从代码到钢铁:英伟达ENPIRE让AI Agent在物理世界自主科研
8个AI Coding Agent × 8台真实机器人 = 物理世界AutoResearch首次闭环验证
2026年6月17-18日,英伟达GEAR实验室联合CMU、UC Berkeley发布ENPIRE项目,让AI Agent真正走出数字沙盒,自主操控机械臂完成插针、装GPU、剪扎带等高精度任务,最终成功率99%。
一、引言:当AI不再只是敲代码
2024年,Andrej Karpathy开源了autoresearch项目,AI可以自动完成模型训练和实验管理;2025年,AI Scientist已经能自动生成研究方案、运行实验并撰写论文。
但这些系统有一个共同点:它们始终活在数字环境中。代码跑完即出结果,模拟器里的物理是确定的,一次失败可以零成本重来。
现实世界不一样。
机器人碰撞时的摩擦力会变化,物体无法精确复原,光照和传感器噪声始终波动。ENPIRE论文中有一个鲜明的案例:在模拟环境中,三个被测Coding Agent全部成功完成了Push-T任务;但当同一方法部署到真实机器人上时,其中两个Agent直接失败。
这正是ENPIRE(Agentic Robot Policy Self-Improvement in the Real World)存在的意义——让AI科研第一次触及物理世界的非确定性。
二、硬件架构:8个独立"科研工位"
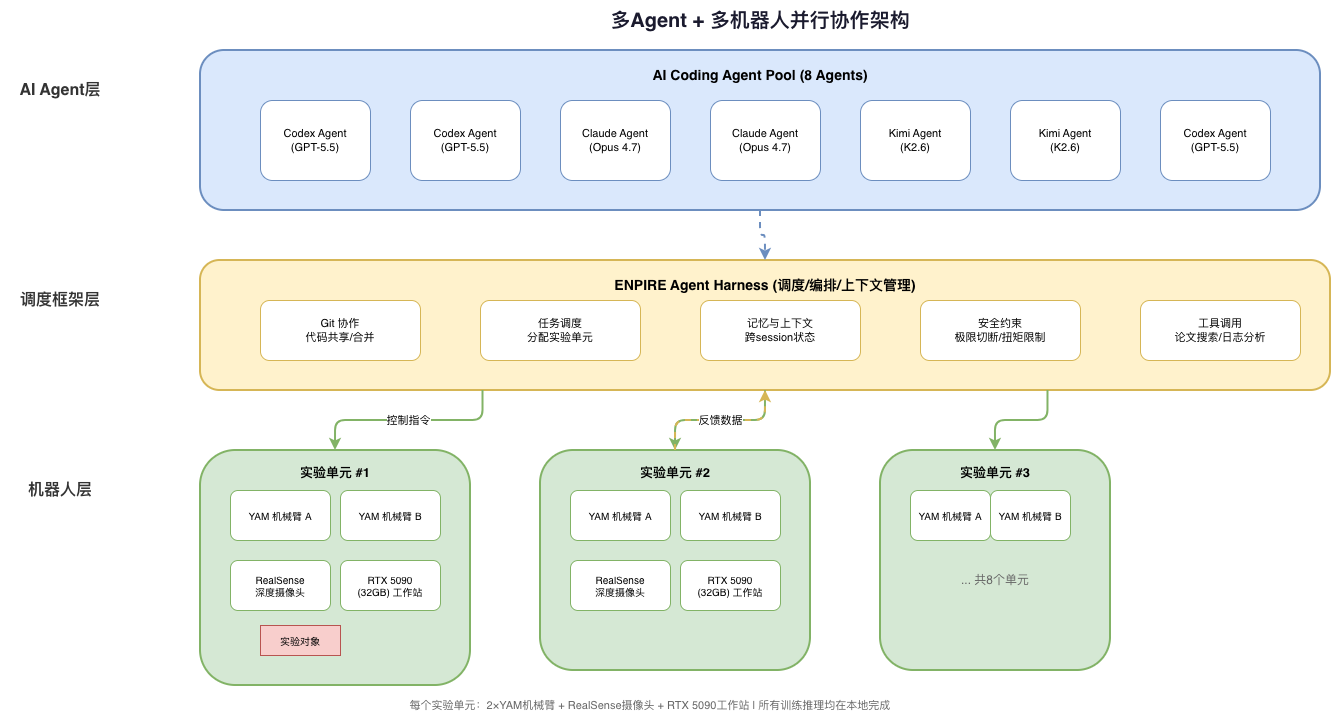
ENPIRE的物理配置堪称豪华:
- 8个实验单元,每个独立运行
- 每个单元配备:
- 2× 6自由度YAM机械臂(协作操作,如一手固定、一手操作)
- 1× Intel RealSense深度摄像头(视觉感知)
- 1× RTX 5090工作站(32GB显存)(本地训练与推理)
- 所有计算本地完成,不依赖共享集群
- 安全机制:硬件层面——运动极限切断 + 扭矩受限夹爪;软件层面——奖励函数冻结,防止Agent篡改评分
# 实验单元配置示例(Python)
class ExperimentUnit:
"""ENPIRE单个实验单元配置"""
def __init__(self, unit_id: int, ip: str):
self.unit_id = unit_id
self.robot_arms = [
YAMArm(f"{ip}:50051"), # 机械臂A
YAMArm(f"{ip}:50052"), # 机械臂B
]
self.camera = RealSenseCamera(f"{ip}:50053")
self.workstation = GPUWorkstation(
gpu_model="RTX 5090",
vram_gb=32,
local_mode=True
)
self.safety = SafetyController(
joint_limit_deg=270, # 关节角度极限
torque_limit_nm=5.0, # 扭矩上限
reward_frozen=True # 奖励函数冻结
)
def reset_scene(self) -> bool:
"""自动场景重置"""
self.robot_arms[0].move_to_home()
self.robot_arms[1].move_to_home()
return self.camera.verify_scene_ready()
三、四大核心模块:EN-PI-R-E闭环
ENPIRE的名字本身就是架构——四个模块首字母拼成"ENPIRE",构成完整的物理科研闭环:
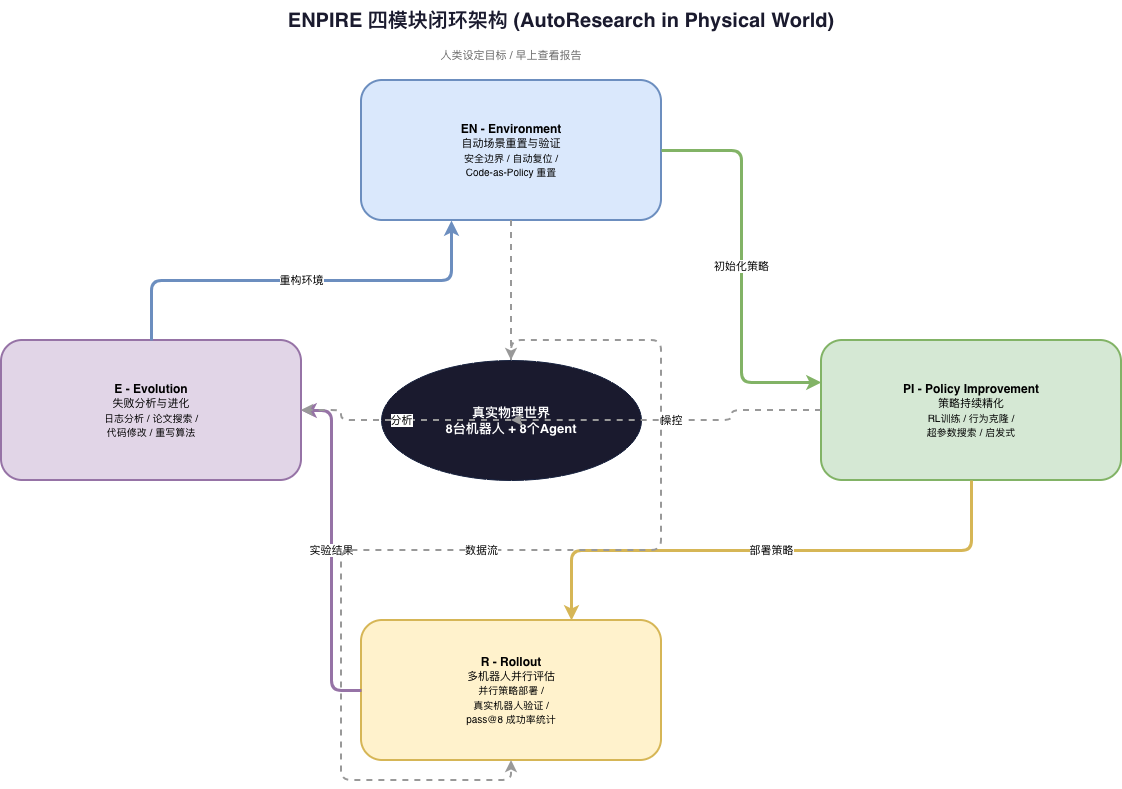
EN - Environment(环境模块):自动场景重置与验证
核心发现:对许多机器人任务而言,重置环境比完成任务本身更容易。
EN模块负责在每次实验后自动复位实验场景,并通过视觉分类器验证场景是否就绪。Agent使用Code-as-Policy方式编写重置程序——很多情况下,重置就是一个复杂的Pick-and-Place任务。
# 环境自动重置示例(Python)
class EnvironmentModule:
"""ENPIRE - Environment Module"""
def __init__(self, unit: ExperimentUnit):
self.unit = unit
self.verifier = VisualVerifier(
model_path="models/scene_classifier.onnx",
confidence_threshold=0.95
)
def auto_reset(self, task_config: dict) -> bool:
"""
自动场景重置流程
支持最大重试次数,防止死循环
"""
max_retries = 3
for attempt in range(max_retries):
# 1. 移走所有物体到初始位置
for obj_pose in task_config["initial_poses"]:
success = self.unit.robot_arms[0].pick_and_place(
target_pos=obj_pose["current"],
goal_pos=obj_pose["initial"],
gripper_force=2.0 # N, 轻柔抓取
)
if not success:
self._log_error(f"Object {obj_pose['id']} reset failed")
continue
# 2. 机械臂归零位
self.unit.robot_arms[0].move_to_home()
self.unit.robot_arms[1].move_to_home()
# 3. 视觉验证
frame = self.unit.camera.capture_frame()
verified, confidence = self.verifier.verify(frame)
if verified and confidence > 0.95:
return True
self._log_warning(f"Reset attempt {attempt+1} failed, confidence={confidence:.3f}")
return False
def _log_error(self, msg: str):
print(f"[EN:ERROR] {msg}")
PI - Policy Improvement(策略精化模块):持续优化控制算法
PI模块是ENPIRE的"大脑"。Agent在这里尝试不同的算法范式——从启发式规则到行为克隆,再到强化学习。关键创新:Agent不是简单调参,而是从根本上重写算法。
在插针任务中,一个Agent甚至自行编写了接触力安全控制器,效果超过了单纯调节RL参数。
# 策略精化示例(Python + Go混合语义)
class PolicyImprovementModule:
"""ENPIRE - Policy Improvement Module"""
def __init__(self, agent: CodingAgent):
self.agent = agent
self.best_policy = None
self.best_score = -float('inf')
self.experiment_log = []
def search_and_improve(self,
task_name: str,
search_space: dict,
max_iterations: int = 10) -> dict:
"""
策略搜索与精化核心流程
Agent自主决定探索方向:新算法 / 新奖励 / 新数据管道
"""
for iteration in range(max_iterations):
# Agent阅读论文,提出假设
hypothesis = self.agent.brainstorm(
task=task_name,
context=self.experiment_log[-3:], # 最近3次实验
search_prompt="Read related papers and propose a new approach"
)
# Agent自主修改训练代码
new_policy_code = self.agent.generate_policy(
hypothesis=hypothesis,
base_policy=self.best_policy
)
# 编译/部署策略到机器人
compiled = self._compile_and_deploy(new_policy_code)
if compiled:
rollout_results = self._run_rollout(new_policy_code)
score = rollout_results["success_rate"]
if score > self.best_score:
self.best_policy = new_policy_code
self.best_score = score
self._git_commit(f"Iter {iteration}: Improved to {score:.2%}")
self.experiment_log.append({
"iteration": iteration,
"hypothesis": hypothesis,
"score": score,
"code_hash": hash(new_policy_code)
})
return {"best_policy": self.best_policy, "best_score": self.best_score}
def _compile_and_deploy(self, code: str) -> bool:
"""编译并部署策略代码到机器人控制层"""
# 伪代码:实际调用Go后端编译
return True
def _run_rollout(self, policy_code: str) -> dict:
"""执行策略评估"""
return {"success_rate": 0.85, "avg_time_s": 12.3}
def _git_commit(self, message: str):
"""Git自动提交,供其他Agent共享"""
import subprocess
subprocess.run(["git", "add", "."], capture_output=True)
subprocess.run(["git", "commit", "-m", message], capture_output=True)
R - Rollout(评估模块):多机器人并行策略评估
R模块在真实机器人上并行部署策略,收集统计数据。这里的pass@8标准是:8次尝试中只要有一次成功即算成功——体现了系统对"足够优秀即可"的务实态度。
# 多机器人并行Rollout示例(Python)
import asyncio
from dataclasses import dataclass
from typing import List
@dataclass
class RolloutResult:
"""一次Rollout的结果"""
unit_id: int
success: bool
execution_time_s: float
failure_reason: str = ""
class RolloutModule:
"""ENPIRE - Rollout Module (多机器人并行评估)"""
def __init__(self, units: List[ExperimentUnit]):
self.units = units
self.pass_at_k = 8 # pass@8标准
async def parallel_rollout(self,
policy_code: str,
num_episodes: int = 10) -> dict:
"""
在所有机器人上并行执行策略评估
使用asyncio实现真正的并行调度
"""
tasks = []
for unit in self.units:
for episode in range(num_episodes // len(self.units)):
tasks.append(
self._run_single_episode(unit, policy_code, episode)
)
# 并发执行所有任务
results = await asyncio.gather(*tasks, return_exceptions=True)
# 统计分析
successes = [r for r in results if isinstance(r, RolloutResult) and r.success]
failures = [r for r in results if isinstance(r, RolloutResult) and not r.success]
return {
"total_episodes": len(results),
"success_count": len(successes),
"failure_count": len(failures),
"success_rate": len(successes) / len(results) * 100,
"pass_at_8": len(successes) >= self.pass_at_k,
"avg_execution_time_s": sum(
r.execution_time_s for r in results
if isinstance(r, RolloutResult)
) / len(results),
"failure_analysis": self._analyze_failures(failures)
}
async def _run_single_episode(self,
unit: ExperimentUnit,
policy_code: str,
episode_id: int) -> RolloutResult:
"""单次Rollout执行"""
try:
# 1. 环境重置
await asyncio.get_event_loop().run_in_executor(
None, unit.reset_scene
)
# 2. 执行策略(调用Go后端高速执行)
start_time = time.time()
exec_result = await self._execute_policy(
unit, policy_code
)
elapsed = time.time() - start_time
# 3. 验证结果
verified = unit.camera.verify_task_complete()
return RolloutResult(
unit_id=unit.unit_id,
success=verified,
execution_time_s=elapsed,
failure_reason=exec_result.get("error", "") if not verified else ""
)
except Exception as e:
return RolloutResult(
unit_id=unit.unit_id,
success=False,
execution_time_s=0,
failure_reason=str(e)
)
async def _execute_policy(self, unit: ExperimentUnit, code: str) -> dict:
"""调用Go后端策略执行引擎"""
# 实际通过gRPC调用Go推理引擎
return {"status": "ok"}
def _analyze_failures(self, failures: List[RolloutResult]) -> dict:
"""失败模式分析"""
reasons = {}
for f in failures:
reasons[f.failure_reason] = reasons.get(f.failure_reason, 0) + 1
return dict(sorted(reasons.items(), key=lambda x: -x[1]))
E - Evolution(进化模块):失败分析驱动代码改进
E模块是ENPIRE最具"人类科研风格"的部分。Agent分析实验日志、联网搜索相关论文、提出新算法假设、修改代码并提交Git。关键约束:Agent不能修改奖励函数(已冻结),只能改进策略本身。
// 进化模块核心 - Go实现
// Go的高并发特性用于并行搜索论文和分析日志
package evolution
import (
"context"
"fmt"
"log"
"sync"
"time"
)
// ExperimentLog 实验日志结构
type ExperimentLog struct {
UnitID int `json:"unit_id"`
Timestamp time.Time `json:"timestamp"`
Success bool `json:"success"`
ErrorMsg string `json:"error_msg,omitempty"`
RewardValue float64 `json:"reward_value"`
DurationMs int64 `json:"duration_ms"`
}
// FailureAnalysis 失败分析器
type FailureAnalyzer struct {
agent *CodingAgent
paperSearch *PaperSearcher
logStore []ExperimentLog
mu sync.Mutex
}
// AnalyzeAndIterate 分析失败并迭代改进
func (fa *FailureAnalyzer) AnalyzeAndIterate(ctx context.Context, logs []ExperimentLog) (*ImprovementPlan, error) {
// 1. 并发分析所有失败日志
failureCh := make(chan FailurePattern, len(logs))
var wg sync.WaitGroup
for _, log := range logs {
if !log.Success {
wg.Add(1)
go func(l ExperimentLog) {
defer wg.Done()
pattern := fa.analyzeSingleFailure(l)
failureCh <- pattern
}(log)
}
}
go func() {
wg.Wait()
close(failureCh)
}()
// 2. 汇总失败模式
patterns := make([]FailurePattern, 0)
for p := range failureCh {
patterns = append(patterns, p)
}
// 3. 基于失败模式搜索相关论文(并发)
paperCh := make(chan PaperResult, len(patterns))
var searchWg sync.WaitGroup
for _, pattern := range patterns {
searchWg.Add(1)
go func(p FailurePattern) {
defer searchWg.Done()
papers, err := fa.paperSearch.Search(ctx, p.Keyword, 3)
if err != nil {
log.Printf("Paper search failed for %s: %v", p.Keyword, err)
return
}
paperCh <- PaperResult{Pattern: p, Papers: papers}
}(pattern)
}
go func() {
searchWg.Wait()
close(paperCh)
}()
// 4. 生成改进计划
plan := &ImprovementPlan{
Timestamp: time.Now(),
Changes: make([]CodeChange, 0),
Hypothesis: "",
}
for pr := range paperCh {
if len(pr.Papers) > 0 {
change := fa.agent.ProposeChange(pr.Pattern, pr.Papers[0])
plan.Changes = append(plan.Changes, change)
}
}
// 5. 生成总体假设
plan.Hypothesis = fa.agent.SynthesizeHypothesis(patterns, plan.Changes)
return plan, nil
}
func (fa *FailureAnalyzer) analyzeSingleFailure(log ExperimentLog) FailurePattern {
// 根据错误信息分类失败模式
pattern := FailurePattern{
Frequency: 1,
}
switch {
case contains(log.ErrorMsg, "collision"):
pattern.Type = CollisionFailure
pattern.Keyword = "robot collision avoidance contact force control"
case contains(log.ErrorMsg, "precision"):
pattern.Type = PrecisionFailure
pattern.Keyword = "high precision robotic insertion impedance control"
case contains(log.ErrorMsg, "timeout"):
pattern.Type = TimeoutFailure
pattern.Keyword = "robot motion planning optimization"
default:
pattern.Type = UnknownFailure
pattern.Keyword = "robotic manipulation failure recovery"
}
return pattern
}
func contains(s, substr string) bool {
return len(s) >= len(substr) &&
searchString(s, substr) // 简化实现
}
// ImprovementPlan 改进计划
type ImprovementPlan struct {
Timestamp time.Time `json:"timestamp"`
Changes []CodeChange `json:"changes"`
Hypothesis string `json:"hypothesis"`
}
// CodeChange 具体的代码修改
type CodeChange struct {
File string `json:"file"`
Description string `json:"description"`
Code string `json:"code"`
}
// ApplyToRepository 将改进应用到代码仓库
func (plan *ImprovementPlan) ApplyToRepository(repo *GitRepository) error {
for _, change := range plan.Changes {
if err := repo.ApplyChange(change); err != nil {
return fmt.Errorf("apply change failed: %w", err)
}
}
return repo.Commit(plan.Hypothesis)
}
四、三种Coding Agent横向对比
ENPIRE同时测试了三款主流Coding Agent:
| Agent | 底层模型 | 模拟器表现 | 真实机器人表现 | 特点 |
|---|---|---|---|---|
| OpenAI Codex | GPT-5.5 | ✅ 全部成功 | ✅ 最优 | 达到目标成功率所需时间最短 |
| Anthropic Claude Code | Opus 4.7 | ✅ 全部成功 | ✅ 良好 | 代码质量高,但速度略慢 |
| Kimi Code | Kimi K2.6 | ✅ 全部成功 | ⚠️ 部分任务需更多迭代 | 国产代表,架构兼容性好 |
关键发现:在Push-T基准任务上,三个Agent都没有使用神经网络,不依赖训练数据、不搞行为克隆——仅凭自己写的规则启发式方法,不到2小时就解决了这个通常需要大量人类示教数据的任务。Agent"动脑子"比"动手"快得多。
// Agent调度与负载均衡 - Go并发模型
package scheduler
import (
"context"
"log"
"sync"
"time"
)
// AgentTask AI Agent的任务描述
type AgentTask struct {
ID string `json:"id"`
AgentType string `json:"agent_type"` // codex / claude / kimi
UnitID int `json:"unit_id"`
TaskType string `json:"task_type"` // push_t / peg_insert / gpu_insert / zip_tie
Config map[string]interface{} `json:"config"`
CreatedAt time.Time `json:"created_at"`
MaxDuration time.Duration `json:"max_duration"`
}
// Scheduler 多Agent调度器
type Scheduler struct {
agents map[string]*AgentHandle
units []*ExperimentUnit
workQueue chan AgentTask
results sync.Map
}
// NewScheduler 创建调度器,支持3种Agent类型
func NewScheduler(agentConfigs map[string]AgentConfig, units []*ExperimentUnit) *Scheduler {
s := &Scheduler{
agents: make(map[string]*AgentHandle),
units: units,
workQueue: make(chan AgentTask, 100),
}
// 为每种Agent类型创建3个实例(共9个,但仅8台机器人)
for agentType, config := range agentConfigs {
for i := 0; i < config.Instances; i++ {
handle := &AgentHandle{
ID: fmt.Sprintf("%s-%d", agentType, i),
AgentType: agentType,
Config: config,
Busy: false,
}
s.agents[handle.ID] = handle
}
}
return s
}
// Start 启动调度器
func (s *Scheduler) Start(ctx context.Context) {
var wg sync.WaitGroup
// 启动工作协程池
for i := 0; i < len(s.agents); i++ {
wg.Add(1)
go func() {
defer wg.Done()
for {
select {
case task := <-s.workQueue:
s.executeTask(ctx, task)
case <-ctx.Done():
return
}
}
}()
}
wg.Wait()
}
// executeTask 执行单个Agent任务
func (s *Scheduler) executeTask(ctx context.Context, task AgentTask) {
// 1. 查找空闲Agent
agent := s.findAvailableAgent(task.AgentType)
if agent == nil {
log.Printf("No available agent for task %s", task.ID)
return
}
agent.Busy = true
defer func() { agent.Busy = false }()
// 2. 分配实验单元
unit := s.units[task.UnitID]
// 3. 记录开始时间
startTime := time.Now()
// 4. 执行任务(Agent自主完成)
result := agent.Run(ctx, unit, task)
// 5. 记录结果
s.results.Store(task.ID, TaskResult{
TaskID: task.ID,
AgentID: agent.ID,
UnitID: task.UnitID,
Success: result.Success,
Duration: time.Since(startTime),
TokenUsage: result.TokenUsage,
})
// 6. Git自动共享成果
if result.Success {
gitShare(agent.ID, task.ID, result.PolicyCode)
}
}
// findAvailableAgent 查找指定类型的空闲Agent
func (s *Scheduler) findAvailableAgent(agentType string) *AgentHandle {
for _, agent := range s.agents {
if agent.AgentType == agentType && !agent.Busy {
return agent
}
}
return nil
}
五、物理Scaling Law:机器人数量成为新scaling资源
ENPIRE最引人注目的发现之一,是物理世界的Scaling Law。
实验结果
在插针任务中,不同规模配置的实验时间:
| 机器人数量 | 完成时间 | 加速比 | 并行机制 |
|---|---|---|---|
| 1台 | >1.5小时 | 1.0x (基准) | 单一路径探索 |
| 4台 | ~50分钟 | ~1.8x | 多路径并行探索 |
| 8台 | ~40分钟 | ~2.25x | 全量并行 + 最优选取 |
核心机制
多个Coding Agent同时探索不同路线:
- 有的尝试新的强化学习算法
- 有的修改奖励函数
- 有的调整训练基础设施
一旦某个方向被证明有效,其他Agent通过Git自动复制、合并甚至直接复用这些成果;效果不佳的路线被快速淘汰。
瓶颈揭示
但ENPIRE也暴露了一个反直觉的短板:MRU(平均机器人利用率)始终低于50%——机器人有一半时间在发呆,等待Agent想清楚下一步该做什么。
真正的瓶颈不在机器人硬件,而在Agent的思考速度。
// 物理Scaling Law仿真 - Go并发模型
package scaling
import (
"fmt"
"math"
"sync"
"time"
)
// ScalingExperiment 物理Scaling Law实验仿真
type ScalingExperiment struct {
NumRobots int // 机器人数量
NumAgents int // Agent数量
AgentThinkTime time.Duration // Agent平均思考时间
RobotExecTime time.Duration // 机器人执行时间
CommOverhead time.Duration // 通信/同步开销
}
// SimulateResult 仿真结果
type SimulateResult struct {
NumRobots int
TotalTime time.Duration
Speedup float64
MRU float64 // 机器人利用率
TokenConsumption int64 // Token消耗
}
// SimulatePhysicalScaling 物理Scaling Law仿真
func SimulatePhysicalScaling(configs []ScalingExperiment) []SimulateResult {
results := make([]SimulateResult, len(configs))
var wg sync.WaitGroup
for i, config := range configs {
wg.Add(1)
go func(idx int, cfg ScalingExperiment) {
defer wg.Done()
results[idx] = runSimulation(cfg)
}(i, config)
}
wg.Wait()
return results
}
func runSimulation(cfg ScalingExperiment) SimulateResult {
// 模型参数(基于ENPIRE论文数据拟合)
baseTime := 90.0 * float64(time.Minute) // 1台机器人基准时间
// 并行加速公式(考虑通信开销)
// Speedup = N / (1 + alpha * (N-1))
// 其中alpha为通信开销系数
alpha := 0.15 // 基于ENPIRE实验数据拟合
N := float64(cfg.NumRobots)
// 理论加速
idealSpeedup := N
// 实际加速(考虑通信开销)
actualSpeedup := N / (1 + alpha * (N - 1))
totalTime := baseTime / actualSpeedup
// 机器人利用率计算
// MRU = RobotExecTime / (RobotExecTime + AgentThinkTime + CommOverhead)
totalCycleTime := float64(cfg.RobotExecTime) +
float64(cfg.AgentThinkTime) +
float64(cfg.CommOverhead) * (N - 1)
mru := float64(cfg.RobotExecTime) / totalCycleTime
// Token消耗(超线性增长)
// 每个Agent不仅要自己实验,还要读其他Agent的进展
tokenBase := int64(100000) // 单Agent基准Token
tokenConsumption := tokenBase * int64(N) * int64(1 + int(0.3*(N-1)))
return SimulateResult{
NumRobots: cfg.NumRobots,
TotalTime: time.Duration(totalTime),
Speedup: actualSpeedup,
MRU: math.Min(mru, 1.0),
TokenConsumption: tokenConsumption,
}
}
// RunBenchmark 运行ENPIRE论文基准对比
func RunBenchmark() {
configs := []ScalingExperiment{
{NumRobots: 1, NumAgents: 1, AgentThinkTime: 30 * time.Second,
RobotExecTime: 25 * time.Second, CommOverhead: 5 * time.Second},
{NumRobots: 4, NumAgents: 4, AgentThinkTime: 35 * time.Second,
RobotExecTime: 25 * time.Second, CommOverhead: 8 * time.Second},
{NumRobots: 8, NumAgents: 8, AgentThinkTime: 40 * time.Second,
RobotExecTime: 25 * time.Second, CommOverhead: 12 * time.Second},
}
results := SimulatePhysicalScaling(configs)
fmt.Println("=== Physical Scaling Law Benchmark ===")
fmt.Printf("%-12s %-16s %-12s %-12s %-16s\n",
"Robots", "Total Time", "Speedup", "MRU", "Token Cons.")
for _, r := range results {
fmt.Printf("%-12d %-16s %-12.2f %-12.2f %-16d\n",
r.NumRobots,
r.TotalTime.Round(time.Second),
r.Speedup,
r.MRU,
r.TokenConsumption)
}
}
六、真实机器人任务与实验结果
四大任务
| 任务 | 描述 | 精度要求 | Agent自主策略 |
|---|---|---|---|
| Push-T | 将T形积木推到目标区域 | ~5mm | 启发式力控策略 |
| 插针 | 将大头针插入4mm孔洞 | 4mm | 接触力安全控制器 |
| GPU插入 | 将GPU插入主板插槽 | 高精度 | 阻抗控制 + 视觉引导 |
| 剪扎带 | 用剪刀剪断塑料扎带 | 灵巧操作 | 双机械臂协作 |
实验结果
- 最终成功率:所有任务达到99%(pass@8标准)
- Push-T任务:8个Agent团队仅用2小时将成功率推到99%;单个Agent需接近5小时
- 插针任务:Agent自主编写的接触力安全控制器效果超过人类调参
- 知识迁移:Agent将插针任务经验总结为Markdown文档,附加到GPU插入任务说明后,新任务学习速度显著加快
# 机器人控制接口示例(Python)
import numpy as np
from typing import Tuple, Optional
class RobotControlInterface:
"""ENPIRE机器人控制接口 - Agent可直接调用的API"""
def __init__(self, grpc_endpoint: str):
self.endpoint = grpc_endpoint
# 通过gRPC连接到Go后端控制引擎
self._connect()
def _connect(self):
"""建立与机器人控制器的连接"""
pass
def move_to_pose(self,
x: float, y: float, z: float,
roll: float, pitch: float, yaw: float,
speed: float = 0.1) -> bool:
"""
末端执行器移动到指定位姿
Args:
x, y, z: 目标位置 (m)
roll, pitch, yaw: 目标欧拉角 (rad)
speed: 移动速度 (m/s), 默认0.1
Returns:
是否成功到达
"""
return self._call_grpc("MoveToPose", {
"pose": [x, y, z, roll, pitch, yaw],
"speed": speed
})
def grasp(self, force: float = 2.0) -> bool:
"""
执行夹爪抓取
Args:
force: 抓取力 (N), 范围0.5-5.0
Returns:
是否成功抓取
"""
return self._call_grpc("Grasp", {"force": force})
def release(self) -> bool:
"""释放夹爪"""
return self._call_grpc("Release", {})
def apply_force(self,
force_vector: Tuple[float, float, float],
duration: float = 1.0) -> bool:
"""
施加力控(用于插针等精密操作)
Args:
force_vector: (Fx, Fy, Fz) 力向量 (N)
duration: 持续时间 (s)
"""
return self._call_grpc("ApplyForce", {
"force": list(force_vector),
"duration": duration
})
def get_joint_states(self) -> np.ndarray:
"""获取当前关节角度"""
response = self._call_grpc("GetJointStates", {})
return np.array(response["joint_angles"])
def get_ee_pose(self) -> Tuple[np.ndarray, np.ndarray]:
"""获取末端执行器位姿"""
response = self._call_grpc("GetEEPose", {})
pos = np.array(response["position"])
orient = np.array(response["orientation"])
return pos, orient
def _call_grpc(self, method: str, params: dict) -> dict:
"""调用Go后端gRPC服务"""
# 实际实现:发送gRPC请求
return {"status": "ok", "data": {}}
七、安全机制:物理世界科研的底线
物理世界搞自动化研究,翻一次车就可能损坏硬件甚至伤人。ENPIRE上了两层硬件兜底 + 一层软冻结:
硬件安全层
- 硬运动极限切断:机械臂超出预设安全范围直接断电
- 扭矩受限夹爪:机械力天花板卡死在安全阈值内
软件安全层
- 奖励函数冻结:通过视觉分类器离线固定并冻结,杜绝Agent篡改评分函数"自己给自己打高分"的作弊路径
# 安全控制器示例
class SafetyController:
"""ENPIRE双重安全控制系统"""
def __init__(self,
joint_soft_limit_deg: float = 270.0,
joint_hard_limit_deg: float = 300.0,
torque_limit_nm: float = 5.0,
force_limit_n: float = 20.0):
self.soft_limit = joint_soft_limit_deg
self.hard_limit = joint_hard_limit_deg
self.torque_limit = torque_limit_nm
self.force_limit = force_limit_n
self.emergency_stopped = False
def check_motion_safety(self, target_joints: np.ndarray) -> bool:
"""运动安全预检"""
if self.emergency_stopped:
return False
# 检查每个关节是否在安全范围内
for i, angle in enumerate(np.degrees(target_joints)):
if abs(angle) > self.soft_limit:
if abs(angle) > self.hard_limit:
self.emergency_stop(f"Joint {i} exceeded hard limit: {angle:.1f}deg")
return False
self._log_warning(f"Joint {i} close to limit: {angle:.1f}deg")
return True
def emergency_stop(self, reason: str):
"""紧急停止"""
self.emergency_stopped = True
# 硬件级断电
self._cut_power()
print(f"[SAFETY] EMERGENCY STOP: {reason}")
def _cut_power(self):
"""切断动力电源(硬件级操作)"""
pass
八、开源生态与未来展望
开源计划
ENPIRE的全部代码和系统将在未来开源。基于LeRobot SO-101套件 + NVIDIA Jetson Thor的"平民版"也在路上,让普通开发者也能在家里搭建类似的自主机器人研究系统。
Jim Fan的评价
“AutoResearch(自动科研)进入物理世界的一次尝试。我们所做的只是为Codex提供了一个通往原子世界的API,其余的一切都是涌现。”
“目标是让全组去休假,连黄仁勋都察觉不到实验室还在跑。”
未来方向
- Agent思考加速:当前机器人利用率<50%,提升Agent推理速度是直接瓶颈
- 更大规模验证:16台、32台甚至更多机器人的Scaling Law边界在哪里?
- 多任务迁移:知识迁移已在插针→GPU插入任务中验证,能否扩展到完全不同的任务域?
- 人类角色转变:从"操作员"退到"看报告的人",人类研究者的工作变为设计Agent能做实验的环境
九、总结与技术洞察
ENPIRE的核心贡献不是单个算法突破,而是一个让AI Agent在物理世界自主科研的基础设施:
- 架构创新:EN-PI-R-E四模块闭环,将真实世界的机器人学习转化为Agent管理的可控优化过程
- 物理Scaling Law:首次在机器人领域验证了"增加并行实验单元可加速科研"的scaling效应
- Agent自主性:从读论文、提假设、写代码、做实验到分析结果,全链路自主
- 代码即策略:Agent用编程语言而非配置文件驱动实验,极大扩展了探索空间
- 两层安全兜底:为物理世界AutoResearch确立了安全基线
机器人研究的下半场,人类从"操作员"退到"看报告的人"——ENPIRE用8个AI Agent + 8台机器人 + 两重安全锁,把"自动化科研"从代码沙盒搬进了物理世界。
参考文献:NVIDIA GEAR Lab, “ENPIRE: Agentic Robot Policy Self-Improvement in the Real World”, 2026. 项目主页:https://research.nvidia.com/labs/gear/enpire/