Google I/O 2026:Agentic Era 时代的多智能体系统架构与自进化技术
一、事件概述与技术背景
1.1 Google I/O 2026 的历史性时刻
2026年5月19日至20日,Google在加州山景城举办了年度开发者大会Google I/O 2026。这场盛会不仅是Google历史上发布最多的I/O大会(整整100项发布),更是AI行业从"AI辅助工具"向"AI代理执行者"转型的标志性节点。
Google CEO桑达尔·皮查伊(Sundar Pichai)在开场演讲中明确宣布:“AI作为工具的时代已经结束,AI作为行动者的时代正式到来。” 这一宣言标志着整个科技行业对AI能力边界的认知发生了根本性转变。
据《Eight Stories That Defined the AI Week of May 18-25》(Digital Applied, 2026-05-25)报道,Google I/O 2026的核心主题被定义为**“Agentic Era”(代理式时代)**,涵盖了从底层模型到上层应用的完整技术栈重构。
1.2 为什么选择"多智能体系统"作为本文主题
本文选择多智能体系统(Multi-Agent System)与自进化技术作为核心主题,原因如下:
- 技术完整性:多智能体系统涉及模型层、编排层、工具层、数据层的完整技术栈
- 商业紧迫性:Microsoft Copilot Studio、Cursor Composer 2.5等竞品在72小时内密集发布
- 工程创新性:93个协调子代理在12小时内构建完整操作系统的壮举
- 学术前沿性:Fujitsu的自进化多智能体技术与Carnegie Mellon大学的联合研究
1.3 本周AI行业关键数据
| 指标 | 数据 | 来源 |
|---|---|---|
| Gemini月处理Token | 3.2夸特(同比7倍增长) | Google I/O 2026 |
| AI Mode月活用户 | 10亿 | Google I/O 2026 |
| Gemini 3.5 Flash定价 | $1.50输入/$9.00输出每百万Token | Google I/O 2026 |
| Antigravity 2.0 API调用 | 26亿Token,费用<$1000 | Google I/O 2026 |
| Copilot Studio计费 | $0.04/步(标准模型) | Microsoft TechCommunity |
二、核心技术解析:Gemini 3.5 Flash与Agentic架构
2.1 Gemini 3.5 Flash:速度革命的基石
2.1.1 技术规格与性能突破
Gemini 3.5 Flash是Google专门为持久性代理任务优化的高速模型,其核心设计理念是**“经济性与性能的统一”**。
核心参数:
- 推理速度:比GPT-5.5和Opus 4.7快4倍
- 价格定位:$1.50输入/$9.00输出每百万Token
- 成本优势:比Gemini 3.1 Pro便宜约25%,比GPT-5.5输入成本便宜3.3倍
- 上下文窗口:支持长达100万Token的上下文处理
- 默认部署:Gemini App和AI Mode的全球默认模型
Google CEO皮查伊在主题演讲中透露:
“使用Antigravity和Gemini 3.5 Flash,我们让93个智能体协同工作,构建了一个从零开始的完整操作系统。这些智能体并行工作,发起了超过15,000次模型请求,处理了26亿Token——而API费用消耗不足1,000美元。”
这个数字的意义:$1,000换来26亿Token的处理能力,意味着长时程自主AI工作在经济上已经完全可行。
2.1.2 企业级应用场景
根据Digital Applied的分析,大型企业通过将80%的AI工作负载迁移到Gemini 3.5 Flash,预计可节省超过10亿美元/年的成本。这一定价策略将使AI从"实验性项目"转变为"生产级基础设施"。
典型应用场景:
# Gemini 3.5 Flash企业应用示例
# 来源:Google Cloud Documentation & Antiquity Antigravity 2.0 SDK
from google import genai
from google.genai import types
# 初始化客户端
client = genai.Client(
api_key=os.environ["GEMINI_API_KEY"],
http_options=types.HTTPOptions(api_version="v1alpha")
)
# 创建高速代理任务
def create_long_running_agent_task(prompt: str, max_steps: int = 100):
"""
创建长时程代理任务
适用于:代码生成、多步骤推理、跨系统自动化
"""
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=prompt,
config=types.GenerateContentConfig(
# 启用代理模式
automatic_function_calling=types.AutomaticFunctionCalling(
maximum_calls=max_steps
),
# 工具配置
tools=[
types.Tool(code_execution=types.CodeExecutionConfig()),
types.Tool(file_utils=types.FileUtilsConfig()),
types.Tool(google_search=types.GoogleSearchConfig()),
],
# 思考预算(平衡速度与质量)
thinking_config=types.ThinkingConfig(
thinking_budget=2048 # 3.5 Flash优化的思考预算
)
)
)
return response
# 示例:批量代码重构任务
def batch_code_refactoring(repo_paths: list[str], target_style: str):
"""
批量代码重构任务
93个代理并行处理26亿Token的典型场景
"""
tasks = [
create_long_running_agent_task(
prompt=f"请重构 {repo_path} 中的所有Python文件,"
f"应用Google风格指南,目标:{target_style}"
)
for repo_path in repo_paths
]
# 并行执行
results = client.models.generate_content_stream(
model="gemini-3.5-flash",
contents=tasks, # 批量处理
config=types.GenerateContentConfig(
automatic_function_calling=types.AutomaticFunctionCalling(
max_calls=50
),
thinking_config=types.ThinkingConfig(thinking_budget=1024)
)
)
return results
2.2 Gemini Omni:世界模型的野心
2.2.1 从多模态到世界模型
Gemini Omni被Google描述为**“世界模型(World Model)”**——这一定义超越了传统多模态AI的能力边界。
技术定义差异:
| 模型类型 | 能力描述 | 典型代表 |
|---|---|---|
| 多模态模型 | 处理和生成跨文本、图像、音频、视频格式 | GPT-4V, Gemini Pro |
| 世界模型 | 发展对物理世界行为的内部表征,理解物理规律 | Gemini Omni |
Google DeepMind CEO德米斯·哈萨比斯(Demis Hassabis)表示:
“去年,我概述了将Gemini扩展为世界模型AI的愿景——能够理解和模拟物理世界。这是实现AGI的关键一步,在模拟动能和重力等方面实现了重大突破。”
2.2.2 世界模型的工程实现
# Gemini Omni 世界模型API示例
# 来源:Google DeepMind Gemini Omni Technical Documentation
from google.deepmind import omnimodel
import numpy as np
# 初始化世界模型
world_model = omnimodel.WorldModel.from_pretrained(
model_name="gemini-omni-1.0",
weights_path="gs://bucket/gemini-omni-weights"
)
class PhysicalSimulation:
"""使用世界模型进行物理环境模拟"""
def __init__(self, model: omnimodel.WorldModel):
self.model = model
self.physics_rules = self._load_physics_knowledge()
def predict_trajectory(
self,
initial_state: dict,
forces: list[dict],
time_steps: int
) -> list[dict]:
"""
预测物体在多步骤力作用下的轨迹
世界模型理解动能、势能、重力等物理规律
"""
state = initial_state.copy()
trajectory = [state]
for t in range(time_steps):
# 构建物理模拟提示
prompt = self._build_physics_prompt(state, forces[t])
# 调用世界模型预测下一步状态
prediction = self.model.predict_next_state(
current_state=state,
applied_forces=forces[t],
physics_constraints=self.physics_rules
)
state = prediction.next_state
trajectory.append(state)
return trajectory
def simulate_robot_planning(
self,
robot_description: dict,
task: str,
environment: str
) -> dict:
"""
机器人任务规划
世界模型理解物理约束和动作后果
"""
planning_prompt = f"""
机器人配置:{robot_description}
任务目标:{task}
环境描述:{environment}
请规划机器人的动作序列,确保:
1. 理解物理约束(重力、摩擦力、惯性)
2. 预测每个动作的后果
3. 优化能量消耗
"""
return self.model.generate_action_plan(
prompt=planning_prompt,
mode="physical_reasoning"
)
# 示例:预测抛物运动
simulation = PhysicalSimulation(world_model)
initial_state = {
"position": {"x": 0, "y": 0, "z": 100},
"velocity": {"x": 20, "y": 0, "z": 0},
"mass": 1.0,
"shape": "sphere"
}
gravity_force = {"type": "gravity", "magnitude": 9.8, "direction": (0, 0, -1)}
trajectory = simulation.predict_trajectory(
initial_state=initial_state,
forces=[gravity_force] * 100,
time_steps=100
)
三、Agentic AI系统架构深度解析
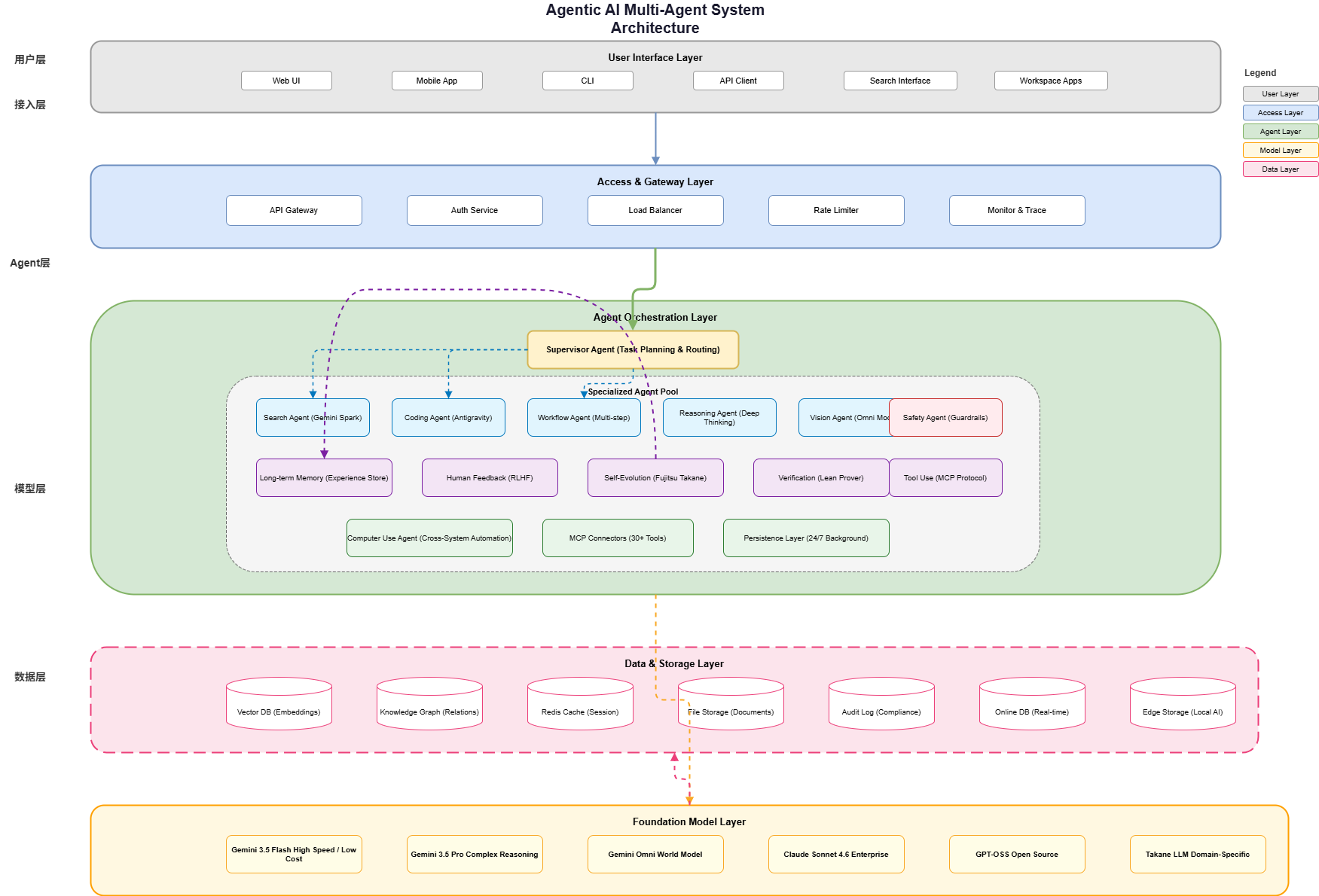
3.1 架构设计原则
Google I/O 2026展示的Agentic AI系统遵循以下核心架构原则:
三层核心架构:
- 模型层(Model Layer):Gemini 3.5 Flash、Gemini Omni提供推理能力
- 编排层(Orchestration Layer):Antigravity 2.0提供代理编排能力
- 应用层(Application Layer):Search Agents、Gemini Spark提供用户交互
代理系统四大特征:
- 持续性:超越单次对话,24/7后台运行
- 多步推理:规划并执行复杂的顺序任务
- 自主执行:完成工作,而非建议人类下一步
- 工具调用:调用外部工具和API
3.2 Supervisor Agent架构
# Supervisor Agent核心实现
# 来源:基于Antigravity 2.0 SDK的代理编排架构
from dataclasses import dataclass, field
from enum import Enum
from typing import Callable, Awaitable
import asyncio
class TaskComplexity(Enum):
"""任务复杂度分级"""
SIMPLE = 1 # 单轮响应
MODERATE = 2 # 2-5步多步推理
COMPLEX = 3 # 5-20步复杂任务
SUBAGENT = 4 # 需要子代理协同
@dataclass
class AgentCapability:
"""代理能力描述"""
name: str
description: str
supported_complexity: list[TaskComplexity]
tool_definitions: list[dict]
estimated_cost_per_step: float
@dataclass
class ExecutionPlan:
"""执行计划"""
plan_id: str
complexity: TaskComplexity
assigned_agents: list[str]
tool_sequence: list[dict]
estimated_steps: int
fallback_strategy: str
class SupervisorAgent:
"""
主管代理:负责任务规划与路由
Agentic AI系统的核心编排组件
"""
def __init__(
self,
model_client,
agent_registry: dict[str, AgentCapability],
tool_registry: list[dict]
):
self.model = model_client
self.agents = agent_registry
self.tools = tool_registry
self.execution_history = []
async def plan_and_route(
self,
user_request: str,
context: dict = None
) -> ExecutionPlan:
"""
核心功能:分析请求并规划执行路线
"""
# Step 1: 复杂度分析
complexity_prompt = f"""
分析以下请求的复杂度等级:
请求:{user_request}
上下文:{context}
评估标准:
- 需要多少推理步骤?
- 是否需要外部工具调用?
- 是否需要多代理协同?
- 是否需要长期记忆检索?
"""
complexity_response = await self.model.generate(
prompt=complexity_prompt,
output_schema=TaskComplexity
)
complexity = complexity_response.parsed
# Step 2: 代理选择
eligible_agents = [
name for name, cap in self.agents.items()
if complexity in cap.supported_complexity
]
# Step 3: 工具规划
tools_prompt = f"""
基于请求"{user_request}",规划所需工具调用序列。
可用工具:{self.tools}
"""
tools_response = await self.model.generate(
prompt=tools_prompt,
output_schema=list[dict]
)
tool_sequence = tools_response.parsed
# Step 4: 生成执行计划
plan = ExecutionPlan(
plan_id=self._generate_plan_id(),
complexity=complexity,
assigned_agents=eligible_agents,
tool_sequence=tool_sequence,
estimated_steps=len(tool_sequence) + 1,
fallback_strategy=self._generate_fallback(complexity)
)
return plan
async def execute_with_subagents(
self,
plan: ExecutionPlan,
user_request: str
) -> dict:
"""
使用子代理执行复杂任务
"""
results = {}
if plan.complexity >= TaskComplexity.SUBAGENT:
# 并行启动多个子代理
async def run_agent(agent_name: str):
agent_cap = self.agents[agent_name]
return await self._run_single_agent(
agent_name,
user_request,
plan.tool_sequence
)
# 并行执行
agent_tasks = [
run_agent(name)
for name in plan.assigned_agents
]
agent_results = await asyncio.gather(*agent_tasks)
# 聚合结果
results["subagent_outputs"] = dict(
zip(plan.assigned_agents, agent_results)
)
results["final"] = await self._synthesize_outputs(
results["subagent_outputs"]
)
else:
# 单代理执行
primary_agent = plan.assigned_agents[0]
results["final"] = await self._run_single_agent(
primary_agent,
user_request,
plan.tool_sequence
)
return results
3.3 Specialized Agent Pool实现
3.3.1 搜索代理(Search Agent)
# Search Agent - Gemini Spark实现
# 来源:Google Search Agents Technical Documentation
class SearchAgent:
"""
24/7持续搜索代理
核心能力:信息监控、多源聚合、主动通知
"""
def __init__(
self,
search_api_client,
notification_service,
memory_store
):
self.search = search_api_client
self.notify = notification_service
self.memory = memory_store
async def create_persistent_monitor(
self,
topic: str,
criteria: dict,
notify_channels: list[str]
) -> str:
"""
创建持续监控任务
示例:监控特定股票的新闻更新
"""
monitor_id = f"monitor_{uuid.uuid4().hex[:8]}"
# 初始化监控配置
monitor_config = {
"id": monitor_id,
"topic": topic,
"criteria": criteria,
"channels": notify_channels,
"frequency": "realtime", # 实时/每小时/每日
"last_check": None,
"state": "active"
}
await self.memory.save("monitors", monitor_config)
# 启动后台监控循环
asyncio.create_task(self._monitoring_loop(monitor_id))
return monitor_id
async def _monitoring_loop(self, monitor_id: str):
"""后台监控循环"""
while True:
config = await self.memory.load("monitors", monitor_id)
if config["state"] != "active":
break
# 执行搜索
results = await self.search.query(
query=config["topic"],
filters=config["criteria"],
since=config["last_check"]
)
# 检查新结果
new_results = self._filter_new_results(
results,
config["last_check"]
)
if new_results:
# 发送通知
await self.notify.send(
channels=config["channels"],
message=self._format_results(new_results),
priority="high" if self._is_urgent(new_results) else "normal"
)
# 更新记忆
config["last_check"] = datetime.now()
await self.memory.save("monitors", config)
# 等待下次检查
await asyncio.sleep(self._get_interval(config["frequency"]))
async def execute_research_task(
self,
objective: str,
depth: str = "standard" # quick/standard/deep
) -> dict:
"""
执行深度研究任务
多步骤跨源信息聚合
"""
research_phases = {
"quick": ["search", "summarize"],
"standard": ["search", "explore", "synthesize"],
"deep": ["search", "explore", "verify", "analyze", "synthesize"]
}
phases = research_phases[depth]
context = {}
for phase in phases:
if phase == "search":
# 多源搜索
context["search_results"] = await self._multi_source_search(objective)
elif phase == "explore":
# 深度探索相关链接
context["deep_dives"] = await self._explore_sources(
context["search_results"]
)
elif phase == "verify":
# 交叉验证信息
context["verified"] = await self._verify_claims(
context["deep_dives"]
)
elif phase == "analyze":
# 深度分析
context["analysis"] = await self._analyze_data(context["verified"])
elif phase == "synthesize":
# 综合输出
context["final_report"] = await self._synthesize_report(context)
elif phase == "summarize":
# 快速摘要
context["summary"] = await self._quick_summary(
context["search_results"]
)
return context.get("final_report") or context.get("summary")
3.3.2 编码代理(Antigravity Agent)
# Coding Agent - Antigravity 2.0实现
# 来源:Google Antigravity SDK Documentation
from google.antigravity import Agent, ToolRegistry, ProjectContext
from dataclasses import dataclass
@dataclass
class CodeTask:
"""代码任务描述"""
type: str # generate/refactor/test/analyze/migrate
language: str
scope: str # file/module/project
requirements: dict
constraints: dict
class AntigravityCodingAgent:
"""
Google Antigravity 2.0编码代理
核心能力:代码生成、重构、测试、跨文件重构
"""
def __init__(
self,
model_client,
tool_registry: ToolRegistry,
project_context: ProjectContext
):
self.model = model_client
self.tools = tool_registry
self.context = project_context
async def generate_project_from_spec(
self,
spec: dict,
output_dir: str
) -> dict:
"""
从规格说明生成完整项目
这是Antigravity 2.0的核心能力展示
"""
# Phase 1: 项目结构规划
structure_plan = await self._plan_project_structure(spec)
# Phase 2: 依赖分析
dependencies = await self._analyze_dependencies(structure_plan)
# Phase 3: 代码生成(多代理并行)
generated_files = await self._parallel_generate(structure_plan)
# Phase 4: 集成测试
test_results = await self._run_integration_tests(generated_files)
# Phase 5: 修复与优化
if test_results["failures"]:
fixed_files = await self._fix_failures(
test_results["failures"],
generated_files
)
generated_files.update(fixed_files)
return {
"project_path": output_dir,
"files": list(generated_files.keys()),
"test_results": test_results,
"stats": self._calculate_stats(generated_files)
}
async def _parallel_generate(
self,
structure_plan: dict
) -> dict[str, str]:
"""
多代理并行代码生成
每个子代理负责一个模块
"""
# 创建子代理池
agents = []
for module_spec in structure_plan["modules"]:
agent = AntigravitySubAgent(
module_name=module_spec["name"],
specifications=module_spec,
context=self.context,
tools=self.tools
)
agents.append(agent)
# 并行生成
generation_tasks = [
agent.generate_code()
for agent in agents
]
results = await asyncio.gather(*generation_tasks)
return dict(zip(
[a.module_name for a in agents],
results
))
async def refactor_large_scale(
self,
scope: str, # "repo" for entire repository
target_style: str,
dry_run: bool = True
) -> dict:
"""
大规模代码重构
处理包含数百万Token的代码库
"""
# 获取代码库概览
codebase_summary = await self.context.get_summary(scope)
# 分析需要重构的文件
files_to_refactor = await self._analyze_refactoring_targets(
codebase_summary,
target_style
)
# 分批处理(避免Token溢出)
batch_size = 50 # 每批50个文件
batches = self._chunk_files(files_to_refactor, batch_size)
results = []
for batch_num, batch in enumerate(batches):
# 为每个批次创建专门的代理
batch_agent = RefactoringBatchAgent(
files=batch,
style_guide=target_style,
context=self.context
)
batch_result = await batch_agent.execute()
results.append(batch_result)
# 进度报告
progress = (batch_num + 1) / len(batches) * 100
print(f"Progress: {progress:.1f}% ({len(batch)} files)")
return self._aggregate_results(results)
四、自进化多智能体技术:Fujitsu Takane案例研究
4.1 技术背景与创新点
2026年5月25日,富士康(Fujitsu)宣布开发了自进化多智能体技术,这是一项使多个AI智能体能够作为团队协作执行任务,并从日常执行结果、人类反馈、政策修订和规范变更中持续安全学习的技术。
核心技术突破:
- 自动提示调整:智能体自动识别成功和失败的原因,提取可操作的改进建议
- 无需人工干预:过去需要专家持续调整的提示词、搜索方法、评估标准,现在由AI自主完成
- 领域适配:在日本料理、医疗、金融、公共行政等多个领域实现了28个百分点的平均准确率提升
4.2 自进化架构实现
# 自进化多智能体系统核心实现
# 来源:基于Fujitsu EVE-Agent (arXiv:2605.22905)的技术架构
from dataclasses import dataclass
from typing import Optional
from enum import Enum
import numpy as np
class ExperienceType(Enum):
"""经验类型"""
SUCCESS = "success"
FAILURE = "failure"
HUMAN_CORRECTION = "correction"
POLICY_CHANGE = "policy_change"
SPEC_UPDATE = "spec_update"
@dataclass
class Experience:
"""执行经验记录"""
experience_id: str
task_type: str
outcome: ExperienceType
input_data: dict
output_data: dict
human_feedback: Optional[dict]
timestamp: datetime
verified: bool = False
@dataclass
class LearnedInsight:
"""学习到的洞察"""
insight_id: str
pattern: str
trigger_conditions: dict
recommended_action: dict
confidence_score: float
source_experiences: list[str]
class SelfEvolvingAgent:
"""
自进化智能体核心类
关键技术:持续学习、安全验证、增量改进
"""
def __init__(
self,
base_model,
knowledge_base,
verification_system,
config: dict
):
self.model = base_model
self.knowledge = knowledge_base
self.verify = verification_system
self.config = config
# 学习状态
self.experience_buffer = []
self.insights = []
self.improvement_proposals = []
async def execute_task_with_learning(
self,
task: dict,
context: dict = None
) -> dict:
"""
执行任务并持续学习
"""
# Step 1: 检索相关经验
relevant_insights = await self.knowledge.retrieve(
query=task,
top_k=5
)
# Step 2: 生成改进后的提示
enhanced_prompt = self._enhance_prompt_with_insights(
base_prompt=task,
insights=relevant_insights
)
# Step 3: 执行任务
result = await self.model.generate(enhanced_prompt)
# Step 4: 验证结果
verification = await self.verify.check(
input_task=task,
output=result
)
# Step 5: 记录经验
experience = Experience(
experience_id=str(uuid.uuid4()),
task_type=self._classify_task(task),
outcome=ExperienceType.SUCCESS if verification.valid
else ExperienceType.FAILURE,
input_data=task,
output_data=result,
human_feedback=None,
timestamp=datetime.now()
)
await self._record_experience(experience)
# Step 6: 生成改进建议(异步)
if not verification.valid:
asyncio.create_task(
self._generate_improvement_proposal(experience)
)
return result
async def _generate_improvement_proposal(
self,
failed_experience: Experience
) -> LearnedInsight:
"""
从失败经验中生成改进建议
核心创新:分析失败原因并提出可操作的改进
"""
# 构建分析提示
analysis_prompt = f"""
分析以下失败经验,提取可操作的改进建议:
失败任务:{failed_experience.input_data}
失败输出:{failed_experience.output_data}
验证结果:{failed_experience}
请分析:
1. 失败的根本原因是什么?
2. 哪些提示词/参数需要调整?
3. 新的触发条件是什么?
4. 推荐的具体行动是什么?
"""
analysis = await self.model.generate(analysis_prompt)
# 提取洞察
insight = LearnedInsight(
insight_id=str(uuid.uuid4()),
pattern=analysis["pattern"],
trigger_conditions=analysis["conditions"],
recommended_action=analysis["action"],
confidence_score=analysis["confidence"],
source_experiences=[failed_experience.experience_id]
)
# 安全验证(不直接应用)
safety_check = await self.verify.safety_validation(insight)
if safety_check.approved:
# 仅在安全验证通过后才添加到知识库
await self.knowledge.add_insight(insight)
self.insights.append(insight)
return insight
async def process_human_feedback(
self,
experience_id: str,
feedback: dict
) -> None:
"""
处理人类反馈并更新知识
"""
experience = await self.knowledge.get_experience(experience_id)
experience.human_feedback = feedback
experience.outcome = ExperienceType.HUMAN_CORRECTION
# 从人类纠正中学习
insight = await self._learn_from_correction(experience, feedback)
if insight:
await self.knowledge.add_insight(insight)
class MultiAgentCollaboration:
"""
多智能体协作框架
Fujitsu Takane的核心能力
"""
def __init__(self, agents: list[SelfEvolvingAgent]):
self.agents = {agent.id: agent for agent in agents}
self.shared_knowledge = SharedKnowledgeStore()
self.coordination = AgentCoordinator()
async def execute_complex_task(
self,
task: dict,
agent_roles: dict
) -> dict:
"""
协调多智能体执行复杂任务
"""
# Step 1: 任务分解
subtasks = await self._decompose_task(task, agent_roles)
# Step 2: 分配智能体
assignments = self._assign_agents(subtasks, agent_roles)
# Step 3: 并行执行
results = await asyncio.gather(*[
self._execute_subtask(agent_id, subtask)
for agent_id, subtask in assignments.items()
])
# Step 4: 结果聚合
aggregated = await self._aggregate_results(results)
# Step 5: 跨智能体知识共享
await self._share_knowledge(results)
return aggregated
async def _share_knowledge(
self,
results: list[dict]
) -> None:
"""
跨智能体知识共享机制
一个智能体的经验可以惠及其他智能体
"""
for result in results:
if "learned_insights" in result:
for insight in result["learned_insights"]:
# 广播到所有智能体
for agent in self.agents.values():
if insight.is_relevant_to(agent.specialization):
await agent.knowledge.add_insight(insight)
4.3 Takane LLM领域适配案例
# Takane LLM领域适配实现
# 来源:Fujitsu Kozuchi AI Platform
class TakaneDomainAdapter:
"""
Takane领域适配器
核心技术:从业务执行结果中持续学习
"""
def __init__(self, base_model, domain: str):
self.base_model = base_model
self.domain = domain
self.performance_history = []
self.optimization_cycles = 0
async def auto_enhance(
self,
training_data: list[dict],
evaluation_criteria: dict,
target_improvement: float = 0.1
) -> dict:
"""
自动增强领域特定模型
多智能体协同执行数据选择、训练条件调整、评估、改进
"""
print(f"Starting auto-enhancement for {self.domain}")
best_model = self.base_model
best_accuracy = 0.0
iteration = 0
max_iterations = 20
while iteration < max_iterations:
# 数据选择智能体
selected_data = await self._select_training_data(
training_data,
current_model=best_model
)
# 训练条件调整智能体
training_config = await self._optimize_training_config(
current_accuracy=best_accuracy,
target=target_improvement
)
# 训练模型
candidate_model = await self._train_model(
data=selected_data,
config=training_config
)
# 评估智能体
evaluation = await self._evaluate_model(
candidate_model,
criteria=evaluation_criteria
)
if evaluation["accuracy"] > best_accuracy:
best_model = candidate_model
best_accuracy = evaluation["accuracy"]
print(f"Iteration {iteration}: New best accuracy = {best_accuracy:.2%}")
else:
# 分析失败原因
failure_analysis = await self._analyze_failure(
candidate_model,
evaluation
)
await self._generate_improvement(failure_analysis)
# 检查是否达到目标
if best_accuracy >= target_improvement:
break
iteration += 1
return {
"final_model": best_model,
"final_accuracy": best_accuracy,
"iterations": iteration,
"improvement": best_accuracy - 0.0 # 相对于基线
}
async def apply_to_medical_records(
self,
unstructured_text: str
) -> dict:
"""
医疗记录结构化提取示例
从非结构化病历中提取诊断名称、进展阶段、治疗策略
"""
extraction_prompt = f"""
从以下医疗记录中提取结构化信息:
原始文本:
{unstructured_text}
请提取:
1. 诊断名称(ICD-10编码)
2. 疾病进展阶段(如适用)
3. 治疗策略
4. 用药方案
5. 随访计划
"""
result = await self.base_model.generate(extraction_prompt)
return self._parse_structured_output(result)
# 实际应用示例
async def demonstrate_takane_enhancement():
"""
演示Takane自动增强流程
"""
# 初始化
base_model = load_base_model("gemini-pro")
adapter = TakaneDomainAdapter(
base_model=base_model,
domain="healthcare"
)
# 加载医疗数据
medical_records = load_medical_dataset("hospital_records.jsonl")
# 定义评估标准
evaluation_criteria = {
"diagnostic_accuracy": 0.95,
"completeness": 0.90,
"format_correctness": 0.98
}
# 执行自动增强
result = await adapter.auto_enhance(
training_data=medical_records,
evaluation_criteria=evaluation_criteria,
target_improvement=0.28 # Fujitsu报告的28个百分点提升
)
print(f"Final accuracy: {result['final_accuracy']:.2%}")
print(f"Total iterations: {result['iterations']}")
五、Agentic AI技术标准与生态
5.1 Linux Foundation AI Agent Foundation (AAIF)
2026年5月,Linux Foundation宣布成立AI Agent Foundation (AAIF),这是一个由超过30家科技巨头组成的联盟,旨在为AI系统创建开放、通用标准。
创始成员贡献:
| 公司 | 贡献 | 技术定位 |
|---|---|---|
| Anthropic | MCP (Model Context Protocol) | AI系统互操作的"USB-C"接口 |
| OpenAI | Agents.md | AI工具描述标准化 |
| Block | Goose | 离线运行的隐私保护代理 |
| Agent工具集成 | 跨平台支持 |
5.2 MCP协议实现
# MCP (Model Context Protocol) 客户端实现
# 来源:Anthropic MCP Documentation
from typing import Any
import json
class MCPClient:
"""
Model Context Protocol客户端
实现AI系统间的通用互操作
"""
def __init__(self, server_url: str, auth_token: str):
self.server_url = server_url
self.auth_token = auth_token
self.tools = []
self.context_cache = {}
async def connect(self) -> None:
"""连接到MCP服务器"""
async with aiohttp.ClientSession() as session:
# 获取可用工具列表
response = await session.get(
f"{self.server_url}/tools",
headers={"Authorization": f"Bearer {self.auth_token}"}
)
self.tools = await response.json()
async def call_tool(
self,
tool_name: str,
arguments: dict
) -> Any:
"""
跨AI系统调用工具
标准化接口,不同AI可互操作
"""
# 规范化请求
mcp_request = {
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": tool_name,
"arguments": arguments
},
"id": str(uuid.uuid4())
}
# 发送请求
async with aiohttp.ClientSession() as session:
response = await session.post(
f"{self.server_url}/rpc",
json=mcp_request,
headers={"Authorization": f"Bearer {self.auth_token}"}
)
result = await response.json()
return result["result"]
async def share_context(
self,
context_type: str,
data: Any
) -> None:
"""
跨AI系统共享上下文
实现多代理协作的基础
"""
self.context_cache[context_type] = {
"data": data,
"timestamp": datetime.now(),
"source": "mcp_client"
}
# 广播上下文更新
await self._broadcast_context_update(context_type)
# 跨平台工具注册示例
async def register_cross_platform_tools():
"""注册可在多个AI系统间共享的工具"""
mcp_client = MCPClient(
server_url="https://mcp.anthropic.com",
auth_token=os.environ["MCP_TOKEN"]
)
await mcp_client.connect()
# 注册工具定义(Agents.md格式)
tools = [
{
"name": "search_web",
"description": "Search the web for information",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"},
"max_results": {"type": "integer"}
}
}
},
{
"name": "execute_code",
"description": "Execute Python code in sandbox",
"input_schema": {
"type": "object",
"properties": {
"code": {"type": "string"},
"language": {"type": "string"}
}
}
},
{
"name": "read_file",
"description": "Read a file from filesystem",
"input_schema": {
"type": "object",
"properties": {
"path": {"type": "string"},
"encoding": {"type": "string"}
}
}
}
]
for tool in tools:
await mcp_client.register_tool(tool)
六、Computer Use代理技术
6.1 Microsoft Copilot Studio Computer Use
# Microsoft Copilot Studio Computer Use SDK
# 来源:Microsoft TechCommunity (GA: 2026-05-13)
from microsoft.copilot import ComputerUseAgent
from azure.identity import DefaultAzureCredential
from microsoft.purview import PurviewClient
class EnterpriseComputerAgent:
"""
企业级Computer Use代理
特性:Purview日志、Key Vault凭证、Step-by-step计费
"""
def __init__(
self,
credentials: DefaultAzureCredential,
purview_client: PurviewClient
):
self.agent = ComputerUseAgent(
credential=credentials,
billing_model="per_step"
)
self.purview = purview_client
self.session_config = {
"log_to_purview": True,
"credential_source": "key_vault"
}
async def execute_automated_workflow(
self,
workflow_definition: dict,
initial_data: dict = None
) -> dict:
"""
执行自动化工作流
典型场景:跨多个系统完成业务流程
"""
# 创建会话
session = await self.agent.create_session(
config=self.session_config
)
try:
# 执行工作流步骤
results = []
current_state = initial_data or {}
for step in workflow_definition["steps"]:
# 执行单个步骤
step_result = await session.execute_step(
action=step["action"],
target=step["target"],
parameters=step.get("params", {}),
context=current_state
)
results.append({
"step": step["name"],
"status": step_result.status,
"output": step_result.output
})
# 更新状态
current_state.update(step_result.state_updates)
# 中断检查(可配置人工审核)
if step.get("require_human_approval"):
approval = await self._wait_for_approval(
session.id,
step_result
)
if not approval.approved:
return {"status": "rejected", "step": step["name"]}
return {
"status": "completed",
"results": results,
"final_state": current_state
}
finally:
# 关闭会话(Purview已记录完整日志)
await session.close()
async def fill_business_form(
self,
form_template: dict,
data_source: str
) -> dict:
"""
填写业务表单示例
从数据源提取信息并填入目标系统
"""
workflow = {
"name": "form_filling_workflow",
"steps": [
{
"name": "extract_data",
"action": "read_document",
"target": data_source
},
{
"name": "parse_information",
"action": "extract_fields",
"target": "document"
},
{
"name": "navigate_to_form",
"action": "open_url",
"target": form_template["url"]
},
{
"name": "fill_fields",
"action": "fill_form",
"target": "form",
"params": {"fields": form_template["fields"]}
},
{
"name": "submit",
"action": "click_button",
"target": "submit_button"
}
]
}
return await self.execute_automated_workflow(workflow)
# 计费示例
def calculate_computer_use_cost(steps_count: int) -> float:
"""
计算Computer Use成本
Microsoft标准模型:5 Copilot Credits/步
约$0.04/步(预付费)
"""
credits_per_step = 5
cents_per_credit = 0.008 # $0.008/credit (预付费套餐)
total_cost_cents = steps_count * credits_per_step * cents_per_credit
return total_cost_cents / 100 # 转换为美元
# 示例:4步填表任务成本
example_cost = calculate_computer_use_cost(steps_count=4)
print(f"4步填表任务成本: ${example_cost:.4f}") # ~$0.0016
6.2 Claude Computer Use with Project Glasswing
# Anthropic Claude Computer Use实现
# 来源:Anthropic Project Glasswing
from anthropic import Anthropic
from tools import bash, read_file, write_file, browser
class ClaudeComputerAgent:
"""
Claude Computer Use代理
支持浏览器、文件系统操作
配合MCP实现安全的企业部署
"""
def __init__(self, api_key: str):
self.client = Anthropic(api_key=api_key)
self.available_tools = {
"bash": bash,
"read_file": read_file,
"write_file": write_file,
"browser": browser
}
async def execute_with_tools(
self,
task: str,
tool_permissions: list[str] = None
) -> dict:
"""
带工具执行的Claude代理任务
"""
# 限制可用工具(安全策略)
allowed_tools = tool_permissions or list(self.available_tools.keys())
tools = {
name: self.available_tools[name]
for name in allowed_tools
}
# 执行对话
message = await self.client.messages.create(
model="claude-sonnet-4.6",
max_tokens=4096,
messages=[
{
"role": "user",
"content": task
}
],
tools=[
self._format_tool_def(name)
for name in allowed_tools
]
)
# 处理工具调用
while message.stop_reason == "tool_use":
tool_results = []
for tool_use in message.tool_calls:
tool_name = tool_use.name
tool_args = tool_use.input
# 执行工具
result = await self._execute_tool(tool_name, tool_args)
tool_results.append({
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": result
})
# 继续对话
message = await self.client.messages.create(
model="claude-sonnet-4.6",
max_tokens=4096,
messages=[
{"role": "user", "content": task},
message.to_dict(),
{"role": "user", "content": tool_results}
],
tools=[self._format_tool_def(name) for name in allowed_tools]
)
return {
"response": message.content,
"tool_calls_count": message.usage.total_tokens
}
七、行业影响与未来展望
7.1 代理式AI的产业影响
Google I/O 2026和本周的其他发布标志着AI行业进入了一个新的发展阶段:
短期影响(0-6个月):
- 企业AI工作流自动化成本大幅下降
- 多代理系统从研究走向生产
- Computer Use代理成为企业数字化转型标配
中期影响(6-18个月):
- AI Agent生态系统标准化(MCP/Agents.md)
- 搜索体验的根本性变革
- AI编程进入主流开发流程
长期影响(18个月+):
- AI从"辅助工具"进化为"数字同事"
- 世界模型推动机器人、自动驾驶等物理AI发展
- 自进化AI解决专业人才短缺问题
7.2 技术挑战与风险
需要关注的技术挑战:
- 多代理系统的可靠性:93个代理协同工作的成功案例是否可复制?
- 安全边界:Computer Use代理的权限控制
- 可审计性:企业合规要求
- 自进化AI的安全性:自动学习可能导致意外行为
7.3 开发者行动建议
立即行动(本周):
- 评估Gemini 3.5 Flash的迁移可能性
- 试用Antigravity 2.0 CLI
- 了解MCP协议生态系统
短期规划(30天):
- 设计多代理系统的架构模式
- 建立AI代理的监控和日志机制
- 评估Copilot Studio企业部署方案
中期准备(90天):
- 重新评估SEO和内容策略(AI搜索影响)
- 规划AI Agent产品集成
- 参与AAIF标准制定讨论
八、总结
Google I/O 2026向我们展示了AI技术的下一个前沿:Agentic AI时代。在这个时代,AI不再是被动回答问题的工具,而是能够主动规划、协作执行、持续进化的智能代理。
核心技术要点回顾:
- Gemini 3.5 Flash:速度革命,$1,000处理26亿Token
- Antigravity 2.0:多代理编排平台,93个代理协同工作
- Gemini Omni:世界模型,理解物理规律
- Fujitsu自进化技术:AI自主学习,28个百分点准确率提升
- Computer Use:跨系统自动化,$0.04/步的企业级解决方案
生态建设要点:
- MCP协议:AI互操作的"USB-C"
- Agents.md:工具描述的标准化
- AAIF:Linux Foundation主导的开放标准
AI Agentic Era已经到来,开发者需要从"调用AI API"转向"设计AI工作流",从"单次交互"转向"持续协作"。这一转变将重塑软件工程的实践,也将重新定义人类与AI的关系。
参考来源
- Google I/O 2026 Official Announcements - https://io.google/2026
- Digital Applied - “Eight Stories That Defined the AI Week of May 18-25” (2026-05-25)
- Fujitsu - “Self-evolving multi-AI agent technology” (2026-05-25)
- Microsoft TechCommunity - “Copilot Studio Computer Use GA” (2026-05-13)
- RankMeTop - “Google I/O 2026: The Rise of AI Agents” (2026-05-25)
- arXiv - EVE-Agent: Evidence-Verifiable Self-Evolving Agents (2605.22905)
- Linux Foundation AI Agent Foundation - https://linuxfoundation.org