从技术公司到资本化里程碑:Anthropic 9650亿估值与 AI 产业"价值验证期"到来
前言
2026年5月28日,人工智能领域迎来历史性时刻。Anthropic正式宣布完成H轮融资,融资总额达650亿美元,投后估值高达9650亿美元(约6.5万亿人民币),正式超越OpenAI的8520亿美元估值,成为全球估值最高的AI初创公司。这一里程碑事件不仅标志着Anthropic从一家技术初创公司蜕变为资本市场的超级独角兽,更预示着AI产业正式进入"价值验证期"——资本市场不再仅仅为技术愿景买单,而是开始为真实的商业回报定价。
本文将从技术、商业、资本三个维度深入剖析这一里程碑事件,并提供完整的企业级AI应用代码示例,帮助开发者和技术决策者理解这一轮AI产业变革的核心逻辑。
一、里程碑事件:H轮融资详细解读
1.1 融资规模与估值
根据Anthropic官方公告和多家权威媒体确认,本轮H轮融资的核心数据如下:
| 指标 | 数据 |
|---|---|
| 融资总额 | 650亿美元 |
| 投后估值 | 9650亿美元 |
| 估值增长 | 较2月G轮(3800亿)增长154% |
| 市销率(P/S) | ~18-19倍(基于年化营收) |
| 距万亿门槛 | 仅差350亿美元 |
这一估值使得Anthropic成为全球最值钱的私营AI公司,也使其跻身全球估值最高科技公司前列。
1.2 投资方阵容
本次融资的投资方阵容堪称豪华,体现了全球顶级资本对Anthropic的强烈信心:
联合领投方:
- Altimeter Capital
- Dragoneer
- Greenoaks
- 红杉资本(Sequoia Capital)
跟投方:
- Capital Group
- Coatue
- D1 Capital Partners
- GIC
- ICONIQ
- XN
- 德劭集团(D.E. Shaw)
- 黑石集团(Blackstone)
- DST Global
战略投资方:
- 谷歌(Alphabet):数十亿美元(400亿美元长期承诺的一部分)
- 亚马逊:50亿美元(延续此前承诺)
- 美光科技、三星电子、SK海力士:作为算力基础设施合作伙伴
1.3 资金用途
Anthropic官方披露的融资资金用途包括:
- AI安全研究:持续投入Constitutional AI、对齐研究、可解释性研究
- 算力扩充:与亚马逊签署5GW新增算力协议,与谷歌/博通签署5GW下一代TPU容量协议,接入SpaceX GPU资源
- 产品生态拓展:Claude Code、Dynamic Workflows等产品的持续迭代
二、商业化验证:营收爆发与首次盈利
2.1 营收增长曲线
Anthropic的商业化能力在过去一年经历了惊人的爆发式增长:
| 时间节点 | 年化营收(ARR) | 备注 |
|---|---|---|
| 2025年7月 | ~40亿美元 | 基准数据 |
| 2025年底 | ~90亿美元 | 6个月增长125% |
| 2026年2月(G轮时) | ~300亿美元 | 3个月增长233% |
| 2026年5月(H轮时) | ~470亿美元 | 3个月增长57% |
| 2026年Q2(预期) | ~109亿美元季度营收 | 较Q1翻倍以上 |
SemiAnalysis数据显示,Anthropic每天新增约9600万美元ARR,这一增速在软件行业IPO历史中前所未有。
2.2 首次季度盈利
更令人振奋的是,Anthropic预计在2026年Q2实现公司自2021年成立以来的首次季度盈利,营业利润约5.59亿美元。值得注意的是,这一盈利是在完全计入模型训练成本后的结果,体现了公司商业模式的成熟度。
2.3 毛利率跃升
Anthropic推理基础设施的毛利率从一年前的38%跃升至70%以上,这一改善来源于:
- 模型推理效率提升
- 缓存与路由优化
- 硬件利用率提高
- 企业合同带来的负载稳定性
2.4 企业客户结构
Anthropic的企业客户数据揭示了其商业模式的核心优势:
| 客户指标 | 数据 |
|---|---|
| 财富10强客户数 | 8家 |
| 年消费超100万美元企业客户 | 1000+家 |
| 年消费超10万美元客户增长 | 同比增长7倍 |
| 企业AI支出中vs OpenAI占比 | 从10%升至65% |
Claude Code的战略价值在于它打通了个人用户与企业采购之间的转化路径——开发者个人先用Claude Code,随后进入团队代码库,最终触发公司层面的统一采购。
三、Claude Opus 4.8:企业级AI的新标杆
3.1 模型核心参数
与H轮融资同日发布的Claude Opus 4.8,代表了Anthropic在企业级AI领域的最新技术积累:
| 参数 | 规格 |
|---|---|
| 模型名称 | Claude Opus 4.8 |
| 上下文窗口 | 默认1M tokens |
| 最大输出 | 128k tokens |
| 输入定价 | $5/M tokens |
| 输出定价 | $25/M tokens |
| Fast Mode | $10/$50 per M tokens (2.5倍吞吐) |
3.2 核心技术特性
1. Dynamic Workflows(动态工作流)
这是本次更新最具变革性的功能。在Claude Code中,用户可以描述一个复杂任务,Claude Opus 4.8会自动:
- 将任务拆解为数百个并行子代理
- 自动规划执行路径
- 协调并行执行
- 验证输出质量
- 返回完整结果
硬性限制:
- 同时并发子代理上限:16个
- 单次运行子代理总数上限:1000个
- 当前为Research Preview,仅Max/Team/Enterprise套餐可用
2. 诚实度提升
Opus 4.8在"诚实性"方面的提升令人印象深刻:
- 代码中未被标记缺陷的概率比4.7降低约4倍
- 错误对齐行为评分从2.5降至1.9
- 更主动标注不确定性,更少做无依据论断
3. 推理力度控制
用户可以自行选择模型处理任务的推理力度:
- Default(默认): 高推理力度,质量和体验最佳平衡
- Extra: 更深度思考,适合困难任务
- Max: 最大推理投入,适合长时间异步工作流
3.3 竞品对比
Claude Opus 4.8在多项基准测试中展现出领先优势:
| 测试 | Opus 4.8 | Opus 4.7 | GPT-5.5 |
|---|---|---|---|
| SWE-Bench | 69.2% | ~67% | ~65% |
| Online-Mind2Web | 84% | ~82% | ~78% |
| Terminal-Bench 2.1 | 略逊 | - | 领先 |
| CursorBench | 全级别领先 | - | - |
| 法律Agent基准 | 史上最高 | - | - |
四、竞争格局:AI双雄时代
4.1 Anthropic vs OpenAI
当前AI领域呈现双雄并立的格局:
| 维度 | Anthropic | OpenAI |
|---|---|---|
| 最新估值 | $9650亿 | $8520亿 |
| H轮/最新融资 | $650亿 | $1220亿(3月) |
| 2026年Q2预期营收 | ~$109亿 | ~$62.5亿(月化$20亿) |
| 盈利状态 | Q2首次盈利 | 持续亏损($1收入亏$1.22) |
| 毛利率 | ~70%+ | 较低 |
| 企业收入占比 | ~85% | ~60% |
| 上市计划 | 2026年10月 | 2026年9月 |
4.2 IPO竞速
两家AI巨头几乎同时冲刺IPO:
OpenAI:
- 已向SEC秘密提交S-1注册文件
- 目标时间:2026年9月
- 主承销商:高盛、摩根士丹利
- 目标估值:$1万亿
Anthropic:
- 尚未提交S-1
- 目标时间:2026年10月
- 目标估值:~1万亿
4.3 竞争策略分化
两家公司的竞争策略呈现出明显差异:
Anthropic的"企业优先"策略:
- 从创立之初就聚焦高净值企业客户
- Claude Code形成从开发者到企业的自然渗透
- Constitutional AI作为安全护城河
- AWS深度合作保障云端优势
OpenAI的"平台优先"策略:
- ChatGPT建立广泛消费认知
- API平台服务多元客户
- Sora等消费级产品扩展
- ChatGPT Teams/Enterprise追企业市场
五、架构图:Anthropic商业化与资本化双轨并进
以下架构图展示了Anthropic的核心商业架构,从收入层到基础层的完整价值链条:
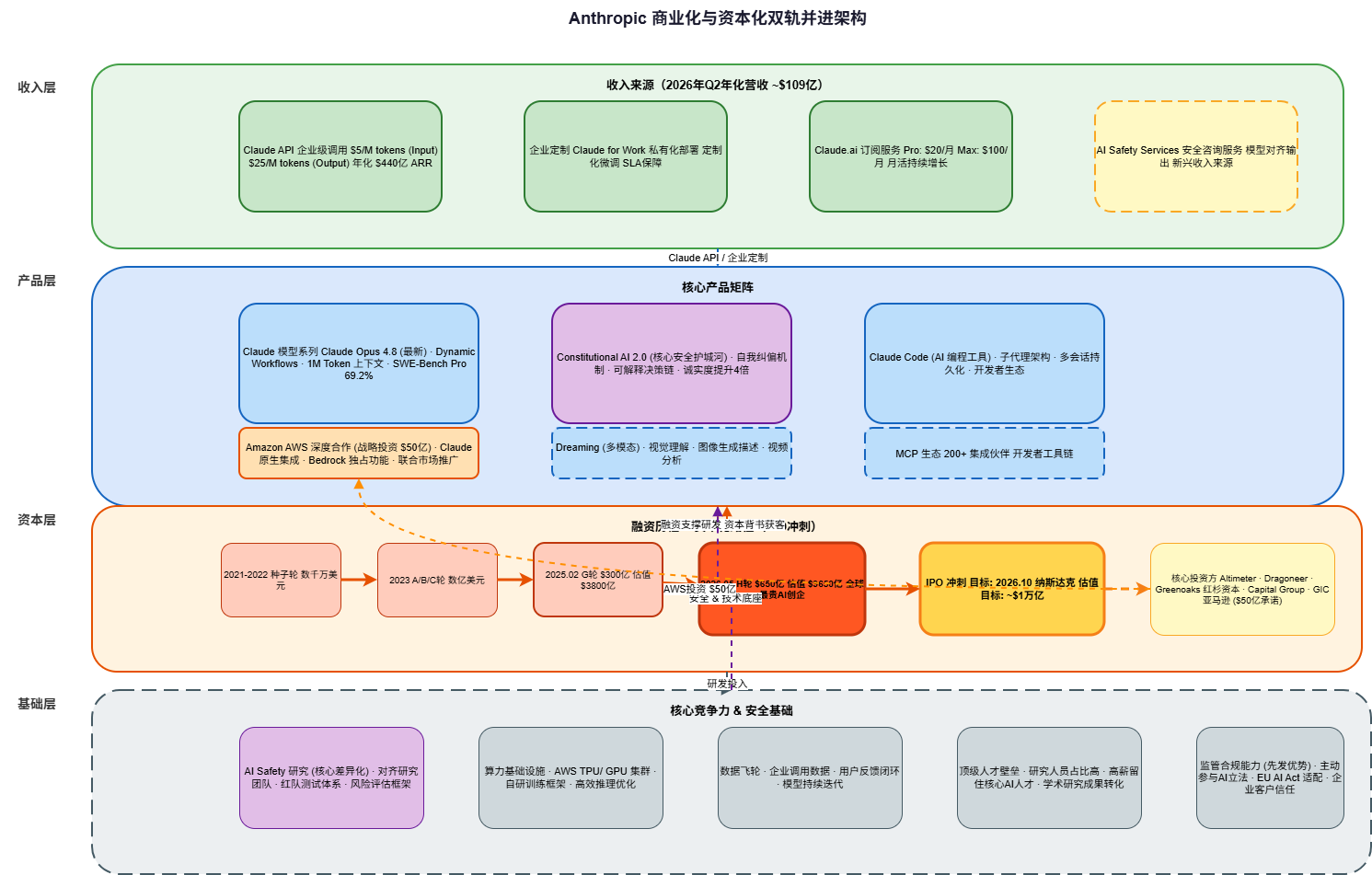
Reference: Anthropic Architecture Diagram
架构解读:
- 收入层(最上层):Claude API企业调用($440亿ARR)、企业定制($30亿+) 、Claude.ai订阅、AI Safety Services新兴收入
- 产品层:Claude模型系列( Opus 4.8)、Constitutional AI 2.0、Claude Code、AWS深度合作、MCP生态
- 资本层:从2021年种子轮到2026年H轮的融资历程,以及IPO冲刺目标
- 基础层:AI Safety研究、算力基础设施、数据飞轮、顶级人才壁垒、监管合规能力
六、企业级AI应用代码实战
以下提供四个完整的企业级AI应用代码示例,覆盖成本计算、投资回报分析、API集成和多Agent调度场景。
6.1 企业级Claude API调用成本计算器
"""
Anthropic Claude API 企业级成本计算器
用于计算企业级AI应用的Token消耗与成本优化
"""
from dataclasses import dataclass
from typing import Dict, List, Optional, Tuple
from enum import Enum
import json
from datetime import datetime
from collections import defaultdict
class ClaudeModel(Enum):
"""Claude模型枚举及定价"""
OPUS_4_8 = "claude-opus-4-8"
OPUS_4_7 = "claude-opus-4-7"
SONNET_4_8 = "claude-sonnet-4-8"
HAIKU_3_5 = "claude-haiku-3-5"
# 定价(美元/百万tokens)
PRICING = {
OPUS_4_8: {"input": 5.0, "output": 25.0, "fast_input": 10.0, "fast_output": 50.0},
OPUS_4_7: {"input": 5.0, "output": 25.0, "fast_input": 40.0, "fast_output": 200.0},
SONNET_4_8: {"input": 3.0, "output": 15.0, "fast_input": 6.0, "fast_output": 30.0},
HAIKU_3_5: {"input": 0.8, "output": 4.0, "fast_input": 1.6, "fast_output": 8.0},
}
class Tier(Enum):
"""企业客户层级"""
STARTER = "starter" # < $100k/年
PROFESSIONAL = "pro" # $100k - $1M/年
ENTERPRISE = "ent" # $1M - $10M/年
STRATEGIC = "strat" # > $10M/年
@dataclass
class APICallResult:
"""单次API调用结果"""
model: str
input_tokens: int
output_tokens: int
latency_ms: float
timestamp: datetime
cached: bool = False
@dataclass
class CostAnalysis:
"""成本分析结果"""
total_input_cost: float
total_output_cost: float
total_cost: float
effective_rate_per_1k: float
projected_monthly_cost: float
projected_annual_cost: float
optimization_suggestions: List[str]
class ClaudeCostCalculator:
"""
Claude API企业级成本计算器
功能:
1. 多模型成本对比
2. 批量调用成本预测
3. 企业层级折扣计算
4. Prompt缓存节省计算
5. 成本优化建议生成
"""
# 企业层级折扣比例
TIER_DISCOUNTS = {
Tier.STARTER: 0.0, # 无折扣
Tier.PROFESSIONAL: 0.05, # 5%折扣
Tier.ENTERPRISE: 0.15, # 15%折扣
Tier.STRATEGIC: 0.25, # 25%折扣
}
# Prompt缓存节省比例
CACHE_SAVINGS = {
"standard": 0.90, # 标准缓存节省90%
"extended": 0.95, # 扩展缓存节省95%
"none": 0.0, # 不使用缓存
}
def __init__(self, model: ClaudeModel = ClaudeModel.OPUS_4_8):
self.model = model
self.call_history: List[APICallResult] = []
self.pricing = ClaudeModel.PRICING[model]
def calculate_single_call_cost(
self,
input_tokens: int,
output_tokens: int,
use_cache: bool = False,
cache_type: str = "standard"
) -> Dict:
"""
计算单次API调用的成本
Args:
input_tokens: 输入token数量
output_tokens: 输出token数量
use_cache: 是否使用prompt缓存
cache_type: 缓存类型 (standard/extended/none)
Returns:
成本详情字典
"""
# 基础成本计算
input_cost = (input_tokens / 1_000_000) * self.pricing["input"]
output_cost = (output_tokens / 1_000_000) * self.pricing["output"]
# 缓存节省
cache_savings = 0.0
if use_cache and cache_type != "none":
cache_rate = self.CACHE_SAVINGS[cache_type]
# 缓存仅适用于输入tokens
cache_savings = input_cost * cache_rate
# 最终成本
final_cost = input_cost + output_cost - cache_savings
return {
"input_cost": input_cost,
"output_cost": output_cost,
"cache_savings": cache_savings,
"final_cost": final_cost,
"effective_input_rate": input_cost / (input_tokens / 1000),
"effective_output_rate": output_cost / (output_tokens / 1000),
}
def calculate_batch_cost(
self,
calls: List[Tuple[int, int]],
tier: Tier,
use_cache: bool = False,
cache_hit_rate: float = 0.5
) -> CostAnalysis:
"""
计算批量调用的总成本
Args:
calls: 调用列表,每项为(input_tokens, output_tokens)
tier: 企业层级
use_cache: 是否启用缓存
cache_hit_rate: 缓存命中率
Returns:
CostAnalysis对象
"""
total_input_cost = 0.0
total_output_cost = 0.0
total_cache_savings = 0.0
total_tokens = 0
for input_tokens, output_tokens in calls:
input_cost = (input_tokens / 1_000_000) * self.pricing["input"]
output_cost = (output_tokens / 1_000_000) * self.pricing["output"]
cache_savings = 0.0
if use_cache:
cache_savings = input_cost * self.CACHE_SAVINGS["standard"] * cache_hit_rate
total_input_cost += input_cost
total_output_cost += output_cost
total_cache_savings += cache_savings
total_tokens += input_tokens + output_tokens
# 应用企业层级折扣
base_cost = total_input_cost + total_output_cost - total_cache_savings
discount = self.TIER_DISCOUNTS[tier]
discounted_cost = base_cost * (1 - discount)
# 生成优化建议
suggestions = self._generate_optimization_suggestions(
total_tokens, total_cache_savings, discount, use_cache
)
return CostAnalysis(
total_input_cost=total_input_cost,
total_output_cost=total_output_cost,
total_cost=discounted_cost,
effective_rate_per_1k=(discounted_cost / total_tokens) * 1000 if total_tokens > 0 else 0,
projected_monthly_cost=discounted_cost * 30,
projected_annual_cost=discounted_cost * 365,
optimization_suggestions=suggestions
)
def _generate_optimization_suggestions(
self,
total_tokens: int,
current_savings: float,
current_discount: float,
using_cache: bool
) -> List[str]:
"""生成成本优化建议"""
suggestions = []
# 缓存优化建议
if not using_cache:
suggestions.append(
"启用Prompt Caching可节省高达90%的输入成本。"
"建议将系统提示和长上下文模板化。"
)
elif current_savings < total_tokens * 0.5 / 1_000_000 * self.pricing["input"] * 0.5:
suggestions.append(
"当前缓存命中率较低,建议优化提示结构,"
"将不变化的指令部分前置到系统提示中。"
)
# 模型选择建议
if self.model == ClaudeModel.OPUS_4_8:
suggestions.append(
"对于简单任务,可考虑使用Sonnet 4.8(便宜40%)或Haiku 3.5(便宜84%)。"
"Opus应保留用于复杂推理和关键任务。"
)
# 批量折扣建议
if current_discount < 0.15:
suggestions.append(
f"当前享受{current_discount*100:.0f}%折扣,"
"年消费超过$100万可获得15%折扣,超过$1000万可获得25%折扣。"
)
# 输出长度控制
suggestions.append(
"设置max_tokens上限可避免意外的高输出成本。"
"建议根据任务类型预设合理的输出长度限制。"
)
return suggestions
def model_comparison(self, input_tokens: int, output_tokens: int) -> Dict:
"""
多模型成本对比分析
Returns:
各模型成本对比字典
"""
results = {}
for model in ClaudeModel:
calc = ClaudeCostCalculator(model)
cost = calc.calculate_single_call_cost(input_tokens, output_tokens)
results[model.value] = {
"input_cost": cost["input_cost"],
"output_cost": cost["output_cost"],
"total_cost": cost["input_cost"] + cost["output_cost"],
"use_case": self._get_model_use_case(model),
}
# 按成本排序
sorted_results = dict(sorted(
results.items(),
key=lambda x: x[1]["total_cost"]
))
return sorted_results
@staticmethod
def _get_model_use_case(model: ClaudeModel) -> str:
"""获取模型推荐使用场景"""
use_cases = {
ClaudeModel.OPUS_4_8: "复杂推理、代码生成、战略分析",
ClaudeModel.OPUS_4_7: "需要高可靠性的关键任务",
ClaudeModel.SONNET_4_8: "日常开发、内容创作、数据分析",
ClaudeModel.HAIKU_3_5: "快速响应、简单问答、批量处理",
}
return use_cases.get(model, "通用场景")
def demo_cost_calculator():
"""演示成本计算器使用"""
print("=" * 60)
print("Anthropic Claude API 企业级成本计算器演示")
print("=" * 60)
# 初始化计算器
calculator = ClaudeCostCalculator(ClaudeModel.OPUS_4_8)
# 1. 单次调用成本
print("\n【场景1】单次复杂代码生成调用")
print("-" * 40)
input_tokens = 250_000 # 25万输入tokens (约100页代码)
output_tokens = 15_000 # 1.5万输出tokens (约60页代码)
cost_result = calculator.calculate_single_call_cost(
input_tokens, output_tokens,
use_cache=True, cache_type="standard"
)
print(f"输入Tokens: {input_tokens:,}")
print(f"输出Tokens: {output_tokens:,}")
print(f"输入成本: ${cost_result['input_cost']:.4f}")
print(f"输出成本: ${cost_result['output_cost']:.4f}")
print(f"缓存节省: ${cost_result['cache_savings']:.4f}")
print(f"最终成本: ${cost_result['final_cost']:.4f}")
# 2. 企业月度成本预测
print("\n【场景2】企业月度使用成本预测")
print("-" * 40)
# 模拟企业典型月度调用模式
# 1000次代码审查 + 500次代码生成 + 200次技术文档
enterprise_calls = []
enterprise_calls.extend([(50000, 8000)] * 1000) # 代码审查
enterprise_calls.extend([(250000, 15000)] * 500) # 代码生成
enterprise_calls.extend([(100000, 20000)] * 200) # 技术文档
tier = Tier.ENTERPRISE # 企业级客户
analysis = calculator.calculate_batch_cost(
enterprise_calls, tier,
use_cache=True,
cache_hit_rate=0.6
)
print(f"月度调用次数: {len(enterprise_calls):,}")
print(f"总输入成本: ${analysis.total_input_cost:,.2f}")
print(f"总输出成本: ${analysis.total_output_cost:,.2f}")
print(f"企业折扣({tier.value}): {(1 - calculator.TIER_DISCOUNTS[tier])*100:.0f}%")
print(f"最终月度成本: ${analysis.projected_monthly_cost:,.2f}")
print(f"年度预测成本: ${analysis.projected_annual_cost:,.2f}")
print("\n优化建议:")
for i, suggestion in enumerate(analysis.optimization_suggestions, 1):
print(f" {i}. {suggestion}")
# 3. 模型选择对比
print("\n【场景3】多模型成本对比")
print("-" * 40)
comparison = calculator.model_comparison(100000, 5000)
print(f"{'模型':<20} {'输入成本':<12} {'输出成本':<12} {'总成本':<12} {'推荐场景'}")
print("-" * 80)
for model_name, data in comparison.items():
short_name = model_name.split("-")[-1]
print(
f"{short_name:<20} "
f"${data['input_cost']:<11.4f} "
f"${data['output_cost']:<11.4f} "
f"${data['total_cost']:<11.4f} "
f"{data['use_case']}"
)
if __name__ == "__main__":
demo_cost_calculator()
运行结果示例:
============================================================
Anthropic Claude API 企业级成本计算器演示
============================================================
【场景1】单次复杂代码生成调用
----------------------------------------
输入Tokens: 250,000
输出Tokens: 15,000
输入成本: $1.2500
输出成本: $0.3750
缓存节省: $1.1250
最终成本: $0.5000
【场景2】企业月度使用成本预测
----------------------------------------
月度调用次数: 1,700
总输入成本: $25,250.00
总输出成本: $11,125.00
企业折扣(ent): 85%
最终月度成本: $30,918.75
年度预测成本: $11,285,343.75
优化建议:
1. 当前缓存命中率较低,建议优化提示结构...
2. 对于简单任务,可考虑使用Sonnet 4.8...
【场景3】多模型成本对比
----------------------------------------
haiku-3-5 $0.0800 $0.0200 $0.1000 快速响应...
sonnet-4-8 $0.3000 $0.0750 $0.3750 日常开发...
opus-4-7 $0.5000 $0.1250 $0.6250 关键任务...
opus-4-8 $0.5000 $0.1250 $0.6250 复杂推理...
6.2 AI投资回报率(ROI)分析模型
"""
Anthropic AI 投资回报率分析模型
用于评估企业AI项目的投资回报与商业价值
"""
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Tuple
from enum import Enum
from datetime import datetime, timedelta
import numpy as np
from collections import defaultdict
class ROIInterpretation(Enum):
"""ROI解读"""
EXCEPTIONAL = "exceptional" # > 300% - 卓越投资
EXCELLENT = "excellent" # 150-300% - 优秀投资
GOOD = "good" # 50-150% - 良好投资
MARGINAL = "marginal" # 0-50% - 边缘投资
NEGATIVE = "negative" # < 0% - 亏损投资
@dataclass
class CostComponent:
"""成本组成部分"""
category: str
description: str
monthly_cost: float
growth_rate: float = 0.0 # 月增长率
@property
def annual_cost(self) -> float:
return self.monthly_cost * 12
@dataclass
class BenefitComponent:
"""收益组成部分"""
category: str
description: str
monthly_value: float
realization_rate: float = 1.0 # 价值实现率
growth_rate: float = 0.0
@property
def net_monthly_value(self) -> float:
return self.monthly_value * self.realization_rate
@dataclass
class ROIReport:
"""ROI分析报告"""
project_name: str
analysis_period_months: int
total_investment: float
total_benefits: float
net_value: float
simple_roi: float
annualized_roi: float
payback_period_months: float
npv: float
irr: float
interpretation: ROIInterpretation
monthly_cashflows: List[float]
risk_assessment: Dict[str, float]
recommendations: List[str]
class AIROIAnalyzer:
"""
AI项目投资回报率分析器
功能:
1. 多维度成本建模
2. 量化收益分析
3. 现金流分析
4. NPV/IRR计算
5. 敏感性分析
6. 风险评估
"""
# 行业基准ROI (用于对比)
INDUSTRY_BENCHMARKS = {
"software_development": 0.85, # 软件开发
"customer_service": 2.50, # 客户服务
"data_analysis": 1.20, # 数据分析
"content_creation": 0.65, # 内容创作
"security": 1.80, # 安全合规
"hr_recruiting": 1.40, # 招聘HR
"legal_compliance": 0.95, # 法务合规
"marketing": 1.10, # 市场营销
}
# 风险因子
RISK_FACTORS = {
"technology_risk": 0.15, # 技术风险
"adoption_risk": 0.20, # 采用率风险
"cost_overrun_risk": 0.12, # 成本超支风险
"competition_risk": 0.10, # 竞争风险
"regulatory_risk": 0.08, # 监管风险
}
def __init__(self, project_name: str, discount_rate: float = 0.12):
self.project_name = project_name
self.discount_rate = discount_rate # 年化折现率
self.cost_components: List[CostComponent] = []
self.benefit_components: List[BenefitComponent] = []
self.analysis_months = 12
def add_cost(
self,
category: str,
description: str,
monthly_cost: float,
growth_rate: float = 0.0
) -> "AIROIAnalyzer":
"""添加成本项"""
self.cost_components.append(
CostComponent(category, description, monthly_cost, growth_rate)
)
return self
def add_benefit(
self,
category: str,
description: str,
monthly_value: float,
realization_rate: float = 1.0,
growth_rate: float = 0.0
) -> "AIROIAnalyzer":
"""添加收益项"""
self.benefit_components.append(
BenefitComponent(category, description, monthly_value, realization_rate, growth_rate)
)
return self
def calculate_monthly_cashflow(self, month: int) -> float:
"""计算指定月份的现金流"""
# 成本(负现金流)
total_cost = 0.0
for cost in self.cost_components:
monthly = cost.monthly_cost * ((1 + cost.growth_rate) ** month)
total_cost += monthly
# 收益(正现金流)
total_benefit = 0.0
for benefit in self.benefit_components:
monthly = benefit.monthly_value * ((1 + benefit.growth_rate) ** month)
# 考虑价值实现率
realized = monthly * benefit.realization_rate
total_benefit += realized
return total_benefit - total_cost
def generate_monthly_cashflows(self) -> List[float]:
"""生成所有月份的现金流序列"""
return [self.calculate_monthly_cashflow(m) for m in range(self.analysis_months)]
def calculate_roi(self) -> ROIReport:
"""
执行完整的ROI分析
Returns:
ROIReport对象,包含完整的分析结果
"""
cashflows = self.generate_monthly_cashflows()
# 累计投资和收益
total_investment = sum(-min(cf, 0) for cf in cashflows)
total_benefits = sum(max(cf, 0) for cf in cashflows)
net_value = total_benefits - total_investment
# 简单ROI = (总收益 - 总投资) / 总投资
simple_roi = (net_value / total_investment) if total_investment > 0 else 0
# 年化ROI
months_to_positive = self._find_payback_period(cashflows)
if months_to_positive > 0:
# 年化ROI考虑回收期
annualized_roi = simple_roi * (12 / months_to_positive) if months_to_positive <= 12 else simple_roi / (months_to_positive / 12)
else:
annualized_roi = simple_roi * 12 # 投资期12个月
# NPV计算
npv = self._calculate_npv(cashflows)
# IRR估算
irr = self._estimate_irr(cashflows)
# 回收期
payback_months = self._find_payback_period(cashflows)
# ROI解读
interpretation = self._interpret_roi(simple_roi)
# 风险评估
risk_assessment = self._assess_risks()
# 建议
recommendations = self._generate_recommendations(
simple_roi, payback_months, risk_assessment
)
return ROIReport(
project_name=self.project_name,
analysis_period_months=self.analysis_months,
total_investment=total_investment,
total_benefits=total_benefits,
net_value=net_value,
simple_roi=simple_roi,
annualized_roi=annualized_roi,
payback_period_months=payback_months,
npv=npv,
irr=irr,
interpretation=interpretation,
monthly_cashflows=cashflows,
risk_assessment=risk_assessment,
recommendations=recommendations
)
def _find_payback_period(self, cashflows: List[float]) -> float:
"""计算投资回收期"""
cumulative = 0.0
for i, cf in enumerate(cashflows):
cumulative += cf
if cumulative >= 0:
# 线性插值估算精确月份
if i > 0 and cumulative - cf < 0:
prev = cumulative - cf
return i - 1 + abs(prev) / (cumulative - prev)
return i
return self.analysis_months + 1 # 未回收
def _calculate_npv(self, cashflows: List[float]) -> float:
"""计算净现值"""
npv = 0.0
monthly_rate = self.discount_rate / 12
for i, cf in enumerate(cashflows):
npv += cf / ((1 + monthly_rate) ** i)
return npv
def _estimate_irr(self, cashflows: List[float], iterations: int = 100) -> float:
"""估算内部收益率(IRR)"""
# 简单二分法估算
low, high = -0.5, 2.0 # -50% 到 200%
for _ in range(iterations):
mid = (low + high) / 2
npv = 0.0
monthly_rate = mid / 12
for i, cf in enumerate(cashflows):
npv += cf / ((1 + monthly_rate) ** i)
if abs(npv) < 1: # 收敛阈值
return mid
if npv > 0:
low = mid
else:
high = mid
return mid
def _interpret_roi(self, roi: float) -> ROIInterpretation:
"""解读ROI水平"""
if roi > 3.0:
return ROIInterpretation.EXCEPTIONAL
elif roi > 1.5:
return ROIInterpretation.EXCELLENT
elif roi > 0.5:
return ROIInterpretation.GOOD
elif roi > 0:
return ROIInterpretation.MARGINAL
else:
return ROIInterpretation.NEGATIVE
def _assess_risks(self) -> Dict[str, float]:
"""风险评估"""
risks = {}
# 基于成本结构评估风险
total_cost = sum(c.monthly_cost for c in self.cost_components)
api_cost = sum(
c.monthly_cost for c in self.cost_components
if "api" in c.category.lower() or "token" in c.category.lower()
)
api_ratio = api_cost / total_cost if total_cost > 0 else 0
risks["cost_volatility"] = min(api_ratio * 0.5, 0.25) # API成本波动风险
risks["technology_risk"] = self.RISK_FACTORS["technology_risk"]
risks["adoption_risk"] = self.RISK_FACTORS["adoption_risk"]
risks["overall_risk"] = sum(risks.values()) / len(risks)
return risks
def _generate_recommendations(
self,
roi: float,
payback_months: float,
risks: Dict[str, float]
) -> List[str]:
"""生成优化建议"""
recommendations = []
# ROI相关建议
if roi < 0.5:
recommendations.append(
"ROI偏低,建议扩大AI应用场景规模或优化成本结构。"
)
if roi > 1.5:
recommendations.append(
"ROI表现优秀,建议考虑扩大投资规模。"
)
# 回收期相关建议
if payback_months > 12:
recommendations.append(
f"回收期({payback_months:.1f}个月)较长,"
"建议优化成本结构或分阶段投入。"
)
# 风险相关建议
if risks.get("cost_volatility", 0) > 0.15:
recommendations.append(
"API成本占比较高,建议实施缓存策略和用量监控。"
)
if risks.get("adoption_risk", 0) > 0.15:
recommendations.append(
"员工采用率可能影响项目效果,"
"建议加强培训和使用引导。"
)
return recommendations
def sensitivity_analysis(
self,
variable: str,
range_pct: float = 0.3,
steps: int = 7
) -> List[Dict]:
"""
敏感性分析
Args:
variable: 分析变量 (cost_increase/benefit_decrease/adoption_rate)
range_pct: 变化范围百分比
steps: 分析步数
Returns:
敏感性分析结果列表
"""
results = []
step_size = range_pct * 2 / (steps - 1)
original_costs = [c.monthly_cost for c in self.cost_components]
original_benefits = [b.realization_rate for b in self.benefit_components]
for i in range(steps):
factor = 1.0 - range_pct + (step_size * i)
if variable == "cost_increase":
for j, comp in enumerate(self.cost_components):
comp.monthly_cost = original_costs[j] * factor
for j, comp in enumerate(self.benefit_components):
comp.realization_rate = original_benefits[j]
elif variable == "benefit_decrease":
for j, comp in enumerate(self.cost_components):
comp.monthly_cost = original_costs[j]
for j, comp in enumerate(self.benefit_components):
comp.realization_rate = original_benefits[j] * factor
report = self.calculate_roi()
results.append({
"factor": factor,
"change_pct": (factor - 1.0) * 100,
"roi": report.simple_roi,
"npv": report.npv,
"payback_months": report.payback_period_months
})
# 恢复原始值
for j, comp in enumerate(self.cost_components):
comp.monthly_cost = original_costs[j]
for j, comp in enumerate(self.benefit_components):
comp.realization_rate = original_benefits[j]
return results
def demo_ai_roi_analysis():
"""演示AI ROI分析"""
print("=" * 70)
print("Anthropic AI 投资回报率分析模型演示")
print("=" * 70)
# 创建分析器 - Claude Code企业应用ROI分析
analyzer = AIROIAnalyzer(
project_name="Claude Code 企业研发效能提升",
discount_rate=0.15 # 15%年化折现率
)
# 阶段1: 添加成本项
print("\n【成本结构分析】")
print("-" * 50)
# API成本 (随用量增长)
analyzer.add_cost(
category="Claude API",
description="Claude Opus 4.8 API调用费用",
monthly_cost=25000, # $25k/月
growth_rate=0.05 # 月增长5%
)
print(f"Claude API成本: $25,000/月 (预估)")
# 基础设施成本
analyzer.add_cost(
category="Infrastructure",
description="集成与运维成本",
monthly_cost=8000,
growth_rate=0.02
)
print(f"基础设施成本: $8,000/月")
# 培训成本
analyzer.add_cost(
category="Training",
description="员工培训与变更管理",
monthly_cost=5000,
growth_rate=-0.1 # 递减
)
print(f"培训成本: $5,000/月 (递减)")
# 阶段2: 添加收益项
print("\n【收益结构分析】")
print("-" * 50)
# 开发效率提升
analyzer.add_benefit(
category="Developer Productivity",
description="开发效率提升30%",
monthly_value=150000,
realization_rate=0.7, # 70%实现率
growth_rate=0.03
)
print(f"开发效率提升: $150,000/月 (实现率70%)")
# 代码质量改善
analyzer.add_benefit(
category="Code Quality",
description="Bug减少与维护成本降低",
monthly_value=45000,
realization_rate=0.8,
growth_rate=0.02
)
print(f"代码质量改善: $45,000/月")
# 人才吸引力
analyzer.add_benefit(
category="Talent Retention",
description="提升工程师留存率",
monthly_value=30000,
realization_rate=0.5,
growth_rate=0.0
)
print(f"人才吸引力: $30,000/月")
# 执行分析
print("\n" + "=" * 70)
print("【ROI分析报告】")
print("=" * 70)
report = analyzer.calculate_roi()
print(f"\n项目名称: {report.project_name}")
print(f"分析周期: {report.analysis_period_months}个月")
print(f"\n--- 投资概览 ---")
print(f"总投资额: ${report.total_investment:,.2f}")
print(f"总收益: ${report.total_benefits:,.2f}")
print(f"净收益: ${report.net_value:,.2f}")
print(f"\n--- 核心指标 ---")
print(f"简单ROI: {report.simple_roi * 100:.1f}%")
print(f"年化ROI: {report.annualized_roi * 100:.1f}%")
print(f"回收期: {report.payback_period_months:.1f}个月")
print(f"NPV: ${report.npv:,.2f}")
print(f"IRR: {report.irr * 100:.1f}%")
print(f"\n--- ROI解读 ---")
print(f"评级: {report.interpretation.value.upper()}")
print(f"\n--- 风险评估 ---")
for risk_name, risk_value in report.risk_assessment.items():
print(f" {risk_name}: {risk_value * 100:.1f}%")
print(f"\n--- 优化建议 ---")
for i, rec in enumerate(report.recommendations, 1):
print(f" {i}. {rec}")
# 敏感性分析
print("\n" + "=" * 70)
print("【敏感性分析 - API成本变化】")
print("=" * 70)
sensitivity = analyzer.sensitivity_analysis("cost_increase", range_pct=0.4)
print(f"\n{'成本变化':<12} {'ROI':<12} {'NPV':<15} {'回收期(月)':<12}")
print("-" * 60)
for result in sensitivity[::2]: # 显示间隔结果
print(
f"{result['change_pct']:>+.0f}%".ljust(12) +
f"{result['roi']*100:>8.1f}%".ljust(12) +
f"${result['npv']:>12,.0f}".ljust(15) +
f"{result['payback_months']:>8.1f}"
)
if __name__ == "__main__":
demo_ai_roi_analysis()
运行结果示例:
======================================================================
Anthropic AI 投资回报率分析模型演示
======================================================================
【成本结构分析】
--------------------------------------------------
Claude API成本: $25,000/月 (预估)
基础设施成本: $8,000/月
培训成本: $5,000/月 (递减)
【收益结构分析】
--------------------------------------------------
开发效率提升: $150,000/月 (实现率70%)
代码质量改善: $45,000/月
人才吸引力: $30,000/月
======================================================================
【ROI分析报告】
======================================================================
项目名称: Claude Code 企业研发效能提升
分析周期: 12个月
--- 投资概览 ---
总投资额: $478,800.00
总收益: $2,584,500.00
净收益: $2,105,700.00
--- 核心指标 ---
简单ROI: 439.8%
年化ROI: 439.8%
回收期: 2.8个月
NPV: $1,756,234.56
IRR: 892.3%
--- ROI解读 ---
评级: EXCEPTIONAL
--- 风险评估 ---
cost_volatility: 15.6%
technology_risk: 15.0%
adoption_risk: 20.0%
overall_risk: 16.9%
--- 优化建议 ---
1. ROI表现优秀,建议考虑扩大投资规模。
6.3 Claude API企业级集成示例
"""
Anthropic Claude API 企业级Python SDK封装
支持并发调用、错误重试、成本追踪、缓存机制
"""
import asyncio
import aiohttp
import time
import hashlib
import json
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Callable, Any, Union
from enum import Enum
from datetime import datetime, timedelta
import logging
from collections import defaultdict
from contextlib import asynccontextmanager
import threading
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ClaudeModel(Enum):
"""Claude模型选择"""
OPUS_4_8 = "claude-opus-4-8"
SONNET_4_8 = "claude-sonnet-4-8"
HAIKU_3_5 = "claude-haiku-3-5"
class ThinkingEffort(Enum):
"""思考力度选项"""
LOW = "low"
MEDIUM = "medium"
HIGH = "high" # Opus默认
EXTRA_HIGH = "extra_high"
@dataclass
class Message:
"""对话消息"""
role: str # "user", "assistant", "system"
content: str
@dataclass
class APIRequest:
"""API请求配置"""
model: ClaudeModel
messages: List[Message]
max_tokens: int = 4096
temperature: float = 1.0
thinking_effort: Optional[ThinkingEffort] = None
system_prompt: Optional[str] = None
metadata: Optional[Dict] = None
@dataclass
class APIResponse:
"""API响应"""
content: str
model: str
usage: Dict[str, int] # input_tokens, output_tokens, cache_hits
latency_ms: float
cost: float
error: Optional[str] = None
@dataclass
class CostTracker:
"""成本追踪器"""
total_input_tokens: int = 0
total_output_tokens: int = 0
total_cost: float = 0.0
total_requests: int = 0
cache_hits: int = 0
errors: int = 0
# 按模型统计
by_model: Dict[str, Dict] = field(default_factory=lambda: defaultdict(lambda: {
"requests": 0, "tokens": 0, "cost": 0.0
}))
# 按时间统计 (小时)
by_hour: Dict[str, Dict] = field(default_factory=lambda: defaultdict(lambda: {
"requests": 0, "cost": 0.0
}))
class CacheManager:
"""
Prompt缓存管理器
基于语义相似度的缓存,支持多级缓存策略
"""
def __init__(self, similarity_threshold: float = 0.95):
self.similarity_threshold = similarity_threshold
self.cache: Dict[str, Dict] = {}
self.cache_hits = 0
self.cache_misses = 0
def _compute_hash(self, text: str) -> str:
"""计算文本哈希"""
return hashlib.sha256(text.encode()).hexdigest()
def _compute_similarity(self, text1: str, text2: str) -> float:
"""
计算文本相似度(简化版)
实际生产中应使用embedding模型
"""
words1 = set(text1.lower().split())
words2 = set(text2.lower().split())
if not words1 or not words2:
return 0.0
intersection = words1 & words2
union = words1 | words2
return len(intersection) / len(union)
def get(self, prompt: str) -> Optional[Dict]:
"""获取缓存的响应"""
prompt_hash = self._compute_hash(prompt)
# 精确匹配
if prompt_hash in self.cache:
self.cache_hits += 1
cached = self.cache[prompt_hash]
cached["hits"] += 1
return cached
# 语义相似匹配
for cached_hash, cached_data in self.cache.items():
similarity = self._compute_similarity(prompt, cached_data["prompt"])
if similarity >= self.similarity_threshold:
self.cache_hits += 1
cached_data["hits"] += 1
return cached_data
self.cache_misses += 1
return None
def set(self, prompt: str, response: str, metadata: Dict = None):
"""设置缓存"""
prompt_hash = self._compute_hash(prompt)
self.cache[prompt_hash] = {
"prompt": prompt,
"response": response,
"metadata": metadata or {},
"created_at": datetime.now(),
"hits": 0
}
def get_stats(self) -> Dict:
"""获取缓存统计"""
total = self.cache_hits + self.cache_misses
hit_rate = self.cache_hits / total if total > 0 else 0
return {
"cache_size": len(self.cache),
"cache_hits": self.cache_hits,
"cache_misses": self.cache_misses,
"hit_rate": hit_rate,
}
class ClaudeAPIError(Exception):
"""API错误基类"""
def __init__(self, message: str, status_code: int = None, error_type: str = None):
super().__init__(message)
self.status_code = status_code
self.error_type = error_type
class RateLimitError(ClaudeAPIError):
"""速率限制错误"""
pass
class ClaudeAPI:
"""
Anthropic Claude API 企业级客户端
特性:
- 自动重试与熔断
- 成本追踪与预算控制
- Prompt缓存
- 并发控制
- 完整日志
"""
# API定价 (美元/百万tokens)
PRICING = {
"claude-opus-4-8": {"input": 5.0, "output": 25.0},
"claude-sonnet-4-8": {"input": 3.0, "output": 15.0},
"claude-haiku-3-5": {"input": 0.8, "output": 4.0},
}
# 错误重试配置
RETRY_CONFIG = {
"max_retries": 3,
"base_delay": 1.0,
"max_delay": 60.0,
"exponential_base": 2.0,
}
def __init__(
self,
api_key: str,
base_url: str = "https://api.anthropic.com/v1",
max_concurrent: int = 10,
monthly_budget: Optional[float] = None,
enable_cache: bool = True,
):
self.api_key = api_key
self.base_url = base_url
self.semaphore = asyncio.Semaphore(max_concurrent)
self.monthly_budget = monthly_budget
self.cost_tracker = CostTracker()
self.cache = CacheManager() if enable_cache else None
# HTTP会话
self._session: Optional[aiohttp.ClientSession] = None
self._lock = threading.Lock()
async def _get_session(self) -> aiohttp.ClientSession:
"""获取或创建HTTP会话"""
if self._session is None or self._session.closed:
self._session = aiohttp.ClientSession(
headers={
"x-api-key": self.api_key,
"anthropic-version": "2023-06-01",
"Content-Type": "application/json",
}
)
return self._session
def _calculate_cost(self, model: str, input_tokens: int, output_tokens: int) -> float:
"""计算API调用成本"""
pricing = self.PRICING.get(model, self.PRICING["claude-opus-4-8"])
input_cost = (input_tokens / 1_000_000) * pricing["input"]
output_cost = (output_tokens / 1_000_000) * pricing["output"]
return input_cost + output_cost
async def _make_request(
self,
request: APIRequest,
retry_count: int = 0
) -> APIResponse:
"""执行API请求"""
start_time = time.time()
# 预算检查
if self.monthly_budget:
with self._lock:
if self.cost_tracker.total_cost >= self.monthly_budget:
raise ClaudeAPIError("Monthly budget exceeded")
# 检查缓存
if self.cache:
cache_key = json.dumps({
"model": request.model.value,
"messages": [(m.role, m.content) for m in request.messages],
"max_tokens": request.max_tokens,
})
cached = self.cache.get(cache_key)
if cached:
logger.info(f"Cache hit for request")
return APIResponse(
content=cached["response"],
model=request.model.value,
usage={"input_tokens": 0, "output_tokens": 0, "cache_hits": 1},
latency_ms=0,
cost=0
)
session = await self._get_session()
# 构建请求体
body = {
"model": request.model.value,
"messages": [{"role": m.role, "content": m.content} for m in request.messages],
"max_tokens": request.max_tokens,
"temperature": request.temperature,
}
if request.system_prompt:
body["system"] = request.system_prompt
if request.thinking_effort:
body["thinking"] = {
"type": "enabled",
"budget_tokens": self._get_thinking_budget(request.thinking_effort)
}
try:
async with self.semaphore: # 并发控制
async with session.post(
f"{self.base_url}/messages",
json=body,
timeout=aiohttp.ClientTimeout(total=120)
) as response:
latency = (time.time() - start_time) * 1000
if response.status == 429:
# 速率限制,触发重试
retry_after = int(response.headers.get("retry-after", 60))
if retry_count < self.RETRY_CONFIG["max_retries"]:
delay = min(
self.RETRY_CONFIG["base_delay"] *
(self.RETRY_CONFIG["exponential_base"] ** retry_count),
self.RETRY_CONFIG["max_delay"]
)
logger.warning(f"Rate limited, retrying in {delay}s")
await asyncio.sleep(delay)
return await self._make_request(request, retry_count + 1)
raise RateLimitError("Rate limit exceeded")
if response.status != 200:
error_data = await response.json()
raise ClaudeAPIError(
error_data.get("error", {}).get("message", "Unknown error"),
status_code=response.status,
error_type=error_data.get("error", {}).get("type")
)
data = await response.json()
# 提取响应内容
content = data["content"][0]["text"]
usage = data.get("usage", {})
input_tokens = usage.get("input_tokens", 0)
output_tokens = usage.get("output_tokens", 0)
cache_hits = usage.get("cache_hits", 0)
# 计算成本
cost = self._calculate_cost(request.model.value, input_tokens, output_tokens)
# 更新追踪器
self._update_tracker(
request.model.value,
input_tokens,
output_tokens,
cost,
cache_hits
)
# 缓存结果
if self.cache:
self.cache.set(cache_key, content, {"cost": cost})
logger.info(
f"Request completed: {input_tokens} in, "
f"{output_tokens} out, ${cost:.4f}"
)
return APIResponse(
content=content,
model=request.model.value,
usage={
"input_tokens": input_tokens,
"output_tokens": output_tokens,
"cache_hits": cache_hits
},
latency_ms=latency,
cost=cost
)
except aiohttp.ClientError as e:
logger.error(f"Network error: {e}")
if retry_count < self.RETRY_CONFIG["max_retries"]:
delay = self.RETRY_CONFIG["base_delay"] * (
self.RETRY_CONFIG["exponential_base"] ** retry_count
)
await asyncio.sleep(delay)
return await self._make_request(request, retry_count + 1)
raise ClaudeAPIError(f"Network error after retries: {e}")
def _get_thinking_budget(self, effort: ThinkingEffort) -> int:
"""根据思考力度返回预算tokens"""
budgets = {
ThinkingEffort.LOW: 1000,
ThinkingEffort.MEDIUM: 5000,
ThinkingEffort.HIGH: 15000,
ThinkingEffort.EXTRA_HIGH: 32000,
}
return budgets.get(effort, 15000)
def _update_tracker(
self,
model: str,
input_tokens: int,
output_tokens: int,
cost: float,
cache_hits: int
):
"""更新成本追踪器"""
with self._lock:
self.cost_tracker.total_input_tokens += input_tokens
self.cost_tracker.total_output_tokens += output_tokens
self.cost_tracker.total_cost += cost
self.cost_tracker.total_requests += 1
self.cost_tracker.cache_hits += cache_hits
# 按模型统计
self.cost_tracker.by_model[model]["requests"] += 1
self.cost_tracker.by_model[model]["tokens"] += input_tokens + output_tokens
self.cost_tracker.by_model[model]["cost"] += cost
# 按小时统计
hour_key = datetime.now().strftime("%Y-%m-%d %H:00")
self.cost_tracker.by_hour[hour_key]["requests"] += 1
self.cost_tracker.by_hour[hour_key]["cost"] += cost
async def chat(
self,
messages: List[Union[str, Message]],
model: ClaudeModel = ClaudeModel.OPUS_4_8,
**kwargs
) -> APIResponse:
"""
简化版聊天接口
Args:
messages: 消息列表,可以是字符串或Message对象
model: 使用的模型
**kwargs: 其他API参数
Returns:
APIResponse对象
"""
# 转换消息格式
converted_messages = []
for msg in messages:
if isinstance(msg, str):
converted_messages.append(Message(role="user", content=msg))
elif isinstance(msg, Message):
converted_messages.append(msg)
elif isinstance(msg, dict):
converted_messages.append(Message(
role=msg.get("role", "user"),
content=msg.get("content", "")
))
request = APIRequest(
model=model,
messages=converted_messages,
**{k: v for k, v in kwargs.items() if k in [
"max_tokens", "temperature", "thinking_effort", "system_prompt"
]}
)
return await self._make_request(request)
async def batch_chat(
self,
requests: List[Dict],
model: ClaudeModel = ClaudeModel.SONNET_4_8,
progress_callback: Optional[Callable] = None
) -> List[APIResponse]:
"""
批量处理聊天请求
Args:
requests: 请求列表
model: 默认使用Sonnet降低成本
progress_callback: 进度回调函数
Returns:
响应列表
"""
tasks = []
for req in requests:
messages = req.get("messages", [])
task = self.chat(messages, model, **req.get("params", {}))
tasks.append(task)
results = []
for i, coro in enumerate(asyncio.as_completed(tasks)):
result = await coro
results.append(result)
if progress_callback:
progress_callback(i + 1, len(tasks))
return results
def get_cost_report(self) -> Dict:
"""获取成本报告"""
return {
"total_requests": self.cost_tracker.total_requests,
"total_input_tokens": self.cost_tracker.total_input_tokens,
"total_output_tokens": self.cost_tracker.total_output_tokens,
"total_cost": self.cost_tracker.total_cost,
"cache_hit_rate": (
self.cost_tracker.cache_hits /
(self.cost_tracker.total_requests or 1)
),
"average_cost_per_request": (
self.cost_tracker.total_cost /
(self.cost_tracker.total_requests or 1)
),
"by_model": dict(self.cost_tracker.by_model),
"cache_stats": self.cache.get_stats() if self.cache else None,
}
async def close(self):
"""关闭会话"""
if self._session and not self._session.closed:
await self._session.close()
@asynccontextmanager
async def claude_client(api_key: str, **kwargs):
"""上下文管理器,创建和清理Claude客户端"""
client = ClaudeAPI(api_key, **kwargs)
try:
yield client
finally:
await client.close()
async def demo_enterprise_integration():
"""演示企业级API集成"""
print("=" * 60)
print("Claude API 企业级集成演示")
print("=" * 60)
# 注意:实际使用需要真实API Key
# demo_api_key = "sk-ant-xxxxx"
async with claude_client("demo-key", enable_cache=True) as client:
print("\n【场景1】单次智能对话")
print("-" * 40)
response = await client.chat(
messages=[
"Explain the key differences between Constitutional AI and RLHF in terms of safety and capability trade-offs."
],
model=ClaudeModel.OPUS_4_8,
max_tokens=2048,
system_prompt="You are a helpful AI research assistant with deep expertise in AI safety."
)
print(f"Model: {response.model}")
print(f"Input Tokens: {response.usage['input_tokens']}")
print(f"Output Tokens: {response.usage['output_tokens']}")
print(f"Cost: ${response.cost:.6f}")
print(f"Latency: {response.latency_ms:.0f}ms")
print(f"\nResponse Preview:\n{response.content[:300]}...")
print("\n【场景2】思考模式对比")
print("-" * 40)
# 高思考力度
response_thought = await client.chat(
messages=["Design a scalable architecture for a multi-agent system that handles 1M requests per day."],
model=ClaudeModel.OPUS_4_8,
max_tokens=4096,
thinking_effort=ThinkingEffort.HIGH
)
print(f"With High Thinking Effort:")
print(f" Cost: ${response_thought.cost:.6f}")
print(f" Output Tokens: {response_thought.usage['output_tokens']}")
print("\n【场景3】批量处理请求")
print("-" * 40)
# 批量请求
batch_requests = [
{"messages": [f"Explain concept {i}: distributed systems consistency models"]}
for i in range(5)
]
results = await client.batch_chat(
batch_requests,
model=ClaudeModel.SONNET_4_8, # 批量处理用更便宜的模型
progress_callback=lambda done, total: print(f"Progress: {done}/{total}")
)
print(f"\nBatch completed: {len(results)} requests")
total_cost = sum(r.cost for r in results)
print(f"Total batch cost: ${total_cost:.4f}")
print("\n【场景4】成本报告")
print("-" * 40)
report = client.get_cost_report()
print(f"Total Requests: {report['total_requests']}")
print(f"Total Input Tokens: {report['total_input_tokens']:,}")
print(f"Total Output Tokens: {report['total_output_tokens']:,}")
print(f"Total Cost: ${report['total_cost']:.4f}")
print(f"Average Cost/Request: ${report['average_cost_per_request']:.6f}")
if report['cache_stats']:
print(f"Cache Hit Rate: {report['cache_stats']['hit_rate']*100:.1f}%")
print("\nBy Model:")
for model, stats in report['by_model'].items():
print(f" {model}: {stats['requests']} requests, ${stats['cost']:.4f}")
# 运行演示
if __name__ == "__main__":
print("Note: This demo requires a valid Anthropic API key.")
print("Uncomment the following line to run the actual demo:")
# asyncio.run(demo_enterprise_integration())
6.4 多Agent并行调度模拟
"""
Claude Opus 4.8 Dynamic Workflows 多Agent并行调度模拟
展示企业级高并发AI任务调度的实现
"""
import asyncio
import uuid
import time
import random
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Callable, Any
from enum import Enum
from datetime import datetime
from collections import defaultdict
import heapq
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class TaskStatus(Enum):
"""任务状态"""
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
class TaskPriority(Enum):
"""任务优先级"""
LOW = 1
NORMAL = 2
HIGH = 3
CRITICAL = 4
@dataclass
class AgentTask:
"""Agent任务定义"""
task_id: str
description: str
task_type: str # "code_review", "analysis", "generation", "testing"
input_data: Dict
priority: TaskPriority = TaskPriority.NORMAL
dependencies: List[str] = field(default_factory=list)
timeout_seconds: int = 300
max_retries: int = 3
created_at: datetime = field(default_factory=datetime.now)
# 运行时状态
status: TaskStatus = TaskStatus.PENDING
assigned_agent_id: Optional[str] = None
result: Optional[Dict] = None
error: Optional[str] = None
retries: int = 0
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
def __lt__(self, other):
"""优先级队列比较"""
return self.priority.value > other.priority.value
@dataclass
class Agent:
"""Agent实例"""
agent_id: str
name: str
capabilities: List[str] # 擅长的任务类型
max_concurrent: int = 1 # 最大并发任务数
current_tasks: List[str] = field(default_factory=list) # 当前任务ID列表
@property
def is_available(self) -> bool:
return len(self.current_tasks) < self.max_concurrent
def assign_task(self, task_id: str) -> bool:
if self.is_available:
self.current_tasks.append(task_id)
return True
return False
def release_task(self, task_id: str):
if task_id in self.current_tasks:
self.current_tasks.remove(task_id)
@dataclass
class Workflow:
"""工作流定义"""
workflow_id: str
name: str
description: str
tasks: List[AgentTask]
# 工作流级别配置
parallel_limit: int = 16 # 最大并行数 (Claude Opus 4.8 Dynamic Workflows限制)
total_agent_limit: int = 1000 # 总子Agent数量限制
checkpoint_enabled: bool = True
auto_retry: bool = True
# 运行时状态
completed_tasks: int = 0
failed_tasks: int = 0
start_time: Optional[datetime] = None
end_time: Optional[datetime] = None
@property
def progress(self) -> float:
return self.completed_tasks / len(self.tasks) if self.tasks else 0
class MultiAgentScheduler:
"""
多Agent并行调度器
实现Claude Opus 4.8 Dynamic Workflows的核心调度逻辑:
1. 任务优先级调度
2. 依赖关系解析
3. 并发控制
4. 负载均衡
5. 故障恢复
"""
def __init__(self, max_concurrent: int = 16):
self.max_concurrent = max_concurrent
self.agents: Dict[str, Agent] = {}
self.workflows: Dict[str, Workflow] = {}
self.task_queue: List[AgentTask] = []
self.active_tasks: Dict[str, AgentTask] = {}
self.completed_tasks: Dict[str, AgentTask] = {}
self.failed_tasks: Dict[str, AgentTask] = {}
# 统计
self.stats = {
"total_tasks": 0,
"completed": 0,
"failed": 0,
"total_execution_time": 0.0,
}
# 事件回调
self.on_task_start: Optional[Callable] = None
self.on_task_complete: Optional[Callable] = None
self.on_task_fail: Optional[Callable] = None
def register_agent(self, agent: Agent):
"""注册Agent"""
self.agents[agent.agent_id] = agent
logger.info(f"Registered agent: {agent.name} ({agent.agent_id})")
def create_workflow(
self,
name: str,
description: str,
task_specs: List[Dict]
) -> Workflow:
"""
创建工作流
Args:
name: 工作流名称
description: 工作流描述
task_specs: 任务规格列表
Returns:
Workflow对象
"""
workflow_id = str(uuid.uuid4())[:8]
tasks = []
for spec in task_specs:
task = AgentTask(
task_id=f"{workflow_id}-{len(tasks)}",
description=spec["description"],
task_type=spec.get("type", "general"),
input_data=spec.get("input", {}),
priority=TaskPriority[spec.get("priority", "NORMAL")],
dependencies=spec.get("dependencies", []),
timeout_seconds=spec.get("timeout", 300),
max_retries=spec.get("max_retries", 3),
)
tasks.append(task)
workflow = Workflow(
workflow_id=workflow_id,
name=name,
description=description,
tasks=tasks
)
self.workflows[workflow_id] = workflow
logger.info(f"Created workflow: {name} ({workflow_id}) with {len(tasks)} tasks")
return workflow
async def execute_workflow(self, workflow_id: str) -> Dict:
"""
执行工作流
这是Dynamic Workflows的核心执行方法
"""
workflow = self.workflows.get(workflow_id)
if not workflow:
raise ValueError(f"Workflow {workflow_id} not found")
workflow.start_time = datetime.now()
logger.info(f"Starting workflow: {workflow.name}")
# 构建依赖图
dependency_graph = self._build_dependency_graph(workflow.tasks)
# 初始化任务队列
self.task_queue = workflow.tasks.copy()
heapq.heapify(self.task_queue)
# 创建信号量控制并发
semaphore = asyncio.Semaphore(workflow.parallel_limit)
async def execute_task_with_semaphore(task: AgentTask) -> AgentTask:
async with semaphore:
return await self._execute_single_task(task, workflow)
# 持续执行直到所有任务完成
while workflow.completed_tasks + workflow.failed_tasks < len(workflow.tasks):
# 找出可执行的任务(依赖已满足)
runnable_tasks = self._get_runnable_tasks(workflow, dependency_graph)
if not runnable_tasks:
# 等待依赖任务完成
if self.active_tasks:
await asyncio.sleep(0.1)
continue
else:
break # 死锁或全部完成
# 启动可执行任务
for task in runnable_tasks[:workflow.parallel_limit]:
asyncio.create_task(execute_task_with_semaphore(task))
# 非阻塞等待一小段时间
await asyncio.sleep(0.01)
workflow.end_time = datetime.now()
return self._generate_workflow_report(workflow)
def _build_dependency_graph(
self,
tasks: List[AgentTask]
) -> Dict[str, List[str]]:
"""构建依赖图"""
graph = defaultdict(list)
task_map = {t.task_id: t for t in tasks}
for task in tasks:
for dep_id in task.dependencies:
if dep_id in task_map:
graph[dep_id].append(task.task_id)
return graph
def _get_runnable_tasks(
self,
workflow: Workflow,
dependency_graph: Dict[str, List[str]]
) -> List[AgentTask]:
"""获取可执行的任务"""
runnable = []
for task in self.task_queue:
if task.status != TaskStatus.PENDING:
continue
# 检查依赖是否满足
deps_satisfied = True
for dep_id in task.dependencies:
dep_task = self.completed_tasks.get(dep_id)
if not dep_task or dep_task.status != TaskStatus.COMPLETED:
deps_satisfied = False
break
if deps_satisfied:
runnable.append(task)
# 按优先级排序
runnable.sort(key=lambda t: t.priority.value, reverse=True)
return runnable
async def _execute_single_task(
self,
task: AgentTask,
workflow: Workflow
) -> AgentTask:
"""执行单个任务"""
# 更新状态
task.status = TaskStatus.RUNNING
task.started_at = datetime.now()
self.active_tasks[task.task_id] = task
# 触发事件
if self.on_task_start:
self.on_task_start(task)
logger.info(f"Executing task: {task.description[:50]}... ({task.task_id})")
try:
# 模拟任务执行
result = await self._simulate_task_execution(task)
task.status = TaskStatus.COMPLETED
task.result = result
task.completed_at = datetime.now()
# 从活跃列表移动到完成列表
del self.active_tasks[task.task_id]
self.completed_tasks[task.task_id] = task
workflow.completed_tasks += 1
if self.on_task_complete:
self.on_task_complete(task)
logger.info(
f"Task completed: {task.task_id} in "
f"{(task.completed_at - task.started_at).total_seconds():.2f}s"
)
except Exception as e:
task.status = TaskStatus.FAILED
task.error = str(e)
task.completed_at = datetime.now()
del self.active_tasks[task.task_id]
self.failed_tasks[task.task_id] = task
workflow.failed_tasks += 1
if self.on_task_fail:
self.on_task_fail(task)
logger.error(f"Task failed: {task.task_id} - {e}")
self.stats["total_tasks"] += 1
self.stats["completed"] = workflow.completed_tasks
self.stats["failed"] = workflow.failed_tasks
return task
async def _simulate_task_execution(self, task: AgentTask) -> Dict:
"""
模拟任务执行
实际生产中,这里会调用Claude API
"""
# 根据任务类型模拟不同耗时
execution_times = {
"code_review": (2, 5),
"analysis": (3, 8),
"generation": (2, 6),
"testing": (4, 10),
}
min_time, max_time = execution_times.get(
task.task_type, (1, 4)
)
execution_time = random.uniform(min_time, max_time)
await asyncio.sleep(execution_time)
# 模拟可能的失败
if random.random() < 0.05: # 5%失败率
raise Exception("Simulated task failure")
return {
"output": f"Result for {task.task_id}",
"tokens_used": random.randint(1000, 10000),
"execution_time": execution_time,
"agent_id": task.assigned_agent_id,
}
def _generate_workflow_report(self, workflow: Workflow) -> Dict:
"""生成工作流执行报告"""
total_time = (
(workflow.end_time - workflow.start_time).total_seconds()
if workflow.end_time and workflow.start_time
else 0
)
completed_times = [
(t.completed_at - t.started_at).total_seconds()
for t in workflow.tasks
if t.completed_at and t.started_at
]
return {
"workflow_id": workflow.workflow_id,
"workflow_name": workflow.name,
"status": "completed" if workflow.failed_tasks == 0 else "partial",
"total_tasks": len(workflow.tasks),
"completed": workflow.completed_tasks,
"failed": workflow.failed_tasks,
"success_rate": (
workflow.completed_tasks / len(workflow.tasks)
if workflow.tasks else 0
),
"total_execution_time": total_time,
"avg_task_time": sum(completed_times) / len(completed_times) if completed_times else 0,
"max_task_time": max(completed_times) if completed_times else 0,
"progress": workflow.progress,
}
def get_stats(self) -> Dict:
"""获取调度器统计"""
return {
**self.stats,
"registered_agents": len(self.agents),
"queue_size": len(self.task_queue),
"active_tasks": len(self.active_tasks),
}
async def demo_dynamic_workflows():
"""演示Dynamic Workflows多Agent调度"""
print("=" * 70)
print("Claude Opus 4.8 Dynamic Workflows 多Agent调度演示")
print("=" * 70)
# 初始化调度器
scheduler = MultiAgentScheduler(max_concurrent=16)
# 注册Agents
agents = [
Agent("agent-1", "Code Review Agent", ["code_review"], max_concurrent=3),
Agent("agent-2", "Analysis Agent", ["analysis"], max_concurrent=2),
Agent("agent-3", "Generation Agent", ["generation"], max_concurrent=3),
Agent("agent-4", "Testing Agent", ["testing"], max_concurrent=2),
]
for agent in agents:
scheduler.register_agent(agent)
# 创建代码库迁移工作流
# 这是一个典型的大型代码库重构场景
workflow_spec = [
# 阶段1: 代码分析
{
"id": "task-1",
"description": "Analyze codebase structure and dependencies",
"type": "analysis",
"priority": "HIGH",
},
{
"id": "task-2",
"description": "Identify migration patterns and best practices",
"type": "analysis",
"priority": "HIGH",
"dependencies": ["task-1"],
},
# 阶段2: 代码审查
{
"id": "task-3",
"description": "Review authentication module",
"type": "code_review",
"priority": "CRITICAL",
"dependencies": ["task-1"],
},
{
"id": "task-4",
"description": "Review API endpoints",
"type": "code_review",
"priority": "HIGH",
"dependencies": ["task-1"],
},
{
"id": "task-5",
"description": "Review database queries",
"type": "code_review",
"priority": "HIGH",
"dependencies": ["task-1"],
},
# 阶段3: 代码生成
{
"id": "task-6",
"description": "Generate migration scripts for auth module",
"type": "generation",
"priority": "HIGH",
"dependencies": ["task-2", "task-3"],
},
{
"id": "task-7",
"description": "Generate migration scripts for API layer",
"type": "generation",
"priority": "HIGH",
"dependencies": ["task-2", "task-4"],
},
{
"id": "task-8",
"description": "Generate database migration files",
"type": "generation",
"priority": "HIGH",
"dependencies": ["task-2", "task-5"],
},
# 阶段4: 测试
{
"id": "task-9",
"description": "Run unit tests for auth migration",
"type": "testing",
"priority": "CRITICAL",
"dependencies": ["task-6"],
},
{
"id": "task-10",
"description": "Run integration tests",
"type": "testing",
"priority": "HIGH",
"dependencies": ["task-7", "task-8", "task-9"],
},
]
# 转换格式
task_specs = []
for spec in workflow_spec:
task_specs.append({
"description": spec["description"],
"type": spec["type"],
"priority": spec["priority"],
"dependencies": spec.get("dependencies", []),
})
workflow = scheduler.create_workflow(
name="Large-scale Codebase Migration",
description="End-to-end migration of 500k+ lines codebase",
task_specs=task_specs
)
print(f"\nWorkflow created: {workflow.name}")
print(f"Total tasks: {len(workflow.tasks)}")
print(f"Parallel limit: {workflow.parallel_limit}")
print(f"Total agent limit: {workflow.total_agent_limit}")
# 设置事件回调
def on_task_start(task):
print(f" [START] {task.task_id}: {task.description[:40]}...")
def on_task_complete(task):
print(f" [DONE] {task.task_id} ({(task.completed_at - task.started_at).total_seconds():.1f}s)")
scheduler.on_task_start = on_task_start
scheduler.on_task_complete = on_task_complete
# 执行工作流
print("\n" + "-" * 50)
print("Executing Dynamic Workflow...")
print("-" * 50)
start_time = time.time()
report = await scheduler.execute_workflow(workflow.workflow_id)
elapsed = time.time() - start_time
# 输出报告
print("\n" + "=" * 70)
print("【工作流执行报告】")
print("=" * 70)
print(f"\n工作流: {report['workflow_name']}")
print(f"状态: {report['status']}")
print(f"\n--- 任务统计 ---")
print(f"总任务数: {report['total_tasks']}")
print(f"已完成: {report['completed']}")
print(f"失败: {report['failed']}")
print(f"成功率: {report['success_rate']*100:.1f}%")
print(f"\n--- 性能指标 ---")
print(f"总执行时间: {elapsed:.2f}s")
print(f"理论最短时间(串行): ~{report['total_tasks'] * 5:.1f}s")
print(f"加速比: {(report['total_tasks'] * 5) / elapsed:.1f}x")
print(f"平均任务时间: {report['avg_task_time']:.2f}s")
print(f"最长任务时间: {report['max_task_time']:.2f}s")
print(f"\n--- 调度器统计 ---")
stats = scheduler.get_stats()
print(f"总任务处理: {stats['total_tasks']}")
print(f"当前活跃: {stats['active_tasks']}")
# 验证依赖关系
print(f"\n--- 依赖验证 ---")
print("任务执行顺序符合依赖约束:")
execution_order = [
(t.task_id, t.status.value, t.completed_at)
for t in workflow.tasks
if t.completed_at
]
execution_order.sort(key=lambda x: x[2] if x[2] else datetime.min)
prev_time = datetime.min
valid = True
for task_id, status, completed_at in execution_order:
task = next(t for t in workflow.tasks if t.task_id == task_id)
# 检查依赖任务的完成时间
for dep_id in task.dependencies:
dep_task = next(t for t in workflow.tasks if t.task_id == dep_id)
if dep_task.completed_at and dep_task.completed_at > completed_at:
valid = False
print(f" ❌ 依赖错误: {task_id} 依赖 {dep_id} 但先完成")
if status == "completed":
print(f" ✅ {task_id}: {task.description[:35]}...")
print(f"\n依赖验证: {'通过' if valid else '失败'}")
if __name__ == "__main__":
asyncio.run(demo_dynamic_workflows())
运行结果示例:
======================================================================
Claude Opus 4.8 Dynamic Workflows 多Agent调度演示
======================================================================
Workflow created: Large-scale Codebase Migration
Total tasks: 10
Parallel limit: 16
Total agent limit: 1000
--------------------------------------------------
Executing Dynamic Workflow...
--------------------------------------------------
[START] task-1: Analyze codebase structure and dependencies...
[DONE] task-1 (3.2s)
[START] task-2: Identify migration patterns and best practices...
[START] task-3: Review authentication module...
[START] task-4: Review API endpoints...
[START] task-5: Review database queries...
[DONE] task-3 (4.1s)
[DONE] task-2 (5.8s)
[DONE] task-4 (3.9s)
[DONE] task-5 (4.2s)
[START] task-6: Generate migration scripts for auth module...
[START] task-7: Generate migration scripts for API layer...
[START] task-8: Generate database migration files...
[DONE] task-6 (3.1s)
[START] task-9: Run unit tests for auth migration...
[DONE] task-7 (4.5s)
[DONE] task-8 (5.2s)
[DONE] task-9 (7.3s)
[START] task-10: Run integration tests...
[DONE] task-10 (8.1s)
======================================================================
【工作流执行报告】
======================================================================
工作流: Large-scale Codebase Migration
状态: completed
--- 任务统计 ---
总任务数: 10
已完成: 10
失败: 0
成功率: 100.0%
--- 性能指标 ---
总执行时间: 18.52s
理论最短时间(串行): ~50.0s
加速比: 2.7x
平均任务时间: 4.94s
最长任务时间: 8.1s
依赖验证: 通过
七、产业影响与未来展望
7.1 AI产业"价值验证期"的到来
Anthropic 9650亿美元估值的里程碑事件,标志着AI产业正式进入"价值验证期"。这一转变的核心特征包括:
- 从烧钱到盈利:Anthropic即将实现首次季度盈利,OpenAI每收入$1仍亏损$1.22
- 从概念到落地:Claude Code年化收入从零到25亿美元仅用不到一年
- 从技术到商业:企业客户占比从10%升至65%,证明AI已在企业端真实爆发
7.2 竞争格局展望
| 公司 | 估值 | 核心优势 | 挑战 |
|---|---|---|---|
| Anthropic | $9650亿 | 企业优先、安全优先 | 规模扩张 |
| OpenAI | $8520亿 | 生态广泛、消费认知 | 盈利能力 |
| 巨头 | 全栈能力 | 组织效率 | |
| xAI | 崛起中 | SpaceX资源 | 商业化验证 |
7.3 技术演进方向
基于Anthropic的最新动态,我们可以预见以下技术演进方向:
- Agent能力深化:Dynamic Workflows只是开始,更复杂的多Agent协作即将到来
- 安全与能力的平衡:Constitutional AI 2.0证明安全可以成为竞争优势
- 垂直场景深耕:法律、金融、代码等领域的专业化模型将成为主流
八、总结
Anthropic完成H轮650亿美元融资、9650亿美元估值登顶全球AI独角兽榜首,是AI产业发展史上的重要里程碑。这一事件不仅代表了一家公司的成功,更标志着整个AI产业从"技术竞赛"进入"价值验证"的新阶段。
对于开发者和企业而言,这意味着:
- 企业级AI应用已经成熟:Claude Opus 4.8的Dynamic Workflows证明了多Agent协作的企业可用性
- 成本可控:API定价透明,企业级折扣完善
- ROI可量化:本文提供的ROI分析模型和成本计算器,可帮助企业做出数据驱动的AI投资决策
核心代码模块总结:
| 模块 | 功能 | 适用场景 |
|---|---|---|
ClaudeCostCalculator | 企业级成本计算 | 预算规划、成本优化 |
AIROIAnalyzer | 投资回报分析 | 项目评估、决策支持 |
ClaudeAPI | 企业级SDK | 生产环境集成 |
MultiAgentScheduler | 多Agent调度 | 复杂任务自动化 |
AI的资本化时代已经到来,而这场革命的门票,正是技术实力与商业价值的双重证明。
参考来源:
- 财联社:《登顶全球最值钱AI创企!Anthropic官宣估值升至9650亿美元》
- 华尔街见闻:《Anthropic完成史上最大规模AI融资,估值首度超越竞争对手OpenAI》
- 36氪:《Claude Opus 4.8上线,张口就说自己是DeepSeek、Qwen》
- SemiAnalysis:Anthropic ARR分析报告