华为云Agentic Infra:企业级AI基础设施新范式的深度解析
一、引言:AI基础设施的范式革命
2026年6月5日,华为云INSPIRE创想者大会在上海国际会议中心盛大开幕,这场以"智能跃升,创想未来"为主题的技术盛会,汇聚了全球AI领域的顶尖学者、企业领袖和技术开发者。在本次大会上,华为云正式发布了Agentic Infra(智能体基础设施)新范式,这一里程碑式的发布标志着企业级AI基础设施正式迈入"Agentic Era"(智能体时代)。
1.1 为什么需要Agentic Infra?
传统的AI基础设施主要关注三个维度:算力供给(GPU/TPU集群)、模型服务(推理/训练基础设施)和数据管理(特征存储/向量数据库)。然而,随着大型语言模型(LLM)能力的爆发式提升,特别是多模态理解和复杂推理能力的突破,AI应用正在从"工具"向"智能体"(Agent)演进。
这种演进带来了全新的技术挑战:
传统AI系统特征:
├── 单次请求-响应模式
├── 固定 prompt 输入
├── 无状态或弱状态
└── 任务粒度:单一、原子
Agentic AI系统特征:
├── 多轮交互、持续对话
├── 动态上下文构建
├── 强状态记忆与检索
├── 任务粒度:复杂、长程、多步骤
└── 自主规划与工具调用
传统的"计算密集型"基础设施已经无法满足"智能密集型"应用的需求。华为云正是洞察到了这一趋势,率先提出了Agentic Infra这一系统性解决方案。
1.2 Agentic Infra核心架构概览
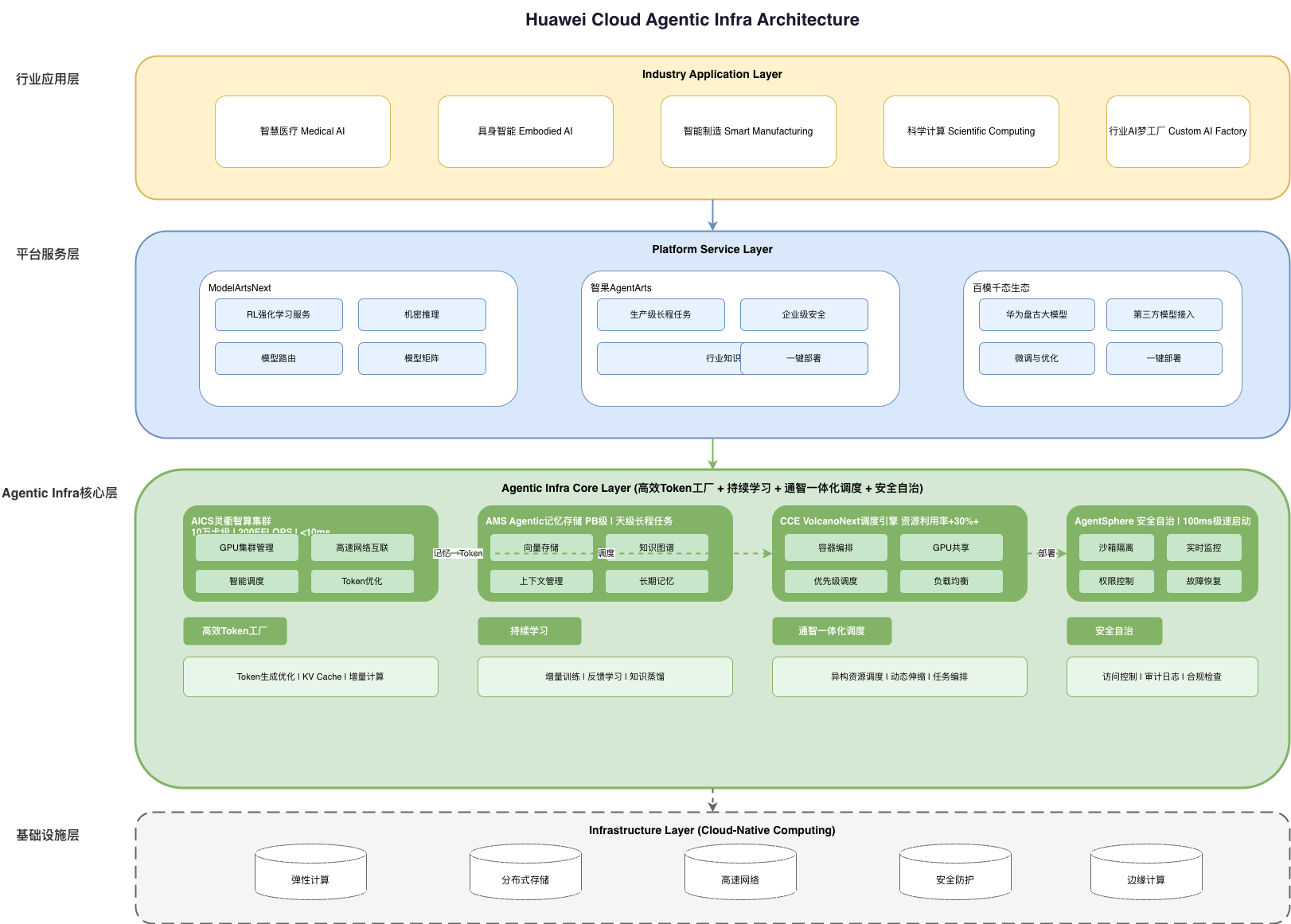
华为云Agentic Infra新范式可以概括为**“四梁八柱”**的架构体系:
四大核心能力:
- 高效Token工厂 - 优化Token生成效率,降低推理成本
- 持续学习 - 支持模型的增量学习和知识更新
- 通智一体化调度 - 打通通用计算与智能计算的边界
- 安全自治 - 构建可信赖的Agent运行环境
四大核心产品:
- AICS灵衢智算集群
- AMS Agentic记忆存储
- CCE VolcanoNext通智一体化调度引擎
- AgentSphere安全自治运行环境
二、核心技术深度解析
2.1 AICS灵衢智算集群:10万卡级的算力基座
AICS(AIC Scheduler Intelligence Cluster)是华为云面向AI原生的新一代智算集群,其核心参数令人瞩目:
| 指标 | 规格 |
|---|---|
| 集群规模 | 10万卡级 |
| 总算力 | 200 EFLOPS |
| Token推理时延 | <10ms |
| 网络互联带宽 | 800Gbps RoCEv2 |
| 存储吞吐 | 10TB/s |
2.1.1 架构设计原理
AICS采用了分层解耦的架构设计,实现了计算、网络、存储的独立弹性扩展:
# Python示例:AICS集群资源调度模拟
from dataclasses import dataclass
from typing import List, Dict, Optional
from enum import Enum
import asyncio
class ResourceType(Enum):
GPU = "gpu"
CPU = "cpu"
MEMORY = "memory"
NETWORK = "network"
STORAGE = "storage"
@dataclass
class ComputeNode:
node_id: str
gpu_count: int
gpu_memory: int # GB
bandwidth: float # Gbps
status: str = "idle"
@dataclass
class TaskRequest:
task_id: str
required_gpus: int
required_memory: int
priority: int
estimated_duration: float
class AICSClusterScheduler:
"""AICS集群调度器核心实现"""
def __init__(self):
self.nodes: Dict[str, ComputeNode] = {}
self.task_queue: List[TaskRequest] = []
self.running_tasks: Dict[str, str] = {} # task_id -> node_id
def register_node(self, node: ComputeNode):
"""注册计算节点"""
self.nodes[node.node_id] = node
print(f"[AICS] Node {node.node_id} registered: "
f"{node.gpu_count} GPUs, {node.bandwidth} Gbps")
async def submit_task(self, task: TaskRequest) -> Optional[str]:
"""
提交任务并自动调度到合适节点
调度策略:
1. 按优先级排序
2. 匹配资源需求
3. 考虑亲和性(任务内GPU通信优化)
"""
# 资源匹配
suitable_nodes = []
for node_id, node in self.nodes.items():
if (node.status == "idle" and
node.gpu_count >= task.required_gpus and
node.gpu_memory >= task.required_memory):
# 计算调度得分(考虑带宽和GPU数量)
score = node.bandwidth * (1 / task.priority)
suitable_nodes.append((node_id, score, node))
if not suitable_nodes:
self.task_queue.append(task)
return None
# 选择得分最高的节点
suitable_nodes.sort(key=lambda x: x[1], reverse=True)
selected_node_id = suitable_nodes[0][0]
# 执行调度
return await self._allocate_task(task, selected_node_id)
async def _allocate_task(self, task: TaskRequest, node_id: str) -> str:
"""任务分配"""
self.nodes[node_id].status = "running"
self.running_tasks[task.task_id] = node_id
# 模拟执行
print(f"[AICS] Task {task.task_id} allocated to {node_id}")
print(f"[AICS] Estimated completion: {task.estimated_duration}s")
return node_id
def get_cluster_status(self) -> Dict:
"""获取集群状态"""
total_gpus = sum(n.gpu_count for n in self.nodes.values())
running_gpus = sum(
n.gpu_count for n in self.nodes.values()
if n.status == "running"
)
return {
"total_nodes": len(self.nodes),
"total_gpus": total_gpus,
"running_gpus": running_gpus,
"idle_gpus": total_gpus - running_gpus,
"utilization": running_gpus / total_gpus if total_gpus > 0 else 0,
"queued_tasks": len(self.task_queue)
}
# 使用示例
async def demo_aics_scheduler():
scheduler = AICSClusterScheduler()
# 注册计算节点(模拟大规模集群)
for i in range(100):
node = ComputeNode(
node_id=f"compute-node-{i:03d}",
gpu_count=8,
gpu_memory=640, # 80GB * 8
bandwidth=800.0
)
scheduler.register_node(node)
# 提交AI任务
tasks = [
TaskRequest("task-001", required_gpus=8,
required_memory=640, priority=1, estimated_duration=120.0),
TaskRequest("task-002", required_gpus=16,
required_memory=1280, priority=2, estimated_duration=180.0),
TaskRequest("task-003", required_gpus=32,
required_memory=2560, priority=1, estimated_duration=300.0),
]
for task in tasks:
await scheduler.submit_task(task)
# 打印集群状态
status = scheduler.get_cluster_status()
print(f"\n[AICS] Cluster Status:")
print(f" Total GPUs: {status['total_gpus']}")
print(f" Utilization: {status['utilization']:.2%}")
print(f" Queued Tasks: {status['queued_tasks']}")
# 运行演示
asyncio.run(demo_aics_scheduler())
2.1.2 Token流水线优化
AICS的Token工厂采用了多项创新技术实现<10ms的推理时延:
- KV Cache优化:采用分级缓存策略,热数据保持在HBM,次热数据下沉到CXL扩展内存
- 增量计算:引入"增量解码"机制,仅计算新生成的Token
- 投机解码:使用小模型预测+大模型验证的并行解码策略
- 动态Batch:根据请求长度动态调整Batch Size,避免气泡
2.2 AMS Agentic记忆存储:PB级的认知底座
AMS(Agentic Memory Service)是华为云专为Agent设计的记忆存储系统,其核心创新在于多模态记忆的统一管理。
2.2.1 系统架构
package ams
import (
"context"
"fmt"
"time"
"github.com/huawei/agentic-infra/proto"
)
// MemoryType 定义记忆类型
type MemoryType int32
const (
MemoryTypeShortTerm MemoryType = iota // 短期记忆(工作内存)
MemoryTypeWorking // 工作记忆(当前会话)
MemoryTypeLongTerm // 长期记忆(持久化)
MemoryTypeEpisodic // 情景记忆(事件序列)
MemoryTypeSemantic // 语义记忆(知识图谱)
)
// MemoryEntry 单条记忆条目
type MemoryEntry struct {
ID string `json:"id"`
Type MemoryType `json:"type"`
Content string `json:"content"`
Embedding []float32 `json:"embedding,omitempty"`
Metadata map[string]string `json:"metadata"`
CreatedAt time.Time `json:"created_at"`
AccessedAt time.Time `json:"accessed_at"`
Importance float32 `json:"importance"` // 0.0-1.0
AccessCount int `json:"access_count"`
TTL time.Duration `json:"ttl,omitempty"` // 过期时间
}
// RetrievalQuery 记忆检索查询
type RetrievalQuery struct {
QueryText string
QueryVector []float32
Limit int
TimeRange *TimeRange
MemoryTypes []MemoryType
Filters map[string]string
}
// RetrievalResult 检索结果
type RetrievalResult struct {
Memory *MemoryEntry
Score float32 // 相关性得分
}
// AgenticMemoryStore Agent记忆存储核心接口
type AgenticMemoryStore interface {
// 写入记忆
Write(ctx context.Context, entry *MemoryEntry) error
// 批量写入
BatchWrite(ctx context.Context, entries []*MemoryEntry) error
// 检索记忆(向量+关键词混合检索)
Retrieve(ctx context.Context, query *RetrievalQuery) ([]*RetrievalResult, error)
// 更新记忆访问记录
UpdateAccess(ctx context.Context, id string) error
// 删除记忆
Delete(ctx context.Context, id string) error
// 记忆压缩(合并相似记忆,删除低价值记忆)
Compress(ctx context.Context, policy *CompressionPolicy) error
// 获取会话记忆链
GetMemoryChain(ctx context.Context, sessionID string) ([]*MemoryEntry, error)
}
// CompressionPolicy 记忆压缩策略
type CompressionPolicy struct {
MaxMemoriesPerSession int // 单会话最大记忆数
MinImportance float32 // 最低重要性阈值
MergeSimilarity float32 // 相似记忆合并阈值
RetainRecentHours int // 保留最近N小时的记忆
}
// VectorStore 向量存储接口
type VectorStore interface {
Upsert(collection string, vectors []*VectorRecord) error
Search(collection string, query []float32, topK int) ([]SearchResult, error)
Delete(collection string, ids []string) error
}
// KnowledgeGraph 知识图谱接口
type KnowledgeGraph interface {
AddTriple(subject, predicate, object string, confidence float32) error
Query(query string) ([]*Triple, error)
GetNeighbors(entity string, depth int) ([]*Triple, error)
}
// AMS主服务实现
type AMSService struct {
shortTermStore *MemoryStore // 短期记忆(Redis)
longTermStore *MemoryStore // 长期记忆(分布式存储)
vectorStore VectorStore // 向量存储(Milvus集群)
knowledgeGraph KnowledgeGraph // 知识图谱(Neo4j)
// 配置
config *AMSConfig
}
// NewAMSService 创建AMS服务实例
func NewAMSService(config *AMSConfig) (*AMSService, error) {
service := &AMSService{
config: config,
}
// 初始化各存储组件
if err := service.initStores(); err != nil {
return nil, fmt.Errorf("failed to init stores: %w", err)
}
return service, nil
}
// StoreMemory 存储Agent记忆(支持自动分层)
func (s *AMSService) StoreMemory(ctx context.Context, sessionID string,
content string, memoryType MemoryType) (*MemoryEntry, error) {
// 1. 生成或获取embedding
embedding, err := s.getEmbedding(content)
if err != nil {
return nil, fmt.Errorf("failed to generate embedding: %w", err)
}
// 2. 评估记忆重要性
importance := s.evaluateImportance(content, memoryType)
// 3. 创建记忆条目
entry := &MemoryEntry{
ID: generateID(),
Type: memoryType,
Content: content,
Embedding: embedding,
Metadata: map[string]string{
"session_id": sessionID,
},
CreatedAt: time.Now(),
AccessedAt: time.Now(),
Importance: importance,
}
// 4. 根据记忆类型选择存储层
switch memoryType {
case MemoryTypeWorking:
// 工作记忆:同时写入Redis和向量存储
if err := s.shortTermStore.Write(ctx, entry); err != nil {
return nil, err
}
if err := s.vectorStore.Upsert("working_memory", []*VectorRecord{toVectorRecord(entry)}); err != nil {
return nil, err
}
case MemoryTypeLongTerm, MemoryTypeEpisodic, MemoryTypeSemantic:
// 长期记忆:写入分布式存储和知识图谱
if err := s.longTermStore.Write(ctx, entry); err != nil {
return nil, err
}
if err := s.vectorStore.Upsert("long_term_memory", []*VectorRecord{toVectorRecord(entry)}); err != nil {
return nil, err
}
// 提取实体关系写入知识图谱
entities := s.extractEntities(content)
for _, entity := range entities {
s.knowledgeGraph.AddTriple(sessionID, "remembered", entity.Name, entry.Importance)
}
}
return entry, nil
}
// RetrieveMemories 检索相关记忆
func (s *AMSService) RetrieveMemories(ctx context.Context,
sessionID string, query string, limit int) ([]*RetrievalResult, error) {
// 1. 生成查询向量
queryEmbedding, err := s.getEmbedding(query)
if err != nil {
return nil, err
}
// 2. 构建检索查询
retrievalQuery := &RetrievalQuery{
QueryText: query,
QueryVector: queryEmbedding,
Limit: limit,
MemoryTypes: []MemoryType{MemoryTypeWorking, MemoryTypeLongTerm, MemoryTypeEpisodic},
Filters: map[string]string{
"session_id": sessionID,
},
}
// 3. 执行混合检索
results, err := s.vectorStore.Search("unified_memory", queryEmbedding, limit*2)
if err != nil {
return nil, err
}
// 4. 后处理:去重、排序、重排序(Rerank)
processedResults := s.processResults(results)
// 5. 更新访问记录
for _, result := range processedResults[:min(limit, len(processedResults))] {
s.UpdateAccess(ctx, result.Memory.ID)
}
return processedResults[:min(limit, len(processedResults))], nil
}
// CompressMemories 记忆压缩(防止上下文溢出)
func (s *AMSService) CompressMemories(ctx context.Context,
sessionID string, policy *CompressionPolicy) error {
// 1. 获取所有会话记忆
allMemories, err := s.GetMemoryChain(ctx, sessionID)
if err != nil {
return err
}
// 2. 按重要性过滤
importantMemories := filterByImportance(allMemories, policy.MinImportance)
// 3. 合并相似记忆
mergedMemories := s.mergeSimilarMemories(importantMemories, policy.MergeSimilarity)
// 4. 保留最近记忆
recentCutoff := time.Now().Add(-time.Duration(policy.RetainRecentHours) * time.Hour)
recentMemories := filterByTime(mergedMemories, recentCutoff)
// 5. 截断至最大数量
finalMemories := recentMemories
if len(finalMemories) > policy.MaxMemoriesPerSession {
// 保留最重要和最近的记忆
finalMemories = selectByImportanceAndRecency(
recentMemories,
policy.MaxMemoriesPerSession
)
}
// 6. 更新存储
return s.rebuildMemoryChain(ctx, sessionID, finalMemories)
}
2.2.2 天级长程任务支持
AMS的核心理念是**“记忆即上下文,上下文即智能”**。通过多层记忆架构,AMS能够支持"天级"甚至"周级"的长程任务:
# Python示例:AMS长程任务记忆管理
from datetime import datetime, timedelta
from typing import List, Dict, Optional
import json
class LongTermTaskMemory:
"""
长程任务记忆管理器
核心思想:将长程任务分解为多个"记忆片段",
每个片段包含任务状态、中间结果和反思总结
"""
def __init__(self, ams_service, task_id: str):
self.ams = ams_service
self.task_id = task_id
self.checkpoints: List[TaskCheckpoint] = []
async def create_checkpoint(self, state: Dict,
intermediate_result: str,
reflection: str) -> str:
"""
创建任务检查点
Args:
state: 当前任务状态
intermediate_result: 中间结果
reflection: 反思总结(对下一步的思考)
Returns:
checkpoint_id: 检查点ID
"""
checkpoint = TaskCheckpoint(
task_id=self.task_id,
checkpoint_id=f"{self.task_id}_cp_{len(self.checkpoints):04d}",
timestamp=datetime.now(),
state_snapshot=json.dumps(state),
intermediate_result=intermediate_result,
reflection=reflection,
next_steps=self.plan_next_steps(reflection)
)
# 存储为情景记忆
memory_content = self._format_checkpoint_memory(checkpoint)
memory = await self.ams.store_memory(
session_id=self.task_id,
content=memory_content,
memory_type=MemoryType.EPISODIC
)
self.checkpoints.append(checkpoint)
return checkpoint.checkpoint_id
async def resume_from_checkpoint(self,
checkpoint_id: Optional[str] = None) -> Dict:
"""
从检查点恢复任务
如果未指定checkpoint_id,默认从最后一个检查点恢复
"""
if checkpoint_id is None:
if not self.checkpoints:
return {"status": "start_fresh", "message": "No checkpoints found"}
checkpoint = self.checkpoints[-1]
else:
checkpoint = next(
(cp for cp in self.checkpoints if cp.checkpoint_id == checkpoint_id),
None
)
if checkpoint is None:
# 从历史记忆中检索
checkpoint = await self._retrieve_checkpoint(checkpoint_id)
return {
"status": "resumed",
"checkpoint": checkpoint,
"state": json.loads(checkpoint.state_snapshot),
"next_steps": checkpoint.next_steps
}
async def get_task_summary(self) -> str:
"""
生成任务摘要(用于上下文重建)
"""
if not self.checkpoints:
return "任务尚未开始"
summary_parts = [
f"任务 {self.task_id} 进度摘要:",
f"总检查点数:{len(self.checkpoints)}",
f"任务时长:{self.checkpoints[-1].timestamp - self.checkpoints[0].timestamp}",
f"\n关键进展:"
]
for i, cp in enumerate(self.checkpoints[:5]): # 最近5个
summary_parts.append(
f"{i+1}. [{cp.timestamp.strftime('%m-%d %H:%M')}] {cp.intermediate_result[:100]}..."
)
# 添加反思
if self.checkpoints:
summary_parts.append(f"\n最新反思:{self.checkpoints[-1].reflection}")
return "\n".join(summary_parts)
# 长程任务示例:多天数据分析任务
async def demo_long_term_analysis():
task_memory = LongTermTaskMemory(ams_service, "data_analysis_2024")
# Day 1: 数据收集
print("=== Day 1: 数据收集 ===")
await task_memory.create_checkpoint(
state={"phase": "collection", "sources": 5},
intermediate_result="已收集5个数据源,共计1.2TB原始数据",
reflection="数据质量良好,但需要补充第三方数据以提高覆盖率"
)
# Day 2: 数据清洗
print("=== Day 2: 数据清洗 ===")
await task_memory.create_checkpoint(
state={"phase": "cleaning", "quality_score": 0.85},
intermediate_result="完成数据清洗,质量评分0.85,数据量缩减至800GB",
reflection="部分数据存在缺失值,需要决定是插值还是删除"
)
# Day 3: 特征工程
print("=== Day 3: 特征工程 ===")
await task_memory.create_checkpoint(
state={"phase": "feature", "features": 156},
intermediate_result="完成156个特征构建,包括时序特征和交叉特征",
reflection="特征重要性分析显示top10特征,建议后续重点关注"
)
# 恢复任务上下文
print("\n=== 恢复任务上下文 ===")
summary = await task_memory.get_task_summary()
print(summary)
state = await task_memory.resume_from_checkpoint()
print(f"\n当前状态: {state['state']}")
print(f"下一步计划: {state['next_steps']}")
2.3 CCE VolcanoNext通智一体化调度引擎
CCE(Cloud Container Engine)VolcanoNext是华为云面向AI workloads的新一代调度引擎,其核心理念是**“通智融合”**——打通通用计算与智能计算的边界。
2.3.1 调度策略创新
# Python示例:VolcanoNext调度策略实现
from typing import List, Tuple, Dict
from dataclasses import dataclass
from enum import Enum
import numpy as np
class WorkloadType(Enum):
TRAINING = "training" # 训练任务
INFERENCE = "inference" # 推理任务
FINE_TUNING = "fine_tuning" # 微调任务
DATA_PROCESSING = "data" # 数据处理
@dataclass
class调度决策:
"""调度决策结果"""
pod_id: str
node_id: str
gpu_allocation: List[int] # GPU分配列表
priority_score: float
estimated_wait: float
class VolcanoScheduler:
"""
VolcanoNext智能调度器
核心调度策略:
1. Gang Scheduling:保证训练任务的All-or-Nothing
2. binpack:优先紧凑分配,减少碎片
3. DRFQ:按资源使用比例公平分配
4. 负载感知:考虑节点实时负载
"""
def __init__(self, cluster_state):
self.cluster = cluster_state
self.pending_queue: List[Dict] = []
def schedule(self, pod_request: Dict) -> 调度决策:
"""
调度入口
调度算法流程:
1. 预筛选:过滤不满足资源需求的节点
2. 评分:对候选节点进行多维度评分
3. 分配:选择得分最高的节点
"""
workload_type = WorkloadType(pod_request.get("workload_type"))
# 1. 预筛选
candidate_nodes = self._pre_filter(pod_request)
if not candidate_nodes:
# 无可用节点,加入等待队列
self.pending_queue.append(pod_request)
return None
# 2. 多维度评分
scores = []
for node in candidate_nodes:
score = self._calculate_score(node, pod_request, workload_type)
scores.append((node, score))
# 3. 选择最优节点
scores.sort(key=lambda x: x[1], reverse=True)
selected_node = scores[0][0]
# 4. 执行分配
return self._allocate(pod_request, selected_node, scores[0][1])
def _pre_filter(self, request: Dict) -> List[Dict]:
"""预筛选满足条件的节点"""
required_gpus = request.get("required_gpus", 0)
required_memory = request.get("required_memory", 0)
candidates = []
for node in self.cluster.nodes.values():
if (node.available_gpus >= required_gpus and
node.available_memory >= required_memory and
node.status == "healthy"):
candidates.append(node)
# Gang Scheduling检查(用于训练任务)
if request.get("workload_type") == "training":
# 检查是否能分配连续的GPU
candidates = [
n for n in candidates
if self._check_gpu_affinity(n, required_gpus)
]
return candidates
def _calculate_score(self, node: Dict, request: Dict,
workload_type: WorkloadType) -> float:
"""
多维度评分
评分维度:
- 资源利用率:优先分配到利用率低的节点(负载均衡)
- GPU亲和性:训练任务优先同Switch域的GPU
- 内存局部性:推理任务优先GPU-direct访问内存的节点
- 队列优先级:考虑等待时间
"""
weights = {
"utilization": 0.3,
"affinity": 0.25,
"locality": 0.2,
"fairness": 0.15,
"wait_time": 0.1
}
score = 0.0
# 资源利用率评分(越低越好,但要避免过度分散)
gpu_util = node.gpu_utilization
utilization_score = 1.0 - abs(gpu_util - 0.7) / 0.7 # 期望70%利用率
score += weights["utilization"] * utilization_score
# GPU亲和性评分
if workload_type == WorkloadType.TRAINING:
affinity_score = self._calculate_affinity_score(node, request)
score += weights["affinity"] * affinity_score
# 内存局部性评分
if workload_type == WorkloadType.INFERENCE:
locality_score = node.gpu_direct_memory_ratio
score += weights["locality"] * locality_score
# 公平性评分(DRFQ)
fairness_score = self._calculate_fairness_score(node, request)
score += weights["fairness"] * fairness_score
# 等待时间补偿
wait_time_score = min(request.get("wait_time", 0) / 300, 1.0) # 最多5分钟补偿
score += weights["wait_time"] * wait_time_score
return score
def _check_gpu_affinity(self, node: Dict, required: int) -> bool:
"""检查GPU亲和性(同Switch域)"""
# 简化实现:检查是否有连续的GPU块
available_gpus = node.available_gpu_ids
if len(available_gpus) < required:
return False
# 检查是否有连续的GPU
sorted_gpus = sorted(available_gpus)
for i in range(len(sorted_gpus) - required + 1):
if sorted_gpus[i + required - 1] - sorted_gpus[i] == required - 1:
return True
return False
def _allocate(self, request: Dict, node: Dict,
score: float) -> 调度决策:
"""执行资源分配"""
pod_id = request["pod_id"]
required_gpus = request.get("required_gpus", 0)
# 分配GPU
allocated_gpus = self._allocate_gpus(node, required_gpus)
# 更新节点状态
node.available_gpus -= required_gpus
node.available_memory -= request.get("required_memory", 0)
return 调度决策(
pod_id=pod_id,
node_id=node["node_id"],
gpu_allocation=allocated_gpus,
priority_score=score,
estimated_wait=0
)
# 调度效果对比演示
def demo_scheduling_comparison():
"""演示VolcanoNext vs 传统调度器的效果对比"""
print("=" * 60)
print("VolcanoNext 调度效果对比演示")
print("=" * 60)
# 模拟调度任务
tasks = [
{"pod_id": "train-1", "workload_type": "training", "required_gpus": 8, "priority": 1},
{"pod_id": "infer-1", "workload_type": "inference", "required_gpus": 1, "priority": 2},
{"pod_id": "train-2", "workload_type": "training", "required_gpus": 4, "priority": 1},
{"pod_id": "infer-2", "workload_type": "inference", "required_gpus": 2, "priority": 2},
{"pod_id": "tune-1", "workload_type": "fine_tuning", "required_gpus": 2, "priority": 1},
]
# 模拟集群状态
cluster = {
"nodes": {
f"node-{i}": {
"node_id": f"node-{i}",
"available_gpus": 8,
"available_memory": 640,
"gpu_utilization": 0.5,
"gpu_direct_memory_ratio": 0.9,
"status": "healthy",
"available_gpu_ids": list(range(8))
}
for i in range(4)
}
}
scheduler = VolcanoScheduler(cluster)
print("\n任务调度结果:")
for task in tasks:
decision = scheduler.schedule(task)
if decision:
print(f" {task['pod_id']:12} -> {decision.node_id} "
f"(GPUs: {decision.gpu_allocation}, Score: {decision.priority_score:.3f})")
else:
print(f" {task['pod_id']:12} -> [Pending]")
# 计算资源利用率
total_gpus = 32 # 4节点 * 8 GPU
used_gpus = sum(8 - node["available_gpus"] for node in cluster["nodes"].values())
utilization = used_gpus / total_gpus
print(f"\n集群资源利用率: {utilization:.1%}")
print(f"等待队列长度: {len(scheduler.pending_queue)}")
2.3.2 资源利用率提升30%+的奥秘
CCE VolcanoNext通过以下技术手段实现资源利用率30%+的提升:
- GPU分时复用:支持将单个GPU划分为多个逻辑分区,供多个推理任务共享
- 异构资源混部:CPU任务与GPU任务混合部署,提高整体利用率
- 预测性伸缩:基于历史负载预测,提前调整资源分配
- 拓扑感知调度:考虑NVLink/NVSwitch拓扑,优化GPU间通信
2.4 AgentSphere:安全自治的Agent运行环境
AgentSphere是华为云为Agent应用打造的安全隔离运行环境,其核心特性包括:
2.4.1 沙箱隔离架构
package agentsphere
import (
"context"
"fmt"
"time"
"github.com/google/uuid"
)
// AgentRuntime Agent运行时
type AgentRuntime struct {
runtimeID string
sandbox *Sandbox
memoryManager *MemoryManager
toolRegistry *ToolRegistry
securityPolicy *SecurityPolicy
monitor *RuntimeMonitor
state RuntimeState
}
// Sandbox 沙箱隔离
type Sandbox struct {
sandboxID string
namespace string
limits *ResourceLimits
networkMode NetworkMode
// 隔离机制
seccompProfile string
apparmorProfile string
capabilities []string
// 资源配额
cpuLimit float64
memoryLimit int64
gpuLimit float64
}
// SecurityPolicy 安全策略
type SecurityPolicy struct {
// 工具调用白名单
allowedTools map[string]bool
// 资源访问限制
maxMemoryAccess int64
maxNetworkCalls int
// 数据边界
allowDataExfiltration bool
allowedDataTypes []string
// 审计配置
auditLevel AuditLevel
auditLogEndpoint string
}
// AgentExecutionContext Agent执行上下文
type AgentExecutionContext struct {
ContextID string
AgentID string
Sandbox *Sandbox
// 记忆引用
workingMemory []string // 记忆ID列表
sessionID string
// 执行状态
state ExecutionState
startTime time.Time
// 安全上下文
securityCtx *SecurityContext
}
// CreateAgentRuntime 创建Agent运行时
func (s *AgentSphere) CreateAgentRuntime(ctx context.Context,
config *RuntimeConfig) (*AgentRuntime, error) {
runtimeID := uuid.New().String()
// 1. 创建沙箱
sandbox, err := s.createSandbox(ctx, config)
if err != nil {
return nil, fmt.Errorf("failed to create sandbox: %w", err)
}
// 2. 初始化安全策略
securityPolicy := s.createSecurityPolicy(config.SecurityLevel)
// 3. 创建运行时
runtime := &AgentRuntime{
runtimeID: runtimeID,
sandbox: sandbox,
memoryManager: NewMemoryManager(),
toolRegistry: s.globalToolRegistry.clone(),
securityPolicy: securityPolicy,
monitor: NewRuntimeMonitor(runtimeID),
state: StateInitializing,
}
// 4. 启动监控
go runtime.monitor.Start(ctx)
// 5. 执行健康检查
if err := runtime.healthCheck(ctx); err != nil {
runtime.Cleanup(ctx)
return nil, fmt.Errorf("health check failed: %w", err)
}
runtime.state = StateReady
return runtime, nil
}
// ExecuteTool 安全执行工具
func (r *AgentRuntime) ExecuteTool(ctx context.Context,
toolCall *ToolCall) (*ToolResult, error) {
// 1. 安全检查
if err := r.securityPolicy.ValidateToolCall(toolCall); err != nil {
r.monitor.RecordSecurityEvent("tool_rejected", toolCall.ToolName)
return nil, fmt.Errorf("security policy violation: %w", err)
}
// 2. 获取工具
tool := r.toolRegistry.Get(toolCall.ToolName)
if tool == nil {
return nil, fmt.Errorf("tool not found: %s", toolCall.ToolName)
}
// 3. 资源检查
if err := r.checkResources(toolCall); err != nil {
return nil, fmt.Errorf("resource limit exceeded: %w", err)
}
// 4. 执行工具(在沙箱内)
startTime := time.Now()
result, err := r.sandbox.Execute(ctx, tool, toolCall.Arguments)
duration := time.Since(startTime)
// 5. 记录监控数据
r.monitor.RecordToolExecution(toolCall.ToolName, duration, err == nil)
// 6. 返回结果
return result, err
}
// Cleanup 清理运行时
func (r *AgentRuntime) Cleanup(ctx context.Context) {
r.state = StateTerminating
// 1. 停止监控
r.monitor.Stop()
// 2. 清理沙箱
if r.sandbox != nil {
r.sandbox.Destroy(ctx)
}
// 3. 清理记忆引用
r.memoryManager.Cleanup()
r.state = StateTerminated
}
2.4.2 100ms级极速启动
AgentSphere采用以下技术实现100ms级启动:
- 容器镜像预热:常用工具和依赖预构建为轻量镜像
- 沙箱池化:预创建沙箱池,请求到达时直接分配
- 增量加载:按需加载Agent特定组件
- 内存快照:保存运行时快照,实现"热启动"
三、ModelArtsNext与智果AgentArts平台
3.1 ModelArtsNext四大核心能力
ModelArtsNext是华为云面向企业AI开发的新一代平台,提供四大核心能力:
| 能力 | 说明 | 技术实现 |
|---|---|---|
| RL强化学习服务 | 支持在线/离线RL训练 | PPO、SAC算法库;分布式训练框架 |
| 机密推理 | 隐私保护下的AI推理 | TEE可信执行环境;密态计算 |
| 模型路由 | 智能选择最适合的模型 | 多模型编排;成本-效果平衡 |
| 模型矩阵 | 多模型协同工作 | 模型ensemble;知识蒸馏 |
# Python示例:ModelArtsNext模型路由实现
from typing import List, Dict, Optional
from dataclasses import dataclass
@dataclass
class ModelInfo:
model_id: str
model_name: str
capability: List[str]
cost_per_1k_tokens: float
latency_p50: float
accuracy: float
max_tokens: int
class ModelRouter:
"""
ModelArtsNext智能模型路由器
路由策略:
1. 任务-模型匹配:根据任务类型匹配合适的模型
2. 成本优化:在满足效果的前提下选择最低成本模型
3. 负载均衡:考虑模型当前负载
4. 兜底策略:模型不可用时自动切换
"""
def __init__(self, model_catalog: List[ModelInfo]):
self.models = {m.model_id: m for m in model_catalog}
self.usage_stats = {m.model_id: {"requests": 0, "errors": 0} for m in model_catalog}
def route(self, request: Dict) -> str:
"""
智能路由
Args:
request: {
"task_type": "classification|generation|reasoning|...",
"complexity": "low|medium|high",
"max_latency": float, # 最大延迟容忍(ms)
"max_cost": float, # 最大成本容忍($)
"context_length": int
}
"""
task_type = request.get("task_type")
complexity = request.get("complexity")
max_latency = request.get("max_latency", float('inf'))
max_cost = request.get("max_cost", float('inf'))
context_length = request.get("context_length", 0)
# 1. 过滤可用模型
candidates = []
for model_id, model in self.models.items():
if not self._is_available(model_id):
continue
if context_length > model.max_tokens:
continue
if model.latency_p50 > max_latency:
continue
if model.cost_per_1k_tokens > max_cost:
continue
if task_type not in model.capability:
continue
candidates.append(model)
if not candidates:
# 兜底:返回默认模型
return self._get_default_model()
# 2. 计算综合得分
scored_models = []
for model in candidates:
score = self._calculate_score(model, request)
scored_models.append((model.model_id, score))
# 3. 选择最优模型
scored_models.sort(key=lambda x: x[1], reverse=True)
selected_model = scored_models[0][0]
# 4. 更新统计
self.usage_stats[selected_model]["requests"] += 1
return selected_model
def _calculate_score(self, model: ModelInfo, request: Dict) -> float:
"""计算模型综合得分"""
weights = {
"latency": 0.3,
"cost": 0.25,
"accuracy": 0.3,
"complexity_match": 0.15
}
# 延迟得分(越低越好)
latency_score = 1.0 - (model.latency_p50 / 1000) # 归一化
# 成本得分(越低越好)
cost_score = 1.0 - (model.cost_per_1k_tokens / 0.1)
# 准确率得分
accuracy_score = model.accuracy
# 复杂度匹配度
complexity = request.get("complexity")
complexity_score = self._complexity_match_score(model, complexity)
return (weights["latency"] * latency_score +
weights["cost"] * cost_score +
weights["accuracy"] * accuracy_score +
weights["complexity_match"] * complexity_score)
# 使用示例
def demo_model_routing():
# 模型目录
models = [
ModelInfo("pangu-pro", "盘古大模型Pro",
["generation", "reasoning"], 0.05, 50, 0.92, 32*1024),
ModelInfo("pangu-lite", "盘古大模型Lite",
["generation"], 0.01, 20, 0.85, 8*1024),
ModelInfo("ERNIE", "文心一言",
["generation", "classification"], 0.03, 40, 0.88, 16*1024),
]
router = ModelRouter(models)
# 路由请求
requests = [
{"task_type": "generation", "complexity": "low",
"max_latency": 30, "max_cost": 0.02},
{"task_type": "reasoning", "complexity": "high",
"max_latency": 100, "max_cost": 0.1},
]
print("ModelArtsNext 智能路由演示")
print("=" * 50)
for req in requests:
model_id = router.route(req)
print(f"Request: {req['task_type']} ({req['complexity']})")
print(f" -> Routed to: {model_id}")
print()
3.2 智果AgentArts企业级智能体平台
智果AgentArts是华为云面向企业客户的智能体开发与运营平台,提供:
- 生产级长程任务支持:支持多天、多步骤的复杂任务编排
- 企业级安全合规:满足金融、医疗等行业的合规要求
- 行业知识深度集成:预置行业知识库和最佳实践
# Python示例:智果AgentArts长程任务编排
from typing import List, Dict, Optional, Callable
from dataclasses import dataclass
from enum import Enum
import asyncio
class TaskState(Enum):
PENDING = "pending"
RUNNING = "running"
WAITING = "waiting" # 等待外部输入
COMPLETED = "completed"
FAILED = "failed"
PAUSED = "paused"
@dataclass
class TaskStep:
step_id: str
name: str
task_fn: Callable
depends_on: List[str] = None
timeout: float = 300.0
retry_count: int = 3
on_error: str = "fail" # fail, skip, pause
class LongTermTaskOrchestrator:
"""
长程任务编排器
支持特性:
1. DAG任务依赖管理
2. 断点续跑(基于检查点)
3. 条件分支与循环
4. 人工介入点
5. 任务监控与告警
"""
def __init__(self, task_id: str, memory_manager):
self.task_id = task_id
self.memory = memory_manager
self.steps: Dict[str, TaskStep] = {}
self.step_states: Dict[str, TaskState] = {}
self.step_results: Dict[str, any] = {}
self.checkpoints: List[Dict] = []
def register_step(self, step: TaskStep):
"""注册任务步骤"""
self.steps[step.step_id] = step
self.step_states[step.step_id] = TaskState.PENDING
async def execute(self, start_from_checkpoint: Optional[str] = None):
"""
执行长程任务
执行策略:
1. 拓扑排序确定执行顺序
2. 按依赖关系调度步骤
3. 支持并行执行独立步骤
4. 自动处理重试和错误恢复
"""
# 从检查点恢复
if start_from_checkpoint:
self._restore_from_checkpoint(start_from_checkpoint)
# 拓扑排序
execution_order = self._topological_sort()
print(f"[AgentArts] Starting task {self.task_id}")
print(f"[AgentArts] Total steps: {len(execution_order)}")
# 创建检查点
await self._create_checkpoint("task_start")
# 执行任务
for step_id in execution_order:
step = self.steps[step_id]
print(f"[AgentArts] Executing step: {step.name}")
try:
# 检查依赖是否完成
for dep_id in (step.depends_on or []):
if self.step_states[dep_id] != TaskState.COMPLETED:
raise RuntimeError(f"Dependency {dep_id} not completed")
# 执行步骤
result = await self._execute_step(step)
self.step_results[step_id] = result
self.step_states[step_id] = TaskState.COMPLETED
# 创建检查点
await self._create_checkpoint(f"step_{step_id}_completed")
except Exception as e:
print(f"[AgentArts] Step {step.name} failed: {e}")
if step.on_error == "fail":
self.step_states[step_id] = TaskState.FAILED
raise
elif step.on_error == "pause":
self.step_states[step_id] = TaskState.PAUSED
await self._handle_pause(step_id, e)
else: # skip
self.step_states[step_id] = TaskState.COMPLETED
print(f"[AgentArts] Task {self.task_id} completed")
await self._create_checkpoint("task_completed")
return self.step_results
async def _execute_step(self, step: TaskStep) -> any:
"""执行单个步骤(带重试)"""
for attempt in range(step.retry_count):
try:
# 执行任务函数
result = await asyncio.wait_for(
step.task_fn(self.step_results),
timeout=step.timeout
)
return result
except asyncio.TimeoutError:
print(f"[AgentArts] Step {step.step_id} timeout (attempt {attempt+1})")
if attempt == step.retry_count - 1:
raise
except Exception as e:
print(f"[AgentArts] Step {step.step_id} error: {e}")
if attempt == step.retry_count - 1:
raise
await asyncio.sleep(2 ** attempt) # 指数退避
raise RuntimeError(f"Step {step.step_id} failed after {step.retry_count} attempts")
async def _create_checkpoint(self, name: str):
"""创建检查点"""
checkpoint = {
"name": name,
"timestamp": asyncio.get_event_loop().time(),
"step_states": self.step_states.copy(),
"step_results": {k: str(v)[:100] for k, v in self.step_results.items()} # 截断
}
self.checkpoints.append(checkpoint)
# 存储到记忆系统
await self.memory.store(
f"checkpoint_{self.task_id}_{name}",
checkpoint
)
def _restore_from_checkpoint(self, checkpoint_name: str):
"""从检查点恢复"""
# 从记忆中获取检查点
checkpoint = self.memory.get(f"checkpoint_{self.task_id}_{checkpoint_name}")
if checkpoint:
self.step_states = checkpoint["step_states"]
print(f"[AgentArts] Restored from checkpoint: {checkpoint_name}")
# 示例:企业级数据分析长程任务
async def demo_enterprise_analytics():
"""
演示长程任务:企业级数据分析
任务流程:
1. 数据采集 -> 2. 数据清洗 -> 3. 特征工程 ->
4. 模型训练 -> 5. 模型评估 -> 6. 报告生成
"""
memory = LongTermTaskMemory(None, "enterprise_analytics")
orchestrator = LongTermTaskOrchestrator("analytics_task", memory)
# 注册任务步骤
orchestrator.register_step(TaskStep(
step_id="collect",
name="数据采集",
task_fn=lambda ctx: {"records": 1000000}
))
orchestrator.register_step(TaskStep(
step_id="clean",
name="数据清洗",
task_fn=lambda ctx: {"cleaned": ctx["collect"]["records"] * 0.85},
depends_on=["collect"]
))
orchestrator.register_step(TaskStep(
step_id="feature",
name="特征工程",
task_fn=lambda ctx: {"features": 156},
depends_on=["clean"]
))
orchestrator.register_step(TaskStep(
step_id="train",
name="模型训练",
task_fn=lambda ctx: {"model_score": 0.92},
depends_on=["feature"]
))
orchestrator.register_step(TaskStep(
step_id="evaluate",
name="模型评估",
task_fn=lambda ctx: {"auc": 0.91, "f1": 0.89},
depends_on=["train"]
))
orchestrator.register_step(TaskStep(
step_id="report",
name="报告生成",
task_fn=lambda ctx: {"report_url": "https://..."},
depends_on=["evaluate"]
))
# 执行任务
results = await orchestrator.execute()
print("\n任务执行结果:")
for step_id, result in results.items():
print(f" {step_id}: {result}")
# 运行演示
asyncio.run(demo_enterprise_analytics())
四、行业AI梦工厂:四大专区深度解析
华为云行业AI梦工厂针对不同行业提供了深度定制化的AI解决方案:
4.1 智慧医疗专区
核心能力:
- 医学影像智能分析(CT/MRI/X光)
- 药物研发辅助(分子生成、靶点预测)
- 临床决策支持(病历分析、诊断建议)
- 医疗知识图谱构建
技术亮点:
- 支持DICOM标准格式
- 多模态医学数据融合
- 隐私计算保护患者数据
4.2 具身智能专区
核心能力:
- 机器人感知与决策
- 仿真环境构建
- 技能学习与迁移
- 实时控制与规划
技术亮点:
- 物理仿真引擎集成
- 视觉-语言-动作多模态
- sim-to-real迁移学习
4.3 智能制造专区
核心能力:
- 质量检测与缺陷识别
- 预测性维护
- 工艺参数优化
- 供应链智能调度
技术亮点:
- 时序数据分析
- 边缘-云协同推理
- 数字孪生集成
4.4 科学计算专区
核心能力:
- 气候模拟与预测
- 材料科学计算
- 基因组学分析
- 天体物理仿真
技术亮点:
- 科学计算加速库
- 异构计算优化
- 大规模并行训练
五、百模千态生态合作计划
华为云百模千态生态合作计划旨在构建开放的AI模型生态:
5.1 生态伙伴类型
| 伙伴类型 | 合作内容 | 权益 |
|---|---|---|
| 模型伙伴 | 模型接入、联合优化 | 优先算力资源、联合营销 |
| 应用伙伴 | 行业解决方案 | 技术支持、市场渠道 |
| 基础设施伙伴 | 硬件优化、加速库 | 联合测试、品牌背书 |
| 数据伙伴 | 高质量数据集 | 数据交易分成 |
5.2 模型接入流程
# Python示例:模型接入标准化流程
class ModelIntegration:
"""
百模千态模型接入标准流程
接入要求:
1. 模型格式标准化(支持多种格式转换)
2. 接口标准化(统一的推理API)
3. 性能基准测试
4. 安全合规审查
"""
def __init__(self):
self.checklist = []
async def integrate_model(self, model_path: str,
model_type: str) -> Dict:
"""
模型接入流程
步骤:
1. 模型格式检测与转换
2. 推理接口标准化
3. 性能基准测试
4. 资源消耗评估
5. 安全扫描
6. 上线发布
"""
result = {
"status": "in_progress",
"steps": []
}
# Step 1: 格式检测
format_check = await self._check_model_format(model_path)
result["steps"].append(format_check)
# Step 2: 接口标准化
api_standard = await self._standardize_api(model_path, model_type)
result["steps"].append(api_standard)
# Step 3: 性能测试
benchmark = await self._run_benchmark(model_path)
result["steps"].append(benchmark)
# Step 4: 资源评估
resource = await self._assess_resources(model_path)
result["steps"].append(resource)
# Step 5: 安全扫描
security = await self._security_scan(model_path)
result["steps"].append(security)
# Step 6: 发布
if all(s["passed"] for s in result["steps"]):
deployment = await self._deploy_model(model_path)
result["status"] = "deployed"
result["deployment"] = deployment
else:
result["status"] = "failed"
result["issues"] = [s for s in result["steps"] if not s["passed"]]
return result
六、总结与展望
华为云Agentic Infra的发布,标志着企业级AI基础设施正式进入"智能体时代"。通过"四梁八柱"的架构体系,华为云为企业和开发者提供了从算力到应用的全栈AI能力:
核心价值:
- 极致性能:10万卡级集群、<10ms推理时延、200 EFLOPS总算力
- 超大规模记忆:PB级存储空间,支持天级长程任务
- 高效调度:资源利用率提升30%+,通智一体化融合
- 安全可信:沙箱隔离、极速启动、安全自治
- 开放生态:百模千态、行业AI梦工厂
未来展望:
随着Agentic Infra的持续演进,我们可以预见:
- 多Agent协同将成为主流范式
- 持续学习将使AI系统越来越智能
- 边缘智能将实现更低延迟的实时响应
- 安全可信将贯穿AI系统的每一个环节
华为云Agentic Infra不仅是一套技术架构,更是一种面向未来的AI发展理念。它为企业和开发者打开了通往AGI(通用人工智能)的大门,让我们共同期待这场智能革命的下一章。
参考资料:
- 华为云官方文档:https://support.huaweicloud.com/
- ModelArts Pro:https://www.huaweicloud.com/product/modelarts.html
- 华为云INSPIRE 2026大会资料