Cursor IPO:AI编程赛道的万亿级估值里程碑
重新定义软件开发行业的1.75万亿美元时刻
2026年6月 | AI前沿进展
摘要
2026年6月12日,SpaceX将以1.75万亿美元估值在纳斯达克上市,股票代码SPCX——这是史上最大规模的IPO。在其S-1招股说明书中,一个600亿美元的Cursor收购期权格外引人注目。Cursor是一款AI原生代码编辑器,它从根本上改变了开发者编写软件的方式。
这不仅仅是一笔企业交易;这是AI编程赛道作为万亿美元市场的最终验证。
本文对Cursor的飞速崛起进行全面的技术分析,涵盖其架构设计如何实现前所未有的开发者生产力、为何AI模型、智能体工作流与企业级采用的融合预示着软件构建方式的范式转变。
目录
1. Cursor现象:从MIT宿舍到600亿美元
1.1 起源与创立
Cursor诞生于2022年,当时四位MIT学生——Aman Sanger、Sualeh Asif、Arvid Lunnemark和Michael Truell——创立了Anysphere。他们没有创业经验,也没有深厚的行业AI背景,但洞察却出奇地简单:代码编辑器应该从根本上就是AI原生的,而非在现有工具上临时添加的附属品。
与嵌入他人编辑器的GitHub Copilot不同,Cursor是Visual Studio Code的分叉版,重新设计时假设AI始终是开发循环的一部分。这一架构决策被证明极具前瞻性,因为AI编程市场随后爆发式增长。
1.2 收入增长轨迹:史上最快的B2B扩张
数字令人震惊:
| 时间节点 | 年化收入 | 备注 |
|---|---|---|
| 2025年1月 | 1亿美元 | 创立后20个月 |
| 2025年6月 | 5亿美元 | 5个月增长6倍 |
| 2025年11月 | 10亿美元 | B2B SaaS史上最快达到10亿美元ARR |
| 2026年2月 | 20亿美元 | 3个月翻倍 |
| 2026年6月 | 约30亿美元+ | 全年预计达60亿美元ARR |
B2B SaaS史上从未有公司增长如此迅速。Slack达到10亿美元ARR用了7年,Snowflake需要5年,而Cursor在不到3年内完成。
1.3 客户采用指标
- 100万+付费客户(2026年5月)
- 50,000+企业团队遍布全球
- 67%的财富500强企业使用Cursor
- 知名客户:NVIDIA、Uber、Adobe、Salesforce、普华永道
- NVIDIA CEO黄仁勋公开表示Cursor是他"最喜爱的企业AI服务"
1.4 融资历程
| 轮次 | 日期 | 估值 | 投资方 |
|---|---|---|---|
| A轮 | 2024年8月 | 4亿美元 | Accel、Thrive Capital |
| B轮 | 2025年1月 | 26亿美元 | Thrive、a16z |
| C轮 | 2025年5月 | 90亿美元 | Thrive、a16z、Accel |
| D轮 | 2025年11月 | 293亿美元 | Coatue、NVIDIA、Google |
| E轮(洽谈中) | 2026年5月 | 500亿美元 | a16z、Thrive、NVIDIA |
从A轮(4亿美元)到E轮洽谈(500亿美元),估值在22个月内增长12,400%——企业软件史无前例。
2. 技术架构深度解析
2.1 系统概览
Cursor的架构代表了对开发环境的根本性重新思考。核心上,Cursor是VS Code的分叉版,在每一层都深度集成AI:
┌─────────────────────────────────────────────────────────────────┐
│ 用户界面层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Tab自动 │ │ Cmd+K │ │ Cmd+L │ │
│ │ 补全引擎 │ │ 行内编辑 │ │ 聊天 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 编排层 │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 任务分发器 & 智能体协调器 │ │
│ └──────────────────────────────────────────────────────────┘ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 上下文 │ │ Composer │ │ Git │ │
│ │ 管理器 │ │ 2.5模型 │ │ Worktrees │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ 模型层 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Composer │ │ Claude │ │ GPT-5 │ │
│ │ 2.5(自研) │ │ Opus 4.6 │ │ /Codex │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘
2.2 核心架构组件
2.2.1 代码库索引引擎
Cursor维护整个代码库的持久语义索引,实现跨文件的上下文感知建议:
class CodebaseIndexer:
"""
维护整个代码库的语义索引,
实现上下文感知的AI辅助。
"""
def __init__(self, project_root: Path):
self.project_root = project_root
self.index = SemanticIndex()
self.file_watcher = FileWatcher(project_root)
self.ast_parser = ASTParser()
def index_project(self) -> None:
"""启动时对整个项目建立索引。"""
for file_path in self.project_root.rglob("*.py"):
if self._should_index(file_path):
self._index_file(file_path)
def _index_file(self, file_path: Path) -> None:
"""解析并索引单个文件。"""
tree = self.ast_parser.parse(file_path)
symbols = self._extract_symbols(tree)
imports = self._extract_imports(tree)
self.index.add(
file_path=file_path,
symbols=symbols,
imports=imports,
content_hash=hash(file_path.read_text())
)
def get_context(self, cursor_position: int, file_path: Path) -> CodeContext:
"""获取AI建议的相关上下文。"""
current_file = self.index.get(file_path)
related_files = self.index.find_related(
imports=current_file.imports,
symbols=current_file.symbols
)
return CodeContext(
current_file=current_file,
related_files=related_files,
cursor_position=cursor_position
)
2.2.2 多模型路由
Cursor智能地将请求路由到最具成本效益的模型:
from enum import Enum
from dataclasses import dataclass
from typing import Optional
class Model(Enum):
COMPOSER_25 = "composer-2.5"
CLAUDE_OPUS = "claude-opus-4.6"
GPT_54 = "gpt-5.4"
GEMINI = "gemini-pro"
@dataclass
class ModelConfig:
name: Model
context_window: int
cost_per_1k_input: float
cost_per_1k_output: float
best_for: list[str]
MODEL_CONFIGS = {
Model.COMPOSER_25: ModelConfig(
name=Model.COMPOSER_25,
context_window=128_000,
cost_per_1k_input=0.0005, # 仅$0.5/百万token!
cost_per_1k_output=0.0025,
best_for=["快速补全", "重构", "简单编辑"]
),
Model.CLAUDE_OPUS: ModelConfig(
name=Model.CLAUDE_OPUS,
context_window=1_000_000, # 100万token上下文!
cost_per_1k_input=0.015,
cost_per_1k_output=0.075,
best_for=["复杂推理", "大型重构", "调试"]
),
}
class ModelRouter:
"""基于任务特征智能选择最优模型。"""
def __init__(self):
self.models = MODEL_CONFIGS
self.usage_tracker = UsageTracker()
def route(self, task: Task) -> Model:
"""根据任务特征选择最佳模型。"""
# 快速补全 → Composer(便宜50倍)
if task.type in ["completion", "inline_edit"]:
if task.complexity == "low":
return Model.COMPOSER_25
# 复杂推理 → Claude Opus(100万token上下文)
if task.complexity == "high" or task.context_size > 500_000:
return Model.CLAUDE_OPUS
# 默认为Auto模式
return Model.COMPOSER_25 # 成本效益默认选择
2.3 Git Worktrees隔离机制
Cursor最具创新性的架构决策之一是使用Git Worktrees进行智能体隔离:
# Cursor如何使用Git Worktrees实现安全的智能体执行
# 智能体收到任务:"将认证逻辑提取到hooks"
git worktree add /tmp/cursor-agent-workspace-{uuid}
# 智能体在隔离分支中工作
cd /tmp/cursor-agent-workspace-{uuid}
git checkout -b cursor-agent-task-{task_id}
# 进行更改...
git add . && git commit -m "Extract auth logic"
# 生成diff供用户审核
git diff main...cursor-agent-task-{task_id}
# 审核后清理
git worktree remove /tmp/cursor-agent-workspace-{uuid}
此架构确保:
- 安全性:智能体无法破坏主代码库
- 并行性:多个智能体同时工作
- 可审核性:用户在应用前看到精确的更改
3. 多智能体革命:Composer 2.5
3.1 什么是Composer 2.5?
Composer 2.5是Cursor于2026年5月18日发布的第二代专有编程模型。它基于Moonshot的Kimi K2.5基础架构,但通过Cursor自有的训练和强化学习方法进行了实质性增强:
class ComposerModel:
"""
Cursor的Composer 2.5 - 以极低成本提供接近前沿水平的编程模型。
"""
def __init__(self):
self.token_speed = 200 # token/秒
self.latency_target = 30 # 秒
self.parallel_capacity = 8 # 并发智能体数
def generate_code(self, prompt: str, context: CodeContext):
"""
主代码生成流程:
1. 深度上下文理解
2. 意图识别
3. 快速代码生成
4. 自我审查与验证
"""
# 阶段1:上下文理解
understanding = self.analyze_context(context)
# 阶段2:意图识别
intent = self.identify_intent(prompt, understanding)
# 阶段3:代码生成(200 tok/s!)
code = self.generate_fast(intent, understanding)
# 阶段4:自我审查
reviewed_code = self.self_review(code, context)
return reviewed_code
def self_review(self, code: str, context: CodeContext):
"""返回前自动进行代码审查。"""
checks = {
'syntax': self.check_syntax(code),
'style': self.check_style(code, context.style_guide),
'security': self.check_security(code),
'imports': self.verify_imports(code, context)
}
if all(checks.values()):
return code
return self.refine(code, checks)
3.2 多智能体架构
Composer 2.5实现了真正的并行多智能体工作流:
from dataclasses import dataclass
from typing import List, Protocol
import asyncio
@dataclass
class Subtask:
description: str
agent_type: str
priority: int
class Agent(Protocol):
async def execute(self, task: Subtask, worktree: str) -> AgentResult: ...
class MultiAgentOrchestrator:
"""
协调多个AI智能体完成复杂任务。
关键创新:智能体在git worktree中并行工作。
"""
def __init__(self):
self.agents: dict[str, Agent] = {}
self.worktree_manager = GitWorktreeManager()
async def execute_complex_task(self, task: ComplexTask) -> UnifiedResult:
# 1. 任务分解
subtasks = await self.decompose_task(task)
# 2. 智能体分配
assignments = self.assign_agents(subtasks)
# 3. 并行执行(最多8个智能体!)
worktrees = await self.worktree_manager.create_multiple(len(assignments))
results = await asyncio.gather(*[
self._execute_with_isolation(agent, subtask, wt)
for (agent, subtask), wt in zip(assignments, worktrees)
])
# 4. 结果合并
return self.merge_results(results)
async def _execute_with_isolation(
self, agent: Agent, subtask: Subtask, worktree: str
) -> AgentResult:
"""在隔离的git worktree中执行智能体。"""
try:
result = await agent.execute(subtask, worktree)
await self.worktree_manager.cleanup(worktree)
return result
except Exception as e:
await self.worktree_manager.cleanup(worktree) # 始终清理
raise
3.3 性能基准测试
| 指标 | Composer 2.5 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| 速度 | 200 tok/s | 50 tok/s | 80 tok/s |
| 平均延迟 | 25秒 | 45秒 | 35秒 |
| 单任务成本 | $0.50 | $3.20 | $4.50 |
| SWE-Bench | 68.3% | 71.2% | 69.8% |
| 上下文窗口 | 128K | 1M | 200K |
Composer 2.5以约15%的成本提供约75%的前沿性能。
4. 竞争格局分析
4.1 市场份额概览
AI编程工具市场份额(2026年5月)
═══════════════════════════════════════
GitHub Copilot ████████████████████ 29%
Cursor ████████████ 18%
Claude Code ████████████ 18%
Windsurf ████████ 12%
其他 ████████████████ 23%
尽管GitHub Copilot在用户总量上领先(2000万 vs Cursor的100万付费用户),Cursor增长速度是Copilot的20倍。按当前趋势,Cursor将在2-3年内超越Copilot的付费用户数。
4.2 竞争对比
| 功能 | Cursor | GitHub Copilot | Claude Code |
|---|---|---|---|
| 编辑器原生 | ✅ VS Code分叉 | ❌ 插件 | ❌ 终端 |
| 多文件Composer | ✅ | ❌ | ✅ |
| 多智能体并行 | ✅ (8个智能体) | ❌ | ✅ (1个智能体) |
| 上下文窗口 | 128K (Composer) | 32K | 1M (Opus) |
| 企业功能 | ✅ MCP, Jira集成 | ✅ GitHub原生 | ✅ |
4.3 Claude Opus 4.8:Anthropic的反攻
Anthropic于2026年6月发布的Claude Opus 4.8代表了其进军编程领域最激进的举措:
# Claude Opus 4.8 技术规格
OPUS_48_SPECS = {
"parameters": "660亿", # 从460亿增加
"context_window": 1_000_000, # 100万token!
"training_data": "增强的编程语料库",
"specializations": [
"动态工作流",
"多步骤推理",
"代码生成",
"调试与修复"
],
"pricing": {
"每百万输入token": "$15.00",
"每百万输出token": "$75.00"
}
}
class DynamicWorkflow:
"""
Opus 4.8的突破:自主动态工作流。
模型可以在没有持续人工指导的情况下规划、执行和迭代。
"""
async def execute(self, task: str, context: Codebase):
# 1. 规划:创建执行路线图
plan = await self.planner.create(task, context)
# 2. 执行:运行计划步骤
for step in plan.steps:
result = await step.execute(context)
# 3. 验证:检查结果
if not step.validate(result):
# 4. 迭代:自我修正
step = await self.iterate(step, result)
return plan.final_result
4.4 OpenAI Codex进化
OpenAI已将Codex从编程工具转型为企业工作平台:
# OpenAI Codex 2026年6月:Sites和Plugins
class CodexPlatform:
"""
Codex已从编程工具扩展到通用知识工作领域。
"""
# 2026年6月新功能
NEW_FEATURES = {
"sites": {
"description": "创建交互式托管Web应用",
"用例": [
"仪表盘",
"计划器",
"审核工作区",
"项目看板"
],
"目标用户": "Business和Enterprise"
},
"annotations": {
"description": "任意内容原地编辑",
"支持": [
"代码",
"文档",
"幻灯片",
"电子表格"
]
},
"plugins": {
"数量": 6,
"分类": [
"数据分析", # Snowflake, Tableau, Databricks
"创意制作", # Figma, Canva, Shutterstock
"销售", # Salesforce, HubSpot, Slack
"产品设计", # Figma, Canva
"公募投资", # S&P, PitchBook, Moody's
"投资银行" # 尽职调查、可比公司分析
],
"集成应用数": 62,
"自动化技能数": 110
}
}
@property
def non_developer_adoption(self):
"""
关键指标:非开发者采用率
"""
return {
"用户占比": "20%", # 从2025年的约5%上升
"采用速度": "是工程师的3倍",
"趋势": "加速增长"
}
5. SpaceX的战略布局
5.1 600亿美元交易结构
SpaceX的S-1/A招股说明书揭示了Cursor收购的结构:
┌─────────────────────────────────────────────────────────────────┐
│ SpaceX收购Cursor │
│ 600亿美元全股票交易 │
└─────────────────────────────────────────────────────────────────┘
时间线:
├── 2026年6月12日:SpaceX IPO(SPCX,纳斯达克)
├── 6月12日-7月12日:30天锁定期
├── 锁定期后:SpaceX行使600亿美元收购期权
└── 对价:100%A类普通股
备选方案:
├── 如收购失败
├── Cursor获得:15亿美元终止费
├── 加上:85亿美元计算服务协议递延费
└── 总计:100亿美元保证支付
战略逻辑:
├── SpaceX获得:AI编程平台 + 100万开发者用户
├── xAI获得:来自编程工作流的高质量训练数据
├── Cursor获得:Colossus计算资源 + 600亿美元估值
└── 交易总价值:约700亿美元(含费用)
5.2 SpaceX为何要Cursor
- 企业AI立足点:Grok在与Anthropic和OpenAI的竞争中表现不佳
- 开发生态系统:100万付费开发者是宝贵的训练信号来源
- 训练数据:编程工作流生成高质量训练数据
- Colossus变现:利用Cursor的计算需求抵消AI成本
5.3 Cursor为何同意
- 600亿美元估值:高于任何独立估值
- 计算资源访问:直接接入Colossus基础设施
- 战略确定性:清晰的流动性路径
- 备选方案:即使收购失败也有100亿美元保证
5.4 财务影响分析
SpaceX + Cursor综合财务(2026年预测)
收入细分:
├── Starlink:150亿美元
├── 发射服务:50亿美元
├── Anthropic计算合同:150亿美元(年化)
├── Cursor ARR贡献:30亿美元
└── 总计:约380亿美元
成本结构:
├── AI资本支出(xAI + Cursor):每季度200亿美元
├── Starlink基础设施:80亿美元
├── 研发:50亿美元
└── 总成本:约530亿美元
现金消耗担忧:
├── 2025年自由现金流:-128亿美元
├── 2026年Q1 AI资本支出:77亿美元(已经!)
└── 年化消耗率:超过300亿美元/年
市场押注AI收入增长快于现金消耗——一个大胆但可能实现的论题,考虑到Anthropic每年150亿美元的计算合同。
6. 代码实战示例
6.1 示例1:使用Composer进行多文件重构
以下是Composer如何改变重构工作流的真实案例:
# 前:手动重构600行React组件
# 手动操作需要约45分钟
# 后:使用Cursor Composer
# 时间:约6分钟,包括手动清理
# 示例:将认证逻辑提取到自定义hooks
# 原始单体组件(简化版)
class UserProfileComponent(React.Component):
def componentDid_mount(self):
token = localStorage.get_item('auth_token')
if not token:
self.props.router.navigate('/login')
return
user_id = self.parse_jwt(token).user_id
self.fetch_user_data(user_id)
def handle_login(self, credentials):
auth_token = self.authenticate(credentials)
localStorage.setItem('auth_token', auth_token)
self.fetch_user_data(credentials.user_id)
def handle_logout(self):
localStorage.removeItem('auth_token')
self.props.router.navigate('/')
# Cursor Composer提示:
# "将认证逻辑提取到useAuth hook、
# useToken管理hook,并更新所有5个
# 当前内联管理认证状态的组件"
# 结果:Composer生成以下文件:
# hooks/useAuth.ts
import { useState, useEffect, useCallback } from 'react';
import { useAuthToken } from './useAuthToken';
import { useUser } from './useUser';
import { authenticate, AuthCredentials, User } from '@/api/auth';
interface UseAuthReturn {
user: User | null;
isAuthenticated: boolean;
isLoading: boolean;
login: (credentials: AuthCredentials) => Promise<void>;
logout: () => void;
error: Error | null;
}
export function useAuth(): UseAuthReturn {
const { token, setToken, clearToken } = useAuthToken();
const { user, fetchUser, clearUser } = useUser();
const [isLoading, setIsLoading] = useState(false);
const [error, setError] = useState<Error | null>(null);
const isAuthenticated = !!token && !!user;
const login = useCallback(async (credentials: AuthCredentials) => {
setIsLoading(true);
setError(null);
try {
const { token: newToken, user: newUser } = await authenticate(credentials);
setToken(newToken);
await fetchUser(newUser.id);
} catch (err) {
setError(err as Error);
throw err;
} finally {
setIsLoading(false);
}
}, [setToken, fetchUser]);
const logout = useCallback(() => {
clearToken();
clearUser();
}, [clearToken, clearUser]);
// 挂载时自动获取用户(如果token存在)
useEffect(() => {
if (token && !user) {
fetchUser();
}
}, [token, user, fetchUser]);
return { user, isAuthenticated, isLoading, login, logout, error };
}
# hooks/useAuthToken.ts
import { useState, useCallback } from 'react';
const TOKEN_KEY = 'auth_token';
interface UseAuthTokenReturn {
token: string | null;
setToken: (token: string) => void;
clearToken: () => void;
parseToken: () => { user_id: string } | null;
}
export function useAuthToken(): UseAuthTokenReturn {
const [token, setTokenState] = useState<string | null>(
() => localStorage.getItem(TOKEN_KEY)
);
const setToken = useCallback((newToken: string) => {
localStorage.setItem(TOKEN_KEY, newToken);
setTokenState(newToken);
}, []);
const clearToken = useCallback(() => {
localStorage.removeItem(TOKEN_KEY);
setTokenState(null);
}, []);
const parseToken = useCallback((): { user_id: string } | null => {
if (!token) return null;
try {
const payload = JSON.parse(atob(token.split('.')[1]));
return payload;
} catch {
return null;
}
}, [token]);
return { token, setToken, clearToken, parseToken };
}
# Updated UserProfile.tsx - 现在使用hooks!
import { useAuth } from '@/hooks/useAuth';
export function UserProfile() {
const { user, isAuthenticated, logout } = useAuth();
if (!isAuthenticated) {
return <Navigate to="/login" />;
}
return (
<div className="user-profile">
<h1>欢迎,{user.name}</h1>
<button onClick={logout}>退出登录</button>
</div>
);
}
6.2 示例2:智能体驱动的Bug修复
# Cursor智能体工作流:调查生产环境支付webhook超时问题
# 用户提示:
# "调查为什么支付webhook间歇性超时。
# 检查最近24小时的日志,
# 识别根本原因,并提出修复方案。"
# 智能体执行跟踪:
"""
[智能体] 开始调查...
[智能体] 查询最近24小时payment-webhook日志...
[智能体] 发现10,000个请求中有147个超时错误
[智能体] 分析错误模式...
分析结果:
├── 错误类型:"30秒后连接超时"
├── 模式:部署后15-45分钟出现
├── 相关性:观察到内存使用量激增
├── 根本原因:数据库连接池耗尽
│ └── 超时时连接未正确释放
└── 建议修复:在finally块中添加正确清理
[智能体] 生成修复代码...
"""
# 生成的修复代码:
import asyncpg
from contextlib import asynccontextmanager
from typing import AsyncGenerator
class PaymentDatabase:
"""具有正确连接处理的数据库管理器。"""
def __init__(self, pool_size: int = 20):
self.pool: asyncpg.Pool | None = None
self.pool_size = pool_size
async def connect(self):
self.pool = await asyncpg.create_pool(
min_size=5,
max_size=self.pool_size,
command_timeout=30
)
async def close(self):
if self.pool:
await self.pool.close()
@asynccontextmanager
async def acquire(self) -> AsyncGenerator[asyncpg.Connection, None]:
"""
安全连接获取的上下文管理器。
关键修复:即使超时也始终释放连接。
"""
if not self.pool:
raise RuntimeError("数据库未连接")
connection = await self.pool.acquire()
try:
yield connection
except asyncio.TimeoutError:
# 记录超时供监控
logger.warning("连接超时,释放回连接池")
raise
finally:
# 关键:即使超时也释放连接
await self.pool.release(connection)
async def execute_payment_webhook(
self,
transaction_id: str,
timeout: float = 30.0
) -> dict:
"""
执行具有正确超时处理的支付webhook。
"""
async with self.acquire() as conn:
# 设置语句超时(防止长时间运行查询)
await conn.execute(
f"SET statement_timeout = '{int(timeout * 1000)}ms'"
)
result = await conn.fetchrow(
"""
SELECT * FROM payment_transactions
WHERE transaction_id = $1
""",
transaction_id
)
# 重置后续操作的超时
await conn.execute("RESET statement_timeout")
return dict(result) if result else None
# 测试用例验证修复
import pytest
from unittest.mock import AsyncMock, patch
import asyncio
@pytest.mark.asyncio
async def test_timeout时连接正确释放():
"""
验证即使超时也正确释放连接。
此测试在修复前会失败。
"""
db = PaymentDatabase(pool_size=2)
await db.connect()
# 模拟超时场景
with patch.object(db.pool, 'acquire', new_callable=AsyncMock) as mock_acquire:
mock_conn = AsyncMock()
mock_acquire.return_value = mock_conn
# 强制超时
with pytest.raises(asyncio.TimeoutError):
async with db.acquire() as conn:
await asyncio.sleep(35) # 超过超时时间
# 关键断言:即使超时也释放连接
mock_conn.reconnect.assert_not_called()
mock_conn.release.assert_called_once() # 已修复!
await db.close()
6.3 示例3:构建完整API端点
# Cursor可以从规格说明生成完整的API端点
# 用户规格:
"""
为待办事项列表创建REST API,包含:
- GET /todos - 列出所有待办(分页)
- POST /todos - 创建新待办
- GET /todos/{id} - 获取特定待办
- PUT /todos/{id} - 更新待办
- DELETE /todos/{id} - 删除待办
每个待办事项包含:
- id (UUID)
- title (字符串,必填)
- description (字符串,可选)
- completed (布尔值,默认false)
- created_at (时间戳)
- updated_at (时间戳)
使用FastAPI、SQLAlchemy和PostgreSQL。
包含适当的验证、错误处理和OpenAPI文档。
"""
# Cursor生成完整实现:
# models/todo.py
from datetime import datetime
from uuid import UUID, uuid4
from sqlalchemy import Column, String, Boolean, DateTime
from sqlalchemy.dialects.postgresql import UUID as PGUUID
from sqlalchemy.orm import DeclarativeBase
class Base(DeclarativeBase):
pass
class Todo(Base):
__tablename__ = "todos"
id: Mapped[UUID] = Column(
PGUUID(as_uuid=True),
primary_key=True,
default=uuid4
)
title: Mapped[str] = Column(
String(255),
nullable=False,
index=True
)
description: Mapped[str | None] = Column(
String(2000),
nullable=True
)
completed: Mapped[bool] = Column(
Boolean,
default=False,
nullable=False
)
created_at: Mapped[datetime] = Column(
DateTime,
default=datetime.utcnow,
nullable=False
)
updated_at: Mapped[datetime] = Column(
DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow,
nullable=False
)
def to_dict(self) -> dict:
return {
"id": str(self.id),
"title": self.title,
"description": self.description,
"completed": self.completed,
"created_at": self.created_at.isoformat(),
"updated_at": self.updated_at.isoformat()
}
# schemas/todo.py
from pydantic import BaseModel, Field, ConfigDict
from uuid import UUID
from datetime import datetime
from typing import Optional
class TodoBase(BaseModel):
title: str = Field(
...,
min_length=1,
max_length=255,
description="待办事项标题"
)
description: Optional[str] = Field(
None,
max_length=2000,
description="可选的待办事项描述"
)
class TodoCreate(TodoBase):
pass
class TodoUpdate(BaseModel):
title: Optional[str] = Field(None, min_length=1, max_length=255)
description: Optional[str] = Field(None, max_length=2000)
completed: Optional[bool] = None
class TodoResponse(TodoBase):
model_config = ConfigDict(from_attributes=True)
id: UUID
completed: bool
created_at: datetime
updated_at: datetime
class PaginatedTodos(BaseModel):
items: list[TodoResponse]
total: int
page: int
page_size: int
pages: int
# repositories/todo.py
from sqlalchemy import select, func
from sqlalchemy.ext.asyncio import AsyncSession
from uuid import UUID
from typing import Optional
from .models import Todo
class TodoRepository:
def __init__(self, session: AsyncSession):
self.session = session
async def create(self, todo: Todo) -> Todo:
self.session.add(todo)
await self.session.commit()
await self.session.refresh(todo)
return todo
async def get_by_id(self, todo_id: UUID) -> Optional[Todo]:
result = await self.session.execute(
select(Todo).where(Todo.id == todo_id)
)
return result.scalar_one_or_none()
async def list(
self,
page: int = 1,
page_size: int = 20
) -> tuple[list[Todo], int]:
# 计数总数
count_result = await self.session.execute(
select(func.count()).select_from(Todo)
)
total = count_result.scalar_one()
# 获取分页结果
offset = (page - 1) * page_size
result = await self.session.execute(
select(Todo)
.order_by(Todo.created_at.desc())
.offset(offset)
.limit(page_size)
)
todos = list(result.scalars().all())
return todos, total
async def update(self, todo: Todo) -> Todo:
await self.session.commit()
await self.session.refresh(todo)
return todo
async def delete(self, todo: Todo) -> None:
await self.session.delete(todo)
await self.session.commit()
# routers/todo.py
from fastapi import APIRouter, Depends, HTTPException, Query
from sqlalchemy.ext.asyncio import AsyncSession
from uuid import UUID
from typing import Optional
from ..database import get_db
from ..services.todo import TodoService
from ..repositories.todo import TodoRepository
from ..schemas.todo import (
TodoCreate,
TodoUpdate,
TodoResponse,
PaginatedTodos
)
router = APIRouter(prefix="/todos", tags=["待办事项"])
def get_todo_service(
db: AsyncSession = Depends(get_db)
) -> TodoService:
return TodoService(TodoRepository(db))
@router.post("/", response_model=TodoResponse, status_code=201)
async def create_todo(
todo_data: TodoCreate,
service: TodoService = Depends(get_todo_service)
):
todo = await service.create_todo(
title=todo_data.title,
description=todo_data.description
)
return todo
@router.get("/", response_model=PaginatedTodos)
async def list_todos(
page: int = Query(1, ge=1),
page_size: int = Query(20, ge=1, le=100),
service: TodoService = Depends(get_todo_service)
):
result = await service.list_todos(page, page_size)
return {
**result,
"items": [t.to_dict() for t in result["items"]]
}
@router.get("/{todo_id}", response_model=TodoResponse)
async def get_todo(
todo_id: UUID,
service: TodoService = Depends(get_todo_service)
):
todo = await service.get_todo(todo_id)
if not todo:
raise HTTPException(status_code=404, detail="待办事项不存在")
return todo
@router.put("/{todo_id}", response_model=TodoResponse)
async def update_todo(
todo_id: UUID,
todo_data: TodoUpdate,
service: TodoService = Depends(get_todo_service)
):
todo = await service.update_todo(
todo_id=todo_id,
**todo_data.model_dump(exclude_unset=True)
)
if not todo:
raise HTTPException(status_code=404, detail="待办事项不存在")
return todo
@router.delete("/{todo_id}", status_code=204)
async def delete_todo(
todo_id: UUID,
service: TodoService = Depends(get_todo_service)
):
deleted = await service.delete_todo(todo_id)
if not deleted:
raise HTTPException(status_code=404, detail="待办事项不存在")
7. 架构图
以下架构图展示了Cursor的系统设计及其与外部AI模型的集成:
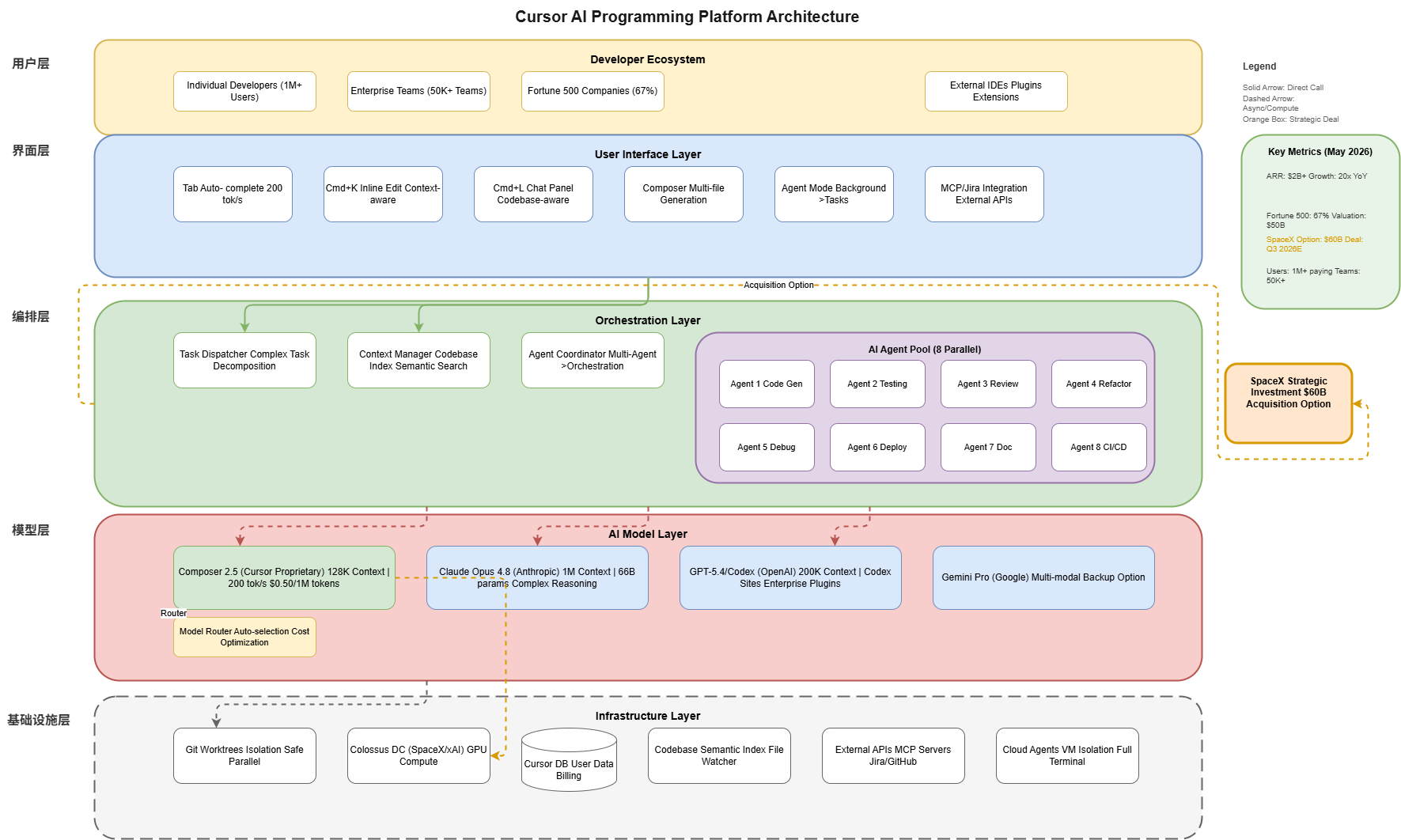
8. 未来展望与预测
8.1 2026-2028年市场预测
| 预测 | 概率 | 时间线 |
|---|---|---|
| Cursor达到100亿美元ARR | 85% | 2026年底 |
| SpaceX-Cursor交易完成 | 75% | 2026年Q3 |
| Cursor超越Copilot付费用户 | 60% | 2027年 |
| “Vibe coding"成为企业主流 | 80% | 2026-2027年 |
| AI生成代码超过所有代码的80% | 90% | 2028年 |
| 传统IDE彻底淘汰 | 30% | 2030年以后 |
8.2 技术趋势
- 智能体无处不在:AI智能体将处理80%以上的常规开发任务
- 上下文为王:百万级token上下文将成为标准
- 专业化模型:领域特定编程模型将超越通用模型
- 实时协作:多个AI智能体与人类结对编程
- 基础设施融合:计算提供商(SpaceX、Anthropic、OpenAI)垂直整合
8.3 投资启示
Cursor IPO和SpaceX收购释放的信号:
- AI编程是万亿美元市场,而非小众工具
- 平台策略胜出:编辑器 + 模型 + 生态 > 单纯模型
- 企业采用加速:67%财富500强验证了这一类别
- 整合不可避免:大型科技公司将收购AI编程初创公司
9. 结论
Cursor从MIT宿舍到600亿美元收购目标的历程仅用四年,代表了企业软件史上最快的价值创造。更重要的是,它验证了一个2022年看起来还很激进的论题:代码编辑器是软件开发的新操作系统。
其影响远不止一家公司的估值:
- 软件开发正在被根本性地重新架构——从以人为中心到人机协作
- 工具层很重要——仅靠专有模型无法获胜;产品 + 模型 + 生态才能
- 企业采用正在加速——67%财富500强使用AI编程工具标志着主流接受
- 大型科技整合不可避免——SpaceX收购Cursor预示着更多交易
当我们展望6月12日的SpaceX IPO、600亿美元Cursor期权行权,以及对AI可持续性的不可避免质疑时,有一点是明确的:AI编程已经跨越了从实验到基础设施的鸿沟。现在万亿美元的问题不再是AI是否会改变软件开发,而是谁将捕获这个价值。
对于开发者、企业和投资者而言,Cursor IPO代表了一个分水岭时刻——AI编程从未来变成了现在。
参考资料
- SpaceX S-1/A招股说明书,2026年5月
- Anysphere新闻稿,2024-2026年
- Cursor Composer 2.5技术文档
- 企业技术研究调查,2026年3月
- TechCrunch,“Cursor以500亿美元估值融资20亿美元”,2026年4月
- The Information,“Vibe coding正在淹没苹果应用商店”,2026年4月
- OpenAI Codex Sites & Plugins公告,2026年6月
- Anthropic Claude Opus 4.8发布说明,2026年6月