OpenAI Robotics: The Next Frontier in Artificial Intelligence
Table of Contents
- Executive Summary
- Introduction: OpenAI’s Bold Move into Robotics
- The Vision: Personal Robots for Everyone
- Leadership and Research Foundation
- Technical Architecture
- Core Technologies
- Short-term vs. Long-term Goals
- Career Opportunities
- Industry Impact
- Code Examples and Implementation
- Future Roadmap
- Conclusion
1. Executive Summary
On June 1, 2026, OpenAI CEO Sam Altman announced a significant strategic expansion: OpenAI Robotics. This initiative marks OpenAI’s official entry into the physical robotics domain, combining their world-leading AI capabilities with hardware systems. The company is actively recruiting engineers across multiple disciplines, with salaries ranging from $210,000 to $310,000 plus equity. This move signals a paradigm shift in how artificial intelligence will integrate with physical world applications.
2. Introduction: OpenAI’s Bold Move into Robotics
For years, OpenAI has been predominantly a software company, focusing on large language models (LLMs), vision models, and the revolutionary GPT series. However, the announcement on June 1, 2026, marks a pivotal moment—the company is officially venturing into robotics.
2.1 The Evolution of OpenAI
OpenAI was founded in 2015 with a mission to ensure that artificial general intelligence (AGI) benefits humanity. Over the past decade, they have:
- Developed GPT-4, one of the most advanced language models
- Created DALL-E for image generation
- Built the Sora video generation model
- Pioneered research in reinforcement learning from human feedback (RLHF)
Now, they’re extending their reach into the physical world.
2.2 Why Robotics Now?
The timing of this announcement is strategic:
- Mature Foundation Models: LLMs and vision models have reached unprecedented capabilities
- Compute Availability: GPU clusters can train massive multimodal models
- Sensor Technology: Cameras, LIDAR, and tactile sensors have become affordable
- Market Readiness: The robotics market is projected to reach $260 billion by 2030
3. The Vision: Personal Robots for Everyone
3.1 The Ultimate Goal
Altman’s vision is ambitious yet clear: “Make personal robots available to everyone.” This echoes the original vision of computing—democratizing access to powerful tools. Just as smartphones put computers in everyone’s pocket, personal robots could become the next universal tool.
3.2 Short-term Objectives
Before reaching the mass market, OpenAI Robotics has defined clear short-term objectives:
┌─────────────────────────────────────────────────────────────┐
│ OpenAI Robotics Roadmap │
├─────────────────────────────────────────────────────────────┤
│ Phase 1: Infrastructure Construction (2026-2027) │
│ Phase 2: Prototype Development (2027-2028) │
│ Phase 3: Enterprise Deployment (2028-2029) │
│ Phase 4: Consumer Launch (2029+) │
└─────────────────────────────────────────────────────────────┘
3.3 Target Applications
Short-term (Infrastructure-focused):
- Construction site assistance
- Warehouse logistics
- Manufacturing support
- Laboratory automation
Long-term (Consumer-focused):
- Home assistance
- Elderly care
- Personal chores
- Companion robots
4. Leadership and Research Foundation
4.1 Aditya Ramesh: The Visionary Leader
The robotics initiative is led by Aditya Ramesh, a key figure in OpenAI’s research division. Ramesh is renowned for his work on:
- DALL-E (image generation from text)
- Sora (video generation)
- World simulation research
His leadership brings a unique perspective: treating the physical world as another domain for AI-generated content.
4.2 World Models: The Foundation
The robotics initiative builds on OpenAI’s “World Model” research project. World models enable AI systems to:
- Simulate physical environments
- Predict outcomes of actions
- Plan sequences of tasks
- Generalize across different scenarios
4.3 Research Team Structure
# OpenAI Robotics Research Team Structure
class ResearchTeam:
def __init__(self):
self.leadership = {
"CEO": "Sam Altman",
"Robotics Lead": "Aditya Ramesh",
"VP Engineering": "Recruiting...",
}
self.divisions = {
"Perception": {
"focus": "Visual understanding, object detection",
"lead": "Hiring",
},
"Motion Planning": {
"focus": "Pathfinding, trajectory optimization",
"lead": "Hiring",
},
"Manipulation": {
"focus": "Grasping, object interaction",
"lead": "Hiring",
},
"Safety": {
"focus": "Human-robot interaction, fail-safes",
"lead": "Hiring",
},
"Hardware Integration": {
"focus": "Sensor-actuator coordination",
"lead": "Hiring",
}
}
self.open_positions = [
"Senior Robotics Engineer",
"Motion Planning Specialist",
"Computer Vision Engineer",
"Reinforcement Learning Researcher",
"Hardware Integration Engineer",
"Safety Systems Engineer",
]
5. Technical Architecture
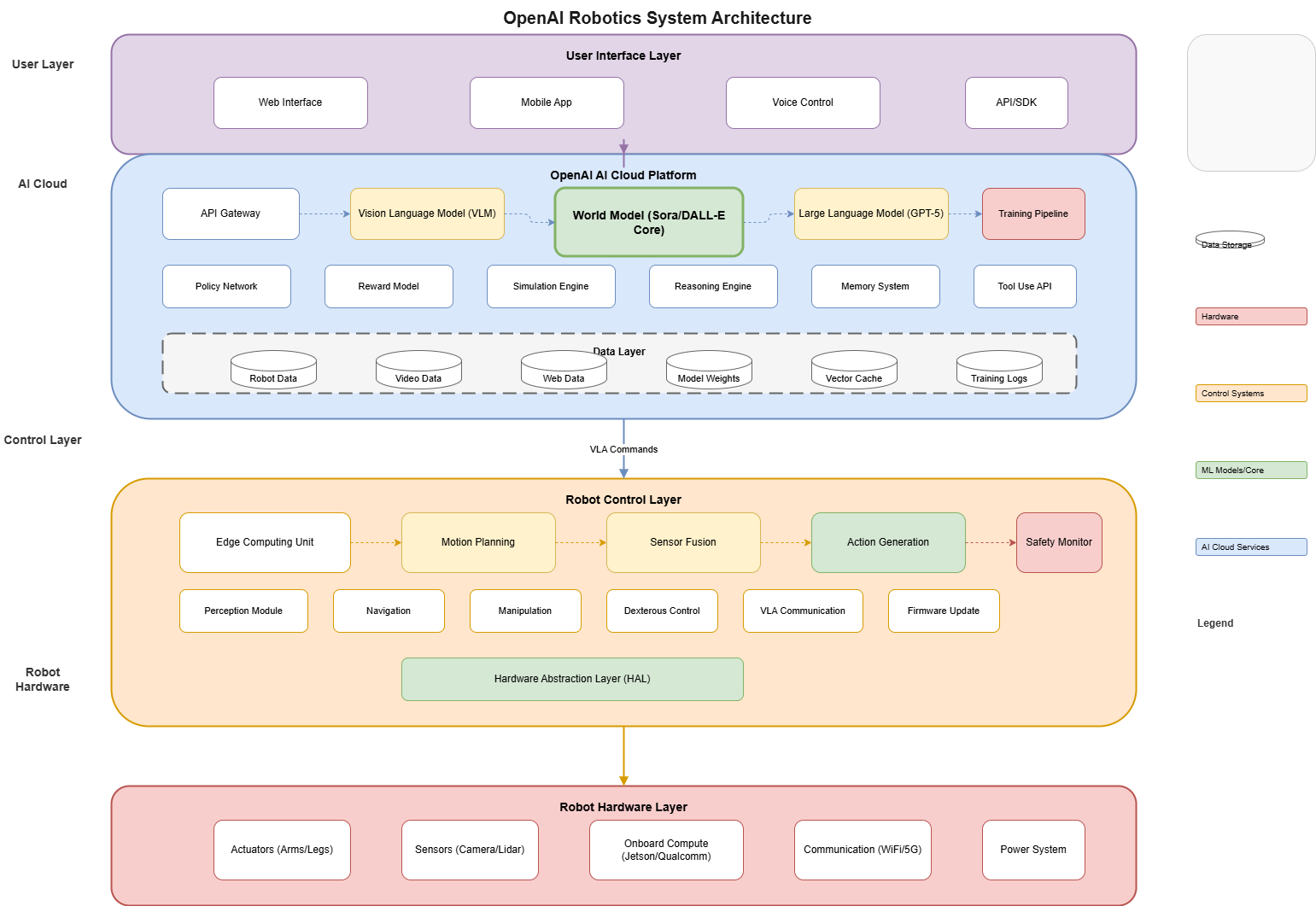
5.1 System Overview
The OpenAI Robotics architecture integrates multiple AI subsystems:
┌─────────────────────────────────────────────────────────────────┐
│ USER INTERFACE LAYER │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │Web App │ │Mobile App│ │Voice Ctrl│ │API/SDK │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ AI CLOUD PLATFORM │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │API Gateway│ │ VLM │ │ World Model │ │ LLM │ │
│ │ │ │(Vision-Lang)│ │ (Sora) │ │ (GPT) │ │
│ └────────────┘ └────────────┘ └────────────┘ └────────────┘ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ Training Pipeline │ Policy Network │ Reward Model │ Memory │ │
│ └─────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ CONTROL LAYER │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ ┌────────────┐ │
│ │Edge Compute│ │ Motion │ │ Sensor │ │ Action │ │
│ │ │ │ Planning │ │ Fusion │ │ Generation │ │
│ └────────────┘ └────────────┘ └────────────┘ └────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ ROBOT HARDWARE │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │Actuators │ │ Sensors │ │Onboard │ │Power Sys │ │
│ │Arms/Legs │ │Camera/LiDAR│ │Compute │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────────┘
5.2 Data Flow Architecture
"""
OpenAI Robotics Data Flow
==========================
This module implements the data pipeline from perception to action.
"""
from dataclasses import dataclass
from typing import List, Optional, Tuple
import numpy as np
@dataclass
class RobotObservation:
"""Raw sensor observations from the robot."""
rgb_image: np.ndarray # Shape: (H, W, 3)
depth_image: np.ndarray # Shape: (H, W)
proprioception: np.ndarray # Joint angles, forces
timestamp: float
@dataclass
class WorldState:
"""High-level world representation."""
objects: List[Object3D]
robot_pose: Pose3D
task_progress: float
confidence: float
@dataclass
class ActionCommand:
"""Action to be executed by the robot."""
joint_targets: np.ndarray
gripper_command: str # "open", "close", "grasp"
duration: float # seconds
safety_level: str # "normal", "cautious", "emergency"
class DataPipeline:
"""
Main data processing pipeline for robot perception and control.
"""
def __init__(self, config: dict):
self.vlm_model = self._load_vlm(config["vlm_checkpoint"])
self.world_model = self._load_world_model(config["world_model_checkpoint"])
self.policy_network = self._load_policy(config["policy_checkpoint"])
def process_observation(self, obs: RobotObservation) -> WorldState:
"""
Convert raw sensor data to high-level world state.
Pipeline:
1. Preprocess images (resize, normalize)
2. Extract features using VLM encoder
3. Query world model for state estimation
4. Return structured world state
"""
# Step 1: Preprocessing
rgb = self._preprocess_image(obs.rgb_image)
depth = self._preprocess_depth(obs.depth_image)
# Step 2: Feature extraction via Vision Language Model
visual_features = self.vlm_model.encode_vision(rgb)
depth_features = self.vlm_model.encode_depth(depth)
# Step 3: Proprioception encoding
proprio_features = self._encode_proprioception(obs.proprioception)
# Step 4: World state estimation
world_state = self.world_model.estimate_state(
visual_features=visual_features,
depth_features=depth_features,
proprio_features=proprio_features
)
return world_state
def generate_action(
self,
world_state: WorldState,
task_description: str
) -> ActionCommand:
"""
Generate robot action from world state and task.
Uses a Vision-Language-Action (VLA) model architecture.
"""
# Encode task in natural language
task_embedding = self.policy_network.encode_task(task_description)
# Cross-attention between world state and task
action_latent = self.policy_network.forward(
state=world_state,
task=task_embedding
)
# Decode action parameters
joint_targets = self.policy_network.decode_joints(action_latent)
gripper_cmd = self.policy_network.decode_gripper(action_latent)
# Safety check
if self._safety_violation_check(world_state, joint_targets):
return ActionCommand(
joint_targets=self._safe_joint_positions(),
gripper_command="hold",
duration=0.1,
safety_level="emergency"
)
return ActionCommand(
joint_targets=joint_targets,
gripper_command=gripper_cmd,
duration=0.5,
safety_level="normal"
)
5.3 Vision-Language-Action Model
The core of the system is a Vision-Language-Action (VLA) model that unifies perception, reasoning, and control:
"""
Vision-Language-Action (VLA) Model Implementation
==================================================
A unified model for robot perception, reasoning, and control.
"""
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer
class VLAModel(nn.Module):
"""
Vision-Language-Action Model for Robot Control
Architecture:
- Vision Encoder: Processes camera inputs
- Language Encoder: Processes task descriptions
- Fusion Module: Combines vision and language features
- Action Decoder: Generates motor commands
"""
def __init__(
self,
vision_model_name: str = "openai/clip-vit-large-patch14",
language_model_name: str = "gpt-4",
action_dim: int = 14, # 7 joints + 7 gripper
hidden_dim: int = 512
):
super().__init__()
# Vision encoder
self.vision_encoder = AutoModel.from_pretrained(vision_model_name)
vision_dim = self.vision_encoder.config.hidden_size
# Language encoder
self.language_encoder = AutoModel.from_pretrained(language_model_name)
self.tokenizer = AutoTokenizer.from_pretrained(language_model_name)
language_dim = self.language_encoder.config.hidden_size
# Projection layers to common space
self.vision_projection = nn.Linear(vision_dim, hidden_dim)
self.language_projection = nn.Linear(language_dim, hidden_dim)
# Cross-attention fusion
self.cross_attention = nn.MultiheadAttention(
embed_dim=hidden_dim,
num_heads=8,
dropout=0.1
)
# Action decoder heads
self.joint_head = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim),
nn.Tanh() # Normalize to [-1, 1]
)
self.gripper_head = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Linear(hidden_dim // 2, 1),
nn.Sigmoid() # Probability of closing
)
def forward(
self,
images: torch.Tensor, # (B, 3, 224, 224)
task_text: list[str], # List of task descriptions
return_hidden: bool = False
) -> dict[str, torch.Tensor]:
"""
Forward pass of the VLA model.
Args:
images: Batch of RGB images from robot cameras
task_text: Natural language task descriptions
return_hidden: Whether to return intermediate features
Returns:
Dictionary containing:
- joint_targets: Target joint angles (B, 7)
- gripper_prob: Gripper closing probability (B, 1)
- hidden_features: Intermediate representations (optional)
"""
batch_size = images.shape[0]
# Vision encoding
vision_outputs = self.vision_encoder(images)
vision_features = vision_outputs.last_hidden_state
vision_features = self.vision_projection(vision_features)
# Language encoding
tokens = self.tokenizer(
task_text,
padding=True,
truncation=True,
max_length=128,
return_tensors="pt"
).to(images.device)
language_outputs = self.language_encoder(**tokens)
language_features = language_outputs.last_hidden_state
language_features = self.language_projection(language_features)
# Cross-modal fusion via cross-attention
# Query: vision features, Key/Value: language features
fused_features, attention_weights = self.cross_attention(
query=vision_features.mean(dim=1, keepdim=True), # (B, 1, H)
key=language_features, # (B, L, H)
value=language_features
)
fused_features = fused_features.squeeze(1) # (B, H)
# Action decoding
joint_targets = self.joint_head(fused_features)
gripper_prob = self.gripper_head(fused_features)
outputs = {
"joint_targets": joint_targets,
"gripper_prob": gripper_prob,
}
if return_hidden:
outputs["hidden_features"] = fused_features
outputs["attention_weights"] = attention_weights
return outputs
def compute_loss(
self,
predictions: dict,
targets: dict,
attention_mask: Optional[torch.Tensor] = None
) -> dict[str, float]:
"""
Compute training loss for the VLA model.
Args:
predictions: Model outputs from forward()
targets: Ground truth labels
Returns:
Dictionary of losses and metrics
"""
# Joint position loss (MSE)
joint_loss = nn.functional.mse_loss(
predictions["joint_targets"],
targets["joint_targets"]
)
# Gripper loss (Binary cross-entropy)
gripper_loss = nn.functional.binary_cross_entropy(
predictions["gripper_prob"],
targets["gripper_action"].float()
)
# Combined loss with weighting
total_loss = joint_loss + 0.5 * gripper_loss
# Additional metrics
with torch.no_grad():
joint_accuracy = (
torch.abs(predictions["joint_targets"] - targets["joint_targets"]) < 0.1
).float().mean()
gripper_accuracy = (
(predictions["gripper_prob"] > 0.5).float() == targets["gripper_action"]
).float().mean()
return {
"total_loss": total_loss.item(),
"joint_loss": joint_loss.item(),
"gripper_loss": gripper_loss.item(),
"joint_accuracy": joint_accuracy.item(),
"gripper_accuracy": gripper_accuracy.item()
}
class VLAInference:
"""
Optimized inference wrapper for the VLA model.
Supports batching, caching, and hardware acceleration.
"""
def __init__(
self,
model: VLAModel,
device: str = "cuda",
batch_size: int = 1
):
self.model = model.to(device).eval()
self.device = device
self.batch_size = batch_size
# Preallocate buffers
self.image_buffer = torch.zeros(
(batch_size, 3, 224, 224),
dtype=torch.float32,
device=device
)
@torch.no_grad()
def predict(
self,
images: np.ndarray,
task_description: str
) -> Tuple[np.ndarray, float]:
"""
Run inference on robot observations.
Args:
images: RGB image array (H, W, 3) or batch (B, H, W, 3)
task_description: Natural language task
Returns:
joint_targets: Target joint angles
inference_time: Time taken for inference (ms)
"""
import time
start_time = time.perf_counter()
# Preprocess images
if images.ndim == 3:
images = images[np.newaxis, ...]
# Normalize to [0, 1]
images = images.astype(np.float32) / 255.0
# Convert to tensor and normalize with ImageNet stats
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
images = (images - mean) / std
# Transpose to (B, C, H, W)
images = np.transpose(images, (0, 3, 1, 2))
# Move to device
images_tensor = torch.from_numpy(images).to(self.device)
# Run model
outputs = self.model(
images=images_tensor,
task_text=[task_description] * len(images)
)
# Convert back to numpy
joint_targets = outputs["joint_targets"].cpu().numpy()
inference_time = (time.perf_counter() - start_time) * 1000
return joint_targets[0], inference_time
6. Core Technologies
6.1 World Models
World models are the foundation of OpenAI’s robotics research. They enable:
"""
World Model Implementation
===========================
Generative models for simulating physical environments.
"""
class WorldModel:
"""
World model for physical environment simulation.
Key capabilities:
1. State encoding: Compress world state into latent representation
2. Dynamics prediction: Predict next state given actions
3. Observation generation: Render simulated observations
4. Counterfactual reasoning: "What if I did X instead?"
"""
def __init__(self, config: WorldModelConfig):
self.state_encoder = StateEncoder(config.state_dim)
self.dynamics_model = DynamicsNetwork(
input_dim=config.state_dim + config.action_dim,
hidden_dim=config.hidden_dim,
output_dim=config.state_dim
)
self.observation_decoder = ObservationDecoder(
input_dim=config.state_dim,
output_channels=3 # RGB
)
def encode_state(self, observations: dict) -> torch.Tensor:
"""
Encode multi-modal observations into latent state.
"""
visual_features = self.state_encoder.encode_vision(observations["image"])
proprio_features = self.state_encoder.encode_proprio(observations["proprio"])
# Fusion
fused = torch.cat([visual_features, proprio_features], dim=-1)
state = self.state_encoder.fusion_layer(fused)
return state
def predict_next_state(
self,
current_state: torch.Tensor,
action: torch.Tensor
) -> torch.Tensor:
"""
Predict the next state given current state and action.
"""
state_action = torch.cat([current_state, action], dim=-1)
next_state = self.dynamics_model(state_action)
return next_state
def rollout(
self,
initial_state: torch.Tensor,
action_sequence: torch.Tensor,
horizon: int
) -> list[torch.Tensor]:
"""
Simulate a sequence of actions and return all states.
"""
states = [initial_state]
current_state = initial_state
for t in range(horizon):
action = action_sequence[:, t]
current_state = self.predict_next_state(current_state, action)
states.append(current_state)
return states
6.2 Reinforcement Learning Pipeline
"""
Reinforcement Learning for Robot Control
========================================
Training pipeline using PPO with world model simulation.
"""
class RobotRLTrainer:
"""
PPO-based trainer for robot manipulation tasks.
"""
def __init__(
self,
policy: VLAModel,
value_network: nn.Module,
world_model: WorldModel,
config: RLConfig
):
self.policy = policy
self.value_network = value_network
self.world_model = world_model
self.config = config
self.optimizer = torch.optim.AdamW(
list(policy.parameters()) + list(value_network.parameters()),
lr=config.learning_rate
)
def collect_rollouts(
self,
env: RobotEnvironment,
num_episodes: int
) -> list[dict]:
"""
Collect experience using the current policy.
Uses world model for imagination rollouts when real interaction is costly.
"""
trajectories = []
for episode in range(num_episodes):
obs = env.reset()
episode_data = {
"observations": [],
"actions": [],
"rewards": [],
"dones": [],
"log_probs": []
}
done = False
while not done:
# Get action from policy
with torch.no_grad():
action_dist = self.policy.get_action_distribution(obs)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
# Environment step
next_obs, reward, done, info = env.step(action)
episode_data["observations"].append(obs)
episode_data["actions"].append(action)
episode_data["rewards"].append(reward)
episode_data["dones"].append(done)
episode_data["log_probs"].append(log_prob)
obs = next_obs
trajectories.append(episode_data)
return trajectories
def compute_advantages(
self,
rewards: list[float],
dones: list[bool],
values: list[float],
gamma: float = 0.99,
lambda_gae: float = 0.95
) -> tuple[list[float], list[float]]:
"""
Compute Generalized Advantage Estimation (GAE).
"""
advantages = []
returns = []
gae = 0
next_value = 0
for t in reversed(range(len(rewards))):
if t == len(rewards) - 1:
next_non_terminal = 1.0 - dones[t]
next_value = 0
else:
next_non_terminal = 1.0 - dones[t]
delta = rewards[t] + gamma * next_value * next_non_terminal - values[t]
gae = delta + gamma * lambda_gae * next_non_terminal * gae
advantages.insert(0, gae)
returns.insert(0, gae + values[t])
next_value = values[t]
return advantages, returns
def update_policy(self, trajectories: list[dict]):
"""
PPO policy update with clipped surrogate objective.
"""
all_observations = torch.cat([
torch.stack(ep["observations"]) for ep in trajectories
])
all_actions = torch.cat([
torch.stack(ep["actions"]) for ep in trajectories
])
all_old_log_probs = torch.cat([
torch.stack(ep["log_probs"]) for ep in trajectories
])
# Compute rewards and values
all_rewards = [r for ep in trajectories for r in ep["rewards"]]
all_dones = [d for ep in trajectories for d in ep["dones"]]
with torch.no_grad():
values = self.value_network(all_observations).squeeze(-1)
advantages, returns = self.compute_advantages(
all_rewards, all_dones, values.cpu().tolist()
)
# Normalize advantages
advantages = torch.tensor(advantages)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# PPO update
for epoch in range(self.config.ppo_epochs):
# New action distribution
action_dist = self.policy.get_action_distribution(all_observations)
new_log_probs = action_dist.log_prob(all_actions)
entropy = action_dist.entropy()
# Ratio for importance sampling
ratio = torch.exp(new_log_probs - all_old_log_probs)
# Clipped surrogate objective
surr1 = ratio * advantages
surr2 = torch.clamp(
ratio,
1 - self.config.clip_epsilon,
1 + self.config.clip_epsilon
) * advantages
# Policy loss
policy_loss = -torch.min(surr1, surr2).mean()
# Value loss
new_values = self.value_network(all_observations).squeeze(-1)
value_loss = nn.functional.mse_loss(new_values, returns)
# Entropy bonus (for exploration)
entropy_loss = -entropy.mean()
# Total loss
total_loss = (
policy_loss +
self.config.value_coef * value_loss +
self.config.entropy_coef * entropy_loss
)
# Gradient step
self.optimizer.zero_grad()
total_loss.backward()
nn.utils.clip_grad_norm_(self.policy.parameters(), 0.5)
self.optimizer.step()
6.3 Simulation Infrastructure
"""
Physics Simulation Wrapper
==========================
Interface to Isaac Gym / MuJoCo / PyBullet for robot simulation.
"""
class RobotSimulator:
"""
Unified interface for robot physics simulation.
"""
def __init__(
self,
backend: str = "mujoco", # mujoco, isaac, pybullet
config: dict = None
):
self.backend = backend
self.config = config or {}
if backend == "mujoco":
self._init_mujoco()
elif backend == "isaac":
self._init_isaac()
elif backend == "pybullet":
self._init_pybullet()
def _init_mujoco(self):
"""Initialize MuJoCo physics engine."""
import mujoco
# Create model from XML
self.model = mujoco.MjModel.from_xml_string(self._get_robot_xml())
self.data = mujoco.MjData(self.model)
# Renderer for visualization
self.renderer = mujoco.viewer.Callback()
def step(self, action: np.ndarray):
"""
Execute one simulation step.
Args:
action: Joint position targets or torques
"""
if self.backend == "mujoco":
import mujoco
self.data.ctrl[:] = action
mujoco.mj_step(self.model, self.data)
def reset(self) -> dict:
"""Reset simulation to initial state."""
import mujoco
mujoco.mj_resetData(self.model, self.data)
return self._get_observation()
def _get_observation(self) -> dict:
"""Extract sensor readings from simulation."""
return {
"qpos": self.data.qpos.copy(), # Joint positions
"qvel": self.data.qvel.copy(), # Joint velocities
"rgb": self._render_image(), # RGB camera
"depth": self._render_depth(), # Depth image
}
7. Short-term vs. Long-term Goals
7.1 Short-term Objectives (2026-2028)
| Goal | Description | Key Metrics |
|---|---|---|
| Infrastructure | Build core robotics platform | API latency < 50ms |
| Prototypes | Develop working robot prototypes | Manipulation success > 80% |
| Validation | Test in controlled environments | Safety incidents < 0.1% |
| Partnerships | Partner with manufacturers | 3+ major partnerships |
7.2 Long-term Vision (2028+)
| Goal | Description | Key Metrics |
|---|---|---|
| Consumer Launch | Personal robot for mass market | Price < $10,000 |
| Capabilities | General-purpose household tasks | 100+ task types |
| Accessibility | Robots in every home | Market penetration > 5% |
7.3 Technical Milestones
Timeline: OpenAI Robotics Development
2026 Q2: Initial hiring and team formation
2026 Q4: First internal prototypes
2027 Q2: World model integration complete
2027 Q4: Simulation-to-reality transfer working
2028 Q2: Field testing with partners
2028 Q4: Enterprise product launch
2029 Q2: Consumer product announcement
2029 Q4: Mass production begins
8. Career Opportunities
8.1 Open Positions
OpenAI is hiring for multiple robotics roles:
| Position | Salary Range | Focus Area |
|---|---|---|
| Senior Robotics Engineer | $210K - $310K | System integration |
| Motion Planning Specialist | $200K - $280K | Pathfinding algorithms |
| Computer Vision Engineer | $190K - $270K | Perception systems |
| RL Researcher | $200K - $300K | Training algorithms |
| Hardware Integration Eng. | $180K - $250K | Sensor-actuator systems |
| Safety Systems Engineer | $190K - $260K | Safety protocols |
8.2 Required Skills
# Required skills for OpenAI Robotics positions
SKILLS_REQUIRED = {
"robotics_engineer": {
"required": [
"ROS/ROS2 development",
"C++ and Python proficiency",
"Kinematics and dynamics",
"Control systems theory"
],
"preferred": [
"Reinforcement learning",
"Computer vision",
"Simulation experience",
"Real robot deployment"
]
},
"motion_planning": {
"required": [
"Path planning algorithms (RRT, PRM, A*)",
"Trajectory optimization",
"Collision detection",
"Optimization solvers"
],
"preferred": [
"Whole-body control",
"Manipulation planning",
"Learning-based planning"
]
},
"computer_vision": {
"required": [
"Deep learning for vision",
"Object detection/segmentation",
"3D reconstruction",
"SLAM"
],
"preferred": [
"Multi-view geometry",
"Point cloud processing",
"Novel view synthesis"
]
}
}
9. Industry Impact
9.1 Market Analysis
The global robotics market is experiencing unprecedented growth:
Market Size Projections:
- 2025: $85 billion
- 2026: $100 billion (OpenAI entry)
- 2028: $150 billion
- 2030: $260 billion
- 2035: $400+ billion (projected)
Key Segments:
- Industrial: $45B (2026)
- Consumer: $25B (2026)
- Healthcare: $20B (2026)
- Logistics: $15B (2026)
9.2 Competitive Landscape
OpenAI joins established players:
| Company | Focus | Strengths |
|---|---|---|
| Boston Dynamics | Dynamic locomotion | Atlas, Spot |
| Tesla (Optimus) | Consumer robots | Manufacturing scale |
| Figure AI | Humanoid robots | Fast development |
| 1X Technologies | Consumer humanoids | Neo robot |
| Agility Robotics | Bipedal robots | Digit platform |
| OpenAI | AI foundation | LLMs, World Models |
9.3 Expected Disruption
OpenAI’s entry is expected to:
- Accelerate AI integration in robotics
- Lower costs through scalable software
- Improve reasoning with foundation models
- Democratize access through cloud robotics
10. Code Examples and Implementation
10.1 Complete Robot Control Loop
"""
Complete Robot Control Loop
============================
End-to-end implementation of a robot manipulation task.
"""
import numpy as np
import torch
from typing import Optional
import time
class RobotController:
"""
High-level robot controller integrating perception, planning, and control.
"""
def __init__(
self,
vla_model: VLAModel,
world_model: WorldModel,
simulator: RobotSimulator,
config: dict
):
self.vla = vla_model
self.world_model = world_model
self.sim = simulator
self.config = config
# State tracking
self.current_state: Optional[dict] = None
self.task_queue: list[str] = []
self.execution_history: list[dict] = []
def initialize(self):
"""Initialize the robot controller."""
# Reset simulation
self.current_state = self.sim.reset()
# Run initial perception
self._update_state()
print("Robot controller initialized")
print(f"Initial joint positions: {self.current_state['qpos']}")
def execute_task(self, task_description: str) -> dict:
"""
Execute a manipulation task described in natural language.
Args:
task_description: e.g., "Pick up the red cube and place it in the box"
Returns:
Execution result with success status and metrics
"""
print(f"\nExecuting task: {task_description}")
start_time = time.time()
max_steps = self.config.get("max_steps", 100)
for step in range(max_steps):
# 1. Perception: Get current observation
obs = self.sim._get_observation()
# 2. Action generation using VLA model
with torch.no_grad():
joint_targets, inference_time = self._generate_action(
obs, task_description
)
# 3. Safety check
if not self._check_safety(joint_targets):
print("Safety constraint violated! Stopping.")
return self._create_result(
success=False,
reason="Safety violation",
steps=step
)
# 4. Execute action in simulation
self.sim.step(joint_targets)
# 5. Check task completion
task_complete = self._check_task_complete(task_description)
if task_complete:
execution_time = time.time() - start_time
print(f"Task completed in {execution_time:.2f}s ({step} steps)")
return self._create_result(
success=True,
execution_time=execution_time,
steps=step,
avg_inference_time=inference_time
)
# Task not completed within step limit
return self._create_result(
success=False,
reason="Step limit exceeded",
steps=max_steps
)
def _generate_action(
self,
obs: dict,
task: str
) -> tuple[np.ndarray, float]:
"""
Generate action using the VLA model.
"""
# Convert observation to tensor
rgb = obs["rgb"]
rgb_tensor = self._preprocess_image(rgb)
# VLA inference
joint_targets, inference_time = self.vla.predict(
images=rgb_tensor,
task_description=task
)
# Scale joint targets to valid range
joint_targets = np.clip(joint_targets, -1, 1)
return joint_targets, inference_time
def _preprocess_image(self, image: np.ndarray) -> np.ndarray:
"""Preprocess RGB image for VLA model."""
import cv2
# Resize to model input size
image = cv2.resize(image, (224, 224))
# Normalize
image = image.astype(np.float32) / 255.0
return image
def _check_safety(self, action: np.ndarray) -> bool:
"""
Check if the proposed action is safe.
Safety checks:
- Joint limits
- Collision avoidance
- Velocity limits
- Force limits
"""
# Joint limit check
joint_limits = np.array(self.config.get("joint_limits", []))
if joint_limits.any():
if np.any(action < joint_limits[:, 0]) or \
np.any(action > joint_limits[:, 1]):
return False
# Velocity limit check
velocity_limit = self.config.get("velocity_limit", 1.0)
if np.abs(action).max() > velocity_limit:
return False
return True
def _check_task_complete(self, task: str) -> bool:
"""
Check if the task has been completed.
In a real system, this would use:
- Vision-based state comparison
- Object detection
- Goal condition evaluation
"""
# Simplified: check if robot has moved significantly
qpos = self.sim.data.qpos
return np.std(qpos) > 0.5 # Placeholder condition
def _update_state(self):
"""Update internal state representation."""
self.current_state = self.sim._get_observation()
def _create_result(
self,
success: bool,
reason: str = None,
steps: int = 0,
execution_time: float = 0,
avg_inference_time: float = 0
) -> dict:
"""Create standardized result dictionary."""
return {
"success": success,
"reason": reason,
"steps": steps,
"execution_time": execution_time,
"avg_inference_time": avg_inference_time,
"timestamp": time.time()
}
# Example usage
def main():
"""Example robot control session."""
# Configuration
config = {
"max_steps": 100,
"velocity_limit": 0.5,
"joint_limits": np.array([
[-1.5, 1.5], # Joint 1
[-1.5, 1.5], # Joint 2
[-1.5, 1.5], # Joint 3
[-1.5, 1.5], # Joint 4
[-1.5, 1.5], # Joint 5
[-1.5, 1.5], # Joint 6
[-1.5, 1.5], # Joint 7
]),
"vlm_checkpoint": "openai/vla-v1",
"world_model_checkpoint": "openai/world-model-v1",
}
# Initialize components
print("Loading models...")
# Create models (in real deployment, load from checkpoints)
device = "cuda" if torch.cuda.is_available() else "cpu"
vla_model = VLAModel().to(device)
world_model = WorldModel(config)
simulator = RobotSimulator(backend="mujoco", config=config)
# Create controller
controller = RobotController(
vla_model=vla_model,
world_model=world_model,
simulator=simulator,
config=config
)
# Initialize
controller.initialize()
# Execute tasks
tasks = [
"Move to neutral position",
"Pick up the blue cube",
"Place the cube in the container",
]
for task in tasks:
result = controller.execute_task(task)
print(f"Task result: {result}\n")
print("Control session complete!")
if __name__ == "__main__":
main()
10.2 Data Collection Pipeline
"""
Robot Data Collection Pipeline
==============================
Efficient system for collecting demonstration data.
"""
import os
import json
import numpy as np
from dataclasses import dataclass, asdict
from typing import Iterator
import h5py
from datetime import datetime
@dataclass
class RobotDemonstration:
"""A single robot demonstration episode."""
episode_id: str
task_description: str
observations: list
actions: list
rewards: list
success: bool
duration: float
metadata: dict
class DataCollector:
"""
System for collecting and storing robot demonstration data.
"""
def __init__(
self,
output_dir: str = "./robot_data",
buffer_size: int = 100,
compression: str = "gzip"
):
self.output_dir = output_dir
self.buffer_size = buffer_size
self.compression = compression
# Create output directory
os.makedirs(output_dir, exist_ok=True)
# Episode buffer
self.buffer: list[RobotDemonstration] = []
self.episode_counter = 0
# HDF5 file for efficient storage
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
self.hdf5_path = os.path.join(
output_dir,
f"demonstrations_{timestamp}.hdf5"
)
self.hdf5_file = h5py.File(self.hdf5_path, "w")
# Dataset groups
self._create_datasets()
def _create_datasets(self):
"""Initialize HDF5 datasets."""
# Create groups
self.observations_grp = self.hdf5_file.create_group("observations")
self.actions_grp = self.hdf5_file.create_group("actions")
self.metadata_grp = self.hdf5_file.create_group("metadata")
# Episode metadata dataset
self.hdf5_file.create_dataset(
"episodes",
shape=(0,),
maxshape=(None,),
dtype=h5py.special_dtype(vlen=str)
)
def record_step(
self,
observation: dict,
action: np.ndarray,
reward: float
):
"""Record a single timestep."""
self.current_observations.append(observation)
self.current_actions.append(action)
self.current_rewards.append(reward)
def start_episode(self, task_description: str):
"""Start a new demonstration episode."""
self.current_task = task_description
self.current_observations = []
self.current_actions = []
self.current_rewards = []
self.episode_start_time = datetime.now()
print(f"Starting episode: {task_description}")
def end_episode(self, success: bool):
"""Complete and store an episode."""
duration = (datetime.now() - self.episode_start_time).total_seconds()
episode = RobotDemonstration(
episode_id=f"ep_{self.episode_counter:06d}",
task_description=self.current_task,
observations=self.current_observations,
actions=self.current_actions,
rewards=self.current_rewards,
success=success,
duration=duration,
metadata={
"num_steps": len(self.current_observations),
"collect_timestamp": self.episode_start_time.isoformat()
}
)
# Add to buffer
self.buffer.append(episode)
self.episode_counter += 1
# Flush if buffer is full
if len(self.buffer) >= self.buffer_size:
self._flush_buffer()
print(f"Episode complete: success={success}, duration={duration:.2f}s")
def _flush_buffer(self):
"""Write buffered episodes to HDF5."""
if not self.buffer:
return
for ep in self.buffer:
# Create subgroup for episode
grp = self.observations_grp.create_group(ep.episode_id)
# Store observations
obs_data = self._stack_observations(ep.observations)
grp.create_dataset(
"rgb",
data=obs_data["rgb"],
compression=self.compression
)
grp.create_dataset(
"depth",
data=obs_data["depth"],
compression=self.compression
)
grp.create_dataset(
"proprio",
data=np.array(obs_data["proprio"]),
compression=self.compression
)
# Store actions
self.actions_grp.create_dataset(
f"{ep.episode_id}/joints",
data=np.array(ep.actions),
compression=self.compression
)
# Store metadata
self.metadata_grp.create_dataset(
f"{ep.episode_id}/task",
data=ep.task_description
)
self.metadata_grp.create_dataset(
f"{ep.episode_id}/success",
data=1 if ep.success else 0
)
self.buffer.clear()
self.hdf5_file.flush()
print(f"Flushed {len(self.buffer)} episodes to disk")
def _stack_observations(self, observations: list) -> dict:
"""Stack observation arrays."""
rgb = np.stack([o["rgb"] for o in observations])
depth = np.stack([o["depth"] for o in observations])
proprio = [o["proprio"] for o in observations]
return {"rgb": rgb, "depth": depth, "proprio": proprio}
def close(self):
"""Finalize and close the data collector."""
# Flush remaining episodes
self._flush_buffer()
# Store summary
summary = {
"total_episodes": self.episode_counter,
"output_path": self.hdf5_path,
"timestamp": datetime.now().isoformat()
}
with open(
os.path.join(self.output_dir, "collection_summary.json"),
"w"
) as f:
json.dump(summary, f, indent=2)
self.hdf5_file.close()
print(f"Data collection complete. Saved to {self.hdf5_path}")
# Utility functions for data processing
def load_demonstrations(hdf5_path: str) -> Iterator[dict]:
"""
Load demonstrations from HDF5 file.
Usage:
for ep in load_demonstrations("demonstrations.hdf5"):
process(ep)
"""
with h5py.File(hdf5_path, "r") as f:
for ep_id in f["observations"].keys():
yield {
"episode_id": ep_id,
"rgb": f[f"observations/{ep_id}/rgb"][:],
"depth": f[f"observations/{ep_id}/depth"][:],
"proprio": f[f"observations/{ep_id}/proprio"][:],
"actions": f[f"actions/{ep_id}/joints"][:],
"task": f[f"metadata/{ep_id}/task"][()],
"success": bool(f[f"metadata/{ep_id}/success"][()])
}
def compute_success_rate(demonstrations: list[dict]) -> float:
"""Compute success rate from demonstration list."""
if not demonstrations:
return 0.0
successes = sum(1 for ep in demonstrations if ep["success"])
return successes / len(demonstrations)
11. Future Roadmap
11.1 Technical Development Path
┌─────────────────────────────────────────────────────────────────────┐
│ OpenAI Robotics Roadmap │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ Phase 1: Foundation (2026) │
│ ├── Build core VLA architecture │
│ ├── Develop world model integration │
│ ├── Create simulation infrastructure │
│ └── Establish hardware partnerships │
│ │
│ Phase 2: Training (2027) │
│ ├── Large-scale data collection │
│ ├── Pre-training on diverse tasks │
│ ├── Simulation-to-reality transfer │
│ └── Safety validation │
│ │
│ Phase 3: Deployment (2028) │
│ ├── Enterprise pilot programs │
│ ├── Field testing and iteration │
│ ├── Performance optimization │
│ └── Cost reduction engineering │
│ │
│ Phase 4: Scale (2029+) │
│ ├── Consumer product launch │
│ ├── Mass manufacturing │
│ ├── Global support infrastructure │
│ └── Continuous improvement via cloud updates │
│ │
└─────────────────────────────────────────────────────────────────────┘
11.2 Expected Capabilities Evolution
| Year | Manipulation | Navigation | Reasoning | Generalization |
|---|---|---|---|---|
| 2026 | Pick/Place | Static env | Task following | Single task |
| 2027 | Multi-finger | Dynamic | Plan sub-tasks | Few-shot |
| 2028 | Tool use | Household | Causal reasoning | Task transfer |
| 2029 | Complex assembly | Outdoor | Long-horizon | Zero-shot |
| 2030 | Open-ended | Unconstrained | Human-level | Universal |
12. Conclusion
OpenAI’s entry into robotics represents a pivotal moment in the history of artificial intelligence. By combining their world-leading foundation models with physical robotic systems, OpenAI is poised to accelerate the path toward general-purpose robots that can assist humans in virtually any task.
The initiative, led by Aditya Ramesh and built upon years of world model research, addresses a fundamental challenge in robotics: enabling robots to understand and interact with the physical world as naturally as humans do. The company’s approach leverages the power of large language models, vision systems, and reinforcement learning to create robots that can learn from experience, reason about complex situations, and adapt to new challenges.
With competitive salaries ranging from $210,000 to $310,000 plus equity, OpenAI is attracting top talent to tackle these challenges. The short-term focus on infrastructure and construction assistance provides immediate value while building toward the ambitious long-term vision: making personal robots available to everyone.
As we look ahead, the integration of AI software with robotic hardware promises to transform industries from manufacturing to healthcare to home assistance. OpenAI Robotics is not just building robots—it’s building the foundation for a future where AI physically assists humanity in ways we’ve only imagined.
The future of robotics is AI-native, and that future starts now.