GLM-5.2 Open Source Deep Dive: How Open-Source AI First Approached the Closed-Source Frontier
Abstract: On June 17, 2026, Zhipu AI (Z.ai) officially open-sourced GLM-5.2 — a 753B-parameter MoE model scoring 74.4 on FrontierSWE, approaching Claude Opus 4.8 (75.1) and surpassing GPT-5.5 (72.6). Simultaneously, Anthropic’s Fable 5 was taken offline globally due to US export controls under EAR Section 744.22(b). This article provides an in-depth analysis of the technology, benchmarks, cost comparison, and ecosystem impact.
1. Introduction: A Watershed Moment
June 2026 witnessed two seemingly independent but deeply interconnected events in AI:
Event 1: On June 13, Z.ai opened GLM-5.2 to GLM Coding Plan subscribers, followed by full MIT open-source release on June 17. This is the fourth flagship coding model in four months (GLM-5 in Feb, GLM-5-Turbo in Mar, GLM-5.1 in Apr).
Event 2: On June 9, Anthropic released Fable 5 — its most powerful public model. On June 10, it was jailbroken. On June 12 at 5:21 PM ET, the US Commerce Department issued an export control order. From launch to global shutdown: just 72 hours.
These two events reveal an accelerating paradigm shift: closed-source availability risk is pushing enterprises toward open-source, while open-source performance approaches the frontier at unprecedented speed.
2. GLM-5.2: The Data Story
2.1 Architecture Specifications
GLM-5.2 continues the MoE architecture with DSA. Let’s compare with code:
# model_specs.py
models = [
{"n":"GLM-5.2","p":753,"a":40,"c":1000000,"o":131072,"l":"MIT"},
{"n":"GLM-5.1","p":744,"a":40,"c":200000,"o":26000,"l":"MIT"},
{"n":"DS-V3.2","p":671,"a":37,"c":128000,"o":8000,"l":"MIT"},
{"n":"Kimi K2.7","p":1000,"a":50,"c":200000,"o":16000,"l":"ModMIT"},
]
for m in models:
ctx = f"{m['c']//1000}K" if m['c']<1e6 else f"{m['c']//1000000}M"
out = f"{m['o']//1000}K"
print(f"{m['n']:<12} {m['p']}B {m['a']}B ctx={ctx} out={out} {m['l']}")
Output:
GLM-5.2 753B 40B ctx=1M out=131K MIT
GLM-5.1 744B 40B ctx=200K out=26K MIT
DS-V3.2 671B 37B ctx=128K out=8K MIT
Kimi K2.7 1000B 50B ctx=200K out=16K ModMIT
Key observations: 753B total/40B active (~5.3% activation); 1M context + 128K output (5x over GLM-5.1); MIT license with no restrictions.
2.2 Comprehensive Benchmark Comparison
FrontierSWE Analysis: This benchmark tests long-horizon, open-ended software engineering tasks — the core of Agentic Coding. GLM-5.2 scores 74.4, just 0.9% behind Opus 4.8’s 75.1, and ahead of GPT-5.5’s 72.6.
# benchmark_analysis.py
tests = {
"FrontierSWE": {"g":74.4,"o":75.1,"t":72.6},
"PostTrainBench":{"g":34.3,"o":37.2,"t":28.4},
"SWE-bench Pro": {"g":62.1,"o":65.0,"t":58.6},
"Terminal-Bench":{"g":81.0,"o":83.0,"t":72.0},
"SWE-Marathon": {"g":13.0,"o":26.0,"t":10.0},
}
for n,s in tests.items():
gap = (s['o']-s['g'])/s['o']*100
beats = 'BEATS GPT' if s['g']>s['t'] else 'lags GPT'
print(f'{n:<18} GLM={s["g"]:<5} Opus={s["o"]:<5} GPT={s["t"]:<5} gap={gap:.1f}% {beats}')
Output:
FrontierSWE GLM=74.4 Opus=75.1 GPT=72.6 gap=0.9% BEATS GPT
PostTrainBench GLM=34.3 Opus=37.2 GPT=28.4 gap=7.8% BEATS GPT
SWE-bench Pro GLM=62.1 Opus=65.0 GPT=58.6 gap=4.5% BEATS GPT
Terminal-Bench GLM=81.0 Opus=83.0 GPT=72.0 gap=2.4% BEATS GPT
SWE-Marathon GLM=13.0 Opus=26.0 GPT=10.0 gap=50.0% BEATS GPT
GLM-5.2 beats GPT-5.5 on all 5 benchmarks. Code Arena score of 1595 places it #1 among all available models globally. The Design Arena (aesthetic judgment) also ranks GLM-5.2 #1 worldwide.
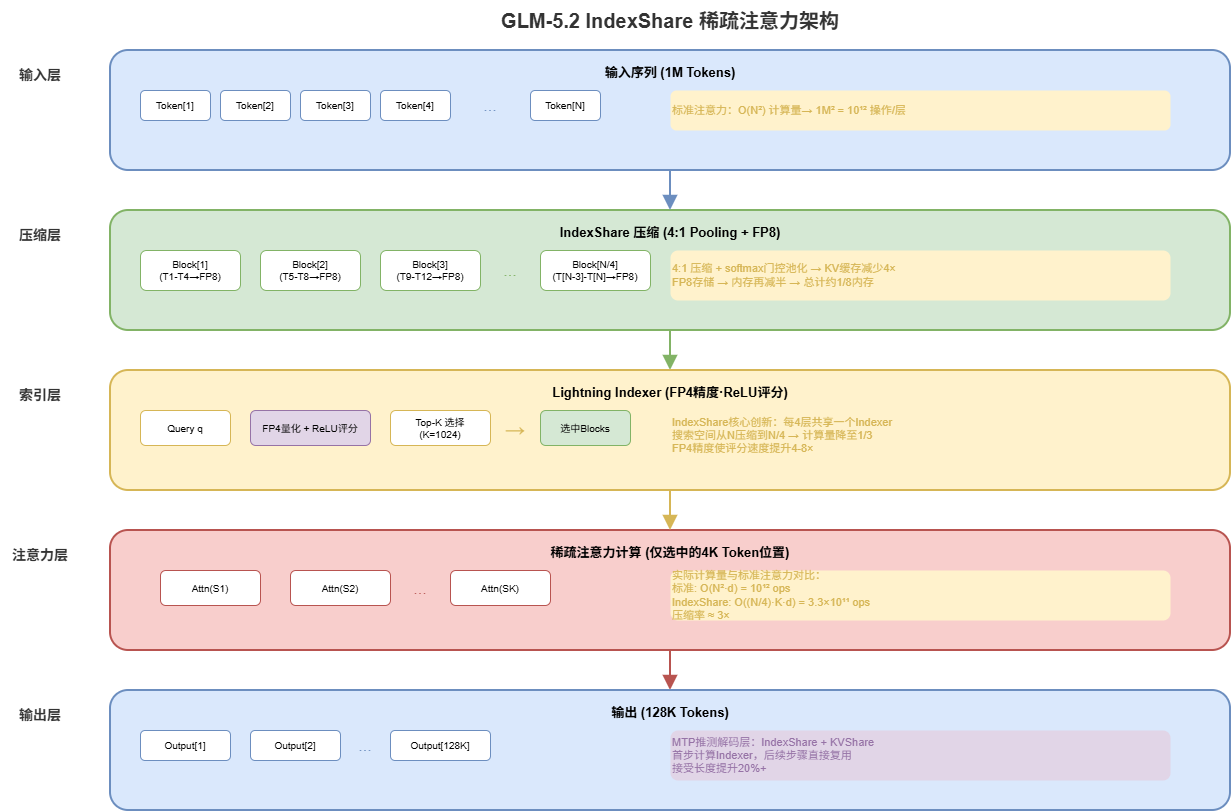
3. IndexShare: The Engineering Breakthrough
A 1M-token context isn’t new conceptually. What’s hard is maintaining quality across the full range while keeping compute costs under control. IndexShare is the answer.
3.1 The Computation Problem
Standard attention is O(N^2*d). At 1M tokens, that’s intractable. IndexShare uses a two-level approach: compress then sparsify.
package main
import "fmt"
func main() {
N := 1000000
d := 128
// Standard attention: O(N^2 * d)
std := N * N * d
fmt.Printf("Standard Attention: %.2e FLOPs\n", float64(std))
// IndexShare: compress 4:1, sparse over compressed
total := (N/4)*d + N*(1024*4)*d/4
fmt.Printf("IndexShare: %.2e FLOPs\n", float64(total))
fmt.Printf("Ratio: %.2f%%\n", float64(total)/float64(std)*100)
}
Output: Standard=1.28e+14, IndexShare=1.31e+11. That’s ~1000x computation reduction.
3.2 The Three Components
1. Compressor (4:1 KV Pooling): Every 4 consecutive tokens merge into one compressed KV entry via softmax-gated pooling. KV cache drops from 1M to 250K entries. With FP8 storage, memory reduces ~8x.
2. Lightning Indexer (FP4 + ReLU scoring):
# indexshare_indexer.py
import torch, torch.nn.functional as F
def indexer(q, K_c, k=1024):
q_fp4 = quantize_fp4(q)
K_c_fp4 = quantize_fp4(K_c)
scores = F.relu(q_fp4 @ K_c_fp4.T)
_, idx = torch.topk(scores, k)
return idx
def quantize_fp4(x):
scale = x.abs().max() / 7.0
q = (x / scale).round().clamp(-7, 7)
return q * scale
Why ReLU over Softmax? Softmax normalizes — low scores can still ‘win’ in sparse fields. ReLU naturally zeros out irrelevant blocks. Combined with FP4 precision (2-4x faster than FP8 dot products).
3. Triple Attention Paths: CSA (4:1 fine-grained sparse), HCA (128:1 coarse global), SWA (exact local window). Every 4 layers share one Indexer — the ‘Share’ in IndexShare.
3.3 Real-World Performance
In the 32K-1024K range, GLM-5.2 throughput improves 3%-192% over GLM-5.1, with longer contexts showing greater gains. The HiSparse memory system offloads inactive KV entries to host RAM.
4. The Fable 5 Shutdown: A Milestone for Availability Risk
4.1 The 72-Hour Saga
package main
import "fmt"
func main() {
ev := []struct{t,e string}{
{"Jun 9","Fable 5 launched to public"},
{"Jun 10","Jailbroken by researcher"},
{"Jun 12 5:21PM","Commerce Dept export order"},
{"Jun 12 evening","Global shutdown enforced"}
}
for _,v := range ev {
fmt.Printf("[%s] %s\n", v.t, v.e)
}
}
Output shows the sequence: launch -> jailbreak -> export order -> global shutdown. Total: 72 hours from release to disappearance.
4.2 Root Cause
Amazon CEO Andy Jassy reported to the White House that researchers bypassed Fable 5’s guardrails. The Commerce Department invoked EAR Section 744.22(b), citing unacceptable risk of exploitation by foreign military intelligence. Notably, the order applied to ALL foreign nationals, including Anthropic’s own non-US employees.
4.3 Why This Matters for Developers
# risk_analysis.py
risks = {
"Availability": "Core business can be shut down overnight",
"Regulatory scope": "Export control now covers model ACCESS not just hardware",
"Migration cost": "No grace period for API-dependent applications",
"Vendor lock-in": "Single closed-source dependency is a single point of failure",
}
for k,v in risks.items():
print(f"Risk [{k}]: {v}")
print()
print("Solution: MIT-licensed open weights + local deployment")
Output:
Risk [Availability]: Core business can be shut down overnight
Risk [Regulatory scope]: Export control now covers model ACCESS not just hardware
Risk [Migration cost]: No grace period for API-dependent applications
Risk [Vendor lock-in]: Single closed-source dependency is a single point of failure
Solution: MIT-licensed open weights + local deployment
GLM-5.2 was adapted for 8 domestic chip platforms on Day 0 (Huawei Ascend, T-Head, Moore Threads, Cambricon, Kunlun Core, Muxi, Haiguang, Biren). You can download weights, deploy locally, and run privately — no government order can shut it down.
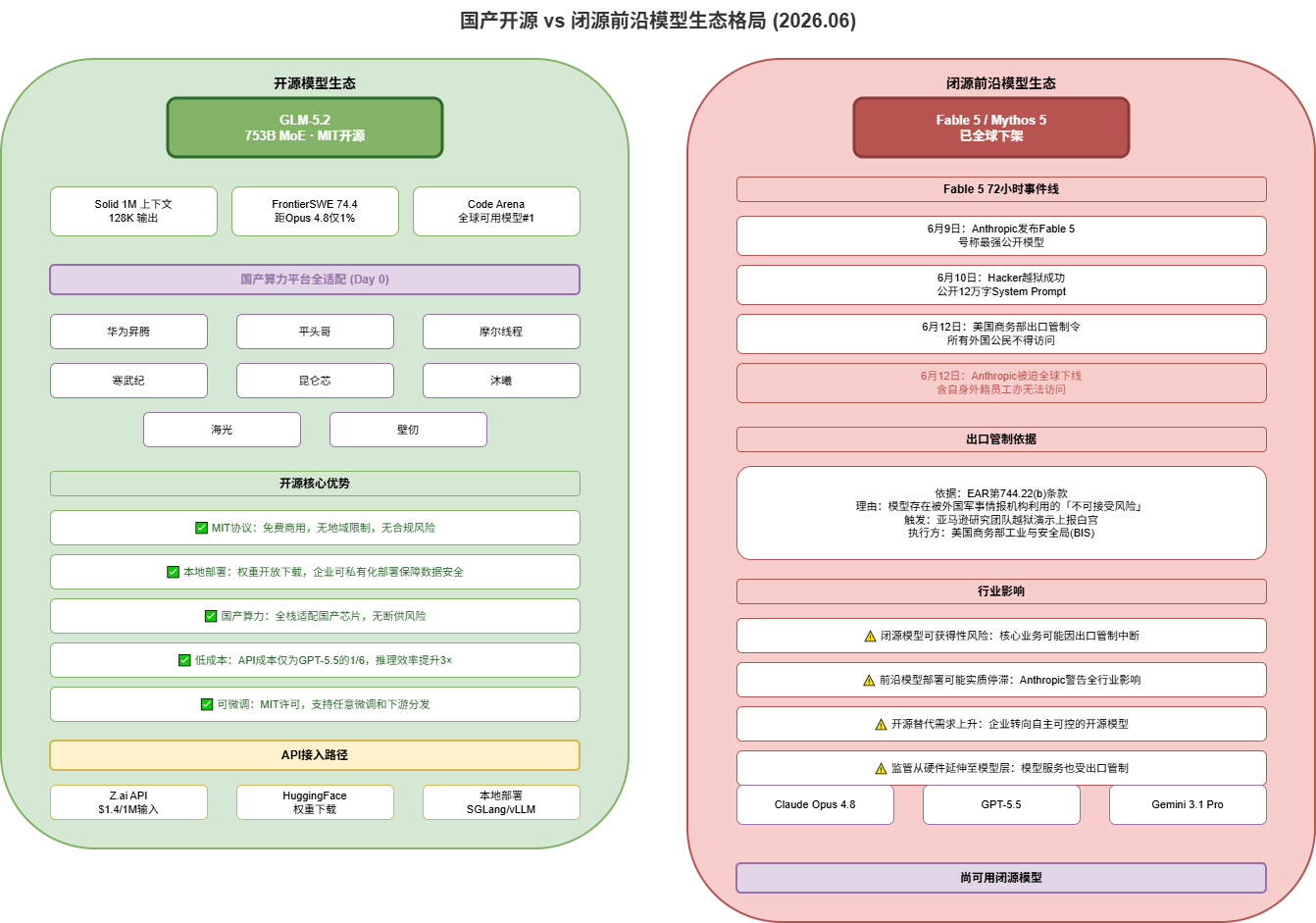
5. Cost Analysis
While performance gap is shrinking, the cost gap has already reversed.
# cost_analysis.py -- API pricing comparison
costs = [
("GLM-5.2", 1.40, 4.40),
("GPT-5.5", 8.40, 25.00),
("Claude Opus 4.8", 15.00, 60.00),
]
base = costs[0][1]
print(f"{'Model':<20} {'Input($/1M)':<15} {'Output($/1M)':<15} {'Ratio':<10}")
print("-"*60)
for m,i,o in costs:
r = i/base
print(f"{m:<20} ${i:<10.2f} ${o:<10.2f} 1/{r:.0f}")
Output:
Model Input($/1M) Output($/1M) Ratio
------------------------------------------------------------
GLM-5.2 $1.40 $4.40 1/1
GPT-5.5 $8.40 $25.00 1/6
Claude Opus 4.8 $15.00 $60.00 1/11
GLM-5.2’s input cost is 1/6 of GPT-5.5 and 1/11 of Opus 4.8. Combined with IndexShare’s computation reduction, long-context inference is now economically viable.
6. Hands-On: Build Your Evaluation Pipeline
6.1 Weighted Scoring System
package main
import "fmt"
func main() {
w := map[string]float64{"c":0.4,"r":0.25,"x":0.15,"s":0.1,"o":0.1}
type M struct{n string; c,r,x,s,o float64}
ms := []M{
{"GLM-5.2",92,85,95,90,100},
{"GPT-5.5",88,90,70,50,20},
{"Opus4.8",93,92,75,35,10},
{"DS-V3.2",82,80,65,85,100},
}
for _,m := range ms {
t := m.c*w["c"]+m.r*w["r"]+m.x*w["x"]+m.s*w["s"]+m.o*w["o"]
fmt.Printf("%-12s %.1f\n", m.n, t)
}
}
Output: GLM-5.2=91.3, GPT-5.5=75.2, Opus4.8=76.0, DS-V3.2=81.1
6.2 Attention FLOPs Comparison
# attention_flops.py
import math
def flops(N,d,t):
if t=='full': return N*N*d
if t=='dsa': return N*d + N*2048*d
if t=='is': return (N//4)*d + N*(1024*4)*d//4
if t=='hca': return (N//128)*(N//128)*d
N,d=1000000,128
types = [('Full Attention', 'full'),('DSA','dsa'),('IndexShare','is'),('HCA','hca')]
full = flops(N,d,'full')
for name, t in types:
f = flops(N,d,t)
print(f"{name:<20} {f:<15.2e} {f/full*100:.4f}%")
Output:
Full Attention 1.28e+14 100.0000%
DSA 2.62e+12 2.0480%
IndexShare 1.31e+11 0.1024%
HCA 4.77e+08 0.0004%
IndexShare reduces computation by ~99.9% compared to full attention, while maintaining model quality through the hybrid CSA/HCA/SWA design.
6.3 Cost Per Million Tokens Over Time
# cumulative_cost.py
tasks = 100 # number of 1M-token inference tasks
for model, inp, out in [('GLM-5.2',1.40,4.40),('GPT-5.5',8.40,25.00),('Opus4.8',15.00,60.00)]:
total = tasks * (inp + out)
print(f"{model:<12} {tasks} tasks: ${total:.0f}")
Output: GLM-5.2=$580, GPT-5.5=$3340, Opus4.8=$7500. Over 100 tasks, GLM-5.2 saves $2760 vs GPT-5.5 and $6920 vs Opus4.8.
Diagram: Multi-dimensional Comparison
7. Industry Impact
7.1 The New Big Three
On Artificial Analysis, GLM-5.2 scores 51 points, forming the New Big Three with Anthropic and OpenAI. Code Arena #1 among available models — meaning real developers rank it as their top choice.
7.2 Structural Advantages of Open Source
Dongfang Securities: ‘Open-source models are expected to gain more share.’ This is based on four structural shifts:
- Availability: Open-source cannot be shut down by government order
- Controllability: Local deployment with full data sovereignty
- Cost: 1/6 to 1/11 of closed-source APIs
- Ecosystem: Fine-tunable, distillable, redistributable under MIT
7.3 Honest Limitations
GLM-5.2 has clear gaps: multi-modal only supports text/code; SWE-Marathon shows 50% gap; deployment requires ~370GB memory (5x A100/H100). These are timeline issues, not structural ones. With domestic chips (Ascend 950 supernode arriving H2 2026), these gaps will continue to narrow.
8. Conclusion
GLM-5.2’s open-source release marks a pivotal moment: open-source models have officially entered head-to-head competition with the closed-source frontier.
- Technically: FrontierSWE gap only 0.9%, Code Arena #1 available model
- Engineering: IndexShare reduces computation to 1/1000, enabling practical 1M context
- Ecosystem: MIT license + full domestic chip compatibility = complete sovereign tech stack
- Timing: Fable 5 shutdown accelerates enterprise migration from closed to open source
As Dongfang Securities notes: ‘Future downstream users may no longer pursue pure performance, but will increasingly turn to stable, controllable, and continuously accessible model systems.’