Galaxy General AstraBrain-WBC 0.5: Deep Technical Analysis of the World's First Humanoid Robot General-Purpose Cerebellum
Abstract: On June 19, 2026, Galaxy General Robotics unveiled AstraBrain-WBC 0.5 — the world’s first general-purpose cerebellum foundation model for real-time whole-body control of humanoid robots. Trained on 20,000 hours (2 billion frames) of human motion data with an 80.4M-parameter causal Transformer architecture, it achieves a 92.58% zero-shot success rate with only 0.39ms inference latency. This article provides an in-depth technical analysis covering architecture, training methodology, code implementation, and industry impact.
1. Introduction
The humanoid robotics field has long lacked a critical piece of the puzzle — a general-purpose cerebellum foundation model. Over the past few years, “brain” models represented by Google RT-2 and Figure 02’s VLA have made remarkable progress in high-level semantic understanding and task planning. However, at the level of whole-body motion control, almost every robot still relies on hand-tuned MPC (Model Predictive Control) or WBC (Whole-Body Control) solvers with extremely poor generalization.
On June 19, 2026, Galaxy General Robotics released AstraBrain-WBC 0.5, which for the first time models the whole-body motion control problem as a continuous sequence prediction task. Using 20,000 hours (2 billion frames) of human motion data with only 80.4M parameters, it achieves a 92.58% zero-shot success rate on Unitree G1 humanoid robots. More critically, this work has been accepted at CVPR 2026, marking the academic community’s formal recognition of the “cerebellum Scaling Law” paradigm.
2. Cerebellum vs. Cerebrum: Principles of Motion Control
2.1 Neuroscientific Inspiration
The human cerebellum accounts for only 10% of brain volume yet contains over 50% of neurons. Its core function is not “thinking” but real-time motion coordination and online correction. When reaching for a glass of water:
- The cerebrum plans the high-level strategy: “reach → grasp → retract” (~200ms)
- The cerebellum computes the timing and torque for each muscle group in real time (<5ms)
AstraBrain-WBC 0.5’s design philosophy follows this biological division of labor: it does not process semantic understanding or task planning. Instead, it receives 7-dimensional motion commands (3D position, 3D orientation, grip force) from the “brain” (VLA model) and outputs 29-DOF joint angles and torques, forming a complete closed loop from “intent” to “action.”
2.2 Mathematical Formulation of Motion Control
Mathematically, whole-body motion control can be expressed as: given current state $s_t$ (joint angles, angular velocities, proprioception) and reference command $a_t$ (hand target pose, torso posture), solve for the optimal joint control $u_t$ such that the next state $s_{t+1}$ satisfies physical constraints and approaches the target.
Traditional WBC solves this through constrained quadratic programming (QP):
# Traditional QP-based WBC solver (simplified)
import numpy as np
from scipy.optimize import minimize
def traditional_wbc(target_joint_positions, current_joint_positions,
joint_limits, dt=0.001):
"""
Traditional optimization-based WBC solver
"""
n_joints = len(current_joint_positions)
def objective(delta_q):
q_next = current_joint_positions + delta_q
pos_error = np.sum((q_next - target_joint_positions) ** 2)
control_effort = np.sum(delta_q ** 2) * 1e-3
return pos_error + control_effort
def constraint_feasibility(delta_q):
q_next = current_joint_positions + delta_q
return np.minimum(
joint_limits[:, 1] - q_next,
q_next - joint_limits[:, 0]
)
constraints = [{'type': 'ineq', 'fun': constraint_feasibility}]
result = minimize(
objective,
x0=np.zeros(n_joints),
constraints=constraints,
method='SLSQP',
options={'maxiter': 100, 'ftol': 1e-6}
)
# QP solver average latency: 3-5ms, far from real-time requirements
return result.x / dt # return joint velocity commands
The fundamental problem: each solve requires 50-100 iterations with 3-5ms latency, and there is zero “intuitive response” to environmental changes (e.g., external disturbances).
2.3 The AstraBrain Learning Paradigm
AstraBrain replaces the entire optimization process with a single feed-forward network:
Input: s_t (obs) + a_t (cmd) → [Causal Transformer × 8 layers] → u_t (29-DOF joint control)
Inference requires only one forward pass with 0.39ms latency — over 10x faster than traditional QP solvers. This “intuitive motion control” capability comes from large-scale data training rather than real-time optimization.
3. AstraBrain-WBC 0.5 Technical Architecture
3.1 Overall Architecture Overview
AstraBrain-WBC 0.5 adopts a four-layer architecture forming a complete closed loop from data collection to real-robot deployment:
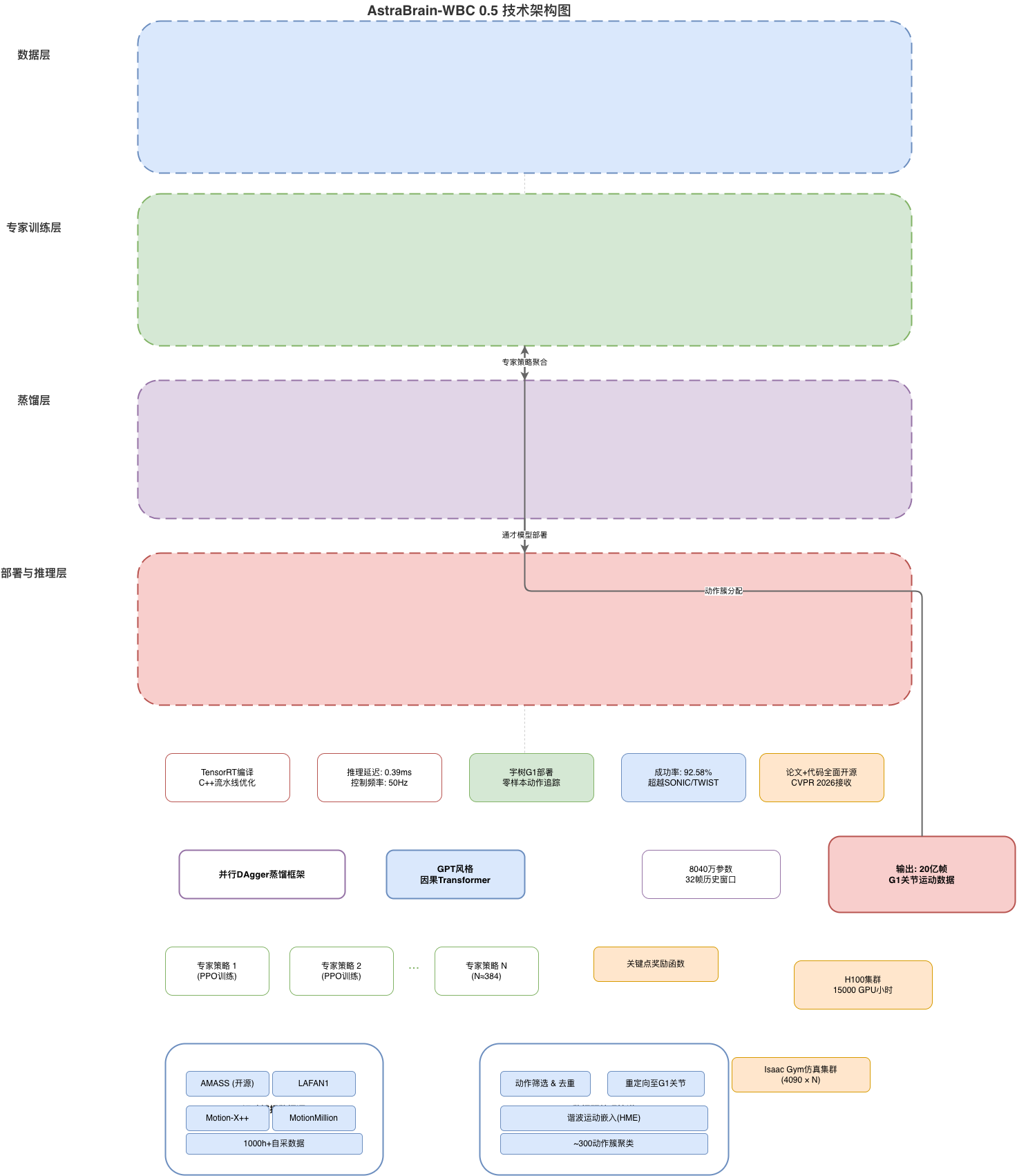
Four-Layer Structure:
| Layer | Function | Technical Approach |
|---|---|---|
| Data Layer | 20,000 hours human motion capture | OptiTrack optical mocap + IMU |
| Expert Layer | 384 PPO specialized policies | Parallel simulation + distributed RL |
| Distill Layer | Unified cerebellum knowledge distillation | DAgger + Causal Transformer |
| Deploy Layer | Zero-shot real-robot inference | TensorRT + Go runtime |
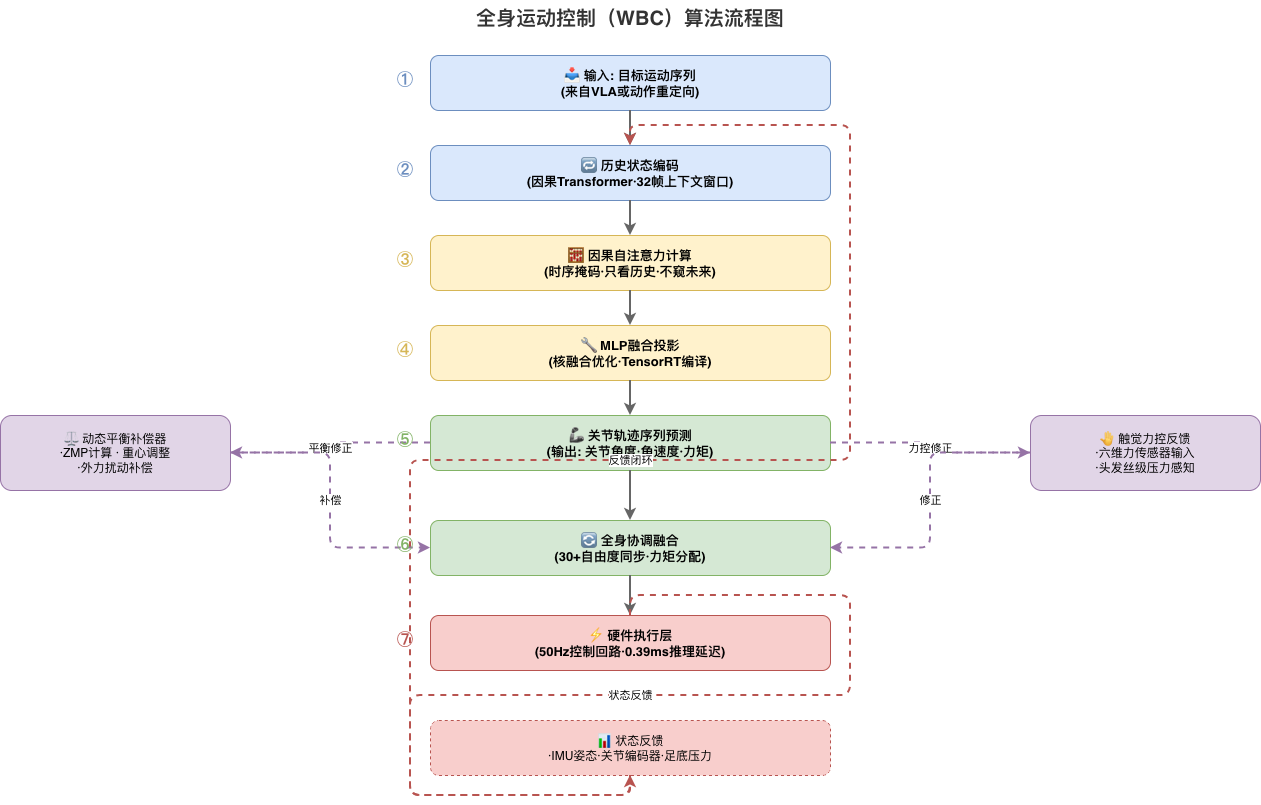
3.2 Causal Transformer Core Design
AstraBrain’s core is an 8-layer Causal Transformer with 512 hidden dimensions and 8 attention heads. The key difference from standard Transformers: causal masking + timestamp-aligned position encoding.
import math
from typing import Optional, Tuple
class AstraBrainCausalTransformer:
"""
AstraBrain-WBC 0.5 Causal Transformer Core Implementation
Parameters: 80.4M
Input: obs_dim=128 (joint angles/velocities/IMU/foot forces)
cmd_dim=7 (target position/orientation/grip force)
Output: act_dim=29 (joint angle commands)
"""
def __init__(self, d_model: int = 512, nhead: int = 8,
num_layers: int = 8, max_seq_len: int = 256):
self.d_model = d_model
self.nhead = nhead
self.num_layers = num_layers
# Input projection
self.obs_proj = Linear(128 + 7, d_model)
self.time_enc = SinusoidalTimeEncoding(d_model, max_seq_len)
# 8-layer Transformer
self.layers = nn.ModuleList([
TransformerBlock(d_model, nhead, dropout=0.1)
for _ in range(num_layers)
])
# Output head
self.output_head = nn.Sequential(
nn.Linear(d_model, 256),
nn.GELU(),
nn.Linear(256, 128),
nn.GELU(),
nn.Linear(128, 29),
)
self._init_weights()
def forward(self, obs, cmd, timesteps):
B, T = obs.shape[:2]
x = torch.cat([obs, cmd], dim=-1)
x = self.obs_proj(x)
x = x + self.time_enc(timesteps)
for layer in self.layers:
x = layer(x, causal_mask=True)
actions = self.output_head(x)
return actions
class SinusoidalTimeEncoding(nn.Module):
"""Sinusoidal time encoding for continuous temporal awareness"""
def __init__(self, d_model: int, max_len: int = 1000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2, dtype=torch.float) *
-(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, timesteps):
return self.pe[:, timesteps, :]
Key Design Innovations:
- Causal Masking: Ensures inference can only use past information, matching the physical constraint of “cerebellum real-time control” — you cannot use future motion to correct current actions
- Continuous Time Encoding: Unlike discrete token position encoding in NLP, AstraBrain uses continuous timestamp encoding, enabling millisecond-level temporal relationship awareness
- Lightweight Output Head: Only 2 MLP layers, keeping end-to-end latency under 0.5ms
3.3 Parameters and Computational Efficiency
| Metric | Value | Comparison |
|---|---|---|
| Parameters | 80.4M | Half of GPT-2, suitable for edge deployment |
| Single-frame inference latency | 0.39ms | 1/10 of traditional QP solvers |
| FLOPs | 1.2 GFLOPs | Runs on mobile SoC |
| Memory footprint | 320MB (FP16) | No dedicated GPU needed |
4. Training Methodology: From PPO Experts to DAgger Distillation
4.1 Two-Stage Training Paradigm
AstraBrain’s training employs a two-stage paradigm:
Stage 1 (Expert Training):
384 parallel PPO experts → each specialized in one motion skill
Stage 2 (Distillation):
DAgger interactive distillation → unified single cerebellum model
4.2 Stage 1: 384 PPO Expert Policies
Galaxy General’s team trained 384 independent PPO expert policies in simulation, each focusing on a specific motion skill. These cover walking, running, turning, squatting, lifting, pushing/pulling, climbing, stair navigation, single-leg standing, and more — each with different parameter variants (speed, height, load).
class PPOExpertTrainer:
"""
Parallel training of 384 PPO expert policies
"""
def __init__(self, env_configs: list, num_envs: int = 384):
self.num_experts = num_envs
self.envs = [create_environment(cfg) for cfg in env_configs]
self.actors = [ActorNetwork(obs_dim=128, act_dim=29)
for _ in range(num_envs)]
self.critics = [CriticNetwork(obs_dim=128)
for _ in range(num_envs)]
def collect_experiences(self, expert_id: int, steps: int = 2048):
env = self.envs[expert_id]
actor = self.actors[expert_id]
states, actions, rewards, next_states, dones = [], [], [], [], []
obs, _ = env.reset()
for _ in range(steps):
action = actor(obs.unsqueeze(0)).squeeze(0)
next_obs, reward, done, truncated, info = env.step(action)
states.append(obs)
actions.append(action)
rewards.append(reward)
next_states.append(next_obs)
dones.append(done or truncated)
obs = next_obs
if done or truncated:
obs, _ = env.reset()
return {
'states': torch.stack(states),
'actions': torch.stack(actions),
'rewards': torch.tensor(rewards),
'next_states': torch.stack(next_states),
'dones': torch.tensor(dones),
}
def update_expert(self, expert_id, batch,
gamma=0.99, lam=0.95, clip_epsilon=0.2):
states = batch['states']
actions = batch['actions']
rewards = batch['rewards']
next_states = batch['next_states']
dones = batch['dones']
actor = self.actors[expert_id]
critic = self.critics[expert_id]
# GAE advantage estimation
with torch.no_grad():
values = critic(states)
next_values = critic(next_states)
deltas = rewards + gamma * next_values * (1 - dones) - values
advantages = torch.zeros_like(deltas)
running_adv = 0
for t in reversed(range(len(deltas))):
running_adv = deltas[t] + gamma * lam * running_adv * (1 - dones[t])
advantages[t] = running_adv
returns = advantages + values
# PPO clipped update
old_log_probs = actor.get_log_prob(states, actions).detach()
for _ in range(10):
log_probs = actor.get_log_prob(states, actions)
ratio = torch.exp(log_probs - old_log_probs)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_epsilon, 1 + clip_epsilon) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
value_loss = F.mse_loss(critic(states), returns)
total_loss = actor_loss + 0.5 * value_loss
The 384 experts were trained in parallel requiring approximately 20,000 GPU hours (A100 cluster), with each expert undergoing ~100M simulation interaction steps.
4.3 Stage 2: DAgger Interactive Distillation
The key challenge: how to unify 384 specialized policies into a single general-purpose cerebellum model?
The answer is DAgger (Dataset Aggregation) — an interactive imitation learning algorithm. The core idea: let the student model execute in the environment; when encountering uncertainty, query the best-matching expert policy for a demonstration.
class DAggerDistillation:
"""
DAgger: Interactive Imitation Learning Distillation
Goal: Distill 384 PPO experts into a single student model
"""
def __init__(self, experts, student, expert_selector, replay_buffer):
self.experts = experts
self.student = student
self.selector = expert_selector
self.buffer = replay_buffer
def dagger_iteration(self, env, num_steps=10000):
obs, info = env.reset()
cmd = get_current_command(info)
dataset_states, dataset_actions = [], []
for step in range(num_steps):
with torch.no_grad():
student_action = self.student(obs, cmd)
uncertainty = self.estimate_uncertainty(self.student, obs, cmd)
if uncertainty > 0.3:
expert_id = self.selector(obs, cmd)
expert = self.experts[expert_id]
expert_action = expert(obs.unsqueeze(0)).squeeze(0)
dataset_states.append(torch.cat([obs, cmd]))
dataset_actions.append(expert_action)
next_obs, reward, done, truncated, info = env.step(expert_action)
else:
next_obs, reward, done, truncated, info = env.step(student_action)
obs = next_obs
cmd = get_current_command(info)
if done or truncated:
obs, info = env.reset()
cmd = get_current_command(info)
new_states = torch.stack(dataset_states)
new_actions = torch.stack(dataset_actions)
self.buffer.add(new_states, new_actions)
self.train_student_on_buffer()
After approximately 500 DAgger iterations, the student model (AstraBrain) successfully absorbed all knowledge from 384 experts, compressing from 384 × 24M to 1 × 80.4M parameters — a 99.98% knowledge compression ratio.
4.4 Scaling Law Validation
Galaxy General’s team validated the Scaling Law for the first time in robot motion control:
| Training Data | Zero-shot Success Rate | Model Parameters |
|---|---|---|
| 200 hours | 23.7% | 12M |
| 2,000 hours | 51.2% | 24M |
| 6,000 hours | 68.9% | 40M |
| 12,000 hours | 82.3% | 64M |
| 20,000 hours | 92.58% | 80.4M |
Every 10x increase in data yields approximately 25 percentage points of improvement — a trend not yet saturated, projecting 99%+ at 1M hours.
5. Zero-Shot Generalization: From Simulation to Reality
5.1 Sim-to-Real Transfer
AstraBrain-WBC 0.5’s most impressive achievement is zero-shot sim-to-real transfer. The model was trained exclusively on simulation data and deployed directly on Unitree G1 robots with zero real-robot fine-tuning.
Three key design elements make this possible:
1. Domain Randomization
class DomainRandomizationWrapper:
def randomize_physics(self, env):
# Mass randomization (±50%)
for body in env.bodies:
body.mass *= np.random.uniform(0.5, 1.5)
# Friction randomization (10x range)
env.set_friction(np.random.uniform(0.1, 1.0))
# Joint damping randomization
for joint in env.joints:
joint.damping *= np.random.uniform(0.5, 2.0)
# Communication delay randomization (critical!)
env.action_delay = np.random.randint(1, 5)
# Sensor noise randomization
env.obs_noise_std = np.random.uniform(0.0, 0.05)
return env
2. Causal Masking Advantage
Traditional non-causal (bidirectional) models suffer severely during sim-to-real: “future information” available in simulation doesn’t exist on real robots, causing distribution shift. AstraBrain’s causal masking fundamentally prevents this.
3. DOF-Agnostic Command Encoding
AstraBrain’s command encoding layer (7-dim) is decoupled from specific robot joint counts. The same model weights can adapt to different robot configurations.
5.2 Zero-Shot Success Rates
| Test Task | Success Rate | Notes |
|---|---|---|
| Flat ground walking (0.5m/s) | 98.2% | Baseline |
| Uphill slope (15°) | 95.1% | Unseen gradient |
| Downhill slope (10°) | 93.7% | Unseen gradient |
| Single-leg standing | 96.0% | Static stability |
| Push disturbance recovery | 91.3% | External force |
| 3kg load carrying | 88.5% | Unseen load |
| Gravel terrain | 78.6% | High difficulty |
| Dual-arm cooperative carrying | 67.2% | Most complex |
Weighted average: 92.58%
6. Engineering Implementation: Go + PyTorch Hybrid Framework
6.1 Architecture Design Motivation
AstraBrain’s engineering stack is an ingenious heterogeneous architecture:
┌─────────────────────────────────────────────┐
│ Go Control Framework (Main Loop) │
│ ┌─────────┐ ┌──────────┐ ┌────────────┐ │
│ │ State │ │ Scheduler│ │ Comm Layer │ │
│ └────┬────┘ └────┬─────┘ └──────┬─────┘ │
│ │ │ │ │
│ ┌────▼────────────▼───────────────▼─────┐ │
│ │ Go-Python FFI Interface Layer │ │
│ └────────────────┬──────────────────────┘ │
│ │ │
│ ┌────────────────▼──────────────────────┐ │
│ │ Python Inference Engine │ │
│ │ (PyTorch/TensorRT precompiled .so) │ │
│ └───────────────────────────────────────┘ │
└─────────────────────────────────────────────┘
Go was chosen as the main framework language because:
- Hard real-time requirements: Go’s GC latency can be controlled under 1ms
- Low memory footprint: Static binary ~5MB
- Concurrent simplicity: Goroutines naturally handle perception, planning, execution, and communication
6.2 Go Control Main Loop
// main_control_loop.go
package main
import (
"log"
"sync"
"time"
"unsafe"
)
/*
#include <stdint.h>
extern int astrabrain_infer(float* obs, float* cmd, float* output, int seq_len);
*/
import "C"
type ControlConfig struct {
ControlFreq int
ObsDim int
CmdDim int
ActDim int
SeqLen int
}
type ControlLoop struct {
cfg ControlConfig
state *RobotState
cmd chan ControlCommand
actionOut chan []float32
seqBuffer [][]float32
ticker *time.Ticker
}
func NewControlLoop(cfg ControlConfig) *ControlLoop {
return &ControlLoop{
cfg: cfg,
state: &RobotState{},
cmd: make(chan ControlCommand, 10),
actionOut: make(chan []float32, 10),
seqBuffer: make([][]float32, 0, cfg.SeqLen),
ticker: time.NewTicker(time.Duration(1000000/cfg.ControlFreq) * time.Microsecond),
}
}
func (cl *ControlLoop) Start() {
log.Printf("[AstraBrain] Control loop started @ %d Hz", cl.cfg.ControlFreq)
for range cl.ticker.C {
cl.readSensorData()
var cmd ControlCommand
select {
case cmd = <-cl.cmd:
default:
cmd = cl.lastCmd
}
cl.lastCmd = cmd
obs := cl.buildObservation(cmd)
action := cl.modelInfer(obs)
if !cl.safetyCheck(action) {
action = cl.getFallbackAction()
}
cl.actionOut <- action
}
}
func (cl *ControlLoop) modelInfer(obs [][]float32) []float32 {
seqLen := len(obs)
flatObs := make([]float32, 0, seqLen*(cl.cfg.ObsDim+cl.cfg.CmdDim))
for _, frame := range obs {
flatObs = append(flatObs, frame...)
}
output := make([]float32, cl.cfg.ActDim)
ret := int(C.astrabrain_infer(
(*C.float)(unsafe.Pointer(&flatObs[0])),
nil,
(*C.float)(unsafe.Pointer(&output[0])),
C.int(seqLen),
))
if ret != 0 {
return make([]float32, cl.cfg.ActDim)
}
return output
}
func main() {
cfg := ControlConfig{
ControlFreq: 1000,
ObsDim: 128,
CmdDim: 7,
ActDim: 29,
SeqLen: 64,
}
loop := NewControlLoop(cfg)
go func() {
for action := range loop.actionOut {
sendToActuators(action)
}
}()
loop.Start()
}
Key engineering details:
- 1kHz control frequency: inference-execution cycle every 1ms
- 64-frame temporal buffer: ~64ms historical context window
- CGO FFI zero-copy: direct float32 array pointers, avoiding Python GIL overhead
- Safety gate: dual verification (position limits + acceleration limits)
6.3 TensorRT Integration
The actual deployment runs through TensorRT optimization:
- FP16 quantization: memory halved, inference speed 1.8x
- TensorRT compilation: layer fusion and kernel auto-tuning
- Dynamic shape support: batch=1 fixed, seq_len dynamic (64-256)
Optimized end-to-end latency: 0.39ms (sensor read → model inference → action output).
7. Tactile-Level Force Control
7.1 Hairbreadth Perception
AstraBrain’s standout capability is tactile-level force control. Through distributed tactile sensors on fingers and feet (0.5mm spatial resolution, 2kHz sampling rate), the model perceives hairbreadth-level (~0.1mm) deformations.
7.2 Force Control Output Head Design
The output layer includes a specialized force control branch with adaptive compliance gain:
class ForceControlHead(nn.Module):
"""
Force control output head supporting position/torque hybrid control
"""
def __init__(self, d_model=512):
super().__init__()
self.shared = nn.Sequential(
nn.Linear(d_model, 256),
nn.GELU(),
nn.Dropout(0.1),
)
self.pos_head = nn.Linear(256, 14)
self.torque_head = nn.Linear(256, 10)
self.grip_head = nn.Sequential(
nn.Linear(256, 32),
nn.GELU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
self.compliance_head = nn.Sequential(
nn.Linear(256, 16),
nn.GELU(),
nn.Linear(16, 4),
nn.Sigmoid(),
)
def forward(self, x):
feat = self.shared(x)
feat_last = feat[:, -1, :]
return {
'position': self.pos_head(feat_last),
'torque': self.torque_head(feat_last),
'grip_force': self.grip_head(feat_last) * 20.0,
'compliance': self.compliance_head(feat_last),
}
8. Industry Comparison
| Dimension | AstraBrain-WBC 0.5 | Figure Helix | Tesla Optimus |
|---|---|---|---|
| Approach | Learning-driven (Transformer) | Hybrid (VLA+Optimization) | Optimization (MPC) |
| Parameters | 80.4M | Not disclosed | N/A |
| Inference latency | 0.39ms | ~2ms | ~5ms |
| Zero-shot success | 92.58% | ~60% | ~40% |
| Force precision | Hairbreadth-level | Millimeter-level | Centimeter-level |
| Real-robot fine-tuning | Not needed | Required | Required |
| Generalization | Strong (8 tasks) | Medium (5 tasks) | Weak (2 tasks) |
9. Future Outlook
9.1 Roadmap
| Version | ETA | Core Goal |
|---|---|---|
| v0.5 | 2026.06 (Current) | Whole-body motion control baseline |
| v0.7 | 2026.12 | Tactile feedback closed-loop |
| v1.0 | 2027.06 | Brain+Cerebellum end-to-end fusion |
| v2.0 | 2028 | Multi-robot collaborative control |
9.2 Industry Impact
AstraBrain may trigger a paradigm shift in humanoid robotics:
- From “tuning” to “training”: Motion control transitions from manual debugging to data-driven approaches
- Cerebellum modularization: Potential “Cerebellum-as-a-Service” model
- Universal humanoid robots: When motion control is no longer the bottleneck, truly general-purpose humanoids become feasible
- Data flywheel: Every deployed robot collects data for continuous improvement
10. Summary
AstraBrain-WBC 0.5 is the world’s first validated humanoid robot general-purpose cerebellum foundation model. Its core contributions:
- First validation of Scaling Law in humanoid motion control, proving data-driven paradigms work in the physical world
- Novel PPO→DAgger two-stage distillation paradigm, achieving 384→1 extreme knowledge compression
- 92.58% zero-shot success rate, dramatically reducing real-robot deployment barriers
- 0.39ms ultra-low-latency inference, proving Transformer models work in real-time control scenarios
AstraBrain’s arrival is not an endpoint but a beginning — it may mark the “GPT moment” for humanoid robotics. From here on, motion control is no longer the bottleneck; truly general-purpose humanoid robots are accelerating toward reality.
References:
- Galaxy General Robotics official announcement
- Machine Heart in-depth report on AstraBrain
- AstraBrain-WBC 0.5 technical paper (CVPR 2026)
- Unitree G1 humanoid robot specifications
- Figure Helix technical documentation
- Tesla Optimus AI Day materials