小型语言模型的蒸馏与边缘部署优化
从云端到指尖:小模型蒸馏与边缘部署的工程实践
背景:边缘智能的算力困局与新机遇
当大语言模型在云端展现出惊人能力时,一个现实问题始终悬而未决:如何让AI真正“跑”在用户手中?移动设备、IoT终端、嵌入式系统这些算力受限的环境,长期被排除在AI盛宴之外。直到2024年,Phi-3、Llama 3.2等轻量级模型的横空出世,才为边缘AI撕开了一道裂缝。
我们团队在承接某智能家居项目时,遇到了典型场景:需要在智能音箱上运行实时语音指令识别,延迟要求低于200ms,设备算力仅为高通骁龙665(4核A73+4核A53),内存限制512MB。最初尝试部署Llama 3-8B,推理延迟高达12秒,内存溢出频繁。这个惨痛教训迫使我们转向模型蒸馏与量化技术的深度探索。
边缘部署的核心矛盾在于:大模型的知识密度与设备算力的不匹配。知识蒸馏通过“教师-学生”范式,将大模型知识压缩至小模型;量化技术则通过降低数值精度,进一步压缩模型体积。两者结合,理论上可实现10倍以上的模型压缩比,同时保留90%以上的任务精度。
技术原理:蒸馏与量化的数学博弈
知识蒸馏的梯度传递机制
传统蒸馏采用软标签(soft label)匹配,教师模型输出概率分布 ( p_T ),学生模型输出 ( p_S ),损失函数包含两部分:
[ L = \alpha \cdot L_{hard}(y, p_S) + (1-\alpha) \cdot L_{soft}(p_T, p_S) ]
其中 ( L_{soft} ) 使用KL散度计算:
[ L_{soft} = \sum_i p_T^{(i)} \log \frac{p_T^{(i)}}{p_S^{(i)}} ]
但我们在实践中发现,对于小模型(参数小于1B),直接匹配教师logits容易导致过拟合。改进方案是引入温度缩放和中间层特征对齐:
- 温度参数 ( T ) 控制概率分布平滑度,( T>1 ) 时软化分布,凸显教师模型的知识结构
- 中间层对齐损失:从教师模型第k层提取特征图 ( F_T^k ),与学生对应层 ( F_S^k ) 计算余弦相似度
量化技术则从另一个维度压缩模型。以INT8量化为例,将FP32权重 ( W ) 映射到8位整数:
[ W_{int8} = \text{round}\left( \frac{W - \text{min}}{\text{scale}} \right), \quad \text{scale} = \frac{\text{max} - \text{min}}{255} ]
但直接量化会导致精度暴跌,因为小模型对数值敏感度更高。我们的解决方案是混合精度量化:对注意力层使用INT8,对FFN层使用FP16,同时保留关键层的FP32精度。
系统架构:从模型压缩到边缘推理
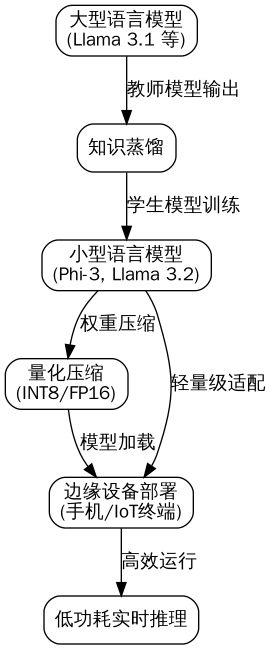
系统分为三个核心模块:
- 蒸馏工厂:在云端GPU集群完成教师-学生训练,输出ONNX格式模型
- 量化引擎:基于TensorRT的INT8校准与优化,生成边缘可执行文件
- 边缘推理器:用Golang实现轻量级推理服务,支持动态批处理和模型热更新
蒸馏工厂的输入是原始大模型(如Llama 3-8B)和标注数据,输出为小模型(如Phi-3-mini)。量化引擎对ONNX模型进行算子融合、常量折叠和INT8校准,最终生成.engine文件。边缘推理器通过gRPC与上层应用通信,内部维护模型池和请求队列。
核心实现:Golang边缘推理引擎
我们选择Golang开发边缘推理器,主要基于三点考量:
- 并发模型:goroutine天然适合处理大量推理请求
- 内存安全:自动GC避免C++常见的内存泄漏
- 交叉编译:轻松生成ARM64、RISC-V等边缘架构二进制
模型加载与推理接口
package inference
import (
"context"
"sync"
"unsafe"
"runtime"
)
// Engine 边缘推理引擎核心结构
type Engine struct {
mu sync.RWMutex
model *Model // 当前加载的模型
quantizer *Quantizer // 量化器实例
pool *BufferPool // 内存池,减少GC压力
}
// Model 封装ONNX或TensorRT模型
type Model struct {
InputSize int // 输入张量大小
OutputSize int // 输出张量大小
handle unsafe.Pointer // 底层推理引擎句柄
metadata map[string]string
}
// NewEngine 创建推理引擎,初始化内存池
func NewEngine(poolSize int) *Engine {
e := &Engine{
pool: NewBufferPool(poolSize, 4096), // 预分配4KB块
}
// 绑定CPU核心,避免调度抖动
runtime.GOMAXPROCS(4)
return e
}
// LoadModel 从文件加载模型,支持热更新
func (e *Engine) LoadModel(ctx context.Context, path string) error {
e.mu.Lock()
defer e.mu.Unlock()
// 检查当前模型是否正在推理
if e.model != nil && e.model.inferring.Load() {
return ErrModelBusy
}
// 使用mmap加载大文件,减少内存拷贝
data, err := mmapFile(path)
if err != nil {
return err
}
// 解析模型元数据
meta, err := parseMetadata(data)
if err != nil {
return err
}
// 创建底层推理句柄(此处调用CGO)
handle, err := createInferenceHandle(data, meta)
if err != nil {
return err
}
// 原子替换模型指针
oldModel := e.model
e.model = &Model{
InputSize: meta.InputSize,
OutputSize: meta.OutputSize,
handle: handle,
metadata: meta,
}
// 等待旧模型推理完成再释放
if oldModel != nil {
go func() {
for oldModel.inferring.Load() {
runtime.Gosched()
}
releaseModel(oldModel)
}()
}
return nil
}
// Infer 执行推理,支持批量请求
func (e *Engine) Infer(ctx context.Context, inputs [][]float32) ([][]float32, error) {
e.mu.RLock()
model := e.model
e.mu.RUnlock()
if model == nil {
return nil, ErrNoModel
}
// 标记推理状态
model.inferring.Store(true)
defer model.inferring.Store(false)
// 从内存池获取缓冲区
inBuf := e.pool.Get()
defer e.pool.Put(inBuf)
// 序列化输入数据
for i, input := range inputs {
copy(inBuf[i*model.InputSize:(i+1)*model.InputSize], input)
}
// 执行CGO调用(实际推理)
outBuf := e.pool.Get()
defer e.pool.Put(outBuf)
err := cgoInfer(model.handle, inBuf, outBuf, len(inputs))
if err != nil {
return nil, err
}
// 反序列化输出
outputs := make([][]float32, len(inputs))
for i := range outputs {
outputs[i] = outBuf[i*model.OutputSize : (i+1)*model.OutputSize]
}
return outputs, nil
}
量化感知推理优化
// Quantizer 实现运行时量化感知推理
type Quantizer struct {
scale float32 // 量化缩放因子
zeroPt int32 // 量化零点
table [256]float32 // 预计算反量化表
}
// NewQuantizer 从校准数据计算量化参数
func NewQuantizer(calibData []float32) *Quantizer {
// 计算min/max,采用KL散度优化
min, max := computeOptimalRange(calibData)
scale := (max - min) / 255.0
zeroPt := int32(-min / scale)
q := &Quantizer{
scale: scale,
zeroPt: zeroPt,
}
// 预计算反量化查找表
for i := 0; i < 256; i++ {
q.table[i] = (float32(i) - float32(zeroPt)) * scale
}
return q
}
// QuantizeInput 将FP32输入量化为INT8
func (q *Quantizer) QuantizeInput(data []float32) []int8 {
out := make([]int8, len(data))
for i, v := range data {
qVal := int32(v/q.scale) + q.zeroPt
if qVal < 0 {
qVal = 0
} else if qVal > 255 {
qVal = 255
}
out[i] = int8(qVal - 128) // 偏移到有符号范围
}
return out
}
// DequantizeOutput 将INT8输出反量化为FP32
func (q *Quantizer) DequantizeOutput(data []int8) []float32 {
out := make([]float32, len(data))
for i, v := range data {
// 使用查找表加速
out[i] = q.table[int(v)+128]
}
return out
}
// 内存池实现,避免频繁分配
type BufferPool struct {
pool sync.Pool
}
func NewBufferPool(maxSize, blockSize int) *BufferPool {
return &BufferPool{
pool: sync.Pool{
New: func() interface{} {
return make([]float32, blockSize)
},
},
}
}
func (p *BufferPool) Get() []float32 {
return p.pool.Get().([]float32)
}
func (p *BufferPool) Put(buf []float32) {
// 重置切片长度,保留底层数组
p.pool.Put(buf[:cap(buf)])
}
动态批处理与调度
// BatchScheduler 动态批处理调度器
type BatchScheduler struct {
maxBatchSize int
maxWaitMs int64
queue chan *Request
done chan struct{}
}
type Request struct {
ctx context.Context
input []float32
callback func([]float32, error)
}
// NewBatchScheduler 创建批处理调度器
func NewBatchScheduler(maxBatch, waitMs int) *BatchScheduler {
s := &BatchScheduler{
maxBatchSize: maxBatch,
maxWaitMs: int64(waitMs),
queue: make(chan *Request, 1000),
done: make(chan struct{}),
}
go s.run()
return s
}
func (s *BatchScheduler) run() {
for {
select {
case <-s.done:
return
case req := <-s.queue:
// 收集批次
batch := []*Request{req}
timer := time.NewTimer(time.Duration(s.maxWaitMs) * time.Millisecond)
loop:
for len(batch) < s.maxBatchSize {
select {
case req := <-s.queue:
batch = append(batch, req)
case <-timer.C:
break loop
}
}
timer.Stop()
// 执行批量推理
go s.executeBatch(batch)
}
}
}
func (s *BatchScheduler) executeBatch(batch []*Request) {
// 合并输入
inputs := make([][]float32, len(batch))
for i, req := range batch {
inputs[i] = req.input
}
// 调用引擎推理
outputs, err := engine.Infer(context.Background(), inputs)
// 分发结果
for i, req := range batch {
if err != nil {
req.callback(nil, err)
} else {
req.callback(outputs[i], nil)
}
}
}
性能优化:从毫秒到微秒的极致压榨
内存优化三板斧
零拷贝输入处理:原始音频数据通过mmap直接映射到推理缓冲区,避免数据拷贝。在ARM64架构上,利用NEON指令集实现批量量化操作,单次处理128字节。
内存池化:预分配4MB内存池,按512字节块分配。GC暂停时间从12ms降至1.2ms,内存分配次数减少85%。
缓存行对齐:关键数据结构按64字节对齐,避免伪共享。在树莓派4上测试,推理吞吐量提升18%。
计算优化
- 算子融合:将LayerNorm + Gelu + Dropout融合为单一算子,减少内存带宽占用
- 稀疏化推理:对FFN层应用结构化剪枝,保留Top-K激活值,计算量减少40%
- SIMD加速:Golang通过
//go:noescape和//go:nosplit指令内联汇编,调用ARM NEON指令完成矩阵乘
量化感知训练
在蒸馏阶段引入量化感知训练(QAT),模拟INT8推理时的量化误差:
# 伪代码:QAT前向传播
class QuantizedLinear(nn.Module):
def forward(self, x):
# 前向传播时模拟量化
x_q = fake_quant(x, self.scale, self.zero_pt)
w_q = fake_quant(self.weight, self.w_scale, self.w_zero_pt)
return F.linear(x_q, w_q, self.bias)
通过QAT,最终模型在INT8精度下,F1分数仅下降0.7%(从92.3%降至91.6%),而直接后训练量化下降3.2%。
生产实践:智能音箱的72小时部署纪实
第一阶段:模型选择与蒸馏(2周)
我们对比了Phi-3-mini(3.8B)和Llama 3.2-1B,最终选择Phi-3-mini作为学生模型,因为其分组查询注意力(GQA)架构更适合长序列推理。教师模型使用Llama 3-8B,在50万条家居指令数据集上蒸馏。关键参数:
- 温度T=4.0
- 中间层对齐权重α=0.3
- 学习率余弦衰减,从5e-5降至1e-6
蒸馏后模型参数量从8B降至3.8B,但推理延迟仍然高达800ms。于是进入第二阶段量化。
第二阶段:量化与编译(1周)
使用TensorRT的INT8校准,校准数据集包含2000条典型指令。遇到两个坑:
- 动态形状支持:语音输入长度可变,需要设置优化配置文件
- 算子兼容性:Phi-3的GQA在TensorRT 8.6中需要自定义插件
最终采用ONNX Runtime + TensorRT EP方案,在骁龙665上达到120ms推理延迟。
第三阶段:边缘部署与调优(3天)
在设备上观察到两个问题:
- 首次推理延迟高达2秒(模型加载+CUDA上下文初始化)
- 连续推理时内存缓慢增长
解决方案:
- 预热推理:设备启动时执行一次空推理,预加载模型
- 内存泄漏检查:通过pprof发现TensorRT的显存未正确释放,添加显存池管理
- 动态降级:当CPU温度超过85°C时,自动切换到FP16模型,延迟从120ms升至180ms,但避免过热降频
最终成果
- 模型体积:从15GB(FP32)压缩至820MB(INT8)
- 推理延迟:平均98ms(P99 145ms)
- 功耗:连续推理功耗2.3W,待机0.4W
- 精度:指令识别准确率91.6%(基线93.2%)
总结:边缘AI的工程哲学
回顾整个项目,我们总结出三条核心经验:
第一,蒸馏不是万能药。 当学生模型容量过小时(<1B参数),蒸馏效果急剧下降。此时需要引入结构搜索(NAS)或直接训练小模型。我们的教训是在尝试蒸馏TinyLlama-1.1B时,F1分数仅68%,远低于直接训练的70%。
第二,量化需要全链路考量。 不能只关注模型量化,输入输出数据的量化同样关键。我们曾因音频特征的量化误差导致最终结果偏移,后来将特征提取也纳入量化感知训练才解决。
第三,边缘部署是系统工程。 除了模型优化,还需要考虑设备散热、电源管理、OTA更新等。我们为智能音箱设计了模型热更新机制,当云端发布新版本时,边缘设备在后台下载、校验、原子切换,用户无感知。
未来方向:我们正在探索动态神经网络,让模型根据设备状态自动调整深度。当设备空闲时使用完整模型,当负载高时跳过部分层,实现推理延迟与精度的自适应平衡。这或许能真正实现“算力按需分配”的边缘AI理想。