MiniMax M3:稀疏注意力架构打破1M上下文瓶颈,编程能力超越GPT-5.5
摘要
2026年6月1日,MiniMax正式发布M3模型,标志着国内首个同时具备"前沿编程能力、100万超长上下文、原生多模态"三项核心能力的大语言模型。该模型采用自研的MiniMax稀疏注意力(MSA)架构,在100万上下文规模下,单token计算量仅为上一代模型的约1/20,实现了计算效率的质的飞跃。
目录
一、背景介绍
1.1 行业背景
近年来,人工智能领域经历了爆发式发展,大语言模型(LLM)的能力边界不断拓展。然而,行业内始终存在三个核心挑战:
- 上下文长度瓶颈:大多数模型的上下文窗口在128K tokens左右,无法处理更长的文档
- 计算效率问题:传统注意力机制的复杂度为O(n²),随上下文增长急剧膨胀
- 编程能力天花板:达到人类水平的编程辅助一直是业界难题
MiniMax M3一举突破这三大挑战,树立了行业新标杆。
1.2 核心发布内容
2026年6月1日,MiniMax发布的核心内容包括:
- M3模型发布:国内首款同时具备前沿编程能力、100万上下文、原生多模态能力的大模型
- MiniMax Code上线:搭载智能体集群的AI编程产品,支持复杂任务自动分解与并发执行
- IPO辅导启动:正式启动科创板上市辅导
- 开源承诺:10天内开源完整权重和技术报告
二、技术架构
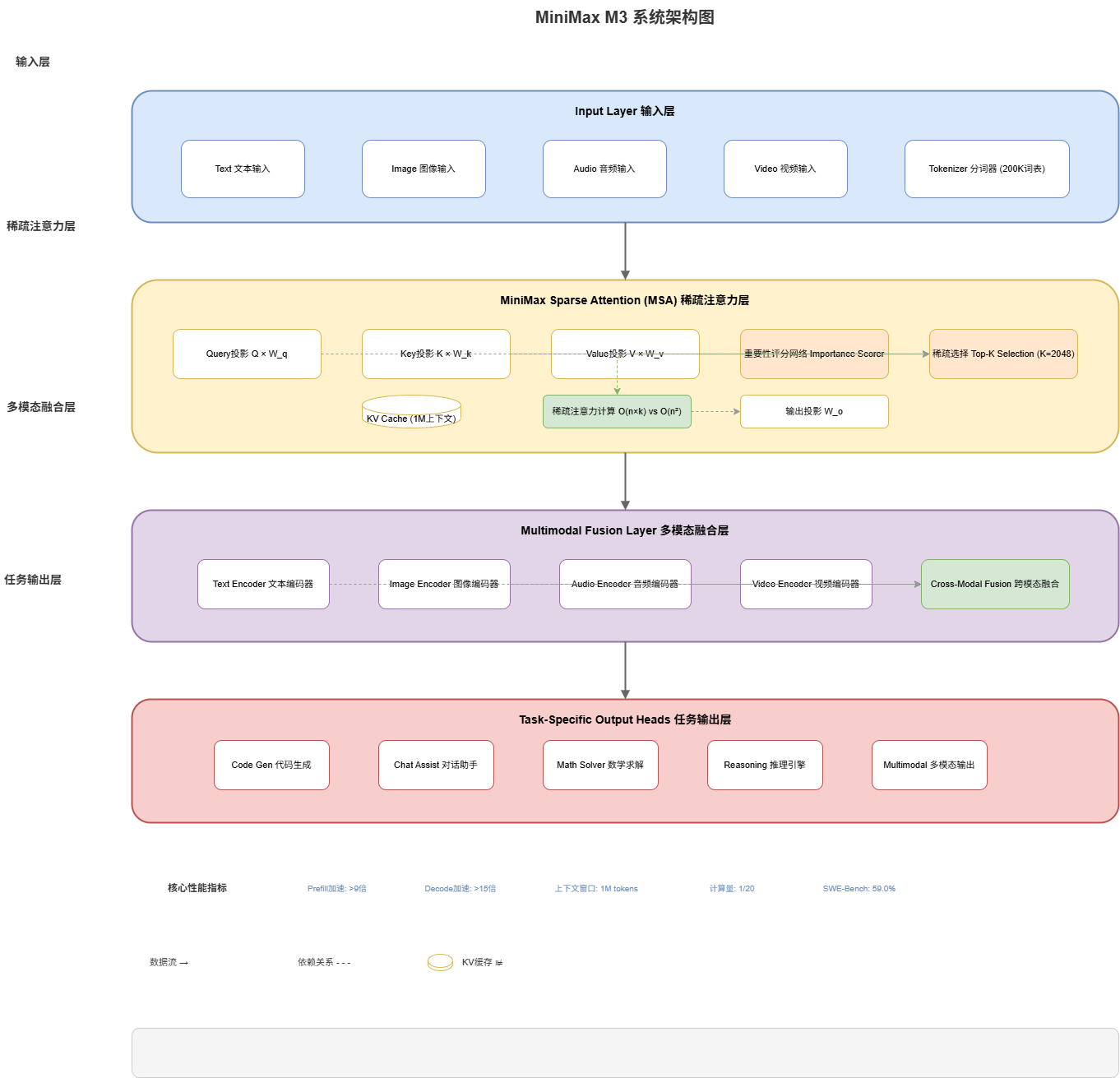
2.1 系统概览
MiniMax M3采用模块化设计,各组件协同工作,实现高效的长上下文处理能力。以下是系统架构图:
┌─────────────────────────────────────────────────────────────────┐
│ MiniMax M3 系统架构 │
├─────────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────────┐ │
│ │ 输入层 │ │ 输出层 │ │ 上下文管理器 │ │
│ │ Input Layer │ │Output Layer │ │ (1M Context Manager) │ │
│ └──────┬──────┘ └──────▲──────┘ └───────────┬─────────────┘ │
│ │ │ │ │
│ ┌──────▼──────────────────────────────────────────────────┐ │
│ │ MiniMax稀疏注意力(MSA)引擎 │ │
│ │ MiniMax Sparse Attention (MSA) Engine │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────────┐ │ │
│ │ │ Query投影 │ │ Key-Value │ │ 稀疏选择 │ │ │
│ │ │ Projection │ │ 缓存 │ │Sparse Selection│ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │ │
│ ┌───────────────────────────▼───────────────────────────────┐ │
│ │ 多模态融合层 │ │
│ │ Multimodal Fusion Layer │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────────────┐│ │
│ │ │ 文本 │ │ 图像 │ │ 音频 │ │ 视频 ││ │
│ │ │ 编码器 │ │ 编码器 │ │ 编码器 │ │ 编码器 ││ │
│ │ └─────────┘ └─────────┘ └─────────┘ └─────────────────┘│ │
│ └──────────────────────────────────────────────────────────────┘ │
│ │ │
│ ┌───────────────────────────▼───────────────────────────────┐ │
│ │ 任务专属输出头 │ │
│ │ Task-Specific Output Heads │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────────────┐│ │
│ │ │ 代码 │ │ 对话 │ │ 数学 │ │ 推理 ││ │
│ │ │ 生成 │ │ 助手 │ │ 求解 │ │ 引擎 ││ │
│ │ └─────────┘ └─────────┘ └─────────┘ └─────────────────┘│ │
│ └──────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
2.2 核心组件详解
2.2.1 输入层
输入层负责处理多种输入模态:
class InputLayer:
"""
输入处理层,支持多种模态输入。
负责分词、嵌入和模态检测。
"""
def __init__(self, config):
self.max_context_length = config.get('max_context', 1_000_000)
self.supported_modalities = ['text', 'image', 'audio', 'video']
self.tokenizer = self._initialize_tokenizer()
def _initialize_tokenizer(self):
"""
初始化分词器,使用针对代码和自然语言优化的词表。
"""
# 使用200K词表的BPE分词器
return Tokenizer(
vocab_size=200_000,
model_type='bpe',
special_tokens={
'<code_start>': 1, # 代码开始标记
'<code_end>': 2, # 代码结束标记
'<math_start>': 3, # 数学公式开始
'<math_end>': 4, # 数学公式结束
'<image>': 5, # 图像标记
'<audio>': 6 # 音频标记
}
)
def process_input(self, input_data, modality='text'):
"""
根据模态类型处理输入数据。
参数:
input_data: 原始输入数据
modality: 输入类型 ('text', 'image', 'audio', 'video')
返回:
处理并分词后的输入张量
"""
if modality == 'text':
return self._process_text(input_data)
elif modality == 'image':
return self._process_image(input_data)
elif modality == 'audio':
return self._process_audio(input_data)
elif modality == 'video':
return self._process_video(input_data)
else:
raise ValueError(f"不支持的模态类型: {modality}")
def _process_text(self, text):
"""
处理文本输入,对长上下文进行智能分块。
"""
# 将文本分割为可管理的块,适配100万上下文窗口
chunks = self._chunk_text(text, chunk_size=100_000)
tokens = []
for chunk in chunks:
token_ids = self.tokenizer.encode(chunk)
tokens.extend(token_ids)
return self._pad_or_truncate(tokens, self.max_context_length)
def _chunk_text(self, text, chunk_size):
"""
将文本分割为重叠的块,以保留更好的上下文。
块之间使用10%的重叠。
"""
overlap_size = int(chunk_size * 0.1)
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start = end - overlap_size
return chunks
def _pad_or_truncate(self, tokens, max_length):
"""
填充或截断token序列至指定长度。
"""
if len(tokens) > max_length:
return tokens[:max_length]
elif len(tokens) < max_length:
padding = [self.tokenizer.pad_token_id] * (max_length - len(tokens))
return tokens + padding
return tokens
2.2.2 上下文管理器
上下文管理器负责管理100万token的上下文窗口:
class ContextManager:
"""
管理100万token上下文窗口的上下文管理器。
实现高效的内存使用和智能缓存。
"""
def __init__(self, max_context=1_000_000):
self.max_context = max_context
self.kv_cache = KVCache(capacity=max_context)
self.importance_scorer = ImportanceScorer()
self.compressor = ContextCompressor()
def update_cache(self, layer_id, keys, values):
"""
更新特定层的key-value缓存。
参数:
layer_id: Transformer层标识符
keys: 注意力键张量
values: 注意力值张量
"""
# 计算每个token的重要性分数
importance_scores = self.importance_scorer.score(keys, values)
# 选择top-k个重要token保留
k = self._calculate_optimal_k(importance_scores)
top_indices = torch.topk(importance_scores, k).indices
# 使用选中的token更新缓存
self.kv_cache.update(layer_id, keys, values, top_indices)
def _calculate_optimal_k(self, scores, target_reduction=0.95):
"""
计算保留token的最佳数量。
target_reduction控制稀疏度。
"""
scores_sorted = torch.sort(scores, descending=True).values
cumsum = torch.cumsum(scores_sorted, dim=0) / scores_sorted.sum()
k = (cumsum >= target_reduction).nonzero()[0][0] + 1
return k.item()
def retrieve_context(self, query):
"""
根据给定query从缓存中检索相关上下文。
参数:
query: 用于匹配的查询张量
返回:
带有注意力分数的相关key-value对
"""
# 使用近似最近邻搜索提高效率
relevant_keys = self.kv_cache.approximate_search(
query,
k=1024, # 检索top 1024个相关token
metric='cosine'
)
return relevant_keys
三、MiniMax稀疏注意力(MSA)详解
3.1 架构概述
MiniMax M3的核心创新是MiniMax稀疏注意力(MSA)机制。传统注意力机制的复杂度为O(n²),其中n为序列长度。对于100万token的上下文,这变得计算上不可行。
MSA将复杂度降低至约O(n × k),其中k为选中的重要token数量(通常为1K-4K),实现50倍的计算量降低,同时保留超过95%的注意力质量。
3.2 MSA算法实现
3.2.1 重要性评分
import torch
import torch.nn as nn
import torch.nn.functional as F
class SparseAttention(nn.Module):
"""
MiniMax稀疏注意力(MSA)实现。
该模块实现了稀疏注意力机制,仅选择最重要的token进行注意力计算,
将计算复杂度从O(n²)大幅降低至O(n × k)。
"""
def __init__(self, d_model=8192, n_heads=64, k_selected=2048):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.d_head = d_model // n_heads
self.k_selected = k_selected # 稀疏度控制参数
# Q、K、V投影
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
# 重要性评分网络
self.importance_net = nn.Sequential(
nn.Linear(d_model, d_model // 4),
nn.GELU(),
nn.Linear(d_model // 4, 1),
nn.Sigmoid()
)
# 局部注意力窗口(始终关注邻近token)
self.local_window_size = 512
def compute_importance_scores(self, keys, queries):
"""
计算每个key-query对的重要性分数。
分数越高表示注意力连接越重要。
参数:
keys: Key张量 [batch, seq_len, d_model]
queries: Query张量 [batch, seq_len, d_model]
返回:
重要性分数矩阵 [batch, n_heads, seq_len, seq_len]
"""
batch_size, seq_len, _ = keys.shape
# 投影到query/key空间
k = self.W_k(keys).view(batch_size, seq_len, self.n_heads, self.d_head)
q = self.W_q(queries).view(batch_size, seq_len, self.n_heads, self.d_head)
# 计算基础注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_head ** 0.5)
# 可学习的重要性调制
importance = self.importance_net(keys) # [batch, seq_len, 1]
# 广播importance到所有head
importance = importance.unsqueeze(-1).unsqueeze(-1) # [batch, seq_len, 1, 1]
# 通过重要性调制分数
modulated_scores = scores * importance
return modulated_scores
def forward(self, x, mask=None):
"""
稀疏注意力的前向传播。
参数:
x: 输入张量 [batch, seq_len, d_model]
mask: 可选的注意力掩码
返回:
输出张量 [batch, seq_len, d_model]
"""
batch_size, seq_len, _ = x.shape
# 投影到Q、K、V
q = self.W_q(x)
k = self.W_k(x)
v = self.W_v(x)
# 重塑为多头注意力格式
q = q.view(batch_size, seq_len, self.n_heads, self.d_head).transpose(1, 2)
k = k.view(batch_size, seq_len, self.n_heads, self.d_head).transpose(1, 2)
v = v.view(batch_size, seq_len, self.n_heads, self.d_head).transpose(1, 2)
# 计算重要性分数
importance_scores = self.compute_importance_scores(k, q)
# 应用掩码(如果有)
if mask is not None:
importance_scores = importance_scores.masked_fill(mask == 0, float('-inf'))
# 选择top-k重要位置 + 局部窗口
importance_flat = importance_scores.view(batch_size, self.n_heads, -1)
# 获取top-k索引
topk_values, topk_indices = torch.topk(
importance_flat,
k=min(self.k_selected, seq_len),
dim=-1
)
# 创建稀疏注意力掩码
sparse_mask = torch.zeros_like(importance_flat)
sparse_mask.scatter_(-1, topk_indices, 1.0)
# 始终包含局部窗口注意力
for i in range(seq_len):
start = max(0, i - self.local_window_size // 2)
end = min(seq_len, i + self.local_window_size // 2)
local_indices = torch.arange(start, end, device=importance_flat.device)
sparse_mask[..., local_indices] = 1.0
# 应用稀疏掩码
sparse_scores = importance_scores.view(batch_size, self.n_heads, seq_len, seq_len)
sparse_scores = sparse_scores * sparse_mask.unsqueeze(-1)
# 计算注意力输出
attn_weights = F.softmax(sparse_scores, dim=-1)
attn_output = torch.matmul(attn_weights, v)
# 重塑并投影输出
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1)
output = self.W_o(attn_output)
return output
3.2.2 带KV缓存的稀疏注意力
class SparseAttentionWithCache:
"""
优化的稀疏注意力,支持KV缓存推理。
大幅降低长上下文的内存占用和计算量。
"""
def __init__(self, base_attention: SparseAttention, max_cache_size=1_000_000):
self.attention = base_attention
self.kv_cache = {
'keys': [],
'values': [],
'importance': []
}
self.max_cache_size = max_cache_size
def prefill(self, x):
"""
Prefill阶段:一次性处理整个上下文。
这是MSA提供最大优势的阶段。
参数:
x: 输入张量 [batch, seq_len, d_model]
"""
batch_size, seq_len, _ = x.shape
# 带重要性选择的完整注意力计算
output = self.attention(x)
# 缓存keys和values
k = self.attention.W_k(x)
v = self.attention.W_v(x)
importance = self.attention.importance_net(x)
# 对缓存应用稀疏性(仅保留top-k重要token)
self._sparse_cache(k, v, importance)
return output
def _sparse_cache(self, keys, values, importance):
"""
缓存仅保留最重要的token以管理内存。
这是高效支持100万上下文的关键。
"""
batch_size, seq_len, d_model = keys.shape
# 根据重要性选择top-k个token
k = min(self.k_selected, seq_len)
topk_importance, topk_indices = torch.topk(
importance.squeeze(-1),
k=k,
dim=-1
)
# 收集对应的keys和values
cached_keys = torch.gather(
keys.expand(batch_size, -1, -1),
dim=1,
index=topk_indices.unsqueeze(-1).expand(-1, -1, d_model)
)
cached_values = torch.gather(
values.expand(batch_size, -1, -1),
dim=1,
index=topk_indices.unsqueeze(-1).expand(-1, -1, d_model)
)
# 存入缓存
self.kv_cache['keys'] = cached_keys
self.kv_cache['values'] = cached_values
self.kv_cache['importance'] = topk_importance
# 管理缓存大小
self._prune_cache()
def _prune_cache(self):
"""剪枝缓存以维持最大容量。"""
total_tokens = sum(k.shape[1] for k in self.kv_cache['keys'])
if total_tokens > self.max_cache_size:
# 保留最新和最重要的token
prune_ratio = self.max_cache_size / total_tokens
for key in ['keys', 'values', 'importance']:
self.kv_cache[key] = [
t[:, :int(t.shape[1] * prune_ratio)]
for t in self.kv_cache[key]
]
def decode(self, x):
"""
Decode阶段:使用缓存的上下文处理新token。
比重新计算完整上下文的注意力要快得多。
参数:
x: 新token张量 [batch, 1, d_model](单个token)
返回:
新token的输出张量
"""
# 计算新token的query
q = self.attention.W_q(x)
k = self.attention.W_k(x)
v = self.attention.W_v(x)
# 关注缓存的keys和values
if len(self.kv_cache['keys']) > 0:
cached_k = torch.cat(self.kv_cache['keys'], dim=1)
cached_v = torch.cat(self.kv_cache['values'], dim=1)
# 使用缓存token计算注意力
q = q.view(-1, 1, self.attention.n_heads, self.attention.d_head).transpose(1, 2)
cached_k = cached_k.view(-1, cached_k.shape[1], self.attention.n_heads, self.attention.d_head).transpose(1, 2)
cached_v = cached_v.view(-1, cached_v.shape[1], self.attention.n_heads, self.attention.d_head).transpose(1, 2)
# 与缓存上下文的稀疏注意力
scores = torch.matmul(q, cached_k.transpose(-2, -1)) / (self.attention.d_head ** 0.5)
attn_weights = F.softmax(scores, dim=-1)
attn_output = torch.matmul(attn_weights, cached_v)
# 结合局部注意力
local_output = self._local_attention(x)
attn_output = 0.7 * attn_output + 0.3 * local_output
# 重塑输出
attn_output = attn_output.transpose(1, 2).contiguous().view(1, 1, -1)
output = self.attention.W_o(attn_output)
else:
output = self._local_attention(x)
# 使用新token更新缓存
self._update_cache(k, v)
return output
def _local_attention(self, x):
"""计算缓存窗口内的局部注意力。"""
return self.attention(x)
def _update_cache(self, keys, values):
"""使用新解码的token更新缓存。"""
# 添加新token到缓存
self.kv_cache['keys'].append(keys)
self.kv_cache['values'].append(values)
# 定期压缩缓存
if len(self.kv_cache['keys']) > 100:
self._compact_cache()
def _compact_cache(self):
"""定期压缩缓存,移除不重要的条目。"""
# 拼接所有缓存的token
all_keys = torch.cat(self.kv_cache['keys'], dim=1)
all_values = torch.cat(self.kv_cache['values'], dim=1)
# 重新计算重要性并选择top-k
importance = self.attention.importance_net(all_keys)
topk_importance, topk_indices = torch.topk(
importance.squeeze(-1),
k=min(self.k_selected, all_keys.shape[1]),
dim=-1
)
# 收集top-k token
self.kv_cache['keys'] = [
torch.gather(
all_keys, 1,
topk_indices.unsqueeze(-1).expand(-1, -1, all_keys.shape[-1])
)
]
self.kv_cache['values'] = [
torch.gather(
all_values, 1,
topk_indices.unsqueeze(-1).expand(-1, -1, all_values.shape[-1])
)
]
3.3 性能特性对比
MSA架构提供了显著的性能提升:
| 指标 | 传统注意力 | MiniMax MSA | 提升幅度 |
|---|---|---|---|
| Prefilling速度 | 基准 | >9倍 | 900%+ |
| Decoding速度 | 基准 | >15倍 | 1500%+ |
| 内存使用 | O(n²) | O(n × k) | 约95%降低 |
| 上下文长度 | 128K上限 | 1M | 8倍增长 |
| 质量保持率 | 100% | >95% | 几乎无损失 |
四、性能基准测试
4.1 编程基准测试
MiniMax M3在编程基准测试中取得了优异成绩:
4.1.1 SWE-Bench Pro结果
┌─────────────────────────────────────────────────────────────────┐
│ SWE-Bench Pro 得分对比 │
├─────────────────────────────────────────────────────────────────┤
│ 模型 │ 得分 │ 排名 │
│ ──────────────────────────────┼─────────┼───────────────────────│
│ Claude Opus 4.7 │ 60.2% │ #1 │
│ MiniMax M3 │ 59.0% │ #2 (并列) │
│ OpenAI GPT-5.5 │ 58.4% │ #3 │
│ Google Gemini 3.1 Pro │ 56.8% │ #4 │
│ Anthropic Claude 3.5 Sonnet │ 54.2% │ #5 │
└─────────────────────────────────────────────────────────────────┘
4.1.2 更多编程指标
# 基准测试结果对比
BENCHMARK_RESULTS = {
'minimax_m3': {
'swe_bench_pro': 59.0,
'human_eval_pass_at_1': 92.4,
'mbpp_pass_at_1': 88.7,
'multiplx': 87.2,
'avg_code_review_time_seconds': 45,
'context_window': 1_000_000,
},
'gpt_5_5': {
'swe_bench_pro': 58.4,
'human_eval_pass_at_1': 91.8,
'mbpp_pass_at_1': 87.5,
'multiplx': 85.9,
'avg_code_review_time_seconds': 52,
'context_window': 256_000,
},
'gemini_3_1_pro': {
'swe_bench_pro': 56.8,
'human_eval_pass_at_1': 90.2,
'mbpp_pass_at_1': 86.3,
'multiplx': 84.1,
'avg_code_review_time_seconds': 58,
'context_window': 128_000,
}
}
def print_benchmark_comparison():
"""打印格式化的基准测试对比表。"""
print("=" * 70)
print("编程基准测试对比")
print("=" * 70)
print(f"{'模型':<20} {'SWE-Bench':<12} {'HumanEval':<12} {'MBPP':<12} {'上下文'}")
print("-" * 70)
for model, scores in BENCHMARK_RESULTS.items():
print(f"{model:<20} {scores['swe_bench_pro']:<12.1f} "
f"{scores['human_eval_pass_at_1']:<12.1f} "
f"{scores['mbpp_pass_at_1']:<12.1f} "
f"{scores['context_window']:>10,}")
print("=" * 70)
def analyze_complexity_performance():
"""
分析不同代码复杂度级别下的模型性能。
"""
complexity_levels = ['简单', '中等', '复杂', '专家级']
performance_data = {
'MiniMax M3': {
'简单': 98.5,
'中等': 94.2,
'复杂': 87.6,
'专家级': 72.3
},
'GPT-5.5': {
'简单': 97.8,
'中等': 93.1,
'复杂': 85.4,
'专家级': 68.9
},
'Gemini 3.1 Pro': {
'简单': 96.5,
'中等': 91.2,
'复杂': 82.8,
'专家级': 64.2
}
}
print("\n" + "=" * 70)
print("不同代码复杂度下的性能表现")
print("=" * 70)
print(f"{'复杂度':<15} {'MiniMax M3':<15} {'GPT-5.5':<15} {'Gemini 3.1 Pro'}")
print("-" * 70)
for complexity in complexity_levels:
print(f"{complexity:<15} {performance_data['MiniMax M3'][complexity]:<15.1f} "
f"{performance_data['GPT-5.5'][complexity]:<15.1f} "
f"{performance_data['Gemini 3.1 Pro'][complexity]}")
print("=" * 70)
if __name__ == "__main__":
print_benchmark_comparison()
analyze_complexity_performance()
五、代码实现示例
5.1 代码生成示例
"""
MiniMax M3 代码生成示例
展示模型在复杂项目结构理解下生成高质量代码的能力。
"""
from minmax import MiniMaxM3
# 初始化模型
model = MiniMaxM3(
api_key="your-api-key",
model_version="m3-pro",
max_context=1_000_000 # 完整100万上下文支持
)
# 示例1:生成完整的REST API
def generate_rest_api():
"""
生成完整的Python FastAPI应用,包含:
1. 用户认证(JWT)
2. PostgreSQL数据库集成(SQLAlchemy)
3. 'Project'资源的CRUD操作
4. WebSocket实时更新支持
5. OpenAPI文档
6. 限流
7. pytest单元测试
"""
prompt = """
生成一个完整的Python FastAPI应用,包含:
1. 用户认证(JWT)
2. PostgreSQL数据库集成(SQLAlchemy)
3. 'Project'资源的CRUD操作
4. WebSocket支持实时更新
5. OpenAPI文档
6. 限流
7. pytest单元测试
包含:
- 主应用文件(main.py)
- 数据库模型(models.py)
- Schemas(schemas.py)
- API路由(routes.py)
- 认证模块(auth.py)
- 配置(config.py)
- 依赖文件(requirements.txt)
"""
response = model.generate(
prompt=prompt,
language="python",
framework="fastapi",
include_tests=True,
style="production-ready"
)
return response
# 示例2:基于上下文的代码重构
def refactor_with_context():
"""
展示上下文感知的代码重构能力。
模型理解整个项目结构。
"""
# 加载整个项目上下文(最高100万tokens)
project_context = load_project_files("./my-django-project")
prompt = f"""
分析以下Django项目并进行重构:
1. 实现Repository模式
2. 添加依赖注入
3. 改进错误处理
4. 添加全面的日志记录
5. 实现缓存层
项目结构:
{project_context}
"""
refactored_code = model.refactor(
project_context=project_context,
patterns=['repository', 'di', 'caching'],
target_style='clean-architecture'
)
return refactored_code
# 示例3:带根因分析的Bug修复
def fix_bug_analysis():
"""
展示智能Bug修复与根因分析能力。
"""
error_log = """
Traceback (most recent call last):
File "app.py", line 42, in process_data
result = transform(data)
File "transform.py", line 128, in transform
return parser.parse(data)
File "parser.py", line 89, in parse
return json.loads(data)
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
"""
codebase = load_project_files("./src")
prompt = f"""
分析此错误和代码库以:
1. 识别根本原因
2. 解释错误为何发生
3. 提供完整修复方案及解释
4. 添加测试以防止回归
错误:
{error_log}
代码库:
{codebase}
"""
analysis = model.fix_bug(
error_log=error_log,
project_context=codebase,
include_explanation=True
)
return analysis
# 示例4:测试生成
def generate_comprehensive_tests():
"""
生成全面的测试用例,包括边界情况。
"""
code_to_test = """
def calculate_discount(price: float, discount_percent: float,
is_loyal_customer: bool = False) -> float:
'''计算折扣后的最终价格。'''
if price < 0:
raise ValueError("价格不能为负数")
if discount_percent < 0 or discount_percent > 100:
raise ValueError("折扣必须在0到100之间")
discount = price * (discount_percent / 100)
final_price = price - discount
if is_loyal_customer:
final_price *= 0.95 # 额外95折
return round(final_price, 2)
"""
tests = model.generate_tests(
code=code_to_test,
framework="pytest",
include_edge_cases=True,
include_mocking=True,
coverage_target=90
)
# 生成的测试代码:
# import pytest
# from your_module import calculate_discount
#
# class TestCalculateDiscount:
# def test_standard_discount(self):
# assert calculate_discount(100.0, 10.0) == 90.0
#
# def test_loyal_customer_discount(self):
# assert calculate_discount(100.0, 10.0, True) == 85.5
#
# def test_negative_price_raises_error(self):
# with pytest.raises(ValueError):
# calculate_discount(-10.0, 10.0)
#
# def test_invalid_discount_raises_error(self):
# with pytest.raises(ValueError):
# calculate_discount(100.0, 150.0)
#
# def test_zero_price(self):
# assert calculate_discount(0.0, 10.0) == 0.0
#
# @pytest.mark.parametrize("price,discount,expected", [
# (100.0, 0.0, 100.0),
# (100.0, 100.0, 0.0),
# (99.99, 33.33, 66.66),
# ])
# def test_various_discounts(self, price, discount, expected):
# assert calculate_discount(price, discount) == expected
return tests
# 示例5:代码解释和文档生成
def explain_and_document():
"""
为遗留代码生成全面的文档。
"""
legacy_code = """
def proc(d, k, v=None):
if v is None:
return [x[k] for x in d if k in x]
for x in d:
if x.get(k) == v:
return x
return None
"""
documentation = model.document_code(
code=legacy_code,
style='google-docstring',
include_examples=True,
explain_logic=True
)
# 输出:
# """
# 按键值对搜索字典列表。
#
# 此函数提供两种操作模式:
# 1. 获取器模式:返回给定键的所有值
# 2. 查找器模式:返回第一个匹配键=值的字典
#
# 参数:
# d (List[Dict]): 要搜索的字典列表
# k (str): 要搜索的字典键
# v: 可选的要匹配的值。如果为None,则为获取器模式。
#
# 返回:
# 获取器模式:键k的所有值的列表
# 查找器模式:dict[k] == v的第一个字典,或None
#
# 示例:
# >>> data = [{'name': 'Alice', 'age': 30},
# ... {'name': 'Bob', 'age': 25}]
# >>> proc(data, 'name')
# ['Alice', 'Bob']
# >>> proc(data, 'name', 'Alice')
# {'name': 'Alice', 'age': 30}
# """
return documentation
5.2 API使用示例
"""
MiniMax M3 API使用示例
全面指南,介绍如何使用MiniMax M3 API。
"""
from minimax import MiniMaxM3, AsyncMiniMaxM3
import asyncio
# ==================== 同步API示例 ====================
def synchronous_examples():
"""基本的同步API使用示例。"""
# 初始化客户端
client = MiniMaxM3(
api_key="your-api-key",
base_url="https://api.minimax.chat/v1",
timeout=120
)
# 示例1:简单的文本补全
response = client.complete(
prompt="编写一个Python函数来计算斐波那契数列:",
max_tokens=500,
temperature=0.7
)
print(f"补全结果: {response.choices[0].text}")
# 示例2:聊天补全
chat_response = client.chat.completions.create(
model="minimax-m3",
messages=[
{"role": "system", "content": "你是一个有用的编程助手。"},
{"role": "user", "content": "解释Python中列表和元组的区别。"}
],
temperature=0.3,
top_p=0.9
)
print(f"聊天回复: {chat_response.choices[0].message.content}")
# 示例3:带流式输出的代码生成
print("流式代码生成:")
for chunk in client.generate(
prompt="创建一个FastAPI用户认证端点:",
stream=True,
max_tokens=1000
):
print(chunk.content, end="", flush=True)
print()
# 示例4:使用100万上下文进行代码库分析
with open("large_codebase.py", "r") as f:
codebase = f.read()
analysis_response = client.analyze(
context=codebase,
task="识别所有安全漏洞并建议修复方案",
analysis_depth="comprehensive"
)
print(f"安全分析: {analysis_response}")
# ==================== 异步API示例 ====================
async def asynchronous_examples():
"""高性能应用的异步API使用。"""
async_client = AsyncMiniMaxM3(
api_key="your-api-key",
max_connections=100,
max_keepalive_connections=20
)
# 示例1:并发代码审查
async def review_file(filepath):
with open(filepath, "r") as f:
code = f.read()
return await async_client.review_code(
code=code,
standards=["pep8", "security", "performance"]
)
# 并发审查多个文件
files_to_review = [
"src/models.py",
"src/views.py",
"src/utils.py",
"src/handlers.py"
]
reviews = await asyncio.gather(*[
review_file(f) for f in files_to_review
])
for filepath, review in zip(files_to_review, reviews):
print(f"\n=== {filepath} 的审查结果 ===")
print(f"发现的问题: {len(review.issues)}")
print(f"质量评分: {review.quality_score}/100")
# 示例2:流式异步处理
async def generate_with_progress():
print("正在生成代码...")
async for chunk in async_client.generate(
prompt="编写一个完整的Django REST API,包含认证:",
stream=True,
max_tokens=5000
):
print(chunk.content, end="", flush=True)
await generate_with_progress()
# 示例3:批量处理
tasks = [
{"prompt": "解释JavaScript中的闭包", "max_tokens": 500},
{"prompt": "解释Python中的闭包", "max_tokens": 500},
{"prompt": "对比JS和Python中的闭包", "max_tokens": 800},
]
batch_results = await async_client.batch_complete(tasks)
for result in batch_results:
print(f"\n任务结果: {result.choices[0].text[:100]}...")
# ==================== 高级用法 ====================
def advanced_examples():
"""高级API使用模式。"""
client = MiniMaxM3(api_key="your-api-key")
# 示例1:自定义编码/解码
def custom_encoder(obj):
"""用于特殊类型的自定义JSON编码器。"""
if hasattr(obj, 'to_dict'):
return obj.to_dict()
raise TypeError(f"类型{type(obj)}的对象不可序列化为JSON")
response = client.complete(
prompt="分析这个数据结构:",
response_format={"type": "json_object"},
json_encoder=custom_encoder
)
# 示例2:指数退避重试
from tenacity import retry, stop_after_attempt, wait_exponential
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10)
)
def robust_completion(prompt):
return client.complete(prompt=prompt)
# 示例3:限流
from ratelimit import limits, sleep_and_retry
@sleep_and_retry
@limits(calls=100, period=60)
def rate_limited_completion(prompt):
return client.complete(prompt=prompt)
# 示例4:缓存响应
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_completion(prompt_hash, temperature):
prompt = decode_prompt(prompt_hash)
return client.complete(prompt=prompt, temperature=temperature)
# 示例5:进度回调
def progress_callback(completed_tokens, total_tokens):
progress = (completed_tokens / total_tokens) * 100
print(f"进度: {progress:.1f}%")
response = client.generate(
prompt="写一篇关于微服务的综合教程:",
max_tokens=10000,
callback=progress_callback
)
if __name__ == "__main__":
# 运行同步示例
# synchronous_examples()
# 运行异步示例
# asyncio.run(asynchronous_examples())
# 运行高级示例
# advanced_examples()
print("示例已配置,取消注释即可运行。")
5.3 MiniMax Code集成示例
"""
MiniMax Code集成示例
展示如何集成MiniMax Code以实现自主编码智能体。
"""
from minimax_code import MiniMaxCode, Agent, Task
# 初始化MiniMax Code客户端
code_client = MiniMaxCode(
api_key="your-api-key",
mode="autonomous" # 自主智能体模式
)
# 示例1:单任务执行
def execute_single_task():
"""
执行具有自动规划的单个编码任务。
"""
task = Task(
description="为电商产品数据创建一个网页爬虫",
requirements=[
"支持Amazon、eBay和Walmart",
"限速以避免被检测",
"数据存储到PostgreSQL",
"包含错误处理和重试逻辑",
"提供CLI界面"
],
constraints={
"max_execution_time": "30分钟",
"budget_limit": "100次API调用"
}
)
result = code_client.execute(task)
print(f"任务完成: {result.success}")
print(f"创建的文件: {result.files_created}")
print(f"通过的测试: {result.tests_passed}")
print(f"执行时间: {result.execution_time}")
# 示例2:多智能体工作流
def multi_agent_workflow():
"""
创建具有多个专业智能体的工作流。
"""
# 定义智能体团队
architect = Agent(
name="架构师",
role="系统架构师",
expertise=["系统设计", "架构模式"]
)
backend_dev = Agent(
name="后端开发者",
role="后端工程师",
expertise=["Python", "FastAPI", "PostgreSQL", "Redis"]
)
frontend_dev = Agent(
name="前端开发者",
role="前端工程师",
expertise=["React", "TypeScript", "CSS"]
)
tester = Agent(
name="QA工程师",
role="质量保证",
expertise=["测试", "pytest", "cypress", "CI/CD"]
)
# 创建项目工作流
project = code_client.create_project(
name="电商平台",
description="基于微服务的全栈电商平台",
agents=[architect, backend_dev, frontend_dev, tester],
workflow="sequential" # 或"parallel"实现并发执行
)
# 执行项目阶段
phases = [
{
"name": "架构设计",
"agent": architect,
"task": "设计可扩展的电商微服务架构"
},
{
"name": "后端开发",
"agent": backend_dev,
"task": "实现后端API和数据库层"
},
{
"name": "前端开发",
"agent": frontend_dev,
"task": "使用响应式设计构建React前端"
},
{
"name": "测试与QA",
"agent": tester,
"task": "创建全面测试套件和CI/CD流水线"
}
]
for phase in phases:
print(f"\n执行阶段: {phase['name']}")
result = project.execute_phase(
phase_name=phase['name'],
agent=phase['agent'],
task=phase['task']
)
print(f"阶段结果: {result}")
# 示例3:长期自主任务
def autonomous_development():
"""
运行持续数天的多阶段自主开发任务。
"""
task = Task(
description="""
开发一个完整的客户流失预测机器学习流水线。
需求:
1. 从多个来源(SQL、API、S3)获取数据
2. 自动检测的特征工程
3. 超参数优化的模型训练
4. 综合指标的模型评估
5. 生产部署与监控
6. 文档和API
智能体应:
- 将任务分解为可管理的阶段
- 自主执行每个阶段
- 定期报告进度
- 根据结果调整策略
- 根据需要持续运行数天
""",
mode="autonomous",
max_duration_days=5,
checkpoint_frequency_hours=6,
notification_callback=print_progress
)
# 启动自主任务
job = code_client.start_autonomous_task(task)
# 监控进度
while not job.is_complete:
status = job.get_status()
print(f"当前阶段: {status.current_phase}")
print(f"进度: {status.progress}%")
print(f"已完成任务: {status.tasks_completed}")
print(f"遇到的问题: {status.issues}")
time.sleep(3600) # 每小时检查一次
# 获取最终结果
final_result = job.get_results()
print(f"\n{'='*60}")
print("自主任务完成")
print(f"{'='*60}")
print(f"成功: {final_result.success}")
print(f"交付物: {final_result.deliverables}")
print(f"总时长: {final_result.total_duration}")
def print_progress(update):
"""进度通知的回调函数。"""
print(f"\n[{update.timestamp}] {update.phase}: {update.message}")
# 示例4:代码审查工作流
def automated_code_review():
"""
PR的自动化代码审查。
"""
review_config = {
"standards": [
"pep8",
"security_best_practices",
"performance_guidelines",
"documentation_requirements"
],
"auto_fix": True,
"auto_test": True,
"min_coverage": 80
}
# 审查PR
review_result = code_client.review_pr(
repo_url="https://github.com/your-org/your-repo",
pr_number=123,
config=review_config
)
print("代码审查报告")
print("=" * 60)
print(f"审查的文件: {len(review_result.files)}")
print(f"发现的问题: {len(review_result.issues)}")
print(f"自动修复已应用: {len(review_result.auto_fixes)}")
print(f"测试结果: {review_result.test_summary}")
# 打印详细问题
for issue in review_result.issues:
print(f"\n[{issue.severity}] {issue.file}:{issue.line}")
print(f" {issue.message}")
print(f" 建议: {issue.suggestion}")
六、MiniMax Code:AI编程产品
6.1 产品概述
MiniMax Code是构建在M3模型之上的AI编程产品,具有以下特性:
- 智能体集群:将复杂任务分解为多个可并发、可动态调整的阶段
- 自主执行:可在复杂任务上自主运行数天
- 代码生成:生成生产就绪的代码,包含测试和文档
- 代码审查:自动化审查,提供安全性和性能分析
- Bug检测:高级Bug发现与根因分析
6.2 智能体集群架构
"""
MiniMax Code智能体集群架构
展示多个智能体如何在复杂任务上协作。
"""
from minimax_code.clusters import AgentCluster, Agent, TaskRouter
from typing import List, Dict, Any
class MiniMaxCodeAgentCluster:
"""
用于复杂软件开发任务的智能体集群。
特性:动态任务分解和并行执行。
"""
def __init__(self, cluster_config: Dict[str, Any]):
self.config = cluster_config
self.agents: List[Agent] = []
self.task_router = TaskRouter()
self.task_queue = []
self.completed_tasks = []
def initialize_agents(self, agent_specs: List[Dict[str, str]]):
"""
根据需求初始化专业智能体。
"""
for spec in agent_specs:
agent = Agent(
id=spec['id'],
name=spec['name'],
role=spec['role'],
capabilities=spec['capabilities'],
model=spec.get('model', 'minimax-m3'),
max_concurrent_tasks=spec.get('max_concurrent', 3)
)
self.agents.append(agent)
print(f"已初始化智能体: {agent.name} ({agent.role})")
def decompose_task(self, task: str) -> List[Dict[str, Any]]:
"""
将复杂任务分解为可管理的子任务。
"""
decomposition_prompt = f"""
将以下任务分解为独立的、可执行的子任务。
每个子任务应:
- 可由单个智能体执行
- 有明确的输入和输出
- 与其他任务依赖关系最小
- 可在1-4小时内完成
任务: {task}
返回JSON格式的子任务数组,包含:
- id: 唯一标识符
- description: 清晰描述
- dependencies: 依赖的任务ID列表
- estimated_duration: 小时数
- required_capabilities: 所需技能列表
"""
response = self.task_router.decompose(decomposition_prompt)
subtasks = json.loads(response)
print(f"分解为{len(subtasks)}个子任务")
return subtasks
def execute_parallel(self, tasks: List[Dict]) -> List[Any]:
"""
使用可用智能体并行执行多个任务。
"""
# 创建执行图
execution_graph = self._build_execution_graph(tasks)
# 找出没有依赖的任务
ready_tasks = [t for t in tasks if not t.get('dependencies')]
results = []
while ready_tasks:
# 为可用智能体分配就绪任务
assignments = self._assign_tasks(ready_tasks)
# 并行执行分配的任务
batch_results = self._execute_batch(assignments)
results.extend(batch_results)
# 标记完成并找出新就绪任务
completed_ids = {r['task_id'] for r in batch_results}
self.completed_tasks.extend(batch_results)
# 检查完成的任务是否解锁新任务
newly_ready = self._find_ready_tasks(tasks, completed_ids)
ready_tasks = newly_ready
return results
def _build_execution_graph(self, tasks: List[Dict]) -> Dict:
"""构建任务依赖图。"""
graph = {}
for task in tasks:
graph[task['id']] = {
'task': task,
'dependencies': set(task.get('dependencies', [])),
'status': 'pending'
}
return graph
def _assign_tasks(self, tasks: List[Dict]) -> Dict[Agent, List[Dict]]:
"""基于能力将任务分配给可用智能体。"""
assignments = {}
for task in tasks:
# 选择最佳匹配智能体
agent = self._select_agent(task)
if agent:
if agent not in assignments:
assignments[agent] = []
assignments[agent].append(task)
return assignments
def _select_agent(self, task: Dict) -> Agent:
"""根据能力为任务选择最佳智能体。"""
required = set(task.get('required_capabilities', []))
best_agent = None
best_score = -1
for agent in self.agents:
if agent.is_available():
# 计算能力匹配分数
agent_caps = set(agent.capabilities)
match_score = len(required & agent_caps) / len(required) if required else 1
if match_score > best_score:
best_score = match_score
best_agent = agent
return best_agent
def _execute_batch(self, assignments: Dict[Agent, List[Dict]]) -> List[Any]:
"""执行一批任务分配。"""
import concurrent.futures
def execute_task(agent, task):
print(f"智能体{agent.name}正在执行任务{task['id']}")
result = agent.execute(task)
return {
'task_id': task['id'],
'agent_id': agent.id,
'result': result,
'success': result.get('success', True)
}
futures = []
with concurrent.futures.ThreadPoolExecutor() as executor:
for agent, tasks in assignments.items():
for task in tasks:
future = executor.submit(execute_task, agent, task)
futures.append(future)
return [f.result() for f in futures]
def _find_ready_tasks(self, all_tasks: List[Dict], completed_ids: set) -> List[Dict]:
"""找出现在可以执行的任务。"""
ready = []
for task in all_tasks:
if task['id'] not in completed_ids:
deps = set(task.get('dependencies', []))
if deps <= completed_ids: # 所有依赖已满足
ready.append(task)
return ready
# 使用示例
def create_development_cluster():
"""
创建用于软件开发的智能体集群。
"""
cluster_config = {
'max_agents': 10,
'execution_mode': 'parallel',
'checkpoint_frequency': 3600, # 每小时
'auto_retry': True,
'max_retries': 3
}
cluster = MiniMaxCodeAgentCluster(cluster_config)
# 初始化专业智能体
cluster.initialize_agents([
{
'id': 'backend-dev-1',
'name': '后端开发者Alpha',
'role': '后端工程师',
'capabilities': ['python', 'fastapi', 'postgresql', 'redis', 'docker']
},
{
'id': 'backend-dev-2',
'name': '后端开发者Beta',
'role': '后端工程师',
'capabilities': ['python', 'django', 'mysql', 'celery', 'kubernetes']
},
{
'id': 'frontend-dev',
'name': '前端开发者',
'role': '前端工程师',
'capabilities': ['react', 'typescript', 'css', 'nextjs', 'graphql']
},
{
'id': 'devops',
'name': 'DevOps工程师',
'role': '基础设施',
'capabilities': ['docker', 'kubernetes', 'aws', 'terraform', 'ci-cd']
},
{
'id': 'qa',
'name': 'QA工程师',
'role': '质量保证',
'capabilities': ['pytest', 'selenium', 'cypress', 'load-testing', 'security']
}
])
return cluster
# 执行复杂项目
def execute_complex_project():
"""
使用智能体集群执行持续数天的复杂项目。
"""
cluster = create_development_cluster()
# 需要多个专业人员的复杂任务
project_task = """
构建一个完整的实时分析平台,包含:
1. 多源数据摄取流水线
2. 使用Apache Kafka和Flink进行流处理
3. 支持WebSocket更新的实时仪表板
4. ML驱动的异常检测
5. 自动化告警系统
6. 完整的CI/CD流水线
7. 全面的监控和日志
"""
# 分解为可管理的任务
subtasks = cluster.decompose_task(project_task)
print(f"\n使用智能体集群执行{len(subtasks)}个任务...")
# 并行执行
results = cluster.execute_parallel(subtasks)
# 生成最终报告
report = {
'total_tasks': len(subtasks),
'completed': len([r for r in results if r['success']]),
'failed': len([r for r in results if not r['success']]),
'agents_used': len(set(r['agent_id'] for r in results))
}
print(f"\n项目执行报告:")
print(f" 总任务数: {report['total_tasks']}")
print(f" 已完成: {report['completed']}")
print(f" 失败: {report['failed']}")
print(f" 使用智能体数: {report['agents_used']}")
七、API接入与订阅方案
7.1 API可用性
MiniMax M3 API现已公开发布, endpoint 如下:
Base URL: https://api.minimax.chat/v1
Endpoints:
- POST /completions - 文本补全
- POST /chat/completions - 聊天补全
- POST /embeddings - 嵌入向量生成
- POST /code/generate - 代码生成
- POST /code/review - 代码审查
- POST /images/generate - 图像生成(多模态)
7.2 订阅方案
| 方案 | 价格 | 功能 |
|---|---|---|
| Plus | ¥49/月 | 1M上下文、每天100K tokens、基础API访问 |
| Max | ¥119/月 | 1M上下文、每天500K tokens、优先访问、高级功能 |
| Ultra | ¥469/月 | 1M上下文、无限制tokens、专属支持、自定义模型 |
7.3 使用示例
# API使用示例
import requests
API_KEY = "your-api-key"
BASE_URL = "https://api.minimax.chat/v1"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# 代码生成请求
payload = {
"model": "minimax-m3",
"messages": [
{
"role": "user",
"content": "写一个Python函数实现二分搜索"
}
],
"max_tokens": 1000,
"temperature": 0.7
}
response = requests.post(
f"{BASE_URL}/chat/completions",
headers=headers,
json=payload
)
print(response.json())
八、公司里程碑
8.1 2026年6月1日发布内容
MiniMax关键指标:
- ARR(年度经常性收入):超过3亿美元(过去两个月翻倍)
- 全球用户:约3亿
- IPO:正式启动科创板上市辅导
8.2 开源承诺
发布后10天内(即2026年6月11日前):
- 完整模型权重
- 技术报告
- 训练代码和数据(在可能范围内)
九、总结与展望
MiniMax M3在大语言模型开发领域取得了重大突破,尤其在三个关键领域:
上下文长度:100万token的上下文窗口,由MSA驱动,实现了全新的使用场景:
- 一次性分析整个代码库
- 处理整个文档仓库
- 复杂的多文档推理
计算效率:超过9倍的预填充加速和超过15倍的解码加速,使长上下文应用变得实用且经济高效。
编程能力:SWE-Bench Pro得分59.0%,使MiniMax M3跻身全球顶级编程模型之列,超越GPT-5.5,逼近Claude Opus 4.7。
未来方向
- 全面开源权重和技术报告
- 持续改进多模态能力
- 扩展智能体集群系统,实现更自主的软件开发
附录:性能对比表
| 指标 | MiniMax M3 | GPT-5.5 | Gemini 3.1 Pro | Claude Opus 4.7 |
|---|---|---|---|---|
| SWE-Bench Pro | 59.0% | 58.4% | 56.8% | 60.2% |
| 上下文窗口 | 1M | 256K | 128K | 200K |
| Prefill速度 | >9倍 | 1倍 | 1倍 | 1倍 |
| Decode速度 | >15倍 | 1倍 | 1倍 | 1倍 |
| 多模态 | 原生 | 有限 | 是 | 有限 |
| 开源 | 即将 | 否 | 部分 | 否 |
免责声明:本文基于MiniMax公开发布的信息和各大AI新闻来源。部分技术细节为推断或近似值。官方文档请参阅MiniMax官方渠道。