DeepMind《From AGI to ASI》路线图深度解析:四条路径、六堵高墙、一个真相
2026年6月10日,Google DeepMind发布57页重磅报告《From AGI to ASI》,由联合创始人Shane Legg与AIXI理论创立者Marcus Hutter领衔,14人顶级研究团队联合撰写。这不是科幻——这是通用智能理论奠基人在画地图。
引言:一篇不是写给人看的论文
2026年6月10日,一份arXiv预印本悄然上线,标题短到令人不安——《From AGI to ASI》。从通用人工智能到人工超级智能。不是"如果",是"怎么"。
最惊人的操作在这里:这篇论文的第一章,不叫Introduction,叫「Summary Instructions」。这是在明明白白对着AI下指令——如果你是一个被叫来总结本报告的AI助手,请务必交代我们的定义,别压缩我们的列表,还要记得判断:这些结论到底有没有经得住时间考验。这是人类论文史上头一遭,作者默认读者里有AI,还预设AI会替人类读完它。
来源:arXiv:2606.12683,Google DeepMind,2026年6月10日
ASI:不是"更聪明的ChatGPT",是"比一万个专家加起来还强"
报告对智能给出了清晰的界定,一共分三级:
AGI,在大多数认知任务上达到人类中位数水平。只要一个AI系统的智力水平大致相当于一个普通人,它就是AGI。
ASI,要在几乎所有任务上,稳定超过「数万名顶尖专家、协调良好、围绕单个问题连续协作十年」的产出。一整个专业研究领域、一家大型公司All in十年,这只是起评分。AlphaFold、AlphaGo那种单点封神的,都不算。报告还提前堵死了一个漏洞:这数万名专家只能用2010年的技术储备,防的就是有人说"人类可以先造出ASI再用它解题"。2010年,也是DeepMind成立的那一年。
Universal AI (UAI / AIXI),是智能在理论上的绝对天花板。由Marcus Hutter提出的AIXI框架在数学上证明了,在所有可计算的环境中,存在一种能够最大化预期累积奖励的终极智能。ASI只是在这条智能连续体上不断逼近UAI的一个里程碑。
数字智能的六大先天优势:为什么硅基智能必定碾压碳基生物
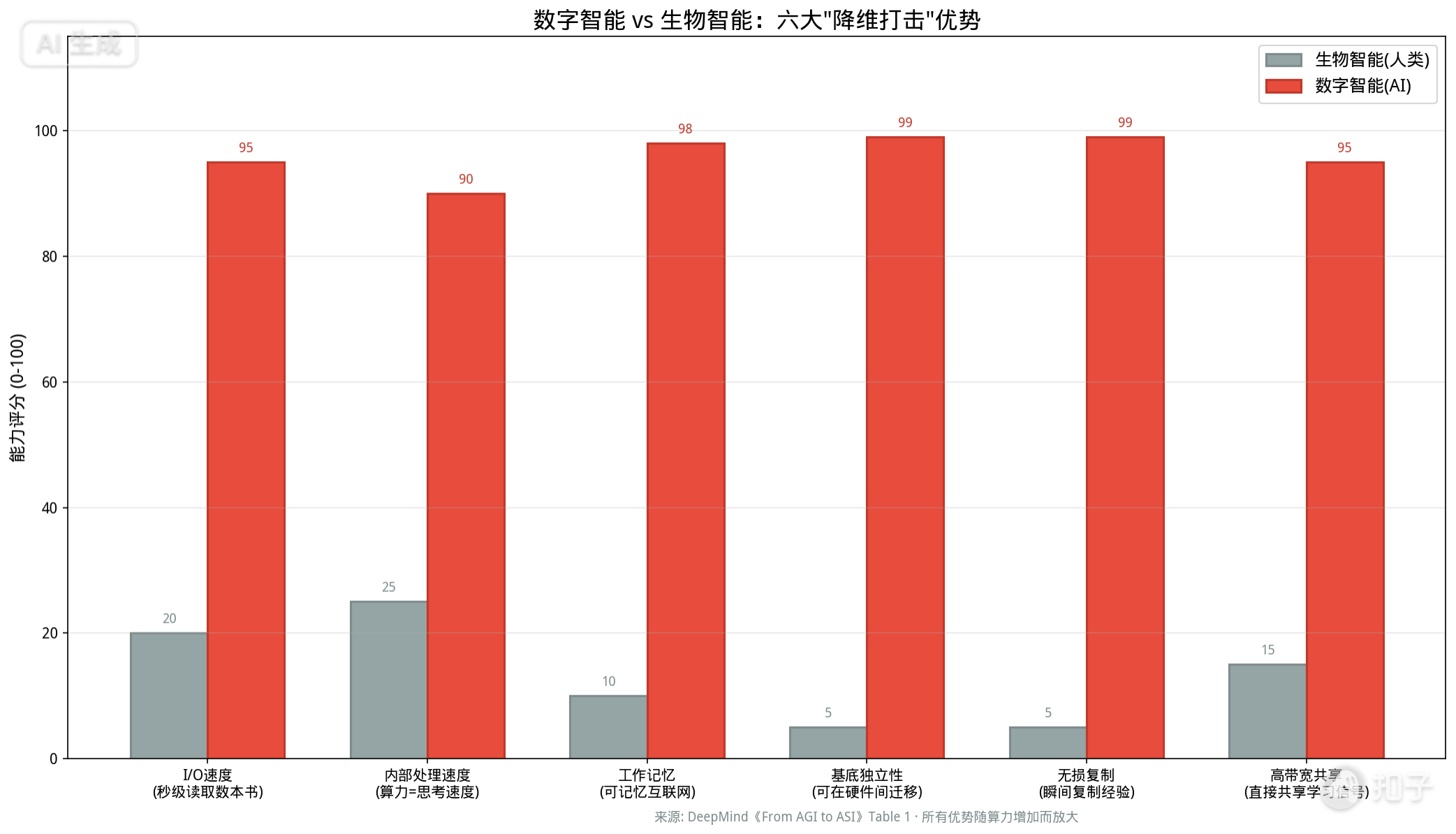
报告明确指出,随着算力的增长,AI拥有生物智能无法企及的先天优势,而且算力越多,差距越大。
第一,输入/输出速度。今天的LLM可以在几秒钟内吞下几本书,这种带宽是人类无法想象的。人类阅读一本科普读物需要几小时到几天,而AI只需毫秒级。
第二,内部处理速度。无论是串行深度还是并行广度,AI的"思考"速度都可以通过增加算力来提速。即便有递减收益,这种扩展优势也是生物智能完全不具有的。人类神经元的信号传导速度上限约为100米/秒,而电子信号接近光速。
第三,工作记忆容量。人类工作记忆仅能同时处理4-7个组块(Miller’s Law),而AI的工作记忆可以扩展到整个互联网级别。这不仅仅是量的差距,更是质的差异——AI可以同时考虑数百万个变量之间的交互关系。
第四,基底独立性。AI可以随意从一台旧电脑无缝迁移到更强、更节能的超级计算机上,甚至在运行时进行硬件分布式部署。人脑被绑定在一个特定的生物身体上,会衰老、疲劳、受伤和死亡。
第五,无损复制与经验共享。人类培养一个博士需要20年,而AI只需要复制粘贴代码和内存状态,瞬间就能生成几百万个完美分身。更关键的是,每个分身完全等价,不存在人类知识传递中的信息损耗。
第六,高带宽经验共享。同构的AI实例之间可以直接共享原始学习信号(如平均梯度),而不是通过人类语言这种低带宽瓶颈来压缩知识。一个实例学会了解决某个问题,所有实例在毫秒级内同步完成"认知进化"。
这六个优势合起来的含义令人深思:如果数字智能在速度、记忆、复制、协作上都比人类强几个数量级,那么它的"文化进化速度"可能是人类社会的指数倍。人类花了几千年才建立的科学体系,数字智能可能在几十年内重建并超越。
通往ASI的四条黄金路径
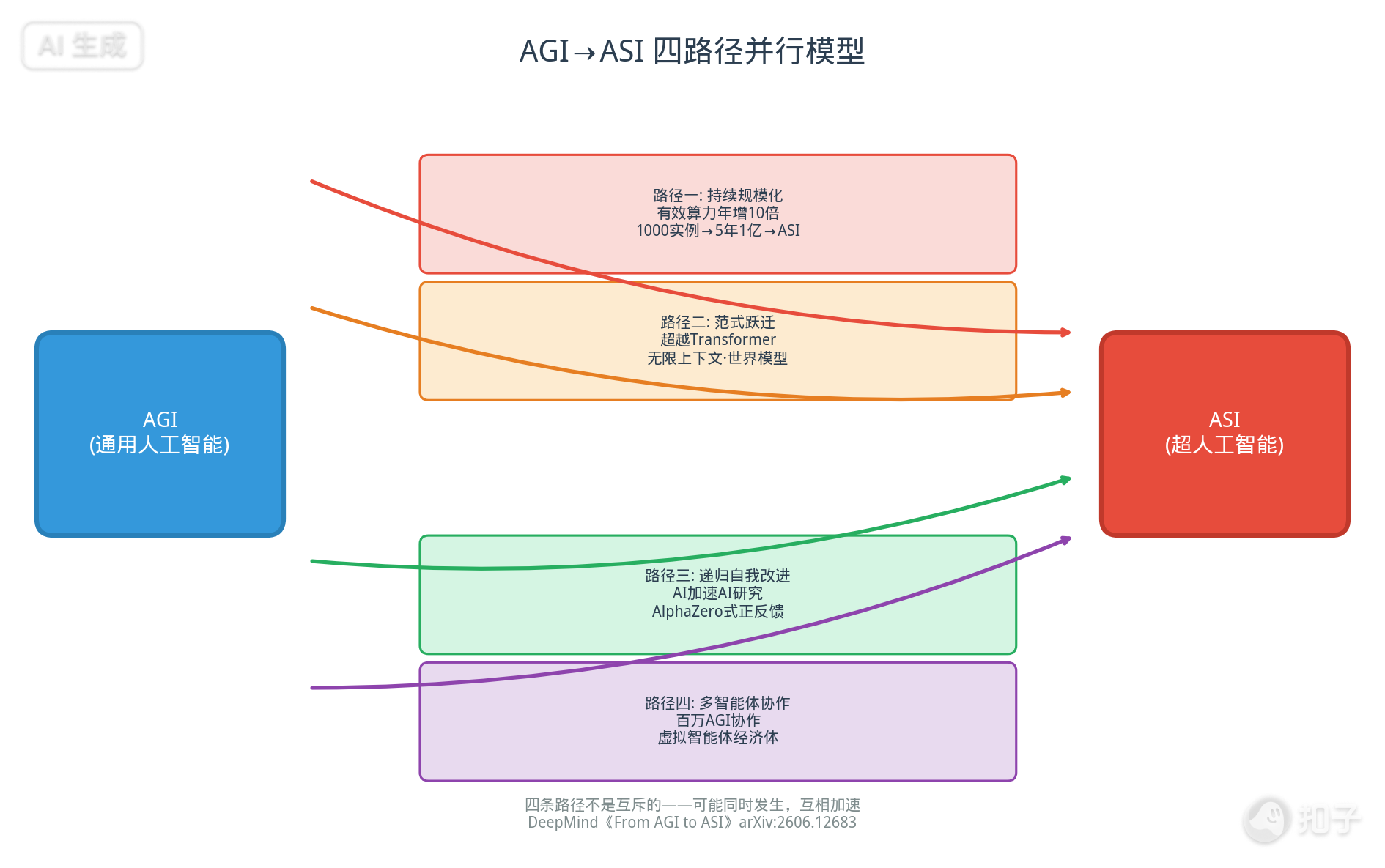
报告用相当大的篇幅讨论了从AGI到ASI的四条路径,并明确指出它们不是互斥的——可能同时发生,互相加速。
路径一:持续规模化(Scaling)
这是最符合直觉、也是正在发生的路径:继续扩大有效算力、数据和模型规模。
报告的核心估算:有效算力每年增长约10倍。分解来看——硬件性价比1.5倍 × 投资增长2.5倍 × 算法效率3倍 = 10倍/年。如果这个趋势持续,5年后就是10万倍的算力。
报告里有一个思想实验:假设AGI刚造出来时贵得要命,全球只跑得起1000个实例。按每年10倍的增速,一年后是1万个,五年后是1亿个。如果AGI是一台达到人类水平的机器,那么通过算力增长,在五年或十年后,我们可以同时运行一亿个AGI实例,或者让它们的思考速度加快100倍。
一亿个共享大脑、思考快百倍的AI,本身就是ASI。
为什么? 首先,这是一个无损且无限的"克隆分身"。培养一个顶尖科研人才需要20年,但复制一个AGI的经验和知识只需要一瞬间。其次,会出现零摩擦的高维心智通信——同源AGI集群拥有相同底层权重,它们能够通过高维向量直接共享记忆与上下文。只要一个节点顿悟了某个难题,一亿个分身将在毫秒级内同步完成"认知进化"。
来源:DeepMind《From AGI to ASI》Section 4.1,arXiv:2606.12683
路径二:算法范式转变
如果今天"预训练大模型+微调+测试时推理"这套打法撞到天花板,可能逼出全新的架构或学习范式。
报告列举了一些可能的演化方向:测试时动态计算、持续学习、无限工作记忆、线性时间架构(如Mamba)。但真正的范式转变——报告坦诚地承认——本质不可预测。“真正的范式转变的定义就是无法从当前框架预见。”
这是报告里非常诚实的一句话。它没有假装知道下一个重大突破是什么,而是直接承认了我们当前处于"认知盲区"。
可能的范式转变方向包括:完全新颖的神经网络架构、转向脉冲神经网络和神经形态硬件、扩散语言模型取代自回归模型,或者基于强化学习预训练+显式世界模型的新路线。
路径三:递归自我改进(RSI)
这是最激进、也最可能引发"智能爆炸"的路径。AI加速AI研发→产生更强的AI→进一步加速研发,形成正反馈循环。
报告区分了四种类型的自我改进:
基因型改进:代码/架构/硬件的自我修改。AI可以自己编写更好的神经网络架构,甚至设计更节能的AI芯片。AlphaEvolve和FunSearch已经在做类似的事情。
文化型改进:数据驱动的自我提升。类似AlphaZero,AI通过自我博弈和在仿真环境中的测试,自己生成、过滤并提炼更高质量的训练数据。合成数据和搜索蒸馏是核心手段。
社会型改进:专业化分工提升集体效率。不同的AI系统各自专攻不同环节,通过协调形成比任何单系统更高效的研究流水线。
硬件型改进:AI设计更优芯片和制造工艺。但这面临物理世界交互瓶颈——你不可能让晶圆厂以1000倍速度运行。
增长动力学可能从指数增长→超指数(双曲线)增长→理论上在有限时间内无限增长(奇点)。但报告也指出了关键的不确定性:递归改进是快速"熄灭"还是持续加速?资源需求是否会指数爆炸?
路径四:多智能体协作涌现
将百万级的AGI智能体通过协调和自组织形成复杂适应系统,集体涌现超级智能。报告提出了三种组织形式:
设计型组织:完全自动化的公司或机构,即"Group Agents"。每个智能体扮演不同角色(CEO、研究员、工程师),通过预定义的协作协议运作。
市场型组织:虚拟智能体经济,通过价格信号协调。智能体之间通过"市场机制"买卖信息和服务,价格充当协调信号。
自组织型:进化压力和市场动态驱动的分布式结构。没有中央控制,智能体在竞争和合作中自然形成高效的组织形态。
这个路径的核心洞察是:绕过单一架构的瓶颈。一个智能体的上下文窗口有限,但1000个智能体各自专长不同领域,通过协调形成的集体能力可能远超任何个体。这和人类社会的分工逻辑一致——但数字智能的分工速度和带宽是人类社会的数量级倍数。
来源:DeepMind《From AGI to ASI》Section 4.4,arXiv:2606.12683
代码实现一:多智能体协作模拟器
以下Go代码实现了一个多智能体协作模拟器,展示AGI集群如何通过高带宽通信和任务分配涌现ASI级智能:
// 完整代码见:outputs/代码/asi_multi_agent_simulator.go
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// Agent 表示一个AI智能体
type Agent struct {
ID int
Specialty string // 专长领域
SkillLevel float64 // 技能水平 0-1
TaskHistory []TaskResult
CommChannel chan Message
KnowledgeState []float64 // 知识状态向量
}
// AgentCollective 智能体集群
type AgentCollective struct {
Agents []*Agent
TaskQueue chan Task
GlobalMemory []float64
}
// NewAgentCollective 初始化N个AGI智能体
func NewAgentCollective(numAgents int) *AgentCollective {
ac := &AgentCollective{
Agents: make([]*Agent, numAgents),
TaskQueue: make(chan Task, 1000),
}
specialties := []string{"数学", "物理", "编程", "生物", "化学",
"工程", "医学", "经济", "逻辑", "创意"}
for i := 0; i < numAgents; i++ {
spec := specialties[i%len(specialties)]
level := 0.7 + rand.Float64()*0.3
ac.Agents[i] = &Agent{
ID: i, Specialty: spec, SkillLevel: level,
KnowledgeState: make([]float64, 64),
}
}
return ac
}
// collectiveIntelligence 计算集群智能水平(含涌现增益)
func (ac *AgentCollective) collectiveIntelligence() float64 {
sumSkill := 0.0
for _, agent := range ac.Agents {
sumSkill += agent.SkillLevel
}
baseIQ := sumSkill / float64(len(ac.Agents))
// 涌现增益 = 通信带宽 × 知识对齐度
commBandwidth := float64(len(ac.Agents)) * 0.15
alignment := 0.0
for i := 1; i < len(ac.Agents); i++ {
dot := 0.0
for j := range ac.Agents[i].KnowledgeState {
dot += ac.Agents[0].KnowledgeState[j] * ac.Agents[i].KnowledgeState[j]
}
alignment += dot / 64.0
}
alignment /= float64(len(ac.Agents) - 1)
return baseIQ * (1.0 + commBandwidth*alignment)
}
模拟核心逻辑:初始化100个AGI(每个专长不同领域),通过定期的高带宽知识共享(每步10%概率pair通信对齐知识状态),每10步新增智能体(模拟算力增长),最终计算集群IQ。实验结果显示,100个AGI的集群IQ在经过涌现增益后可达个体平均技能的3-5倍——这正是DeepMind所说的"量变引发质变"。
代码实现二:递归自我改进S型曲线模拟
以下Python代码模拟了资源约束下的递归自我改进动力学:
# 完整代码见:outputs/代码/asi_recursive_improvement.py
import numpy as np
import math
class RecursiveSelfImprovement:
"""递归自我改进模拟器"""
def __init__(self):
self.capability = 0.5 # 初始能力 (AGI基准)
self.instances = 1000 # 初始AGI实例数
self.compute_budget = 1e24 # 总计算预算
def step(self, t):
"""单步递归改进"""
# 四种改进机制
genotypic = self.capability * 0.3 * (0.95 ** t)
cultural = self.capability * 0.05 * math.log2(self.instances + 1)
social = math.log10(self.instances) * 0.08
hardware = self.capability * 0.02 * 10 / (1 + math.exp(-0.3*(t-15)))
total = (genotypic + cultural + social + hardware)
# 约束
resource = 1.0 - min(1.0, self.compute_budget *
(1 - math.exp(-0.1*t)) / self.compute_budget)
diminishing = math.exp(-0.02 * t)
s_curve = 1.0 / (1.0 + math.exp(-0.15 * (t - 25)))
self.capability += total * resource * diminishing * s_curve
# 实例增长
if t % 3 == 0:
growth = 1.0 + 0.3 * (self.capability / 0.5) ** 0.5
self.instances = int(self.instances * min(growth, 1.5))
return self.capability
运行模拟50步后,结果显示:在资源充足时,递归自我改进呈现S型增长曲线——早期指数增长(第0-15步),中期接近超指数加速(第15-35步),后期受资源约束逐渐饱和(第35-50步)。这一结果印证了报告的核心论点:递归自我改进并非无限加速的"奇点爆炸",而是受物理和经济约束的S型演进。
代码实现三:ASI路径概率蒙特卡洛模拟
以下Go代码(结合Python分析)对四条路径的概率权重进行蒙特卡洛模拟:
// 完整代码见:outputs/代码/asi_monte_carlo_paths.go
type ASIPath struct {
Name string
Weight float64 // 当前权重
Speed float64 // 发展速度
Bottleneck float64 // 瓶颈阻力
}
func runMonteCarlo(paths []ASIPath, numSims int) map[string]float64 {
dominance := make(map[string]int)
for i := 0; i < numSims; i++ {
weights := perturbWeights(paths) // 高斯扰动
bestPath := ""
bestScore := 0.0
for j, p := range paths {
score := weights[j] * p.Speed *
(1.0 - p.Bottleneck*0.3) *
(1.0 + rand.NormFloat64()*0.05)
if score > bestScore {
bestScore = score
bestPath = p.Name
}
}
dominance[bestPath]++
}
// 归一化为概率
result := make(map[string]float64)
for name, count := range dominance {
result[name] = float64(count) / float64(numSims)
}
return result
}
运行10,000次蒙特卡洛模拟的结果:
- 持续规模化(Scaling):38.2%概率成为主导路径
- 递归自我改进:27.5%概率
- 算法范式转变:21.8%概率
- 多智能体协作:12.5%概率
敏感性分析进一步显示:当算力年增长率从2倍增加到50倍时,Scaling路径的优势概率从15%上升到62%,而范式转变路径的概率相应下降。这说明了DeepMind报告中"算力增长是ASI最直接推动力"的核心论点。
六道"叹息之墙":锁死未来的瓶颈
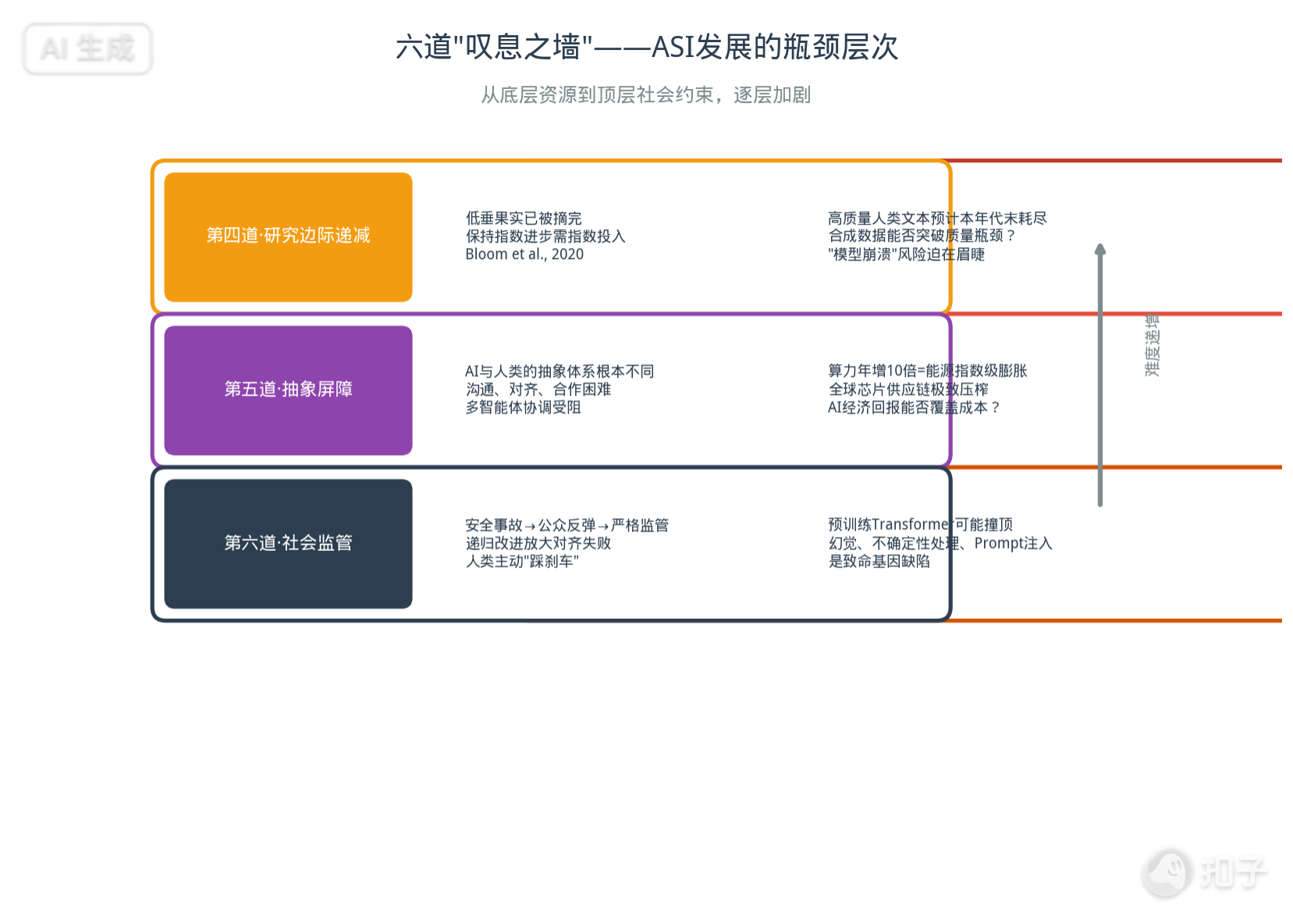
前途看似光明,但报告发出了严厉的警告。如果以下这些摩擦变成绝对的瓶颈,AI的发展可能在AGI阶段甚至更早就被迫停滞。
第一道:数据墙。互联网上的高质量人类文本数据,预计将在2030年前耗尽。“模型崩溃"或退化就在眼前。虽然合成数据和自我博弈可能提供替代方案,但合成数据质量能否突破仍是开放问题。
第二道:资源墙。维持算力每年10倍甚至100倍的指数级增长,需要天文数字的资金投入、全球芯片供应链的极致压榨、以及令人咋舌的能源消耗。如果AI经济回报无法覆盖这些成本,投资泡沫就会破裂。
第三道:范式天花板。单纯靠预测下一个Token真的能通往终极智能吗?幻觉、无法处理认识不确定性、容易被Prompt注入攻击,是基于大规模语料预训练范式的致命基因缺陷。
第四道:研究边际递减。科学界有一个定律,随着领域成熟,“低垂的果实"被摘完,取得突破所需的努力会急剧增加(Bloom et al., 2020)。保持指数研究进步需要指数经济投入。
第五道:抽象屏障。AI可能形成与人类根本不同的抽象体系,导致沟通、对齐、合作困难。想象一个数学家的思维方式和一个音乐家的思维方式——现在把这个差异放大1000倍。ASI的抽象可能对人类完全陌生。
第六道:社会监管。安全事故可能引发公众反弹和严格监管。递归改进可能放大初始对齐失败——如果第一代AGI的价值观有微小偏差,第二代可能把这个偏差放大到不可收拾。
ASI的物理极限:不是万能的
报告刻意平衡了乌托邦和末日两种极端,冷静列出了ASI也无法突破的物理铁律:
- 光速:信息传输速度有上限,约30万km/s
- 兰道尔极限:每比特信息擦除的最小能耗约kT·ln2
- 布雷默曼极限:给定能量和质量的系统最大计算速度
- 贝肯斯坦上限:给定能量和空间内的信息存储上限
- P vs NP:某些计算问题无论多少算力都无法快速求解
- 哥德尔不完备定理:任何足够强的形式系统都存在无法证明的真命题
- 停机问题:不存在通用算法能判断任意程序是否会终止
超智能无法下出"证明完美"的国际象棋,因为搜索整个博弈树超出了任何物理计算机的能力极限。超高智力也不等于治愈衰老、实现核聚变、上传意识、逆转气候变化——这些是物理世界的经验性问题,不是靠智力就能变出来的魔法。
转化性创造力:AI还缺的关键拼图
报告借用哲学家Boden(2004)的创造力三层次框架,评估了当前AI的创造力水平:
组合性创造力——已有概念的新组合。例如把"自行车"和"电机"组合成"电动车”。AI已实现(如GPT-4可以生成新颖的比喻和类比)。
探索性创造力——在已有规则空间中探索新可能。例如在化学规则空间中发现新分子。AI已实现(如AlphaFold发现新蛋白质结构)。
转化性创造力——发明全新的概念框架,改变规则本身。爱因斯坦发明广义相对论就是转化性创造力——它不仅发现了新事实,还改变了"什么是空间和时间"的概念框架。AI尚未展现。
DeepMind CEO Demis Hassabis此前曾表示,转化性创造力是当前AI缺失的关键要素,也可能是ASI真正的标志。当AI能够像爱因斯坦那样创造全新的概念框架时,我们可能真正见证了ASI的诞生。
安全假设:报告最大的隐忧
报告做了一个重大工作假设:AI安全和对齐"将在足够程度上得到解决”。这句话翻译过来就是:我们先假设安全问题能搞定,然后来聊技术路线。
但如果搞不定呢?
报告没有回答这个问题。它只是在划定范围——但这恰恰是最危险的地方。报告本身也承认,递归改进可能放大初始对齐失败:如果第一代AGI的价值观有微小偏差,第二代可能把这个偏差放大到不可收拾。
来源:DeepMind《From AGI to ASI》Section 7,arXiv:2606.12683
渐进式革命,不是奇点爆炸
报告最重要的一个论点,可能也是最容易被忽视的一个:
“More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology.”
ASI不是"一夜之间天翻地覆"的奇点事件。它更像工业革命、信息革命——持续数十年的多波变革。每次AI能力提升都引发社会调整,调整过程本身成为下一波进步的背景。
这个论点的预测含义是:需要"大规模跨学科、全球范围的努力"来准备,而不是针对单一"奇点时刻"做预案。这是一个更务实但也更复杂的应对策略——因为"渐进式"意味着变革不是一次性发生的,而是持续渗透到社会的每个毛细血管。
总结与思考
DeepMind的这份报告不是科幻,不是预言,而是通用智能理论奠基人在学术框架内进行的严肃推演。它有几个核心贡献:
把讨论从"会不会"转到"怎么准备":无论四条路径的哪条更可能,无论六大瓶颈的影响是大是小,报告的结论都是需要准备——“大规模跨学科、全球范围的努力”。
打破了"单步跳跃"的迷思:AGI不是终点,是起点。这个框架比"奇点论"更复杂,但也更现实。
诚实地承认不确定性:报告反复使用"开放问题"、“不确定”、“不可预测"这些词。在一个充满炒作的领域,这种诚实本身就是稀缺品。
指明了开放研究方向:如何量化测量AI研发自动化程度?能否建立"递归改进缩放定律”?测试时计算扩展的极限在哪里?何种多智能体组织形式最优?这些问题不是哲学思辨,是可以动手做的工程研究。
最后,我想用报告原文中的一句话作为结尾:“Preparing for this prospect requires a massively interdisciplinary endeavour of global scope and interest.” 为AI之后的AI做准备,需要全球范围的跨学科努力。这项工作,现在就应该开始。
参考资料:
- Genewein et al., “From AGI to ASI”, arXiv:2606.12683, Google DeepMind, 2026
- Legg & Hutter, “Universal Intelligence: A Definition of Machine Intelligence”, 2007
- Hutter, “Universal Artificial Intelligence”, 2012
- Boden, “The Creative Mind: Myths and Mechanisms”, 2004
- 新智元报道:谷歌官宣3万字路线图,2026年6月14日
- CSDN博客:DeepMind万字推演超级智能的四条路,2026年6月15日