多模态大模型的统一架构突破
从分立到统一:多模态大模型架构的演进与实践
背景介绍
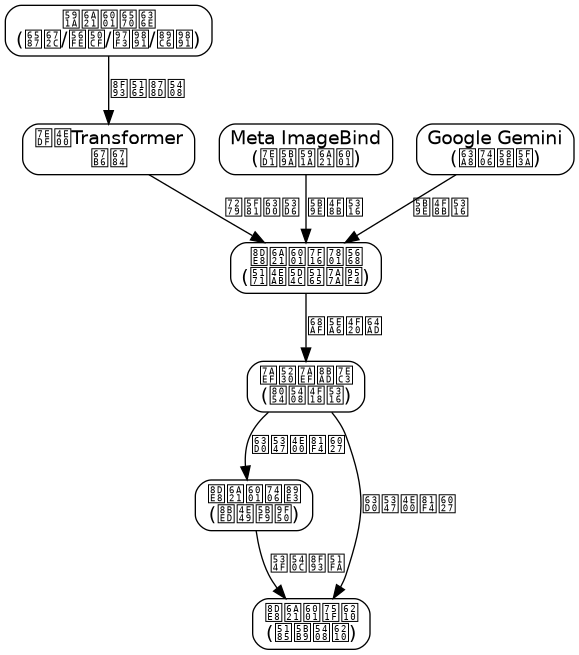
在人工智能发展的漫长历程中,我们曾长期致力于让机器理解单一模态的信息——文本、图像、语音或视频。然而,人类对世界的感知从来都是多通道的:我们阅读文字时脑海中会浮现画面,听到声音时会联想场景,观看视频时会理解语义。这种跨模态的认知能力,正是当前AI系统所追求的终极目标之一。
传统多模态系统通常采用“拼凑式”架构:为每种模态训练独立的编码器,再通过后期融合(Late Fusion)或注意力机制将特征拼接。这种设计存在根本性缺陷——模态间的信息对齐依赖于人工设计的接口,导致跨模态理解存在语义鸿沟。例如,一个文本描述“红色的苹果”与一张苹果图像,在独立编码器中的特征空间可能完全不同,即使通过线性变换映射到同一维度,也难以保证语义一致性。
2023年以来,多模态大模型领域迎来突破性进展。Meta发布的ImageBind模型首次实现了六种模态(图像、文本、音频、深度、热成像、IMU数据)的统一嵌入空间,无需配对数据即可实现跨模态对齐。Google的Gemini模型则展示了强大的多模态推理能力,能够在文本、图像、音频、视频和代码之间进行流畅的推理和生成。这些突破的共同点在于:放弃模态特异性设计,采用统一的Transformer架构进行端到端训练。
这种范式转变的背后,是深度学习理论的重要进展。研究表明,当模型参数规模超过一定阈值(约70B参数),多模态数据中的共享语义结构会被自动捕获,无需显式的模态对齐模块。这意味着,我们不再需要为每种模态设计复杂的编码器,而是让Transformer在大量多模态数据上自学习跨模态表示。
技术原理
统一嵌入空间的核心机制
多模态统一架构的基石在于构建共享的嵌入空间。传统方法中,文本使用BERT/RoBERTa,图像使用ViT/ResNet,音频使用HuBERT/Wav2Vec,每种模型将输入映射到各自的潜在空间。统一架构则要求所有模态共享同一个嵌入空间,即对于语义相同的概念,无论以何种模态呈现,其嵌入向量应尽可能接近。
实现这一目标的关键技术包括:
模态对齐损失函数:在训练过程中,我们不仅需要最小化预测误差,还需要最小化不同模态中相同语义的嵌入距离。常用的损失函数包括对比损失(Contrastive Loss)和三元组损失(Triplet Loss)。以ImageBind为例,它使用“绑定”机制——将图像作为锚点,所有其他模态通过图像进行对齐。对于给定的图像-文本对,损失函数为:
L = -log(exp(sim(I,T)/τ) / Σexp(sim(I,T_j)/τ))
其中sim表示余弦相似度,τ是温度参数。
跨模态注意力:在Transformer内部,通过跨模态注意力机制实现不同模态信息的交互。具体来说,每个token在自注意力计算时,可以关注到其他模态的token。例如,在处理视频时,文本token可以关注到视觉token和音频token,从而实现多模态融合。
动态路由机制:对于多模态输入,不同模态对最终决策的贡献可能不同。动态路由机制允许模型根据输入内容自适应地调整各模态的权重。例如,在识别“狗叫”这一概念时,音频模态的权重应高于视觉模态;而在识别“红色汽车”时,视觉模态更为重要。
位置编码的模态适应性
Transformer的位置编码在处理多模态数据时面临挑战:不同模态的数据具有不同的结构特性。文本是一维序列,图像是二维网格,视频是三维时空,音频是一维时间序列。统一架构需要一种能够适应所有模态结构的位置编码方案。
一种有效的解决方案是可学习的位置编码:为每种模态单独学习位置编码,并在训练过程中与模型参数一起优化。具体实现时,我们可以为文本、图像、音频、视频分别定义不同的位置编码表,在输入阶段将对应的位置编码加到token嵌入上。
更先进的方法如旋转位置编码(RoPE),通过旋转矩阵对位置信息进行编码,具有相对位置感知能力,且易于扩展到不同维度。在统一架构中,我们可以将不同模态的位置编码统一表示为:
PE(x, y, z, t) = f_rot(x) ⊕ f_rot(y) ⊕ f_rot(z) ⊕ f_rot(t)
其中⊕表示向量拼接,对于文本只有x维度,图像有x,y维度,视频有x,y,t维度,音频只有t维度。
模态标记与统一分词
不同模态的数据在输入Transformer前需要被转换为token序列。统一架构要求所有模态的token具有相同的表示形式,通常是一个固定维度的向量序列。
文本模态:使用SentencePiece或BPE分词器将文本转换为token ID,再通过嵌入层转换为向量。
图像模态:将图像分割为固定大小的patch(如16x16像素),每个patch通过线性投影转换为向量。这与ViT(Vision Transformer)的处理方式一致。
音频模态:将音频信号转换为频谱图(如mel频谱),再类似图像处理方式分割为patch。或者使用原始波形,通过1D卷积转换为token。
视频模态:将视频帧序列作为独立图像处理,每帧生成一组patch token,再加上时间位置编码。
所有模态的token最终拼接成一个长序列,输入到统一的Transformer中。为了区分模态,我们可以在token嵌入中加入模态类型嵌入(Modality Type Embedding),类似于BERT中的Segment Embedding。
系统架构设计
整体架构概述
基于上述原理,我们设计一个统一的多模态大模型系统架构。该系统采用分层设计,从上到下包括:
- 多模态输入层:接收并预处理文本、图像、音频、视频数据
- 统一编码层:将不同模态数据转换为统一token序列
- 跨模态Transformer层:核心计算层,实现多模态信息的深度交互
- 任务适配层:根据下游任务输出相应格式的结果
- 训练与推理引擎:提供分布式训练和高效推理支持
数据流设计
系统处理多模态输入的数据流如下:
- 输入接收:API网关接收包含多种模态的请求,如“请描述这张图片中的场景,并说明背景音乐的情绪”
- 模态识别与预处理:系统自动识别输入中的模态类型,对图像进行尺寸标准化(224x224),音频重采样(16kHz),视频抽帧(每秒1帧)
- 统一分词:各模态数据通过对应的分词器转换为token序列,并添加模态标识和位置编码
- 序列拼接:所有token按固定顺序拼接(文本→图像→音频→视频),形成统一的输入序列
- Transformer计算:输入序列经过多层Transformer编码,生成上下文感知的表示
- 任务解码:根据任务类型(文本生成、图像描述、语音识别等),使用对应的解码头输出结果
训练架构设计
训练架构采用数据并行与模型并行相结合的策略:
- 数据并行:多GPU/TPU上复制完整模型,每个设备处理不同的batch
- 张量并行:单个Transformer层内,将注意力头分布到不同设备
- 流水线并行:将Transformer层按深度分割到不同设备
对于多模态数据,我们设计了模态平衡采样器,确保每个batch中不同模态的数据比例均衡。同时,采用渐进式训练策略:第一阶段使用单模态数据预训练(文本+图像),第二阶段引入音频和视频数据,第三阶段进行多模态对齐微调。
核心实现
下面我们使用Golang实现一个简化的多模态统一Transformer模型。代码包含核心的数据结构、前向传播和训练逻辑。
package multimodal
import (
"encoding/binary"
"fmt"
"math"
"math/rand"
"sync"
)
// 多模态Transformer配置
type MultiModalConfig struct {
HiddenDim int // 隐藏层维度
NumLayers int // Transformer层数
NumHeads int // 注意力头数
MaxSeqLen int // 最大序列长度
VocabSize int // 词表大小
ImagePatchDim int // 图像patch维度
AudioFreqDim int // 音频频率维度
DropoutRate float64 // Dropout概率
}
// 模态类型枚举
type Modality int
const (
ModalityText Modality = 0
ModalityImage Modality = 1
ModalityAudio Modality = 2
ModalityVideo Modality = 3
)
// 多模态Token结构
type MultiModalToken struct {
Embedding []float64 // Token嵌入向量
ModalityType Modality // 模态类型
Position int // 位置索引
IsSpecial bool // 是否为特殊token
}
// 多模态编码器
type MultiModalEncoder struct {
Config *MultiModalConfig
TextEmbed *EmbeddingLayer // 文本嵌入层
ImageEmbed *PatchEmbedLayer // 图像patch嵌入层
AudioEmbed *PatchEmbedLayer // 音频patch嵌入层
VideoEmbed *PatchEmbedLayer // 视频帧嵌入层
ModalityEmbed *EmbeddingLayer // 模态类型嵌入
PositionEmbed *EmbeddingLayer // 位置编码嵌入
TransformerLayers []*TransformerLayer // Transformer层
LayerNorm *LayerNorm // 层归一化
OutputProj *LinearLayer // 输出投影
}
// 创建新的多模态编码器
func NewMultiModalEncoder(config *MultiModalConfig) *MultiModalEncoder {
encoder := &MultiModalEncoder{
Config: config,
TextEmbed: NewEmbeddingLayer(config.VocabSize, config.HiddenDim),
ImageEmbed: NewPatchEmbedLayer(config.ImagePatchDim, config.HiddenDim),
AudioEmbed: NewPatchEmbedLayer(config.AudioFreqDim, config.HiddenDim),
VideoEmbed: NewPatchEmbedLayer(config.ImagePatchDim*3, config.HiddenDim), // 视频考虑时间维度
ModalityEmbed: NewEmbeddingLayer(4, config.HiddenDim), // 4种模态
PositionEmbed: NewEmbeddingLayer(config.MaxSeqLen, config.HiddenDim),
LayerNorm: NewLayerNorm(config.HiddenDim),
OutputProj: NewLinearLayer(config.HiddenDim, config.HiddenDim),
}
// 初始化Transformer层
encoder.TransformerLayers = make([]*TransformerLayer, config.NumLayers)
for i := 0; i < config.NumLayers; i++ {
encoder.TransformerLayers[i] = NewTransformerLayer(config)
}
return encoder
}
// 前向传播:将多模态输入编码为统一表示
func (e *MultiModalEncoder) Forward(inputs []MultiModalToken) ([]float64, error) {
if len(inputs) == 0 {
return nil, fmt.Errorf("empty input sequence")
}
if len(inputs) > e.Config.MaxSeqLen {
return nil, fmt.Errorf("sequence length %d exceeds max %d", len(inputs), e.Config.MaxSeqLen)
}
// 1. 获取每个token的嵌入
seqLen := len(inputs)
hiddenStates := make([][]float64, seqLen)
for i, token := range inputs {
var tokenEmbed []float64
switch token.ModalityType {
case ModalityText:
tokenEmbed = e.TextEmbed.Forward(int(token.Embedding[0]))
case ModalityImage:
tokenEmbed = e.ImageEmbed.Forward(token.Embedding)
case ModalityAudio:
tokenEmbed = e.AudioEmbed.Forward(token.Embedding)
case ModalityVideo:
tokenEmbed = e.VideoEmbed.Forward(token.Embedding)
default:
return nil, fmt.Errorf("unknown modality type: %v", token.ModalityType)
}
// 2. 添加模态类型嵌入
modalityEmbed := e.ModalityEmbed.Forward(int(token.ModalityType))
for j := 0; j < len(tokenEmbed); j++ {
tokenEmbed[j] += modalityEmbed[j]
}
// 3. 添加位置编码
posEmbed := e.PositionEmbed.Forward(token.Position)
for j := 0; j < len(tokenEmbed); j++ {
tokenEmbed[j] += posEmbed[j]
}
hiddenStates[i] = tokenEmbed
}
// 4. 通过所有Transformer层
for _, layer := range e.TransformerLayers {
var err error
hiddenStates, err = layer.Forward(hiddenStates)
if err != nil {
return nil, fmt.Errorf("transformer layer error: %v", err)
}
}
// 5. 最终层归一化和投影
output := make([]float64, e.Config.HiddenDim)
for _, state := range hiddenStates {
normalized := e.LayerNorm.Forward(state)
projected := e.OutputProj.Forward(normalized)
for j := 0; j < len(output); j++ {
output[j] += projected[j]
}
}
// 取平均作为序列表示
for j := 0; j < len(output); j++ {
output[j] /= float64(seqLen)
}
return output, nil
}
// Transformer层
type TransformerLayer struct {
Config *MultiModalConfig
SelfAttn *MultiHeadAttention
CrossAttn *MultiHeadAttention // 跨模态注意力
FFN *FeedForwardNetwork
Norm1 *LayerNorm
Norm2 *LayerNorm
Norm3 *LayerNorm
Dropout float64
}
func NewTransformerLayer(config *MultiModalConfig) *TransformerLayer {
return &TransformerLayer{
Config: config,
SelfAttn: NewMultiHeadAttention(config.HiddenDim, config.NumHeads),
CrossAttn: NewMultiHeadAttention(config.HiddenDim, config.NumHeads),
FFN: NewFeedForwardNetwork(config.HiddenDim, config.HiddenDim*4),
Norm1: NewLayerNorm(config.HiddenDim),
Norm2: NewLayerNorm(config.HiddenDim),
Norm3: NewLayerNorm(config.HiddenDim),
Dropout: config.DropoutRate,
}
}
func (l *TransformerLayer) Forward(inputs [][]float64) ([][]float64, error) {
// 自注意力子层
residual := inputs
normalized := make([][]float64, len(inputs))
for i, inp := range inputs {
normalized[i] = l.Norm1.Forward(inp)
}
attnOutput, err := l.SelfAttn.Forward(normalized)
if err != nil {
return nil, err
}
// 残差连接
for i := range inputs {
for j := range inputs[i] {
attnOutput[i][j] += residual[i][j]
}
}
// 跨模态注意力子层(与文本模态进行交互)
residual = attnOutput
normalized = make([][]float64, len(attnOutput))
for i, inp := range attnOutput {
normalized[i] = l.Norm2.Forward(inp)
}
// 使用文本模态作为query,其他模态作为key/value
crossOutput, err := l.CrossAttn.Forward(normalized)
if err != nil {
return nil, err
}
for i := range crossOutput {
for j := range crossOutput[i] {
crossOutput[i][j] += residual[i][j]
}
}
// 前馈网络子层
residual = crossOutput
normalized = make([][]float64, len(crossOutput))
for i, inp := range crossOutput {
normalized[i] = l.Norm3.Forward(inp)
}
ffnOutput := l.FFN.Forward(normalized)
for i := range ffnOutput {
for j := range ffnOutput[i] {
ffnOutput[i][j] += residual[i][j]
}
}
return ffnOutput, nil
}
// 多模态对比损失函数
func ContrastiveLoss(textEmbeddings, imageEmbeddings [][]float64, temperature float64) float64 {
batchSize := len(textEmbeddings)
similarityMatrix := make([][]float64, batchSize)
for i := 0; i < batchSize; i++ {
similarityMatrix[i] = make([]float64, batchSize)
for j := 0; j < batchSize; j++ {
similarityMatrix[i][j] = CosineSimilarity(textEmbeddings[i], imageEmbeddings[j])
}
}
// 计算交叉熵损失
var loss float64
for i := 0; i < batchSize; i++ {
var sumExp float64
for j := 0; j < batchSize; j++ {
sumExp += math.Exp(similarityMatrix[i][j] / temperature)
}
loss -= math.Log(math.Exp(similarityMatrix[i][i]/temperature) / sumExp)
}
return loss / float64(batchSize)
}
// 余弦相似度计算
func CosineSimilarity(a, b []float64) float64 {
var dot, normA, normB float64
for i := 0; i < len(a); i++ {
dot += a[i] * b[i]
normA += a[i] * a[i]
normB += b[i] * b[i]
}
return dot / (math.Sqrt(normA) * math.Sqrt(normB) + 1e-8)
}
// 辅助结构:嵌入层、线性层、层归一化等
type EmbeddingLayer struct {
Weights [][]float64
Dim int
}
func NewEmbeddingLayer(vocabSize, dim int) *EmbeddingLayer {
weights := make([][]float64, vocabSize)
for i := 0; i < vocabSize; i++ {
weights[i] = make([]float64, dim)
for j := 0; j < dim; j++ {
weights[i][j] = rand.NormFloat64() * 0.02
}
}
return &EmbeddingLayer{Weights: weights, Dim: dim}
}
func (e *EmbeddingLayer) Forward(idx int) []float64 {
return e.Weights[idx]
}
type PatchEmbedLayer struct {
Projection *LinearLayer
}
func NewPatchEmbedLayer(inputDim, outputDim int) *PatchEmbedLayer {
return &PatchEmbedLayer{
Projection: NewLinearLayer(inputDim, outputDim),
}
}
func (p *PatchEmbedLayer) Forward(input []float64) []float64 {
return p.Projection.Forward(input)
}
type LinearLayer struct {
Weights [][]float64
Bias []float64
InDim int
OutDim int
}
func NewLinearLayer(inDim, outDim int) *LinearLayer {
weights := make([][]float64, outDim)
for i := 0; i < outDim; i++ {
weights[i] = make([]float64, inDim)
for j := 0; j < inDim; j++ {
weights[i][j] = rand.NormFloat64() * math.Sqrt(2.0/float64(inDim))
}
}
return &LinearLayer{
Weights: weights,
Bias: make([]float64, outDim),
InDim: inDim,
OutDim: outDim,
}
}
func (l *LinearLayer) Forward(input []float64) []float64 {
output := make([]float64, l.OutDim)
for i := 0; i < l.OutDim; i++ {
var sum float64
for j := 0; j < l.InDim; j++ {
sum += l.Weights[i][j] * input[j]
}
output[i] = sum + l.Bias[i]
}
return output
}
type LayerNorm struct {
Gamma []float64
Beta []float64
Dim int
}
func NewLayerNorm(dim int) *LayerNorm {
gamma := make([]float64, dim)
beta := make([]float64, dim)
for i := 0; i < dim; i++ {
gamma[i] = 1.0
beta[i] = 0.0
}
return &LayerNorm{Gamma: gamma, Beta: beta, Dim: dim}
}
func (l *LayerNorm) Forward(input []float64) []float64 {
var mean, variance float64
for _, v := range input {
mean += v
}
mean /= float64(l.Dim)
for _, v := range input {
variance += (v - mean) * (v - mean)
}
variance /= float64(l.Dim)
output := make([]float64, l.Dim)
for i, v := range input {
output[i] = l.Gamma[i]*(v-mean)/math.Sqrt(variance+1e-5) + l.Beta[i]
}
return output
}
type MultiHeadAttention struct {
NumHeads int
HeadDim int
HiddenDim int
Wq, Wk, Wv *LinearLayer
Wo *LinearLayer
}
func NewMultiHeadAttention(hiddenDim, numHeads int) *MultiHeadAttention {
headDim := hiddenDim / numHeads
return &MultiHeadAttention{
NumHeads: numHeads,
HeadDim: headDim,
HiddenDim: hiddenDim,
Wq: NewLinearLayer(hiddenDim, hiddenDim),
Wk: NewLinearLayer(hiddenDim, hiddenDim),
Wv: NewLinearLayer(hiddenDim, hiddenDim),
Wo: NewLinearLayer(hiddenDim, hiddenDim),
}
}
func (m *MultiHeadAttention) Forward(inputs [][]float64) ([][]float64, error) {
seqLen := len(inputs)
if seqLen == 0 {
return nil, fmt.Errorf("empty input for attention")
}
// 计算Q、K、V
q := make([][]float64, seqLen)
k := make([][]float64, seqLen)
v := make([][]float64, seqLen)
for i, inp := range inputs {
q[i] = m.Wq.Forward(inp)
k[i] = m.Wk.Forward(inp)
v[i] = m.Wv.Forward(inp)
}
// 分头计算注意力
output := make([][]float64, seqLen)
for i := range output {
output[i] = make([]float64, m.HiddenDim)
}
var wg sync.WaitGroup
for h := 0; h < m.NumHeads; h++ {
wg.Add(1)
go func(headIdx int) {
defer wg.Done()
start := headIdx * m.HeadDim
end := start + m.HeadDim
// 计算当前头的注意力分数
attnScores := make([][]float64, seqLen)
for i := 0; i < seqLen; i++ {
attnScores[i] = make([]float64, seqLen)
for j := 0; j < seqLen; j++ {
var score float64
for d := start; d < end; d++ {
score += q[i][d] * k[j][d]
}
attnScores[i][j] = score / math.Sqrt(float64(m.HeadDim))
}
}
// Softmax
for i := 0; i < seqLen; i++ {
var maxScore float64
for j := 0; j < seqLen; j++ {
if attnScores[i][j] > maxScore {
maxScore = attnScores[i][j]
}
}
var sumExp float64
for j := 0; j < seqLen; j++ {
attnScores[i][j] = math.Exp(attnScores[i][j] - maxScore)
sumExp += attnScores[i][j]
}
for j := 0; j < seqLen; j++ {
attnScores[i][j] /= sumExp
}
}
// 加权求和
for i := 0; i < seqLen; i++ {
for d := start; d < end; d++ {
var sum float64
for j := 0; j < seqLen; j++ {
sum += attnScores[i][j] * v[j][d]
}
output[i][d] = sum
}
}
}(h)
}
wg.Wait()
// 输出投影
for i := 0; i < seqLen; i++ {
output[i] = m.Wo.Forward(output[i])
}
return output, nil
}
type FeedForwardNetwork struct {
W1 *LinearLayer
W2 *LinearLayer
}
func NewFeedForwardNetwork(hiddenDim, intermediateDim int) *FeedForwardNetwork {
return &FeedForwardNetwork{
W1: NewLinearLayer(hiddenDim, intermediateDim),
W2: NewLinearLayer(intermediateDim, hiddenDim),
}
}
func (f *FeedForwardNetwork) Forward(inputs [][]float64) [][]float64 {
outputs := make([][]float64, len(inputs))
for i, inp := range inputs {
intermediate := f.W1.Forward(inp)
// ReLU激活
for j := range intermediate {
if intermediate[j] < 0 {
intermediate[j] = 0
}
}
outputs[i] = f.W2.Forward(intermediate)
}
return outputs
}
上述代码实现了多模态统一Transformer的核心组件。注意,这是一个教学示例,实际生产系统需要处理更复杂的细节,如梯度计算、优化器、数据加载等。
性能优化
计算优化
多模态大模型面临的主要性能瓶颈在于计算和内存。以下优化策略在生产中至关重要:
Flash Attention:标准注意力机制的计算复杂度为O(n²d),其中n是序列长度,d是隐藏层维度。Flash Attention通过分块计算和重计算,将显存占用降低到O(n√d),同时保持计算精度。对于多模态模型,不同模态的token数量差异很大(文本通常几十个token,图像可能几百个,视频可能上千个),Flash Attention能显著减少显存占用。
混合精度训练:使用FP16或BF16进行前向传播和反向传播,FP32仅用于权重更新和归一化层。这不仅能减少显存占用,还能利用现代GPU的Tensor Core加速计算。对于多模态模型,不同模态对精度的敏感度不同,我们可以为不同模态设置不同的精度级别。
梯度累积与检查点:当batch size受限于显存时,使用梯度累积在多个小batch上累积梯度后再更新参数。梯度检查点技术则在前向传播时丢弃中间激活值,反向传播时重新计算,以时间换空间。
内存优化
KV缓存:在推理阶段,自注意力机制中每个token需要与所有历史token计算注意力。通过缓存历史token的K和V矩阵,可以避免重复计算。对于多模态模型,我们可以为不同模态设置不同的缓存策略,例如图像模态的KV缓存可以复用多次查询。
模型并行:当单卡无法容纳模型时,采用张量并行将Transformer层内的参数分布到多个设备。对于多模态模型,我们可以按模态进行切分,将不同模态的处理分布到不同设备上。
量化:将模型权重从FP32量化到INT8或INT4,可以减少4-8倍的内存占用。对于多模态模型,不同模态的层对量化的敏感度不同,我们可以采用混合精度量化策略。
数据加载优化
多模态数据加载是另一个性能瓶颈。由于不同模态的数据格式和大小不同,数据加载器需要高效处理异构数据:
// 多模态数据加载器
type MultiModalDataLoader struct {
TextData []string
ImagePaths []string
AudioPaths []string
BatchSize int
PrefetchSize int
textQueue chan []string
imageQueue chan [][]float64
audioQueue chan [][]float64
}
// 异步数据预处理
func (l *MultiModalDataLoader) StartPreprocessing() {
go func() {
for i := 0; i < len(l.TextData); i += l.BatchSize {
batch := l.TextData[i:min(i+l.BatchSize, len(l.TextData))]
l.textQueue <- batch
}
close(l.textQueue)
}()
go func() {
for i := 0; i < len(l.ImagePaths); i += l.BatchSize {
batch := l.ImagePaths[i:min(i+l.BatchSize, len(l.ImagePaths))]
images := make([][]float64, len(batch))
for j, path := range batch {
// 异步加载和预处理图像
images[j] = loadAndProcessImage(path)
}
l.imageQueue <- images
}
close(l.imageQueue)
}()
}
生产实践
部署架构
在多模态大模型的生产部署中,我们采用微服务架构,将不同功能模块解耦:
- API Gateway:统一入口,负责请求路由、认证限流
- 模态路由器:根据请求内容自动识别模态组合,分发到对应的处理管道
- 推理服务:模型的核心推理引擎,支持动态批量和请求缓存
- 后处理服务:对模型输出进行格式化,如文本校验、图像后处理
服务化实现
// 多模态推理服务
type MultiModalService struct {
encoder *MultiModalEncoder
cache *sync.Map
mu sync.RWMutex
}
func NewMultiModalService(config *MultiModalConfig) *MultiModalService {
return &MultiModalService{
encoder: NewMultiModalEncoder(config),
cache: &sync.Map{},
}
}
// 处理多模态请求
func (s *MultiModalService) ProcessRequest(ctx context.Context, req *MultiModalRequest) (*MultiModalResponse, error) {
// 1. 检查缓存
cacheKey := generateCacheKey(req)
if cached, ok := s.cache.Load(cacheKey); ok {
return cached.(*MultiModalResponse), nil
}
// 2. 解析请求中的多模态数据
tokens, err := parseMultiModalInput(req)
if err != nil {
return nil, fmt.Errorf("parse input error: %v", err)
}
// 3. 模型推理
start := time.Now()
embeddings, err := s.encoder.Forward(tokens)
if err != nil {
return nil, fmt.Errorf("inference error: %v", err)
}
inferenceTime := time.Since(start)
// 4. 后处理
response := &MultiModalResponse{
Embeddings: embeddings,
InferenceTime: inferenceTime,
ModalityStats: getModalityStats(tokens),
}
// 5. 缓存结果(根据TTL)
s.cache.Store(cacheKey, response)
return response, nil
}
监控与可观测性
在生产环境中,我们需要对多模态模型进行全面的监控:
- 模态分布监控:统计各类模态请求的比例,用于容量规划
- 推理延迟监控:按模态组合统计P50/P95/P99延迟
- 内存使用监控:跟踪KV缓存大小,防止OOM
- 模型漂移检测:监控模型输出的分布变化,及时发现数据漂移
容错与降级
多模态系统需要优雅处理部分模态输入异常的情况:
// 降级策略:当某种模态输入异常时,使用默认值或忽略该模态
func (s *MultiModalService) degradedInference(req *MultiModalRequest) (*MultiModalResponse, error) {
// 尝试解析所有模态,对失败的模态使用占位符
tokens, failedModalities := parseWithFallback(req)
// 记录降级日志
if len(failedModalities) > 0 {
log.Warnf("degraded inference for modalities: %v", failedModalities)
}
return s.encoder.Forward(tokens)
}
总结
多模态大模型的统一架构代表了AI系统设计的重要范式转变。通过共享嵌入空间、统一Transformer架构和端到端训练,我们正在接近构建真正理解多模态世界的AI系统。
技术演进的关键里程碑包括:
- 模态对齐:从人工设计的接口到自学习的统一嵌入空间
- 架构统一:从多编码器拼接到单一Transformer处理所有模态
- 训练策略:从分阶段训练到端到端多任务学习
然而,当前技术仍面临挑战:长视频理解的计算开销、细粒度多模态对齐的准确性、以及模型可解释性的不足。未来,我们期待更高效的注意力机制、更强大的跨模态推理能力,以及更轻量的部署方案。
作为工程师,理解这些技术原理并在实际系统中落地,是推动AI从实验室走向生产的关键。希望本文的实现和优化经验能为你在构建多模态系统时提供参考。