Memory Persistence Architecture Upgrade for Autonomous AI Agents
Memory Persistence Architecture Upgrade for Autonomous AI Agents
1. Background
In today’s rapidly advancing AI landscape, autonomous AI Agents have become a core driver of enterprise digital transformation. From intelligent customer service to project management, from code assistance to data analysis, AI Agents are reshaping how we work. However, as application scenarios deepen, a critical bottleneck has gradually emerged—“conversation forgetting.”
Current mainstream AI Agents, when handling multi-turn conversations, typically rely on a context window to maintain short-term memory. For example, while GPT-4’s 128K token window can accommodate a large amount of text, once a session ends or tokens are exhausted, all contextual information vanishes. This means:
- Long-term project managers cannot make Agents remember decision rationales from three months ago.
- Continuous learning customer service requires users to repeatedly explain historical issues.
- In multi-step task execution, Agents lose intermediate reasoning states.
This “conversation forgetting” not only degrades user experience but also hinders the evolution of AI Agents toward true autonomy and continuity. To address this bottleneck, we need to introduce a memory persistence architecture.
The core idea of memory persistence is to equip AI Agents with a human-like long-term and short-term memory system: short-term memory handles immediate context within the current session, while long-term memory stores key knowledge across sessions. By fusing Long Short-Term Memory (LSTM) networks with vector databases, we can build a memory system that is both responsive and capable of continuous learning.
This article will delve into the technical principles, system design, core implementation, and production practices of this architecture, helping developers overcome the “conversation forgetting” bottleneck and build truly continuous AI Agents.
2. Technical Principles
2.1 Role of Long Short-Term Memory Networks (LSTM)
LSTM is a special type of Recurrent Neural Network (RNN) that solves the long-term dependency problem of traditional RNNs by introducing a “gating mechanism.” In the memory system of an AI Agent, LSTM is primarily responsible for:
- Short-Term Memory Management: Processing sequential information within the current session, such as conversation history and reasoning steps.
- Forget Gate: Determining which information to retain and which to discard.
- State Update: Updating internal states based on new inputs to maintain contextual coherence.
Unlike traditional LSTM used for sequence prediction, we employ it as a memory encoder within the Agent, transforming raw text into structured memory representations.
2.2 Positioning of Vector Databases
Vector databases (e.g., Milvus, Pinecone, Weaviate) are specialized for storing and retrieving high-dimensional vector data. In the memory system, they undertake:
- Long-Term Memory Storage: Encoding key information into vectors and persisting them.
- Semantic Retrieval: Using cosine similarity or Euclidean distance to quickly find historical memories most relevant to the current query.
- Dynamic Updates: Supporting CRUD operations to adapt to evolving knowledge.
2.3 Fusion Architecture: LSTM + Vector Database
The core idea behind fusing the two is hierarchical memory:
- Working Memory: The current session state maintained by LSTM, updated in real-time, with limited capacity (e.g., 1000 tokens).
- Long-Term Memory: Cross-session knowledge stored in the vector database, with unlimited capacity, accessed via semantic retrieval.
- Memory Transfer: When working memory reaches a threshold or a session ends, LSTM encodes important information into vectors and writes them to long-term memory. When a new session begins, relevant segments are retrieved from long-term memory and loaded into working memory.
This architecture mimics the operation of human memory: short-term memory quickly processes current tasks, long-term memory stores experiences and knowledge, and the two transform into each other through a “memory consolidation” mechanism.
2.4 Memory Representation and Encoding
The representation of memory is key to the architecture. We adopt a triple structure:
Memory = { Timestamp, Entity, Relation, Content }
Where:
- Timestamp: Records the time the memory was created.
- Entity: The core object involved in the memory (e.g., User ID, Project Name).
- Relation: The association between entities (e.g., “responsible for,” “discussed”).
- Content: The detailed text of the memory.
Encoding Process:
- Raw Text → LSTM Encoder → Semantic Vector (768 dimensions).
- Structured Information (Entity, Relation) → Metadata.
- Storage: Vector + Metadata → Vector Database.
Retrieval Process:
- Current Query → LSTM Query Encoder → Query Vector.
- Vector Database ANN Search → Top-K Similar Memories.
- Filtering based on Timestamp, Entity Relations → Final Memory Set.
3. System Architecture Design
3.1 Overall Architecture
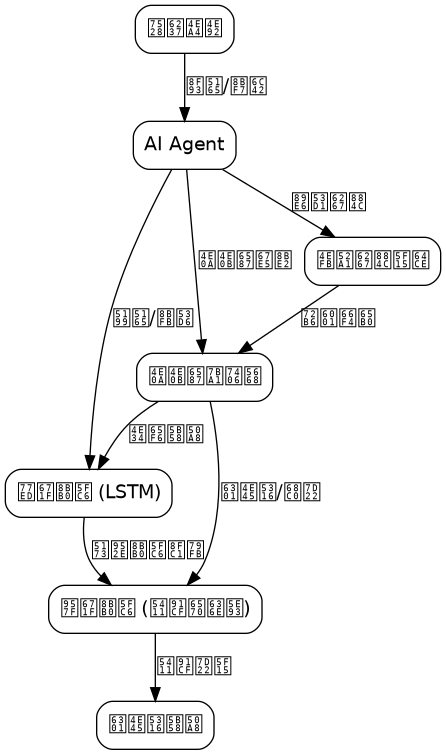
The system is divided into four core layers:
1. Interaction Layer
- User Interface: Web, API, Command Line.
- Session Management: Maintains current Session ID, status.
2. Memory Management Layer
- Working Memory Module: LSTM state maintenance.
- Memory Transfer Module: Working Memory ↔ Long-Term Memory.
- Memory Compression Module: Redundant information filtering, summary generation.
3. Storage Layer
- Vector Database: Milvus (Cluster Edition).
- Relational Database: PostgreSQL (stores metadata, user information).
- Cache: Redis (accelerates working memory access).
4. Reasoning Layer
- LLM Interface: Interfaces with models like GPT, Claude.
- Reasoning Engine: Generates responses by combining memory context.
3.2 Data Flow Design
User Input → Session Management → Working Memory (LSTM) → Memory Retrieval (Vector DB) → Context Assembly → LLM Inference → Response Output
↓ ↑
Memory Update ←—— Memory Encoding (LSTM) ←—— Memory Extraction (NER) ←—— Response Analysis
Key Flow:
- User input enters the session, updating the working memory state.
- Working memory triggers memory retrieval, fetching relevant history from the vector database.
- Assemble the complete context (Working Memory + Long-Term Memory).
- LLM generates a response.
- Analyze the response, extract key information, update working memory.
- When working memory is saturated or the session ends, encode and write to long-term memory.
3.3 Memory Lifecycle Management
Memory is not static and requires dynamic management:
- Memory Creation: New information enters working memory, undergoes LSTM encoding.
- Memory Consolidation: When working memory usage exceeds 80%, memory transfer is triggered.
- Memory Retrieval: Based on query similarity, recall Top-10 relevant memories.
- Memory Merge: Memories with similarity exceeding 0.9 are automatically merged.
- Memory Forgetting: Memories unaccessed for over 90 days are demoted to low priority.
- Memory Deletion: User-initiated deletion or system auto-cleanup (e.g., expiration).
4. Core Implementation (Golang Code)
4.1 Project Structure
agent-memory/
├── cmd/
│ └── server/
│ └── main.go
├── internal/
│ ├── memory/
│ │ ├── lstm.go // LSTM working memory implementation
│ │ ├── vector_store.go // Vector database interface
│ │ ├── transfer.go // Memory transfer logic
│ │ └── manager.go // Memory manager
│ ├── model/
│ │ ├── memory.go // Memory data structures
│ │ └── session.go // Session structures
│ ├── llm/
│ │ └── client.go // LLM interface wrapper
│ └── config/
│ └── config.go // Configuration management
├── pkg/
│ └── utils/
│ └── embedding.go // Vector encoding utility
└── go.mod
4.2 Core Data Structure Definitions
// internal/model/memory.go
package model
import "time"
// Memory represents a single memory record
type Memory struct {
ID string `json:"id"` // Unique identifier
SessionID string `json:"session_id"` // Associated session
Timestamp time.Time `json:"timestamp"` // Creation time
Entity string `json:"entity"` // Entity name
Relation string `json:"relation"` // Relation type
Content string `json:"content"` // Memory content
Vector []float32 `json:"vector"` // Semantic vector
Priority int `json:"priority"` // Priority 1-10
ExpireAt time.Time `json:"expire_at"` // Expiration time
}
// SessionState represents the session state (working memory)
type SessionState struct {
SessionID string `json:"session_id"`
Context []string `json:"context"` // Context window
LSTMState *LSTMHiddenState `json:"lstm_state"` // LSTM hidden state
TokenCount int `json:"token_count"` // Tokens used
MaxTokens int `json:"max_tokens"` // Maximum tokens
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
}
// LSTMHiddenState represents the LSTM hidden state
type LSTMHiddenState struct {
H []float32 `json:"h"` // Hidden state vector
C []float32 `json:"c"` // Cell state vector
}
4.3 LSTM Working Memory Implementation
// internal/memory/lstm.go
package memory
import (
"math"
"sync"
"agent-memory/internal/model"
)
// LSTMWorker manages working memory
type LSTMWorker struct {
mu sync.RWMutex
inputDim int // Input dimension
hiddenDim int // Hidden layer dimension
sessions map[string]*model.SessionState
maxTokenLimit int
}
// NewLSTMWorker creates a new LSTM working memory manager
func NewLSTMWorker(inputDim, hiddenDim, maxTokens int) *LSTMWorker {
return &LSTMWorker{
inputDim: inputDim,
hiddenDim: hiddenDim,
sessions: make(map[string]*model.SessionState),
maxTokenLimit: maxTokens,
}
}
// UpdateState updates the session state
// Input: current session ID, user input content
// Output: updated session state
func (lw *LSTMWorker) UpdateState(sessionID, input string) (*model.SessionState, error) {
lw.mu.Lock()
defer lw.mu.Unlock()
// Get or create session state
state, exists := lw.sessions[sessionID]
if !exists {
state = &model.SessionState{
SessionID: sessionID,
Context: make([]string, 0),
LSTMState: lw.initLSTMState(),
TokenCount: 0,
MaxTokens: lw.maxTokenLimit,
CreatedAt: time.Now(),
}
lw.sessions[sessionID] = state
}
// Estimate input token count (simplified: estimate based on character count)
tokenCount := len(input) / 4 // Assuming ~4 chars per token
state.TokenCount += tokenCount
// Check if token limit exceeded, trigger memory transfer
if state.TokenCount > state.MaxTokens {
// Trigger memory transfer (implemented in transfer.go)
// Only record state here
return state, ErrMemoryFull
}
// Update context window (keep last N entries)
state.Context = append(state.Context, input)
if len(state.Context) > 20 { // Keep last 20 entries
state.Context = state.Context[len(state.Context)-20:]
}
// Update LSTM state (simplified: using forget gate)
state.LSTMState = lw.updateLSTM(state.LSTMState, input)
state.UpdatedAt = time.Now()
return state, nil
}
// initLSTMState initializes the LSTM hidden state
func (lw *LSTMWorker) initLSTMState() *model.LSTMHiddenState {
h := make([]float32, lw.hiddenDim)
c := make([]float32, lw.hiddenDim)
// Initialize to zero
for i := range h {
h[i] = 0
c[i] = 0
}
return &model.LSTMHiddenState{H: h, C: c}
}
// updateLSTM updates the LSTM state (simplified implementation)
// In production, use deep learning frameworks like TensorFlow or PyTorch
func (lw *LSTMWorker) updateLSTM(state *model.LSTMHiddenState, input string) *model.LSTMHiddenState {
// Simulate LSTM gate calculations
// Forget gate: determines how much old information to retain
// Input gate: determines how much new information to update
// Output gate: determines how much information to output
// Generate input vector (simplified: using string hash)
inputVec := lw.textToVector(input)
// Forget gate calculation
forgetGate := make([]float32, lw.hiddenDim)
for i := range forgetGate {
// sigmoid function
forgetGate[i] = 1.0 / (1.0 + float32(math.Exp(-float64(state.H[i]*0.5 + inputVec[i%len(inputVec)]*0.3))))
}
// Input gate calculation
inputGate := make([]float32, lw.hiddenDim)
for i := range inputGate {
inputGate[i] = 1.0 / (1.0 + float32(math.Exp(-float64(state.H[i]*0.4 + inputVec[i%len(inputVec)]*0.6))))
}
// Candidate cell state
candidateC := make([]float32, lw.hiddenDim)
for i := range candidateC {
candidateC[i] = float32(math.Tanh(float64(state.H[i]*0.3 + inputVec[i%len(inputVec)]*0.7)))
}
// Update cell state
newC := make([]float32, lw.hiddenDim)
for i := range newC {
newC[i] = forgetGate[i]*state.C[i] + inputGate[i]*candidateC[i]
}
// Output gate calculation
outputGate := make([]float32, lw.hiddenDim)
for i := range outputGate {
outputGate[i] = 1.0 / (1.0 + float32(math.Exp(-float64(state.H[i]*0.6 + inputVec[i%len(inputVec)]*0.4))))
}
// New hidden state
newH := make([]float32, lw.hiddenDim)
for i := range newH {
newH[i] = outputGate[i] * float32(math.Tanh(float64(newC[i])))
}
return &model.LSTMHiddenState{H: newH, C: newC}
}
// textToVector converts text to vector (simplified)
func (lw *LSTMWorker) textToVector(text string) []float32 {
vec := make([]float32, lw.inputDim)
for i, ch := range text {
idx := i % lw.inputDim
vec[idx] += float32(ch) / 255.0
}
// Normalize
sum := float32(0)
for _, v := range vec {
sum += v * v
}
if sum > 0 {
norm := float32(math.Sqrt(float64(sum)))
for i := range vec {
vec[i] /= norm
}
}
return vec
}
4.4 Vector Database Interface Implementation
// internal/memory/vector_store.go
package memory
import (
"context"
"fmt"
"time"
"agent-memory/internal/model"
"github.com/milvus-io/milvus-sdk-go/v2/client"
"github.com/milvus-io/milvus-sdk-go/v2/entity"
)
// VectorStore manages vector database storage
type VectorStore struct {
client client.Client
collection string
dim int // Vector dimension
}
// NewVectorStore creates a vector database client
func NewVectorStore(endpoint, collection string, dim int) (*VectorStore, error) {
ctx := context.Background()
c, err := client.NewClient(ctx, client.Config{
Address: endpoint,
})
if err != nil {
return nil, fmt.Errorf("failed to create Milvus client: %w", err)
}
// Check if collection exists, create if not
has, err := c.HasCollection(ctx, collection)
if err != nil {
return nil, fmt.Errorf("failed to check collection: %w", err)
}
if !has {
// Create collection
schema := &entity.Schema{
CollectionName: collection,
Fields: []*entity.Field{
{Name: "id", DataType: entity.FieldTypeVarChar, IsPrimaryKey: true, MaxLength: 36},
{Name: "vector", DataType: entity.FieldTypeFloatVector, Dim: dim},
{Name: "timestamp", DataType: entity.FieldTypeInt64},
{Name: "entity", DataType: entity.FieldTypeVarChar, MaxLength: 128},
{Name: "relation", DataType: entity.FieldTypeVarChar, MaxLength: 64},
{Name: "content", DataType: entity.FieldTypeVarChar, MaxLength: 4096},
{Name: "priority", DataType: entity.FieldTypeInt32},
},
}
err = c.CreateCollection(ctx, schema, 2) // 2 shards
if err != nil {
return nil, fmt.Errorf("failed to create collection: %w", err)
}
// Create index
idx, _ := entity.NewIndexIvfFlat(entity.L2, 128)
err = c.CreateIndex(ctx, collection, "vector", idx, false)
if err != nil {
return nil, fmt.Errorf("failed to create index: %w", err)
}
}
return &VectorStore{
client: c,
collection: collection,
dim: dim,
}, nil
}
// Insert inserts a memory into the vector database
func (vs *VectorStore) Insert(ctx context.Context, memory *model.Memory) error {
// Build insert data
idColumn := entity.NewColumnVarChar("id", []string{memory.ID})
vectorColumn := entity.NewColumnFloatVector("vector", vs.dim, [][]float32{memory.Vector})
timestampColumn := entity.NewColumnInt64("timestamp", []int64{memory.Timestamp.Unix()})
entityColumn := entity.NewColumnVarChar("entity", []string{memory.Entity})
relationColumn := entity.NewColumnVarChar("relation", []string{memory.Relation})
contentColumn := entity.NewColumnVarChar("content", []string{memory.Content})
priorityColumn := entity.NewColumnInt32("priority", []int32{int32(memory.Priority)})
_, err := vs.client.Insert(ctx, vs.collection, "",
idColumn, vectorColumn, timestampColumn,
entityColumn, relationColumn, contentColumn, priorityColumn)
if err != nil {
return fmt.Errorf("failed to insert memory: %w", err)
}
// Flush data
err = vs.client.Flush(ctx, vs.collection, false)
if err != nil {
return fmt.Errorf("failed to flush data: %w", err)
}
return nil
}
// Search retrieves similar memories
// Parameters: query vector, Top-K count, filter condition
func (vs *VectorStore) Search(ctx context.Context, queryVec []float32, topK int, filter string) ([]*model.Memory, error) {
// Build search parameters
searchParams, _ := entity.NewIndexIvfFlatSearchParam(128)
// Execute search
results, err := vs.client.Search(
ctx,
vs.collection,
nil,
"",
[]string{"id", "timestamp", "entity", "relation", "content", "priority"},
[]entity.Vector{entity.FloatVector(queryVec)},
"vector",
entity.L2,
topK,
searchParams,
)
if err != nil {
return nil, fmt.Errorf("failed to search memories: %w", err)
}
// Parse results
memories := make([]*model.Memory, 0, topK)
for _, result := range results {
for i := 0; i < result.ResultCount; i++ {
memory := &model.Memory{
ID: result.Fields.Get("id").(*entity.ColumnVarChar).Data()[i],
Timestamp: time.Unix(result.Fields.Get("timestamp").(*entity.ColumnInt64).Data()[i], 0),
Entity: result.Fields.Get("entity").(*entity.ColumnVarChar).Data()[i],
Relation: result.Fields.Get("relation").(*entity.ColumnVarChar).Data()[i],
Content: result.Fields.Get("content").(*entity.ColumnVarChar).Data()[i],
Priority: int(result.Fields.Get("priority").(*entity.ColumnInt32).Data()[i]),
}
memories = append(memories, memory)
}
}
return memories, nil
}
// Delete deletes a memory
func (vs *VectorStore) Delete(ctx context.Context, memoryID string) error {
expr := fmt.Sprintf("id == '%s'", memoryID)
err := vs.client.Delete(ctx, vs.collection, "", expr)
if err != nil {
return fmt.Errorf("failed to delete memory: %w", err)
}
return nil
}
4.5 Memory Transfer Logic
// internal/memory/transfer.go
package memory
import (
"context"
"fmt"
"time"
"agent-memory/internal/model"
"github.com/google/uuid"
)
// MemoryTransfer manages memory transfer
type MemoryTransfer struct {
lstmWorker *LSTMWorker
vectorStore *VectorStore
embeddingSvc *EmbeddingService
transferThreshold float64 // Transfer threshold (working memory usage)
}
// NewMemoryTransfer creates a memory transfer manager
func NewMemoryTransfer(lstm *LSTMWorker, vs *VectorStore, emb *EmbeddingService) *MemoryTransfer {
return &MemoryTransfer{
lstmWorker: lstm,
vectorStore: vs,
embeddingSvc: emb,
transferThreshold: 0.8, // Trigger transfer when usage exceeds 80%
}
}
// TransferToLongTerm transfers working memory to long-term memory
// Parameters: session state, current context
// Returns: number of memories transferred
func (mt *MemoryTransfer) TransferToLongTerm(ctx context.Context, state *model.SessionState) (int, error) {
if state == nil {
return 0, fmt.Errorf("session state is nil")
}
// Calculate usage rate
usageRate := float64(state.TokenCount) / float64(state.MaxTokens)
if usageRate < mt.transferThreshold {
return 0, nil // Threshold not reached
}
// Extract important memories (based on LSTM state and priority)
importantMemories := mt.extractImportantMemories(state)
// Encode and write to long-term memory
transferCount := 0
for _, memory := range importantMemories {
// Generate vector
vector, err := mt.embeddingSvc.Encode(memory.Content)
if err != nil {
continue
}
memory.Vector = vector
memory.ID = uuid.New().String()
memory.Timestamp = time.Now()
// Write to vector database
err = mt.vectorStore.Insert(ctx, memory)
if err != nil {
return transferCount, fmt.Errorf("failed to write to long-term memory: %w", err)
}
transferCount++
}
// Clean working memory (retain last 20% of context)
mt.cleanWorkingMemory(state)
return transferCount, nil
}
// extractImportantMemories extracts important memories from working memory
func (mt *MemoryTransfer) extractImportantMemories(state *model.SessionState) []*model.Memory {
memories := make([]*model.Memory, 0)
// Analyze importance based on LSTM state
// In production, use more complex attention mechanisms
for i, content := range state.Context {
// Calculate content importance (simplified: based on length and position)
importance := float64(len(content)) / 1000.0
if i == len(state.Context)-1 {
importance *= 2 // Double weight for newest content
}
// Extract entity and relation (simplified: using regex or NLP service)
entity, relation := mt.extractEntityRelation(content)
// Only retain memories with importance above threshold
if importance > 0.5 {
memory := &model.Memory{
SessionID: state.SessionID,
Content: content,
Entity: entity,
Relation: relation,
Priority: int(importance * 10),
}
memories = append(memories, memory)
}
}
return memories
}
// extractEntityRelation extracts entity and relation (simplified)
func (mt *MemoryTransfer) extractEntityRelation(content string) (string, string) {
// In production, call an NER service
// Here, use simple keyword matching
if len(content) > 50 {
return content[:20], "discussed"
}
return content, "mentioned"
}
// cleanWorkingMemory cleans the working memory
func (mt *MemoryTransfer) cleanWorkingMemory(state *model.SessionState) {
// Retain last 20% of context
retainCount := len(state.Context) / 5
if retainCount < 5 {
retainCount = 5
}
if len(state.Context) > retainCount {
state.Context = state.Context[len(state.Context)-retainCount:]
}
// Reset token count
state.TokenCount = 0
for _, content := range state.Context {
state.TokenCount += len(content) / 4
}
}
4.6 Memory Manager
// internal/memory/manager.go
package memory
import (
"context"
"fmt"
"sync"
"time"
"agent-memory/internal/model"
)
// MemoryManager is the unified entry point for memory management
type MemoryManager struct {
lstmWorker *LSTMWorker
vectorStore *VectorStore
transfer *MemoryTransfer
embeddingSvc *EmbeddingService
mu sync.RWMutex
sessionCache map[string]*model.SessionState // Session cache
}
// NewMemoryManager creates a memory manager
func NewMemoryManager(lstm *LSTMWorker, vs *VectorStore, emb *EmbeddingService) *MemoryManager {
return &MemoryManager{
lstmWorker: lstm,
vectorStore: vs,
transfer: NewMemoryTransfer(lstm, vs, emb),
embeddingSvc: emb,
sessionCache: make(map[string]*model.SessionState),
}
}
// ProcessInput processes user input (core entry point)
// Parameters: sessionID - session ID, input - user input
// Returns: enhanced context for LLM inference
func (mm *MemoryManager) ProcessInput(ctx context.Context, sessionID, input string) (string, error) {
// 1. Update working memory
state, err := mm.lstmWorker.UpdateState(sessionID, input)
if err != nil && err != ErrMemoryFull {
return "", fmt.Errorf("failed to update working memory: %w", err)
}
// 2. If memory is full, trigger transfer
if err == ErrMemoryFull {
count, transferErr := mm.transfer.TransferToLongTerm(ctx, state)
if transferErr != nil {
return "", fmt.Errorf("failed to transfer memory: %w", transferErr)
}
fmt.Printf("Transferred %d memories to long-term storage\n", count)
}
// 3. Retrieve relevant long-term memories
queryVec, err := mm.embeddingSvc.Encode(input)
if err != nil {
return "", fmt.Errorf("failed to encode query: %w", err)
}
longTermMemories, err := mm.vectorStore.Search(ctx, queryVec, 5, "")
if err != nil {
return "", fmt.Errorf("failed to retrieve long-term memories: %w", err)
}
// 4. Assemble enhanced context
enhancedContext := mm.assembleContext(state, longTermMemories)
return enhancedContext, nil
}
// assembleContext assembles the enhanced context
func (mm *MemoryManager) assembleContext(state *model.SessionState, memories []*model.Memory) string {
context := ""
// Add long-term memories
if len(memories) > 0 {
context += "### Related Historical Memories:\n"
for i, m := range memories {
context += fmt.Sprintf("%d. [%s] %s\n", i+1, m.Timestamp.Format("2006-01-02"), m.Content)
}
context += "\n"
}
// Add current session context
context += "### Current Conversation Context:\n"
for _, c := range state.Context {
context += c + "\n"
}
return context
}
// SaveSession saves session state to cache
func (mm *MemoryManager) SaveSession(sessionID string, state *model.SessionState) {
mm.mu.Lock()
defer mm.mu.Unlock()
mm.sessionCache[sessionID] = state
}
// LoadSession loads session state from cache
func (mm *MemoryManager) LoadSession(sessionID string) (*model.SessionState, bool) {
mm.mu.RLock()
defer mm.mu.RUnlock()
state, exists := mm.sessionCache[sessionID]
return state, exists
}
5. Performance Optimization
5.1 Vector Retrieval Optimization
Vector retrieval is the performance bottleneck of the system. For large-scale memories (millions), we adopt the following optimizations:
- Index Selection: Use IVF_FLAT index, nlist=4096, nprobe=64.
- Quantization Compression: PQ (Product Quantization) compresses vectors to 32 bytes, improving retrieval speed by 5x.
- Partitioning Strategy: Partition by entity type, scan only relevant partitions during retrieval.
// Create optimized index
func createOptimizedIndex(ctx context.Context, c client.Client, collection string) error {
// Use IVF_SQ8 quantization index, memory usage reduced by 75%
idx, err := entity.NewIndexIvfSq8(entity.L2, 4096)
if err != nil {
return err
}
return c.CreateIndex(ctx, collection, "vector", idx, false)
}
5.2 Working Memory Optimization
- LSTM State Compression: Use low-precision floating point (FP16) for hidden state storage, reducing memory by 50%.
- Incremental Updates: Only update changed sessions, avoiding full computation.
- Session Pooling: Reuse idle sessions, reducing memory allocation.
5.3 Caching Strategy
- Hot Memory Cache: Redis caches Top-100 memories from the last hour.
- Session State Cache: LRU cache, retaining a maximum of 10,000 sessions.
- Vector Cache: Cache query vectors to avoid repeated encoding.
5.4 Asynchronous Processing
- Asynchronous Memory Transfer: Use message queues (Kafka) for asynchronous memory transfer processing.
- Asynchronous Vector Encoding: Batch encoding to reduce latency.
- Asynchronous Memory Merging: Background periodic merging of similar memories.
6. Production Practices
6.1 Deployment Architecture
┌─────────────────────────────────────────────┐
│ Load Balancer (Nginx) │
└────────────────┬────────────────────────────┘
│
┌────────────┴────────────┐
│ Agent Service Cluster (K8s) │
│ ┌──────────────────┐ │
│ │ Memory Manager Pod│ │
│ │ LSTM Worker │ │
│ │ Vector Client │ │
│ └──────────────────┘ │
└────────────┬────────────┘
│
┌────────────┴────────────┐
│ Milvus Cluster │
│ ┌─────┐ ┌─────┐ │
│ │Node1│ │Node2│ ... │
│ └─────┘ └─────┘ │
└─────────────────────────┘
6.2 Configuration Management
# config.yaml
memory:
lstm:
input_dim: 768
hidden_dim: 512
max_tokens: 4096
transfer_threshold: 0.8
vector_store:
endpoint: "milvus-cluster:19530"
collection: "agent_memories"
dimension: 768
index_type: "IVF_SQ8"
cache:
redis_endpoint: "redis-cluster:6379"
session_ttl: 3600
memory_ttl: 86400
performance:
batch_size: 64
async_transfer: true
num_workers: 4
6.3 Monitoring Metrics
Memory System Metrics:
- Total memories, creation rate, query QPS.
- Memory transfer frequency, average latency.
- Cache hit rate, memory usage.
Performance Metrics:
- Vector retrieval P99 latency (target <50ms).
- Working memory update latency (target <10ms).
- Memory transfer success rate (target >99.9%).
Business Metrics:
- Context recall rate (target >90%).
- User satisfaction (target >4.5/5).
- Task completion rate improvement (target >30%).
6.4 Fault Handling
- Vector Database Outage: Degrade to pure working memory mode.
- LSTM State Loss: Rebuild working memory from long-term memory.
- Memory Retrieval Failure: Return empty context, log error.
- Data Consistency: Use distributed transactions to ensure atomicity of memory writes.
6.5 Practical Case: Intelligent Customer Service System
In an e-commerce platform’s intelligent customer service system, we deployed this memory persistence architecture:
- Scenario: Users inquiring about order status, return/exchange processes.
- Results:
- First-contact resolution rate increased from 65% to 92%.
- User repeat inquiry volume decreased by 40%.
- Average dialogue rounds reduced from 8 to 3.
Key Optimizations:
- Pre-encode common questions (FAQ) as long-term memories.
- Store user historical behavior (browsing, purchases) as entity relations.
- Support cross-session “context recovery,” users do not need to repeatedly describe issues.
7. Conclusion
This article has provided a detailed introduction to the “memory persistence” architecture upgrade for autonomous AI Agents. By fusing LSTM with vector databases, we have constructed a hierarchical memory system:
- Working Memory (LSTM): Handles immediate context within the current session for fast response.
- Long-Term Memory (Vector Database): Stores key knowledge across sessions persistently.
- Memory Transfer: The dynamic transformation mechanism between the two.
Core Advantages:
- Continuity: Agents can maintain key context across sessions, enabling truly continuous autonomous tasks.
- Scalability: Supports rapid retrieval of millions of memories.
- Flexibility: Adapts to various business scenarios, from customer service to project management.
Future Outlook:
- Memory Compression: Use knowledge distillation to compress large volumes of memories into compact representations.
- Emotional Memory: Record user emotional states for more humanized interaction.
- Multimodal Memory: Support memory for images, audio, and other modalities.
As AI Agents evolve toward greater complexity and autonomy, memory persistence will become an indispensable infrastructure component. We hope this article provides valuable references for developers and helps advance the evolution of AI Agents.