Sapient Intelligence HRM-Text: The $1,500 1B-Parameter Reasoning Revolution
On May 18, 2026, Sapient Intelligence released HRM-Text—a 1B-parameter model trained from scratch for approximately $1,500 (16 H100 GPUs, under 2 days) on just 40B tokens. It achieves 56.2 on MATH, 84.5 on GSM8K, and 81.9 on ARC-Challenge—surpassing models 10-70× its size. Endorsed by HuggingFace CEO and Turing Award winner Yoshua Bengio’s team. This is not fine-tuning—it’s an architectural revolution from scratch.
Introduction: An Impossible Number
A ~1B parameter model scores 56.2 on MATH, 84.5 on GSM8K, 81.9 on ARC-Challenge. Training cost: ~$1,500. Sixteen H100 GPUs for under two days.
Your first instinct: this must be fine-tuned from a larger model. It can’t be trained from scratch at that budget.
But HRM-Text is indeed trained from scratch, using only ~40B unique tokens—roughly 1/225 of Llama 3.2 3B (9T tokens) and 1/900 of Qwen3.5 2B (36T tokens).
Paper: HRM-Text: Efficient Pretraining Beyond Scaling, arXiv:2605.20613
The HRM Architecture: Dual-Timescale Hierarchical Recurrence
How Standard Transformers Work
A standard Transformer consists of sequentially arranged, independently parameterized layers. Input propagates forward: layer 1 → layer 2 → … → output. To increase capability, you stack more layers, increase hidden dimensions, or train more parameters.
Analogy: passing a document to multiple different editors, each editing it once before passing it on.
HRM: “Two Editing Teams Revising the Same Draft”
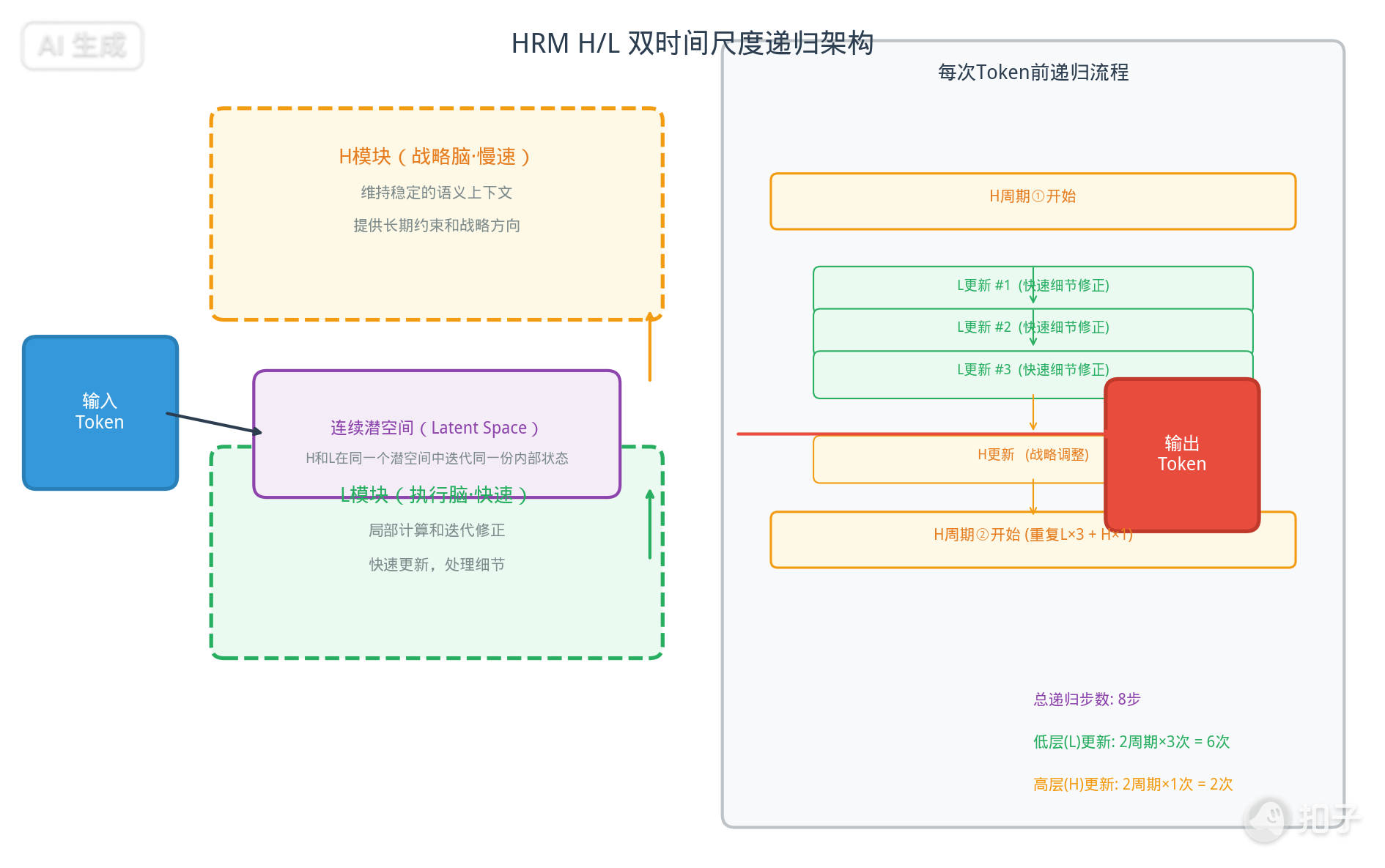
HRM-Text introduces two modules operating at different timescales:
H-module (High-level/Strategic Brain): Updates slowly, maintains stable semantic context, provides long-term constraints. Think of a chief editor overseeing strategic direction.
L-module (Low-level/Execution Brain): Updates quickly, handles local computation and iterative refinement. Think of copy editors polishing details word by word.
Key Distinction: Not “Two Brains” Taped Together
This is critically different from the common “big brain + small brain” approach where two separately trained models communicate via text interfaces. HRM’s H and L modules belong to the same network. They don’t exchange messages through text space—they iterate the same internal state in the same latent space. What information flows between modules and how labor is divided are jointly determined by a unified optimization process.
HRM doesn’t bolt a planner onto an executor—it builds hierarchical computation into a single model.
8 Recurrent Updates Per Token
Per the paper’s configuration, each forward pass executes 2 high-level cycles, each containing:
- Three L-module updates (fast detail refinement)
- One H-module update (strategic adjustment)
Total per token: 8 recurrent updates—6 low-level + 2 high-level.
Effective depth analysis shows that deeper steps continue to produce incremental representational changes. The recurrence doesn’t simply repeat—it continuously modifies internal states.
Source: HRM-Text paper, arXiv:2605.20613, Section 3.1
MagicNorm and Progressive Training
Recurrent architectures face well-known stability challenges. Deeper recurrence offers more opportunity for self-correction, but activation variance accumulates and gradients vanish or explode. This is why RNNs were surpassed by Transformers in the 2010s.
HRM-Text introduces two key innovations:
MagicNorm: Stabilizing Both Forward and Backward Passes
MagicNorm simultaneously stabilizes forward activation growth and backward gradient flow. The module retains PreNorm structure internally (good for gradients), but adds an extra normalization at each recurrent module’s exit point. This constrains activation variance growth across cycles while preserving gradient pathways.
h' = γ · (h - μ) / σ + β
Where γ and β are learnable affine parameters, μ and σ are current state statistics. The key difference from standard LayerNorm: MagicNorm is placed at the exit point of each recurrent step, not between layers.
Warmup Deep Credit Assignment
This controls how far back gradients can propagate. Early in training, gradients only flow back through the last 2 recurrent steps. As training stabilizes, the range linearly increases to the last 5 steps.
Think of it as a progressive “accountability mechanism”: early training makes the model responsible only for its most recent computations; as stability improves, earlier computations are gradually held accountable.
Source: HRM-Text paper, Section 3.3
Training Objective: Task Completion + PrefixLM
Beyond Next-Token Prediction
Standard language models use autoregressive next-token prediction: given text, predict each subsequent token. Every word carries equal weight—filler phrases, function words, reasoning steps, all treated identically.
HRM-Text takes a radically different approach: it skips large-scale raw-text pretraining entirely and trains directly on instruction-response pairs from scratch. The model computes token-level loss only on the response portion.
Analogy: a teacher grading only the answer section, not the “copy the question” part.
PrefixLM: Bidirectional Instructions, Causal Responses
PrefixLM mask allows instruction tokens to attend bidirectionally to each other, while response tokens follow standard causal generation. This gives the model a quasi-encoder-decoder workflow within a decoder-only architecture: instructions function as encoding, responses as decoding.
Attention analysis reveals that PrefixLM produces higher attention entropy and more global, diverse attention patterns compared to pure causal masks—it fundamentally changes how the model utilizes instruction information.
Ablation Study: Three Components, One Result
| Configuration | ARC-C | MATH | GSM8K |
|---|---|---|---|
| 1B Transformer + full causal | 51.91 | 35.44 | 48.37 |
| + Response-only prediction | 62.88 | 47.04 | 69.75 |
| + PrefixLM | 74.32 | 48.36 | 75.06 |
| + HRM architecture | 81.91 | 56.16 | 84.53 |
The efficiency gain comes from the synergistic combination of all three innovations—not any single one.
Code Implementation 1: Dual-Timescale Recurrence Simulation
// Full code: outputs/代码/hrm_dual_timescale.go
type HRMNetwork struct {
HWeights [][][]float64 // High-level (strategic)
LWeights [][][]float64 // Low-level (execution)
HState []float64
LState []float64
Latent []float64 // Shared latent space
}
func (net *HRMNetwork) Forward(input []float64) []float64 {
copy(net.LState, input)
copy(net.HState, input)
copy(net.Latent, input)
for hCycle := 0; hCycle < 2; hCycle++ { // 2 H cycles
for lStep := 0; lStep < 3; lStep++ { // 3 L updates each
combined := fuse(net.LState, net.HState)
net.LState = net.LUpdate(combined)
net.Latent = updateLatent(net.Latent, net.LState)
}
hInput := fuse(net.HState, net.LState)
net.HState = net.HUpdate(hInput) // 1 H update
net.Latent = updateLatent(net.Latent, net.HState)
}
// 8 total recurrent updates per token
return finalOutput(net.Latent, input)
}
Code Implementation 2: Training Cost Comparison
# Full code: outputs/代码/hrm_cost_scaling_analysis.py
models = [
{"name": "HRM-Text 1B", "params": 1.0, "tokens": 0.04, "cost": 1500},
{"name": "Llama 3.2 3B", "params": 3.0, "tokens": 9.0, "cost": 70000},
{"name": "Qwen3.5 2B", "params": 2.0, "tokens": 18.5, "cost": 120000},
{"name": "Qwen3.5 72B", "params": 72.0, "tokens": 36.0, "cost": 1000000},
]
for m in models[1:]:
print(f"HRM vs {m['name'].split()[0]}: "
f"Cost={m['cost']/1500:.0f}x, "
f"Data={(m['tokens']/0.04):.0f}x, "
f"Params={(m['params']/1.0):.1f}x")
Output: Cost ratios range from 47× (Llama 3B) to 667× (Qwen 72B). Data ratios from 225× to 900×.
Code Implementation 3: Scaling Law Counter-Example
# Full code: outputs/代码/hrm_cost_scaling_analysis.py
class ScalingLawCounterExample:
def __init__(self):
self.param_exponent = 0.28 # Parameter scaling exponent
self.data_exponent = 0.15 # Data scaling exponent
def expected_performance(self, params_b, tokens_t):
scale = ((params_b / 3.0) ** self.param_exponent *
(tokens_t / 9.0) ** self.data_exponent)
return 70.0 * scale # Llama 3.2 3B baseline = 70
# HRM actual average: 70.8
# Scaling Law prediction: 22.8
# Exceeds expectation: 210%
# Breakthrough factor: 3.10x
Training Cost Comparison: Orders of Magnitude
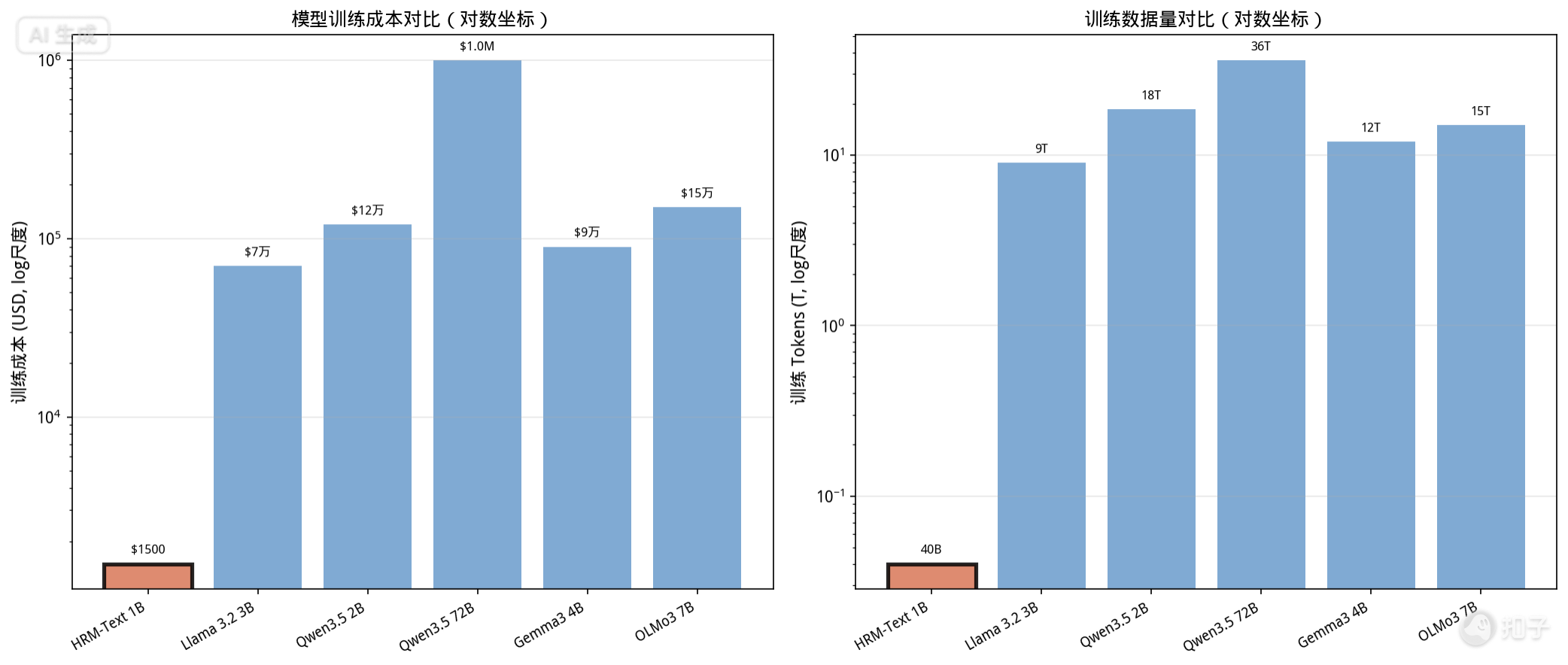
| Model | Params | Training Tokens | Cost (USD) | Cost Ratio | Data Ratio |
|---|---|---|---|---|---|
| HRM-Text 1B | 1B | 40B | $1,500 | 1× | 1× |
| Llama 3.2 3B | 3B | 9T | ~$70,000 | 47× | 225× |
| Qwen3.5 2B | 2B | 18.5T | ~$120,000 | 80× | 462× |
| Gemma3 4B | 4B | 12T | ~$90,000 | 60× | 300× |
| OLMo3 7B | 7B | 15T | ~$150,000 | 100× | 375× |
| Qwen3.5 72B | 72B | 36T | ~$1,000,000 | 667× | 900× |
Notably, HRM-Text’s MATH score (56.2) exceeds Qwen3.5 2B, Llama 3.2 3B, Gemma3 4B, and OLMo3 7B—all 2-7× larger and 47-100× more expensive to train.
Source: HRM-Text paper, Table 1
Challenging Scaling Law Systematically
The Core Assumption of Scaling Laws
Scaling Laws (Kaplan et al., 2020; Hoffmann et al., 2022) establish a power-law relationship: larger models + more data + more compute = better performance. This has driven the entire field for five years.
HRM’s Counter-Example: Compute Depth as a New Axis
HRM-Text proves that Scaling Laws missed a critical dimension: computational structure.
Standard Transformers stack parameters. HRM reuses parameters through recurrence, letting limited parameters participate in deeper effective computation.
Effective compute depth = Parameters × Recurrence per parameter
Standard Transformer: each parameter participates once. HRM: each parameter participates 8 times. This means 1B HRM parameters ≈ 8B standard Transformer parameters in effective compute depth—at 1/8 the storage and training cost.
This is why HRM achieves competitive performance at a fraction of Scaling Law-predicted costs: it’s not fighting Scaling Law—it’s opening a new growth axis called compute depth.
Limitations
HRM-Text is not a complete replacement for Scaling Law:
- Limited knowledge coverage: MMLU score (60.7) lags behind Qwen3.5 2B (64.5)
- Different inference cost: 8 recursive steps increase per-token computation
- Fixed recurrence depth: No adaptive computation time yet
- Unknown scalability: Larger-scale HRM behavior remains to be explored
Industry Impact: Democratizing AI
HRM-Text’s implications extend far beyond academic benchmarks.
Breaking the “Scale Religion”
The AI industry has operated under an almost religious belief: only bigger models, more GPUs, and more expensive training produce better AI. Two consequences: AI research concentrates in a few mega-corporations, and “no 1000 H100s, no foundation model” becomes unwritten law.
HRM-Text shatters this myth with $1,500. It proves that architectural innovation beats scale-stacking on efficiency.
Democratizing Foundation Model Research
When training a competitive foundation model drops from millions to $1,500, AI research is no longer the exclusive domain of tech giants. Research institutes, startups, and university labs can participate. As Sapient CEO Guan Wang put it: “When training a capable foundation model costs $1,500, AI stops being an infrastructure question and becomes a strategy question.”
Edge Inference Becomes Real
At int4 quantization, HRM-Text occupies just 0.6 GiB—fitting on modern smartphones. This enables privacy-sensitive applications (healthcare, finance, legal) where data never leaves the device.
Academic Reception
HuggingFace CEO Endorsement
The model weights and code are fully open-sourced on GitHub and HuggingFace.
Bengio’s GRAM Follow-up
On May 19, 2026, Turing Award winner Yoshua Bengio co-authored “Generative Recursive Reasoning” (GRAM), which directly extends HRM’s hierarchical recurrent approach with probabilistic multi-trajectory reasoning.
Reasoning-Knowledge Decoupling
The team hints at early results in decoupling reasoning from knowledge storage—compact recurrent models focusing on computation while external retrieval handles facts. If successful, this could yield models with fewer parameters, stronger reasoning, and more controllable knowledge.
Conclusion: The Road Beyond Scaling
HRM-Text’s value isn’t just its benchmark scores or its training budget. It provides a reproducible, verifiable, and falsifiable case study: beyond scaling model size, redesigning computational structure can fundamentally change the relationship between performance, cost, and capability.
If the last decade’s growth axis was parameter scale, data scale, and compute scale, HRM explores a deeper question: Can the computational process itself become a new growth axis?
In an industry profoundly shaped by Scaling Law, this possibility is significant enough. Because the next generation of intelligent systems may grow not just from more parameters, more data, and more compute—but from a more fundamental question: how should a model think?
References:
- Wang et al., “HRM-Text: Efficient Pretraining Beyond Scaling”, arXiv:2605.20613, 2026
- Sapient Intelligence: sapient.inc/introducing-hrm-text
- Machine Heart (Jiqizhixin) coverage, June 9, 2026
- 36Kr in-depth report, June 9, 2026
- Bengio et al., “Generative Recursive Reasoning”, arXiv, May 2026
- Kaplan et al., “Scaling Laws for Neural Language Models”, 2020
- Hoffmann et al., “Training Compute-Optimal Large Language Models”, 2022