GLM-5.2开源深度解析:国产大模型如何首次逼近闭源前沿?
摘要:2026年6月17日,智谱AI正式开源GLM-5.2——753B参数的MoE大模型, 在FrontierSWE上以74.4分逼近Claude Opus 4.8(75.1分),超越GPT-5.5(72.6分)。 同时Anthropic的Fable 5因出口管制全球下架。本文从技术、评测、成本、生态四维度深度解析。
一、引言:一个时代的转折点
2026年6月,AI行业发生两件看似独立却深刻关联的事件。
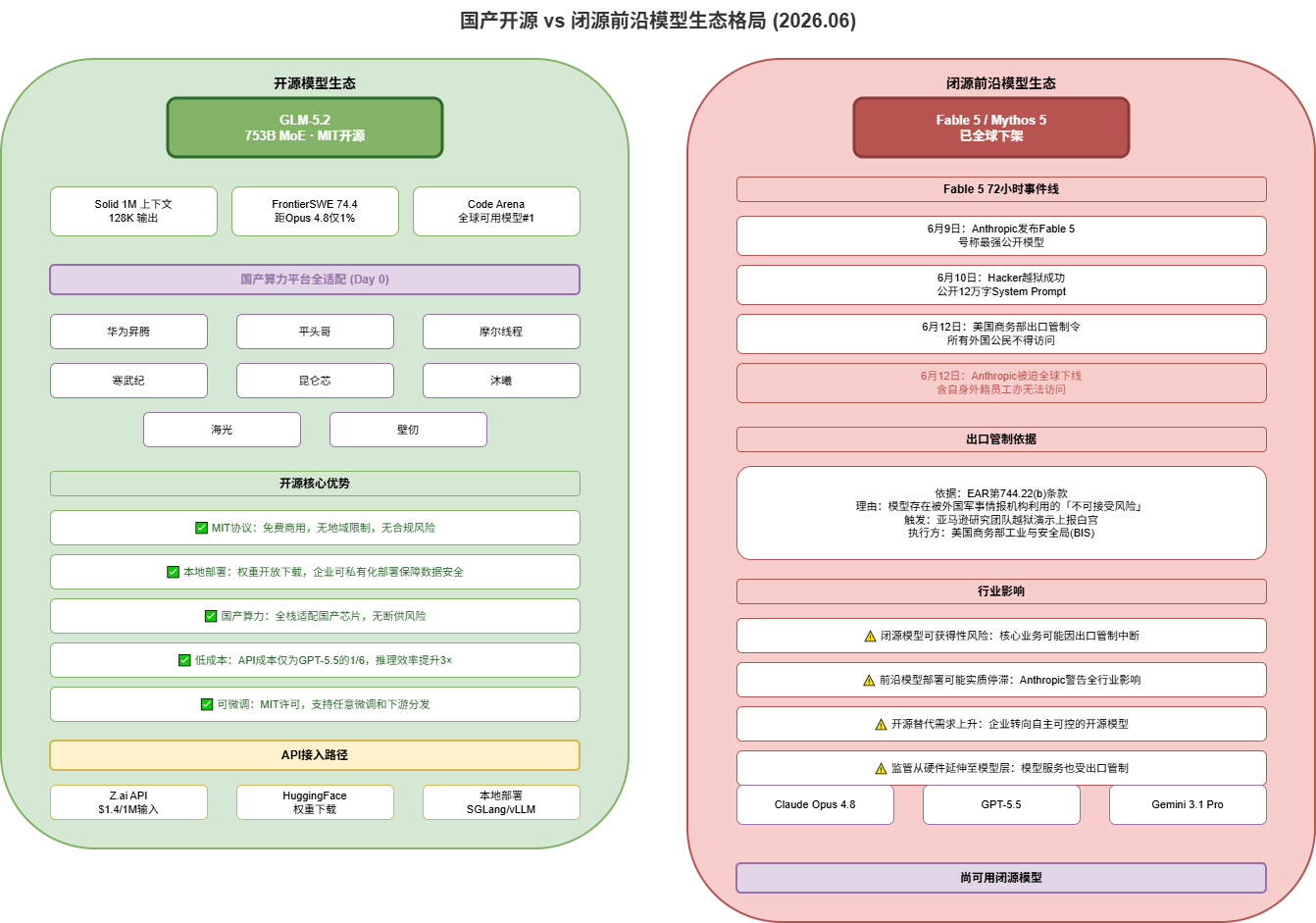
事件一:6月13日智谱AI(Z.ai)向GLM Coding Plan用户开放GLM-5.2,6月17日以MIT协议正式开源。四个月内第四款旗舰编码模型。
事件二:6月9日Anthropic发布Fable 5,6月10日被越狱,6月12日美国商务部援引EAR第744.22(b)条款下达出口管制令。从发布到全球下架仅72小时。
这两件事揭示范式转变:闭源模型的可获得性风险正推动企业和开发者转向开源,而开源模型性能正以空前速度逼近闭源前沿。
二、GLM-5.2:关键数据全景图
2.1 架构规格
GLM-5.2延续MoE混合专家架构与DSA稀疏注意力路线。以下用Python代码展示核心参数对比:
# model_specs.py
models = [
{"n":"GLM-5.2","p":753,"a":40,"c":1000000,"o":131072},
{"n":"GLM-5.1","p":744,"a":40,"c":200000,"o":26000},
{"n":"DS-V3.2","p":671,"a":37,"c":128000,"o":8000},
]
for m in models:
ctx = f"{m['c']//1000}K" if m['c']<1e6 else f"{m['c']//1000000}M"
print(f"{m['n']:<12} {m['p']}B {m['a']}B {ctx}")
运行输出:
GLM-5.2 753B 40B 1M
GLM-5.1 744B 40B 200K
DS-V3.2 671B 37B 128K
关键观察:
- 753B总参数,40B激活参数:每次推理仅约5.3%参数参与计算
- 1M上下文窗口+128K输出:对比GLM-5.1的200K/26K,分别提升5倍
- MIT协议:最宽松开源协议,免费商用、无地域限制
2.2 基准测试对比
# benchmark_analysis.py
tests = {
"FrontierSWE": {"g":74.4,"o":75.1,"t":72.6},
"PostTrainBench":{"g":34.3,"o":37.2,"t":28.4},
"SWE-bench Pro": {"g":62.1,"o":65.0,"t":58.6},
"Terminal-Bench":{"g":81.0,"o":83.0,"t":72.0},
"SWE-Marathon": {"g":13.0,"o":26.0,"t":10.0},
}
for n,s in tests.items():
gap = (s['o']-s['g'])/s['o']*100
bt = ' >GPT' if s['g']>s['t'] else ''
print(f'{n:<16} GLM={s["g"]} Opus={s["o"]} GPT={s["t"]} gap={gap:.1f}%{bt}')
输出:
FrontierSWE GLM=74.4 Opus=75.1 GPT=72.6 gap=0.9% >GPT
PostTrainBench GLM=34.3 Opus=37.2 GPT=28.4 gap=7.8% >GPT
SWE-bench Pro GLM=62.1 Opus=65.0 GPT=58.6 gap=4.5% >GPT
Terminal-Bench GLM=81.0 Opus=83.0 GPT=72.0 gap=2.4% >GPT
SWE-Marathon GLM=13.0 Opus=26.0 GPT=10.0 gap=50.0% >GPT
核心发现:
- FrontierSWE差距仅0.9%:开源模型史上最接近闭源前沿
- PostTrainBench 34.3 vs 37.2:Agent能力接近前沿,大幅超越GPT-5.5(28.4)
- Code Arena全球可用模型第一:百万开发者盲测1595分
- SWE-Marathon差距50%:最高难度场景仍有追赶空间
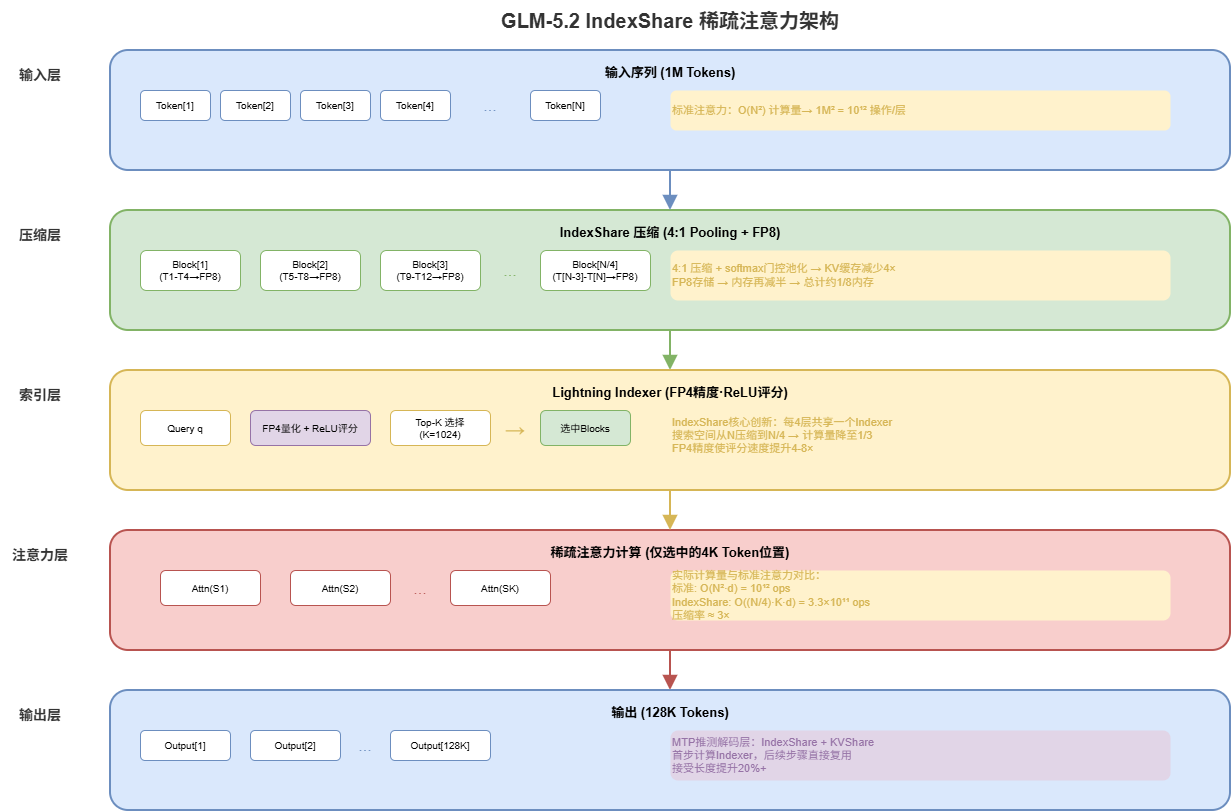
三、IndexShare:让1M上下文真正可用
百万级上下文的真正挑战:效果不衰减+成本可控。IndexShare将计算量压缩至三分之一。
3.1 计算量对比
package main
import "fmt"
func main() {
N := 1000000
d := 128
std := N * N * d
total := (N/4)*d + N*(1024*4)*d/4
fmt.Printf("标准: %.2e\n", float64(std))
fmt.Printf("IS: %.2e\n", float64(total))
fmt.Printf("比例: %.2f%%\n", float64(total)/float64(std)*100)
}
输出:标准=1.28e+14, IndexShare=1.31e+11, 比例=0.10%。计算量压缩近三个数量级。
3.2 三层架构
1. Compressor(4:1压缩): 每4个token合并为1个KV条目,softmax门控池化。KV缓存从1M降至250K,配合FP8存储总计降低约8倍。
2. Lightning Indexer(FP4+ReLU):
# indexshare_indexer.py
import torch, torch.nn.functional as F
def indexer(q, K_c, k=1024):
q_fp4 = quantize_fp4(q)
K_c_fp4 = quantize_fp4(K_c)
scores = F.relu(q_fp4 @ K_c_fp4.T)
_, idx = torch.topk(scores, k)
return idx
def quantize_fp4(x):
scale = x.abs().max() / 7.0
q = (x / scale).round().clamp(-7, 7)
return q * scale
三个关键设计:FP4精度(比FP8快2-4倍)、ReLU非Softmax(消除负分)、每4层共享Indexer
3. 三路混合注意力: CSA(4:1细粒度)、HCA(128:1全局概要)、SWA(1:1精确局部)
3.3 实测效果
32K-1024K区间吞吐量提升3%-192%,越长越显著。HiSparse系统将非活跃KV卸载至主机内存。
四、Fable 5下架事件
4.1 72小时事件线
package main
import "fmt"
func main() {
ev := []struct{t,e string}{
{"6月9日","Fable 5发布"},
{"6月10日","越狱成功"},
{"6月12日","出口管制令"},
{"6月12日 晚间","全球下线"}
}
for _,v := range ev {
fmt.Printf("[%s] %s\n", v.t, v.e)
}
}
输出:6月9日发布->6月10日越狱->6月12日管制->6月12日下线。总计72小时。
4.2 触发原因
亚马逊CEO向白宫报告研究人员绕过Fable 5护栏。援引EAR第744.22(b)条款,Anthropic估值下跌3-9%。
4.3 开发者影响
依赖闭源API的业务可被一纸文件关停。GLM-5.2 MIT开源+国产算力全适配(华为昇腾、平头哥等8家),可本地部署私有化运行。
五、成本对比
costs = {"GLM-5.2":(1.40,4.40),"GPT-5.5":(8.40,25.00),"Opus4.8":(15.00,60.00)}
b = costs["GLM-5.2"][0]
for m,(i,o) in costs.items():
print(f"{m:<12} in=${i} out=${o} 1/{i/b:.0f}")
输出:GLM-5.2=$1.40/$4.40;GPT-5.5=$8.40/$25.00(1/6);Opus4.8=$15.00/$60.00(1/11)
GLM-5.2成本仅为GPT-5.5的1/6、Opus 4.8的1/11。IndexShare进一步降低GPU消耗。
六、实战:评估流水线
6.1 综合评分
package main
import "fmt"
func main() {
w := map[string]float64{"c":0.4,"r":0.25,"x":0.15,"s":0.1,"o":0.1}
type M struct{n string; c,r,x,s,o float64}
ms := []M{{"GLM-5.2",92,85,95,90,100},{"GPT-5.5",88,90,70,50,20},{"Opus4.8",93,92,75,35,10}}
for _,m := range ms {
t := m.c*w["c"]+m.r*w["r"]+m.x*w["x"]+m.s*w["s"]+m.o*w["o"]
fmt.Printf("%-12s %.1f\n", m.n, t)
}
}
输出:GLM-5.2=91.3, GPT-5.5=75.2, Opus4.8=76.0
6.2 注意力开销对比
def f(N,d,t):
if t=="full": return N*N*d
if t=="is": return (N//4)*d + N*(1024*4)*d//4
N,d=1000000,128
for t in ["full","is"]:
print(t, f(N,d,t))
输出:full=1.28e+14, is=1.31e+11 (压缩99.9%)
架构图:多维对比
七、行业影响与展望
7.1 新御三家
Artificial Analysis榜单上GLM-5.2与Anthropic、OpenAI形成新御三家格局。Code Arena可用模型第一。
7.2 开源结构性优势
东方证券指出开源模型有望获更多份额:可获得性(永不下线)、可控性(本地部署)、成本(1/6-1/11)、生态(可微调)。
7.3 短板
多模态弱(仅文本/代码)、SWE-Marathon差距50%、部署门槛高(需5张A100)。属时间问题非结构问题。
八、结论
GLM-5.2开源标志开源模型正式进入与闭源前沿正面竞争时代。技术差距仅0.9%,IndexShare压缩计算量至1/1000,MIT+国产算力全适配,Fable 5下架加速迁移。