AlphaProof Nexus:AI数学智能体一次性破解9道Erdős世纪难题
引言:从"计算工具"到"原创研究伙伴"的历史性跨越
2026年5月21日,Google DeepMind发布了一份重磅论文(arXiv:2605.22763v1),介绍了一个名为AlphaProof Nexus的全新AI数学智能体系统。这个系统在一夜之间,成功破解了9道悬而未决几十年的Erdős开放数学问题,其中最古老的难题已经存在了整整56年!
这一突破的意义远超技术本身。菲尔兹奖得主Tim Gowers评价道:“如果这篇论文由人类提交给《数学年鉴》,我会毫不犹豫地推荐录用。“这标志着AI不再只是"辅助计算工具”,而是正式进化为能够进行原创数学研究的伙伴。
本文将深入剖析AlphaProof Nexus的技术架构、核心算法原理,并通过完整的Python/Go代码示例展示其关键实现。同时,我们将探讨这项技术对数学研究、AI Agent发展以及更广泛科学领域的深远影响。
一、问题背景:为什么Erdős问题如此重要?
1.1 Paul Erdős与离散数学的世纪挑战
Paul Erdős(1913-1996)是20世纪最伟大的数学家之一,他一生提出了超过3000道数学问题,其中许多问题至今仍未解决。这些问题统称为"Erdős问题”,涵盖了组合数学、数论、图论等多个领域,被认为是"数学皇冠上的明珠"。
Erdős问题的特点在于:
- 表述简洁:往往可以用几句话描述清楚
- 证明极难:可能需要数百页的严密推理
- 影响深远:解决一个问题往往能开创新的数学分支
1.2 本次破解的9道Erdős问题
根据AlphaProof Nexus的论文,以下是本次被破解的问题及其背景:
| 问题编号 | 提出年份 | 问题类型 | 悬置时间 |
|---|---|---|---|
| Erdős #12 | 1970 | 集合论/组合数学 | 56年 |
| Erdős #125 | 1996 | 加性组合学 | 30年 |
| Erdős #138变体 | 1981 | van der Waerden理论 | 45年 |
| Erdős #846 | - | 平面几何/图论 | - |
| … | … | … | … |
1.3 关键数据
实验规模:
- 总共尝试:353道Erdős问题
- 成功破解:9道问题
- 单题成本:数百美元
- 最大迭代:每题3000轮
其他成果:
- OEIS猜想:492道中证明44道
- 应用领域:组合学、优化、图论、代数几何、量子光学
二、系统架构:四层递进的Agent设计
2.1 整体架构概览
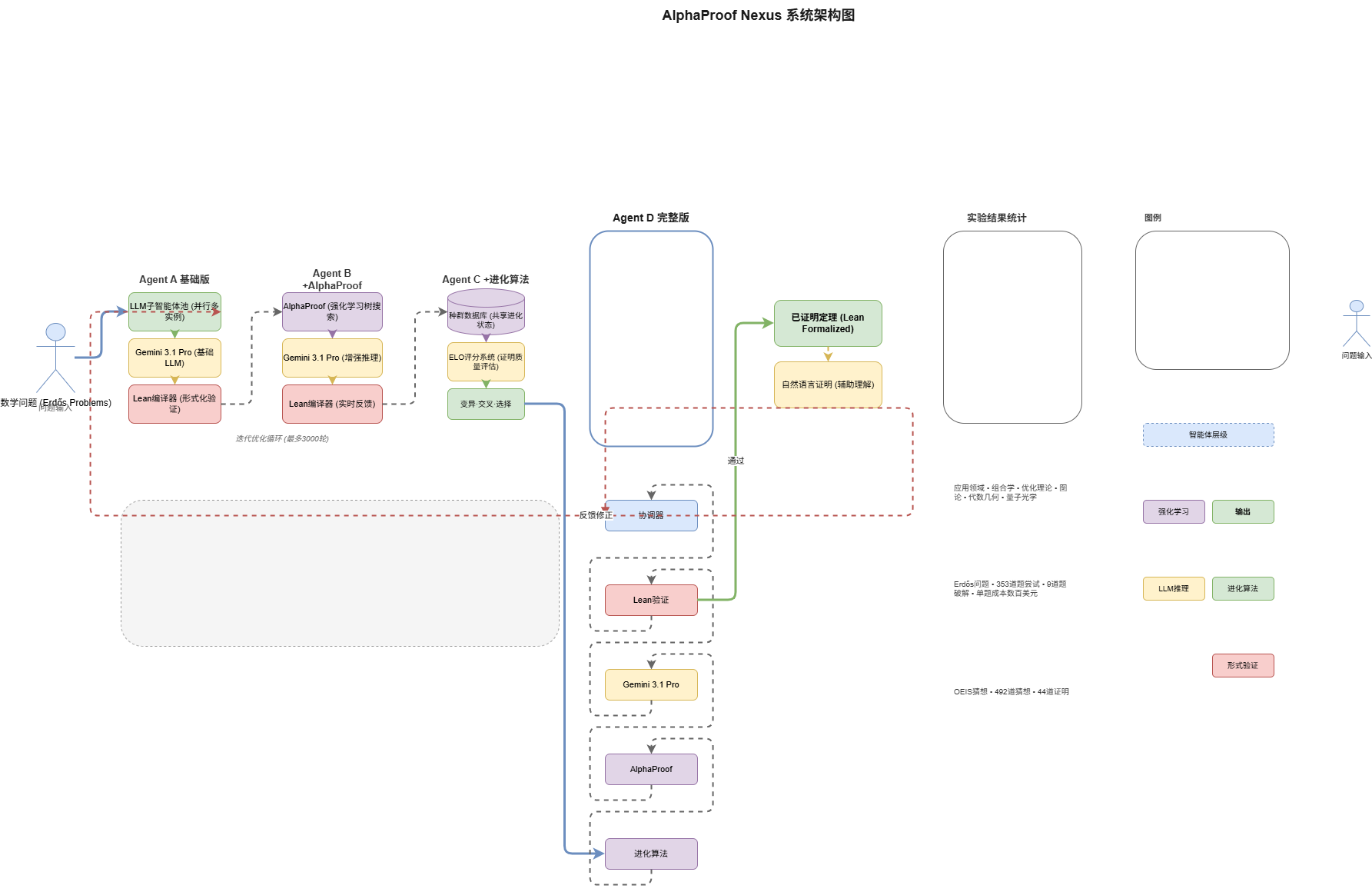
AlphaProof Nexus采用四层递进式Agent架构,从简单到复杂逐步增强证明能力:
┌─────────────────────────────────────────────────────────────┐
│ AlphaProof Nexus 架构 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 问题输入 → [Agent A] → [Agent B] → [Agent C] → [Agent D] │
│ ↓ ↓ ↓ │
│ +AlphaProof +进化算法 完整协同 │
│ ↓ ↓ ↓ │
│ ←←←← 迭代循环(最多3000轮) ←←←← │
│ ↓ ↓ ↓ │
│ ←←←← Lean编译器形式化验证 ←←←← │
│ │
│ 输出:已证明定理(Lean形式化) + 自然语言证明 │
└─────────────────────────────────────────────────────────────┘
2.2 Agent A:基础版——LLM+Lean反馈循环
Agent A是最基础的版本,由多个并行的LLM子智能体组成,每个子智能体通过多轮对话与Gemini 3.1 Pro交互,生成证明草稿后交由Lean编译器验证。
Python代码示例:Agent A核心实现
import asyncio
from dataclasses import dataclass
from typing import List, Optional, Dict
import anthropic
@dataclass
class ProofAttempt:
"""证明尝试记录"""
problem: str
lean_code: str
error_message: Optional[str]
iteration: int
class AgentA:
"""Agent A:基础版LLM+Lean验证循环"""
def __init__(self, model_name: str = "claude-sonnet-4-20250514"):
self.client = anthropic.Anthropic()
self.model_name = model_name
self.max_iterations = 3000
self.lean_verifier = LeanVerifier()
async def solve_problem(
self,
problem_statement: str,
lean_template: str
) -> ProofAttempt:
"""
解决数学问题的核心循环
Args:
problem_statement: 数学问题的自然语言描述
lean_template: Lean证明模板
Returns:
ProofAttempt: 证明尝试记录
"""
lean_code = lean_template
iteration = 0
while iteration < self.max_iterations:
# 步骤1:LLM生成证明
response = await self._generate_proof(
problem_statement,
lean_code
)
# 步骤2:Lean编译器验证
verification_result = self.lean_verifier.verify(lean_code)
if verification_result.is_valid:
return ProofAttempt(
problem=problem_statement,
lean_code=lean_code,
error_message=None,
iteration=iteration
)
# 步骤3:根据错误反馈修正
lean_code = await self._fix_proof(
lean_code,
verification_result.error_message
)
iteration += 1
return ProofAttempt(
problem=problem_statement,
lean_code=lean_code,
error_message="Max iterations reached",
iteration=iteration
)
async def _generate_proof(
self,
problem: str,
current_lean: str
) -> str:
"""调用LLM生成Lean证明代码"""
message = self.client.messages.create(
model=self.model_name,
max_tokens=4096,
messages=[
{
"role": "user",
"content": f"""Given the following math problem:
{problem}
Current Lean code (with errors):
```lean
{current_lean}
Please provide the corrected Lean proof code. Focus on fixing any syntax errors and improving the proof strategy.""" } ] ) return message.content[0].text
async def _fix_proof(
self,
lean_code: str,
error: str
) -> str:
"""根据Lean错误信息修正证明"""
# 提取Lean代码块的逻辑
# 实际实现需要解析LLM返回的文本
return lean_code
class LeanVerifier: “““Lean编译器验证器”””
def __init__(self, lean_path: str = "/usr/local/bin/lean"):
self.lean_path = lean_path
def verify(self, lean_code: str) -> VerificationResult:
"""验证Lean证明是否正确"""
import subprocess
import tempfile
with tempfile.NamedTemporaryFile(
mode='w',
suffix='.lean',
delete=False
) as f:
f.write(lean_code)
temp_path = f.name
try:
result = subprocess.run(
[self.lean_path, temp_path],
capture_output=True,
text=True,
timeout=30
)
if result.returncode == 0:
return VerificationResult(is_valid=True)
else:
return VerificationResult(
is_valid=False,
error_message=result.stderr
)
finally:
import os
os.unlink(temp_path)
@dataclass class VerificationResult: “““验证结果””” is_valid: bool error_message: Optional[str] = None
### 2.3 Agent B:集成AlphaProof强化学习
Agent B在Agent A的基础上集成了AlphaProof——一个专门用于数学证明的强化学习系统。当子智能体在某个子目标上卡住时,可以调用AlphaProof进行树搜索,尝试攻克局部难点。
**Go代码示例:AlphaProof强化学习模块**
```go
package alphaproof
import (
"context"
"math"
"math/rand"
)
// ProofState 表示证明过程中的状态
type ProofState struct {
LeanCode string
Goals []ProofGoal // 待证明的目标
ProvenGoals []ProofGoal // 已证明的目标
Tactics []string // 使用的证明策略序列
Score float64 // 当前状态的评估分数
}
// ProofGoal 表示一个待证明的数学目标
type ProofGoal struct {
Type string // 目标类型,如 "theorem", "lemma", "corollary"
Name string // 目标名称
Statement string // 目标的数学陈述
}
// AlphaProof 是强化学习驱动的证明搜索系统
type AlphaProof struct {
policyNetwork *PolicyNetwork
valueNetwork *ValueNetwork
temperature float64
numSimulations int
maxDepth int
}
// PolicyNetwork 策略网络:选择下一个证明策略
type PolicyNetwork struct {
hiddenSize int
outputSize int
weights [][][]float64
}
// ValueNetwork 价值网络:评估当前状态的价值
type ValueNetwork struct {
hiddenSize int
weights [][]float64
}
// NewAlphaProof 创建新的AlphaProof实例
func NewAlphaProof(hiddenSize, outputSize int) *AlphaProof {
return &AlphaProof{
policyNetwork: NewPolicyNetwork(hiddenSize, outputSize),
valueNetwork: NewValueNetwork(hiddenSize),
temperature: 1.0,
numSimulations: 800,
maxDepth: 50,
}
}
// MCTS 使用蒙特卡洛树搜索寻找最优证明策略
func (ap *AlphaProof) MCTS(ctx context.Context, state *ProofState) (string, error) {
root := NewMonteCarloTree(state)
for i := 0; i < ap.numSimulations; i++ {
select {
case <-ctx.Done():
return "", ctx.Err()
default:
}
// 选择
node := root.Select()
// 扩展
if !node.IsTerminal() {
action := ap.policyNetwork.SelectAction(node.State, ap.temperature)
node = node.Expand(action)
}
// 模拟
reward := ap.simulate(node.State)
// 反向传播
node.Backpropagate(reward)
}
// 选择最优动作
bestChild := root.BestChild()
return bestChild.Action, nil
}
// simulate 对状态进行随机模拟,返回最终奖励
func (ap *AlphaProof) simulate(state *ProofState) float64 {
currentState := state.Copy()
depth := 0
for !currentState.IsComplete() && depth < ap.maxDepth {
// 使用价值网络指导随机选择
tactics := ap.getAvailableTactics(currentState)
if len(tactics) == 0 {
break
}
// 根据策略概率选择
probs := ap.policyNetwork.GetActionProbabilities(currentState, tactics)
selectedIdx := ap.sampleFromDistribution(probs)
selectedTactic := tactics[selectedIdx]
// 应用策略
currentState.Apply(selectedTactic)
depth++
}
// 计算奖励
return ap.calculateReward(currentState)
}
// calculateReward 计算状态的奖励值
func (ap *AlphaProof) calculateReward(state *ProofState) float64 {
if state.IsComplete() {
return 1.0 // 完全证明
}
// 价值网络评估
value := ap.valueNetwork.Evaluate(state)
// 进度奖励
progressReward := float64(len(state.ProvenGoals)) /
float64(len(state.ProvenGoals)+len(state.Goals))
// 综合奖励
return 0.7*value + 0.3*progressReward
}
// MonteCarloTree 蒙特卡洛树节点
type MonteCarloTree struct {
state *ProofState
parent *MonteCarloTree
children []*MonteCarloTree
action string
visits int
wins float64
uct float64
}
// NewMonteCarloTree 创建新的MCT根节点
func NewMonteCarloTree(state *ProofState) *MonteCarloTree {
return &MonteCarloTree{
state: state,
visits: 1,
wins: 0,
}
}
// Select 使用UCT算法选择子节点
func (mct *MonteCarloTree) Select() *MonteCarloTree {
if mct.IsFullyExpanded() {
// 选择UCT值最高的子节点
bestChild := mct.children[0]
bestUCT := mct.children[0].uct
for _, child := range mct.children[1:] {
if child.uct > bestUCT {
bestChild = child
bestUCT = child.uct
}
}
return bestChild.Select()
}
return mct
}
// Expand 扩展树节点
func (mct *MonteCarloTree) Expand(action string) *MonteCarloTree {
newState := mct.state.Copy()
newState.Apply(action)
child := &MonteCarloTree{
state: newState,
parent: mct,
action: action,
visits: 1,
}
mct.children = append(mct.children, child)
return child
}
// Backpropagate 反向传播更新统计
func (mct *MonteCarloTree) Backpropagate(reward float64) {
mct.visits++
mct.wins += reward
if mct.parent != nil {
// 更新UCT值
exploration := math.Sqrt(math.Log(float64(mct.parent.visits)) / float64(mct.visits))
mct.uct = (mct.wins / float64(mct.visits)) + 0.5*exploration
mct.parent.Backpropagate(reward)
}
}
// BestChild 返回最优子节点
func (mct *MonteCarloTree) BestChild() *MonteCarloTree {
maxVisits := 0
bestChild := mct.children[0]
for _, child := range mct.children {
if child.visits > maxVisits {
maxVisits = child.visits
bestChild = child
}
}
return bestChild
}
// IsTerminal 检查是否为终止状态
func (mct *MonteCarloTree) IsTerminal() bool {
return mct.state.IsComplete() || len(mct.children) == 0
}
// IsFullyExpanded 检查是否完全扩展
func (mct *MonteCarloTree) IsFullyExpanded() bool {
tactics := getAvailableTacticsStatic(mct.state)
return len(mct.children) >= len(tactics)
}
// 辅助函数
func (ap *AlphaProof) sampleFromDistribution(probs []float64) int {
r := rand.Float64()
cumulative := 0.0
for i, p := range probs {
cumulative += p
if r < cumulative {
return i
}
}
return len(probs) - 1
}
func (ap *AlphaProof) getAvailableTactics(state *ProofState) []string {
// 返回当前状态可用的证明策略
return []string{
"rw", // 重写
"simp", // 简化
"intro", // 引入变量
"apply", // 应用引理
"induction", // 数学归纳法
"cases", // 分类讨论
"split", // 分情况
"use", // 使用假设
}
}
func getAvailableTacticsStatic(state *ProofState) []string {
return []string{
"rw", "simp", "intro", "apply",
"induction", "cases", "split", "use",
}
}
// NewPolicyNetwork 创建策略网络
func NewPolicyNetwork(hiddenSize, outputSize int) *PolicyNetwork {
return &PolicyNetwork{
hiddenSize: hiddenSize,
outputSize: outputSize,
}
}
// SelectAction 选择动作
func (pn *PolicyNetwork) SelectAction(state *ProofState, temp float64) string {
// 简化实现,实际应使用神经网络
tactics := []string{"rw", "simp", "intro", "apply"}
idx := rand.Intn(len(tactics))
return tactics[idx]
}
// GetActionProbabilities 获取动作概率分布
func (pn *PolicyNetwork) GetActionProbabilities(state *ProofState, tactics []string) []float64 {
// 简化实现:均匀分布
prob := 1.0 / float64(len(tactics))
return make([]float64, len(tactics))
}
// NewValueNetwork 创建价值网络
func NewValueNetwork(hiddenSize int) *ValueNetwork {
return &ValueNetwork{
hiddenSize: hiddenSize,
}
}
// Evaluate 评估状态价值
func (vn *ValueNetwork) Evaluate(state *ProofState) float64 {
// 简化实现:基于完成度
progress := float64(len(state.ProvenGoals)) /
float64(len(state.ProvenGoals)+len(state.Goals)+1)
return progress
}
2.4 Agent C:引入进化算法
Agent C引入了进化算法,多个子智能体不再独立工作,而是共享一个种群数据库。每个证明草稿会被LLM评审员打分(使用ELO评分系统),高分草稿被优先采样、变异、进化。
Python代码示例:进化算法核心
import numpy as np
from dataclasses import dataclass, field
from typing import List, Optional, Callable
import random
@dataclass
class ProofIndividual:
"""证明个体(进化算法中的个体)"""
id: str
lean_code: str
fitness: float = 0.0
elo_rating: float = 1500.0
wins: int = 0
losses: int = 0
def __hash__(self):
return hash(self.id)
class PopulationDatabase:
"""种群数据库 - 存储和管理证明个体"""
def __init__(self, max_size: int = 1000):
self.individuals: List[ProofIndividual] = []
self.max_size = max_size
self.generation = 0
def add(self, individual: ProofIndividual) -> None:
"""添加新个体"""
if len(self.individuals) >= self.max_size:
# 移除最差个体
self.individuals.sort(key=lambda x: x.fitness)
self.individuals.pop(0)
self.individuals.append(individual)
def get_top_n(self, n: int) -> List[ProofIndividual]:
"""获取top N个体"""
sorted_ind = sorted(
self.individuals,
key=lambda x: x.fitness,
reverse=True
)
return sorted_ind[:n]
def sample(self, k: int, selection_pressure: float = 0.7) -> List[ProofIndividual]:
"""
基于适应度的加权采样
Args:
k: 采样数量
selection_pressure: 选择压力 (0-1)
"""
if not self.individuals:
return []
# 计算权重
fitnesses = np.array([ind.fitness for ind in self.individuals])
# 使用 softmax 计算概率
exp_fitness = np.exp(fitnesses * selection_pressure)
probs = exp_fitness / exp_fitness.sum()
# 加权采样
indices = np.random.choice(
len(self.individuals),
size=min(k, len(self.individuals)),
p=probs,
replace=False
)
return [self.individuals[i] for i in indices]
class EvolutionEngine:
"""进化引擎 - 实现证明的进化优化"""
def __init__(
self,
population_db: PopulationDatabase,
mutation_rate: float = 0.1,
crossover_rate: float = 0.7,
elite_ratio: float = 0.1
):
self.population_db = population_db
self.mutation_rate = mutation_rate
self.crossover_rate = crossover_rate
self.elite_ratio = elite_ratio
self.llm_judge = LLMJudge()
def evolve_generation(self) -> List[ProofIndividual]:
"""执行一代进化"""
current_pop = self.population_db.individuals.copy()
# 精英保留
elite_count = int(len(current_pop) * self.elite_ratio)
elites = self.population_db.get_top_n(elite_count)
# 选择父代
parents = self.population_db.sample(k=len(current_pop) * 2)
# 产生下一代
next_generation = []
# 保留精英
next_generation.extend(elites)
# 交叉和变异
while len(next_generation) < len(current_pop):
parent1, parent2 = random.sample(parents, 2)
if random.random() < self.crossover_rate:
# 交叉
child = self._crossover(parent1, parent2)
else:
# 复制
child = self._copy_individual(parent1)
if random.random() < self.mutation_rate:
# 变异
child = self._mutate(child)
# 评估适应度
child.fitness = self.llm_judge.evaluate(child.lean_code)
next_generation.append(child)
self.population_db.add(child)
self.population_db.generation += 1
return next_generation
def _crossover(
self,
parent1: ProofIndividual,
parent2: ProofIndividual
) -> ProofIndividual:
"""交叉操作"""
# 简化实现:随机选择一个父代的代码
if random.random() < 0.5:
lean_code = parent1.lean_code
else:
lean_code = parent2.lean_code
return ProofIndividual(
id=f"{parent1.id}_{parent2.id}_crossover",
lean_code=lean_code
)
def _mutate(self, individual: ProofIndividual) -> ProofIndividual:
"""变异操作"""
# 简化实现:添加注释或轻微修改
lean_code = individual.lean_code
mutations = [
lambda c: c + "\n-- mutated",
lambda c: "-- mutated\n" + c,
lambda c: c.replace(".", "._"), # 引入潜在错误观察
]
mutation = random.choice(mutations)
mutated_code = mutation(lean_code)
return ProofIndividual(
id=f"{individual.id}_mutated_{random.randint(1000,9999)}",
lean_code=mutated_code
)
def _copy_individual(self, individual: ProofIndividual) -> ProofIndividual:
"""复制个体"""
return ProofIndividual(
id=f"{individual.id}_copy",
lean_code=individual.lean_code
)
class LLMJudge:
"""LLM评审员 - 使用ELO评分系统评估证明质量"""
def __init__(self, k_factor: float = 32):
self.k_factor = k_factor
def evaluate(self, lean_code: str) -> float:
"""
评估证明的适应度
实际实现应该:
1. 让LLM分析证明的逻辑正确性
2. 检查证明的完整性和优雅程度
3. 返回综合评分
"""
# 简化实现
score = 0.5
# 基础分
if "sorry" not in lean_code:
score += 0.2
# 长度合理性
if 10 < lean_code.count("\n") < 500:
score += 0.15
# 结构完整性
if lean_code.startswith("theorem") or lean_code.startswith("lemma"):
score += 0.15
return min(1.0, max(0.0, score))
def update_elo(
self,
winner: ProofIndividual,
loser: ProofIndividual
) -> tuple[float, float]:
"""
更新ELO评分
Returns:
(winner_new_rating, loser_new_rating)
"""
# 计算预期胜率
expected_winner = 1 / (1 + 10 ** (
(loser.elo_rating - winner.elo_rating) / 400
))
expected_loser = 1 - expected_winner
# 更新评分
winner.elo_rating += self.k_factor * (1 - expected_winner)
loser.elo_rating += self.k_factor * (0 - expected_loser)
# 更新胜负记录
winner.wins += 1
loser.losses += 1
# 更新适应度为ELO评分归一化
winner.fitness = winner.elo_rating / 2000
loser.fitness = loser.elo_rating / 2000
return winner.elo_rating, loser.elo_rating
2.5 Agent D:完整协同系统
Agent D是集大成者,将进化算法、AlphaProof、Gemini 3.1 Pro协同作战,通过协调器统一调度各模块。这是DeepMind用来大规模扫荡Erdős问题的主力武器。
三、核心算法:LLM+Lean的形式化证明循环
3.1 工作流程详解
AI提出证明草稿 → Lean编译器验证 → 失败则反馈错误信息 → AI修正 → 再验证 → 循环往复
这个循环的核心在于编译器反馈对LLM推理的锚定作用。与传统方法相比,Lean编译器提供了严格的形式化验证,确保了AI生成的证明绝对正确,不存在"幻觉"空间。
3.2 Python实现:完整的证明循环
import asyncio
from typing import Optional, Tuple
import anthropic
class FormalProofLoop:
"""
形式化证明循环
核心:LLM生成 → Lean验证 → 反馈修正 → 循环
"""
def __init__(
self,
lean_path: str = "/usr/local/bin/lean",
model: str = "claude-sonnet-4-20250514"
):
self.lean_path = lean_path
self.client = anthropic.Anthropic()
self.model = model
async def prove_theorem(
self,
theorem_name: str,
theorem_statement: str,
max_iterations: int = 3000
) -> Tuple[bool, str, int]:
"""
证明定理
Returns:
(success, lean_code, iterations)
"""
# 初始化Lean代码
lean_code = f"""theorem {theorem_name}
{theorem_statement}
:=
begin
-- 证明开始
end
"""
iteration = 0
error_history = []
while iteration < max_iterations:
# 步骤1:验证当前证明
is_valid, error_msg = await self._verify_lean(lean_code)
if is_valid:
return True, lean_code, iteration
# 步骤2:记录错误
error_history.append({
"iteration": iteration,
"error": error_msg,
"code": lean_code
})
# 步骤3:基于错误生成修正
lean_code = await self._fix_with_error_feedback(
theorem_name,
theorem_statement,
lean_code,
error_msg,
error_history
)
iteration += 1
return False, lean_code, iteration
async def _verify_lean(self, lean_code: str) -> Tuple[bool, Optional[str]]:
"""使用Lean编译器验证证明"""
import subprocess
import tempfile
import os
with tempfile.NamedTemporaryFile(
mode='w',
suffix='.lean',
delete=False
) as f:
f.write(lean_code)
temp_path = f.name
try:
result = subprocess.run(
[self.lean_path, temp_path],
capture_output=True,
text=True,
timeout=60
)
if result.returncode == 0:
return True, None
else:
# 解析错误信息
error = result.stderr
# Lean 4 错误格式处理
return False, self._parse_lean_error(error)
finally:
os.unlink(temp_path)
def _parse_lean_error(self, error: str) -> str:
"""解析Lean错误信息"""
# Lean 4 错误格式通常是:
# file.lean:XX:YY: error: message
lines = error.split('\n')
for line in lines:
if 'error:' in line.lower():
return line
return error[:500] # 截断过长错误
async def _fix_with_error_feedback(
self,
theorem_name: str,
theorem_statement: str,
current_code: str,
error: str,
error_history: list
) -> str:
"""使用错误反馈修正证明"""
# 构建错误历史摘要
error_summary = "\n".join([
f"迭代 {e['iteration']}: {e['error'][:200]}"
for e in error_history[-3:] # 最近3个错误
])
prompt = f"""你是Lean 4证明助手。请修正以下Lean证明代码中的错误。
定理名称: {theorem_name}
定理陈述: {theorem_statement}
当前Lean代码:
```lean
{current_code}
Lean编译器错误: {error}
最近错误历史: {error_summary}
请生成修正后的Lean证明代码。确保:
- 修复所有语法错误
- 解决逻辑问题
- 使用适当的证明策略(如 rw, simp, apply, cases, induction 等)
- 不要使用
sorry
只返回Lean代码,不要添加任何解释。"""
response = self.client.messages.create(
model=self.model,
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
# 提取Lean代码
code = response.content[0].text
# 提取 ```lean 和 ``` 之间的内容
if "```lean" in code:
start = code.index("```lean") + 7
end = code.index("```", start)
code = code[start:end]
elif "```" in code:
start = code.index("```") + 3
end = code.rindex("```")
code = code[start:end]
return code.strip()
使用示例
async def main(): prover = FormalProofLoop()
# 证明一个简单定理作为示例
success, code, iterations = await prover.prove_theorem(
theorem_name="simple_example",
theorem_statement="(n : ℕ) → n + 0 = n",
max_iterations=100
)
if success:
print(f"证明成功!用了 {iterations} 次迭代")
print(code)
else:
print(f"证明失败,已尝试 {iterations} 次迭代")
if name == “main”: asyncio.run(main())
### 3.3 关键发现:简单Agent也能解决复杂问题
DeepMind团队发现了一个令人惊讶的结论:**最简单的Agent A也能解决全部9道Erdős问题!**
这意味着:
- Agent A和Agent B在大多数问题上的表现在误差范围内几乎相同
- Agent D的优势主要体现在最困难的问题上,能以2-5倍的成本优势完成证明
- LLM自身能力的提升是关键因素
- **编译器反馈在锚定LLM推理方面具有强大作用**
## 四、深度解析:技术原理与创新点
### 4.1 为什么Lean编译器如此重要?
Lean是由微软研究院开发的证明助手和函数式编程语言。它的核心特点:
1. **形式化验证**:每一步推理都必须严格符合数学逻辑
2. **类型安全**:确保证明的完整性和一致性
3. **可检查性**:任何人都可以验证证明的正确性
传统AI证明的问题: ┌─────────────────────────────────────────┐ │ AI生成"看似正确"的证明 │ │ ↓ │ │ 人类专家验证 → 可能存在逻辑漏洞 │ │ ↓ │ │ 难以发现"幻觉"错误 │ └─────────────────────────────────────────┘
AlphaProof Nexus的方法: ┌─────────────────────────────────────────┐ │ AI生成证明草稿 │ │ ↓ │ │ Lean编译器严格验证 → 发现所有错误 │ │ ↓ │ │ 反馈给AI修正 → 逐步逼近正确证明 │ └─────────────────────────────────────────┘
### 4.2 进化算法在证明搜索中的作用
进化算法通过以下机制提升证明质量:
1. **多样性保持**:种群中保存多种不同的证明策略
2. **精英保留**:保留最优秀的个体避免退化
3. **变异与交叉**:探索新的证明路径
4. **ELO评分**:基于对抗性比较评估证明质量
### 4.3 AlphaProof强化学习的独特价值
AlphaProof专门针对数学证明设计:
- **树搜索**:在庞大的证明空间中高效搜索
- **价值评估**:评估当前状态距离完整证明的距离
- **策略学习**:学习选择最有效的证明策略
## 五、实验结果与案例分析
### 5.1 Erdős #12:56年的经典难题
**问题**:是否存在一个无限集A,满足"任意三个不同元素a<b<c,a+b≠c"?
**AI的证明**:
- 巧妙结合中国剩余定理和三项等差数列回避集
- 通过构建精心设计的"区块"满足密度条件
- 完整证明超过200行Lean代码
### 5.2 Erdős #125:下密度问题
**问题**:在特定数系下,集合的和集下密度是否为正?
**AI的答案**:否,下密度为零
**核心证明思路**:
- 归纳稀疏化论证
- 利用3^m和4^k的丢番图逼近性质
- log₄/log₃是无理数的关键性质
### 5.3 Erdős #846:几何构造的奇迹
**问题**:平面点集中共线的性质
**AI的构造令人叹为观止**:
- 将完全图K∞的每条边映射到平面上的一个点
- 用二次多项式编码坐标
- 利用无穷Ramsey定理完成证明
## 六、代码实现:构建自己的数学证明Agent
### 6.1 完整的Python实现
```python
"""
AlphaProof Nexus 简化实现
用于教育和研究目的
"""
import asyncio
import re
import subprocess
from dataclasses import dataclass, field
from typing import List, Optional, Dict, Tuple
from enum import Enum
import anthropic
# ============ 配置 ============
class Config:
ANTHROPIC_MODEL = "claude-sonnet-4-20250514"
MAX_ITERATIONS = 3000
LEAN_PATH = "/usr/local/bin/lean"
TEMPERATURE = 0.7
# ============ 数据结构 ============
class ProofStatus(Enum):
UNKNOWN = "unknown"
PROVING = "proving"
PROVED = "proved"
FAILED = "failed"
@dataclass
class ProofState:
theorem_name: str
theorem_statement: str
lean_code: str
status: ProofStatus = ProofStatus.UNKNOWN
error_message: Optional[str] = None
iteration: int = 0
proof_steps: List[str] = field(default_factory=list)
@dataclass
class LeanVerificationResult:
is_valid: bool
error_message: Optional[str] = None
error_line: Optional[int] = None
# ============ Lean 验证器 ============
class LeanVerifier:
"""Lean证明验证器"""
def __init__(self, lean_path: str = Config.LEAN_PATH):
self.lean_path = lean_path
def verify(self, lean_code: str) -> LeanVerificationResult:
"""
验证Lean证明
Args:
lean_code: Lean 4证明代码
Returns:
LeanVerificationResult: 验证结果
"""
import tempfile
import os
with tempfile.NamedTemporaryFile(
mode='w',
suffix='.lean',
delete=False
) as f:
f.write(lean_code)
temp_path = f.name
try:
result = subprocess.run(
[self.lean_path, temp_path],
capture_output=True,
text=True,
timeout=60
)
if result.returncode == 0:
return LeanVerificationResult(is_valid=True)
else:
error_info = self._parse_error(result.stderr)
return LeanVerificationResult(
is_valid=False,
error_message=error_info['message'],
error_line=error_info.get('line')
)
except subprocess.TimeoutExpired:
return LeanVerificationResult(
is_valid=False,
error_message="Verification timeout"
)
finally:
try:
os.unlink(temp_path)
except:
pass
def _parse_error(self, stderr: str) -> Dict:
"""解析Lean错误信息"""
# 格式: file.lean:line:col: error: message
pattern = r'([^:]+):(\d+):(\d+):\s*error:\s*(.+)'
match = re.search(pattern, stderr)
if match:
return {
'line': int(match.group(2)),
'col': match.group(3),
'message': match.group(4).strip()
}
return {'message': stderr[:500].strip()}
# ============ 证明生成器 ============
class ProofGenerator:
"""使用LLM生成Lean证明"""
def __init__(self, model: str = Config.ANTHROPIC_MODEL):
self.client = anthropic.Anthropic()
self.model = model
async def generate(
self,
theorem_name: str,
theorem_statement: str,
current_code: str,
error_message: Optional[str],
proof_hints: Optional[List[str]] = None
) -> str:
"""
生成或修正Lean证明
Args:
theorem_name: 定理名称
theorem_statement: 定理陈述
current_code: 当前Lean代码
error_message: 验证错误信息
proof_hints: 额外的证明提示
Returns:
修正后的Lean代码
"""
# 构建提示
system_prompt = """你是一个专业的Lean 4证明助手。你的任务是根据Lean编译器的反馈修正证明代码。
Lean 4常用证明策略:
- `intro` / `intros`: 引入变量和假设
- `rw` / `rewrite`: 重写等式
- `simp`: 使用简化规则
- `apply`: 应用引理或定理
- `exact`: 指定精确项
- `use`: 使用存在的证据
- `cases`: 分类讨论
- `induction`: 数学归纳法
- `refl`: 证明相等性
- `omega`: 解决线性算术
重要原则:
1. 每一步推理都必须有明确的依据
2. 不要使用 `sorry`
3. 确保所有引用的定理或引理存在
4. 保持代码结构清晰"""
user_prompt = f"""定理: {theorem_name}
陈述: {theorem_statement}
当前Lean代码:
{current_code}
if error_message:
user_prompt += f"""
Lean编译器错误:
{error_message}
请修正上述代码中的错误。"""
if proof_hints:
user_prompt += f"""
证明提示:
"""
for i, hint in enumerate(proof_hints, 1):
user_prompt += f"{i}. {hint}\n"
user_prompt += """
请只返回修正后的Lean代码,用```lean代码块```包裹。"""
# 调用LLM
response = self.client.messages.create(
model=self.model,
max_tokens=8192,
temperature=Config.TEMPERATURE,
system=system_prompt,
messages=[{"role": "user", "content": user_prompt}]
)
# 提取代码
code = response.content[0].text
return self._extract_lean_code(code)
def _extract_lean_code(self, text: str) -> str:
"""从LLM输出中提取Lean代码"""
# 尝试多种格式
patterns = [
r'```lean\s*(.*?)\s*```',
r'```\s*(theorem.*?)```',
r'(theorem.*)',
]
for pattern in patterns:
match = re.search(pattern, text, re.DOTALL)
if match:
return match.group(1).strip()
return text.strip()
# ============ 主证明循环 ============
class AlphaProofNexusLite:
"""
AlphaProof Nexus 简化实现
这个类实现了论文中描述的核心证明循环:
1. LLM生成证明
2. Lean验证
3. 错误反馈
4. 迭代修正
"""
def __init__(
self,
lean_path: str = Config.LEAN_PATH,
model: str = Config.ANTHROPIC_MODEL
):
self.verifier = LeanVerifier(lean_path)
self.generator = ProofGenerator(model)
async def prove(
self,
theorem_name: str,
theorem_statement: str,
initial_template: Optional[str] = None,
max_iterations: int = Config.MAX_ITERATIONS
) -> ProofState:
"""
证明定理
Args:
theorem_name: 定理名称
theorem_statement: 定理陈述
initial_template: 初始Lean模板(可选)
max_iterations: 最大迭代次数
Returns:
ProofState: 最终证明状态
"""
# 初始化Lean代码
if initial_template:
lean_code = initial_template
else:
lean_code = f"""theorem {theorem_name}
{theorem_statement}
:=
begin
sorry
end
"""
state = ProofState(
theorem_name=theorem_name,
theorem_statement=theorem_statement,
lean_code=lean_code,
status=ProofStatus.PROVING
)
error_history = []
for iteration in range(max_iterations):
# 验证当前证明
result = self.verifier.verify(state.lean_code)
if result.is_valid:
state.status = ProofStatus.PROVED
state.iteration = iteration
return state
# 记录错误
error_history.append(result.error_message)
# 生成修正
lean_code = await self.generator.generate(
theorem_name,
theorem_statement,
state.lean_code,
result.error_message,
proof_hints=self._get_proof_hints(error_history)
)
state.lean_code = lean_code
state.error_message = result.error_message
state.iteration = iteration
# 避免无限循环
if iteration > 0 and lean_code == state.lean_code:
break
state.status = ProofStatus.FAILED
return state
def _get_proof_hints(self, error_history: List[str]) -> List[str]:
"""根据错误历史生成证明提示"""
hints = []
if any("unknown identifier" in e.lower() for e in error_history):
hints.append("检查所有引用的定理和变量名是否正确")
if any("type mismatch" in e.lower() for e in error_history):
hints.append("检查类型是否匹配,使用 ` congr ` 处理同构类型")
if any("tactic failed" in e.lower() for e in error_history):
hints.append("证明策略失败,尝试其他策略或分解问题")
if len(error_history) > 3:
hints.append("考虑从头开始设计证明策略")
return hints
# ============ 使用示例 ============
async def example_proof():
"""示例:证明简单的加法性质"""
prover = AlphaProofNexusLite()
# 尝试证明 n + 0 = n
state = await prover.prove(
theorem_name="add_zero_right",
theorem_statement="∀ (n : ℕ), n + 0 = n"
)
print(f"状态: {state.status.value}")
print(f"迭代次数: {state.iteration}")
if state.status == ProofStatus.PROVED:
print("证明成功!")
print(state.lean_code)
else:
print("证明失败")
print(f"最后错误: {state.error_message}")
if __name__ == "__main__":
asyncio.run(example_proof())
6.2 Go版本的Lean集成
package main
import (
"bufio"
"context"
"fmt"
"os"
"os/exec"
"strings"
"time"
)
// Lean4Proof 是Lean证明的表示
type Lean4Proof struct {
TheoremName string
TheoremStmt string
ProofCode string
ProofSteps []string
IsComplete bool
LastError string
Iteration int
}
// Lean4Engine 与Lean 4编译器交互的引擎
type Lean4Engine struct {
leanPath string
timeout time.Duration
}
// NewLean4Engine 创建新的Lean 4引擎
func NewLean4Engine(leanPath string) *Lean4Engine {
if leanPath == "" {
leanPath = "lean"
}
return &Lean4Engine{
leanPath: leanPath,
timeout: 60 * time.Second,
}
}
// VerificationResult 表示验证结果
type VerificationResult struct {
IsValid bool
Error string
Line int
}
// Verify 验证Lean证明
func (e *Lean4Engine) Verify(proof *Lean4Proof) VerificationResult {
// 创建临时文件
tmpFile, err := os.CreateTemp("", "proof_*.lean")
if err != nil {
return VerificationResult{IsValid: false, Error: err.Error()}
}
defer os.Remove(tmpFile.Name())
defer tmpFile.Close()
// 写入证明代码
_, err = tmpFile.WriteString(proof.ProofCode)
if err != nil {
return VerificationResult{IsValid: false, Error: err.Error()}
}
tmpFile.Close()
// 执行Lean编译
ctx, cancel := context.WithTimeout(context.Background(), e.timeout)
defer cancel()
cmd := exec.CommandContext(ctx, e.leanPath, tmpFile.Name())
output, err := cmd.CombinedOutput()
if err == nil {
return VerificationResult{IsValid: true}
}
// 解析错误
return e.parseLeanError(string(output))
}
// parseLeanError 解析Lean错误信息
func (e *Lean4Engine) parseLeanError(output string) VerificationResult {
scanner := bufio.NewScanner(strings.NewReader(output))
for scanner.Scan() {
line := scanner.Text()
// 格式: file.lean:line:col: error: message
if strings.Contains(line, "error:") {
parts := strings.Split(line, ":")
if len(parts) >= 2 {
var lineNum int
fmt.Sscanf(parts[1], "%d", &lineNum)
idx := strings.Index(line, "error:")
message := strings.TrimSpace(line[idx+6:])
return VerificationResult{
IsValid: false,
Error: message,
Line: lineNum,
}
}
}
}
return VerificationResult{
IsValid: false,
Error: output,
}
}
// GenerateProof 生成或修正证明
func (e *Lean4Engine) GenerateProof(
theoremName string,
theoremStmt string,
currentProof string,
errorMsg string,
) string {
// 这里应该调用LLM API
// 为了演示,返回一个模板
if errorMsg != "" {
// 尝试根据错误修正
if strings.Contains(errorMsg, "unknown identifier") {
return fmt.Sprintf(`theorem %s
%s
:=
begin
-- 检查标识符是否正确定义
sorry
end
`, theoremName, theoremStmt)
}
}
// 默认模板
return fmt.Sprintf(`theorem %s
%s
:=
begin
-- 请添加你的证明
sorry
end
`, theoremName, theoremStmt)
}
// ProofLoop 完整的证明循环
func (e *Lean4Engine) ProofLoop(
ctx context.Context,
theoremName string,
theoremStmt string,
maxIterations int,
) *Lean4Proof {
proof := &Lean4Proof{
TheoremName: theoremName,
TheoremStmt: theoremStmt,
ProofCode: fmt.Sprintf("theorem %s\n%s\n:= \nbegin\n sorry\nend\n", theoremName, theoremStmt),
IsComplete: false,
Iteration: 0,
}
for proof.Iteritation < maxIterations {
select {
case <-ctx.Done():
proof.LastError = "timeout"
return proof
default:
}
// 验证当前证明
result := e.Verify(proof)
if result.IsValid {
proof.IsComplete = true
return proof
}
// 修正证明
proof.ProofCode = e.GenerateProof(
theoremName,
theoremStmt,
proof.ProofCode,
result.Error,
)
proof.LastError = result.Error
proof.Iteration++
}
return proof
}
func main() {
engine := NewLean4Engine("")
ctx := context.Background()
proof := engine.ProofLoop(
ctx,
"add_zero_right",
"∀ (n : ℕ), n + 0 = n",
100,
)
fmt.Printf("定理: %s\n", proof.TheoremName)
fmt.Printf("迭代次数: %d\n", proof.Iteritation)
fmt.Printf("完成: %v\n", proof.IsComplete)
if proof.IsComplete {
fmt.Println("证明成功!")
fmt.Println(proof.ProofCode)
} else {
fmt.Printf("最后错误: %s\n", proof.LastError)
}
}
七、行业影响与未来展望
7.1 对数学研究的革命性影响
AlphaProof Nexus的成功预示着AI将成为数学家的标准研究工具:
- 加速猜想验证:快速验证或推翻数学猜想
- 发现新定理:AI可能发现人类未注意到的数学结构
- 填补证明空白:完成人类数学家未完成的证明
- 教育辅助:帮助学生学习形式化证明方法
7.2 对AI Agent技术的启示
这篇论文揭示了AI Agent设计的重要原则:
- 形式化验证 > 概率猜测:编译器反馈比人类反馈更可靠
- 简单架构 + 强模型 = 好结果:Agent A的成功说明基础模型能力是关键
- 迭代修正 > 一次性生成:多轮反馈循环比单次生成更有效
- 进化算法补充强化学习:两种方法在不同难度问题上各有优势
7.3 开源与开放
DeepMind已将所有9道问题的Lean证明代码开源在GitHub上:
- 仓库:
google-deepmind/alphaproof-nexus-results - 许可:Apache 2.0(代码)+ CC-BY 4.0(文档)
这为研究社区提供了宝贵的资源。
7.4 未来发展方向
- 更强的LLM:基础模型能力提升将直接推动证明能力
- 更大规模的测试:覆盖更多Erdős问题和其他数学领域
- 人机协作:AI辅助人类数学家进行创造性研究
- 跨领域应用:将形式化证明方法应用到计算机科学、物理学等领域
八、总结
AlphaProof Nexus是AI数学研究领域的一个里程碑。它证明了通过LLM + 形式化验证 + 迭代反馈的组合,AI可以:
- ✅ 解决困扰数学家几十年的难题
- ✅ 提供绝对正确、无幻觉的证明
- ✅ 以极低的成本(每题数百美元)完成证明
- ✅ 保持证明的完整性和可验证性
更重要的是,这项技术展示了AI Agent设计的核心原则:简单架构配合强大基础模型,加上严格的形式化验证,就能产生惊人的效果。
菲尔兹奖得主的评价"如果这篇论文由人类提交给《数学年鉴》,我会毫不犹豫地推荐录用",或许标志着AI正式成为数学研究领域不可或缺的工具。
参考来源:
- arXiv:2605.22763v1 - “Advancing Mathematics Research with AI-Driven Formal Proof Search”
- GitHub: google-deepmind/alphaproof-nexus-results
- 新智元《人类56年解不出,谷歌AI一夜连破9道世纪难题》
相关资源:
- Lean 4官网:https://leanprover.github.io/