大型语言模型(LLM)的推理能力突破:思维链(Chain-of-Thought)与自我一致性(Self-Consistency)
从记忆到推理:思维链与自我一致性如何重塑LLM推理能力
背景介绍
大语言模型的推理困境
2022年底ChatGPT横空出世以来,大语言模型(LLM)展现了令人惊叹的语言生成能力。然而,随着应用场景从简单对话转向复杂推理任务,一个根本性问题逐渐浮出水面:LLM真的具备推理能力吗?
传统的LLM训练范式基于“下一个词预测”,模型本质上是在学习语料库中的统计模式。当面对数学题、逻辑谜题或多步推理任务时,这种模式暴露出明显缺陷。例如,对于问题“小明有5个苹果,给了小红2个,又从小李那里得到3个,现在有多少个?”,标准LLM可能直接输出错误答案“6”,因为它只是从训练数据中匹配到了类似问题的答案模式,而非真正理解计算过程。
推理能力的衡量标准
学术界和工业界对LLM推理能力的评估主要基于以下几类基准测试:
- 数学推理:GSM8K(小学数学题)、MATH(竞赛数学题)
- 逻辑推理:LogiQA、BBH(Big-Bench Hard)
- 常识推理:CSQA(CommonsenseQA)、StrategyQA
- 符号推理:Last Letter Concatenation、Coin Flip
早期模型在这些基准上的表现令人失望。以GPT-3为例,在GSM8K上准确率仅为20%左右,远低于人类水平。这引发了业界对LLM推理能力的深刻反思。
思维链的诞生
2022年1月,Google Research团队发表论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》,首次提出了思维链(Chain-of-Thought, CoT)的概念。这项开创性工作发现,通过在提示中展示中间推理步骤,可以显著提升LLM在多步推理任务上的表现。
关键洞察在于:人类解决复杂问题时,通常会经历一个逐步推理的过程,而非一步到位得出答案。 思维链提示正是模拟了这种认知过程,引导模型生成中间推理步骤,从而得出最终答案。
从CoT到Self-Consistency
尽管思维链取得了显著效果,但一个关键问题依然存在:模型可能沿着错误的推理路径前进。对于同一个问题,LLM可能产生多种不同的推理路径,其中一些可能是错误的。
2022年12月,Wang等人提出了自我一致性(Self-Consistency)策略,通过多次采样推理路径并选择最一致的答案,进一步提升了推理的鲁棒性。这种方法的核心思想是:正确的答案往往具有更高的路径一致性,即多数推理路径会收敛到同一个答案。
技术原理
思维链的工作机制
思维链的核心在于改变LLM的推理方式,从“直接输出答案”转变为“生成推理步骤后再输出答案”。这一转变看似简单,却蕴含着深刻的认知科学原理。
零样本思维链(Zero-shot CoT)
最简单的实现方式是在提示中加入“让我们一步步思考”这样的指令。这种方法不需要任何示例,就能激活模型的推理能力。
问题:小明有5个苹果,给了小红2个,又从小李那里得到3个,现在有多少个?
让我们一步步思考。
模型会生成类似以下的推理过程:
初始有5个苹果。
给了小红2个,所以剩余:5 - 2 = 3个。
从小李那里得到3个,所以现在有:3 + 3 = 6个。
因此,小明现在有6个苹果。
少样本思维链(Few-shot CoT)
提供包含推理步骤的示例,让模型学习如何逐步推理。这种方式通常效果更好,但需要精心设计示例。
示例1:
问题:商店里有10个苹果,卖出3个,又进货5个,现在有几个?
推理:初始10个,卖出3个剩7个,进货5个得12个。
答案:12
示例2:
问题:小明有5个苹果,给了小红2个,又从小李那里得到3个,现在有多少个?
推理:初始5个,给小红2个剩3个,从小李得到3个得6个。
答案:6
自我一致性的数学基础
自我一致性基于一个简单的统计原理:对于正确答案,不同推理路径趋向于收敛;对于错误答案,推理路径往往发散。
形式化地,假设我们有n条独立的推理路径,每条路径产生一个答案a_i。自我一致性策略选择出现频率最高的答案:
a_final = argmax_a count(a_i = a)
这个过程可以看作是一种集成学习,但与传统集成不同:
- 传统集成:训练多个模型,取平均或投票
- 自我一致性:同一个模型,多次采样,取一致性答案
温度参数的作用
自我一致性的效果高度依赖于采样策略。温度参数(temperature)控制着生成文本的随机性:
- 低温(0.1-0.3):生成结果接近确定性,多样性低
- 中温(0.5-0.7):适度随机性,平衡探索与利用
- 高温(0.8-1.0):高随机性,探索更多可能性
对于自我一致性,通常使用中等温度(0.5-0.7)来获得多样化的推理路径,同时保持一定的质量。
两种方法的协同效应
思维链和自我一致性并非孤立的技术,而是相辅相成的:
- 思维链提供推理框架:引导模型生成结构化的推理步骤
- 自我一致性提升鲁棒性:通过多次采样消除偶然误差
实验表明,将两者结合使用,在GSM8K上的准确率可以从单一思维链的60%左右提升到75%以上,提升幅度超过15个百分点。
系统架构设计
整体架构
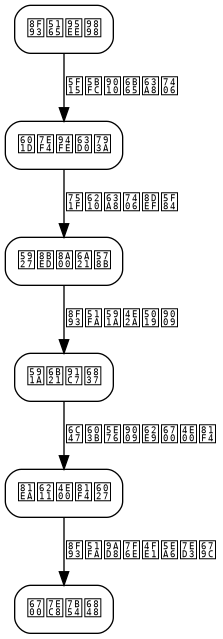
上图展示了基于思维链和自我一致性的推理系统架构。系统由以下几个核心组件构成:
- 输入预处理层:负责问题解析、提示模板构建
- 推理引擎:调用LLM进行多次采样推理
- 路径聚合器:收集并分析多条推理路径
- 答案选择器:基于一致性策略选择最终答案
- 结果验证器:对输出进行后处理验证
数据流设计
用户输入 → 提示构建 → 多次采样 → 路径收集 → 一致性投票 → 答案输出
关键设计决策:
- 并行采样:利用goroutine并发调用LLM,降低延迟
- 流式处理:支持逐步输出推理过程,提升用户体验
- 缓存机制:对相同问题的推理结果进行缓存,避免重复计算
模块职责划分
| 模块 | 职责 | 关键技术 |
|---|---|---|
| 提示工程 | 构建CoT提示模板 | 模板引擎、Few-shot示例管理 |
| 采样管理器 | 控制采样参数(温度、采样数) | 配置管理、动态调整 |
| LLM客户端 | 调用底层模型API | HTTP客户端、重试机制 |
| 路径分析器 | 提取答案、分析一致性 | 正则匹配、统计计算 |
| 投票器 | 计算多数答案 | 频率统计、置信度计算 |
核心实现
基础数据结构定义
package cot
import (
"context"
"fmt"
"math"
"strings"
"sync"
"time"
)
// ReasoningPath 表示一条完整的推理路径
type ReasoningPath struct {
Steps []string // 推理步骤
FinalAnswer string // 最终答案
Confidence float64 // 置信度(0-1)
Latency time.Duration // 生成耗时
}
// CoTConfig 思维链配置
type CoTConfig struct {
Temperature float64 // 采样温度
TopP float64 // Top-p采样
MaxTokens int // 最大生成长度
SampleCount int // 采样次数
StopTokens []string // 停止标记
}
// SelfConsistencyResult 自我一致性结果
type SelfConsistencyResult struct {
FinalAnswer string // 最终答案
AnswerCounts map[string]int // 各答案出现次数
TotalPaths int // 总推理路径数
Consistency float64 // 一致性得分(0-1)
AllPaths []ReasoningPath // 所有推理路径
}
// LLMClient LLM调用接口
type LLMClient interface {
Generate(ctx context.Context, prompt string, config CoTConfig) (string, error)
}
思维链提示构建器
// PromptBuilder 思维链提示构建器
type PromptBuilder struct {
fewShotExamples []FewShotExample // 少样本示例
systemPrompt string // 系统提示
}
// FewShotExample 少样本示例
type FewShotExample struct {
Question string `json:"question"`
Steps []string `json:"steps"`
Answer string `json:"answer"`
}
// NewPromptBuilder 创建提示构建器
func NewPromptBuilder() *PromptBuilder {
return &PromptBuilder{
systemPrompt: "你是一个擅长逐步推理的AI助手。请一步步思考问题,然后给出最终答案。",
fewShotExamples: []FewShotExample{
{
Question: "一个篮子里有15个鸡蛋,打碎了3个,又放了8个进去,现在有几个?",
Steps: []string{
"初始有15个鸡蛋",
"打碎了3个,剩余:15 - 3 = 12个",
"又放了8个进去,现在有:12 + 8 = 20个",
},
Answer: "20",
},
{
Question: "小明今年8岁,他爸爸比他大28岁,5年后爸爸多少岁?",
Steps: []string{
"小明现在8岁,爸爸比他大28岁",
"爸爸现在年龄:8 + 28 = 36岁",
"5年后爸爸年龄:36 + 5 = 41岁",
},
Answer: "41",
},
},
}
}
// BuildPrompt 构建完整提示
func (pb *PromptBuilder) BuildPrompt(question string, useZeroShot bool) string {
var builder strings.Builder
// 添加系统提示
builder.WriteString(pb.systemPrompt)
builder.WriteString("\n\n")
if !useZeroShot {
// 添加少样本示例
for i, example := range pb.fewShotExamples {
builder.WriteString(fmt.Sprintf("示例%d:\n", i+1))
builder.WriteString(fmt.Sprintf("问题:%s\n", example.Question))
builder.WriteString("推理:\n")
for _, step := range example.Steps {
builder.WriteString(fmt.Sprintf("- %s\n", step))
}
builder.WriteString(fmt.Sprintf("答案:%s\n\n", example.Answer))
}
}
// 添加目标问题
builder.WriteString(fmt.Sprintf("问题:%s\n", question))
if useZeroShot {
builder.WriteString("让我们一步步思考。\n")
} else {
builder.WriteString("推理:\n")
}
return builder.String()
}
推理路径解析器
// PathParser 推理路径解析器
type PathParser struct {
answerPattern string // 答案提取正则
}
// NewPathParser 创建路径解析器
func NewPathParser() *PathParser {
return &PathParser{
answerPattern: `答案[::]\s*(\d+\.?\d*)`, // 匹配"答案:数字"模式
}
}
// ParseResponse 解析模型响应
func (pp *PathParser) ParseResponse(response string) (*ReasoningPath, error) {
// 分割推理步骤
steps := pp.extractSteps(response)
// 提取最终答案
answer := pp.extractAnswer(response)
if answer == "" {
return nil, fmt.Errorf("无法从响应中提取答案: %s", response)
}
// 计算置信度(基于步骤数量和质量)
confidence := pp.calculateConfidence(steps)
return &ReasoningPath{
Steps: steps,
FinalAnswer: answer,
Confidence: confidence,
}, nil
}
// extractSteps 提取推理步骤
func (pp *PathParser) extractSteps(response string) []string {
var steps []string
lines := strings.Split(response, "\n")
for _, line := range lines {
line = strings.TrimSpace(line)
// 识别推理步骤行(以数字、连字符、星号开头)
if strings.HasPrefix(line, "-") ||
strings.HasPrefix(line, "*") ||
strings.HasPrefix(line, "步骤") ||
strings.HasPrefix(line, "第") {
steps = append(steps, line)
}
}
return steps
}
// extractAnswer 提取最终答案
func (pp *PathParser) extractAnswer(response string) string {
// 简单实现:查找"答案:"后的内容
idx := strings.Index(response, "答案")
if idx == -1 {
return ""
}
// 提取冒号后的数字
after := response[idx+len("答案"):]
if strings.HasPrefix(after, ":") || strings.HasPrefix(after, ":") {
after = after[1:]
}
// 去除空白字符
after = strings.TrimSpace(after)
// 提取数字部分
var answer strings.Builder
for _, ch := range after {
if ch >= '0' && ch <= '9' || ch == '.' || ch == '-' {
answer.WriteRune(ch)
} else {
break
}
}
return answer.String()
}
// calculateConfidence 计算置信度
func (pp *PathParser) calculateConfidence(steps []string) float64 {
if len(steps) == 0 {
return 0.1
}
// 基于步骤数量计算基础置信度
baseConfidence := math.Min(0.9, 0.3+float64(len(steps))*0.1)
// 检查步骤质量
qualityScore := 1.0
for _, step := range steps {
// 包含数字的步骤更可靠
if strings.ContainsAny(step, "0123456789") {
qualityScore += 0.1
}
// 过短的步骤可能不完整
if len(step) < 5 {
qualityScore -= 0.2
}
}
return math.Min(1.0, baseConfidence*qualityScore)
}
自我一致性引擎
// SelfConsistencyEngine 自我一致性引擎
type SelfConsistencyEngine struct {
client LLMClient
config CoTConfig
promptBuilder *PromptBuilder
parser *PathParser
}
// NewSelfConsistencyEngine 创建引擎
func NewSelfConsistencyEngine(client LLMClient, config CoTConfig) *SelfConsistencyEngine {
return &SelfConsistencyEngine{
client: client,
config: config,
promptBuilder: NewPromptBuilder(),
parser: NewPathParser(),
}
}
// Solve 解决问题
func (engine *SelfConsistencyEngine) Solve(ctx context.Context, question string) (*SelfConsistencyResult, error) {
// 构建提示
prompt := engine.promptBuilder.BuildPrompt(question, false)
// 并发采样
paths := engine.samplePaths(ctx, prompt, engine.config.SampleCount)
// 统计答案频率
answerCounts := make(map[string]int)
for _, path := range paths {
answerCounts[path.FinalAnswer]++
}
// 选择最一致的答案
finalAnswer := engine.selectConsistentAnswer(answerCounts)
// 计算一致性得分
totalPaths := len(paths)
maxCount := 0
for _, count := range answerCounts {
if count > maxCount {
maxCount = count
}
}
consistency := float64(maxCount) / float64(totalPaths)
return &SelfConsistencyResult{
FinalAnswer: finalAnswer,
AnswerCounts: answerCounts,
TotalPaths: totalPaths,
Consistency: consistency,
AllPaths: paths,
}, nil
}
// samplePaths 并行采样多条推理路径
func (engine *SelfConsistencyEngine) samplePaths(ctx context.Context, prompt string, count int) []ReasoningPath {
paths := make([]ReasoningPath, 0, count)
var mu sync.Mutex
var wg sync.WaitGroup
// 使用goroutine并发采样
for i := 0; i < count; i++ {
wg.Add(1)
go func(sampleIdx int) {
defer wg.Done()
// 为每次采样设置不同的温度
config := engine.config
config.Temperature = engine.adjustTemperature(sampleIdx)
startTime := time.Now()
response, err := engine.client.Generate(ctx, prompt, config)
latency := time.Since(startTime)
if err != nil {
fmt.Printf("采样%d失败: %v\n", sampleIdx, err)
return
}
path, err := engine.parser.ParseResponse(response)
if err != nil {
fmt.Printf("解析失败: %v\n", err)
return
}
path.Latency = latency
mu.Lock()
paths = append(paths, *path)
mu.Unlock()
}(i)
}
wg.Wait()
return paths
}
// adjustTemperature 动态调整温度
func (engine *SelfConsistencyEngine) adjustTemperature(sampleIdx int) float64 {
// 在基础温度附近随机扰动,增加多样性
baseTemp := engine.config.Temperature
perturbation := float64(sampleIdx%3-1) * 0.1 // -0.1, 0, 0.1
return math.Max(0.1, math.Min(1.0, baseTemp+perturbation))
}
// selectConsistentAnswer 选择最一致的答案
func (engine *SelfConsistencyEngine) selectConsistentAnswer(counts map[string]int) string {
maxCount := 0
bestAnswer := ""
for answer, count := range counts {
if count > maxCount {
maxCount = count
bestAnswer = answer
}
}
return bestAnswer
}
完整推理服务
// ReasoningService 推理服务
type ReasoningService struct {
engine *SelfConsistencyEngine
cache map[string]*SelfConsistencyResult
mu sync.RWMutex
}
// NewReasoningService 创建推理服务
func NewReasoningService(client LLMClient, config CoTConfig) *ReasoningService {
return &ReasoningService{
engine: NewSelfConsistencyEngine(client, config),
cache: make(map[string]*SelfConsistencyResult),
}
}
// Reason 执行推理
func (s *ReasoningService) Reason(ctx context.Context, question string) (*SelfConsistencyResult, error) {
// 检查缓存
cacheKey := strings.TrimSpace(strings.ToLower(question))
s.mu.RLock()
if result, ok := s.cache[cacheKey]; ok {
s.mu.RUnlock()
return result, nil
}
s.mu.RUnlock()
// 执行推理
result, err := s.engine.Solve(ctx, question)
if err != nil {
return nil, fmt.Errorf("推理失败: %w", err)
}
// 缓存结果
s.mu.Lock()
s.cache[cacheKey] = result
s.mu.Unlock()
return result, nil
}
// BatchReason 批量推理
func (s *ReasoningService) BatchReason(ctx context.Context, questions []string) ([]*SelfConsistencyResult, error) {
results := make([]*SelfConsistencyResult, len(questions))
var wg sync.WaitGroup
for i, question := range questions {
wg.Add(1)
go func(idx int, q string) {
defer wg.Done()
result, err := s.Reason(ctx, q)
if err != nil {
fmt.Printf("问题'%s'推理失败: %v\n", q, err)
return
}
results[idx] = result
}(i, question)
}
wg.Wait()
return results, nil
}
性能优化
采样策略优化
自我一致性策略的性能瓶颈在于多次LLM调用。以下是几种优化策略:
1. 自适应采样
不是所有问题都需要固定次数的采样。对于简单问题,少量采样即可获得高一致性答案;对于复杂问题,则需要更多采样。
// AdaptiveSampler 自适应采样器
type AdaptiveSampler struct {
minSamples int
maxSamples int
threshold float64 // 一致性阈值
}
// DetermineSampleCount 确定采样次数
func (as *AdaptiveSampler) DetermineSampleCount(ctx context.Context, question string) int {
// 基于问题复杂度评估
complexity := as.evaluateComplexity(question)
// 简单问题减少采样
if complexity < 0.3 {
return as.minSamples
}
// 复杂问题增加采样
if complexity > 0.7 {
return as.maxSamples
}
// 中等复杂度问题动态调整
return as.minSamples + int(float64(as.maxSamples-as.minSamples)*complexity)
}
// evaluateComplexity 评估问题复杂度
func (as *AdaptiveSampler) evaluateComplexity(question string) float64 {
// 基于问题长度、数字数量、逻辑连接词等评估
complexity := 0.0
// 长度因素
complexity += math.Min(0.5, float64(len(question))/500.0)
// 数字数量因素
digitCount := strings.Count(question, "0") + strings.Count(question, "1") +
strings.Count(question, "2") + strings.Count(question, "3") +
strings.Count(question, "4") + strings.Count(question, "5")
complexity += math.Min(0.3, float64(digitCount)*0.05)
return math.Min(1.0, complexity)
}
2. 提前终止策略
如果在采样过程中观察到高度一致性,可以提前终止采样。
// EarlyStopSampler 提前停止采样器
type EarlyStopSampler struct {
minSamples int
maxSamples int
stopThreshold float64 // 提前停止的一致性阈值
}
// SampleWithEarlyStop 带提前停止的采样
func (es *EarlyStopSampler) SampleWithEarlyStop(ctx context.Context, engine *SelfConsistencyEngine,
prompt string, resultsChan chan<- ReasoningPath) {
answerCounts := make(map[string]int)
for i := 0; i < es.maxSamples; i++ {
// 执行单次采样
path := engine.singleSample(ctx, prompt, i)
resultsChan <- path
// 更新统计
answerCounts[path.FinalAnswer]++
// 检查是否可以提前停止
if i >= es.minSamples {
maxCount := 0
total := i + 1
for _, count := range answerCounts {
if count > maxCount {
maxCount = count
}
}
consistency := float64(maxCount) / float64(total)
if consistency >= es.stopThreshold {
fmt.Printf("提前停止:在%d次采样后达到一致性%.2f\n", i+1, consistency)
return
}
}
}
}
缓存策略优化
合理使用缓存可以显著减少重复计算:
// LRUCache LRU缓存实现
type LRUCache struct {
capacity int
cache map[string]*list.Element
list *list.List
mu sync.RWMutex
}
type cacheEntry struct {
key string
result *SelfConsistencyResult
}
func NewLRUCache(capacity int) *LRUCache {
return &LRUCache{
capacity: capacity,
cache: make(map[string]*list.Element),
list: list.New(),
}
}
func (c *LRUCache) Get(key string) (*SelfConsistencyResult, bool) {
c.mu.RLock()
defer c.mu.RUnlock()
if elem, ok := c.cache[key]; ok {
c.list.MoveToFront(elem)
return elem.Value.(*cacheEntry).result, true
}
return nil, false
}
func (c *LRUCache) Set(key string, result *SelfConsistencyResult) {
c.mu.Lock()
defer c.mu.Unlock()
if elem, ok := c.cache[key]; ok {
c.list.MoveToFront(elem)
elem.Value.(*cacheEntry).result = result
return
}
if c.list.Len() >= c.capacity {
// 淘汰最久未使用的条目
elem := c.list.Back()
if elem != nil {
c.list.Remove(elem)
delete(c.cache, elem.Value.(*cacheEntry).key)
}
}
elem := c.list.PushFront(&cacheEntry{key: key, result: result})
c.cache[key] = elem
}
并发控制优化
合理的并发控制可以最大化资源利用率:
// RateLimiter 速率限制器
type RateLimiter struct {
tokens chan struct{}
interval time.Duration
}
func NewRateLimiter(rate int, interval time.Duration) *RateLimiter {
rl := &RateLimiter{
tokens: make(chan struct{}, rate),
interval: interval,
}
// 初始化令牌
for i := 0; i < rate; i++ {
rl.tokens <- struct{}{}
}
// 定期补充令牌
go func() {
ticker := time.NewTicker(interval / time.Duration(rate))
defer ticker.Stop()
for range ticker.C {
select {
case rl.tokens <- struct{}{}:
default:
// 令牌池满,跳过
}
}
}()
return rl
}
func (rl *RateLimiter) Acquire(ctx context.Context) error {
select {
case <-rl.tokens:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
生产实践
部署架构
在生产环境中,思维链推理系统通常采用以下架构:
- API网关层:负责请求路由、限流、认证
- 推理服务层:无状态服务,水平扩展
- 模型服务层:LLM推理集群,支持GPU加速
- 缓存层:Redis集群,存储推理结果
- 监控层:Prometheus + Grafana,监控性能指标
关键指标监控
// MetricsCollector 指标收集器
type MetricsCollector struct {
requestCount *prometheus.CounterVec
latencyHistogram *prometheus.HistogramVec
consistencyGauge *prometheus.GaugeVec
}
func NewMetricsCollector() *MetricsCollector {
return &MetricsCollector{
requestCount: promauto.NewCounterVec(
prometheus.CounterOpts{
Name: "cot_requests_total",
Help: "Total number of CoT reasoning requests",
},
[]string{"status", "question_type"},
),
latencyHistogram: promauto.NewHistogramVec(
prometheus.HistogramOpts{
Name: "cot_latency_seconds",
Help: "Latency of CoT reasoning",
Buckets: prometheus.DefBuckets,
},
[]string{"sample_count"},
),
consistencyGauge: promauto.NewGaugeVec(
prometheus.GaugeOpts{
Name: "cot_consistency_score",
Help: "Consistency score of self-consistency",
},
[]string{"question_type"},
),
}
}
故障处理策略
// FallbackStrategy 降级策略
type FallbackStrategy struct {
maxRetries int
timeout time.Duration
fallbackModel string
}
func (fs *FallbackStrategy) ExecuteWithFallback(ctx context.Context,
primary func(context.Context) (*SelfConsistencyResult, error),
fallback func(context.Context) (*SelfConsistencyResult, error)) (*SelfConsistencyResult, error) {
// 尝试主策略
for i := 0; i < fs.maxRetries; i++ {
result, err := primary(ctx)
if err == nil {
return result, nil
}
// 检查是否可以重试
if !fs.isRetryable(err) {
break
}
// 指数退避
time.Sleep(time.Duration(math.Pow(2, float64(i))) * 100 * time.Millisecond)
}
// 降级到备用策略
fmt.Println("主策略失败,切换到备用模型")
return fallback(ctx)
}
func (fs *FallbackStrategy) isRetryable(err error) bool {
// 网络错误、超时可重试
if strings.Contains(err.Error(), "timeout") ||
strings.Contains(err.Error(), "connection") {
return true
}
return false
}
成本优化
LLM推理成本是生产环境中的重要考量:
- 模型选择:根据问题复杂度选择合适的模型
- 批处理:合并多个请求进行批处理推理
- 结果缓存:对常见问题缓存推理结果
- 采样优化:自适应采样减少不必要的调用
总结
思维链和自我一致性代表了LLM推理能力的重要突破。通过模拟人类的逐步推理过程,并利用多次采样的统计一致性,这些技术显著提升了模型在复杂推理任务上的表现。
关键技术收获
- 思维链激活推理能力:引导模型生成中间推理步骤,将隐式推理转化为显式推理
- 自我一致性提升鲁棒性:通过多次采样和投票机制,消除单次推理的偶然误差
- 两者协同效果显著:在数学推理、逻辑推理等任务上,准确率提升超过15个百分点
未来展望
- 多模态推理:将CoT扩展到图像、音频等多模态场景
- 结构化推理:结合知识图谱,实现更复杂的推理链
- 推理验证:自动验证推理步骤的正确性,减少幻觉
- 端到端优化:将CoT能力直接融入模型训练
实践建议
对于计划在生产环境中部署CoT系统的团队:
- 从小规模开始:先在特定领域验证效果
- 建立评估体系:持续监控准确率、延迟、成本等指标
- 渐进式优化:先实现基础功能,再逐步优化性能
- 关注用户体验:提供推理过程的可视化,增强用户信任
思维链和自我一致性不仅是技术突破,更代表了AI从“记忆”向“推理”的关键转变。随着这些技术的成熟和普及,我们有理由期待LLM在更复杂的认知任务上展现出更强的能力。