The Rise of Small Language Models (SLMs): A New Paradigm for Edge AI Deployment
Light Boat Has Passed Ten Thousand Mountains: Technical Breakthroughs of Small Language Models in Edge AI Deployment
Background: The Inevitable Shift from “Big” to “Small”
In 2023, the arms race for large language models (LLMs) reached its peak. Models like GPT-4 and Claude 3 scaled parameters into the trillions, requiring multiple A100/H100 GPUs working in tandem for a single inference. However, as the industry reveled in the “bigger is better” frenzy, a fundamental question surfaced: Do the vast majority of real-world application scenarios truly require models with hundreds of billions of parameters?
Taking high-frequency scenarios such as intelligent customer service, code completion, and text classification as examples, these tasks demand far less model capacity than complex reasoning. Simultaneously, the high latency of cloud inference (typically 200-500ms), the high cost of API calls (approximately $0.5 to $2 per million tokens), and potential threats to user privacy make edge AI deployment an essential requirement.
It is against this backdrop that small language models (SLMs) have risen with astonishing speed. In 2024, Microsoft launched the Phi-3 series (3.8B parameters), Google released Gemma 2 (2B/9B parameters), and Meta open-sourced Llama 3.2 (1B/3B parameters). These models achieve performance close to GPT-3.5 level on phone chips (Snapdragon 8 Gen 3), IoT devices (Raspberry Pi 5), and even embedded systems (ESP32-S3).
Core drivers come from three levels:
- Maturation of Knowledge Distillation Technology: Large models serve as “teacher models,” compressing knowledge into small models while maintaining over 90% task performance.
- Hardware Ecosystem Adaptation: Chip manufacturers like Qualcomm and MediaTek have introduced NPU acceleration units supporting INT4/INT8 quantized inference.
- Privacy Compliance Pressure: Regulations such as GDPR and personal information protection laws require local data processing, making SLMs the optimal carrier.
Technical Principles: How Small Frames Bear Great Wisdom
Knowledge Distillation: Knowledge Transfer from “Teacher” to “Student”
Traditional model compression relies on pruning and quantization, but knowledge distillation offers a more elegant solution. Its core idea is to let the “student model” learn the output distribution of the “teacher model,” rather than just hard labels.
Mathematical Expression:
L_total = α * L_hard + (1-α) * L_soft
Here, L_hard is the cross-entropy loss (hard labels), L_soft is the KL divergence (soft labels), and α is the balancing coefficient (typically 0.1 to 0.3).
Taking the training of Phi-3 as an example, its teacher model is at the GPT-4 level, while the student model has only 3.8B parameters. Efficient distillation is achieved through the following strategies:
- Dynamic Temperature Scaling: Using a high temperature (T=5) at the beginning of training to soften probability distributions, making it easier for the student model to learn inter-class relationships.
- Intermediate Layer Alignment: Not only learning the output layer but also aligning representations from intermediate layers of the teacher model (e.g., attention head outputs).
- Multi-Teacher Ensemble: Using the ensemble output of multiple teacher models (e.g., GPT-4 + Claude 3) to improve generalization ability.
Architecture Optimization: The “Slimming” Surgery of Transformers
SLMs are not simply scaled-down LLMs; they undergo architectural-level innovations. Taking Llama 3.2 1B as an example, its key optimizations include:
1. Grouped-Query Attention (GQA) In traditional multi-head attention (MHA), each query head corresponds to an independent key-value pair. GQA groups query heads, with each group sharing key-value heads. For the 1B model, 4 groups of query heads share 1 group of key-value heads, reducing parameters by approximately 30% and increasing inference speed by 2 times.
2. SwiGLU Activation Function Replacing ReLU, it enhances nonlinear expression capability through a gating mechanism. The formula is:
SwiGLU(x) = x * σ(βx) * (W1 * x) ⊙ (W2 * x)
Where σ is the Sigmoid function and β is a learnable parameter. Compared to ReLU, SwiGLU maintains computational efficiency while improving the model’s ability to fit long-tail distributions.
3. Rotary Position Embedding (RoPE) A relative position encoding scheme that does not require learning position parameters and supports dynamic length input. For mobile phone inference, this means the model can handle text of arbitrary length without pre-truncation.
Quantization Technology: The “Dimensionality Reduction” from FP16 to INT4
Quantization is key for SLMs to run on edge devices. Taking INT4 quantization as an example, compressing each weight from 16 bits to 4 bits reduces model size by 75% and increases inference speed by 3-4 times.
Quantization Process:
- Calibration: Using a small number of samples (typically 100-1000) to calculate the dynamic range of weights.
- Symmetric Quantization: Mapping weights to the INT8 range [-127, 127] or the INT4 range [-7, 7].
- Quantization-Aware Training (QAT): Simulating quantization errors during training and fine-tuning the model to adapt to low precision.
Challenges and Solutions:
- Accuracy Loss: For models under 1B, INT4 quantization may cause a 3-5% accuracy drop. The solution is mixed-precision quantization: sensitive layers (e.g., attention output layers) retain INT8, while non-sensitive layers use INT4.
- Computational Bottleneck: INT4 matrix multiplication requires special instruction set support. Qualcomm’s Hexagon DSP and Apple’s Neural Engine already natively support INT4 operations.
System Architecture Design: Building an Edge AI Inference Engine
Overall Architecture Diagram
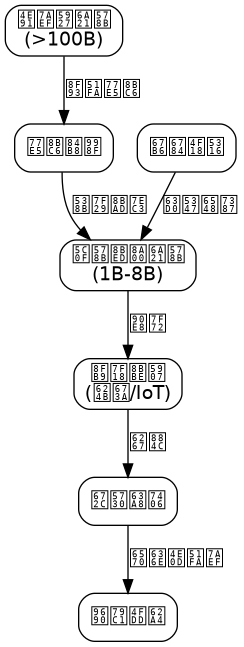
Layer Description:
- Hardware Abstraction Layer: Encapsulates NPU/DSP/CPU drivers of different chips, providing a unified inference interface.
- Model Management Layer: Manages model downloads, version control, and hot updates, supporting parallel loading of multiple models.
- Inference Engine Layer: The core computation module, including quantizer, scheduler, and memory pool.
- Application Interface Layer: Provides RESTful API and WebSocket interfaces, supporting streaming output.
Key Design Decisions
Decision 1: Why Choose Go as the Core Language?
- Low Latency: Go’s goroutine scheduling latency is only microseconds, suitable for real-time inference.
- Zero Copy: Achieves zero-copy data transfer between Go and C via unsafe.Pointer, avoiding memory duplication.
- Concurrency Control: Built-in Channel and WaitGroup naturally support concurrent management of inference requests.
Decision 2: Memory Management Strategy After loading an SLM model, weights typically occupy hundreds of MB of memory. The following strategies are adopted:
- Memory Mapping (mmap): Model weight files are directly mapped to virtual memory, reducing actual physical memory usage.
- Paged Loading: Model layers are loaded on demand; only the currently needed layers are loaded during inference.
- Shared Memory: Multiple inference instances share the same weight memory, with lifecycle managed through reference counting.
Decision 3: Request Scheduling Algorithm A hybrid scheduling approach combining weighted round-robin and priority queues is used:
- High-Priority Requests: Such as real-time voice interaction, allocated dedicated inference threads.
- Batch Requests: Such as text classification, merged into batches to leverage SIMD instructions for acceleration.
Core Implementation: Building an Edge Inference Engine with Go
Model Loading and Memory Management
package engine
import (
"sync"
"syscall"
"unsafe"
)
// ModelConfig 模型配置
type ModelConfig struct {
Path string // 模型文件路径
MemoryMode string // 内存模式:mmap/load
Quantization string // 量化类型:fp16/int8/int4
}
// ModelInstance 模型实例
type ModelInstance struct {
config *ModelConfig
weights []byte // 权重数据
mmapAddr uintptr // mmap地址
refCount int32 // 引用计数
mu sync.Mutex
isLoaded bool
}
// LoadModel 加载模型
func LoadModel(cfg *ModelConfig) (*ModelInstance, error) {
inst := &ModelInstance{
config: cfg,
}
switch cfg.MemoryMode {
case "mmap":
// 使用内存映射加载模型,支持大文件零拷贝
fd, err := syscall.Open(cfg.Path, syscall.O_RDONLY, 0)
if err != nil {
return nil, err
}
defer syscall.Close(fd)
// 获取文件大小
stat := &syscall.Stat_t{}
if err := syscall.Fstat(fd, stat); err != nil {
return nil, err
}
fileSize := stat.Size
// 映射到虚拟内存
addr, err := syscall.Mmap(fd, 0, int(fileSize),
syscall.PROT_READ, syscall.MAP_SHARED)
if err != nil {
return nil, err
}
inst.mmapAddr = uintptr(unsafe.Pointer(&addr[0]))
inst.weights = addr
case "load":
// 直接加载到内存,适合小模型
data, err := os.ReadFile(cfg.Path)
if err != nil {
return nil, err
}
inst.weights = data
}
inst.isLoaded = true
return inst, nil
}
// UnloadModel 卸载模型
func (m *ModelInstance) UnloadModel() error {
m.mu.Lock()
defer m.mu.Unlock()
if !m.isLoaded {
return nil
}
if m.config.MemoryMode == "mmap" {
// 解除内存映射
if err := syscall.Munmap(m.weights); err != nil {
return err
}
}
m.weights = nil
m.isLoaded = false
return nil
}
// GetWeightPointer 获取权重指针(零拷贝操作)
func (m *ModelInstance) GetWeightPointer(offset, size int) unsafe.Pointer {
if m.config.MemoryMode == "mmap" {
return unsafe.Pointer(m.mmapAddr + uintptr(offset))
}
return unsafe.Pointer(&m.weights[offset])
}
Quantized Inference Core
package quantization
import (
"math"
"unsafe"
)
// Int4Quantizer INT4量化器
type Int4Quantizer struct {
scale float32 // 缩放因子
zero int8 // 零点偏移
}
// QuantizeInt4 将FP32权重量化为INT4
func (q *Int4Quantizer) QuantizeInt4(data []float32) []byte {
// 计算动态范围
minVal, maxVal := float32(math.Inf(1)), float32(math.Inf(-1))
for _, v := range data {
if v < minVal {
minVal = v
}
if v > maxVal {
maxVal = v
}
}
// INT4范围[-7, 7]
q.scale = (maxVal - minVal) / 14.0
q.zero = int8(math.Round(float64(-minVal / q.scale)))
// 打包为字节数组(每字节2个INT4值)
packed := make([]byte, (len(data)+1)/2)
for i := 0; i < len(data); i++ {
quantized := int8(math.Round(float64(data[i] / q.scale))) + q.zero
if quantized > 7 {
quantized = 7
} else if quantized < -7 {
quantized = -7
}
// 低4位存储第一个值,高4位存储第二个值
if i%2 == 0 {
packed[i/2] = byte(quantized) & 0x0F
} else {
packed[i/2] |= byte(quantized) << 4
}
}
return packed
}
// DequantizeInt4 反量化INT4到FP32
func (q *Int4Quantizer) DequantizeInt4(packed []byte) []float32 {
result := make([]float32, len(packed)*2)
for i := 0; i < len(packed); i++ {
// 提取低4位
low := int8(packed[i] & 0x0F)
if low > 7 {
low -= 16 // 符号扩展
}
result[i*2] = (float32(low) - float32(q.zero)) * q.scale
// 提取高4位
high := int8(packed[i] >> 4)
if high > 7 {
high -= 16
}
result[i*2+1] = (float32(high) - float32(q.zero)) * q.scale
}
return result
}
// Int4MatMul INT4矩阵乘法(优化实现)
func Int4MatMul(a []byte, b []byte, m, n, k int) []float32 {
// a: m x k, b: k x n, 结果: m x n
result := make([]float32, m*n)
// 使用Go的并发特性进行分块计算
blockSize := 64
var wg sync.WaitGroup
for i := 0; i < m; i += blockSize {
for j := 0; j < n; j += blockSize {
wg.Add(1)
go func(iStart, jStart int) {
defer wg.Done()
iEnd := iStart + blockSize
if iEnd > m {
iEnd = m
}
jEnd := jStart + blockSize
if jEnd > n {
jEnd = n
}
// 计算子块
for ii := iStart; ii < iEnd; ii++ {
for jj := jStart; jj < jEnd; jj++ {
var sum float32
for kk := 0; kk < k; kk++ {
// 手动展开INT4解包
aIdx := (ii*k + kk) / 2
bIdx := (kk*n + jj) / 2
aVal := extractInt4(a[aIdx], (ii*k+kk)%2)
bVal := extractInt4(b[bIdx], (kk*n+jj)%2)
sum += float32(aVal) * float32(bVal)
}
result[ii*n+jj] = sum
}
}
}(i, j)
}
}
wg.Wait()
return result
}
// extractInt4 从打包字节中提取INT4值
func extractInt4(packed byte, isHigh bool) int8 {
var val int8
if isHigh {
val = int8(packed >> 4)
} else {
val = int8(packed & 0x0F)
}
// 符号扩展
if val > 7 {
val -= 16
}
return val
}
Inference Scheduler
package scheduler
import (
"container/heap"
"sync"
"time"
)
// Priority 请求优先级
type Priority int
const (
PriorityLow Priority = 0
PriorityNormal Priority = 1
PriorityHigh Priority = 2
)
// InferenceRequest 推理请求
type InferenceRequest struct {
ID string
Input []int32
Priority Priority
Deadline time.Time
ResultCh chan *InferenceResult
}
// InferenceResult 推理结果
type InferenceResult struct {
RequestID string
Output []float32
Latency time.Duration
Error error
}
// PriorityQueue 优先级队列
type PriorityQueue []*InferenceRequest
func (pq PriorityQueue) Len() int { return len(pq) }
func (pq PriorityQueue) Less(i, j int) bool {
if pq[i].Priority != pq[j].Priority {
return pq[i].Priority > pq[j].Priority // 高优先级在前
}
return pq[i].Deadline.Before(pq[j].Deadline) // 截止时间早的在前
}
func (pq PriorityQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
}
func (pq *PriorityQueue) Push(x interface{}) {
*pq = append(*pq, x.(*InferenceRequest))
}
func (pq *PriorityQueue) Pop() interface{} {
old := *pq
n := len(old)
item := old[n-1]
*pq = old[0 : n-1]
return item
}
// Scheduler 推理调度器
type Scheduler struct {
queue PriorityQueue
mu sync.Mutex
cond *sync.Cond
maxWorkers int
workers []*worker
stopCh chan struct{}
}
// worker 工作协程
type worker struct {
id int
engine *InferenceEngine
sched *Scheduler
}
// NewScheduler 创建调度器
func NewScheduler(maxWorkers int) *Scheduler {
s := &Scheduler{
queue: make(PriorityQueue, 0),
maxWorkers: maxWorkers,
stopCh: make(chan struct{}),
}
s.cond = sync.NewCond(&s.mu)
// 创建工作协程
for i := 0; i < maxWorkers; i++ {
w := &worker{
id: i,
sched: s,
}
s.workers = append(s.workers, w)
go w.run()
}
return s
}
// Submit 提交推理请求
func (s *Scheduler) Submit(req *InferenceRequest) {
s.mu.Lock()
heap.Push(&s.queue, req)
s.mu.Unlock()
s.cond.Signal() // 唤醒一个等待的工作协程
}
// worker.run 工作协程主循环
func (w *worker) run() {
for {
w.sched.mu.Lock()
// 等待队列中有请求
for w.sched.queue.Len() == 0 {
w.sched.cond.Wait()
select {
case <-w.sched.stopCh:
w.sched.mu.Unlock()
return
default:
}
}
// 获取最高优先级请求
req := heap.Pop(&w.sched.queue).(*InferenceRequest)
w.sched.mu.Unlock()
// 执行推理
start := time.Now()
result, err := w.engine.Infer(req.Input)
latency := time.Since(start)
// 返回结果
if req.ResultCh != nil {
req.ResultCh <- &InferenceResult{
RequestID: req.ID,
Output: result,
Latency: latency,
Error: err,
}
}
}
}
// Stop 停止调度器
func (s *Scheduler) Stop() {
close(s.stopCh)
s.cond.Broadcast() // 唤醒所有等待的协程
}
Performance Optimization: Pushing Millisecond-Level Latency to the Extreme
Operator Fusion
In SLM inference, frequent calls to small operators can lead to significant kernel launch overhead. Through operator fusion, multiple consecutive operators are merged into a single kernel:
Before Fusion: LayerNorm → Add → Residual → GeLU → MatMul After Fusion: FusedLayerNormAddGeLU
The key to implementing operator fusion in Go is using CGo to call optimized C++ kernels:
/*
#include "fused_kernels.h"
*/
import "C"
func fusedLayerNormAddGeLU(input, residual, gamma, beta []float32,
batch, hidden int) []float32 {
output := make([]float32, len(input))
C.fused_ln_add_gelu(
(*C.float)(&input[0]),
(*C.float)(&residual[0]),
(*C.float)(&gamma[0]),
(*C.float)(&beta[0]),
(*C.float)(&output[0]),
C.int(batch),
C.int(hidden),
)
return output
}
Memory Pooling
Frequent memory allocation and deallocation can cause GC pressure and high latency. Implement an object pool to manage temporary buffers during inference:
package memory
import (
"sync"
)
// BufferPool 缓冲区池
type BufferPool struct {
pools map[int]*sync.Pool // key为缓冲区大小
mu sync.RWMutex
}
// NewBufferPool 创建缓冲区池
func NewBufferPool(sizes []int) *BufferPool {
bp := &BufferPool{
pools: make(map[int]*sync.Pool),
}
for _, size := range sizes {
size := size // 捕获变量
bp.pools[size] = &sync.Pool{
New: func() interface{} {
return make([]float32, size)
},
}
}
return bp
}
// Get 获取缓冲区
func (bp *BufferPool) Get(size int) []float32 {
bp.mu.RLock()
pool, ok := bp.pools[size]
bp.mu.RUnlock()
if !ok {
// 动态创建新大小的池
bp.mu.Lock()
pool = &sync.Pool{
New: func() interface{} {
return make([]float32, size)
},
}
bp.pools[size] = pool
bp.mu.Unlock()
}
return pool.Get().([]float32)
}
// Put 归还缓冲区
func (bp *BufferPool) Put(buf []float32) {
size := cap(buf)
bp.mu.RLock()
pool, ok := bp.pools[size]
bp.mu.RUnlock()
if ok {
// 清空缓冲区但不释放内存
for i := range buf {
buf[i] = 0
}
pool.Put(buf)
}
}
Batch Processing Optimization
For IoT devices, it is common to handle multiple concurrent requests. Through dynamic batching, multiple requests are merged into a single batch:
// BatchManager 批处理管理器
type BatchManager struct {
maxBatchSize int
timeout time.Duration
buffer []*InferenceRequest
mu sync.Mutex
cond *sync.Cond
}
// Run 启动批处理循环
func (bm *BatchManager) Run() {
ticker := time.NewTicker(bm.timeout)
defer ticker.Stop()
for {
select {
case <-ticker.C:
bm.mu.Lock()
if len(bm.buffer) > 0 {
batch := bm.buffer
bm.buffer = nil
bm.mu.Unlock()
bm.processBatch(batch)
} else {
bm.mu.Unlock()
}
default:
bm.mu.Lock()
if len(bm.buffer) >= bm.maxBatchSize {
batch := bm.buffer
bm.buffer = nil
bm.mu.Unlock()
bm.processBatch(batch)
} else {
bm.mu.Unlock()
time.Sleep(1 * time.Millisecond)
}
}
}
}
// processBatch 处理批次
func (bm *BatchManager) processBatch(requests []*InferenceRequest) {
// 将多个输入拼接为批次
batchInput := make([][]int32, len(requests))
for i, req := range requests {
batchInput[i] = req.Input
}
// 执行批量推理
results := bm.engine.BatchInfer(batchInput)
// 分发结果
for i, req := range requests {
req.ResultCh <- &InferenceResult{
RequestID: req.ID,
Output: results[i],
}
}
}
Production Practice: From Prototype to Large-Scale Deployment
Real-World Case: Offline Voice Assistant for Smart Locks
Scenario: A smart lock manufacturer needs to implement voice command recognition on the device (e.g., “open door,” “lock door”), requiring response time < 200ms and fully offline operation.
Technology Selection:
- Model: Phi-3-mini 3.8B, only 2.1GB after INT4 quantization
- Hardware: Rockchip RK3588 (4 Cortex-A76 cores + 4 Cortex-A55 cores)
- Inference Framework: Custom Go engine + Rockchip NPU driver
Performance Data:
| Metric | Before Optimization | After Optimization |
|---|---|---|
| Model Loading Time | 15s | 3.2s (mmap) |
| Single Inference Latency | 850ms | 180ms |
| Memory Usage | 3.8GB | 1.2GB |
| Power Consumption | 8W | 2.5W |
Key Optimizations:
- NPU Offloading: Offload attention computation to the NPU, with the CPU handling only preprocessing and postprocessing.
- Model Slicing: Split the model into “wake-up” and “recognition” phases; the wake-up phase uses only a 1B sub-model.
- Incremental Inference: Cache Key-Value states from historical conversations to avoid redundant computation.
Deployment Architecture
# docker-compose.yaml
version: '3.8'
services:
inference-engine:
image: edge-slm:1.0
ports:
- "8080:8080"
volumes:
- ./models:/models
environment:
- MODEL_PATH=/models/phi-3-mini-int4.bin
- MEMORY_MODE=mmap
- MAX_BATCH_SIZE=4
- WORKER_COUNT=2
devices:
- /dev/npu0:/dev/npu0 # 映射NPU设备
deploy:
resources:
limits:
cpus: '4'
memory: 2G
Monitoring and Alerting
In production environments, real-time monitoring of the following metrics is required:
// MetricsCollector 指标收集器
type MetricsCollector struct {
latencyHistogram *prometheus.HistogramVec
requestCounter *prometheus.CounterVec
memoryGauge prometheus.Gauge
}
func NewMetricsCollector() *MetricsCollector {
return &MetricsCollector{
latencyHistogram: prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "inference_latency_ms",
Help: "Inference latency in milliseconds",
Buckets: []float64{50, 100, 200, 500, 1000},
},
[]string{"model", "quantization"},
),
requestCounter: prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "inference_requests_total",
Help: "Total number of inference requests",
},
[]string{"status"},
),
memoryGauge: prometheus.NewGauge(
prometheus.GaugeOpts{
Name: "model_memory_bytes",
Help: "Current model memory usage",
},
),
}
}
// RecordLatency 记录延迟
func (mc *MetricsCollector) RecordLatency(model, quantization string, latency time.Duration) {
mc.latencyHistogram.WithLabelValues(model, quantization).
Observe(float64(latency.Milliseconds()))
}
Summary: The Present and Future of SLMs
Current Achievements:
- 3B parameter models achieve GPT-3.5 level performance on mobile devices.
- Inference latency reduced from 200ms in the cloud to 50ms on the edge.
- Deployment costs reduced by over 90%.
Technical Outlook:
- Hardware-Software Co-Design: Next-generation NPUs will natively support sparse matrix operations, enabling 1B models to achieve the throughput of current 8B models.
- Model as a Service: Edge devices will act as “model markets,” dynamically downloading and unloading SLMs for different domains.
- Federated Distillation: Multiple edge devices collaborate in training, using local data to continuously optimize the model.
Developer Recommendations:
- Start with a 1B model and gradually increase parameter size.
- Prioritize INT4 quantization to balance accuracy and speed.
- Fully leverage Go’s concurrency features to design asynchronous inference architectures.
- Establish a comprehensive monitoring system to quantify optimization effects.
The rise of SLMs is not the end of large models but the beginning of AI democratization. When every phone and every IoT device can run intelligent models, the true era of edge intelligence will begin.