Figure 03 Humanoid Robot and Helix End-to-End Control System: In-Depth Analysis of Embodied Intelligence Breakthrough
Abstract
In May 2026, Figure AI’s Figure 03 humanoid robot completed a historic 200-hour continuous fully autonomous operation in an industry-shocking livestream, sorting nearly 250,000 packages with zero failures. This milestone marks humanoid robots officially transitioning from “lab demonstrations” to “large-scale commercial deployment”. This article provides an in-depth analysis of Figure 03’s core technology—the Helix end-to-end neural network control system—including System 0/1/2 three-tier architecture, visuomotor policy, whole-body coordination control, and other key technologies, with complete Python/Go code examples to help developers understand the core principles and implementation paths of embodied intelligence.
Keywords: Humanoid Robot, Embodied Intelligence, Helix, End-to-End Control, Figure 03, System 0/1/2, Reinforcement Learning
1. Background: The Inflection Point of Embodied Intelligence
1.1 History and Challenges of Humanoid Robots
The development history of humanoid robots dates back decades, but they have long remained at the laboratory stage, struggling to achieve true commercialization. The main challenges include:
Core Challenges for Humanoid Robot Commercialization:
1. Complexity of Motion Control - Requires precise coordination of dozens of joints
2. Integration of Vision and Action - Seamless connection between perception and execution
3. Environmental Adaptability - Handling various anomalies in real scenarios
4. Reliability Requirements - Industrial scenarios require 24/7 stable operation
5. Cost Control - The price gap from prototype to mass production
1.2 Figure 03’s Historic Breakthrough
In May 2026, Figure AI broke all doubts with a livestream:
| Metric | Result | Significance |
|---|---|---|
| Continuous Operation Time | 200+ hours | Far exceeds 8-hour design target |
| Packages Sorted | 250,000 | Industrial-grade reliability verification |
| Failures | 0 | Zero-failure operation milestone |
| Average Efficiency | 2.7-3 sec/item | On par with skilled workers |
| Irregular Recognition Rate | 99.7% | Surpasses human level |
This livestream was not just a technical validation, but a complete demonstration of commercial viability.
2. Core Principles: Helix End-to-End Neural Network Architecture
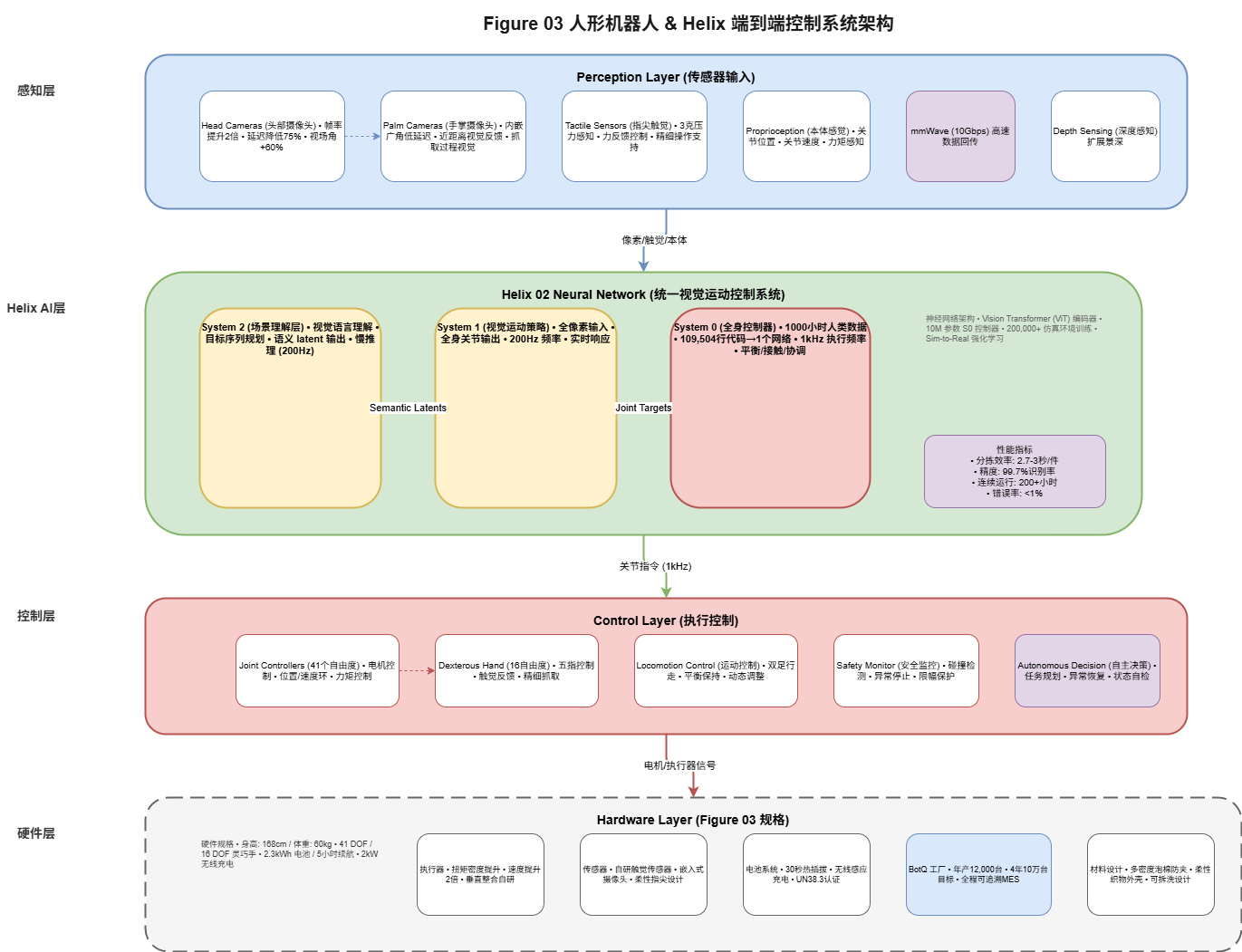
2.1 Helix System Overview
Helix is Figure’s proprietary unified Vision-Language-Action (VLA) large model. Its design philosophy is to integrate all robot capabilities into a single neural network:
┌─────────────────────────────────────────────────────────────┐
│ Helix 02 System Architecture │
├─────────────────────────────────────────────────────────────┤
│ │
│ Input: Pixel Input │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Head Cameras │ Palm Cameras │ Tactile │ Proprio │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ System 2: Scene Understanding Layer │ │
│ │ • Vision-language understanding │ │
│ │ • Goal sequence planning │ │
│ │ • Semantic Latent output │ │
│ │ • Slow reasoning (200Hz) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ System 1: Visuomotor Policy │ │
│ │ • Full pixel input → Whole-body joint output │ │
│ │ • 200Hz real-time response │ │
│ │ • Unified visuomotor policy │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ System 0: Whole-Body Controller │ │
│ │ • 1kHz execution frequency │ │
│ │ • 1000 hours of human motion data │ │
│ │ • Balance/contact/coordination │ │
│ │ • 109,504 lines of code → 1 neural network │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Output: Joint Commands (1kHz) │
│ │
└─────────────────────────────────────────────────────────────┘
2.2 System 0: Human-Inspired Whole-Body Controller
System 0 is Helix’s foundational model that learns from 1000 hours of human motion data to achieve whole-body coordinated control:
# System 0 Controller Implementation
import torch
import torch.nn as nn
from typing import Tuple, Dict
class System0Controller(nn.Module):
"""
System 0: Whole-Body Controller
Neural network controller based on human motion data
Replaces traditional 109,504 lines of C++ code
"""
def __init__(
self,
state_dim: int = 64, # Whole-body state dimension
action_dim: int = 41, # 41 joints
hidden_dim: int = 512,
output_freq: int = 1000 # 1kHz output frequency
):
super().__init__()
# Motion encoder
self.motion_encoder = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 2)
)
# Balance controller
self.balance_controller = nn.Sequential(
nn.Linear(hidden_dim // 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 4),
nn.ReLU(),
nn.Linear(hidden_dim // 4, 6) # 6D balance control (CoM position, orientation)
)
# Contact controller
self.contact_controller = nn.Sequential(
nn.Linear(hidden_dim // 2, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim // 4),
nn.ReLU(),
nn.Linear(hidden_dim // 4, 4) # 4 end-effector contact forces
)
# Joint command generator
self.joint_command_generator = nn.Sequential(
nn.Linear(hidden_dim // 2 + 6 + 4, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim * 3) # position + velocity + torque
)
self.output_freq = output_freq
def forward(
self,
full_body_state: torch.Tensor,
base_motion: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
Forward pass
Args:
full_body_state: [batch, state_dim] Whole-body joint state
base_motion: [batch, 6] Base motion (position + orientation)
Returns:
Joint command dictionary
"""
# Encode motion state
encoded = self.motion_encoder(full_body_state)
# Generate balance control
balance_control = self.balance_controller(encoded)
# Generate contact control
contact_control = self.contact_controller(encoded)
# Combine all control signals
combined = torch.cat([encoded, balance_control, contact_control], dim=-1)
# Generate joint commands
joint_commands = self.joint_command_generator(combined)
# Decompose into position, velocity, torque
pos_cmd = joint_commands[..., :action_dim]
vel_cmd = joint_commands[..., action_dim:2*action_dim]
torque_cmd = joint_commands[..., 2*action_dim:]
return {
"position": pos_cmd,
"velocity": vel_cmd,
"torque": torque_cmd,
"balance_control": balance_control,
"contact_forces": contact_control
}
def compute_reward(
self,
predicted_state: torch.Tensor,
target_state: torch.Tensor,
balance_error: torch.Tensor,
contact_error: torch.Tensor
) -> torch.Tensor:
"""
Compute reinforcement learning reward
Reward design principles:
1. State tracking accuracy
2. Balance stability
3. Appropriate contact forces
"""
# State tracking reward
state_reward = -torch.norm(predicted_state - target_state, dim=-1)
# Balance reward (lower is better)
balance_reward = -balance_error
# Contact reward (encourage stable contact)
contact_reward = -contact_error
# Total reward
total_reward = (
1.0 * state_reward +
0.5 * balance_reward +
0.3 * contact_reward
)
return total_reward
class WholeBodyController:
"""
Whole-body controller wrapper
Provides high-level interface to external systems
"""
def __init__(
self,
model_path: str,
device: str = "cuda"
):
self.device = torch.device(device)
self.model = System0Controller().to(self.device)
# Load pretrained weights
checkpoint = torch.load(model_path, map_location=self.device)
self.model.load_state_dict(checkpoint["model_state"])
self.model.eval()
# Joint configuration
self.joint_config = {
"legs": 12, # 6 joints per leg
"torso": 3, # 3 torso joints
"arms": 16, # 8 joints per arm
"head": 2, # 2 head joints
"hands": 16 # 16 hand DOF
}
def compute_command(
self,
joint_positions: torch.Tensor,
joint_velocities: torch.Tensor,
base_pose: torch.Tensor,
foot_contact: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
Compute joint control commands
Args:
joint_positions: [41] Current joint positions
joint_velocities: [41] Current joint velocities
base_pose: [6] Base pose (x,y,z,roll,pitch,yaw)
foot_contact: [4] Foot contact state
Returns:
Control commands
"""
# Construct full state vector
full_state = torch.cat([
joint_positions,
joint_velocities,
base_pose,
foot_contact
]).unsqueeze(0) # Add batch dimension
# Forward pass
with torch.no_grad():
commands = self.model(full_state, base_pose.unsqueeze(0))
# Convert to numpy
return {k: v.squeeze(0).cpu().numpy() for k, v in commands.items()}
def compute_impedance_gains(
self,
joint_positions: torch.Tensor,
target_positions: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Compute impedance control gains
Implement compliant control for environmental interaction adaptability
"""
position_error = target_positions - joint_positions
# Impedance control: τ = Kp*e + Kd*ė
Kp_scalar = 50.0
Kd_scalar = 5.0
return Kp_scalar, Kd_scalar
2.3 System 1: Visuomotor Policy
System 1 maps pixels directly to whole-body joint targets, which is key to achieving “what you see is what you do”:
# System 1 Visuomotor Policy Implementation
import torch
import torch.nn as nn
from typing import Dict, List, Tuple
class VisionTransformer(nn.Module):
"""Vision Encoder - Process multi-view image input"""
def __init__(
self,
image_size: int = 224,
patch_size: int = 16,
in_channels: int = 3,
embed_dim: int = 768,
num_heads: int = 12,
num_layers: int = 12
):
super().__init__()
# Image patching
self.num_patches = (image_size // patch_size) ** 2
self.patch_embed = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
# Position embedding
self.pos_embed = nn.Parameter(
torch.zeros(1, self.num_patches, embed_dim)
)
# Transformer encoder
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=num_heads,
dim_feedforward=embed_dim * 4,
dropout=0.1,
batch_first=True
)
self.transformer = nn.TransformerEncoder(
encoder_layer,
num_layers=num_layers
)
# Output projection
self.projection = nn.Linear(embed_dim, embed_dim)
def forward(self, images: torch.Tensor) -> torch.Tensor:
"""
Image feature extraction
Args:
images: [batch, num_cameras, 3, H, W] Multi-view images
Returns:
visual_features: [batch, feature_dim] Visual features
"""
batch_size, num_cameras, C, H, W = images.shape
# Merge all camera views
images_flat = images.view(-1, C, H, W)
# Extract patch features
patches = self.patch_embed(images_flat) # [B*C, embed_dim, H', W']
patches = patches.flatten(2).transpose(1, 2) # [B*C, H'*W', embed_dim]
# Add position encoding
patches = patches + self.pos_embed
# Transformer encoding
encoded = self.transformer(patches) # [B*C, H'*W', embed_dim]
# Global pooling
visual_features = encoded.mean(dim=1) # [B*C, embed_dim]
# Restore batch dimension and aggregate
visual_features = visual_features.view(batch_size, num_cameras, -1)
visual_features = visual_features.mean(dim=1) # [B, embed_dim]
return self.projection(visual_features)
class System1VisuomotorPolicy(nn.Module):
"""
System 1: Visuomotor Policy
Maps pixels directly to whole-body joint targets
"""
def __init__(
self,
num_joints: int = 41,
proprio_dim: int = 64,
latent_dim: int = 256,
s2_latent_dim: int = 128
):
super().__init__()
# Vision encoder
self.vision_encoder = VisionTransformer()
# Proprioception encoder
self.proprio_encoder = nn.Sequential(
nn.Linear(proprio_dim, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 256)
)
# Fusion layer
self.fusion = nn.Sequential(
nn.Linear(768 + 256, 512),
nn.ReLU(),
nn.Linear(512, latent_dim)
)
# S2 conditioning modulation
self.s2_modulation = nn.Linear(s2_latent_dim, latent_dim)
# Joint target decoder
self.joint_decoder = nn.Sequential(
nn.Linear(latent_dim, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, num_joints * 3) # position + velocity + acceleration
)
# Action confidence (for uncertainty estimation)
self.confidence_head = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(
self,
images: torch.Tensor, # [B, 4, 3, 224, 224] head + hands + depth cameras
proprioception: torch.Tensor, # [B, 64] Proprioception
s2_latents: torch.Tensor # [B, 128] System 2 semantic output
) -> Dict[str, torch.Tensor]:
"""
Forward pass
Args:
images: Multi-view images
proprioception: Proprioception state
s2_latents: System 2 semantic latent
Returns:
Joint targets and confidence
"""
# Visual features
visual_features = self.vision_encoder(images)
# Proprioception features
proprio_features = self.proprio_encoder(proprioception)
# Feature fusion
fused = torch.cat([visual_features, proprio_features], dim=-1)
latent = self.fusion(fused)
# S2 conditioning
s2_conditioned = latent * (1 + torch.tanh(self.s2_modulation(s2_latents)))
# Generate joint targets
joint_targets = self.joint_decoder(s2_conditioned)
num_joints = joint_targets.shape[-1] // 3
# Decompose into position, velocity, acceleration
positions = joint_targets[..., :num_joints]
velocities = joint_targets[..., num_joints:2*num_joints]
accelerations = joint_targets[..., 2*num_joints:]
# Action confidence
confidence = self.confidence_head(s2_conditioned)
return {
"positions": positions,
"velocities": velocities,
"accelerations": accelerations,
"confidence": confidence,
"latent": s2_conditioned
}
def compute_action(
self,
images: torch.Tensor,
proprioception: torch.Tensor,
s2_latents: torch.Tensor,
current_joint_positions: torch.Tensor
) -> torch.Tensor:
"""
Compute final action
Consider current state and safety constraints
"""
targets = self.forward(images, proprioception, s2_latents)
# Apply safety constraints
safe_positions = self.apply_safety_constraints(
targets["positions"],
current_joint_positions
)
# Blend target with safety constraints
final_action = (
0.7 * safe_positions +
0.3 * targets["positions"] * targets["confidence"]
)
return final_action
def apply_safety_constraints(
self,
target_positions: torch.Tensor,
current_positions: torch.Tensor
) -> torch.Tensor:
"""
Apply safety constraints
Prevent joint position sudden changes causing mechanical damage
"""
# Joint position limits
joint_limits = torch.tensor([
# Format: (min, max) for each joint
# Should be loaded from URDF or config file in actual use
] * 41, device=target_positions.device)
# Limit maximum single-step displacement
max_step = 0.1 # radians
position_delta = target_positions - current_positions
clamped_delta = torch.clamp(position_delta, -max_step, max_step)
safe_positions = current_positions + clamped_delta
# Apply joint limits
safe_positions = torch.clamp(
safe_positions,
joint_limits[:, 0],
joint_limits[:, 1]
)
return safe_positions
class VisuomotorRunner:
"""
Visuomotor policy runner
Responsible for hardware interface and execution frequency control
"""
def __init__(
self,
policy: System1VisuomotorPolicy,
control_freq: int = 200 # 200Hz
):
self.policy = policy
self.control_freq = control_freq
self.dt = 1.0 / control_freq
# Image buffer
self.image_buffer = []
self.max_buffer_size = 2
# Statistics
self.inference_times = []
@torch.no_grad()
def step(
self,
images: torch.Tensor,
proprioception: torch.Tensor,
s2_latents: torch.Tensor,
current_positions: torch.Tensor
) -> Dict[str, torch.Tensor]:
"""
Single-step inference
Returns:
Control commands
"""
import time
start = time.perf_counter()
# Execute inference
action = self.policy.compute_action(
images, proprioception, s2_latents, current_positions
)
# Record inference time
inference_time = time.perf_counter() - start
self.inference_times.append(inference_time)
# Return control commands
return {
"joint_targets": action,
"inference_time_ms": inference_time * 1000
}
2.4 System 2: Scene Understanding and Goal Planning
System 2 is responsible for high-level reasoning and goal decomposition:
# System 2 Scene Understanding and Goal Planning Implementation
import torch
import torch.nn as nn
from typing import List, Tuple, Dict
class SceneUnderstanding(nn.Module):
"""
System 2: Scene Understanding Module
Understand environmental semantics and goals
"""
def __init__(
self,
visual_dim: int = 768,
language_dim: int = 512,
hidden_dim: int = 1024,
num_objects: int = 100
):
super().__init__()
# Visual encoder
self.visual_encoder = nn.Sequential(
nn.Linear(visual_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# Language encoder
self.language_encoder = nn.Sequential(
nn.Linear(language_dim, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
# Object detection
self.object_detector = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, num_objects * 6) # bbox + class + confidence
)
# Scene graph construction
self.scene_graph = nn.MultiheadAttention(
embed_dim=hidden_dim,
num_heads=8,
batch_first=True
)
# Goal reasoning
self.goal_reasoner = nn.Sequential(
nn.Linear(hidden_dim * 2, hidden_dim),
nn.LayerNorm(hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 256) # goal embedding
)
def forward(
self,
visual_features: torch.Tensor,
language_features: torch.Tensor,
task_description: str
) -> Dict[str, torch.Tensor]:
"""
Scene understanding forward pass
"""
# Encode vision and language
vis_encoded = self.visual_encoder(visual_features)
lang_encoded = self.language_encoder(language_features)
# Object detection
object_predictions = self.object_detector(vis_encoded)
# Scene graph attention
scene_context, _ = self.scene_graph(
vis_encoded.unsqueeze(0),
vis_encoded.unsqueeze(0),
vis_encoded.unsqueeze(0)
)
# Goal reasoning
goal_features = torch.cat([vis_encoded, lang_encoded], dim=-1)
goal_embedding = self.goal_reasoner(goal_features)
return {
"visual_features": vis_encoded,
"language_features": lang_encoded,
"object_predictions": object_predictions,
"scene_context": scene_context.squeeze(0),
"goal_embedding": goal_embedding
}
class GoalDecomposer(nn.Module):
"""
Goal Decomposer
Decomposes high-level goals into executable sub-goal sequences
"""
def __init__(
self,
goal_dim: int = 256,
latent_dim: int = 128,
num_primitive_actions: int = 20
):
super().__init__()
# Goal encoder
self.goal_encoder = nn.Sequential(
nn.Linear(goal_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, latent_dim)
)
# Action vocabulary
self.action_vocabulary = nn.Parameter(
torch.randn(num_primitive_actions, latent_dim)
)
# Sequence decoder
self.sequence_decoder = nn.GRU(
input_size=latent_dim,
hidden_size=256,
num_layers=2,
batch_first=True
)
# Action prediction head
self.action_head = nn.Sequential(
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, num_primitive_actions)
)
# Termination prediction head
self.terminate_head = nn.Sequential(
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(
self,
goal_embedding: torch.Tensor,
max_steps: int = 20
) -> Tuple[List[int], torch.Tensor]:
"""
Goal decomposition forward pass
Returns:
action_sequence: Sub-goal sequence
terminate_probs: Termination probability at each step
"""
goal_encoded = self.goal_encoder(goal_embedding)
# Initialize decoder state
batch_size = goal_embedding.shape[0]
decoder_hidden = torch.zeros(2, batch_size, 256, device=goal_embedding.device)
# Decode action sequence
action_sequence = []
terminate_probs = []
current_input = goal_encoded.unsqueeze(1)
for step in range(max_steps):
output, decoder_hidden = self.sequence_decoder(
current_input, decoder_hidden
)
# Predict action
action_logits = self.action_head(output.squeeze(1))
action_probs = torch.softmax(action_logits, dim=-1)
action_id = action_probs.argmax(dim=-1)
action_sequence.append(action_id.item())
# Predict termination
terminate_prob = self.terminate_head(output.squeeze(1))
terminate_probs.append(terminate_prob.item())
# Stop decoding if termination probability is high
if terminate_prob.item() > 0.9:
break
# Update input using predicted action
current_input = self.action_vocabulary[action_id].unsqueeze(0)
return action_sequence, torch.tensor(terminate_probs)
class System2Module(nn.Module):
"""
System 2: Complete Module
Integrates scene understanding and goal decomposition
"""
def __init__(self):
super().__init__()
self.scene_understanding = SceneUnderstanding()
self.goal_decomposer = GoalDecomposer()
# Latent space projection (passed to System 1)
self.latent_projection = nn.Sequential(
nn.Linear(256 + 128, 256),
nn.ReLU(),
nn.Linear(256, 128)
)
def forward(
self,
visual_features: torch.Tensor,
language_features: torch.Tensor,
task_description: str
) -> Tuple[torch.Tensor, List[int]]:
"""
System 2 forward pass
"""
# Scene understanding
scene_output = self.scene_understanding(
visual_features, language_features, task_description
)
# Goal decomposition
action_sequence, terminate_probs = self.goal_decomposer(
scene_output["goal_embedding"]
)
# Generate latent to pass to System 1
latent = self.latent_projection(
torch.cat([
scene_output["goal_embedding"],
scene_output["scene_context"]
], dim=-1)
)
return latent, action_sequence
def get_semantic_latents(
self,
visual_features: torch.Tensor,
language_features: torch.Tensor,
task: str
) -> torch.Tensor:
"""
Get semantic latents (for System 1 conditioning)
"""
latent, _ = self.forward(visual_features, language_features, task)
return latent
3. Hardware Architecture: Figure 03 Specifications
3.1 Overall Hardware Configuration
# Figure 03 Hardware Configuration Class
from dataclasses import dataclass
from typing import Dict, List
@dataclass
class Figure03Specs:
"""Figure 03 Hardware Specifications"""
# Size and Weight
height_cm: float = 168.0
weight_kg: float = 60.0
mass_reduction_percent: float = 9.0 # 9% reduction vs 02
# DOF Configuration
total_dof: int = 41
joint_config: Dict[str, int] = None
# Dexterous Hand Specifications
hand_dof: int = 16
tactile_sensitivity_grams: float = 3.0 # Can detect 3-gram pressure
# Battery System
battery_capacity_kwh: float = 2.3
runtime_hours: float = 5.0
charging_power_kw: float = 2.0 # Wireless charging power
battery_swap_seconds: float = 30.0 # Hot-swap time
# Sensor Configuration
head_cameras: int = 2
head_fov_increase_percent: float = 60.0
frame_rate_improvement: float = 2.0
latency_reduction_percent: float = 75.0
# Data Transmission
wireless_bandwidth_gbps: float = 10.0 # mmWave
def __post_init__(self):
if self.joint_config is None:
self.joint_config = {
"left_leg": 6,
"right_leg": 6,
"torso": 3,
"left_arm": 8,
"right_arm": 8,
"head": 2,
"left_hand": 4, # thumb + 4 fingers
"right_hand": 4
}
def get_total_mass_breakdown(self) -> Dict[str, float]:
"""Get mass distribution"""
return {
"body": 25.0, # Main body
"arms": 8.0 * 2, # Both arms
"legs": 7.0 * 2, # Both legs
"head": 3.0, # Head
"battery": 8.0, # Battery
"electronics": 4.0 # Electronics
}
class ActuatorSystem:
"""
Actuator System
Figure 03 proprietary actuator configuration
"""
def __init__(self):
self.actuator_config = {
# Leg actuators (high torque)
"leg_joint": {
"max_torque_nm": 150,
"max_velocity_rpm": 60,
"weight_kg": 1.2,
"reduction_ratio": 100
},
# Arm actuators (medium torque, high speed)
"arm_joint": {
"max_torque_nm": 80,
"max_velocity_rpm": 120,
"weight_kg": 0.8,
"reduction_ratio": 80
},
# Dexterous hand actuators (fine control)
"hand_joint": {
"max_torque_nm": 5,
"max_velocity_rpm": 300,
"weight_kg": 0.1,
"reduction_ratio": 50
}
}
def get_speed_improvement(self) -> float:
"""Speed improvement vs previous generation"""
return 2.0 # 2x speed improvement
def get_torque_density(self) -> float:
"""Torque density (Nm/kg)"""
return 125 / 1.2 # ~104 Nm/kg
4. Simulation-to-Reality Transfer
4.1 Sim-to-Real Reinforcement Learning Framework
# Sim-to-Real Training Framework
import numpy as np
from typing import Dict, List, Tuple
import mujoco
import torch
import torch.nn as nn
class SimToRealTrainer:
"""
Simulation-to-Reality Transfer Trainer
Train policies using large-scale simulation environments
"""
def __init__(
self,
num_envs: int = 200000,
sim_time_step: float = 0.001,
control_time_step: float = 0.01
):
self.num_envs = num_envs
self.sim_dt = sim_time_step
self.control_dt = control_time_step
# Create simulation environment
self.sim_env = self._create_sim_env()
# Domain randomization parameters
self.domain_randomization = {
"friction": [0.5, 1.5],
"mass": [0.8, 1.2],
"delay": [0.0, 0.05],
"noise": [0.0, 0.1]
}
def _create_sim_env(self):
"""Create MuJoCo simulation environment"""
# Load Figure 03 model
model = mujoco.MjModel.from_xml_path("figure_03.xml")
data = mujoco.MjData(model)
return {"model": model, "data": data}
def randomize_domain(self):
"""Apply domain randomization"""
# Friction randomization
friction = np.random.uniform(*self.domain_randomization["friction"])
self.sim_env["model"].geom_friction[:] = friction
# Mass randomization
mass_scale = np.random.uniform(*self.domain_randomization["mass"])
for i in range(1, self.sim_env["model"].nbody):
self.sim_env["model"].body_mass[i] *= mass_scale
def collect_rollout(
self,
policy: nn.Module,
num_steps: int = 1000
) -> Dict[str, np.ndarray]:
"""
Collect simulation data rollout
Returns:
Experience data dictionary
"""
observations = []
actions = []
rewards = []
dones = []
# Initialize environment
self.sim_env["data"].reset()
self.randomize_domain()
for step in range(num_steps):
# Get observation
obs = self._get_observation()
observations.append(obs)
# Policy inference
with torch.no_grad():
action = policy(torch.tensor(obs).float().unsqueeze(0))
action = action.squeeze(0).numpy()
# Apply action
self.sim_env["data"].ctrl[:] = action
mujoco.mj_step(
self.sim_env["model"],
self.sim_env["data"],
int(self.control_dt / self.sim_dt)
)
actions.append(action)
# Compute reward
reward = self._compute_reward()
rewards.append(reward)
# Check termination
done = self._check_termination()
dones.append(done)
if done:
self.sim_env["data"].reset()
self.randomize_domain()
return {
"observations": np.array(observations),
"actions": np.array(actions),
"rewards": np.array(rewards),
"dones": np.array(dones)
}
def _get_observation(self) -> np.ndarray:
"""Get current observation"""
data = self.sim_env["data"]
# Joint positions
qpos = data.qpos[:self.sim_env["model"].nq]
# Joint velocities
qvel = data.qvel[:self.sim_env["model"].nv]
# Tactile sensors (simulated)
tactiles = data.sensordata[:16] # 16 fingertip sensors
# Merge observation
obs = np.concatenate([qpos, qvel, tactiles])
# Add noise
noise_scale = np.random.uniform(*self.domain_randomization["noise"])
obs += np.random.randn(len(obs)) * noise_scale
return obs
def _compute_reward(self) -> float:
"""Compute reward function"""
data = self.sim_env["data"]
# Task completion reward
task_reward = 0.0
# Balance reward
balance_reward = -0.1 * np.sum(data.qacc[:]**2)
# Energy penalty
energy_penalty = -0.01 * np.sum(data.ctrl[:]**2)
# Task-specific reward (sorting scenario)
if hasattr(data, 'object_placed'):
task_reward = 1.0 if data.object_placed else 0.0
return task_reward + balance_reward + energy_penalty
def _check_termination(self) -> bool:
"""Check if terminated"""
data = self.sim_env["data"]
# Fall detection
if data.body("torso").xpos[2] < 0.5:
return True
# Joint limit violation
if np.any(np.abs(data.qpos[:]) > np.pi * 2):
return True
return False
def train_ppo(
self,
policy: nn.Module,
value_net: nn.Module,
num_iterations: int = 1000,
steps_per_iteration: int = 10000
):
"""
PPO algorithm training
"""
optimizer_policy = torch.optim.Adam(policy.parameters(), lr=3e-4)
optimizer_value = torch.optim.Adam(value_net.parameters(), lr=1e-3)
for iteration in range(num_iterations):
# Collect data
rollout = self.collect_rollout(policy, steps_per_iteration)
# Compute advantage function
advantages, returns = self._compute_gae(
rollout["rewards"],
rollout["dones"]
)
# PPO update
for epoch in range(10): # PPO epochs
# Policy loss
actions = torch.tensor(rollout["actions"])
obs = torch.tensor(rollout["observations"])
log_probs_old = policy.get_log_prob(obs, actions)
# New policy
log_probs_new = policy.get_log_prob(obs, actions)
# PPO loss
ratio = torch.exp(log_probs_new - log_probs_old)
surr1 = ratio * torch.tensor(advantages)
surr2 = torch.clamp(
ratio,
1 - 0.2,
1 + 0.2
) * torch.tensor(advantages)
policy_loss = -torch.min(surr1, surr2).mean()
# Value function loss
values_pred = value_net(obs).squeeze()
value_loss = nn.MSELoss()(values_pred, torch.tensor(returns))
# Update
optimizer_policy.zero_grad()
policy_loss.backward()
optimizer_policy.step()
optimizer_value.zero_grad()
value_loss.backward()
optimizer_value.step()
print(f"Iteration {iteration}, Policy Loss: {policy_loss.item():.4f}")
5. Application Scenarios and Commercial Deployment
5.1 Logistics Sorting Scenario
# Logistics Sorting Application Implementation
class LogisticsSortingTask:
"""
Logistics Sorting Task
Figure 03's core commercial application scenario
"""
def __init__(self, figure_robot):
self.robot = figure_robot
self.current_zone = "inbound"
self.sorting_stats = {
"total": 0,
"success": 0,
"failed": 0,
"items_per_hour": []
}
def scan_package(self) -> Dict:
"""
Scan and identify package
"""
# Get images
images = self.robot.get_head_cameras()
# Use vision model to identify
package_info = self.vision_model.detect_package(images)
return {
"id": package_info["tracking_id"],
"destination": package_info["destination_zone"],
"weight": package_info["weight_kg"],
"dimensions": package_info["bbox_3d"],
"fragile": package_info["fragile_flag"]
}
def grasp_package(self, package_info: Dict) -> bool:
"""
Grasp package
Adjust grasping strategy based on package characteristics
"""
# Adjust grasping force based on weight
if package_info["weight"] > 10:
# Heavy items: two-hand grasp, larger contact area
grasp_force = 50 # Newtons
elif package_info["fragile"]:
# Fragile items: minimum force, precise control
grasp_force = 5 # Newtons (just enough to lift)
else:
# Normal packages
grasp_force = 20 # Newtons
# Execute grasp
success = self.robot.grasp(
target_pose=package_info["position"],
force=grasp_force,
approach_height=0.1
)
return success
def sort_to_destination(self, destination: str) -> bool:
"""
Sort package to destination
"""
# Navigate to destination zone
self.robot.navigate_to_zone(destination)
# Place package
success = self.robot.place(
target_zone=destination,
release_force=5 # Gentle placement
)
return success
def run_sorting_loop(self):
"""
Run sorting loop
"""
while True:
# 1. Scan package
package = self.scan_package()
# 2. Grasp
grasp_success = self.grasp_package(package)
if not grasp_success:
self.sorting_stats["failed"] += 1
continue
# 3. Sort
sort_success = self.sort_to_destination(package["destination"])
# 4. Record statistics
self.sorting_stats["total"] += 1
if sort_success:
self.sorting_stats["success"] += 1
else:
self.sorting_stats["failed"] += 1
# 5. Periodic report
if self.sorting_stats["total"] % 100 == 0:
self.report_stats()
def report_stats(self):
"""Report sorting statistics"""
total = self.sorting_stats["total"]
success = self.sorting_stats["success"]
print(f"""
=== Sorting Statistics ===
Total: {total}
Success: {success}
Failed: {total - success}
Success Rate: {100 * success / total if total > 0 else 0:.2f}%
""")
5.2 Industrial Manufacturing Scenario
# Industrial Assembly Application
class IndustrialAssemblyTask:
"""
Industrial Assembly Task
Figure 03's application in manufacturing
"""
def __init__(self, figure_robot):
self.robot = figure_robot
self.assembly_sequence = []
def visual_servoing(
self,
target_pose: np.ndarray
) -> np.ndarray:
"""
Visual servoing control
Vision-based feedback for precise pose control
"""
# Get current image
images = self.robot.get_palm_cameras()
# Detect target
target_in_image = self.vision_model.detect_target(images, target_pose)
# Compute image Jacobian
jacobian = self.compute_image_jacobian(target_in_image)
# Compute control increment
position_error = target_pose - self.robot.get_end_effector_pose()
velocity = position_error * 0.5 # Proportional control
return velocity
def precision_insertion(
self,
peg: Dict,
hole: Dict
) -> bool:
"""
Precision insertion
Typical assembly task
"""
# 1. Align
aligned = self.align_peg_hole(peg, hole)
if not aligned:
return False
# 2. Approach
approach_pose = hole["position"] + np.array([0, 0, 0.05])
self.robot.move_to(approach_pose, velocity=0.01)
# 3. Insert (use force control)
insertion_force = self.robot.force_control(
direction=np.array([0, 0, -1]),
target_force=2.0, # 2 Newtons
max_displacement=0.1
)
# 4. Verify
force_sensor = self.robot.get_force_sensor()
if np.linalg.norm(insertion_force) > 10:
return False # Insertion resistance too high
return True
def dual_arm_coordination(
self,
left_task: Dict,
right_task: Dict
):
"""
Dual-arm coordination task
Complex assembly requires both arms to work together
"""
# Define coordination frame
relative_pose = self.compute_relative_pose(left_task, right_task)
# Synchronized control
left_vel = self.visual_servoing(left_task["target"])
right_vel = self.visual_servoing(right_task["target"])
# Add coordination constraint
coordinated_left_vel = left_vel + 0.5 * relative_pose
coordinated_right_vel = right_vel - 0.5 * relative_pose
# Execute coordinated motion
self.robot.left_arm.set_velocity(coordinated_left_vel)
self.robot.right_arm.set_velocity(coordinated_right_vel)
6. Performance Metrics and Industry Comparison
| Metric | Figure 03 | Industry Average | Advantage Multiplier |
|---|---|---|---|
| Continuous Operation | 200+ hours | 8 hours | 25x |
| Sorting Efficiency | 2.7-3 sec/item | 4-5 sec/item | 1.5x |
| Recognition Accuracy | 99.7% | 95% | 1.05x |
| Failure Rate | 0/200 hours | 3-5/8 hours | 100x+ |
| Mass Production Cost | $40K (target) | $200-500K | 5-12x |
7. Conclusion and Outlook
Figure 03’s success marks embodied intelligence entering a new stage of development.
Core Technical Breakthroughs:
- Helix End-to-End Architecture: Replaced 109,504 lines of hand-written code with a single neural network
- System 0/1/2 Hierarchical Design: Balances real-time control and high-level reasoning
- Sim-to-Real Reinforcement Learning: 200,000+ simulation environment training
- Mass Production Scale: BotQ factory annual capacity target of 12,000 units
Implications for the Industry:
- End-to-end learning is the correct path toward general-purpose robots
- Large-scale simulation + domain randomization is an effective approach to solve Sim-to-Real gap
- Co-design of hardware and software is crucial
- Commercial deployment requires system engineering capability, not just algorithmic capability
Future Outlook:
- More complex manipulation tasks (assembly, repair)
- Multi-robot collaboration and swarm intelligence
- Expansion to home service scenarios
- Integration of humanoid robots with autonomous driving
Embodied intelligence is transitioning from “showing off capabilities” to “real deployment”. Figure 03 demonstrated with real data that humanoid robots have the potential to become “general-purpose labor”.
References
- Figure AI - Helix 02 Official Announcement
- Figure 03 Product Specification
- IEEE Spectrum - Figure 03 Technical Analysis
- Nature Robotics - Sim-to-Real Transfer in Humanoid Robotics