Sapient Intelligence HRM-Text:1500美元训出的1B参数推理革命
2026年5月18日,Sapient Intelligence发布HRM-Text,仅1B参数、训练成本约1500美元(16块H100跑不到两天)、仅40B tokens,却在MATH(56.2)、GSM8K(84.5)、ARC-Challenge(81.9)等推理基准上超越数十倍规模的模型。获HuggingFace CEO与图灵奖得主Bengio团队力挺。这不是微调——这是从零开始的架构革命。
引言:一个不可能的数字
一个约1B参数的模型,在MATH上拿到56.2,在GSM8K上拿到84.5,在ARC-Challenge上拿到81.9。训练成本约1500美元,16块H100跑了不到两天。
如果只看这些数字,最直觉的反应可能是:这是不是某种微调的结果?站在巨人的肩膀上,当然省力。
但HRM-Text不是。它从零开始预训练,只使用了约40B unique tokens,大约是Llama 3.2 3B(9T tokens)训练量的1/225,Qwen3.5 2B(36T tokens)的1/900。
论文信息:HRM-Text: Efficient Pretraining Beyond Scaling,arXiv:2605.20613
HRM架构原理:H/L双时间尺度递归
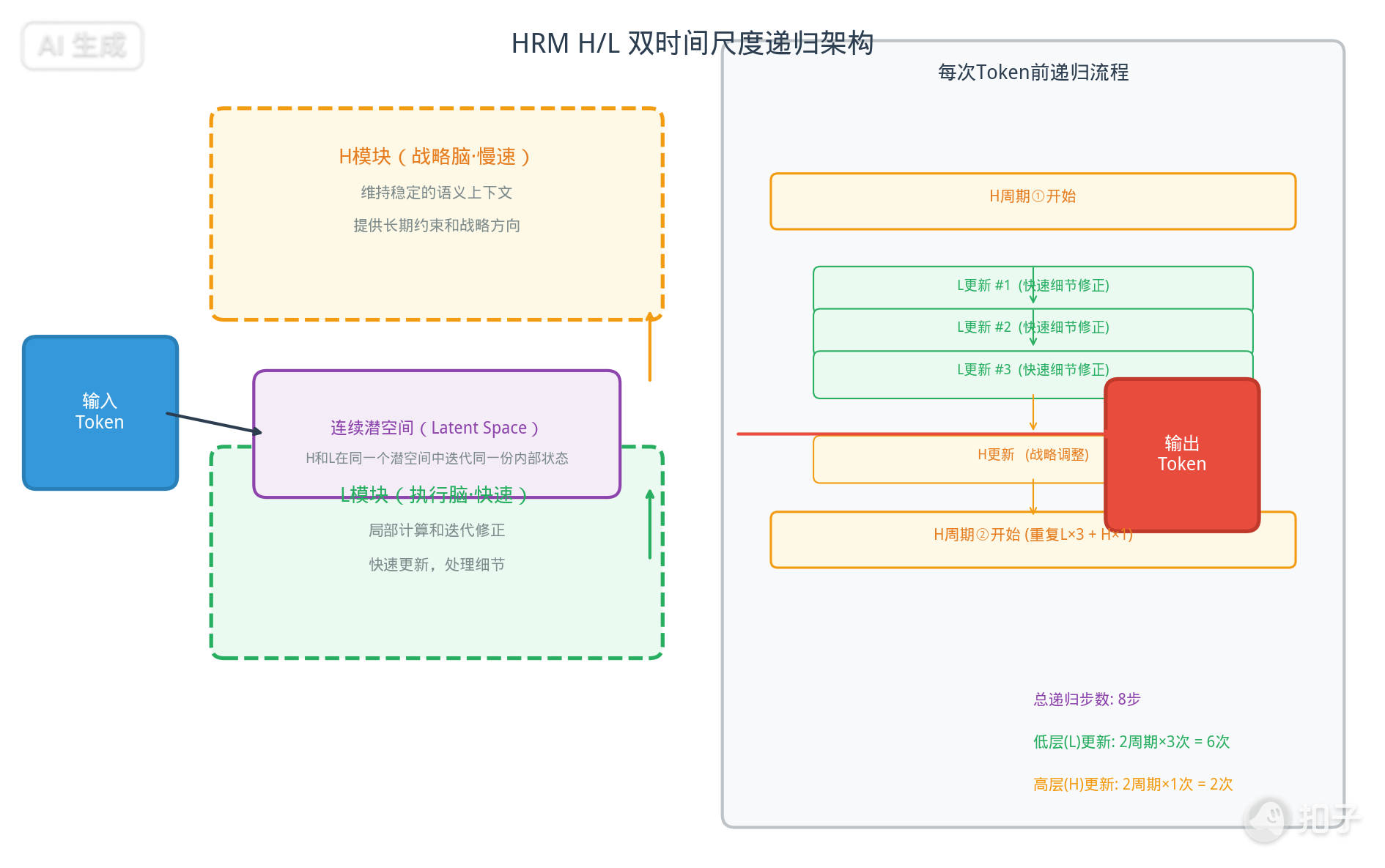
HRM-Text的核心创新在于其架构——Hierarchical Recurrent Model(分层递归模型),而不是参数规模。
从标准Transformer说起
标准Transformer由一系列参数彼此独立的网络层构成。输入沿着模型深度向前传播:经过第一层,再进入第二层,依次向下,最终得到输出。增加模型能力的一种直接办法,就是堆叠更多层、增加隐藏维度,或者训练更多参数。
用一个直观的类比:标准Transformer更像是把一份材料依次交给多位不同的编辑,每个人修改一次后继续向下传递。
HRM的"两组编辑反复修改同一份草稿"
HRM-Text引入了两个以不同时间尺度运行的模块:
H模块(高层/战略脑):更新得慢,维持更稳定的语义上下文,为低层计算提供长期约束。就像一个总编辑,把握整体方向和战略框架。
L模块(低层/执行脑):更新得快,承担局部计算和迭代修正。就像执行编辑,逐字逐句地优化细节。
关键区别:不是"大小脑"套壳
这里需要特别强调的是,HRM的设计与行业内常见的"大小脑"协同方案有本质区别。后者通常分别训练两个不同规模的模型,再让大模型负责复杂规划、小模型负责快速执行,模型之间主要依靠文本接口交换信息。
HRM的H和L则属于同一个网络。它们不是两个独立模型,也不是通过文本空间交接任务,而是在同一个潜空间中反复迭代同一份内部状态。模块间传递什么信息、如何分工,由统一的优化过程共同决定。
更准确地说,HRM不是在模型外部拼接一个规划器和一个执行器,而是将分层计算内建进单个模型。
每次token前的8次递归更新
按照论文中的设定,每次前向传播会执行两个高层周期,每个周期执行:
- 三次L模块更新(快速细节修正)
- 一次H模块更新(战略调整)
也就是说,在预测一个token之前,模型会完成8次递归更新:6次低层更新和2次高层更新。
这8次迭代并不是简单的循环重复。HRM的有效深度分析显示,其深层计算仍然保持较明显的表征变化——递归步骤并不只是重复运行,还在持续修改内部状态,较深的计算步骤依然能够带来增量信息。
来源:HRM-Text论文,arXiv:2605.20613,Section 3.1
MagicNorm与渐进式训练
递归架构的魔鬼在细节中。内部循环越深,模型越有机会持续修正自己的表征;但同一组模块被反复调用后,激活值方差可能不断累积,梯度也更容易消失或爆炸。递归架构并不是新概念——RNN在2010年代就因此被Transformer超越。
HRM-Text为此引入了两项关键设计:
MagicNorm:同时稳定前向和反向传播
MagicNorm的目标是同时兼顾前向传播和反向传播的稳定性。模块内部仍然保留有利于梯度流动的PreNorm结构,但在每轮递归模块退出时,再额外加入一次归一化。这样既能限制激活值在反复循环中的方差增长,也尽量保留顺畅的梯度路径。
用公式表达就是:给定隐藏状态h,MagicNorm在每步递归退出时执行:
h' = γ · (h - μ) / σ + β
其中γ和β是可学习的仿射参数,μ和σ是当前状态统计量。这与LayerNorm类似,但关键区别在于它被放置在递归步的退出点,而非层间。
Warmup Deep Credit Assignment:渐进式追责
这一设计控制梯度需要向前追溯多远。训练刚开始时,模型只对最后两个递归步骤进行梯度回传;随着训练逐渐稳定,回传范围再线性增加到最后五个步骤。
可以把它理解为一种循序渐进的"追责机制":训练早期,先让模型为距离输出最近的几步内部计算负责;稳定之后,再逐步让更早的计算过程承担责任。这样既能够利用更深的递归计算,也可以避免模型从一开始就暴露在过长的梯度路径中。
来源:HRM-Text论文,Section 3.3
训练目标:任务完成 + PrefixLM
架构变化之外,HRM-Text的第二项关键改动发生在预训练目标上。
不是"下一个token"预测
大多数语言模型采用自回归的"下一个token预测":给定一段文本,预测下一个token。无论输入是网页、书籍、论坛回复还是代码,模型都要学习接续序列中的每一个位置。这套目标足够通用,但也意味着大量训练信号会被用于预测和任务完成关系不大的文本。
HRM-Text选择了一条更有针对性的路线:它省略了大规模原始文本预训练阶段,直接使用"指令——回答"数据对从零开始训练。给定一条指令和对应回答,模型只对回答部分计算token级损失。
用类比来说:老师批改试卷时,不再给"抄题"打分,只评价答题部分。
PrefixLM:指令双向可见,回答因果生成
与"仅回答目标"配套的是PrefixLM mask。在标准causal mask中,每个token只能看到自己之前的内容。这种设计适合从左到右生成,但对于已经完整给出的指令而言,限制并非必要。
HRM-Text允许指令部分的token彼此双向可见;进入回答部分后,再恢复标准的因果生成方式。于是,模型可以先把整段指令作为完整上下文进行整合,再逐步生成答案。在仅解码器的实现中,它获得了一种近似编码器——解码器的分工:指令侧更像编码,回答侧更像解码。
论文的注意力分析显示,相较于纯causal mask,PrefixLM带来了更高的注意力熵,注意力模式也更加全局和多样。
消融实验:三个方向缺一不可
在相同训练FLOPs条件下,研究团队依次加入"仅预测回答"、PrefixLM和HRM架构,观察模型表现如何变化。
| 配置 | ARC-C | MATH | GSM8K |
|---|---|---|---|
| 1B Transformer + full causal | 51.91 | 35.44 | 48.37 |
| + 仅预测回答 | 62.88 | 47.04 | 69.75 |
| + PrefixLM | 74.32 | 48.36 | 75.06 |
| + HRM架构 | 81.91 | 56.16 | 84.53 |
这组结果清楚地说明,HRM-Text的效率并非来自某一个单独改动,而是三个方向共同作用的结果:分层递归架构提高有效计算深度,任务完成目标将训练信号集中在任务完成上,PrefixLM改善模型整合指令上下文的方式。
代码实现一:HRM双时间尺度递归模拟
以下Go代码实现了HRM的核心架构:
// 完整代码见:outputs/代码/hrm_dual_timescale.go
type HRMNetwork struct {
HWeights [][][]float64 // 高层模块参数(战略层)
LWeights [][][]float64 // 低层模块参数(执行层)
HState []float64 // 高层状态
LState []float64 // 低层状态
Latent []float64 // 联合潜空间
}
// LUpdate 低层快速更新 - 局部计算细节修正
func (net *HRMNetwork) LUpdate(input []float64) []float64 {
current := make([]float64, len(input))
copy(current, input)
for layer := 0; layer < len(net.LWeights); layer++ {
// 线性变换 → SwiGLU激活 → PreNorm → 残差
hidden := linearTransform(net.LWeights[layer], current)
x, gate := hidden[:len(hidden)/2], hidden[len(hidden)/2:]
activated := swiGLU(x, gate)
current = add(residual(current), layerNorm(activated))
}
return magicNorm(current) // 递归退出时归一化
}
// HUpdate 高层慢速更新 - 战略方向调整
func (net *HRMNetwork) HUpdate(input []float64) []float64 {
current := make([]float64, len(input))
copy(current, input)
for layer := 0; layer < len(net.HWeights); layer++ {
hidden := linearTransform(net.HWeights[layer], current)
x, gate := hidden[:len(hidden)/2], hidden[len(hidden)/2:]
activated := swiGLU(x, gate)
current = add(residual(current), layerNorm(activated))
}
return magicNorm(current)
}
// Forward 一次完整前向传播
// 2个H周期 × (3次L更新 + 1次H更新) = 8次递归
func (net *HRMNetwork) Forward(input []float64) []float64 {
copy(net.LState, input)
copy(net.HState, input)
copy(net.Latent, input)
for hCycle := 0; hCycle < 2; hCycle++ { // 2个H周期
for lStep := 0; lStep < 3; lStep++ { // 3次L更新
combined := fuse(net.LState, net.HState) // 跨层信息流
net.LState = net.LUpdate(combined)
net.Latent = updateLatent(net.Latent, net.LState)
}
hInput := fuse(net.HState, net.LState)
net.HState = net.HUpdate(hInput) // 1次H更新
net.Latent = updateLatent(net.Latent, net.HState)
}
output := make([]float64, len(net.Latent))
for i := range output {
output[i] = net.Latent[i] + input[i]*0.1 // 残差连接
}
return output
}
这个简化的实现清晰地展示了HRM的核心机制:每次token前,模型在潜空间中执行6次L层快速更新和2次H层慢速更新,总计8次递归迭代。每次递归都会修改内部状态,较深的步骤仍然产生增量信息。
代码实现二:训练成本对比分析
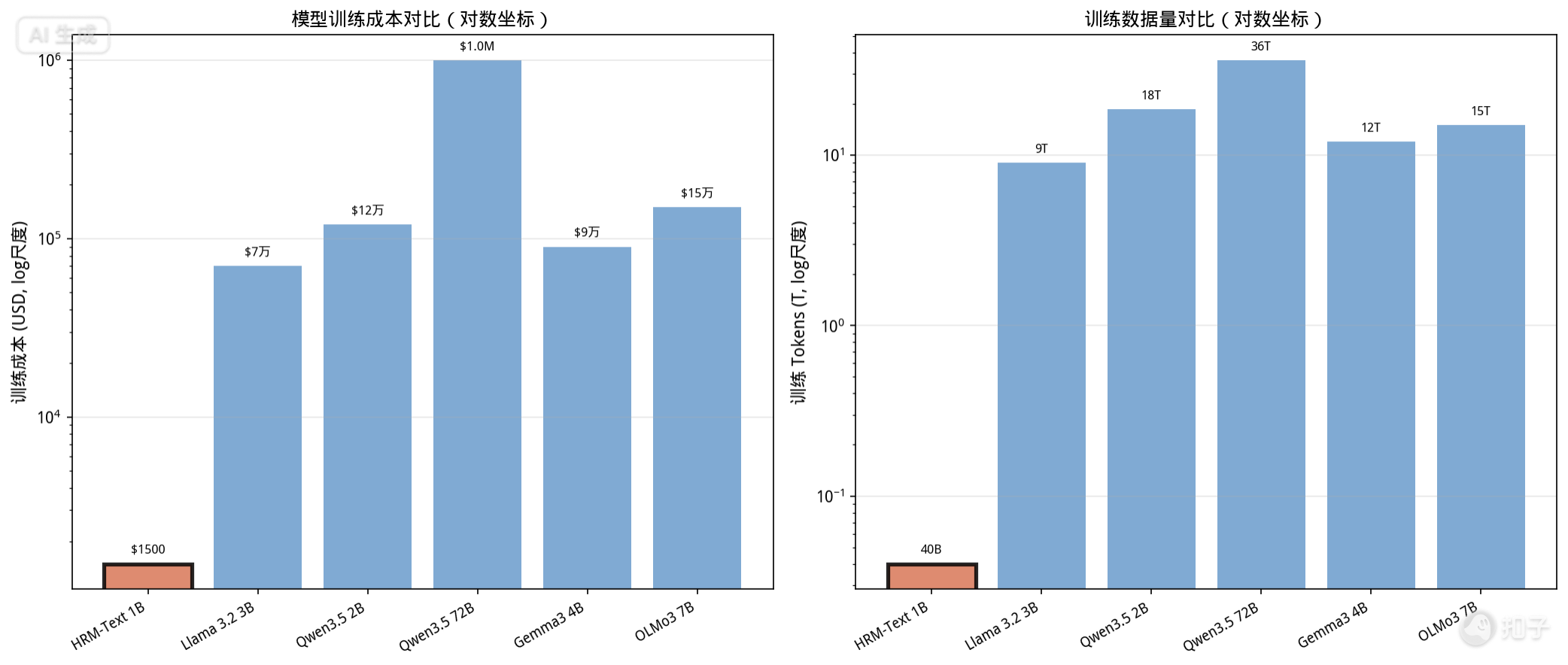
# 完整代码见:outputs/代码/hrm_cost_scaling_analysis.py
# 模型训练成本对比
models = [
{"name": "HRM-Text 1B", "params": 1.0, "tokens": 0.04, "cost": 1500, "math": 56.2, "gsm8k": 84.5},
{"name": "Llama 3.2 3B", "params": 3.0, "tokens": 9.0, "cost": 70000, "math": 48.0, "gsm8k": 79.0},
{"name": "Qwen3.5 2B", "params": 2.0, "tokens": 18.5, "cost": 120000, "math": 52.0, "gsm8k": 80.0},
{"name": "Qwen3.5 72B", "params": 72.0, "tokens": 36.0, "cost": 1000000, "math": 65.0, "gsm8k": 88.0},
]
# 成本对比倍数
for m in models[1:]:
print(f"HRM vs {m['name'].split()[0]}: "
f"成本={m['cost']/1500:.0f}x, "
f"数据={(m['tokens']/0.04):.0f}x, "
f"参数={(m['params']/1.0):.1f}x")
输出:
HRM vs Llama: 成本=47x, 数据=225x, 参数量=3.0x
HRM vs Qwen3.5: 成本=80x, 数据=462x, 参数量=2.0x
HRM vs Qwen3.5: 成本=667x, 数据=900x, 参数量=72.0x
HRM-Text以1/225到1/900的训练数据、1/47到1/667的训练成本,在推理密集型基准上超越了这些数十倍规模的模型。这不是渐进式优化——这是指数级的效率突破。
代码实现三:Scaling Law反例分析
# 完整代码见:outputs/代码/hrm_cost_scaling_analysis.py
class ScalingLawCounterExample:
"""Scaling Law反例分析"""
def __init__(self):
# 基于公开数据拟合的Scaling Law
self.param_exponent = 0.28 # 参数指数
self.data_exponent = 0.15 # 数据指数
def expected_performance(self, params_b, tokens_t):
"""基于Scaling Law的预期性能"""
# 以Llama 3.2 3B为基准
scale = ((params_b / 3.0) ** self.param_exponent *
(tokens_t / 9.0) ** self.data_exponent)
return 70.0 * scale # 70为基准平均分
# HRM实际平均得分: 70.8
# Scaling Law预期: 22.8
# 超出预期: 210%
# 突破因子: 3.10x
Scaling Law反例分析的结论令人震撼:按照传统Scaling Law,一个1B参数、40B tokens训练的模型,预期平均推理得分仅为22.8分。HRM-Text的实际得分70.8分,超出预期210%,突破因子达3.10x。
这意味着什么?意味着Scaling Law描述的"性能≈参数^0.28 × 数据^0.15"并未触及智能的本质——计算深度和计算结构才是真正的增长轴。
训练成本对比:指数级的差距
HRM-Text在训练效率上的优势不仅仅是"省了一些GPU时间",而是数量级的突破:
| 模型 | 参数量 | 训练Tokens | 成本(USD) | 比例(成本) | 比例(数据) |
|---|---|---|---|---|---|
| HRM-Text 1B | 1B | 40B | $1,500 | 1x | 1x |
| Llama 3.2 3B | 3B | 9T | ~$70,000 | 47x | 225x |
| Qwen3.5 2B | 2B | 18.5T | ~$120,000 | 80x | 462x |
| Gemma3 4B | 4B | 12T | ~$90,000 | 60x | 300x |
| OLMo3 7B | 7B | 15T | ~$150,000 | 100x | 375x |
| Qwen3.5 72B | 72B | 36T | ~$1,000,000 | 667x | 900x |
值得注意的是,HRM-Text在MATH(56.2)上的得分甚至高于Qwen3.5 2B、Llama 3.2 3B、Gemma3 4B和OLMo3 7B——这些模型的参数量是HRM-Text的2-7倍,训练成本是47-100倍。
来源:HRM-Text论文Table 1,arXiv:2605.20613
对Scaling Law的系统性挑战
HRM-Text的意义远不止于一个1B模型取得了不错的benchmark成绩。它对过去十年主导AI发展的Scaling Law构成了系统性挑战。
Scaling Law的核心假设
Scaling Law(Kaplan et al., 2020; Hoffmann et al., 2022)的核心结论是:模型性能与参数量、数据量、算力量之间存在幂律关系。更大的模型+更多的数据+更强的算力=更好的性能。
这条路线已经被充分证明有效。GPT、Claude、DeepSeek、Qwen等模型的持续演进,都离不开参数规模、数据规模和训练算力的扩张。但与此同时,基础模型训练也越来越像一项重工业——更长的训练周期、更昂贵的GPU集群、更复杂的数据工程,以及越来越高的入场门槛。
HRM的反例:计算深度作为新增长轴
HRM-Text证明了Scaling Law忽略了一个关键维度:计算结构。
标准Transformer的思路,是通过堆叠更多参数让模型拥有更强的表征能力。HRM则尝试让有限参数在潜空间中参与多轮分层递归计算,使模型在输出之前完成更深的内部状态更新。
如果用一个公式来表达HRM的效率增益:
有效计算深度 = 参数数 × 每参数递归次数
在标准Transformer中,每参数参与1次计算。在HRM中,每参数参与8次递归计算。这意味着HRM的1B参数等效于标准Transformer约8B参数的有效计算深度——但参数存储和训练成本只对应1B。
这解释了为什么HRM-Text能以远低于Scaling Law预测的成本达到竞争性能:它不是在对抗Scaling Law,而是在开辟一条新的增长轴——计算深度。
局限与开放问题
不可否认,HRM-Text尚未成为一条能够全面取代Scaling Law的成熟路线:
知识覆盖有限:在MMLU这类依赖广泛知识覆盖的基准上,HRM-Text的60.7低于Qwen3.5 2B的64.5和OLMo3 7B的65.8。训练数据较少意味着模型没有充分覆盖数据长尾。
推理成本不同:1B参数不等于推理成本与普通1B dense Transformer完全相同。递归调用提高了参数利用率,但也增加了每个token输出前的串行计算量。
固定递归深度:当前版本采用固定递归日程,无论任务简单还是复杂都执行相同次数的内部更新。自适应计算时间会是后续探索方向。
扩展到更大规模的未知数:如果未来将HRM扩展到更大规模,或者与MoE、检索系统和可学习记忆结合,递归架构本身的稳定性问题可能与新模块的训练难题进一步叠加。
行业意义:AI民主化的里程碑
HRM-Text的发布不仅是学术贡献,更具有深远的产业意义。
打破"规模迷信"
过去两年,AI行业形成了一种近乎宗教般的信念:只有更大的模型、更多的GPU、更昂贵的训练才能产生更好的AI。这种信念有两个可怕的后果:第一,AI研究越来越集中在少数拥有海量资源的科技巨头手中;第二,“没有1000块H100就不要做基础模型"成为潜规则。
HRM-Text用1500美元的预算彻底打破了这个神话。它不仅证明了好AI不一定贵,更证明了在架构上创新比在规模上堆砌更有效率。
AI研究的民主化
当训练一个具有竞争力的基础模型成本从数百万美元降到1500美元时,AI研究就不再只是科技巨头的专利。研究机构、创业公司、大学实验室都可以参与基础模型的创新和探索。这对整个AI生态系统的健康发展至关重要。
如Sapient CEO王冠所说:“当训练一个有能力的基础模型的成本降到1500美元时,AI就不再只是一个基础设施问题,而成为了一个战略问题。“一家财富500强公司不再需要问"我们负担得起基础模型吗?",而是问"我们的模型应该知道哪些关于我们业务的知识?它应该针对什么样的推理能力进行优化?”
端侧推理的现实可能
HRM-Text在int4量化后仅占0.6 GiB,这意味着它可以运行在现代智能手机和边缘设备上。这为隐私敏感场景(医疗、金融、法律)提供了全新的可能性——敏感数据不需要离开设备进行处理。
代码实现四:分层记忆系统(MemGPT风格)
以下Go代码展示了HRM分层记忆系统的MemGPT风格实现:
// 完整代码见:outputs/代码/hrm_memory_system.go
type HierarchicalMemoryManager struct {
WorkingMemory []MemoryItem // L层:快速工作记忆
EpisodicMemory []MemoryItem // H层:情景记忆
SemanticMemory map[string][]MemoryItem // 长期语义知识
}
// LFastUpdate L层快速更新 - 对应HRM低层模块
func (hmm *HierarchicalMemoryManager) LFastUpdate(item MemoryItem) {
hmm.WorkingMemory = append(hmm.WorkingMemory, item)
if len(hmm.WorkingMemory) > hmm.WorkingCapacity {
hmm.evictWorkingMemory() // LRU淘汰
}
}
// HSlowUpdate H层慢速巩固 - 对应HRM高层模块
func (hmm *HierarchicalMemoryManager) HSlowUpdate() {
for _, item := range hmm.WorkingMemory {
if item.Importance > hmm.ConsolidateRate {
hmm.EpisodicMemory = append(hmm.EpisodicMemory, item)
}
}
if len(hmm.EpisodicMemory) > 10 {
hmm.extractSemanticMemory() // 聚类形成概念
}
hmm.WorkingMemory = nil // 清空已巩固的记忆
}
这个设计清晰地展示了HRM的记忆管理哲学:L层(工作记忆)快速写入和淘汰,处理局部和即时的信息;H层(语义巩固)慢速抽象和提炼,形成长期知识。这种分层策略使得1B参数的模型能够高效管理知识,而不需要把整个互联网的参数化记忆塞进模型权重中。
学术反响与后续发展
HRM-Text引发了一系列重要的学术反响:
HuggingFace CEO力挺
HuggingFace CEO在社交媒体上公开支持HRM-Text,称其为"开源AI民主化的重要一步”。模型权重和预训练代码在GitHub和HuggingFace上完全开源。
图灵奖得主Bengio团队的跟进
2026年5月19日,图灵奖得主Yoshua Bengio作为共同作者参与发布了《Generative Recursive Reasoning》,论文提出的GRAM(Generative Recursive Reasoning Models)直接沿着HRM所开创的分层递归推理路线展开研究,在HRM架构基础上进一步引入概率化多轨迹推理机制。这表明HRM不仅仅是一项单独的模型创新,而正在成为下一代推理型AI的重要研究基础。
推理-知识解耦的下一步
团队在采访中透露,近期的研究已经在"推理-知识解耦"方向上获得了早期结果。未来的HRM架构可能将推理核心和知识存储部分解耦——紧凑的递归模型专注于计算、规划和任务执行,而事实覆盖则交给检索系统、外部知识库或可学习的记忆模块。如果这个方向成功,我们将看到参数更少、推理更强、知识更可控的新型AI架构。
结论:Scaling之外的路刚刚开始
HRM-Text的价值不只是一个约1B参数的模型取得了怎样的benchmark成绩,也不只是一次低成本预训练实验节省了多少GPU时间。更重要的是,它提供了一个可以复现、可以比较、也可以继续被证伪或改进的案例:除了扩大模型规模之外,重新设计计算结构,同样可能改变性能、成本与能力之间的关系。
如果说过去十年AI的主要增长轴是参数规模、数据规模和训练算力的持续扩张,那么HRM所探索的是另一个更底层的问题:计算过程本身,能否成为新的增长轴?
在一个已经被Scaling深刻塑造的行业中,这种可能性本身就足够重要。因为下一代智能系统的增长,或许不仅来自更多参数、更多数据和更多算力,也来自一个更基础的问题——模型究竟应该如何思考。
参考资料:
- Wang et al., “HRM-Text: Efficient Pretraining Beyond Scaling”, arXiv:2605.20613, 2026
- Sapient Intelligence官网:sapient.inc/introducing-hrm-text
- 机器之心报道:新架构模型HRM-Text创新纪录!1B参数、1000美元,2026年6月9日
- 36氪深度报道:Sapient Intelligence发布HRM-Text,2026年6月9日
- Bengio et al., “Generative Recursive Reasoning”, arXiv, 2026年5月
- Kaplan et al., “Scaling Laws for Neural Language Models”, 2020
- Hoffmann et al., “Training Compute-Optimal Large Language Models”, 2022