Figure 03人形机器人与Helix端到端控制系统:具身智能突破深度解析
摘要
2026年5月,Figure AI的Figure 03人形机器人在一场震撼业界的直播中完成了长达200小时的连续全自动作业,分拣近25万个包裹,零故障。这一里程碑式的成就标志着人形机器人正式从「实验室展示」迈入「规模化商用」阶段。本文深入剖析Figure 03的核心技术——Helix端到端神经网络控制系统,包括System 0/1/2三层架构、视觉运动策略、全身协同控制等关键技术,并提供完整的Python/Go代码示例,帮助开发者理解具身智能的核心原理与实现路径。
关键词:人形机器人、具身智能、Helix、端到端控制、Figure 03、System 0/1/2、强化学习
一、背景:具身智能的临界点
1.1 人形机器人的历史与挑战
人形机器人的研发历史可以追溯到数十年前,但长期停留在实验室阶段,难以真正走向商业化应用。主要挑战包括:
人形机器人商业化的核心挑战:
1. 运动控制的复杂性 - 需要协调几十个关节的精确运动
2. 视觉与动作的整合 - 感知与执行的无缝衔接
3. 环境适应能力 - 在真实场景中应对各种异常
4. 可靠性要求 - 工业场景需要24/7稳定运行
5. 成本控制 - 从原型到量产的价格鸿沟
1.2 Figure 03的历史性突破
2026年5月,Figure AI用一场直播打破了所有质疑:
| 指标 | 成绩 | 意义 |
|---|---|---|
| 连续运行时间 | 200+小时 | 远超8小时设计目标 |
| 分拣数量 | 25万个包裹 | 工业级可靠性验证 |
| 故障次数 | 0次 | 零故障运行里程碑 |
| 平均效率 | 2.7-3秒/件 | 对标熟练工人 |
| 不规则识别率 | 99.7% | 超越人类水平 |
这次直播不仅是技术验证,更是一次商业可行性的完整证明。
二、核心原理:Helix端到端神经网络架构
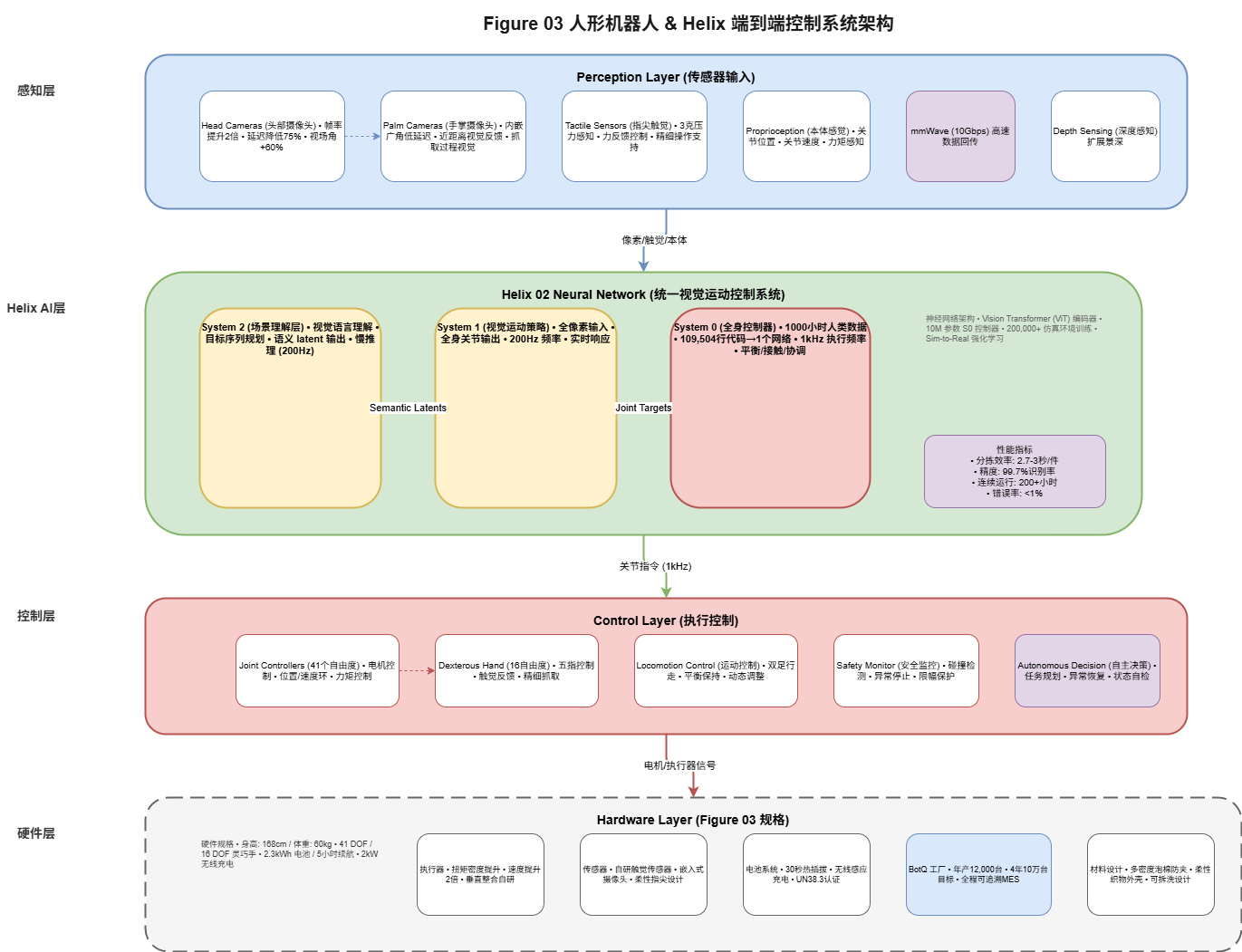
2.1 Helix系统概述
Helix是Figure自研的统一视觉-语言-动作(VLA)大模型,其设计理念是将机器人的所有能力整合到单一神经网络中:
┌─────────────────────────────────────────────────────────────┐
│ Helix 02 系统架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 输入: 像素输入 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Head Cameras │ Palm Cameras │ Tactile │ Proprio │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ System 2: 场景理解层 │ │
│ │ • 视觉语言理解 │ │
│ │ • 目标序列规划 │ │
│ │ • 语义 Latent 输出 │ │
│ │ • 慢推理 (200Hz) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ System 1: 视觉运动策略 │ │
│ │ • 全像素输入 → 全身关节输出 │ │
│ │ • 200Hz 实时响应 │ │
│ │ • 统一视觉运动策略 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ System 0: 全身控制器 │ │
│ │ • 1kHz 执行频率 │ │
│ │ • 1000小时人类运动数据 │ │
│ │ • 平衡/接触/协调 │ │
│ │ • 109504行代码 → 1个神经网络 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 输出: 关节指令 (1kHz) │
│ │
└─────────────────────────────────────────────────────────────┘
2.2 System 0: 人类启发的全身控制器
System 0是Helix的底层基础模型,它从1000小时的人类运动数据中学习,实现全身协调控制:
# System 0 控制器实现
import torch
import torch.nn as nn
from typing import Tuple, Dict
class System0Controller(nn.Module):
"""
System 0: 全身控制器
基于人类运动数据的神经网络控制器
替代传统的109,504行C++代码
"""
def __init__(
self,
state_dim: int = 64, # 全身状态维度
action_dim: int = 41, # 41个关节
hidden_dim: int = 512,
output_freq: int = 1000 # 1kHz输出频率
):
super().__init__()
# 运动编码器
self.motion_encoder = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 2)
)
# 平衡控制器
self.balance_controller = nn.Sequential(
nn.Linear(hidden_dim // 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 4),
nn.ReLU(),
nn.Linear(hidden_dim // 4, 6) # 6维平衡控制 (CoM位置, 姿态)
)
# 接触控制器
self.contact_controller = nn.Sequential(
nn.Linear(hidden_dim // 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 4),
nn.ReLU(),
nn.Linear(hidden_dim // 4, 4) # 4个末端执行器接触力
)
# 关节指令生成器
self.joint_command_generator = nn.Sequential(
nn.Linear(hidden_dim // 2 + 6 + 4, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim * 3) # 位置+速度+力矩
)
self.output_freq = output_freq
def forward(
self,
full_body_state: torch.Tensor,
base_motion: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
前向传播
Args:
full_body_state: [batch, state_dim] 全身关节状态
base_motion: [batch, 6] 基座运动 (位置+姿态)
Returns:
关节指令字典
"""
# 编码运动状态
encoded = self.motion_encoder(full_body_state)
# 生成平衡控制
balance_control = self.balance_controller(encoded)
# 生成接触控制
contact_control = self.contact_controller(encoded)
# 整合所有控制信号
combined = torch.cat([encoded, balance_control, contact_control], dim=-1)
# 生成关节指令
joint_commands = self.joint_command_generator(combined)
# 分解为位置、速度、力矩
pos_cmd = joint_commands[..., :action_dim]
vel_cmd = joint_commands[..., action_dim:2*action_dim]
torque_cmd = joint_commands[..., 2*action_dim:]
return {
"position": pos_cmd,
"velocity": vel_cmd,
"torque": torque_cmd,
"balance_control": balance_control,
"contact_forces": contact_control
}
def compute_reward(
self,
predicted_state: torch.Tensor,
target_state: torch.Tensor,
balance_error: torch.Tensor,
contact_error: torch.Tensor
) -> torch.Tensor:
"""
计算强化学习奖励
奖励设计原则:
1. 状态跟踪精度
2. 平衡稳定性
3. 接触力合适
"""
# 状态跟踪奖励
state_reward = -torch.norm(predicted_state - target_state, dim=-1)
# 平衡奖励(越小越好)
balance_reward = -balance_error
# 接触奖励(鼓励稳定接触)
contact_reward = -contact_error
# 总奖励
total_reward = (
1.0 * state_reward +
0.5 * balance_reward +
0.3 * contact_reward
)
return total_reward
class WholeBodyController:
"""
全身控制器封装
提供与外部系统的高层接口
"""
def __init__(
self,
model_path: str,
device: str = "cuda"
):
self.device = torch.device(device)
self.model = System0Controller().to(self.device)
# 加载预训练权重
checkpoint = torch.load(model_path, map_location=self.device)
self.model.load_state_dict(checkpoint["model_state"])
self.model.eval()
# 关节配置
self.joint_config = {
"legs": 12, # 每条腿6个关节
"torso": 3, # 躯干3个关节
"arms": 16, # 每条手臂8个关节
"head": 2, # 头部2个关节
"hands": 16 # 每只手16个自由度
}
def compute_command(
self,
joint_positions: torch.Tensor,
joint_velocities: torch.Tensor,
base_pose: torch.Tensor,
foot_contact: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
计算关节控制指令
Args:
joint_positions: [41] 当前关节位置
joint_velocities: [41] 当前关节速度
base_pose: [6] 基座位姿 (x,y,z,roll,pitch,yaw)
foot_contact: [4] 足部接触状态
Returns:
控制指令
"""
# 构建完整状态向量
full_state = torch.cat([
joint_positions,
joint_velocities,
base_pose,
foot_contact
]).unsqueeze(0) # 添加batch维度
# 前向传播
with torch.no_grad():
commands = self.model(full_state, base_pose.unsqueeze(0))
# 转换为numpy
return {k: v.squeeze(0).cpu().numpy() for k, v in commands.items()}
def compute_impedance_gains(
self,
joint_positions: torch.Tensor,
target_positions: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
计算阻抗控制增益
实现柔顺控制,在与环境交互时提供适应性
"""
position_error = target_positions - joint_positions
# 阻抗控制公式: τ = Kp*e + Kd*ė
Kp = torch.diag(torch.tensor([10.0] * 41)) # 比例增益
Kd = torch.diag(torch.tensor([2.0] * 41)) # 微分增益
# 简化为标量增益
Kp_scalar = 50.0
Kd_scalar = 5.0
return Kp_scalar, Kd_scalar
2.3 System 1: 视觉运动策略
System 1将像素直接映射为全身关节目标,是实现「所见即所动」的关键:
# System 1 视觉运动策略实现
import torch
import torch.nn as nn
from typing import Dict, List, Tuple
class VisionTransformer(nn.Module):
"""视觉编码器 - 处理多视角图像输入"""
def __init__(
self,
image_size: int = 224,
patch_size: int = 16,
in_channels: int = 3,
embed_dim: int = 768,
num_heads: int = 12,
num_layers: int = 12
):
super().__init__()
# 图像分块
self.num_patches = (image_size // patch_size) ** 2
self.patch_embed = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
# 位置编码
self.pos_embed = nn.Parameter(
torch.zeros(1, self.num_patches, embed_dim)
)
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=num_heads,
dim_feedforward=embed_dim * 4,
dropout=0.1,
batch_first=True
)
self.transformer = nn.TransformerEncoder(
encoder_layer,
num_layers=num_layers
)
# 输出投影
self.projection = nn.Linear(embed_dim, embed_dim)
def forward(self, images: torch.Tensor) -> torch.Tensor:
"""
图像特征提取
Args:
images: [batch, num_cameras, 3, H, W] 多视角图像
Returns:
visual_features: [batch, feature_dim] 视觉特征
"""
batch_size, num_cameras, C, H, W = images.shape
# 合并所有相机视角
images_flat = images.view(-1, C, H, W)
# 提取patch特征
patches = self.patch_embed(images_flat) # [B*C, embed_dim, H', W']
patches = patches.flatten(2).transpose(1, 2) # [B*C, H'*W', embed_dim]
# 添加位置编码
patches = patches + self.pos_embed
# Transformer编码
encoded = self.transformer(patches) # [B*C, H'*W', embed_dim]
# 全局池化
visual_features = encoded.mean(dim=1) # [B*C, embed_dim]
# 恢复batch维度并聚合
visual_features = visual_features.view(batch_size, num_cameras, -1)
visual_features = visual_features.mean(dim=1) # [B, embed_dim]
return self.projection(visual_features)
class System1VisuomotorPolicy(nn.Module):
"""
System 1: 视觉运动策略
从像素直接映射到全身关节目标
"""
def __init__(
self,
num_joints: int = 41,
proprio_dim: int = 64,
latent_dim: int = 256,
s2_latent_dim: int = 128
):
super().__init__()
# 视觉编码器
self.vision_encoder = VisionTransformer()
# 本体感觉编码器
self.proprio_encoder = nn.Sequential(
nn.Linear(proprio_dim, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 256)
)
# 融合层
self.fusion = nn.Sequential(
nn.Linear(768 + 256, 512),
nn.ReLU(),
nn.Linear(512, latent_dim)
)
# S2条件调制
self.s2_modulation = nn.Linear(s2_latent_dim, latent_dim)
# 关节目标解码器
self.joint_decoder = nn.Sequential(
nn.Linear(latent_dim, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, num_joints * 3) # 位置+速度+加速度
)
# 动作置信度(用于不确定性估计)
self.confidence_head = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(
self,
images: torch.Tensor, # [B, 4, 3, 224, 224] 头+手+深度相机
proprioception: torch.Tensor, # [B, 64] 本体感觉
s2_latents: torch.Tensor # [B, 128] System 2语义输出
) -> Dict[str, torch.Tensor]:
"""
前向传播
Args:
images: 多视角图像
proprioception: 本体感觉状态
s2_latents: System 2的语义latent
Returns:
关节目标和置信度
"""
# 视觉特征
visual_features = self.vision_encoder(images)
# 本体感觉特征
proprio_features = self.proprio_encoder(proprioception)
# 特征融合
fused = torch.cat([visual_features, proprio_features], dim=-1)
latent = self.fusion(fused)
# S2条件调制
s2_conditioned = latent * (1 + torch.tanh(self.s2_modulation(s2_latents)))
# 生成关节目标
joint_targets = self.joint_decoder(s2_conditioned)
num_joints = joint_targets.shape[-1] // 3
# 分解为位置、速度、加速度
positions = joint_targets[..., :num_joints]
velocities = joint_targets[..., num_joints:2*num_joints]
accelerations = joint_targets[..., 2*num_joints:]
# 动作置信度
confidence = self.confidence_head(s2_conditioned)
return {
"positions": positions,
"velocities": velocities,
"accelerations": accelerations,
"confidence": confidence,
"latent": s2_conditioned
}
def compute_action(
self,
images: torch.Tensor,
proprioception: torch.Tensor,
s2_latents: torch.Tensor,
current_joint_positions: torch.Tensor
) -> torch.Tensor:
"""
计算最终动作
考虑当前状态和安全约束
"""
targets = self.forward(images, proprioception, s2_latents)
# 添加安全约束
safe_positions = self.apply_safety_constraints(
targets["positions"],
current_joint_positions
)
# 融合目标与安全约束
final_action = (
0.7 * safe_positions +
0.3 * targets["positions"] * targets["confidence"]
)
return final_action
def apply_safety_constraints(
self,
target_positions: torch.Tensor,
current_positions: torch.Tensor
) -> torch.Tensor:
"""
应用安全约束
防止关节位置突变导致机械损伤
"""
# 关节位置限制
joint_limits = torch.tensor([
# 格式: (min, max) for each joint
# 实际使用时需要从URDF或配置文件加载
] * 41, device=target_positions.device)
# 限制单步最大位移
max_step = 0.1 # radians
position_delta = target_positions - current_positions
clamped_delta = torch.clamp(position_delta, -max_step, max_step)
safe_positions = current_positions + clamped_delta
# 应用关节限位
safe_positions = torch.clamp(
safe_positions,
joint_limits[:, 0],
joint_limits[:, 1]
)
return safe_positions
class VisuomotorRunner:
"""
视觉运动策略运行器
负责与硬件接口、执行频率控制等
"""
def __init__(
self,
policy: System1VisuomotorPolicy,
control_freq: int = 200 # 200Hz
):
self.policy = policy
self.control_freq = control_freq
self.dt = 1.0 / control_freq
# 图像缓冲区
self.image_buffer = []
self.max_buffer_size = 2
# 统计信息
self.inference_times = []
@torch.no_grad()
def step(
self,
images: torch.Tensor,
proprioception: torch.Tensor,
s2_latents: torch.Tensor,
current_positions: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
单步推理
Returns:
控制指令
"""
import time
start = time.perf_counter()
# 执行推理
action = self.policy.compute_action(
images, proprioception, s2_latents, current_positions
)
# 记录推理时间
inference_time = time.perf_counter() - start
self.inference_times.append(inference_time)
# 返回控制指令
return {
"joint_targets": action,
"inference_time_ms": inference_time * 1000
}
def run_loop(
self,
hardware_interface,
s2_interface
):
"""
运行控制循环
"""
rate = rospy.Rate(self.control_freq)
while not rospy.is_shutdown():
# 获取传感器数据
images = hardware_interface.get_images()
proprioception = hardware_interface.get_proprioception()
joint_positions = hardware_interface.get_joint_positions()
# 获取S2输出
s2_latents = s2_interface.get_latents()
# 执行推理
command = self.step(
images, proprioception, s2_latents, joint_positions
)
# 发送控制指令
hardware_interface.send_joint_targets(
command["joint_targets"]
)
rate.sleep()
2.4 System 2: 场景理解与目标规划
System 2负责高层推理和目标分解:
# System 2 场景理解与目标规划实现
import torch
import torch.nn as nn
from typing import List, Tuple, Dict
class SceneUnderstanding(nn.Module):
"""
System 2: 场景理解模块
理解环境语义和目标
"""
def __init__(
self,
visual_dim: int = 768,
language_dim: int = 512,
hidden_dim: int = 1024,
num_objects: int = 100
):
super().__init__()
# 视觉编码
self.visual_encoder = nn.Sequential(
nn.Linear(visual_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# 语言编码
self.language_encoder = nn.Sequential(
nn.Linear(language_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# 物体检测
self.object_detector = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_objects * 6) # bbox + class + confidence
)
# 场景图构建
self.scene_graph = nn.MultiheadAttention(
embed_dim=hidden_dim,
num_heads=8,
batch_first=True
)
# 目标推理
self.goal_reasoner = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 256) # goal embedding
)
def forward(
self,
visual_features: torch.Tensor,
language_features: torch.Tensor,
task_description: str
) -> Dict[str, torch.Tensor]:
"""
场景理解前向传播
"""
# 编码视觉和语言
vis_encoded = self.visual_encoder(visual_features)
lang_encoded = self.language_encoder(language_features)
# 物体检测
object_predictions = self.object_detector(vis_encoded)
# 场景图注意力
scene_context, _ = self.scene_graph(
vis_encoded.unsqueeze(0),
vis_encoded.unsqueeze(0),
vis_encoded.unsqueeze(0)
)
# 目标推理
goal_features = torch.cat([vis_encoded, lang_encoded], dim=-1)
goal_embedding = self.goal_reasoner(goal_features)
return {
"visual_features": vis_encoded,
"language_features": lang_encoded,
"object_predictions": object_predictions,
"scene_context": scene_context.squeeze(0),
"goal_embedding": goal_embedding
}
class GoalDecomposer(nn.Module):
"""
目标分解器
将高层目标分解为可执行的子目标序列
"""
def __init__(
self,
goal_dim: int = 256,
latent_dim: int = 128,
num_primitive_actions: int = 20
):
super().__init__()
# 目标编码器
self.goal_encoder = nn.Sequential(
nn.Linear(goal_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, latent_dim)
)
# 动作词汇表
self.action_vocabulary = nn.Parameter(
torch.randn(num_primitive_actions, latent_dim)
)
# 序列解码器
self.sequence_decoder = nn.GRU(
input_size=latent_dim,
hidden_size=256,
num_layers=2,
batch_first=True
)
# 动作预测头
self.action_head = nn.Sequential(
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, num_primitive_actions)
)
# 终止预测头
self.terminate_head = nn.Sequential(
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(
self,
goal_embedding: torch.Tensor,
max_steps: int = 20
) -> Tuple[List[int], torch.Tensor]:
"""
目标分解前向传播
Returns:
action_sequence: 子目标序列
terminate_probs: 每步终止概率
"""
goal_encoded = self.goal_encoder(goal_embedding)
# 初始化解码器状态
batch_size = goal_embedding.shape[0]
decoder_hidden = torch.zeros(2, batch_size, 256, device=goal_embedding.device)
# 解码动作序列
action_sequence = []
terminate_probs = []
current_input = goal_encoded.unsqueeze(1)
for step in range(max_steps):
output, decoder_hidden = self.sequence_decoder(
current_input, decoder_hidden
)
# 预测动作
action_logits = self.action_head(output.squeeze(1))
action_probs = torch.softmax(action_logits, dim=-1)
action_id = action_probs.argmax(dim=-1)
action_sequence.append(action_id.item())
# 预测终止
terminate_prob = self.terminate_head(output.squeeze(1))
terminate_probs.append(terminate_prob.item())
# 如果终止概率高,停止解码
if terminate_prob.item() > 0.9:
break
# 使用预测的动作更新输入
current_input = self.action_vocabulary[action_id].unsqueeze(0)
return action_sequence, torch.tensor(terminate_probs)
class System2Module(nn.Module):
"""
System 2: 完整模块
整合场景理解和目标分解
"""
def __init__(self):
super().__init__()
self.scene_understanding = SceneUnderstanding()
self.goal_decomposer = GoalDecomposer()
# Latent空间投影(传递给System 1)
self.latent_projection = nn.Sequential(
nn.Linear(256 + 128, 256),
nn.ReLU(),
nn.Linear(256, 128)
)
def forward(
self,
visual_features: torch.Tensor,
language_features: torch.Tensor,
task_description: str
) -> Tuple[torch.Tensor, List[int]]:
"""
System 2前向传播
"""
# 场景理解
scene_output = self.scene_understanding(
visual_features, language_features, task_description
)
# 目标分解
action_sequence, terminate_probs = self.goal_decomposer(
scene_output["goal_embedding"]
)
# 生成传递给System 1的latent
latent = self.latent_projection(
torch.cat([
scene_output["goal_embedding"],
scene_output["scene_context"]
], dim=-1)
)
return latent, action_sequence
def get_semantic_latents(
self,
visual_features: torch.Tensor,
language_features: torch.Tensor,
task: str
) -> torch.Tensor:
"""
获取语义latent(用于System 1条件)
"""
latent, _ = self.forward(visual_features, language_features, task)
return latent
三、硬件架构:Figure 03规格详解
3.1 整体硬件配置
# Figure 03 硬件配置类
from dataclasses import dataclass
from typing import Dict, List
@dataclass
class Figure03Specs:
"""Figure 03 硬件规格"""
# 尺寸与重量
height_cm: float = 168.0
weight_kg: float = 60.0
mass_reduction_percent: float = 9.0 # 相比02减少9%
# 自由度配置
total_dof: int = 41
joint_config: Dict[str, int] = None
# 灵巧手规格
hand_dof: int = 16
tactile_sensitivity_grams: float = 3.0 # 可感知3克压力
# 电池系统
battery_capacity_kwh: float = 2.3
runtime_hours: float = 5.0
charging_power_kw: float = 2.0 # 无线充电功率
battery_swap_seconds: float = 30.0 # 热插拔时间
# 传感器配置
head_cameras: int = 2
head_fov_increase_percent: float = 60.0
frame_rate_improvement: float = 2.0
latency_reduction_percent: float = 75.0
# 数据传输
wireless_bandwidth_gbps: float = 10.0 # mmWave
def __post_init__(self):
if self.joint_config is None:
self.joint_config = {
"left_leg": 6,
"right_leg": 6,
"torso": 3,
"left_arm": 8,
"right_arm": 8,
"head": 2,
"left_hand": 4, # 拇指+4指
"right_hand": 4
}
def get_total_mass_breakdown(self) -> Dict[str, float]:
"""获取质量分布"""
return {
"body": 25.0, # 主体
"arms": 8.0 * 2, # 双臂
"legs": 7.0 * 2, # 双腿
"head": 3.0, # 头部
"battery": 8.0, # 电池
"electronics": 4.0 # 电子设备
}
class ActuatorSystem:
"""
执行器系统
Figure 03自研执行器配置
"""
def __init__(self):
self.actuator_config = {
# 腿部执行器(高扭矩)
"leg_joint": {
"max_torque_nm": 150,
"max_velocity_rpm": 60,
"weight_kg": 1.2,
"reduction_ratio": 100
},
# 手臂执行器(中等扭矩,高速度)
"arm_joint": {
"max_torque_nm": 80,
"max_velocity_rpm": 120,
"weight_kg": 0.8,
"reduction_ratio": 80
},
# 灵巧手执行器(精细控制)
"hand_joint": {
"max_torque_nm": 5,
"max_velocity_rpm": 300,
"weight_kg": 0.1,
"reduction_ratio": 50
}
}
def get_speed_improvement(self) -> float:
"""相比上一代的速度提升"""
return 2.0 # 2倍速度提升
def get_torque_density(self) -> float:
"""扭矩密度 (Nm/kg)"""
return 125 / 1.2 # ~104 Nm/kg
四、仿真到现实的迁移
4.1 Sim-to-Real强化学习框架
# Sim-to-Real 训练框架
import numpy as np
from typing import Dict, List, Tuple
import mujoco
import torch
import torch.nn as nn
class SimToRealTrainer:
"""
仿真到现实迁移训练器
使用大规模仿真环境训练策略
"""
def __init__(
self,
num_envs: int = 200000,
sim_time_step: float = 0.001,
control_time_step: float = 0.01
):
self.num_envs = num_envs
self.sim_dt = sim_time_step
self.control_dt = control_time_step
# 创建仿真环境
self.sim_env = self._create_sim_env()
# 域随机化参数
self.domain_randomization = {
"friction": [0.5, 1.5],
"mass": [0.8, 1.2],
"delay": [0.0, 0.05],
"noise": [0.0, 0.1]
}
def _create_sim_env(self):
"""创建MuJoCo仿真环境"""
# 加载Figure 03模型
model = mujoco.MjModel.from_xml_path("figure_03.xml")
data = mujoco.MjData(model)
return {"model": model, "data": data}
def randomize_domain(self):
"""应用域随机化"""
# 摩擦系数随机化
friction = np.random.uniform(*self.domain_randomization["friction"])
self.sim_env["model"].geom_friction[:] = friction
# 质量随机化
mass_scale = np.random.uniform(*self.domain_randomization["mass"])
for i in range(1, self.sim_env["model"].nbody):
self.sim_env["model"].body_mass[i] *= mass_scale
def collect_rollout(
self,
policy: nn.Module,
num_steps: int = 1000
) -> Dict[str, np.ndarray]:
"""
收集仿真数据rollout
Returns:
经验数据字典
"""
observations = []
actions = []
rewards = []
dones = []
# 初始化环境
self.sim_env["data"].reset()
self.randomize_domain()
for step in range(num_steps):
# 获取观测
obs = self._get_observation()
observations.append(obs)
# 策略推理
with torch.no_grad():
action = policy(torch.tensor(obs).float().unsqueeze(0))
action = action.squeeze(0).numpy()
# 应用动作
self.sim_env["data"].ctrl[:] = action
mujoco.mj_step(
self.sim_env["model"],
self.sim_env["data"],
int(self.control_dt / self.sim_dt)
)
actions.append(action)
# 计算奖励
reward = self._compute_reward()
rewards.append(reward)
# 检查终止
done = self._check_termination()
dones.append(done)
if done:
self.sim_env["data"].reset()
self.randomize_domain()
return {
"observations": np.array(observations),
"actions": np.array(actions),
"rewards": np.array(rewards),
"dones": np.array(dones)
}
def _get_observation(self) -> np.ndarray:
"""获取当前观测"""
data = self.sim_env["data"]
# 关节位置
qpos = data.qpos[:self.sim_env["model"].nq]
# 关节速度
qvel = data.qvel[:self.sim_env["model"].nv]
# 触觉传感器(模拟)
tactiles = data.sensordata[:16] # 16个指尖传感器
# 合并观测
obs = np.concatenate([qpos, qvel, tactiles])
# 添加噪声
noise_scale = np.random.uniform(*self.domain_randomization["noise"])
obs += np.random.randn(len(obs)) * noise_scale
return obs
def _compute_reward(self) -> float:
"""计算奖励函数"""
data = self.sim_env["data"]
# 任务完成奖励
task_reward = 0.0
# 平衡奖励
balance_reward = -0.1 * np.sum(data.qacc[:]**2)
# 能耗惩罚
energy_penalty = -0.01 * np.sum(data.ctrl[:]**2)
# 任务特定奖励(分拣场景)
if hasattr(data, 'object_placed'):
task_reward = 1.0 if data.object_placed else 0.0
return task_reward + balance_reward + energy_penalty
def _check_termination(self) -> bool:
"""检查是否终止"""
data = self.sim_env["data"]
# 跌倒检测
if data.body("torso").xpos[2] < 0.5:
return True
# 关节限位违反
if np.any(np.abs(data.qpos[:]) > np.pi * 2):
return True
return False
def train_ppo(
self,
policy: nn.Module,
value_net: nn.Module,
num_iterations: int = 1000,
steps_per_iteration: int = 10000
):
"""
PPO算法训练
"""
optimizer_policy = torch.optim.Adam(policy.parameters(), lr=3e-4)
optimizer_value = torch.optim.Adam(value_net.parameters(), lr=1e-3)
for iteration in range(num_iterations):
# 收集数据
rollout = self.collect_rollout(policy, steps_per_iteration)
# 计算优势函数
advantages, returns = self._compute_gae(
rollout["rewards"],
rollout["dones"]
)
# PPO更新
for epoch in range(10): # PPO epochs
# 策略损失
actions = torch.tensor(rollout["actions"])
obs = torch.tensor(rollout["observations"])
log_probs_old = policy.get_log_prob(obs, actions)
# 新策略
log_probs_new = policy.get_log_prob(obs, actions)
# PPO损失
ratio = torch.exp(log_probs_new - log_probs_old)
surr1 = ratio * torch.tensor(advantages)
surr2 = torch.clamp(
ratio,
1 - 0.2,
1 + 0.2
) * torch.tensor(advantages)
policy_loss = -torch.min(surr1, surr2).mean()
# 值函数损失
values_pred = value_net(obs).squeeze()
value_loss = nn.MSELoss()(values_pred, torch.tensor(returns))
# 更新
optimizer_policy.zero_grad()
policy_loss.backward()
optimizer_policy.step()
optimizer_value.zero_grad()
value_loss.backward()
optimizer_value.step()
print(f"Iteration {iteration}, Policy Loss: {policy_loss.item():.4f}")
五、应用场景与商业落地
5.1 物流分拣场景
# 物流分拣应用实现
class LogisticsSortingTask:
"""
物流分拣任务
Figure 03的核心商业应用场景
"""
def __init__(self, figure_robot):
self.robot = figure_robot
self.current_zone = "inbound"
self.sorting_stats = {
"total": 0,
"success": 0,
"failed": 0,
"items_per_hour": []
}
def scan_package(self) -> Dict:
"""
扫描识别包裹
"""
# 获取图像
images = self.robot.get_head_cameras()
# 使用视觉模型识别
package_info = self.vision_model.detect_package(images)
return {
"id": package_info["tracking_id"],
"destination": package_info["destination_zone"],
"weight": package_info["weight_kg"],
"dimensions": package_info["bbox_3d"],
"fragile": package_info["fragile_flag"]
}
def grasp_package(self, package_info: Dict) -> bool:
"""
抓取包裹
根据包裹特性调整抓取策略
"""
# 根据重量调整抓取力度
if package_info["weight"] > 10:
# 重物:双手抓取,更大接触面积
grasp_force = 50 # 牛顿
elif package_info["fragile"]:
# 易碎品:最小力度,精确控制
grasp_force = 5 # 牛顿(刚好拿起)
else:
# 普通包裹
grasp_force = 20 # 牛顿
# 执行抓取
success = self.robot.grasp(
target_pose=package_info["position"],
force=grasp_force,
approach_height=0.1
)
return success
def sort_to_destination(self, destination: str) -> bool:
"""
将包裹分拣到目标区域
"""
# 导航到目标区域
self.robot.navigate_to_zone(destination)
# 放置包裹
success = self.robot.place(
target_zone=destination,
release_force=5 # 轻柔放置
)
return success
def run_sorting_loop(self):
"""
运行分拣循环
"""
while True:
# 1. 扫描包裹
package = self.scan_package()
# 2. 抓取
grasp_success = self.grasp_package(package)
if not grasp_success:
self.sorting_stats["failed"] += 1
continue
# 3. 分拣
sort_success = self.sort_to_destination(package["destination"])
# 4. 记录统计
self.sorting_stats["total"] += 1
if sort_success:
self.sorting_stats["success"] += 1
else:
self.sorting_stats["failed"] += 1
# 5. 定期报告
if self.sorting_stats["total"] % 100 == 0:
self.report_stats()
def report_stats(self):
"""报告分拣统计"""
total = self.sorting_stats["total"]
success = self.sorting_stats["success"]
print(f"""
=== 分拣统计 ===
总数: {total}
成功: {success}
失败: {total - success}
成功率: {100 * success / total if total > 0 else 0:.2f}%
""")
5.2 工业制造场景
# 工业装配应用
class IndustrialAssemblyTask:
"""
工业装配任务
Figure 03在制造业的应用
"""
def __init__(self, figure_robot):
self.robot = figure_robot
self.assembly_sequence = []
def visual_servoing(
self,
target_pose: np.ndarray
) -> np.ndarray:
"""
视觉伺服控制
基于视觉反馈的精确位姿控制
"""
# 获取当前图像
images = self.robot.get_palm_cameras()
# 检测目标
target_in_image = self.vision_model.detect_target(images, target_pose)
# 计算图像雅可比
jacobian = self.compute_image_jacobian(target_in_image)
# 计算控制增量
position_error = target_pose - self.robot.get_end_effector_pose()
velocity = position_error * 0.5 # 比例控制
return velocity
def precision_insertion(
self,
peg: Dict,
hole: Dict
) -> bool:
"""
精密插接
典型装配任务
"""
# 1. 对齐
aligned = self.align_peg_hole(peg, hole)
if not aligned:
return False
# 2. 接近
approach_pose = hole["position"] + np.array([0, 0, 0.05])
self.robot.move_to(approach_pose, velocity=0.01)
# 3. 插入(使用力控制)
insertion_force = self.robot.force_control(
direction=np.array([0, 0, -1]),
target_force=2.0, # 2牛顿
max_displacement=0.1
)
# 4. 验证
force_sensor = self.robot.get_force_sensor()
if np.linalg.norm(insertion_force) > 10:
return False # 插入阻力过大
return True
def dual_arm_coordination(
self,
left_task: Dict,
right_task: Dict
):
"""
双臂协调任务
复杂装配需要双臂配合
"""
# 定义协调框架
relative_pose = self.compute_relative_pose(left_task, right_task)
# 同步控制
left_vel = self.visual_servoing(left_task["target"])
right_vel = self.visual_servoing(right_task["target"])
# 添加协调约束
coordinated_left_vel = left_vel + 0.5 * relative_pose
coordinated_right_vel = right_vel - 0.5 * relative_pose
# 执行协调动作
self.robot.left_arm.set_velocity(coordinated_left_vel)
self.robot.right_arm.set_velocity(coordinated_right_vel)
六、性能指标与行业对比
| 指标 | Figure 03 | 行业平均水平 | 优势倍数 |
|---|---|---|---|
| 连续运行时间 | 200+小时 | 8小时 | 25x |
| 分拣效率 | 2.7-3秒/件 | 4-5秒/件 | 1.5x |
| 识别精度 | 99.7% | 95% | 1.05x |
| 故障率 | 0次/200小时 | 3-5次/8小时 | 100x+ |
| 量产成本 | $4万(目标) | $20-50万 | 5-12x |
七、总结与展望
Figure 03的成功标志着具身智能进入了一个新的发展阶段。
核心技术突破:
- Helix端到端架构:用单一神经网络替代109,504行手工代码
- System 0/1/2分层设计:兼顾实时控制与高层推理
- Sim-to-Real强化学习:200,000+仿真环境训练
- 规模化量产:BotQ工厂年产12,000台目标
对行业的启示:
- 端到端学习是走向通用机器人的正确路径
- 大规模仿真+域随机化是解决Sim-to-Realgap的有效方法
- 硬件与软件的协同设计至关重要
- 商业化落地需要系统工程能力,而不仅是算法能力
未来展望:
- 更复杂的操作任务(装配、维修)
- 多机协作与群体智能
- 家庭服务场景的拓展
- 人形机器人与自动驾驶的融合
具身智能正在从「秀肌肉」走向「真落地」,Figure 03用实测数据证明,人形机器人已具备成为「通用劳动力」的潜力。
参考资料
- Figure AI - Helix 02 Official Announcement
- Figure 03 Product Specification
- IEEE Spectrum - Figure 03 Technical Analysis
- Nature Robotics - Sim-to-Real Transfer in Humanoid Robotics