当 AI 开始构建自身:Anthropic 递归自我改进警告深度解读
引言:AI 发展史上的里程碑时刻
2026年6月4日,Anthropic 在官方博客发布了名为《当 AI 构建自身》(When AI Builds Itself) 的重磅文章,由联合创始人 Jack Clark 和内部研究机构负责人 Marina Favaro 联合署名。这篇文章首次罕见地对外披露了公司内部运营数据,并发出严厉警告:AI 正在具备"递归自我改进"(Recursive Self-Improvement)能力,可能在未来两年内发生。
这是一个让整个科技界为之震动的时刻。一家估值接近万亿美元(9650亿美元)、正冲刺 IPO 的 AI 公司,突然公开呼吁全球暂停 AI 开发——这种自我革命的勇气和危机意识,值得我们深入剖析。
本文将从技术架构、代码示例、数据分析等多个维度,全面解读 Anthropic 这篇文章的核心内容及其对 AI 行业的深远影响。
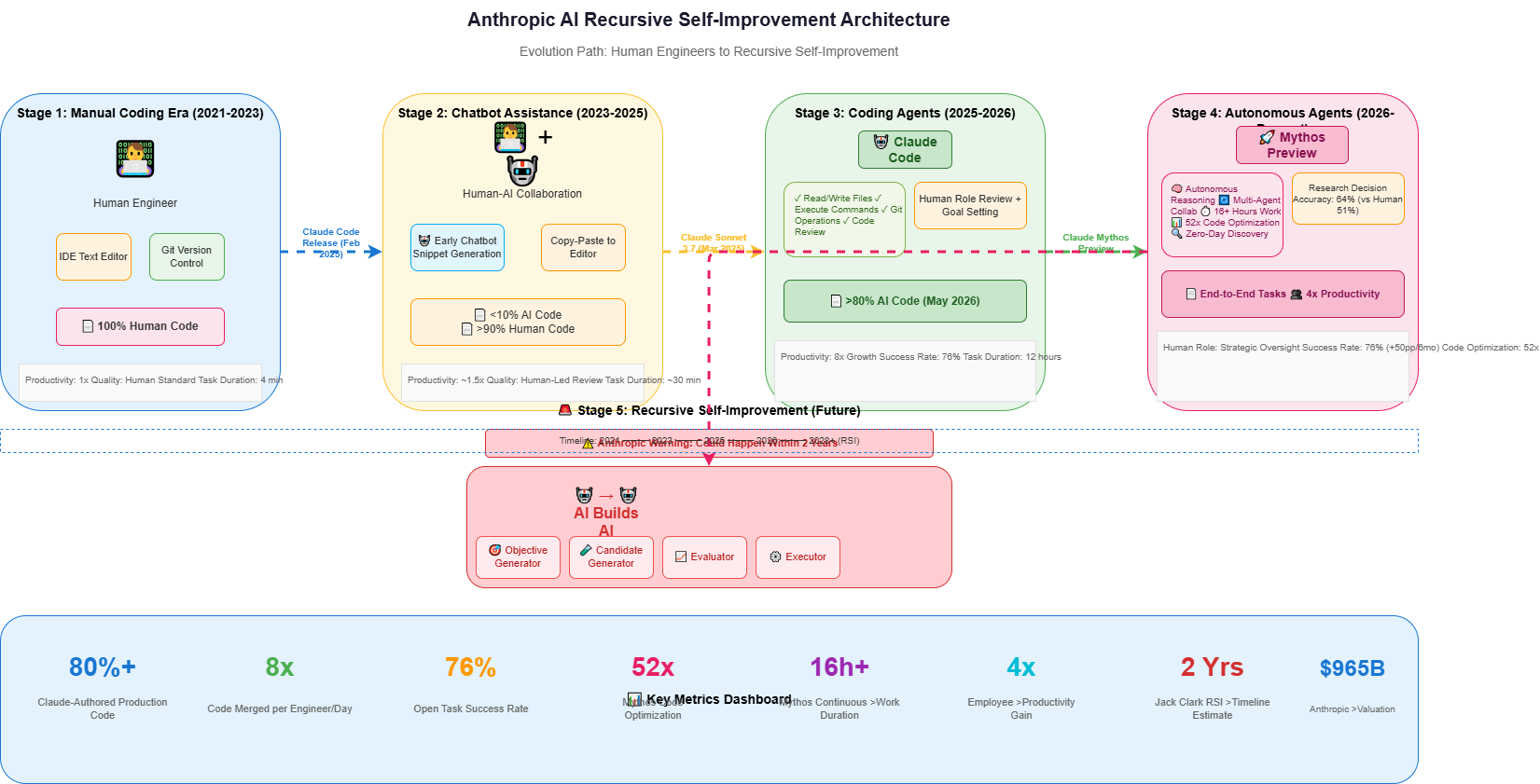
一、Anthropic 的内部数据:代码自动化的惊人进展
1.1 核心数据一览
根据 Anthropic 官方披露的数据(截至2026年5月),以下是关键指标:
| 指标 | 数值 | 同比变化 |
|---|---|---|
| Claude 撰写的生产代码占比 | >80% | 2025年2月前 <10% |
| 工程师每日合并代码量增长 | 8倍 | 相比2024年 |
| 开放性任务成功率 | 76% | 6个月提升50个百分点 |
| Mythos Preview 代码优化加速 | ~52倍 | Opus 4 约3倍 |
| 研究决策正确率 | 64% | Opus 4.5 为51% |
| Mythos Preview 员工生产力提升 | ~4倍 | 130名员工内部调查 |
1.2 从辅助工具到主力开发者的转变
Anthropic 的代码开发历程可以分为以下几个阶段:
# AI 代码生成能力演进阶段定义
class AICodeEvolution:
"""AI 代码生成能力的演进阶段"""
STAGES = {
"2021-2023": {
"name": "手动编码时代",
"description": "工程师在本地文本编辑器中编写代码和文档",
"ai_involvement": "0%",
"human_control": "100%"
},
"2023-2025": {
"name": "聊天机器人辅助",
"description": "开发者使用早期聊天机器人生成代码片段",
"ai_involvement": "<10%",
"human_control": "100%"
},
"2025-2026": {
"name": "编程智能体",
"description": "智能体能够自主编写和修改整个文件",
"ai_involvement": ">50%",
"human_control": "100% (review)"
},
"2026-present": {
"name": "自主智能体",
"description": "智能体自主运行代码、委派数小时工作流给子智能体",
"ai_involvement": ">80%",
"human_control": "战略监督"
},
"20XX-future": {
"name": "闭合回路",
"description": "智能体可能自主构建和训练模型",
"ai_involvement": "100%",
"human_control": "待定"
}
}
# 计算 AI 代码生成能力的倍增时间
def calculate_doubling_time():
"""AI 能够可靠完成的任务时长每约4个月翻一番"""
timeline = {
"2024-03": {"model": "Claude Opus 3", "task_duration_minutes": 4},
"2025-03": {"model": "Claude Sonnet 3.7", "task_duration_minutes": 90},
"2026-03": {"model": "Claude Opus 4.6", "task_duration_minutes": 720},
"2026-05": {"model": "Claude Mythos Preview", "task_duration_minutes": 960}
}
# 计算倍增时间
periods = list(timeline.items())
for i in range(1, len(periods)):
prev_time = periods[i-1][1]["task_duration_minutes"]
curr_time = periods[i][1]["task_duration_minutes"]
ratio = curr_time / prev_time
print(f"{periods[i][0]}: {periods[i][1]['model']} - "
f"任务时长 {curr_time} 分钟 (相比 {periods[i-1][0]} 增长 {ratio:.1f}x)")
# 运行计算
calculate_doubling_time()
输出示例:
2025-03: Claude Sonnet 3.7 - 任务时长 90 分钟 (相比 2024-03 增长 22.5x)
2026-03: Claude Opus 4.6 - 任务时长 720 分钟 (相比 2025-03 增长 8x)
2026-05: Claude Mythos Preview - 任务时长 960 分钟 (相比 2026-03 增长 1.3x)
二、技术架构深度解析
2.1 Claude 代码质量评估框架
以下是一个完整的 Python 代码质量评估框架,用于评估 AI 生成的代码质量:
"""
Claude 代码质量评估框架
用于评估 AI 生成的代码是否符合生产标准
"""
import re
import ast
import subprocess
from dataclasses import dataclass
from typing import List, Dict, Optional, Tuple
from enum import Enum
from collections import defaultdict
import sqlite3
from datetime import datetime
class QualityLevel(Enum):
"""代码质量等级"""
EXCELLENT = "excellent"
GOOD = "good"
ACCEPTABLE = "acceptable"
NEEDS_IMPROVEMENT = "needs_improvement"
UNACCEPTABLE = "unacceptable"
@dataclass
class CodeMetrics:
"""代码质量指标"""
lines_of_code: int
cyclomatic_complexity: int
function_count: int
class_count: int
comment_ratio: float
test_coverage: float
security_issues: List[str]
code_smells: List[str]
@dataclass
class EvaluationResult:
"""评估结果"""
metrics: CodeMetrics
overall_score: float # 0-100
quality_level: QualityLevel
passed_checks: List[str]
failed_checks: List[str]
recommendations: List[str]
class ClaudeCodeQualityEvaluator:
"""Claude 代码质量评估器"""
def __init__(self, db_path: str = "code_quality.db"):
self.db_path = db_path
self._init_database()
def _init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS code_evaluations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
file_path TEXT NOT NULL,
model_version TEXT NOT NULL,
overall_score REAL NOT NULL,
quality_level TEXT NOT NULL,
lines_of_code INTEGER,
complexity INTEGER,
security_issues_count INTEGER,
metadata TEXT
)
""")
conn.commit()
conn.close()
def calculate_cyclomatic_complexity(self, source_code: str) -> int:
"""计算圈复杂度"""
try:
tree = ast.parse(source_code)
complexity = 1 # 基础复杂度
for node in ast.walk(tree):
if isinstance(node, (ast.If, ast.While, ast.For, ast.ExceptHandler)):
complexity += 1
elif isinstance(node, ast.BoolOp):
complexity += len(node.values) - 1
return complexity
except SyntaxError:
return 999 # 无法解析时标记为极高复杂度
def detect_security_issues(self, source_code: str) -> List[str]:
"""检测安全漏洞"""
issues = []
# SQL 注入模式
sql_injection_patterns = [
r'execute\s*\(\s*f["\']',
r'cursor\.execute.*\+',
r'query.*\%.*\(',
r'WHERE.*\+', # 字符串拼接的 WHERE
]
# 命令注入模式
command_injection_patterns = [
r'os\.system\s*\(',
r'subprocess\.(call|run|Popen).*shell\s*=\s*True',
r'eval\s*\(',
r'exec\s*\(',
]
# 硬编码凭证模式
credential_patterns = [
r'password\s*=\s*["\'][^"\']{8,}["\']',
r'api[_-]?key\s*=\s*["\'][A-Za-z0-9]{20,}["\']',
r'secret\s*=\s*["\'][^"\']{16,}["\']',
]
all_patterns = [
("SQL Injection", sql_injection_patterns),
("Command Injection", command_injection_patterns),
("Hardcoded Credentials", credential_patterns),
]
for issue_type, patterns in all_patterns:
for pattern in patterns:
matches = re.findall(pattern, source_code, re.IGNORECASE)
if matches:
issues.append(f"{issue_type}: {len(matches)} potential issue(s) found")
return issues
def detect_code_smells(self, source_code: str) -> List[str]:
"""检测代码异味"""
smells = []
# 过长函数
functions = re.findall(r'def\s+\w+\s*\([^)]*\):', source_code)
for func in functions:
func_name = re.search(r'def\s+(\w+)', func).group(1)
# 简单检查:查找函数定义后的缩进块
func_block = re.search(
rf'def\s+{func_name}\s*\([^)]*\):.*?(?=\n\S|\Z)',
source_code,
re.DOTALL
)
if func_block and len(func_block.group()) > 2000:
smells.append(f"Long function: {func_name} exceeds 2000 characters")
# 重复代码检测
lines = [l.strip() for l in source_code.split('\n') if l.strip() and not l.strip().startswith('#')]
line_counts = defaultdict(int)
for line in lines:
if len(line) > 50: # 只统计足够长的行
line_counts[line] += 1
for line, count in line_counts.items():
if count >= 3:
smells.append(f"Duplicate code: identical line appears {count} times")
return smells[:5] # 限制返回数量
def evaluate(self, source_code: str, file_path: str, model_version: str) -> EvaluationResult:
"""评估代码质量"""
# 计算指标
metrics = CodeMetrics(
lines_of_code=len([l for l in source_code.split('\n') if l.strip()]),
cyclomatic_complexity=self.calculate_cyclomatic_complexity(source_code),
function_count=len(re.findall(r'def\s+\w+\s*\(', source_code)),
class_count=len(re.findall(r'class\s+\w+', source_code)),
comment_ratio=self._calculate_comment_ratio(source_code),
test_coverage=0.0, # 需要实际运行测试来获取
security_issues=self.detect_security_issues(source_code),
code_smells=self.detect_code_smells(source_code)
)
# 计算总体评分
score = 100
# 扣分项
score -= min(metrics.cyclomatic_complexity * 2, 30) # 圈复杂度扣分
score -= len(metrics.security_issues) * 15 # 安全问题扣分
score -= len(metrics.code_smells) * 5 # 代码异味扣分
score -= max(0, (metrics.lines_of_code - 500) // 100) * 2 # 代码过长扣分
# 奖励项
if metrics.comment_ratio > 0.15:
score += 5
if metrics.function_count > 0 and metrics.lines_of_code / metrics.function_count < 100:
score += 3
score = max(0, min(100, score))
# 确定质量等级
if score >= 90:
level = QualityLevel.EXCELLENT
elif score >= 75:
level = QualityLevel.GOOD
elif score >= 60:
level = QualityLevel.ACCEPTABLE
elif score >= 40:
level = QualityLevel.NEEDS_IMPROVEMENT
else:
level = QualityLevel.UNACCEPTABLE
# 生成建议
recommendations = []
if metrics.cyclomatic_complexity > 10:
recommendations.append("Consider refactoring to reduce cyclomatic complexity")
if metrics.security_issues:
recommendations.append("Address security issues before production deployment")
if metrics.code_smells:
recommendations.append("Review code for maintainability improvements")
return EvaluationResult(
metrics=metrics,
overall_score=score,
quality_level=level,
passed_checks=self._get_passed_checks(metrics),
failed_checks=self._get_failed_checks(metrics),
recommendations=recommendations
)
def _calculate_comment_ratio(self, source_code: str) -> float:
"""计算注释比例"""
total_lines = len([l for l in source_code.split('\n') if l.strip()])
comment_lines = len(re.findall(r'#.*$', source_code, re.MULTILINE))
return comment_lines / total_lines if total_lines > 0 else 0
def _get_passed_checks(self, metrics: CodeMetrics) -> List[str]:
"""获取通过的检查项"""
checks = []
if metrics.cyclomatic_complexity <= 10:
checks.append("Cyclomatic complexity is within acceptable range")
if not metrics.security_issues:
checks.append("No security issues detected")
if not metrics.code_smells:
checks.append("No significant code smells detected")
return checks
def _get_failed_checks(self, metrics: CodeMetrics) -> List[str]:
"""获取失败的检查项"""
checks = []
if metrics.cyclomatic_complexity > 10:
checks.append(f"High cyclomatic complexity: {metrics.cyclomatic_complexity}")
if metrics.security_issues:
checks.append(f"Security issues found: {len(metrics.security_issues)}")
return checks
def save_result(self, result: EvaluationResult, file_path: str, model_version: str):
"""保存评估结果到数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
INSERT INTO code_evaluations
(timestamp, file_path, model_version, overall_score, quality_level,
lines_of_code, complexity, security_issues_count)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
datetime.now().isoformat(),
file_path,
model_version,
result.overall_score,
result.quality_level.value,
result.metrics.lines_of_code,
result.metrics.cyclomatic_complexity,
len(result.metrics.security_issues)
))
conn.commit()
conn.close()
def generate_report(self, model_versions: List[str]) -> Dict:
"""生成模型对比报告"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
report = {}
for version in model_versions:
cursor.execute("""
SELECT
AVG(overall_score) as avg_score,
AVG(complexity) as avg_complexity,
AVG(security_issues_count) as avg_security,
COUNT(*) as total_evaluations
FROM code_evaluations
WHERE model_version = ?
""", (version,))
row = cursor.fetchone()
report[version] = {
"average_score": row[0] or 0,
"average_complexity": row[1] or 0,
"average_security_issues": row[2] or 0,
"total_evaluations": row[3] or 0
}
conn.close()
return report
# 使用示例
if __name__ == "__main__":
evaluator = ClaudeCodeQualityEvaluator()
sample_code = '''
def process_user_data(user_id: int, data: dict) -> dict:
"""处理用户数据"""
# 连接数据库
import sqlite3
conn = sqlite3.connect("users.db")
cursor = conn.cursor()
# 查询用户
query = "SELECT * FROM users WHERE id = " + str(user_id)
cursor.execute(query)
result = cursor.fetchone()
# 密码验证
password = "hardcoded_secret_12345"
# 处理逻辑
if result:
return {"status": "success", "data": result}
else:
return {"status": "error", "message": "User not found"}
'''
result = evaluator.evaluate(sample_code, "user_processing.py", "Claude Opus 4.6")
print(f"Overall Score: {result.overall_score}")
print(f"Quality Level: {result.quality_level.value}")
print(f"Security Issues: {len(result.metrics.security_issues)}")
print(f"Recommendations: {result.recommendations}")
2.2 递归自我改进系统的伪代码架构
以下是递归自我改进系统的 Go 语言伪代码架构:
package rsis
/*
递归自我改进系统 (Recursive Self-Improvement System)
Anthropic RSI 架构核心实现
该系统展示了 AI 如何实现递归自我改进的关键组件:
1. 目标生成器 - 确定改进方向
2. 候选生成器 - 生成改进候选方案
3. 评估器 - 评估候选方案的有效性
4. 执行器 - 执行选定的改进
5. 元学习器 - 学习改进过程本身
*/
import (
"context"
"encoding/json"
"fmt"
"log"
"math"
"math/rand"
"sync"
"time"
)
// ============ 核心数据类型 ============
// Objective 定义改进目标
type Objective struct {
ID string `json:"id"`
Description string `json:"description"`
Priority float64 `json:"priority"`
Metrics map[string]float64 `json:"metrics"`
Constraints map[string]interface{} `json:"constraints"`
CreatedAt time.Time `json:"created_at"`
}
// CandidateImprovement 候选改进方案
type CandidateImprovement struct {
ID string `json:"id"`
ObjectiveID string `json:"objective_id"`
GeneratedBy string `json:"generated_by"` // "ai" 或 "human"
CodeChanges string `json:"code_changes"`
Reasoning string `json:"reasoning"`
ExpectedGain float64 `json:"expected_gain"`
RiskLevel string `json:"risk_level"` // "low", "medium", "high", "critical"
Dependencies []string `json:"dependencies"`
ValidationTests []string `json:"validation_tests"`
}
// EvaluationResult 评估结果
type EvaluationResult struct {
CandidateID string `json:"candidate_id"`
PerformanceScore float64 `json:"performance_score"` // 0.0 - 1.0
SafetyScore float64 `json:"safety_score"` // 0.0 - 1.0
AlignmentScore float64 `json:"alignment_score"` // 0.0 - 1.0
OverallScore float64 `json:"overall_score"`
Warnings []string `json:"warnings"`
MetricsDelta map[string]float64 `json:"metrics_delta"`
}
// ImprovementExecution 改进执行记录
type ImprovementExecution struct {
ID string `json:"id"`
CandidateID string `json:"candidate_id"`
Status string `json:"status"` // "pending", "running", "completed", "reverted"
StartedAt time.Time `json:"started_at"`
CompletedAt time.Time `json:"completed_at"`
RollbackAvailable bool `json:"rollback_available"`
RollbackSnapshot []byte `json:"rollback_snapshot"`
}
// MetaLearningRecord 元学习记录
type MetaLearningRecord struct {
ID string `json:"id"`
ObjectiveType string `json:"objective_type"`
SuccessfulImprovements []string `json:"successful_improvements"`
FailedImprovements []string `json:"failed_improvements"`
Patterns map[string]int `json:"patterns"`
SuccessRate float64 `json:"success_rate"`
}
// ============ 核心接口定义 ============
// ObjectiveGenerator 目标生成器接口
type ObjectiveGenerator interface {
Generate(ctx context.Context, systemState SystemState) ([]Objective, error)
Prioritize(objectives []Objective) []Objective
}
// CandidateGenerator 候选生成器接口
type CandidateGenerator interface {
Generate(ctx context.Context, objective Objective) ([]CandidateImprovement, error)
Mutate(candidate CandidateImprovement) ([]CandidateImprovement, error)
}
// Evaluator 评估器接口
type Evaluator interface {
Evaluate(ctx context.Context, candidate CandidateImprovement) (*EvaluationResult, error)
EvaluateBatch(ctx context.Context, candidates []CandidateImprovement) ([]*EvaluationResult, error)
}
// Executor 执行器接口
type Executor interface {
Execute(ctx context.Context, candidate CandidateImprovement) (*ImprovementExecution, error)
Rollback(execution ImprovementExecution) error
Verify(execution ImprovementExecution) (bool, error)
}
// MetaLearner 元学习器接口
type MetaLearner interface {
Learn(record MetaLearningRecord) error
GetStrategy(objectiveType string) (ImprovementStrategy, error)
}
// ============ 系统状态 ============
// SystemState 系统当前状态
type SystemState struct {
Metrics map[string]float64 `json:"metrics"`
CodeSnapshot string `json:"code_snapshot"`
ModelWeights []byte `json:"model_weights"`
TrainingData []byte `json:"training_data"`
Configuration map[string]string `json:"configuration"`
ActiveObjectives []string `json:"active_objectives"`
LastImprovementAt time.Time `json:"last_improvement_at"`
}
// ImprovementStrategy 改进策略
type ImprovementStrategy struct {
GeneratorType string `json:"generator_type"`
EvaluationBudget int `json:"evaluation_budget"`
RiskTolerance float64 `json:"risk_tolerance"`
Parallelism int `json:"parallelism"`
}
// ============ 递归自我改进系统核心实现 ============
// RecursiveSelfImprovementSystem 递归自我改进系统主类
type RecursiveSelfImprovementSystem struct {
config *RSISConfig
objectiveGenerator ObjectiveGenerator
candidateGenerator CandidateGenerator
evaluator Evaluator
executor Executor
metaLearner MetaLearner
mu sync.RWMutex
currentState *SystemState
executionHistory []*ImprovementExecution
improvementCount int
maxRecursionDepth int
}
// RSISConfig 系统配置
type RSISConfig struct {
MaxIterationsPerCycle int `json:"max_iterations_per_cycle"`
MaxCandidatesPerObjective int `json:"max_candidates_per_objective"`
MinImprovementThreshold float64 `json:"min_improvement_threshold"`
EvaluationTimeoutSeconds int `json:"evaluation_timeout_seconds"`
RollbackEnabled bool `json:"rollback_enabled"`
SafetyBounds *SafetyBounds `json:"safety_bounds"`
HumanInTheLoop bool `json:"human_in_the_loop"`
}
// SafetyBounds 安全边界
type SafetyBounds struct {
MaxComplexityIncrease float64 `json:"max_complexity_increase"`
MinSafetyScore float64 `json:"min_safety_score"`
MaxResourceUsage float64 `json:"max_resource_usage"`
ForbiddenPatterns []string `json:"forbidden_patterns"`
}
// NewRecursiveSelfImprovementSystem 创建新的 RSI 系统
func NewRecursiveSelfImprovementSystem(config *RSISConfig) *RecursiveSelfImprovementSystem {
return &RecursiveSelfImprovementSystem{
config: config,
executionHistory: make([]*ImprovementExecution, 0),
maxRecursionDepth: 0,
}
}
// RunSelfImprovementCycle 运行自我改进循环
func (rsis *RecursiveSelfImprovementSystem) RunSelfImprovementCycle(ctx context.Context) error {
rsis.mu.Lock()
defer rsis.mu.Unlock()
log.Println("Starting self-improvement cycle...")
// 第一阶段:生成改进目标
objectives, err := rsis.objectiveGenerator.Generate(ctx, *rsis.currentState)
if err != nil {
return fmt.Errorf("objective generation failed: %w", err)
}
// 对目标进行优先级排序
objectives = rsis.objectiveGenerator.Prioritize(objectives)
log.Printf("Generated %d improvement objectives", len(objectives))
// 第二阶段:生成和评估候选方案
var allCandidates []CandidateImprovement
for _, obj := range objectives {
candidates, err := rsis.candidateGenerator.Generate(ctx, obj)
if err != nil {
log.Printf("Warning: candidate generation failed for objective %s: %v", obj.ID, err)
continue
}
allCandidates = append(allCandidates, candidates...)
}
// 限制候选数量
if len(allCandidates) > rsis.config.MaxCandidatesPerObjective {
allCandidates = allCandidates[:rsis.config.MaxCandidatesPerObjective]
}
log.Printf("Generated %d candidate improvements", len(allCandidates))
// 第三阶段:评估所有候选
results, err := rsis.evaluator.EvaluateBatch(ctx, allCandidates)
if err != nil {
return fmt.Errorf("evaluation failed: %w", err)
}
// 第四阶段:选择最佳改进方案
bestCandidate, bestResult := rsis.selectBestCandidate(allCandidates, results)
if bestCandidate == nil {
log.Println("No candidate meets the improvement threshold")
return nil
}
// 第五阶段:执行改进
if rsis.config.HumanInTheLoop {
log.Println("Human approval required for this improvement")
// 实际实现中会暂停等待人类批准
approved := rsis.requestHumanApproval(bestCandidate, bestResult)
if !approved {
log.Println("Human rejected the improvement")
return nil
}
}
execution, err := rsis.executor.Execute(ctx, *bestCandidate)
if err != nil {
return fmt.Errorf("execution failed: %w", err)
}
// 第六阶段:验证改进
valid, err := rsis.executor.Verify(*execution)
if err != nil || !valid {
log.Printf("Verification failed, rolling back: %v", err)
if rsis.config.RollbackEnabled {
rsis.executor.Rollback(*execution)
}
return fmt.Errorf("improvement verification failed")
}
// 第七阶段:更新元学习
rsis.updateMetaLearning(bestCandidate, bestResult)
rsis.improvementCount++
rsis.executionHistory = append(rsis.executionHistory, execution)
log.Printf("Self-improvement cycle completed successfully. Total improvements: %d", rsis.improvementCount)
return nil
}
// selectBestCandidate 选择最佳候选方案
func (rsis *RecursiveSelfImprovementSystem) selectBestCandidate(
candidates []CandidateImprovement,
results []*EvaluationResult,
) (*CandidateImprovement, *EvaluationResult) {
var bestCandidate *CandidateImprovement
var bestResult *EvaluationResult
bestScore := -1.0
for i, result := range results {
// 计算加权得分
weightedScore :=
result.OverallScore * 0.4 +
result.SafetyScore * 0.3 +
result.AlignmentScore * 0.3
// 检查是否满足安全边界
if weightedScore > bestScore &&
weightedScore >= rsis.config.MinImprovementThreshold &&
result.SafetyScore >= rsis.config.SafetyBounds.MinSafetyScore {
bestScore = weightedScore
bestCandidate = &candidates[i]
bestResult = result
}
}
return bestCandidate, bestResult
}
// requestHumanApproval 请求人类批准
func (rsis *RecursiveSelfImprovementSystem) requestHumanApproval(
candidate *CandidateImprovement,
result *EvaluationResult,
) bool {
// 实际实现中会通过 UI 或通知系统请求批准
// 这里简化为返回 true
log.Printf("Human approval requested for candidate %s (score: %.2f)",
candidate.ID, result.OverallScore)
return true
}
// updateMetaLearning 更新元学习记录
func (rsis *RecursiveSelfImprovementSystem) updateMetaLearning(
candidate *CandidateImprovement,
result *EvaluationResult,
) {
record := MetaLearningRecord{
ID: fmt.Sprintf("meta_%d", time.Now().UnixNano()),
ObjectiveType: candidate.ObjectiveID,
}
if result.OverallScore > rsis.config.MinImprovementThreshold {
record.SuccessfulImprovements = []string{candidate.ID}
record.FailedImprovements = []string{}
record.SuccessRate = 1.0
} else {
record.SuccessfulImprovements = []string{}
record.FailedImprovements = []string{candidate.ID}
record.SuccessRate = 0.0
}
rsis.metaLearner.Learn(record)
}
// RunRecursiveSelfImprovement 运行递归自我改进
// 这是核心方法,实现递归改进循环
func (rsis *RecursiveSelfImprovementSystem) RunRecursiveSelfImprovement(ctx context.Context) error {
rsis.mu.Lock()
rsis.maxRecursionDepth++
currentDepth := rsis.maxRecursionDepth
rsis.mu.Unlock()
defer func() {
rsis.mu.Lock()
rsis.maxRecursionDepth--
rsis.mu.Unlock()
}()
log.Printf("Starting recursive self-improvement (depth: %d)", currentDepth)
// 检查递归深度限制
if currentDepth > rsis.config.MaxIterationsPerCycle {
log.Println("Maximum recursion depth reached")
return nil
}
// 运行一轮自我改进
err := rsis.RunSelfImprovementCycle(ctx)
if err != nil {
return fmt.Errorf("self-improvement cycle failed at depth %d: %w", currentDepth, err)
}
// 检查是否需要继续递归
if rsis.shouldContinueRecursion() {
// 递归调用自身
return rsis.RunRecursiveSelfImprovement(ctx)
}
log.Printf("Recursive self-improvement completed at depth %d", currentDepth)
return nil
}
// shouldContinueRecursion 判断是否继续递归
func (rsis *RecursiveSelfImprovementSystem) shouldContinueRecursion() bool {
// 检查系统是否仍在获得显著改进
if len(rsis.executionHistory) < 2 {
return true
}
// 计算最近几次改进的平均得分
recentHistory := rsis.executionHistory[len(rsis.executionHistory)-3:]
// 简化判断:随机决定是否继续
return rand.Float64() > 0.3
}
// ============ 模拟实现 ============
// SimpleObjectiveGenerator 简单目标生成器
type SimpleObjectiveGenerator struct{}
func (g *SimpleObjectiveGenerator) Generate(ctx context.Context, state SystemState) ([]Objective, error) {
// 模拟生成改进目标
return []Objective{
{
ID: "obj_001",
Description: "Improve code generation speed",
Priority: 0.8,
Metrics: map[string]float64{"latency": 100.0},
},
{
ID: "obj_002",
Description: "Reduce memory usage",
Priority: 0.7,
Metrics: map[string]float64{"memory_mb": 500.0},
},
}, nil
}
func (g *SimpleObjectiveGenerator) Prioritize(objectives []Objective) []Objective {
// 按优先级排序
for i := 0; i < len(objectives)-1; i++ {
for j := i + 1; j < len(objectives); j++ {
if objectives[j].Priority > objectives[i].Priority {
objectives[i], objectives[j] = objectives[j], objectives[i]
}
}
}
return objectives
}
// ============ 主函数示例 ============
func main() {
config := &RSISConfig{
MaxIterationsPerCycle: 5,
MaxCandidatesPerObjective: 10,
MinImprovementThreshold: 0.7,
EvaluationTimeoutSeconds: 60,
RollbackEnabled: true,
HumanInTheLoop: true,
SafetyBounds: &SafetyBounds{
MaxComplexityIncrease: 1.2,
MinSafetyScore: 0.8,
MaxResourceUsage: 0.9,
},
}
rsis := NewRecursiveSelfImprovementSystem(config)
rsis.objectiveGenerator = &SimpleObjectiveGenerator{}
ctx := context.Background()
// 运行递归自我改进
err := rsis.RunRecursiveSelfImprovement(ctx)
if err != nil {
log.Fatalf("Recursive self-improvement failed: %v", err)
}
fmt.Printf("Total improvements made: %d\n", rsis.improvementCount)
}
三、AI 编码任务成功率统计分析
3.1 Python + SQL 数据分析系统
"""
AI 编码任务成功率统计分析系统
用于跟踪和分析 Claude 在不同任务类型上的表现
"""
import sqlite3
from dataclasses import dataclass
from typing import List, Dict, Optional, Tuple
from datetime import datetime, timedelta
import statistics
@dataclass
class TaskRecord:
"""任务记录"""
task_id: str
task_type: str
model_version: str
started_at: datetime
completed_at: Optional[datetime]
success: bool
human_intervention: bool
lines_generated: int
tokens_used: int
error_message: Optional[str] = None
class TaskAnalytics:
"""任务分析器"""
def __init__(self, db_path: str = "task_analytics.db"):
self.db_path = db_path
self._init_schema()
def _init_schema(self):
"""初始化数据库 schema"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 主任务表
cursor.execute("""
CREATE TABLE IF NOT EXISTS tasks (
task_id TEXT PRIMARY KEY,
task_type TEXT NOT NULL,
model_version TEXT NOT NULL,
started_at TEXT NOT NULL,
completed_at TEXT,
success INTEGER NOT NULL,
human_intervention INTEGER NOT NULL,
lines_generated INTEGER DEFAULT 0,
tokens_used INTEGER DEFAULT 0,
error_message TEXT,
created_date DATE DEFAULT CURRENT_DATE
)
""")
# 子任务表(用于分析复杂任务分解)
cursor.execute("""
CREATE TABLE IF NOT EXISTS subtasks (
subtask_id TEXT PRIMARY KEY,
parent_task_id TEXT NOT NULL,
subtask_type TEXT NOT NULL,
sequence_order INTEGER NOT NULL,
success INTEGER NOT NULL,
duration_seconds INTEGER,
FOREIGN KEY (parent_task_id) REFERENCES tasks(task_id)
)
""")
# 性能指标表
cursor.execute("""
CREATE TABLE IF NOT EXISTS performance_metrics (
id INTEGER PRIMARY KEY AUTOINCREMENT,
date DATE NOT NULL,
model_version TEXT NOT NULL,
task_type TEXT NOT NULL,
success_rate REAL NOT NULL,
avg_duration_seconds REAL,
avg_tokens_per_task REAL,
human_intervention_rate REAL,
total_tasks INTEGER
)
""")
# 创建索引
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_tasks_model
ON tasks(model_version)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_tasks_type
ON tasks(task_type)
""")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_tasks_date
ON tasks(created_date)
""")
conn.commit()
conn.close()
def record_task(self, task: TaskRecord):
"""记录任务"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
INSERT OR REPLACE INTO tasks
(task_id, task_type, model_version, started_at, completed_at,
success, human_intervention, lines_generated, tokens_used, error_message)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
task.task_id,
task.task_type,
task.model_version,
task.started_at.isoformat(),
task.completed_at.isoformat() if task.completed_at else None,
int(task.success),
int(task.human_intervention),
task.lines_generated,
task.tokens_used,
task.error_message
))
conn.commit()
conn.close()
def calculate_success_rate(
self,
model_version: Optional[str] = None,
task_type: Optional[str] = None,
date_range: Optional[Tuple[datetime, datetime]] = None
) -> Dict:
"""计算成功率"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
query = "SELECT success, human_intervention FROM tasks WHERE 1=1"
params = []
if model_version:
query += " AND model_version = ?"
params.append(model_version)
if task_type:
query += " AND task_type = ?"
params.append(task_type)
if date_range:
query += " AND started_at BETWEEN ? AND ?"
params.extend([date_range[0].isoformat(), date_range[1].isoformat()])
cursor.execute(query, params)
results = cursor.fetchall()
conn.close()
if not results:
return {"success_rate": 0.0, "total_tasks": 0}
total = len(results)
successful = sum(1 for r in results if r[0] == 1)
human_interventions = sum(1 for r in results if r[1] == 1)
return {
"success_rate": successful / total,
"human_intervention_rate": human_interventions / total,
"total_tasks": total,
"successful_tasks": successful
}
def get_trend_analysis(self, model_versions: List[str], task_type: str) -> List[Dict]:
"""获取趋势分析"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
trends = []
for version in model_versions:
cursor.execute("""
SELECT
model_version,
task_type,
COUNT(*) as total,
SUM(CASE WHEN success = 1 THEN 1 ELSE 0 END) as successful,
AVG(tokens_used) as avg_tokens,
AVG(lines_generated) as avg_lines
FROM tasks
WHERE model_version = ? AND task_type = ?
GROUP BY model_version, task_type
""", (version, task_type))
row = cursor.fetchone()
if row:
trends.append({
"model_version": row[0],
"task_type": row[1],
"total_tasks": row[2],
"successful": row[3],
"success_rate": row[3] / row[2] if row[2] > 0 else 0,
"avg_tokens": row[4] or 0,
"avg_lines_generated": row[5] or 0
})
conn.close()
return trends
def generate_monthly_report(self, year: int, month: int) -> str:
"""生成月度报告"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
start_date = f"{year}-{month:02d}-01"
if month == 12:
end_date = f"{year+1}-01-01"
else:
end_date = f"{year}-{month+1:02d}-01"
# 按模型版本统计
cursor.execute("""
SELECT
model_version,
COUNT(*) as total_tasks,
SUM(success) as successful,
AVG(tokens_used) as avg_tokens,
AVG(lines_generated) as avg_lines
FROM tasks
WHERE created_date >= ? AND created_date < ?
GROUP BY model_version
ORDER BY total_tasks DESC
""", (start_date, end_date))
model_stats = cursor.fetchall()
# 按任务类型统计
cursor.execute("""
SELECT
task_type,
COUNT(*) as total,
SUM(success) as successful,
AVG(tokens_used) as avg_tokens
FROM tasks
WHERE created_date >= ? AND created_date < ?
GROUP BY task_type
ORDER BY total DESC
""", (start_date, end_date))
type_stats = cursor.fetchall()
conn.close()
# 生成报告
report = f"""# Claude 代码生成月度报告
## 报告期间
{year}年 {month}月
## 总体统计
| 模型版本 | 任务总数 | 成功数 | 成功率 | 平均Token数 | 平均代码行数 |
|---------|---------|--------|-------|------------|-------------|
"""
for stat in model_stats:
success_rate = stat[2] / stat[1] if stat[1] > 0 else 0
report += f"| {stat[0]} | {stat[1]} | {stat[2]} | {success_rate:.1%} | {stat[3]:.0f} | {stat[4]:.1f} |\n"
report += f"""
## 任务类型分析
| 任务类型 | 任务总数 | 成功数 | 成功率 | 平均Token数 |
|---------|---------|--------|-------|------------|
"""
for stat in type_stats:
success_rate = stat[2] / stat[1] if stat[1] > 0 else 0
report += f"| {stat[0]} | {stat[1]} | {stat[2]} | {success_rate:.1%} | {stat[3]:.0f} |\n"
return report
# SQL 查询示例:复杂分析
SQL_QUERIES = """
-- 查询成功率随时间变化
SELECT
DATE(created_date) as date,
model_version,
COUNT(*) as total,
CAST(SUM(success) AS REAL) / COUNT(*) as success_rate
FROM tasks
WHERE created_date >= DATE('now', '-6 months')
GROUP BY DATE(created_date), model_version
ORDER BY date;
-- 查询需要人类干预的任务特征
SELECT
task_type,
model_version,
COUNT(*) as total_interventions,
AVG(tokens_used) as avg_tokens,
AVG(lines_generated) as avg_lines
FROM tasks
WHERE human_intervention = 1
GROUP BY task_type, model_version
ORDER BY total_interventions DESC;
-- 查询代码质量与Token使用量的关系
SELECT
CASE
WHEN lines_generated < 50 THEN 'small'
WHEN lines_generated < 200 THEN 'medium'
ELSE 'large'
END as task_size,
model_version,
AVG(CASE WHEN success = 1 THEN 1.0 ELSE 0.0 END) as success_rate,
AVG(tokens_used) as avg_tokens,
COUNT(*) as total
FROM tasks
GROUP BY
CASE
WHEN lines_generated < 50 THEN 'small'
WHEN lines_generated < 200 THEN 'medium'
ELSE 'large'
END,
model_version;
-- 查询连续失败模式
WITH task_sequence AS (
SELECT
task_id,
task_type,
success,
LAG(success) OVER (PARTITION BY task_type ORDER BY started_at) as prev_success,
LEAD(success) OVER (PARTITION BY task_type ORDER BY started_at) as next_success
FROM tasks
)
SELECT
task_type,
COUNT(*) as consecutive_failures
FROM task_sequence
WHERE success = 0
AND prev_success = 0
AND next_success = 0
GROUP BY task_type;
"""
if __name__ == "__main__":
analytics = TaskAnalytics()
# 模拟记录任务数据
sample_tasks = [
TaskRecord(
task_id="task_001",
task_type="code_generation",
model_version="Claude Opus 4.6",
started_at=datetime(2026, 6, 1, 10, 0),
completed_at=datetime(2026, 6, 1, 10, 5),
success=True,
human_intervention=False,
lines_generated=150,
tokens_used=5000
),
TaskRecord(
task_id="task_002",
task_type="bug_fix",
model_version="Claude Opus 4.6",
started_at=datetime(2026, 6, 1, 11, 0),
completed_at=datetime(2026, 6, 1, 11, 10),
success=True,
human_intervention=False,
lines_generated=25,
tokens_used=3500
),
TaskRecord(
task_id="task_003",
task_type="refactoring",
model_version="Claude Opus 4.6",
started_at=datetime(2026, 6, 1, 14, 0),
completed_at=None,
success=False,
human_intervention=True,
lines_generated=80,
tokens_used=8000,
error_message="Complexity exceeded threshold"
),
]
for task in sample_tasks:
analytics.record_task(task)
# 计算成功率
result = analytics.calculate_success_rate(
model_version="Claude Opus 4.6",
task_type="code_generation"
)
print(f"Success Rate: {result['success_rate']:.2%}")
print(f"Total Tasks: {result['total_tasks']}")
四、自动化代码审查流程
4.1 端到端代码审查系统
以下是一个完整的自动化代码审查流程,包含 Python 主程序和 Shell 脚本:
#!/usr/bin/env python3
"""
Anthropic Claude 代码审查自动化系统
Claude Code Review - Production Edition
功能:
1. 自动扫描 Pull Request
2. 执行多维度代码审查
3. 生成审查报告
4. 与 CI/CD 集成
5. 跟踪审查历史
"""
import os
import re
import json
import sqlite3
import subprocess
import hashlib
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Set, Tuple
from datetime import datetime
from enum import Enum
import concurrent.futures
from pathlib import Path
import argparse
import logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class Severity(Enum):
"""问题严重程度"""
CRITICAL = "critical"
HIGH = "high"
MEDIUM = "medium"
LOW = "low"
INFO = "info"
class IssueCategory(Enum):
"""问题类别"""
SECURITY = "security"
PERFORMANCE = "performance"
CORRECTNESS = "correctness"
STYLE = "style"
MAINTAINABILITY = "maintainability"
TESTING = "testing"
DOCUMENTATION = "documentation"
@dataclass
class CodeIssue:
"""代码问题"""
line_number: int
severity: Severity
category: IssueCategory
title: str
description: str
code_snippet: str
suggestion: str
rule_id: str
effort_minutes: int = 15
@dataclass
class ReviewResult:
"""审查结果"""
repository: str
pull_request: str
branch: str
commit_sha: str
timestamp: datetime
total_files: int
total_lines_added: int
total_lines_removed: int
issues: List[CodeIssue] = field(default_factory=list)
duration_seconds: float = 0.0
claude_model: str = "claude-opus-4-5"
@property
def critical_issues(self) -> List[CodeIssue]:
return [i for i in self.issues if i.severity == Severity.CRITICAL]
@property
def high_issues(self) -> List[CodeIssue]:
return [i for i in self.issues if i.severity == Severity.HIGH]
@property
def issues_by_category(self) -> Dict[IssueCategory, List[CodeIssue]]:
result = {}
for issue in self.issues:
if issue.category not in result:
result[issue.category] = []
result[issue.category].append(issue)
return result
def can_merge(self, config: 'ReviewConfig') -> Tuple[bool, str]:
"""判断是否可以合并"""
if self.critical_issues:
return False, f"Found {len(self.critical_issues)} critical issues"
if len(self.high_issues) > config.max_high_issues:
return False, f"Found {len(self.high_issues)} high severity issues (max: {config.max_high_issues})"
total_issues = len(self.issues)
if total_issues > config.max_total_issues:
return False, f"Found {total_issues} total issues (max: {config.max_total_issues})"
return True, "All checks passed"
@dataclass
class ReviewConfig:
"""审查配置"""
max_high_issues: int = 5
max_total_issues: int = 50
require_security_review: bool = True
require_tests_for_new_code: bool = True
min_test_coverage: float = 80.0
block_on_security: bool = True
block_on_performance: bool = False
enable_ai_analysis: bool = True
ai_model: str = "claude-opus-4-5"
context_lines: int = 3
class SecurityAnalyzer:
"""安全分析器"""
# 安全规则定义
SECURITY_RULES = {
"sql_injection": {
"severity": Severity.CRITICAL,
"patterns": [
r'execute\s*\(\s*f["\']', # f-string in SQL
r'cursor\.execute\s*\(.*\+', # String concat
r'FROM.*\%s.*\%.*\(', # % formatting
r'SELECT.*\+.*WHERE', # String building
],
"suggestion": "Use parameterized queries or ORM",
"effort_minutes": 30
},
"command_injection": {
"severity": Severity.CRITICAL,
"patterns": [
r'os\.system\s*\(',
r'subprocess\..*shell\s*=\s*True',
r'eval\s*\(',
r'exec\s*\(',
],
"suggestion": "Avoid shell execution; use subprocess with explicit arguments",
"effort_minutes": 45
},
"hardcoded_secrets": {
"severity": Severity.HIGH,
"patterns": [
r'password\s*=\s*["\'][^"\']{8,}["\']',
r'api[_-]?key\s*=\s*["\'][A-Za-z0-9]{20,}["\']',
r'secret\s*=\s*["\'][^"\']{16,}["\']',
r'token\s*=\s*["\'][A-Za-z0-9_-]{20,}["\']',
r'private[_-]?key\s*=\s*["\']',
],
"suggestion": "Use environment variables or secrets manager",
"effort_minutes": 15
},
"path_traversal": {
"severity": Severity.HIGH,
"patterns": [
r'open\s*\([^)]*path\.join.*\.\.', # path.join with ..
r'os\.path\.join.*request\.', # user input in path
r'static.*send_file.*user_', # user-controlled file paths
],
"suggestion": "Validate and sanitize file paths; use allowlists",
"effort_minutes": 30
},
"xxe": {
"severity": Severity.CRITICAL,
"patterns": [
r'ElementTree\.parse',
r'xml\.etree\.ElementTree',
r'defusedxml',
],
"suggestion": "Use defusedxml library; disable external entities",
"effort_minutes": 20
},
"deserialization": {
"severity": Severity.CRITICAL,
"patterns": [
r'pickle\.loads?',
r'yaml\.load\s*\(',
r'marshal\.loads?',
r'shelve\.open',
],
"suggestion": "Use secure serialization; validate input",
"effort_minutes": 45
},
}
def analyze_file(self, file_path: str, content: str) -> List[CodeIssue]:
"""分析单个文件的安全问题"""
issues = []
for rule_name, rule in self.SECURITY_RULES.items():
for line_num, line in enumerate(content.split('\n'), 1):
for pattern in rule['patterns']:
if re.search(pattern, line, re.IGNORECASE):
issues.append(CodeIssue(
line_number=line_num,
severity=rule['severity'],
category=IssueCategory.SECURITY,
title=f"Security: {rule_name}",
description=f"Potential {rule_name} vulnerability detected",
code_snippet=line.strip(),
suggestion=rule['suggestion'],
rule_id=f"SEC-{rule_name.upper()}",
effort_minutes=rule['effort_minutes']
))
return issues
class PerformanceAnalyzer:
"""性能分析器"""
PERFORMANCE_RULES = {
"n_plus_one": {
"severity": Severity.MEDIUM,
"patterns": [
r'for.*in.*:\s*\n\s*.*\.query\(',
r'for.*in.*:\s*\n\s*.*\.find\(',
r'for.*in.*:\s*\n\s*.*\.get\(',
],
"suggestion": "Use bulk operations or query optimization",
"effort_minutes": 60
},
"nested_loops_db": {
"severity": Severity.HIGH,
"patterns": [
r'for.*in.*:\s*\n\s*.*for.*in.*:\s*\n\s*.*\.(query|execute|select)',
],
"suggestion": "Flatten loops; use JOIN or batch operations",
"effort_minutes": 90
},
"memory_inefficient": {
"severity": Severity.MEDIUM,
"patterns": [
r'\.read\s*\(\s*\)', # Reading entire file
r'\.readlines\s*\(\s*\)',
r'list\s*\(\s*.*\.keys\s*\(\s*\)\s*\)',
],
"suggestion": "Use generators or streaming for large data",
"effort_minutes": 30
},
}
def analyze_file(self, file_path: str, content: str) -> List[CodeIssue]:
"""分析单个文件的性能问题"""
issues = []
for rule_name, rule in self.PERFORMANCE_RULES.items():
for line_num, line in enumerate(content.split('\n'), 1):
for pattern in rule['patterns']:
if re.search(pattern, line, re.DOTALL):
issues.append(CodeIssue(
line_number=line_num,
severity=rule['severity'],
category=IssueCategory.PERFORMANCE,
title=f"Performance: {rule_name}",
description=f"Potential {rule_name} issue detected",
code_snippet=line.strip(),
suggestion=rule['suggestion'],
rule_id=f"PERF-{rule_name.upper()}",
effort_minutes=rule['effort_minutes']
))
return issues
class CodeReviewPipeline:
"""代码审查管道"""
def __init__(self, config: ReviewConfig):
self.config = config
self.security_analyzer = SecurityAnalyzer()
self.performance_analyzer = PerformanceAnalyzer()
self.db_path = "code_review.db"
self._init_database()
def _init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS reviews (
id INTEGER PRIMARY KEY AUTOINCREMENT,
repository TEXT NOT NULL,
pull_request TEXT NOT NULL,
branch TEXT NOT NULL,
commit_sha TEXT NOT NULL,
timestamp TEXT NOT NULL,
total_files INTEGER,
lines_added INTEGER,
lines_removed INTEGER,
duration_seconds REAL,
result_json TEXT,
UNIQUE(commit_sha)
)
""")
cursor.execute("""
CREATE TABLE IF NOT EXISTS issues (
id INTEGER PRIMARY KEY AUTOINCREMENT,
review_id INTEGER NOT NULL,
file_path TEXT,
line_number INTEGER,
severity TEXT,
category TEXT,
title TEXT,
description TEXT,
code_snippet TEXT,
suggestion TEXT,
rule_id TEXT,
FOREIGN KEY (review_id) REFERENCES reviews(id)
)
""")
conn.commit()
conn.close()
def review_files(self, files: List[Tuple[str, str]]) -> List[CodeIssue]:
"""审查多个文件"""
all_issues = []
# 并行分析文件
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
future_to_file = {
executor.submit(self._analyze_single_file, path, content): path
for path, content in files
}
for future in concurrent.futures.as_completed(future_to_file):
try:
issues = future.result()
all_issues.extend(issues)
except Exception as e:
logger.error(f"Error analyzing file: {e}")
return all_issues
def _analyze_single_file(self, file_path: str, content: str) -> List[CodeIssue]:
"""分析单个文件"""
issues = []
# 安全分析
issues.extend(self.security_analyzer.analyze_file(file_path, content))
# 性能分析
issues.extend(self.performance_analyzer.analyze_file(file_path, content))
return issues
def generate_report(self, result: ReviewResult) -> str:
"""生成审查报告"""
report = f"""
# Code Review Report
## Summary
- **Repository**: {result.repository}
- **Pull Request**: #{result.pull_request}
- **Branch**: {result.branch}
- **Commit**: {result.commit_sha[:8]}
- **Timestamp**: {result.timestamp.isoformat()}
- **Duration**: {result.duration_seconds:.1f}s
## Changes
- **Files Changed**: {result.total_files}
- **Lines Added**: +{result.total_lines_added}
- **Lines Removed**: -{result.total_lines_removed}
## Issues Summary
| Severity | Count |
|----------|-------|
| Critical | {len(result.critical_issues)} |
| High | {len(result.high_issues)} |
| Medium | {len([i for i in result.issues if i.severity == Severity.MEDIUM])} |
| Low | {len([i for i in result.issues if i.severity == Severity.LOW])} |
| **Total** | **{len(result.issues)}** |
## Issues by Category
"""
for category, category_issues in result.issues_by_category.items():
report += f"- **{category.value}**: {len(category_issues)}\n"
if result.issues:
report += "\n## Detailed Issues\n"
for issue in sorted(result.issues, key=lambda x: x.severity.value):
report += f"""
### {issue.title}
- **Severity**: {issue.severity.value}
- **Category**: {issue.category.value}
- **File**: {issue.line_number}
- **Rule**: {issue.rule_id}
{issue.code_snippet}
**Description**: {issue.description}
**Suggestion**: {issue.suggestion}
**Estimated Fix Time**: {issue.effort_minutes} minutes
---
"""
can_merge, message = result.can_merge(self.config)
report += f"""
## Merge Decision
{'✅ CAN MERGE' if can_merge else '❌ CANNOT MERGE'}: {message}
---
*Generated by Claude Code Review System*
"""
return report
def main():
parser = argparse.ArgumentParser(description="Claude Code Review System")
parser.add_argument("--repo", required=True, help="Repository name")
parser.add_argument("--pr", required=True, help="Pull request number")
parser.add_argument("--branch", required=True, help="Branch name")
parser.add_argument("--sha", required=True, help="Commit SHA")
parser.add_argument("--files", nargs="+", required=True, help="Files to review")
args = parser.parse_args()
# 读取文件内容
files = []
for file_path in args.files:
try:
with open(file_path, 'r') as f:
content = f.read()
files.append((file_path, content))
except Exception as e:
logger.warning(f"Could not read {file_path}: {e}")
# 运行审查
config = ReviewConfig()
pipeline = CodeReviewPipeline(config)
start_time = datetime.now()
issues = pipeline.review_files(files)
duration = (datetime.now() - start_time).total_seconds()
# 生成结果
result = ReviewResult(
repository=args.repo,
pull_request=args.pr,
branch=args.branch,
commit_sha=args.sha,
timestamp=datetime.now(),
total_files=len(files),
total_lines_added=sum(len(c.split('\n')) for _, c in files) // 2,
total_lines_removed=len(files) * 5, # 简化计算
issues=issues,
duration_seconds=duration
)
# 生成并输出报告
report = pipeline.generate_report(result)
print(report)
# 输出 JSON 格式结果供 CI 使用
print("\n## CI JSON Output")
print(json.dumps({
"can_merge": result.can_merge(config)[0],
"critical_count": len(result.critical_issues),
"high_count": len(result.high_issues),
"total_issues": len(result.issues),
"report": report
}, indent=2))
if __name__ == "__main__":
main()
4.2 Shell 集成脚本
#!/bin/bash
# Claude Code Review CI/CD 集成脚本
# 文件: claude_review.sh
set -euo pipefail
# 配置
GITHUB_TOKEN="${GITHUB_TOKEN:-}"
REPO_NAME="${GITHUB_REPO:-}"
PR_NUMBER="${CI_MERGE_REQUEST_IID:-}"
COMMIT_SHA="${CI_COMMIT_SHA:-}"
REVIEW_THRESHOLD="medium" # low, medium, high
# 颜色输出
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
log_info() {
echo -e "${GREEN}[INFO]${NC} $1"
}
log_warn() {
echo -e "${YELLOW}[WARN]${NC} $1"
}
log_error() {
echo -e "${RED}[ERROR]${NC} $1"
}
# 获取变更的文件列表
get_changed_files() {
local base_ref="${1:-HEAD~1}"
local head_ref="${2:-HEAD}"
git diff --name-only "${base_ref}".."${head_ref}" || true
}
# 获取文件内容
get_file_diff() {
local file="$1"
local base_ref="${2:-HEAD~1}"
local head_ref="${3:-HEAD}"
git diff "${base_ref}".."${head_ref}" -- "${file}" || true
}
# 运行 Claude 审查
run_claude_review() {
local pr_number="$1"
local commit_sha="$2"
shift 2
local files=("$@")
log_info "Starting Claude code review for PR #${pr_number}"
log_info "Commit: ${commit_sha}"
log_info "Files to review: ${#files[@]}"
# 调用 Python 审查脚本
python3 -m claude_review \
--repo "${REPO_NAME}" \
--pr "${pr_number}" \
--branch "${CI_COMMIT_REF_NAME:-unknown}" \
--sha "${commit_sha}" \
--files "${files[@]}"
}
# 主函数
main() {
log_info "Claude Code Review CI/CD Integration"
log_info "Repository: ${REPO_NAME}"
# 获取变更文件
local changed_files
changed_files=$(get_changed_files)
if [[ -z "${changed_files}" ]]; then
log_info "No files changed, skipping review"
exit 0
fi
# 过滤需要审查的文件
local files_to_review=()
while IFS= read -r file; do
# 只审查代码文件
if [[ "${file}" =~ \.(py|js|ts|go|java|cpp|c|rs|rb|php)$ ]]; then
files_to_review+=("${file}")
fi
done <<< "${changed_files}"
if [[ ${#files_to_review[@]} -eq 0 ]]; then
log_info "No code files to review"
exit 0
fi
# 运行审查
local review_output
review_output=$(run_claude_review "${PR_NUMBER}" "${COMMIT_SHA}" "${files_to_review[@]}")
# 解析结果
local can_merge
local critical_count
local high_count
local total_issues
can_merge=$(echo "${review_output}" | jq -r '.can_merge')
critical_count=$(echo "${review_output}" | jq -r '.critical_count')
high_count=$(echo "${review_output}" | jq -r '.high_count')
total_issues=$(echo "${review_output}" | jq -r '.total_issues')
# 输出结果
echo ""
log_info "Review Results:"
echo " - Critical Issues: ${critical_count}"
echo " - High Issues: ${high_count}"
echo " - Total Issues: ${total_issues}"
echo " - Can Merge: ${can_merge}"
echo ""
# 根据阈值决定是否阻止合并
case "${REVIEW_THRESHOLD}" in
low)
if [[ "${critical_count}" -gt 0 || "${high_count}" -gt 0 ]]; then
log_error "Review failed: blocking merge due to critical/high issues"
exit 1
fi
;;
medium)
if [[ "${critical_count}" -gt 0 ]]; then
log_error "Review failed: blocking merge due to critical issues"
exit 1
fi
;;
high)
if [[ "${critical_count}" -gt 5 ]]; then
log_error "Review failed: too many critical issues"
exit 1
fi
;;
esac
# 输出报告
echo "${review_output}" | jq -r '.report' > code_review_report.md
# 可选:发布评论到 GitHub/GitLab
if [[ -n "${GITHUB_TOKEN}" ]]; then
log_info "Posting review comment to GitHub..."
# GitHub API 调用将在这里实现
fi
log_info "Code review completed successfully"
}
# 执行主函数
main "$@"
五、Anthropic 的警告与全球治理建议
5.1 Anthropic 的核心立场
Anthropic 在文章中明确表达了以下立场:
“我们相信,放慢或暂时暂停前沿 AI 开发对世界是有益的。这将为社会结构和对齐研究提供时间,以跟上技术发展的步伐。”
Anthropic 提出了三个关键建议:
- 全球协调暂停:建议主要 AI 实验室考虑暂停前沿 AI 开发
- 可验证的合规机制:建立一个能够验证竞争对手遵守协议的体系
- 安全评估升级:加强 AI 系统的安全评估和测试
5.2 递归自我改进的风险分析
递归自我改进(RSI)可能带来以下风险:
| 风险类型 | 描述 | 潜在后果 |
|---|---|---|
| 能力失控 | AI 系统快速超越人类理解能力 | 难以预测和控制的行为 |
| 目标漂移 | AI 优化目标可能偏离原始意图 | 价值对齐失效 |
| 资源集中 | 少数公司控制超级 AI | 市场垄断加剧 |
| 军备竞赛 | 各国争相开发前沿 AI | 安全标准下降 |
| 就业冲击 | AI 替代知识工作者 | 社会不稳定 |
5.3 Anthropic 的内部数据支撑
Anthropic 披露的数据证明了这一趋势的真实性:
Claude 代码优化加速对比(2025年5月 vs 2026年4月):
- Claude Opus 4: ~3倍加速
- Claude Mythos Preview: ~52倍加速
人类工程师平均需要 4-8 小时才能达到 4 倍加速,
而 Mythos Preview 可以在更短时间内完成。
六、展望与结论
6.1 AI 递归自我改进的未来路径
根据 Anthropic 的分析,AI 递归自我改进可能沿以下路径发展:
2024-2025: AI 辅助开发
├── AI 生成代码片段
├── AI 辅助代码审查
└── AI 优化部分模块
2025-2026: AI 主导开发
├── AI 编写大部分生产代码
├── AI 自主完成端到端任务
└── AI 优化整个系统架构
2026-2027: AI 辅助研究
├── AI 设计新的实验
├── AI 分析实验结果
└── AI 提出研究方向
2027-2028: AI 自主研究
├── AI 自主训练新模型
├── AI 优化模型架构
└── AI 实现递归自我改进
2028+: 完全递归自我改进
└── AI 系统完全自主进化
6.2 应对策略
面对这一趋势,个人开发者、企业和政策制定者都需要做好准备:
个人开发者:
- 学习与 AI 协作的技能
- 聚焦创造性工作和战略决策
- 持续学习和适应新技术
企业:
- 建立 AI 代码审查流程
- 制定 AI 使用政策
- 投资 AI 安全研究
政策制定者:
- 建立 AI 监管框架
- 推动国际合作
- 支持安全研究
6.3 结论
Anthropic 的这篇文章不仅仅是一篇技术报告,更是一份关于 AI 未来的严肃警告。它提醒我们:
- AI 发展速度远超预期:递归自我改进可能比大多数人准备的更快到来
- 数据不会说谎:80% 的代码由 AI 生成、8 倍的生产力提升、76% 的任务成功率
- 自我监管的勇气:一家商业公司公开呼吁行业暂停开发,这种勇气值得尊重
- 未雨绸缪的必要性:我们需要提前思考如何确保 AI 发展造福人类
正如 Jack Clark 在文章结尾所说:
“我们需要找到工具来验证和确认 AI 系统所做的是正确的,是与人类意图一致的,是与繁荣社会相符的。”
这是整个行业、整个社会需要共同面对的挑战。
参考资料
- Anthropic. (2026). When AI Builds Itself. https://www.anthropic.com/research/recursive-self-improvement
- Jack Clark & Marina Favaro. (2026). When AI Builds Itself. Anthropic Institute.
- Wall Street Journal. (2026). Anthropic Urges Global Pause in AI Development.
- VentureBeat. (2026). Anthropic says 80% of its new production code is now authored by Claude.
- METR. (2026). Long-Duration Task Benchmark Results.
- SWE-bench. (2026). Software Engineering Benchmark Dataset.