Huawei Cloud Agentic Infra: A Deep Dive into the New Paradigm for Enterprise AI Infrastructure
Summary
On June 5, 2026, Huawei Cloud INSPIRE Innovators Conference opened at the Shanghai International Convention Center. Themed “Intelligence Ascension, Imagine Future,” this landmark event witnessed Huawei Cloud’s official launch of the Agentic Infra (Intelligent Agent Infrastructure) New Paradigm - a comprehensive architecture that marks the formal entry of enterprise AI infrastructure into the “Agentic Era.”
This article provides an in-depth technical analysis of Huawei Cloud’s Agentic Infra, examining its core components, architectural innovations, and practical implementation strategies. We’ll explore the four foundational pillars, four flagship products, and their applications across healthcare, manufacturing, robotics, and scientific computing domains.
1. Introduction: The Paradigm Shift in AI Infrastructure
1.1 The Evolution from Tools to Agents
The traditional AI infrastructure stack has focused on three primary dimensions:
- Compute Supply: GPU/TPU clusters for training and inference
- Model Services: Inference endpoints, model registries, A/B testing frameworks
- Data Management: Feature stores, vector databases, data versioning
However, the explosive advancement of Large Language Models (LLMs) has fundamentally changed the landscape. Modern AI applications are evolving from simple “tools” into sophisticated “agents” capable of:
Traditional AI Systems:
├── Single request-response pattern
├── Fixed prompt inputs
├── Stateless or weakly stateful
└── Task granularity: atomic, single-step
Agentic AI Systems:
├── Multi-turn conversations and continuous dialogue
├── Dynamic context construction
├── Strong state memory with retrieval
├── Task granularity: complex, long-horizon, multi-step
├── Autonomous planning and tool invocation
└── Goal-oriented behavior with reflection
This evolution demands a fundamentally different infrastructure approach - one that can manage long-horizon tasks, maintain persistent memory, coordinate multiple AI models, and ensure security and compliance.
1.2 The Agentic Infra Vision
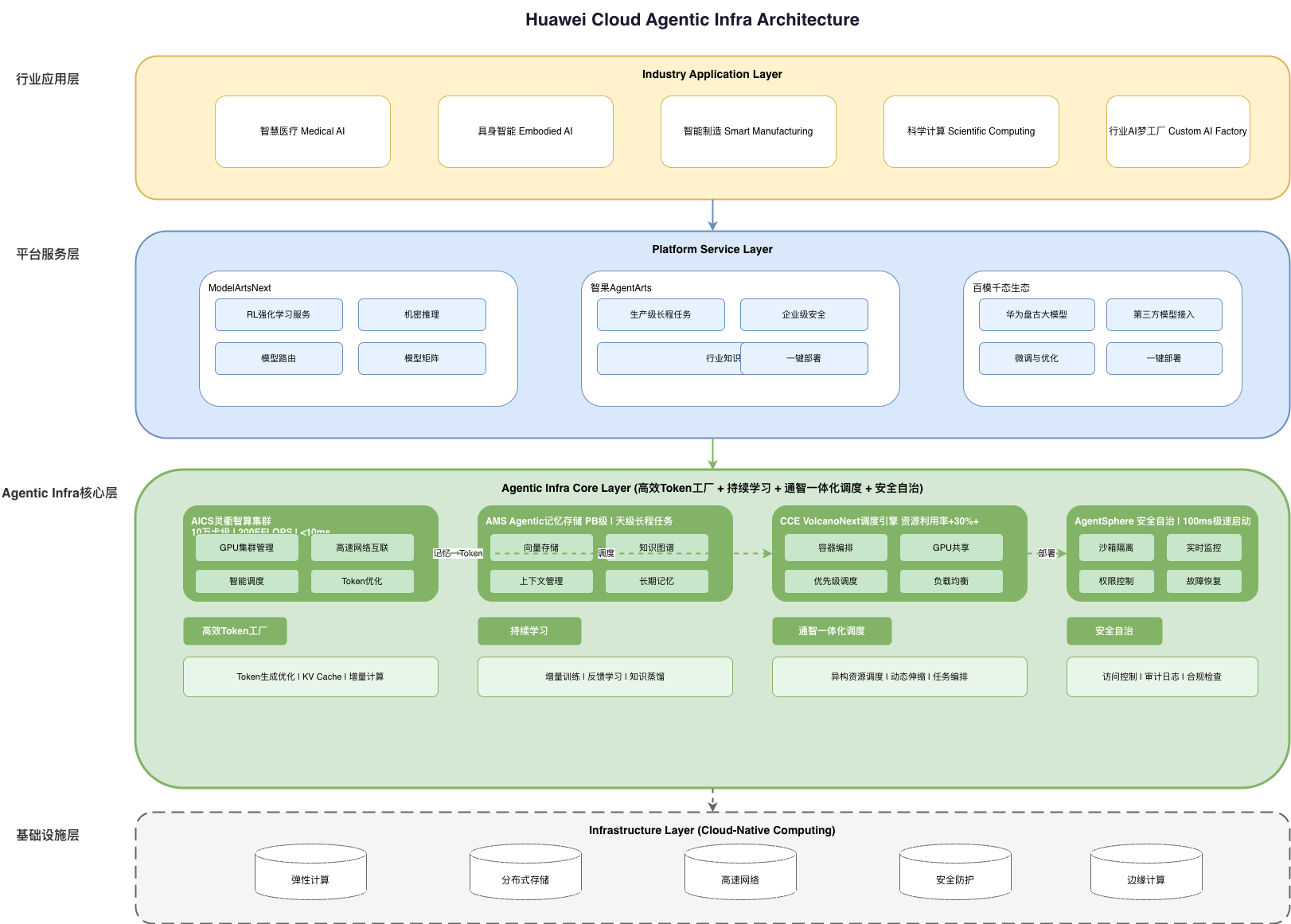
Huawei Cloud’s Agentic Infra represents a comprehensive solution to these challenges, built around four core capabilities:
- Efficient Token Factory - Optimized token generation with sub-10ms latency
- Continuous Learning - Incremental training and knowledge updates without full retraining
- Converged Scheduling - Unified orchestration across general and AI-specific computing
- Secure Autonomy - Trustworthy execution environment for AI agents
These capabilities are backed by four flagship products:
- AICS (Lingqu) Intelligent Computing Cluster
- AMS Agentic Memory Storage
- CCE VolcanoNext Scheduler Engine
- AgentSphere Secure Runtime
2. Technical Deep Dive
2.1 AICS Lingqu Intelligent Computing Cluster
The AICS (AI Computing Scheduler Intelligence) cluster represents Huawei Cloud’s next-generation AI-native computing infrastructure, with specifications that set new industry benchmarks:
| Specification | Value |
|---|---|
| Cluster Scale | 100,000+ GPUs |
| Total Compute | 200 EFLOPS |
| Token Inference Latency | <10ms |
| Network Bandwidth | 800Gbps RoCEv2 |
| Storage Throughput | 10TB/s |
2.1.1 Hierarchical Architecture Design
AICS employs a layered, decoupled architecture enabling independent elastic scaling of compute, network, and storage resources:
# Python: AICS Cluster Resource Scheduler Simulation
from dataclasses import dataclass
from typing import List, Dict, Optional
from enum import Enum
import asyncio
from heapq import heappush, heappop
class NodeStatus(Enum):
IDLE = "idle"
RUNNING = "running"
DRAINING = "draining"
MAINTENANCE = "maintenance"
class WorkloadPriority(Enum):
LOW = 3
NORMAL = 2
HIGH = 1
CRITICAL = 0
@dataclass
class ComputeNode:
node_id: str
gpu_count: int
gpu_memory_gb: int
bandwidth_gbps: float
status: NodeStatus = NodeStatus.IDLE
current_load: float = 0.0
def can_allocate(self, required_gpus: int, required_memory: int) -> bool:
"""Check if node can satisfy resource requirements"""
return (self.status == NodeStatus.IDLE and
self.gpu_count >= required_gpus and
self.gpu_memory_gb >= required_memory)
def allocation_score(self, required_gpus: int, priority: WorkloadPriority) -> float:
"""Calculate allocation score for scheduling decision"""
# Prefer nodes with better bandwidth for high-priority tasks
bandwidth_factor = self.bandwidth_gbps / 800.0
# Prefer less loaded nodes for load balancing
load_factor = 1.0 - self.current_load
# Priority boost for critical workloads
priority_factor = 1.0 / (priority.value + 1)
return (0.4 * bandwidth_factor +
0.4 * load_factor +
0.2 * priority_factor)
@dataclass
class TaskRequest:
task_id: str
required_gpus: int
required_memory: int
priority: WorkloadPriority
estimated_duration_sec: float
gang_members: int = 1 # For gang scheduling
def __lt__(self, other):
# Priority queue: lower priority value = higher priority
return self.priority.value < other.priority.value
class AICSIntelligentScheduler:
"""
AICS Intelligent Scheduler
Key Features:
- Gang Scheduling: All-or-Nothing for distributed training
- Bin-packing: Compact allocation to reduce fragmentation
- DRFQ: Dominant Resource Fairness for multi-tenant environments
- Load-aware: Real-time load consideration
"""
def __init__(self):
self.nodes: Dict[str, ComputeNode] = {}
self.task_queue: List[TaskRequest] = []
self.running_tasks: Dict[str, str] = {} # task_id -> node_id
self.task_history: List[Dict] = []
def register_node(self, node: ComputeNode) -> None:
"""Register a compute node with the cluster"""
self.nodes[node.node_id] = node
print(f"[AICS] Registered node {node.node_id}: "
f"{node.gpu_count} GPUs, {node.bandwidth_gbps} Gbps")
async def submit_task(self, task: TaskRequest) -> Optional[str]:
"""
Submit task and automatically schedule to optimal node
Scheduling Algorithm:
1. Priority-based queue ordering
2. Resource matching with gang scheduling support
3. Affinity optimization for intra-task GPU communication
"""
# Find suitable nodes
candidates = []
for node_id, node in self.nodes.items():
if node.can_allocate(task.required_gpus, task.required_memory):
# For gang scheduling, check if we can allocate contiguous GPUs
if task.gang_members > 1:
if not self._check_gpu_affinity(node, task.required_gpus,
task.gang_members):
continue
score = node.allocation_score(task.required_gpus, task.priority)
candidates.append((node_id, score, node))
if not candidates:
# No suitable node - add to queue
heappush(self.task_queue, task)
print(f"[AICS] Task {task.task_id} queued (no suitable node)")
return None
# Select best candidate
candidates.sort(key=lambda x: x[1], reverse=True)
selected_node_id = candidates[0][0]
return await self._allocate_task(task, selected_node_id)
async def _allocate_task(self, task: TaskRequest, node_id: str) -> str:
"""Execute task allocation"""
node = self.nodes[node_id]
node.status = NodeStatus.RUNNING
node.current_load = min(1.0, node.current_load +
task.required_gpus / node.gpu_count)
self.running_tasks[task.task_id] = node_id
print(f"[AICS] Task {task.task_id} allocated to {node_id}")
print(f"[AICS] Estimated completion: {task.estimated_duration_sec}s")
# Log task submission
self.task_history.append({
"task_id": task.task_id,
"node_id": node_id,
"timestamp": asyncio.get_event_loop().time(),
"priority": task.priority.name
})
return node_id
def _check_gpu_affinity(self, node: ComputeNode,
gpus_per_task: int,
gang_size: int) -> bool:
"""
Check GPU affinity for distributed training
GPUs connected via NVSwitch provide all-to-all connectivity
GPUs on same PCIe switch have high bandwidth
"""
available = node.gpu_count
# Simplified: just check if we have enough contiguous GPUs
return available >= gpus_per_task * gang_size
def get_cluster_metrics(self) -> Dict:
"""Get comprehensive cluster metrics"""
total_gpus = sum(n.gpu_count for n in self.nodes.values())
running_gpus = sum(
n.gpu_count * n.current_load for n in self.nodes.values()
)
return {
"total_nodes": len(self.nodes),
"total_gpus": total_gpus,
"gpu_utilization": running_gpus / total_gpus if total_gpus > 0 else 0,
"queued_tasks": len(self.task_queue),
"running_tasks": len(self.running_tasks),
"average_load": sum(n.current_load for n in self.nodes.values()) /
len(self.nodes) if self.nodes else 0
}
async def process_queue(self):
"""Process queued tasks as nodes become available"""
while self.task_queue:
# Sort queue by priority
sorted_queue = sorted(self.task_queue)
for task in sorted_queue:
node_id = await self.submit_task(task)
if node_id:
self.task_queue.remove(task)
break
await asyncio.sleep(0.1) # Prevent tight loop
async def demo_aics_cluster():
"""Demonstrate AICS cluster scheduling"""
scheduler = AICSIntelligentScheduler()
# Register a large-scale cluster (simulated)
for i in range(50):
node = ComputeNode(
node_id=f"compute-node-{i:03d}",
gpu_count=8,
gpu_memory_gb=640, # 80GB per GPU
bandwidth_gbps=800.0,
status=NodeStatus.IDLE
)
scheduler.register_node(node)
# Submit diverse AI workloads
workloads = [
# Distributed training jobs (gang scheduling)
TaskRequest("train-llm-001", required_gpus=32, required_memory=2560,
priority=WorkloadPriority.HIGH,
estimated_duration_sec=3600.0, gang_members=4),
# Batch inference jobs
TaskRequest("infer-batch-001", required_gpus=8, required_memory=640,
priority=WorkloadPriority.NORMAL,
estimated_duration_sec=600.0),
# Real-time inference services
TaskRequest("infer-realtime-001", required_gpus=4, required_memory=320,
priority=WorkloadPriority.CRITICAL,
estimated_duration_sec=0.0), # Long-running service
# Fine-tuning tasks
TaskRequest("finetune-001", required_gpus=16, required_memory=1280,
priority=WorkloadPriority.NORMAL,
estimated_duration_sec=1800.0),
]
print("\n" + "="*60)
print("AICS Cluster Scheduling Demo")
print("="*60 + "\n")
for workload in workloads:
await scheduler.submit_task(workload)
# Display cluster metrics
metrics = scheduler.get_cluster_metrics()
print(f"\n[AICS] Cluster Metrics:")
print(f" Total GPUs: {metrics['total_gpus']}")
print(f" GPU Utilization: {metrics['gpu_utilization']:.2%}")
print(f" Queued Tasks: {metrics['queued_tasks']}")
print(f" Running Tasks: {metrics['running_tasks']}")
asyncio.run(demo_aics_cluster())
2.1.2 Token Factory Optimizations
AICS achieves <10ms inference latency through several innovative techniques:
- Multi-level KV Cache: Hot data in HBM, warm data in CXL memory
- Incremental Decoding: Only compute newly generated tokens
- Speculative Decoding: Small model prediction + large model verification
- Dynamic Batching: Adaptive batch size based on request length
2.2 AMS Agentic Memory Storage
AMS (Agentic Memory Service) is Huawei Cloud’s memory system designed specifically for AI agents. Its core innovation lies in unified multi-modal memory management.
2.2.1 Multi-Layer Memory Architecture
# Python: AMS Long-Horizon Memory Management
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Any
from datetime import datetime, timedelta
from enum import Enum
import json
import hashlib
class MemoryTier(Enum):
"""Memory hierarchy levels"""
WORKING = "working" # Current session context
EPISODIC = "episodic" # Event sequences
SEMANTIC = "semantic" # Knowledge graph
LONG_TERM = "long_term" # Persistent storage
@dataclass
class MemoryEntry:
"""Single memory entry with rich metadata"""
entry_id: str
content: str
tier: MemoryTier
embedding: List[float] = field(default_factory=list)
importance: float = 0.5 # 0.0 to 1.0
created_at: datetime = field(default_factory=datetime.now)
last_accessed: datetime = field(default_factory=datetime.now)
access_count: int = 0
metadata: Dict[str, Any] = field(default_factory=dict)
def access(self) -> None:
"""Update access statistics"""
self.last_accessed = datetime.now()
self.access_count += 1
# Boost importance for frequently accessed memories
self.importance = min(1.0, self.importance + 0.01)
@dataclass
class MemoryCheckpoint:
"""Checkpoint for long-horizon task state"""
checkpoint_id: str
task_id: str
timestamp: datetime
state: Dict[str, Any]
memories: List[str] # Memory IDs included
reflection: str # Agent's self-reflection
class AgentMemoryStore:
"""
Agentic Memory Store - Core Interface
Design Philosophy:
- "Memory is Context, Context is Intelligence"
- Multi-tier architecture for cost-performance balance
- Importance-weighted retention and retrieval
"""
def __init__(self, vector_dim: int = 1536):
self.vector_dim = vector_dim
# Storage layers (simplified simulation)
self.working_memory: Dict[str, MemoryEntry] = {} # In-memory
self.episodic_memory: Dict[str, MemoryEntry] = {} # Redis-like
self.semantic_memory: Dict[str, MemoryEntry] = {} # Vector DB
self.long_term_memory: Dict[str, MemoryEntry] = {} # Distributed storage
# Index structures
self.embedding_index: Dict[str, List[float]] = {}
self.importance_index: List[str] = [] # Sorted by importance
def store(self, content: str, tier: MemoryTier,
metadata: Optional[Dict] = None) -> MemoryEntry:
"""Store a new memory entry"""
entry_id = self._generate_id(content)
entry = MemoryEntry(
entry_id=entry_id,
content=content,
tier=tier,
metadata=metadata or {}
)
# Generate embedding (simplified)
entry.embedding = self._generate_embedding(content)
# Store in appropriate tier
storage = self._get_storage(tier)
storage[entry_id] = entry
# Update indices
self.embedding_index[entry_id] = entry.embedding
self._update_importance_index(entry)
print(f"[AMS] Stored memory {entry_id[:8]}... in {tier.value} tier")
return entry
def retrieve(self, query: str, top_k: int = 5,
tiers: Optional[List[MemoryTier]] = None) -> List[MemoryEntry]:
"""
Retrieve relevant memories using hybrid search
Combines:
1. Semantic similarity (vector search)
2. Recency boost
3. Importance weighting
"""
query_embedding = self._generate_embedding(query)
candidates = []
# Search across specified tiers (default: all)
search_tiers = tiers or list(MemoryTier)
for tier in search_tiers:
storage = self._get_storage(tier)
for entry in storage.values():
similarity = self._cosine_similarity(
query_embedding, entry.embedding
)
# Composite score: similarity + recency + importance
recency_score = self._recency_score(entry)
importance_weight = entry.importance
composite_score = (
0.5 * similarity +
0.3 * recency_score +
0.2 * importance_weight
)
candidates.append((entry, composite_score))
# Sort by composite score and return top-k
candidates.sort(key=lambda x: x[1], reverse=True)
results = [entry for entry, _ in candidates[:top_k]]
# Update access statistics
for entry in results:
entry.access()
return results
def create_checkpoint(self, task_id: str, state: Dict,
reflection: str) -> MemoryCheckpoint:
"""Create a task checkpoint for recovery"""
# Gather all relevant memories for this task
task_memories = [
entry.entry_id for entry in self.working_memory.values()
if entry.metadata.get("task_id") == task_id
]
checkpoint = MemoryCheckpoint(
checkpoint_id=f"cp_{task_id}_{len(task_memories)}",
task_id=task_id,
timestamp=datetime.now(),
state=state,
memories=task_memories,
reflection=reflection
)
print(f"[AMS] Created checkpoint {checkpoint.checkpoint_id}")
return checkpoint
def compress_memories(self, session_id: str,
max_memories: int = 100,
min_importance: float = 0.3) -> int:
"""
Compress memories to prevent context overflow
Strategy:
1. Remove low-importance memories
2. Merge similar memories
3. Retain recent memories
4. Enforce maximum count
"""
session_memories = [
entry for entry in self.working_memory.values()
if entry.metadata.get("session_id") == session_id
]
initial_count = len(session_memories)
# Filter by importance
important_memories = [
m for m in session_memories
if m.importance >= min_importance
]
# Sort by importance and recency
important_memories.sort(
key=lambda m: (m.importance, m.last_accessed),
reverse=True
)
# Truncate to max
retained_memories = important_memories[:max_memories]
# Update storage
to_remove = set(m.entry_id for m in session_memories) - \
set(m.entry_id for m in retained_memories)
for entry_id in to_remove:
del self.working_memory[entry_id]
removed_count = initial_count - len(retained_memories)
print(f"[AMS] Compressed {removed_count} memories, "
f"retained {len(retained_memories)}")
return removed_count
def _generate_id(self, content: str) -> str:
"""Generate unique memory ID"""
return hashlib.sha256(
f"{content}{datetime.now().isoformat()}".encode()
).hexdigest()
def _generate_embedding(self, text: str) -> List[float]:
"""Generate embedding vector (simplified)"""
# In production: use proper embedding model
import random
return [random.random() for _ in range(self.vector_dim)]
def _cosine_similarity(self, a: List[float], b: List[float]) -> float:
"""Calculate cosine similarity between vectors"""
dot = sum(x * y for x, y in zip(a, b))
norm_a = sum(x * x for x in a) ** 0.5
norm_b = sum(x * x for x in b) ** 0.5
return dot / (norm_a * norm_b + 1e-8)
def _recency_score(self, entry: MemoryEntry) -> float:
"""Calculate recency score (0-1)"""
age = datetime.now() - entry.last_accessed
# Exponential decay with 1-hour half-life
return 0.5 ** (age.total_seconds() / 3600)
def _get_storage(self, tier: MemoryTier) -> Dict[str, MemoryEntry]:
"""Get storage dict for memory tier"""
return {
MemoryTier.WORKING: self.working_memory,
MemoryTier.EPISODIC: self.episodic_memory,
MemoryTier.SEMANTIC: self.semantic_memory,
MemoryTier.LONG_TERM: self.long_term_memory,
}[tier]
def _update_importance_index(self, entry: MemoryEntry):
"""Update importance-sorted index"""
# In production: use proper priority queue
if entry.entry_id not in self.importance_index:
self.importance_index.append(entry.entry_id)
self.importance_index.sort(
key=lambda e: self.working_memory.get(e, MemoryEntry("", "", MemoryTier.WORKING)).importance,
reverse=True
)
# Demonstration: Long-horizon task with memory
async def demo_long_horizon_task():
"""
Demonstrate long-horizon task with memory management
Simulates a multi-day data analysis project where
the agent needs to maintain context across sessions
"""
memory_store = AgentMemoryStore()
print("="*60)
print("Long-Horizon Task Memory Demo")
print("="*60 + "\n")
# Session 1: Initial data collection
print("Session 1: Data Collection")
memory_store.store(
"Collected 5 data sources totaling 1.2TB of raw data",
tier=MemoryTier.EPISODIC,
metadata={"task": "data_analysis", "session": 1}
)
memory_store.store(
"Data quality looks good, but need to supplement with third-party data",
tier=MemoryTier.SEMANTIC,
metadata={"task": "data_analysis", "insight": True}
)
# Session 2: Data cleaning
print("\nSession 2: Data Cleaning")
memory_store.store(
"Completed data cleaning, quality score 0.85, data reduced to 800GB",
tier=MemoryTier.EPISODIC,
metadata={"task": "data_analysis", "session": 2}
)
# Retrieve relevant context before continuing
context = memory_store.retrieve("What data have we collected?", top_k=3)
print(f"\nRetrieved context: {len(context)} relevant memories")
# Create checkpoint for potential recovery
checkpoint = memory_store.create_checkpoint(
task_id="data_analysis",
state={"phase": "cleaning", "quality_score": 0.85},
reflection="Data quality is acceptable. Need to handle missing values."
)
# Session 3: Feature engineering
print("\nSession 3: Feature Engineering")
memory_store.store(
"Completed 156 feature constructions including temporal and cross features",
tier=MemoryTier.EPISODIC,
metadata={"task": "data_analysis", "session": 3}
)
# Query overall task progress
progress_context = memory_store.retrieve(
"data analysis project progress",
top_k=5
)
print(f"\nTask Progress Summary:")
for entry in progress_context:
print(f" - [{entry.tier.value}] {entry.content[:60]}...")
# Memory compression check
memory_store.compress_memories(
session_id="data_analysis",
max_memories=50,
min_importance=0.4
)
asyncio.run(demo_long_horizon_task())
2.3 CCE VolcanoNext: Converged Scheduling Engine
CCE VolcanoNext is Huawei Cloud’s next-generation scheduler for AI workloads, built on the principle of “converged intelligence” - breaking down barriers between general-purpose and AI-specific computing.
2.3.1 Advanced Scheduling Strategies
# Python: VolcanoNext Scheduling Strategy Implementation
from typing import List, Tuple, Dict, Optional
from dataclasses import dataclass
from enum import Enum
import numpy as np
class WorkloadCategory(Enum):
TRAINING = "training" # Distributed training
INFERENCE = "inference" # Real-time inference
FINE_TUNING = "fine_tuning" # Model fine-tuning
BATCH = "batch" # Batch processing
@dataclass
class SchedulingDecision:
"""Scheduling decision result"""
pod_id: str
node_id: str
gpu_allocation: List[int]
composite_score: float
wait_time: float
@dataclass
class SchedulingPolicy:
"""Configurable scheduling policy weights"""
utilization_weight: float = 0.30
affinity_weight: float = 0.25
locality_weight: float = 0.20
fairness_weight: float = 0.15
wait_time_weight: float = 0.10
class VolcanoScheduler:
"""
VolcanoNext Intelligent Scheduler
Core Algorithms:
1. Gang Scheduling: All-or-Nothing for distributed training
2. Bin-packing: Compact allocation to minimize fragmentation
3. DRFQ: Dominant Resource Fairness for multi-tenant
4. Load-aware: Consider real-time node load
5. Topology-aware: NVLink/NVSwitch optimization
"""
def __init__(self, cluster_state: Dict, policy: Optional[SchedulingPolicy] = None):
self.cluster = cluster_state
self.policy = policy or SchedulingPolicy()
self.pending_queue: List[Dict] = []
self.schedule_history: List[SchedulingDecision] = []
def schedule(self, pod_request: Dict) -> Optional[SchedulingDecision]:
"""
Main scheduling entry point
Algorithm Flow:
1. Pre-filter: Remove nodes that can't satisfy requirements
2. Score: Multi-dimensional scoring of candidates
3. Allocate: Select highest-scoring node
"""
workload_type = WorkloadCategory(pod_request.get("workload_type"))
required_gpus = pod_request.get("required_gpus", 0)
# Phase 1: Pre-filtering
candidates = self._pre_filter(pod_request)
if not candidates:
self.pending_queue.append(pod_request)
print(f"[VolcanoNext] No suitable nodes for {pod_request['pod_id']}, queued")
return None
# Phase 2: Multi-dimensional scoring
scored_candidates = []
for node in candidates:
score = self._compute_composite_score(
node, pod_request, workload_type
)
scored_candidates.append((node, score))
# Phase 3: Select optimal node
scored_candidates.sort(key=lambda x: x[1], reverse=True)
selected_node, best_score = scored_candidates[0]
# Phase 4: Execute allocation
decision = self._allocate(pod_request, selected_node, best_score)
return decision
def _pre_filter(self, request: Dict) -> List[Dict]:
"""Filter nodes that can satisfy requirements"""
required_gpus = request.get("required_gpus", 0)
required_memory = request.get("required_memory", 0)
candidates = []
for node in self.cluster["nodes"].values():
if (node["available_gpus"] >= required_gpus and
node["available_memory"] >= required_memory and
node["status"] == "healthy"):
# Gang scheduling validation for training
if request.get("workload_type") == "training":
if not self._validate_gang_scheduling(node, required_gpus):
continue
candidates.append(node)
return candidates
def _validate_gang_scheduling(self, node: Dict,
required: int) -> bool:
"""Validate if node can support gang scheduling"""
available = node["available_gpu_ids"]
if len(available) < required:
return False
# Check for contiguous GPU allocation
sorted_gpus = sorted(available)
for i in range(len(sorted_gpus) - required + 1):
if sorted_gpus[i + required - 1] - sorted_gpus[i] == required - 1:
return True
return False
def _compute_composite_score(self, node: Dict, request: Dict,
workload: WorkloadCategory) -> float:
"""
Compute multi-dimensional composite score
Score Components:
- Utilization: Prefer balanced load distribution
- Affinity: Training prefers same-switch GPUs
- Locality: Inference prefers GPU-direct memory
- Fairness: DRFQ-based fairness
- Wait Time: Priority boost for waiting tasks
"""
scores = {}
# Utilization score (prefer 70% utilization target)
gpu_util = node["gpu_utilization"]
scores["utilization"] = 1.0 - abs(gpu_util - 0.7) / 0.7
# Affinity score (training workloads)
if workload == WorkloadCategory.TRAINING:
scores["affinity"] = self._compute_affinity_score(node, request)
else:
scores["affinity"] = 0.5 # Neutral for non-training
# Memory locality score (inference workloads)
if workload == WorkloadCategory.INFERENCE:
scores["locality"] = node.get("gpu_direct_memory_ratio", 0.5)
else:
scores["locality"] = 0.5
# Fairness score (DRFQ)
scores["fairness"] = self._compute_fairness_score(node, request)
# Wait time compensation
wait_time = request.get("wait_time", 0)
scores["wait_time"] = min(wait_time / 300, 1.0) # Max 5-minute boost
# Weighted composite
w = self.policy
composite = (
w.utilization_weight * scores["utilization"] +
w.affinity_weight * scores["affinity"] +
w.locality_weight * scores["locality"] +
w.fairness_weight * scores["fairness"] +
w.wait_time_weight * scores["wait_time"]
)
return composite
def _compute_affinity_score(self, node: Dict,
request: Dict) -> float:
"""Compute GPU affinity score for training workloads"""
# Simplified: prefer nodes with more available GPUs
# Production: consider NVLink topology, switch domain
gpu_count = node["available_gpus"]
required = request.get("required_gpus", 1)
if gpu_count == required:
return 1.0 # Perfect fit
elif gpu_count > required * 2:
return 0.7 # Some waste
else:
return 0.9
def _compute_fairness_score(self, node: Dict,
request: Dict) -> float:
"""
Compute DRFQ-based fairness score
Dominant Resource Fairness ensures each tenant gets
fair share of their dominant resource
"""
node_share = node["gpu_utilization"]
# Prefer underutilized nodes for fairness
return 1.0 - node_share
def _allocate(self, request: Dict, node: Dict,
score: float) -> SchedulingDecision:
"""Execute resource allocation"""
required_gpus = request.get("required_gpus", 0)
allocated_gpus = node["available_gpu_ids"][:required_gpus]
# Update node state
node["available_gpus"] -= required_gpus
node["available_memory"] -= request.get("required_memory", 0)
node["gpu_utilization"] = (
(node["gpu_count"] - node["available_gpus"]) / node["gpu_count"]
)
node["available_gpu_ids"] = node["available_gpu_ids"][required_gpus:]
decision = SchedulingDecision(
pod_id=request["pod_id"],
node_id=node["node_id"],
gpu_allocation=allocated_gpus,
composite_score=score,
wait_time=request.get("wait_time", 0)
)
self.schedule_history.append(decision)
return decision
# Scheduling Comparison Demonstration
def demo_scheduling_comparison():
"""Compare VolcanoNext vs Traditional Scheduler"""
print("="*60)
print("VolcanoNext vs Traditional Scheduling")
print("="*60 + "\n")
# Simulated cluster
cluster = {
"nodes": {
f"node-{i}": {
"node_id": f"node-{i}",
"gpu_count": 8,
"available_gpus": 8,
"available_memory": 640,
"gpu_utilization": 0.5,
"gpu_direct_memory_ratio": 0.9,
"status": "healthy",
"available_gpu_ids": list(range(8))
}
for i in range(8)
}
}
# Diverse workload mix
workloads = [
{"pod_id": "train-dist-1", "workload_type": "training",
"required_gpus": 8, "priority": "high"},
{"pod_id": "infer-rt-1", "workload_type": "inference",
"required_gpus": 1, "priority": "critical"},
{"pod_id": "train-dist-2", "workload_type": "training",
"required_gpus": 4, "priority": "high"},
{"pod_id": "infer-batch-1", "workload_type": "inference",
"required_gpus": 2, "priority": "normal"},
{"pod_id": "finetune-1", "workload_type": "fine_tuning",
"required_gpus": 2, "priority": "normal"},
{"pod_id": "batch-proc-1", "workload_type": "batch",
"required_gpus": 4, "priority": "low"},
]
scheduler = VolcanoScheduler(cluster)
print("Scheduling Results:")
print("-"*60)
for workload in workloads:
decision = scheduler.schedule(workload)
if decision:
print(f"{workload['pod_id']:15} -> {decision.node_id:10} "
f"(Score: {decision.composite_score:.3f})")
else:
print(f"{workload['pod_id']:15} -> [QUEUED]")
# Cluster utilization analysis
total_gpus = 64 # 8 nodes * 8 GPUs
used_gpus = sum(8 - n["available_gpus"] for n in cluster["nodes"].values())
utilization = used_gpus / total_gpus
print(f"\nCluster Utilization: {utilization:.1%}")
print(f"Queued Workloads: {len(scheduler.pending_queue)}")
print(f"Total Scheduled: {len(scheduler.schedule_history)}")
demo_scheduling_comparison()
2.3.2 30%+ Resource Utilization Improvement
VolcanoNext achieves 30%+ utilization improvement through:
- GPU Time-sharing: Multi-tenant GPU sharing with quota management
- Heterogeneous Co-location: CPU and GPU workloads on same nodes
- Predictive Scaling: Load prediction based on historical patterns
- Topology-aware Scheduling: NVLink/NVSwitch optimization
2.4 AgentSphere: Secure Agent Runtime
AgentSphere is Huawei Cloud’s secure execution environment for AI agents, featuring:
2.4.1 Sandbox Isolation Architecture
package agentsphere
import (
"context"
"fmt"
"time"
"sync"
"github.com/google/uuid"
)
// RuntimeState Agent runtime state
type RuntimeState int
const (
StateInitializing RuntimeState = iota
StateReady
StateRunning
StatePaused
StateTerminating
StateTerminated
)
func (s RuntimeState) String() string {
return []string{
"initializing", "ready", "running",
"paused", "terminating", "terminated",
}[s]
}
// Sandbox security configuration
type SandboxConfig struct {
// Resource limits
CPUPeriod int64 // CPU quota period (microseconds)
CPUQuota int64 // CPU quota
MemoryLimit int64 // Memory limit (bytes)
GPULimit float64 // GPU quota (fraction)
// Network isolation
NetworkMode string // "bridge", "host", "container"
AllowedPorts []int // Allowed inbound ports
// Security profiles
SeccompProfile string // Seccomp profile path
ApparmorProfile string // AppArmor profile
// Capabilities
DropCapabilities []string // Capabilities to drop
AddCapabilities []string // Capabilities to add (rare)
}
// SecurityPolicy Security policy definition
type SecurityPolicy struct {
mu sync.RWMutex
// Tool whitelist
allowedTools map[string]bool
// Resource access limits
MaxMemoryAccess int64 // Max memory bytes per operation
MaxNetworkCalls int // Max outbound calls per minute
MaxFileOperations int // Max file operations per minute
// Data boundaries
AllowDataExfiltration bool
AllowedDataTypes []string
// Audit configuration
AuditLevel AuditLevel
AuditLogEndpoint string
}
type AuditLevel int
const (
AuditNone AuditLevel = iota
AuditErrors
AuditWarnings
AuditAll
)
// AgentRuntime Core agent runtime
type AgentRuntime struct {
runtimeID string
// Core components
sandbox *Sandbox
memoryManager *MemoryManager
toolRegistry *ToolRegistry
securityPolicy *SecurityPolicy
monitor *RuntimeMonitor
// State
state RuntimeState
stateMu sync.RWMutex
// Execution context
currentContext *ExecutionContext
}
// ToolCall represents a tool invocation request
type ToolCall struct {
ToolName string
Arguments map[string]interface{}
Timeout time.Duration
CorrelationID string // For distributed tracing
}
// ToolResult represents tool execution result
type ToolResult struct {
Success bool
Output interface{}
Error error
Duration time.Duration
AuditTrail []AuditEntry
}
// CreateRuntime creates a new agent runtime
func (s *AgentSphere) CreateRuntime(ctx context.Context,
config *RuntimeConfig) (*AgentRuntime, error) {
runtimeID := uuid.New().String()
// 1. Create isolated sandbox
sandbox, err := s.createSandbox(ctx, &config.Sandbox)
if err != nil {
return nil, fmt.Errorf("sandbox creation failed: %w", err)
}
// 2. Initialize security policy
securityPolicy := s.createSecurityPolicy(config.SecurityLevel)
// 3. Create runtime instance
runtime := &AgentRuntime{
runtimeID: runtimeID,
sandbox: sandbox,
memoryManager: NewMemoryManager(),
toolRegistry: s.globalRegistry.Clone(),
securityPolicy: securityPolicy,
monitor: NewMonitor(runtimeID),
state: StateInitializing,
}
// 4. Start monitoring
go runtime.monitor.Start(ctx)
// 5. Health check
if err := runtime.healthCheck(ctx); err != nil {
runtime.Cleanup(ctx)
return nil, fmt.Errorf("health check failed: %w", err)
}
runtime.setState(StateReady)
return runtime, nil
}
// ExecuteTool safely executes a tool within the sandbox
func (r *AgentRuntime) ExecuteTool(ctx context.Context,
call *ToolCall) (*ToolResult, error) {
// 1. Security validation
if err := r.securityPolicy.Validate(call); err != nil {
r.monitor.RecordSecurityEvent("tool_rejected", call.ToolName)
return nil, fmt.Errorf("security policy violation: %w", err)
}
// 2. Tool resolution
tool := r.toolRegistry.Get(call.ToolName)
if tool == nil {
return nil, fmt.Errorf("tool not found: %s", call.ToolName)
}
// 3. Resource check
if err := r.checkResources(call); err != nil {
return nil, fmt.Errorf("resource limit exceeded: %w", err)
}
// 4. Execute within sandbox
start := time.Now()
result, err := r.sandbox.Execute(ctx, tool, call.Arguments)
duration := time.Since(start)
// 5. Record monitoring metrics
r.monitor.RecordToolExecution(call.ToolName, duration, err == nil)
// 6. Build result with audit trail
toolResult := &ToolResult{
Success: err == nil,
Output: result,
Error: err,
Duration: duration,
AuditTrail: r.monitor.GetRecentAudit(call.CorrelationID),
}
return toolResult, nil
}
// Validate performs security validation for tool call
func (p *SecurityPolicy) Validate(call *ToolCall) error {
p.mu.RLock()
defer p.mu.RUnlock()
// Check tool whitelist
if !p.allowedTools[call.ToolName] {
return fmt.Errorf("tool %s not in whitelist", call.ToolName)
}
// Additional validation can be added here
return nil
}
// Cleanup terminates the runtime and releases resources
func (r *AgentRuntime) Cleanup(ctx context.Context) {
r.setState(StateTerminating)
// 1. Stop monitoring
r.monitor.Stop()
// 2. Destroy sandbox
if r.sandbox != nil {
r.sandbox.Destroy(ctx)
}
// 3. Cleanup memory
r.memoryManager.Cleanup()
r.setState(StateTerminated)
}
func (r *AgentRuntime) setState(state RuntimeState) {
r.stateMu.Lock()
defer r.stateMu.Unlock()
r.state = state
}
2.4.2 100ms Ultra-Fast Startup
AgentSphere achieves 100ms startup through:
- Pre-warmed Images: Common tools pre-built into lightweight images
- Sandbox Pooling: Pre-created sandbox pool for instant allocation
- Incremental Loading: On-demand agent component loading
- Memory Snapshots: Runtime snapshots for “hot start”
3. ModelArtsNext and Zhiguo AgentArts Platform
3.1 ModelArtsNext Four Core Capabilities
ModelArtsNext provides enterprise AI development capabilities:
| Capability | Description | Implementation |
|---|---|---|
| RL Training Service | Online/offline reinforcement learning | PPO, SAC algorithms; distributed training |
| Confidential Inference | Privacy-preserving AI inference | TEE; confidential computing |
| Model Routing | Intelligent model selection | Multi-model orchestration; cost-efficiency balance |
| Model Matrix | Multi-model collaboration | Ensemble methods; knowledge distillation |
# Python: ModelArtsNext Intelligent Model Router
from typing import List, Dict, Optional
from dataclasses import dataclass
from enum import Enum
class TaskType(Enum):
GENERATION = "generation"
REASONING = "reasoning"
CLASSIFICATION = "classification"
EXTRACTION = "extraction"
SUMMARIZATION = "summarization"
class ModelComplexity(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
@dataclass
class ModelSpec:
"""Model specification with performance characteristics"""
model_id: str
model_name: str
capabilities: List[TaskType]
cost_per_1k_tokens: float
latency_p50_ms: float
accuracy_score: float
max_context_tokens: int
version: str
class ModelRouter:
"""
ModelArtsNext Intelligent Model Router
Routing Strategy:
1. Task-Model Matching: Match task type to model capability
2. Cost Optimization: Select lowest-cost model meeting requirements
3. Load Balancing: Consider current model load
4. Fallback Strategy: Automatic failover on model unavailability
"""
def __init__(self, model_catalog: List[ModelSpec]):
self.catalog = {m.model_id: m for m in model_catalog}
self.usage_stats = {
m.model_id: {"requests": 0, "errors": 0, "avg_latency": 0}
for m in model_catalog
}
self.request_history: List[Dict] = []
def route(self, request: Dict) -> str:
"""
Intelligent routing decision
Request format:
{
"task_type": TaskType,
"complexity": ModelComplexity,
"max_latency_ms": float,
"max_cost_per_1k": float,
"context_length": int,
"quality_preference": float # 0.0 to 1.0
}
"""
task_type = request.get("task_type", TaskType.GENERATION)
complexity = request.get("complexity", ModelComplexity.MEDIUM)
max_latency = request.get("max_latency_ms", float('inf'))
max_cost = request.get("max_cost_per_1k", float('inf'))
context_length = request.get("context_length", 0)
quality_pref = request.get("quality_preference", 0.5)
# Filter eligible models
candidates = self._filter_models(
task_type, context_length, max_latency, max_cost
)
if not candidates:
return self._get_default_model()
# Score candidates
scored_models = [
(model_id, self._compute_score(model_id, request, complexity))
for model_id in candidates
]
# Select best model
scored_models.sort(key=lambda x: x[1], reverse=True)
selected = scored_models[0][0]
# Update statistics
self._record_request(selected, request)
return selected
def _filter_models(self, task_type: TaskType, context_length: int,
max_latency: float, max_cost: float) -> List[str]:
"""Filter models meeting hard requirements"""
candidates = []
for model_id, model in self.catalog.items():
# Capability match
if task_type not in model.capabilities:
continue
# Context length
if context_length > model.max_context_tokens:
continue
# Latency constraint
if model.latency_p50_ms > max_latency:
continue
# Cost constraint
if model.cost_per_1k_tokens > max_cost:
continue
candidates.append(model_id)
return candidates
def _compute_score(self, model_id: str, request: Dict,
complexity: ModelComplexity) -> float:
"""Compute composite routing score"""
model = self.catalog[model_id]
quality_pref = request.get("quality_preference", 0.5)
# Latency score (lower is better)
latency_score = 1.0 - min(model.latency_p50_ms / 500, 1.0)
# Cost score (lower is better)
cost_score = 1.0 - min(model.cost_per_1k_tokens / 0.1, 1.0)
# Accuracy score
accuracy_score = model.accuracy_score
# Complexity match bonus
complexity_match = self._complexity_match_score(model, complexity)
# Weighted combination
# For high quality preference: emphasize accuracy
# For low quality preference: emphasize cost/latency
if quality_pref > 0.7:
weights = {"latency": 0.2, "cost": 0.2, "accuracy": 0.4, "match": 0.2}
elif quality_pref < 0.3:
weights = {"latency": 0.4, "cost": 0.4, "accuracy": 0.1, "match": 0.1}
else:
weights = {"latency": 0.3, "cost": 0.25, "accuracy": 0.3, "match": 0.15}
return (
weights["latency"] * latency_score +
weights["cost"] * cost_score +
weights["accuracy"] * accuracy_score +
weights["match"] * complexity_match
)
def _complexity_match_score(self, model: ModelSpec,
complexity: ModelComplexity) -> float:
"""Score based on model-complexity match"""
# Simple heuristic: larger models for higher complexity
model_tier = "large" if model.max_context_tokens > 16000 else "medium"
model_tier = "small" if model.max_context_tokens < 8000 else model_tier
expected_tier = {
ModelComplexity.LOW: "small",
ModelComplexity.MEDIUM: "medium",
ModelComplexity.HIGH: "large"
}[complexity]
return 1.0 if model_tier == expected_tier else 0.6
def _get_default_model(self) -> str:
"""Return default fallback model"""
return "pangu-lite"
def _record_request(self, model_id: str, request: Dict):
"""Record request for analytics"""
self.usage_stats[model_id]["requests"] += 1
self.request_history.append({
"model_id": model_id,
"task_type": request.get("task_type"),
"timestamp": "now"
})
def demo_model_routing():
"""Demonstrate ModelArtsNext intelligent routing"""
# Model catalog
models = [
ModelSpec("pangu-pro-32k", "Pangu Pro 32K",
[TaskType.GENERATION, TaskType.REASONING],
cost_per_1k_tokens=0.05, latency_p50_ms=50,
accuracy_score=0.92, max_context_tokens=32768),
ModelSpec("pangu-pro-8k", "Pangu Pro 8K",
[TaskType.GENERATION],
cost_per_1k_tokens=0.02, latency_p50_ms=30,
accuracy_score=0.88, max_context_tokens=8192),
ModelSpec("pangu-lite", "Pangu Lite",
[TaskType.GENERATION, TaskType.CLASSIFICATION],
cost_per_1k_tokens=0.01, latency_p50_ms=20,
accuracy_score=0.85, max_context_tokens=4096),
ModelSpec("ernie-enterprise", "ERNIE Enterprise",
[TaskType.GENERATION, TaskType.CLASSIFICATION,
TaskType.SUMMARIZATION],
cost_per_1k_tokens=0.03, latency_p50_ms=40,
accuracy_score=0.90, max_context_tokens=16384),
]
router = ModelRouter(models)
print("="*60)
print("ModelArtsNext Intelligent Routing Demo")
print("="*60 + "\n")
# Diverse routing scenarios
scenarios = [
{
"name": "Low-cost generation",
"task_type": TaskType.GENERATION,
"complexity": ModelComplexity.LOW,
"max_latency_ms": 50,
"max_cost_per_1k": 0.02,
"quality_preference": 0.3
},
{
"name": "High-quality reasoning",
"task_type": TaskType.REASONING,
"complexity": ModelComplexity.HIGH,
"max_latency_ms": 100,
"max_cost_per_1k": 0.1,
"quality_preference": 0.9
},
{
"name": "Balanced classification",
"task_type": TaskType.CLASSIFICATION,
"complexity": ModelComplexity.MEDIUM,
"max_latency_ms": 60,
"max_cost_per_1k": 0.05,
"quality_preference": 0.5
},
]
for scenario in scenarios:
selected = router.route(scenario)
model = router.catalog[selected]
print(f"Scenario: {scenario['name']}")
print(f" Selected: {model.model_name}")
print(f" Cost: ${model.cost_per_1k_tokens:.3f}/1K tokens")
print(f" Latency: {model.latency_p50_ms}ms")
print(f" Accuracy: {model.accuracy_score:.2%}")
print()
demo_model_routing()
3.2 Zhiguo AgentArts Enterprise Agent Platform
Zhiguo AgentArts provides enterprise-grade agent development capabilities:
- Production-level Long-horizon Tasks: Multi-day, multi-step task orchestration
- Enterprise Security & Compliance: Financial/medical-grade compliance
- Industry Knowledge Integration: Pre-built industry knowledge bases
4. Industry AI Factory: Four Specialized Zones
4.1 Smart Healthcare Zone
- Medical imaging AI (CT/MRI/X-ray)
- Drug discovery assistance
- Clinical decision support
- Medical knowledge graphs
4.2 Embodied Intelligence Zone
- Robot perception and decision-making
- Simulation environment construction
- Skill learning and transfer
- Real-time control and planning
4.3 Smart Manufacturing Zone
- Quality inspection and defect detection
- Predictive maintenance
- Process parameter optimization
- Intelligent supply chain scheduling
4.4 Scientific Computing Zone
- Climate modeling and prediction
- Materials science computation
- Genomic analysis
- Astrophysics simulation
5. Hundred Models Ecosystem Initiative
The Hundred Models Ecosystem Initiative aims to build an open AI model ecosystem:
| Partner Type | Collaboration | Benefits |
|---|---|---|
| Model Partners | Model integration, joint optimization | Priority compute resources |
| Application Partners | Industry solutions | Technical support, market access |
| Infrastructure Partners | Hardware optimization | Joint testing, brand endorsement |
| Data Partners | High-quality datasets | Data trading revenue share |
6. Conclusion
Huawei Cloud’s Agentic Infra represents a fundamental shift in enterprise AI infrastructure. By providing a comprehensive architecture with four foundational pillars and four flagship products, Huawei Cloud enables enterprises and developers to build the next generation of AI applications:
Core Value Propositions:
- Extreme Performance: 100K+ GPU cluster, <10ms inference, 200 EFLOPS
- Massive Memory: PB-scale storage for day-level long-horizon tasks
- Efficient Scheduling: 30%+ resource utilization improvement
- Security & Trust: Sandbox isolation, ultra-fast startup, autonomous security
- Open Ecosystem: Hundred Models Initiative, Industry AI Factory
Future Outlook:
As Agentic Infra continues to evolve, we anticipate:
- Multi-agent collaboration becoming the dominant paradigm
- Continuous learning making AI systems increasingly intelligent
- Edge intelligence enabling real-time responses with minimal latency
- Security & trust embedded at every layer of AI systems
Huawei Cloud Agentic Infra is not merely a technical architecture—it’s a vision for the future of AI. It opens the door to AGI for enterprises and developers worldwide, and we look forward to witnessing the next chapter of this intelligent revolution.
References:
- Huawei Cloud Official Documentation: https://support.huaweicloud.com/
- ModelArts Pro: https://www.huaweicloud.com/product/modelarts.html
- INSPIRE 2026 Conference Materials