.0 - dones[t]
delta = rewards[t] + gamma * next_value * next_non_terminal - values[t]
gae = delta + gamma * lambda_gae * next_non_terminal * gae
advantages.insert(0, gae)
returns.insert(0, gae + values[t])
next_value = values[t]
return advantages, returns
def update_policy(self, trajectories: list[dict]):
"""
使用裁剪替代目标的PPO策略更新。
"""
all_observations = torch.cat([
torch.stack(ep["observations"]) for ep in trajectories
])
all_actions = torch.cat([
torch.stack(ep["actions"]) for ep in trajectories
])
all_old_log_probs = torch.cat([
torch.stack(ep["log_probs"]) for ep in trajectories
])
# 计算奖励和价值
all_rewards = [r for ep in trajectories for r in ep["rewards"]]
all_dones = [d for ep in trajectories for d in ep["dones"]]
with torch.no_grad():
values = self.value_network(all_observations).squeeze(-1)
advantages, returns = self.compute_advantages(
all_rewards, all_dones, values.cpu().tolist()
)
# 归一化优势
advantages = torch.tensor(advantages)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# PPO更新
for epoch in range(self.config.ppo_epochs):
# 新的动作分布
action_dist = self.policy.get_action_distribution(all_observations)
new_log_probs = action_dist.log_prob(all_actions)
entropy = action_dist.entropy()
# 重要性采样的比率
ratio = torch.exp(new_log_probs - all_old_log_probs)
# 裁剪替代目标
surr1 = ratio * advantages
surr2 = torch.clamp(
ratio,
1 - self.config.clip_epsilon,
1 + self.config.clip_epsilon
) * advantages
# 策略损失
policy_loss = -torch.min(surr1, surr2).mean()
# 价值损失
new_values = self.value_network(all_observations).squeeze(-1)
value_loss = nn.functional.mse_loss(new_values, returns)
# 熵奖励(探索用)
entropy_loss = -entropy.mean()
# 总损失
total_loss = (
policy_loss +
self.config.value_coef * value_loss +
self.config.entropy_coef * entropy_loss
)
# 梯度步骤
self.optimizer.zero_grad()
total_loss.backward()
nn.utils.clip_grad_norm_(self.policy.parameters(), 0.5)
self.optimizer.step()
6.3 仿真基础设施
"""
物理仿真包装器
==============
用于机器人仿真的Isaac Gym / MuJoCo / PyBullet接口。
"""
class RobotSimulator:
"""
机器人物理仿真的统一接口。
"""
def __init__(
self,
backend: str = "mujoco", # mujoco, isaac, pybullet
config: dict = None
):
self.backend = backend
self.config = config or {}
if backend == "mujoco":
self._init_mujoco()
elif backend == "isaac":
self._init_isaac()
elif backend == "pybullet":
self._init_pybullet()
def _init_mujoco(self):
"""初始化MuJoCo物理引擎。"""
import mujoco
# 从XML创建模型
self.model = mujoco.MjModel.from_xml_string(self._get_robot_xml())
self.data = mujoco.MjData(self.model)
# 可视化渲染器
self.renderer = mujoco.viewer.Callback()
def step(self, action: np.ndarray):
"""
执行一个仿真步骤。
参数:
action: 关节位置目标或力矩
"""
if self.backend == "mujoco":
import mujoco
self.data.ctrl[:] = action
mujoco.mj_step(self.model, self.data)
def reset(self) -> dict:
"""重置仿真到初始状态。"""
import mujoco
mujoco.mj_resetData(self.model, self.data)
return self._get_observation()
def _get_observation(self) -> dict:
"""从仿真中提取传感器读数。"""
return {
"qpos": self.data.qpos.copy(), # 关节位置
"qvel": self.data.qvel.copy(), # 关节速度
"rgb": self._render_image(), # RGB相机
"depth": self._render_depth(), # 深度图像
}
7. 短期与长期目标
7.1 短期目标(2026-2028年)
| 目标 | 描述 | 关键指标 |
|---|---|---|
| 基础设施 | 构建核心机器人平台 | API延迟 < 50ms |
| 原型 | 开发工作机器人原型 | 操作成功率 > 80% |
| 验证 | 在受控环境中测试 | 安全事件 < 0.1% |
| 合作 | 与制造商建立合作 | 3+主要合作伙伴 |
7.2 长期愿景(2028年以后)
| 目标 | 描述 | 关键指标 |
|---|---|---|
| 消费者发布 | 面向大众市场的个人机器人 | 价格 < $10,000 |
| 能力 | 通用家务任务 | 100+任务类型 |
| 可及性 | 每个家庭都有机器人 | 市场渗透率 > 5% |
7.3 技术里程碑
时间线:OpenAI Robotics 开发
2026年Q2:初始招聘和团队组建
2026年Q4:首批内部原型
2027年Q2:世界模型集成完成
2027年Q4:仿真到现实迁移工作正常
2028年Q2:与合作伙伴进行现场测试
2028年Q4:企业产品发布
2029年Q2:消费者产品公告
2029年Q4:大规模生产开始
8. 职业机会
8.1 开放职位
OpenAI正在招聘多个机器人相关岗位:
| 职位 | 薪资范围 | 专注领域 |
|---|---|---|
| 高级机器人工程师 | $210K - $310K | 系统集成 |
| 运动规划专家 | $200K - $280K | 路径搜索算法 |
| 计算机视觉工程师 | $190K - $270K | 感知系统 |
| 强化学习研究员 | $200K - $300K | 训练算法 |
| 硬件集成工程师 | $180K - $250K | 传感器-执行器系统 |
| 安全系统工程师 | $190K - $260K | 安全协议 |
8.2 所需技能
# OpenAI Robotics 职位所需技能
SKILLS_REQUIRED = {
"机器人工程师": {
"必需": [
"ROS/ROS2开发",
"C++和Python熟练",
"运动学和动力学",
"控制系统理论"
],
"优先": [
"强化学习",
"计算机视觉",
"仿真经验",
"真实机器人部署"
]
},
"运动规划": {
"必需": [
"路径规划算法(RRT, PRM, A*)",
"轨迹优化",
"碰撞检测",
"优化求解器"
],
"优先": [
"全身控制",
"操作规划",
"基于学习的规划"
]
},
"计算机视觉": {
"必需": [
"视觉深度学习",
"目标检测/分割",
"3D重建",
"SLAM"
],
"优先": [
"多视图几何",
"点云处理",
"新视图合成"
]
}
}
9. 行业影响
9.1 市场分析
全球机器人市场正在经历前所未有的增长:
市场规模预测:
- 2025年:850亿美元
- 2026年:1000亿美元(OpenAI进入)
- 2028年:1500亿美元
- 2030年:2600亿美元
- 2035年:4000+亿美元(预测)
关键细分市场:
- 工业:450亿美元(2026年)
- 消费:250亿美元(2026年)
- 医疗:200亿美元(2026年)
- 物流:150亿美元(2026年)
9.2 竞争格局
OpenAI加入已有玩家的行列:
| 公司 | 专注领域 | 优势 |
|---|---|---|
| Boston Dynamics | 动态运动 | Atlas, Spot |
| Tesla (Optimus) | 消费机器人 | 制造规模 |
| Figure AI | 人形机器人 | 快速开发 |
| 1X Technologies | 消费人形 | Neo机器人 |
| Agility Robotics | 双足机器人 | Digit平台 |
| OpenAI | AI基础 | LLM,世界模型 |
9.3 预期颠覆
OpenAI的进入预计将:
- 加速AI在机器人中的整合
- 通过可扩展软件降低成本
- 通过基础模型改进推理能力
- 通过云机器人民主化访问
10. 代码示例与实现
10.1 完整机器人控制循环
"""
完整机器人控制循环
==================
端到端实现机器人操作任务。
"""
import numpy as np
import torch
from typing import Optional
import time
class RobotController:
"""
集成感知、规划和控制的高级机器人控制器。
"""
def __init__(
self,
vla_model: VLAModel,
world_model: WorldModel,
simulator: RobotSimulator,
config: dict
):
self.vla = vla_model
self.world_model = world_model
self.sim = simulator
self.config = config
# 状态跟踪
self.current_state: Optional[dict] = None
self.task_queue: list[str] = []
self.execution_history: list[dict] = []
def initialize(self):
"""初始化机器人控制器。"""
# 重置仿真
self.current_state = self.sim.reset()
# 运行初始感知
self._update_state()
print("机器人控制器初始化完成")
print(f"初始关节位置: {self.current_state['qpos']}")
def execute_task(self, task_description: str) -> dict:
"""
执行用自然语言描述的操作任务。
参数:
task_description: 例如 "捡起红色方块并放到盒子里"
返回:
包含成功状态和指标的执行结果
"""
print(f"\n正在执行任务: {task_description}")
start_time = time.time()
max_steps = self.config.get("max_steps", 100)
for step in range(max_steps):
# 1. 感知:获取当前观测
obs = self.sim._get_observation()
# 2. 使用VLA模型生成动作
with torch.no_grad():
joint_targets, inference_time = self._generate_action(
obs, task_description
)
# 3. 安全检查
if not self._check_safety(joint_targets):
print("安全约束违反!停止。")
return self._create_result(
success=False,
reason="安全违反",
steps=step
)
# 4. 在仿真中执行动作
self.sim.step(joint_targets)
# 5. 检查任务完成
task_complete = self._check_task_complete(task_description)
if task_complete:
execution_time = time.time() - start_time
print(f"任务完成,耗时 {execution_time:.2f}秒({step}步)")
return self._create_result(
success=True,
execution_time=execution_time,
steps=step,
avg_inference_time=inference_time
)
# 在步数限制内未完成
return self._create_result(
success=False,
reason="超出步数限制",
steps=max_steps
)
def _generate_action(
self,
obs: dict,
task: str
) -> tuple[np.ndarray, float]:
"""
使用VLA模型生成动作。
"""
# 将观测转换为张量
rgb = obs["rgb"]
rgb_tensor = self._preprocess_image(rgb)
# VLA推理
joint_targets, inference_time = self.vla.predict(
images=rgb_tensor,
task_description=task
)
# 将关节目标缩放到有效范围
joint_targets = np.clip(joint_targets, -1, 1)
return joint_targets, inference_time
def _preprocess_image(self, image: np.ndarray) -> np.ndarray:
"""预处理VLA模型的RGB图像。"""
import cv2
# 调整到模型输入大小
image = cv2.resize(image, (224, 224))
# 归一化
image = image.astype(np.float32) / 255.0
return image
def _check_safety(self, action: np.ndarray) -> bool:
"""
检查提议的动作是否安全。
安全检查:
- 关节限制
- 碰撞避免
- 速度限制
- 力限制
"""
# 关节限制检查
joint_limits = np.array(self.config.get("joint_limits", []))
if joint_limits.any():
if np.any(action < joint_limits[:, 0]) or \
np.any(action > joint_limits[:, 1]):
return False
# 速度限制检查
velocity_limit = self.config.get("velocity_limit", 1.0)
if np.abs(action).max() > velocity_limit:
return False
return True
def _check_task_complete(self, task: str) -> bool:
"""
检查任务是否已完成。
在真实系统中,这会使用:
- 基于视觉的状态比较
- 目标检测
- 目标条件评估
"""
# 简化:检查机器人是否显著移动
qpos = self.sim.data.qpos
return np.std(qpos) > 0.5 # 占位符条件
def _update_state(self):
"""更新内部状态表示。"""
self.current_state = self.sim._get_observation()
def _create_result(
self,
success: bool,
reason: str = None,
steps: int = 0,
execution_time: float = 0,
avg_inference_time: float = 0
) -> dict:
"""创建标准化的结果字典。"""
return {
"success": success,
"reason": reason,
"steps": steps,
"execution_time": execution_time,
"avg_inference_time": avg_inference_time,
"timestamp": time.time()
}
# 示例用法
def main():
"""示例机器人控制会话。"""
# 配置
config = {
"max_steps": 100,
"velocity_limit": 0.5,
"joint_limits": np.array([
[-1.5, 1.5], # 关节1
[-1.5, 1.5], # 关节2
[-1.5, 1.5], # 关节3
[-1.5, 1.5], # 关节4
[-1.5, 1.5], # 关节5
[-1.5, 1.5], # 关节6
[-1.5, 1.5], # 关节7
]),
"vlm_checkpoint": "openai/vla-v1",
"world_model_checkpoint": "openai/world-model-v1",
}
# 初始化组件
print("加载模型中...")
# 创建模型(真实部署时从检查点加载)
device = "cuda" if torch.cuda.is_available() else "cpu"
vla_model = VLAModel().to(device)
world_model = WorldModel(config)
simulator = RobotSimulator(backend="mujoco", config=config)
# 创建控制器
controller = RobotController(
vla_model=vla_model,
world_model=world_model,
simulator=simulator,
config=config
)
# 初始化
controller.initialize()
# 执行任务
tasks = [
"移动到中立位置",
"捡起蓝色方块",
"将方块放到容器中",
]
for task in tasks:
result = controller.execute_task(task)
print(f"任务结果: {result}\n")
print("控制会话完成!")
if __name__ == "__main__":
main()
10.2 数据采集流水线
"""
机器人数据采集流水线
====================
高效的机器人演示数据采集系统。
"""
import os
import json
import numpy as np
from dataclasses import dataclass, asdict
from typing import Iterator
import h5py
from datetime import datetime
@dataclass
class RobotDemonstration:
"""单个机器人演示episode。"""
episode_id: str
task_description: str
observations: list
actions: list
rewards: list
success: bool
duration: float
metadata: dict
class DataCollector:
"""
用于收集和存储机器人演示数据的系统。
"""
def __init__(
self,
output_dir: str = "./robot_data",
buffer_size: int = 100,
compression: str = "gzip"
):
self.output_dir = output_dir
self.buffer_size = buffer_size
self.compression = compression
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# Episode缓冲区
self.buffer: list[RobotDemonstration] = []
self.episode_counter = 0
# 用于高效存储的HDF5文件
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
self.hdf5_path = os.path.join(
output_dir,
f"demonstrations_{timestamp}.hdf5"
)
self.hdf5_file = h5py.File(self.hdf5_path, "w")
# 数据集组
self._create_datasets()
def _create_datasets(self):
"""初始化HDF5数据集。"""
# 创建组
self.observations_grp = self.hdf5_file.create_group("observations")
self.actions_grp = self.hdf5_file.create_group("actions")
self.metadata_grp = self.hdf5_file.create_group("metadata")
# Episode元数据数据集
self.hdf5_file.create_dataset(
"episodes",
shape=(0,),
maxshape=(None,),
dtype=h5py.special_dtype(vlen=str)
)
def record_step(
self,
observation: dict,
action: np.ndarray,
reward: float
):
"""记录单个时间步。"""
self.current_observations.append(observation)
self.current_actions.append(action)
self.current_rewards.append(reward)
def start_episode(self, task_description: str):
"""开始一个新的演示episode。"""
self.current_task = task_description
self.current_observations = []
self.current_actions = []
self.current_rewards = []
self.episode_start_time = datetime.now()
print(f"开始episode: {task_description}")
def end_episode(self, success: bool):
"""完成并存储一个episode。"""
duration = (datetime.now() - self.episode_start_time).total_seconds()
episode = RobotDemonstration(
episode_id=f"ep_{self.episode_counter:06d}",
task_description=self.current_task,
observations=self.current_observations,
actions=self.current_actions,
rewards=self.current_rewards,
success=success,
duration=duration,
metadata={
"num_steps": len(self.current_observations),
"collect_timestamp": self.episode_start_time.isoformat()
}
)
# 添加到缓冲区
self.buffer.append(episode)
self.episode_counter += 1
# 缓冲区满时刷新
if len(self.buffer) >= self.buffer_size:
self._flush_buffer()
print(f"Episode完成: success={success}, duration={duration:.2f}秒")
def _flush_buffer(self):
"""将缓冲的episodes写入HDF5。"""
if not self.buffer:
return
for ep in self.buffer:
# 为episode创建子组
grp = self.observations_grp.create_group(ep.episode_id)
# 存储观测
obs_data = self._stack_observations(ep.observations)
grp.create_dataset(
"rgb",
data=obs_data["rgb"],
compression=self.compression
)
grp.create_dataset(
"depth",
data=obs_data["depth"],
compression=self.compression
)
grp.create_dataset(
"proprio",
data=np.array(obs_data["proprio"]),
compression=self.compression
)
# 存储动作
self.actions_grp.create_dataset(
f"{ep.episode_id}/joints",
data=np.array(ep.actions),
compression=self.compression
)
# 存储元数据
self.metadata_grp.create_dataset(
f"{ep.episode_id}/task",
data=ep.task_description
)
self.metadata_grp.create_dataset(
f"{ep.episode_id}/success",
data=1 if ep.success else 0
)
self.buffer.clear()
self.hdf5_file.flush()
print(f"已刷新 {len(self.buffer)} 个episodes到磁盘")
def _stack_observations(self, observations: list) -> dict:
"""堆叠观测数组。"""
rgb = np.stack([o["rgb"] for o in observations])
depth = np.stack([o["depth"] for o in observations])
proprio = [o["proprio"] for o in observations]
return {"rgb": rgb, "depth": depth, "proprio": proprio}
def close(self):
"""最终化并关闭数据收集器。"""
# 刷新剩余episodes
self._flush_buffer()
# 存储摘要
summary = {
"total_episodes": self.episode_counter,
"output_path": self.hdf5_path,
"timestamp": datetime.now().isoformat()
}
with open(
os.path.join(self.output_dir, "collection_summary.json"),
"w"
) as f:
json.dump(summary, f, indent=2)
self.hdf5_file.close()
print(f"数据采集完成。已保存到 {self.hdf5_path}")
# 用于数据处理的工具函数
def load_demonstrations(hdf5_path: str) -> Iterator[dict]:
"""
从HDF5文件加载演示。
用法:
for ep in load_demonstrations("demonstrations.hdf5"):
process(ep)
"""
with h5py.File(hdf5_path, "r") as f:
for ep_id in f["observations"].keys():
yield {
"episode_id": ep_id,
"rgb": f[f"observations/{ep_id}/rgb"][:],
"depth": f[f"observations/{ep_id}/depth"][:],
"proprio": f[f"observations/{ep_id}/proprio"][:],
"actions": f[f"actions/{ep_id}/joints"][:],
"task": f[f"metadata/{ep_id}/task"][()],
"success": bool(f[f"metadata/{ep_id}/success"][()])
}
def compute_success_rate(demonstrations: list[dict]) -> float:
"""从演示列表计算成功率。"""
if not demonstrations:
return 0.0
successes = sum(1 for ep in demonstrations if ep["success"])
return successes / len(demonstrations)
11. 未来路线图
11.1 技术发展路径
┌─────────────────────────────────────────────────────────────────────┐
│ OpenAI Robotics 路线图 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 阶段1:基础(2026年) │
│ ├── 构建核心VLA架构 │
│ ├── 开发世界模型集成 │
│ ├── 创建仿真基础设施 │
│ └── 建立硬件合作伙伴 │
│ │
│ 阶段2:训练(2027年) │
│ ├── 大规模数据采集 │
│ ├── 多样化任务预训练 │
│ ├── 仿真到现实迁移 │
│ └── 安全验证 │
│ │
│ 阶段3:部署(2028年) │
│ ├── 企业试点项目 │
│ ├── 现场测试和迭代 │
│ ├── 性能优化 │
│ └── 成本降低工程 │
│ │
│ 阶段4:规模化(2029年以后) │
│ ├── 消费者产品发布 │
│ ├── 大规模制造 │
│ ├── 全球支持基础设施 │
│ └── 通过云更新持续改进 │
│ │
└─────────────────────────────────────────────────────────────────────┘
11.2 预期能力演进
| 年份 | 操作能力 | 导航能力 | 推理能力 | 泛化能力 |
|---|---|---|---|---|
| 2026 | 拾取/放置 | 静态环境 | 任务跟随 | 单任务 |
| 2027 | 多指操作 | 动态环境 | 子任务规划 | 少样本 |
| 2028 | 工具使用 | 家庭环境 | 因果推理 | 任务迁移 |
| 2029 | 复杂装配 | 户外环境 | 长时推理 | 零样本 |
| 2030 | 开放式 | 无限制 | 类人水平 | 通用 |
12. 结论
OpenAI进入机器人领域代表了人工智能历史上的一个关键时刻。通过将其世界领先的基础模型与物理机器人系统相结合,OpenAI有望加速迈向通用机器人的道路,这些机器人可以在几乎任何任务中帮助人类。
由Aditya Ramesh领导、建立在多年世界模型研究基础上的这一项目,解决了一个机器人领域的根本挑战:使机器人能够像人类一样自然地理解和与物理世界互动。该公司采用的方法利用了大语言模型、视觉系统和强化学习的力量,创造出能够从经验中学习、推理复杂情况并适应新挑战的机器人。
凭借21万至31万美元加股权的竞争性薪酬,OpenAI正在吸引顶尖人才来应对这些挑战。短期专注于基础设施和建筑协助,在建设通向让每个人都能拥有个人机器人的雄心勃勃愿景的同时,提供直接价值。
展望未来,AI软件与机器人硬件的融合有望改变从制造业到医疗保健到家政服务的各个行业。OpenAI Robotics不仅仅是在建造机器人——它正在为AI在物理上帮助人类的未来奠定基础,这是我们只能想象的方式。
机器人技术的未来是AI原生的,而那个未来从现在开始。