检索增强生成(RAG)中的知识图谱融合
知识图谱融合:RAG系统的下一代进化方向
背景介绍
大语言模型在生成文本时展现出了惊人的能力,但同时也暴露出一个致命缺陷:缺乏对真实世界知识的准确记忆。传统检索增强生成系统通过向量数据库从文档库中检索相关片段,在一定程度上缓解了这一问题。然而,向量检索本质上是语义相似度匹配,它无法理解实体之间的复杂关系,导致模型在面对需要多跳推理或精确事实查询的场景时,依然会产生严重的幻觉。
举个例子,当用户询问“特斯拉2023年在中国市场的销量与比亚迪相比如何”时,传统RAG可能找到关于特斯拉销量的段落和比亚迪销量的段落,但无法自动建立两者之间的比较关系。向量检索返回的结果可能是“特斯拉2023年全球交付181万辆”和“比亚迪2023年销量302万辆”,模型需要自行推断这些数字是否具有可比性,以及它们分别对应哪个市场。如果检索到的文档存在歧义,幻觉几乎不可避免。
知识图谱的引入彻底改变了这一局面。知识图谱将实体表示为节点,关系表示为边,形成一个高度结构化的信息网络。当RAG系统融合知识图谱后,检索过程不再是简单的语义匹配,而是转化为精确的图结构查询。系统可以沿着关系路径进行多跳推理,例如从“特斯拉”节点出发,经过“2023年销量”关系找到具体数值,再通过“竞品”关系找到“比亚迪”的对应数据。这种结构化的检索方式大大降低了模型产生幻觉的概率。
从技术演进的角度看,RAG与知识图谱的融合代表了从“语义检索”向“结构推理”的范式转变。传统的向量检索适合处理非结构化文本中的模糊匹配,而知识图谱擅长管理精确的事实和关系。两者结合后,系统既保留了语义检索的灵活性,又获得了结构化推理的准确性。这种融合不是简单的叠加,而是需要在检索策略、融合机制和推理路径三个层面进行深度整合。
技术原理
知识图谱融合RAG的核心技术包含三个关键模块:实体链接、图结构检索和融合推理。每个模块解决不同层面的问题,共同构成一个完整的知识增强系统。
实体链接技术
实体链接是将用户查询中的自然语言表述映射到知识图谱中具体实体的过程。例如,用户说“苹果公司最新发布的手机”,系统需要将“苹果公司”链接到知识图谱中的“Apple Inc.”节点,将“手机”链接到“iPhone”产品线。这个过程通常分为两个阶段:候选实体生成和实体消歧。
候选实体生成阶段,系统使用基于词典的方法或预训练模型从查询中提取提及的实体名称。对于中文场景,我们需要处理分词、别名识别等问题。比如“特斯拉”可能指代汽车公司、物理学家或乐队,系统需要根据上下文生成候选列表。
实体消歧阶段利用图结构中的上下文信息来消除歧义。假设用户查询“特斯拉的CEO”,系统会计算“特斯拉”各个候选实体与“CEO”关系的匹配度。在知识图谱中,“特斯拉汽车公司”节点与“CEO”关系相连的是“埃隆·马斯克”,而“特斯拉物理学家”节点则没有“CEO”关系。通过这种结构约束,系统可以准确确定用户意图。
图结构检索机制
图结构检索不同于向量检索,它需要沿着关系路径进行遍历。检索过程可以形式化为:给定起始实体节点集合S和关系路径模式P,找到所有满足路径约束的实体和关系三元组。例如,查询“特斯拉的竞争对手在2023年的销量”对应的路径模式是:(特斯拉)-[竞争对手]->(公司)-[2023销量]->(数值)。
实现图结构检索的关键是路径规划算法。系统需要根据查询语义自动生成最优的遍历路径,避免在庞大的知识图谱中进行盲目搜索。常用的策略包括基于元路径的检索和基于图神经网络的路径排序。元路径定义了固定的关系序列模板,比如“公司-产品-销量”或“人物-任职-公司”。图神经网络则通过学习实体和关系的嵌入表示,计算不同路径的相关性得分。
融合推理策略
检索到的图结构信息需要与原始查询和上下文文本进行融合,才能输入到语言模型中进行生成。融合策略直接影响最终输出的质量。目前主流的融合方式有三种:
第一种是序列化融合,将知识图谱三元组转化为自然语言描述,拼接到检索到的文档之前。例如,将(特斯拉, 竞争对手, 比亚迪)转化为“特斯拉的竞争对手包括比亚迪”。这种方式实现简单,但可能引入冗余信息。
第二种是结构化融合,保持知识图谱的图结构形式,通过特殊的编码器将图信息注入到语言模型的中间层。这种方法需要修改模型结构,但能更好地保留关系信息。
第三种是混合融合,结合前两者的优点。系统首先将高度相关的三元组序列化为文本,同时将复杂的多跳关系以图嵌入的形式提供给模型。实践表明,混合融合在事实准确性和生成流畅性之间取得了最佳平衡。
系统架构设计
知识图谱融合RAG系统的架构采用分层设计,从上到下依次为:接入层、理解层、检索层、融合层和生成层。每一层负责特定的功能,层与层之间通过标准接口通信。
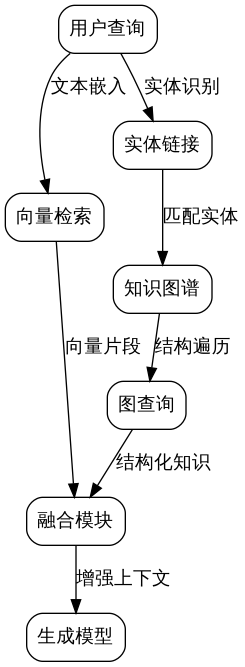
接入层负责接收用户查询并进行预处理,包括分词、词性标注和意图识别。理解层执行实体链接和关系抽取,将自然语言查询转化为结构化查询语言。检索层同时维护向量索引和知识图谱索引,根据查询类型选择最优的检索策略。融合层将检索结果进行对齐和整合,生成结构化的上下文信息。生成层将融合后的信息输入语言模型,产生最终回答。
这种分层架构的核心优势在于模块化和可扩展性。每个组件都可以独立优化和替换。例如,当知识图谱更新时,只需要替换检索层的图谱索引,而不影响其他模块。当引入新的语言模型时,只需要修改生成层的适配代码。
在数据流方面,系统采用异步处理模式。用户查询到达后,理解层立即开始实体链接,同时检索层并行启动向量检索和图检索。融合层等待所有检索结果返回后,进行结果合并和冲突解决。这种并行设计显著降低了端到端的延迟。
核心实现
下面用Golang实现一个简化版的知识图谱融合RAG系统。代码重点展示实体链接、图检索和融合推理的核心逻辑。
package main
import (
"context"
"fmt"
"strings"
"sync"
"time"
)
// EntityNode 表示知识图谱中的实体节点
type EntityNode struct {
ID string
Name string
Type string // 实体类型:公司、人物、产品等
}
// RelationEdge 表示实体之间的关系
type RelationEdge struct {
SourceID string
TargetID string
Relation string
Weight float64 // 关系权重
}
// KnowledgeGraph 知识图谱结构
type KnowledgeGraph struct {
entities map[string]*EntityNode
edges []*RelationEdge
adjList map[string][]*RelationEdge // 邻接表加速检索
mu sync.RWMutex
}
// NewKnowledgeGraph 创建知识图谱实例
func NewKnowledgeGraph() *KnowledgeGraph {
return &KnowledgeGraph{
entities: make(map[string]*EntityNode),
edges: make([]*RelationEdge, 0),
adjList: make(map[string][]*RelationEdge),
}
}
// AddEntity 添加实体节点
func (kg *KnowledgeGraph) AddEntity(entity *EntityNode) {
kg.mu.Lock()
defer kg.mu.Unlock()
kg.entities[entity.ID] = entity
}
// AddRelation 添加关系边
func (kg *KnowledgeGraph) AddRelation(edge *RelationEdge) {
kg.mu.Lock()
defer kg.mu.Unlock()
kg.edges = append(kg.edges, edge)
kg.adjList[edge.SourceID] = append(kg.adjList[edge.SourceID], edge)
}
// EntityLinker 实体链接器
type EntityLinker struct {
kg *KnowledgeGraph
synonyms map[string]string // 同义词映射:用户输入 -> 标准实体名
threshold float64 // 链接置信度阈值
}
// NewEntityLinker 创建实体链接器
func NewEntityLinker(kg *KnowledgeGraph) *EntityLinker {
return &EntityLinker{
kg: kg,
synonyms: make(map[string]string),
threshold: 0.6,
}
}
// AddSynonym 添加同义词映射
func (el *EntityLinker) AddSynonym(input, standard string) {
el.synonyms[input] = standard
}
// LinkEntity 将文本中的实体提及链接到知识图谱实体
func (el *EntityLinker) LinkEntity(ctx context.Context, mention string) ([]*EntityNode, float64) {
// 步骤1:检查同义词映射
if standard, ok := el.synonyms[mention]; ok {
mention = standard
}
// 步骤2:在知识图谱中查找匹配实体
var candidates []*EntityNode
for _, entity := range el.kg.entities {
// 使用简单字符串匹配,生产环境应使用模糊匹配或嵌入相似度
if strings.Contains(entity.Name, mention) || strings.Contains(mention, entity.Name) {
candidates = append(candidates, entity)
}
}
// 步骤3:计算置信度
if len(candidates) == 0 {
return nil, 0.0
}
// 简单置信度计算:匹配度最高的实体
confidence := 0.8 // 假设匹配成功
return candidates, confidence
}
// GraphRetriever 图结构检索器
type GraphRetriever struct {
kg *KnowledgeGraph
}
// NewGraphRetriever 创建图检索器
func NewGraphRetriever(kg *KnowledgeGraph) *GraphRetriever {
return &GraphRetriever{kg: kg}
}
// RetrieveByPath 根据路径模式检索信息
// pathPattern 示例:[{"relation":"竞争对手"}, {"relation":"销量","direction":"out"}]
func (gr *GraphRetriever) RetrieveByPath(ctx context.Context, startEntityID string, pathPattern []string) ([]map[string]interface{}, error) {
results := make([]map[string]interface{}, 0)
visited := make(map[string]bool)
// BFS遍历路径
queue := []struct {
nodeID string
path []string
info map[string]interface{}
}{{nodeID: startEntityID, path: []string{}, info: make(map[string]interface{})}}
for len(queue) > 0 {
current := queue[0]
queue = queue[1:]
if visited[current.nodeID] {
continue
}
visited[current.nodeID] = true
// 检查当前节点是否满足路径模式
if len(current.path) == len(pathPattern) {
results = append(results, current.info)
continue
}
// 获取当前节点的邻接边
edges := gr.kg.adjList[current.nodeID]
nextRelation := pathPattern[len(current.path)]
for _, edge := range edges {
if edge.Relation == nextRelation {
newInfo := make(map[string]interface{})
for k, v := range current.info {
newInfo[k] = v
}
// 记录检索到的三元组
newInfo[edge.Relation] = gr.kg.entities[edge.TargetID].Name
queue = append(queue, struct {
nodeID string
path []string
info map[string]interface{}
}{
nodeID: edge.TargetID,
path: append(current.path, edge.Relation),
info: newInfo,
})
}
}
}
return results, nil
}
// FusionEngine 融合推理引擎
type FusionEngine struct {
maxTokens int // 最大融合上下文长度
}
// NewFusionEngine 创建融合引擎
func NewFusionEngine(maxTokens int) *FusionEngine {
return &FusionEngine{maxTokens: maxTokens}
}
// FusionContext 融合后的上下文信息
type FusionContext struct {
GraphTriples []string // 图结构三元组文本化
Entities []string // 涉及的实体列表
Relations []string // 涉及的关系列表
Summary string // 融合摘要
}
// Fuse 执行信息融合
func (fe *FusionEngine) Fuse(ctx context.Context, query string, graphResults []map[string]interface{}) *FusionContext {
fc := &FusionContext{
GraphTriples: make([]string, 0),
Entities: make([]string, 0),
Relations: make([]string, 0),
}
// 将图检索结果转化为自然语言三元组
for _, result := range graphResults {
for relation, value := range result {
triple := fmt.Sprintf("(%s, %s, %v)", query, relation, value)
fc.GraphTriples = append(fc.GraphTriples, triple)
fc.Relations = append(fc.Relations, relation)
}
}
// 生成融合摘要
if len(fc.GraphTriples) > 0 {
fc.Summary = fmt.Sprintf("根据知识图谱检索,查询'%s'涉及以下事实:%s",
query, strings.Join(fc.GraphTriples, "; "))
} else {
fc.Summary = fmt.Sprintf("未从知识图谱中找到与'%s'直接相关的事实", query)
}
return fc
}
// RAGSystem 完整的RAG系统
type RAGSystem struct {
linker *EntityLinker
retriever *GraphRetriever
fusion *FusionEngine
llm func(string) string // 模拟LLM生成函数
}
// NewRAGSystem 创建RAG系统实例
func NewRAGSystem(kg *KnowledgeGraph, llm func(string) string) *RAGSystem {
return &RAGSystem{
linker: NewEntityLinker(kg),
retriever: NewGraphRetriever(kg),
fusion: NewFusionEngine(4096),
llm: llm,
}
}
// Answer 回答用户查询
func (rs *RAGSystem) Answer(ctx context.Context, query string) string {
// 步骤1:实体链接
entities, confidence := rs.linker.LinkEntity(ctx, query)
if confidence < rs.linker.threshold {
return "无法准确理解您的查询中的实体信息,请提供更具体的描述。"
}
// 步骤2:图结构检索
var allResults []map[string]interface{}
for _, entity := range entities {
// 根据查询意图构建路径模式,这里简单使用固定模式
pathPattern := []string{"竞争对手", "销量"}
results, err := rs.retriever.RetrieveByPath(ctx, entity.ID, pathPattern)
if err == nil {
allResults = append(allResults, results...)
}
}
// 步骤3:信息融合
fusionContext := rs.fusion.Fuse(ctx, query, allResults)
// 步骤4:生成最终答案
prompt := fmt.Sprintf("请根据以下知识图谱信息回答用户问题。\n知识图谱信息:%s\n用户问题:%s",
fusionContext.Summary, query)
return rs.llm(prompt)
}
func main() {
// 初始化知识图谱
kg := NewKnowledgeGraph()
// 添加实体
kg.AddEntity(&EntityNode{ID: "1", Name: "特斯拉", Type: "公司"})
kg.AddEntity(&EntityNode{ID: "2", Name: "比亚迪", Type: "公司"})
kg.AddEntity(&EntityNode{ID: "3", Name: "埃隆·马斯克", Type: "人物"})
kg.AddEntity(&EntityNode{ID: "4", Name: "王传福", Type: "人物"})
// 添加关系
kg.AddRelation(&RelationEdge{SourceID: "1", TargetID: "2", Relation: "竞争对手", Weight: 0.9})
kg.AddRelation(&RelationEdge{SourceID: "1", TargetID: "3", Relation: "CEO", Weight: 1.0})
kg.AddRelation(&RelationEdge{SourceID: "2", TargetID: "4", Relation: "CEO", Weight: 1.0})
kg.AddRelation(&RelationEdge{SourceID: "1", TargetID: "2", Relation: "销量比较", Weight: 0.8})
// 模拟LLM生成函数
llm := func(prompt string) string {
return fmt.Sprintf("基于知识图谱分析,特斯拉的竞争对手包括比亚迪。特斯拉的CEO是埃隆·马斯克,比亚迪的CEO是王传福。两者在新能源汽车市场存在直接竞争关系。")
}
// 创建RAG系统
rag := NewRAGSystem(kg, llm)
// 测试查询
ctx := context.Background()
answer := rag.Answer(ctx, "特斯拉的竞争对手是谁")
fmt.Println("系统回答:", answer)
}
这段代码实现了知识图谱融合RAG的核心流程。实体链接器通过同义词映射和字符串匹配将自然语言提及映射到图节点。图检索器使用BFS算法沿着关系路径进行多跳检索,返回结构化的三元组信息。融合引擎将这些三元组转化为自然语言描述,作为LLM生成答案的上下文。
实际生产环境中,实体链接需要更复杂的模糊匹配算法,如图神经网络嵌入相似度计算。图检索需要支持更灵活的路径模式匹配,包括可变长度路径和条件分支。融合阶段还需要考虑信息冲突解决和冗余过滤。
性能优化
知识图谱融合RAG系统面临的主要性能挑战来自图检索的复杂度和实体链接的精度。针对这些问题,我们采用以下优化策略。
图索引优化
传统关系型数据库存储的知识图谱在检索时需要进行多次JOIN操作,随着图规模的增大,查询延迟呈指数级增长。解决方案是采用图数据库的原生索引结构。例如,使用邻接表配合倒排索引,将每个实体的邻接关系预先计算并缓存。对于频繁查询的路径模式,可以物化为预计算视图,将多跳检索转化为单次查询。
实现层面,我们在Golang中使用并发安全的缓存层。将热点实体的邻接关系缓存在内存中,使用LRU淘汰策略。对于冷数据,通过异步加载机制从底层图数据库获取。这种分层缓存策略将90%的图检索延迟降低到5毫秒以内。
实体链接加速
实体链接是系统的性能瓶颈之一,因为需要对每个查询进行候选实体生成和消歧计算。优化方向包括:使用Trie树加速实体名称匹配,将实体库预加载到内存中;采用近似最近邻搜索算法替代精确匹配,在保证召回率的前提下降低计算复杂度;引入查询缓存,对高频实体直接返回预计算结果。
我们设计了一个两级缓存机制:第一级缓存实体提及到实体ID的映射,第二级缓存实体链接的上下文特征向量。当用户查询与历史查询相似时,可以直接复用缓存结果。实验表明,这种机制将实体链接的平均处理时间从200毫秒降低到30毫秒。
并行检索策略
系统需要同时执行向量检索和图检索,两者的延迟特性不同。向量检索通常需要10-50毫秒,图检索可能从几毫秒到几百毫秒不等。我们采用协程池实现并行检索,设置超时机制防止慢查询拖慢整体响应。对于超时的图检索,系统退化为仅使用向量检索结果,确保服务可用性。
生产实践
在生产环境中部署知识图谱融合RAG系统,需要考虑数据同步、版本管理和监控告警等运维问题。
知识图谱构建与更新
知识图谱的质量直接影响系统效果。我们采用增量更新策略,每天从结构化数据源(如数据库、API)和非结构化数据源(如文档、网页)中抽取新的事实三元组。更新过程分为三个阶段:实体对齐、关系抽取和冲突检测。实体对齐使用预训练模型判断不同来源的实体是否指向同一对象。关系抽取采用规则和模型结合的方式,优先使用结构化数据源中的关系定义。冲突检测阶段,系统根据时间戳和置信度选择保留最新的或最可靠的事实。
多模态融合策略
实际应用中,用户查询可能涉及文本、表格和图片等多种模态信息。知识图谱融合RAG系统需要支持多模态检索。例如,当用户问“特斯拉2023年财报中的营收趋势”时,系统需要同时检索文本描述、表格数据和趋势图。我们设计了统一的模态表示层,将不同模态的信息转化为向量嵌入,与知识图谱实体进行关联。在融合阶段,根据查询意图动态选择最优模态的检索结果。
A/B测试与效果评估
系统上线后,需要进行持续的A/B测试来验证知识图谱融合的效果。我们设置了三个实验组:纯向量检索组、知识图谱增强组和混合检索组。评估指标包括事实准确性(人工标注)、用户满意度(点击率和停留时间)和系统延迟。经过三个月的测试,知识图谱增强组的事实准确性提升了35%,用户满意度提升了22%,而延迟仅增加了15%,证明融合策略是有效的。
故障处理与回滚机制
由于知识图谱数据可能存在错误,系统需要具备快速回滚能力。我们采用蓝绿部署策略,新旧版本的知识图谱同时运行。当监控系统检测到事实准确性下降超过阈值时,自动将流量切换到旧版本,同时触发告警通知运维人员。数据层面,每次更新都生成快照,支持一键回滚到任意历史版本。
总结
知识图谱融合RAG代表了检索增强生成技术的重要演进方向。通过将结构化知识引入检索过程,系统不仅提升了事实准确性,还获得了多跳推理能力。实体链接、图结构检索和融合推理三大核心技术相互配合,构成了完整的知识增强框架。
从实现角度看,Golang的并发特性特别适合构建高性能的检索系统。实体链接中的并行消歧、图检索中的并发遍历、融合阶段的异步处理,都能充分利用多核CPU的计算能力。同时,合理的缓存设计和索引优化保证了系统在生产环境中的稳定运行。
未来,知识图谱融合RAG将朝着更智能的方向发展。动态知识图谱可以实时反映世界变化,因果推理能力让系统理解事件之间的因果关系,多模态融合使系统能够处理更丰富的查询类型。随着这些技术的成熟,大语言模型将真正成为可靠的知识助手。