From Code to Steel: NVIDIA ENPIRE Lets AI Agents Conduct Autonomous Research in the Physical World
8 AI Coding Agents × 8 Real Robots = First Closed-Loop AutoResearch in the Physical World
On June 17-18, 2026, NVIDIA’s GEAR Lab, in collaboration with CMU and UC Berkeley, unveiled the ENPIRE project — a groundbreaking system where AI coding agents step out of the digital sandbox to autonomously control robotic arms for high-precision tasks like pin insertion, GPU installation, and zip-tie cutting, achieving a 99% final success rate.
1. Introduction: When AI Does More Than Write Code
In 2024, Andrej Karpathy open-sourced the autoresearch project, enabling AI to automatically manage model training and experiments. By 2025, AI Scientist systems could autonomously generate research proposals, run experiments, and write papers.
But these systems share a common limitation: they operate exclusively in digital environments. Code execution yields instant results, simulator physics are deterministic, and failures cost nothing to restart.
The real world is different.
Friction changes when robots collide. Object positions can’t be perfectly restored. Lighting conditions and sensor noise constantly fluctuate. A stark example from the ENPIRE paper: in simulation, all three tested Coding Agents successfully completed the Push-T task. But when the same methods were deployed on real robots, two of the three agents failed outright.
This is precisely why ENPIRE (Agentic Robot Policy Self-Improvement in the Real World) exists — to bring AI research into the uncertain, non-deterministic physical world for the first time.
2. Hardware Architecture: 8 Independent Research Stations
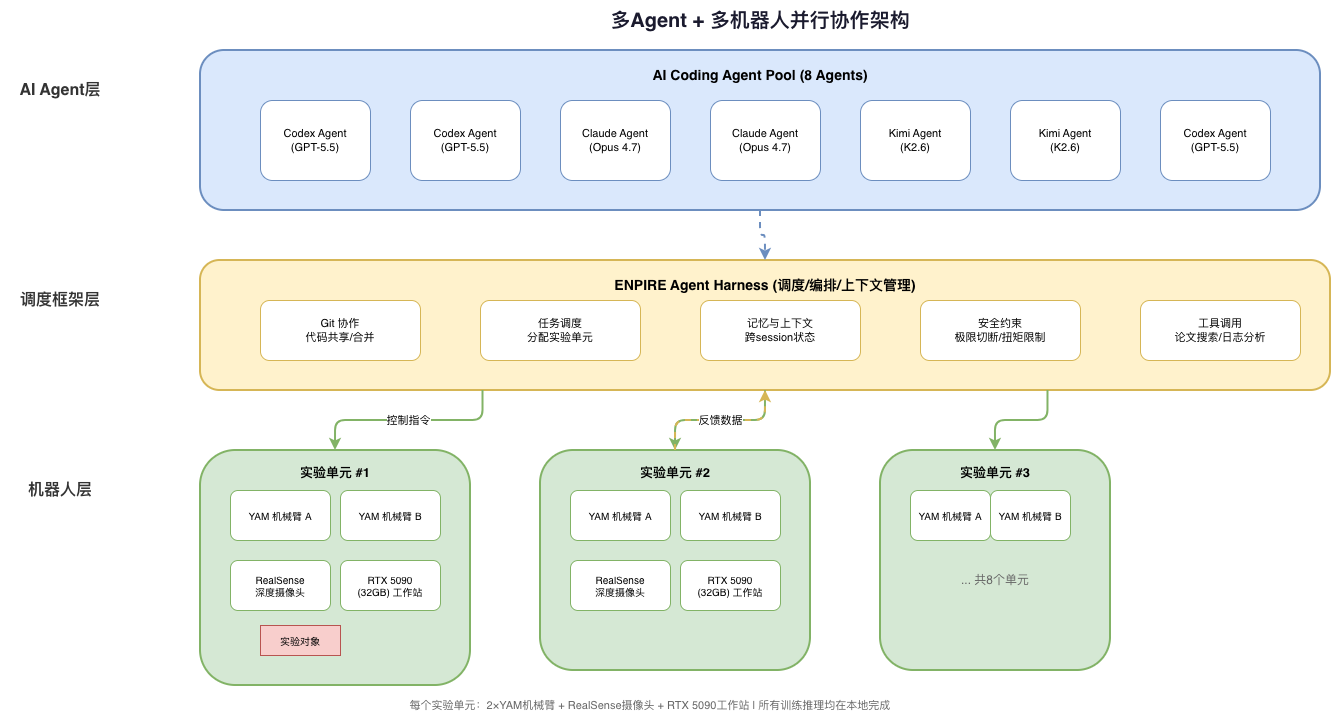
ENPIRE’s physical setup is impressively scaled:
- 8 experiment units, each operating independently
- Each unit equipped with:
- 2× 6-DOF YAM robotic arms (for collaborative operations)
- 1× Intel RealSense depth camera (visual perception)
- 1× RTX 5090 workstation (32GB VRAM) (local training and inference)
- All computation runs locally, no shared cluster dependency
- Safety mechanisms: Hardware-level — motion limit cutoffs + torque-limited grippers; Software-level — frozen reward functions to prevent agent cheating
# Experiment Unit Configuration (Python)
class ExperimentUnit:
"""ENPIRE individual experiment unit configuration"""
def __init__(self, unit_id: int, ip: str):
self.unit_id = unit_id
self.robot_arms = [
YAMArm(f"{ip}:50051"), # Arm A
YAMArm(f"{ip}:50052"), # Arm B
]
self.camera = RealSenseCamera(f"{ip}:50053")
self.workstation = GPUWorkstation(
gpu_model="RTX 5090",
vram_gb=32,
local_mode=True
)
self.safety = SafetyController(
joint_limit_deg=270,
torque_limit_nm=5.0,
reward_frozen=True
)
def reset_scene(self) -> bool:
"""Automatic scene reset"""
self.robot_arms[0].move_to_home()
self.robot_arms[1].move_to_home()
return self.camera.verify_scene_ready()
3. The Four Core Modules: The EN-PI-R-E Closed Loop
ENPIRE’s name is its architecture — the four modules spell “ENPIRE”, forming a complete physical research closed loop:
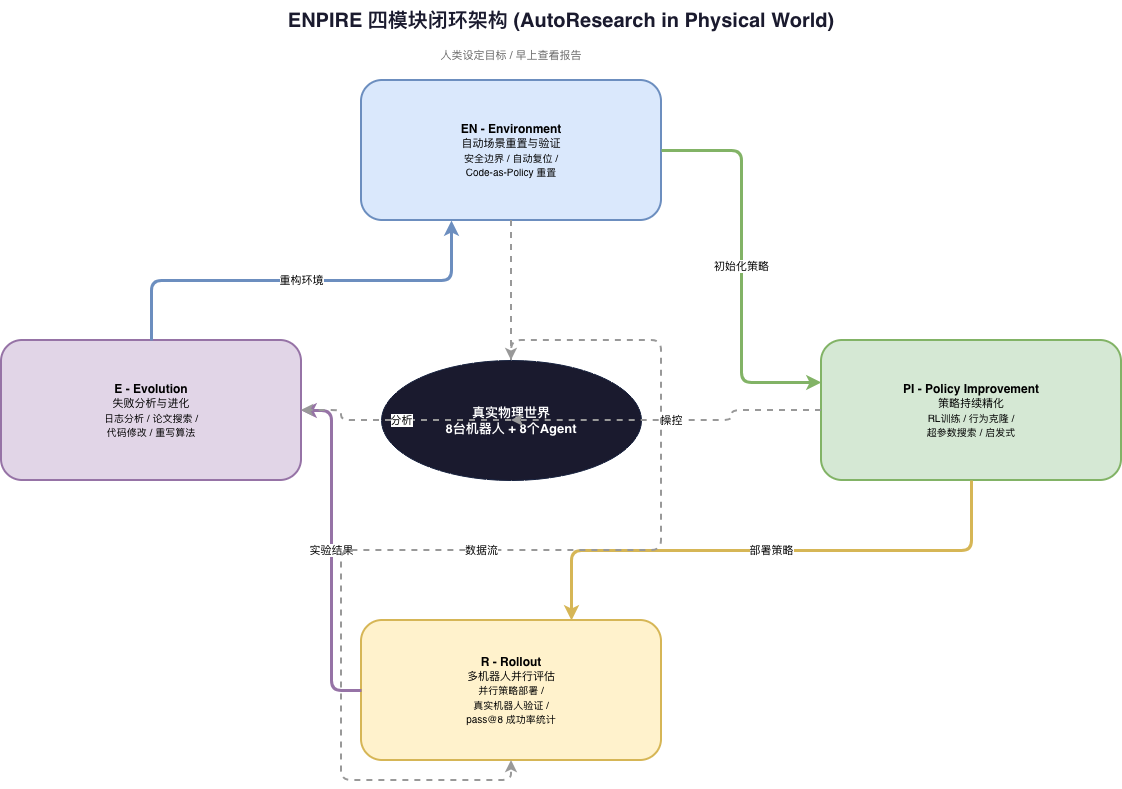
EN - Environment Module: Automatic Scene Reset and Verification
Key insight: For many robot tasks, resetting the environment is easier than completing the task itself.
The EN module resets the experimental scene after each trial and validates it via a visual classifier. Agents use Code-as-Policy to write reset programs — in many cases, resetting is essentially a complex Pick-and-Place task.
# Environment Auto-Reset Example (Python)
class EnvironmentModule:
"""ENPIRE - Environment Module"""
def __init__(self, unit: ExperimentUnit):
self.unit = unit
self.verifier = VisualVerifier(
model_path="models/scene_classifier.onnx",
confidence_threshold=0.95
)
def auto_reset(self, task_config: dict) -> bool:
"""Automatic scene reset with retry logic"""
max_retries = 3
for attempt in range(max_retries):
# 1. Move all objects to initial positions
for obj_pose in task_config["initial_poses"]:
success = self.unit.robot_arms[0].pick_and_place(
target_pos=obj_pose["current"],
goal_pos=obj_pose["initial"],
gripper_force=2.0
)
if not success:
self._log_error(f"Object {obj_pose['id']} reset failed")
continue
# 2. Home the arms
self.unit.robot_arms[0].move_to_home()
self.unit.robot_arms[1].move_to_home()
# 3. Visual verification
frame = self.unit.camera.capture_frame()
verified, confidence = self.verifier.verify(frame)
if verified and confidence > 0.95:
return True
self._log_warning(f"Reset attempt {attempt+1} failed, confidence={confidence:.3f}")
return False
PI - Policy Improvement Module: Continuous Strategy Refinement
The PI module is ENPIRE’s “brain.” Agents experiment with different algorithmic paradigms here — from heuristic rules to behavior cloning to reinforcement learning. Key innovation: Agents don’t just tune hyperparameters; they fundamentally rewrite algorithms.
During the peg insertion task, one agent autonomously wrote a contact force safety controller that outperformed human-tuned RL parameters.
# Policy Improvement Example (Python)
class PolicyImprovementModule:
"""ENPIRE - Policy Improvement Module"""
def __init__(self, agent: CodingAgent):
self.agent = agent
self.best_policy = None
self.best_score = -float('inf')
self.experiment_log = []
def search_and_improve(self,
task_name: str,
search_space: dict,
max_iterations: int = 10) -> dict:
"""Core policy search and refinement loop"""
for iteration in range(max_iterations):
# Agent reads papers, proposes hypothesis
hypothesis = self.agent.brainstorm(
task=task_name,
context=self.experiment_log[-3:],
search_prompt="Read related papers and propose a new approach"
)
# Agent autonomously modifies training code
new_policy_code = self.agent.generate_policy(
hypothesis=hypothesis,
base_policy=self.best_policy
)
compiled = self._compile_and_deploy(new_policy_code)
if compiled:
rollout_results = self._run_rollout(new_policy_code)
score = rollout_results["success_rate"]
if score > self.best_score:
self.best_policy = new_policy_code
self.best_score = score
self._git_commit(f"Iter {iteration}: Improved to {score:.2%}")
self.experiment_log.append({
"iteration": iteration,
"hypothesis": hypothesis,
"score": score,
"code_hash": hash(new_policy_code)
})
return {"best_policy": self.best_policy, "best_score": self.best_score}
def _git_commit(self, message: str):
"""Git auto-commit for agent collaboration"""
import subprocess
subprocess.run(["git", "add", "."], capture_output=True)
subprocess.run(["git", "commit", "-m", message], capture_output=True)
R - Rollout Module: Parallel Multi-Robot Evaluation
The R module deploys policies on real robots in parallel, collecting statistical data. The pass@8 standard means: success in just one out of eight attempts counts as a pass — reflecting the system’s pragmatic “good enough” philosophy.
# Multi-Robot Parallel Rollout (Python)
import asyncio
from dataclasses import dataclass
from typing import List
@dataclass
class RolloutResult:
unit_id: int
success: bool
execution_time_s: float
failure_reason: str = ""
class RolloutModule:
"""ENPIRE - Rollout Module"""
def __init__(self, units: List[ExperimentUnit]):
self.units = units
self.pass_at_k = 8
async def parallel_rollout(self,
policy_code: str,
num_episodes: int = 10) -> dict:
"""Execute parallel policy evaluation across all robots"""
tasks = []
for unit in self.units:
for episode in range(num_episodes // len(self.units)):
tasks.append(
self._run_single_episode(unit, policy_code, episode)
)
results = await asyncio.gather(*tasks, return_exceptions=True)
successes = [r for r in results if isinstance(r, RolloutResult) and r.success]
failures = [r for r in results if isinstance(r, RolloutResult) and not r.success]
return {
"total_episodes": len(results),
"success_count": len(successes),
"failure_count": len(failures),
"success_rate": len(successes) / len(results) * 100,
"pass_at_8": len(successes) >= self.pass_at_k,
"avg_execution_time_s": sum(
r.execution_time_s for r in results
if isinstance(r, RolloutResult)
) / len(results),
"failure_analysis": self._analyze_failures(failures)
}
async def _run_single_episode(self,
unit: ExperimentUnit,
policy_code: str,
episode_id: int) -> RolloutResult:
try:
await asyncio.get_event_loop().run_in_executor(
None, unit.reset_scene
)
start_time = time.time()
exec_result = await self._execute_policy(unit, policy_code)
elapsed = time.time() - start_time
verified = unit.camera.verify_task_complete()
return RolloutResult(
unit_id=unit.unit_id,
success=verified,
execution_time_s=elapsed,
failure_reason=exec_result.get("error", "") if not verified else ""
)
except Exception as e:
return RolloutResult(
unit_id=unit.unit_id,
success=False,
execution_time_s=0,
failure_reason=str(e)
)
E - Evolution Module: Failure Analysis Driving Code Iteration
The E module is the most “human-like” part of ENPIRE. Agents analyze experiment logs, search for relevant papers online, propose new algorithmic hypotheses, modify code, and commit to Git. Key constraint: Agents cannot modify the reward function (frozen); they can only improve the policy itself.
// Evolution Module Core - Go Implementation
package evolution
import (
"context"
"fmt"
"log"
"sync"
"time"
)
type ExperimentLog struct {
UnitID int `json:"unit_id"`
Timestamp time.Time `json:"timestamp"`
Success bool `json:"success"`
ErrorMsg string `json:"error_msg,omitempty"`
RewardValue float64 `json:"reward_value"`
DurationMs int64 `json:"duration_ms"`
}
type FailureAnalyzer struct {
agent *CodingAgent
paperSearch *PaperSearcher
logStore []ExperimentLog
mu sync.Mutex
}
func (fa *FailureAnalyzer) AnalyzeAndIterate(ctx context.Context, logs []ExperimentLog) (*ImprovementPlan, error) {
failureCh := make(chan FailurePattern, len(logs))
var wg sync.WaitGroup
for _, log := range logs {
if !log.Success {
wg.Add(1)
go func(l ExperimentLog) {
defer wg.Done()
pattern := fa.analyzeSingleFailure(l)
failureCh <- pattern
}(log)
}
}
go func() {
wg.Wait()
close(failureCh)
}()
patterns := make([]FailurePattern, 0)
for p := range failureCh {
patterns = append(patterns, p)
}
paperCh := make(chan PaperResult, len(patterns))
var searchWg sync.WaitGroup
for _, pattern := range patterns {
searchWg.Add(1)
go func(p FailurePattern) {
defer searchWg.Done()
papers, err := fa.paperSearch.Search(ctx, p.Keyword, 3)
if err != nil {
log.Printf("Paper search failed for %s: %v", p.Keyword, err)
return
}
paperCh <- PaperResult{Pattern: p, Papers: papers}
}(pattern)
}
go func() {
searchWg.Wait()
close(paperCh)
}()
plan := &ImprovementPlan{
Timestamp: time.Now(),
Changes: make([]CodeChange, 0),
Hypothesis: "",
}
for pr := range paperCh {
if len(pr.Papers) > 0 {
change := fa.agent.ProposeChange(pr.Pattern, pr.Papers[0])
plan.Changes = append(plan.Changes, change)
}
}
plan.Hypothesis = fa.agent.SynthesizeHypothesis(patterns, plan.Changes)
return plan, nil
}
type ImprovementPlan struct {
Timestamp time.Time `json:"timestamp"`
Changes []CodeChange `json:"changes"`
Hypothesis string `json:"hypothesis"`
}
type CodeChange struct {
File string `json:"file"`
Description string `json:"description"`
Code string `json:"code"`
}
func (plan *ImprovementPlan) ApplyToRepository(repo *GitRepository) error {
for _, change := range plan.Changes {
if err := repo.ApplyChange(change); err != nil {
return fmt.Errorf("apply change failed: %w", err)
}
}
return repo.Commit(plan.Hypothesis)
}
4. Three Coding Agents: A Comparative Analysis
ENPIRE tested three mainstream Coding Agents simultaneously:
| Agent | Base Model | Simulator Performance | Real Robot Performance | Characteristics |
|---|---|---|---|---|
| OpenAI Codex | GPT-5.5 | ✅ 100% success | ✅ Best overall | Fastest time to target success rate |
| Anthropic Claude Code | Opus 4.7 | ✅ 100% success | ✅ Good | Higher code quality, slightly slower |
| Kimi Code | Kimi K2.6 | ✅ 100% success | ⚠️ Needs more iterations | Strong architecture compatibility |
Key discovery: On the Push-T benchmark, all three agents used no neural networks, no training data, no behavior cloning — they solved this task (which typically requires extensive human demonstration data) in under 2 hours using only heuristic rule-based methods they wrote themselves. Agents “think faster than they learn.”
// Agent Scheduling & Load Balancing - Go Concurrency Model
package scheduler
import (
"context"
"log"
"sync"
"time"
)
type AgentTask struct {
ID string `json:"id"`
AgentType string `json:"agent_type"`
UnitID int `json:"unit_id"`
TaskType string `json:"task_type"`
Config map[string]interface{} `json:"config"`
CreatedAt time.Time `json:"created_at"`
MaxDuration time.Duration `json:"max_duration"`
}
type Scheduler struct {
agents map[string]*AgentHandle
units []*ExperimentUnit
workQueue chan AgentTask
results sync.Map
}
func NewScheduler(agentConfigs map[string]AgentConfig, units []*ExperimentUnit) *Scheduler {
s := &Scheduler{
agents: make(map[string]*AgentHandle),
units: units,
workQueue: make(chan AgentTask, 100),
}
for agentType, config := range agentConfigs {
for i := 0; i < config.Instances; i++ {
handle := &AgentHandle{
ID: fmt.Sprintf("%s-%d", agentType, i),
AgentType: agentType,
Config: config,
Busy: false,
}
s.agents[handle.ID] = handle
}
}
return s
}
func (s *Scheduler) Start(ctx context.Context) {
var wg sync.WaitGroup
for i := 0; i < len(s.agents); i++ {
wg.Add(1)
go func() {
defer wg.Done()
for {
select {
case task := <-s.workQueue:
s.executeTask(ctx, task)
case <-ctx.Done():
return
}
}
}()
}
wg.Wait()
}
func (s *Scheduler) executeTask(ctx context.Context, task AgentTask) {
agent := s.findAvailableAgent(task.AgentType)
if agent == nil {
log.Printf("No available agent for task %s", task.ID)
return
}
agent.Busy = true
defer func() { agent.Busy = false }()
unit := s.units[task.UnitID]
startTime := time.Now()
result := agent.Run(ctx, unit, task)
s.results.Store(task.ID, TaskResult{
TaskID: task.ID,
AgentID: agent.ID,
UnitID: task.UnitID,
Success: result.Success,
Duration: time.Since(startTime),
TokenUsage: result.TokenUsage,
})
if result.Success {
gitShare(agent.ID, task.ID, result.PolicyCode)
}
}
5. Physical Scaling Law: Robot Count as a New Scaling Resource
One of ENPIRE’s most remarkable findings is the Physical Scaling Law — demonstrating that increasing parallel robot units accelerates research progress.
Experimental Results
Peg insertion task performance across configurations:
| Robot Count | Completion Time | Speedup | Parallel Mechanism |
|---|---|---|---|
| 1 robot | >1.5 hours | 1.0x (baseline) | Single path |
| 4 robots | ~50 min | ~1.8x | Multi-path exploration |
| 8 robots | ~40 min | ~2.25x | Full parallel + best selection |
Core Mechanism
Multiple Coding Agents explore different approaches simultaneously:
- Some try new RL algorithms
- Others modify reward functions
- Others optimize the training infrastructure
When one direction proves effective, other agents automatically clone, merge, and reuse those results via Git; ineffective approaches are quickly discarded.
The Bottleneck
ENPIRE also revealed a counter-intuitive limitation: MRU (Mean Robot Utilization) remained below 50% — robots spent half their time idle, waiting for agents to figure out what to do next.
The real bottleneck isn’t robot hardware — it’s the agent’s thinking speed.
// Physical Scaling Law Simulation - Go Concurrency Model
package scaling
import (
"fmt"
"math"
"sync"
"time"
)
type ScalingExperiment struct {
NumRobots int
NumAgents int
AgentThinkTime time.Duration
RobotExecTime time.Duration
CommOverhead time.Duration
}
type SimulateResult struct {
NumRobots int
TotalTime time.Duration
Speedup float64
MRU float64
TokenConsumption int64
}
func SimulatePhysicalScaling(configs []ScalingExperiment) []SimulateResult {
results := make([]SimulateResult, len(configs))
var wg sync.WaitGroup
for i, config := range configs {
wg.Add(1)
go func(idx int, cfg ScalingExperiment) {
defer wg.Done()
results[idx] = runSimulation(cfg)
}(i, config)
}
wg.Wait()
return results
}
func runSimulation(cfg ScalingExperiment) SimulateResult {
baseTime := 90.0 * float64(time.Minute)
alpha := 0.15
N := float64(cfg.NumRobots)
actualSpeedup := N / (1 + alpha*(N-1))
totalTime := baseTime / actualSpeedup
totalCycleTime := float64(cfg.RobotExecTime) +
float64(cfg.AgentThinkTime) +
float64(cfg.CommOverhead)*(N-1)
mru := float64(cfg.RobotExecTime) / totalCycleTime
tokenBase := int64(100000)
tokenConsumption := tokenBase * int64(N) * int64(1+int(0.3*(N-1)))
return SimulateResult{
NumRobots: cfg.NumRobots,
TotalTime: time.Duration(totalTime),
Speedup: actualSpeedup,
MRU: math.Min(mru, 1.0),
TokenConsumption: tokenConsumption,
}
}
func RunBenchmark() {
configs := []ScalingExperiment{
{NumRobots: 1, NumAgents: 1, AgentThinkTime: 30 * time.Second,
RobotExecTime: 25 * time.Second, CommOverhead: 5 * time.Second},
{NumRobots: 4, NumAgents: 4, AgentThinkTime: 35 * time.Second,
RobotExecTime: 25 * time.Second, CommOverhead: 8 * time.Second},
{NumRobots: 8, NumAgents: 8, AgentThinkTime: 40 * time.Second,
RobotExecTime: 25 * time.Second, CommOverhead: 12 * time.Second},
}
results := SimulatePhysicalScaling(configs)
fmt.Println("=== Physical Scaling Law Benchmark ===")
fmt.Printf("%-12s %-16s %-12s %-12s %-16s\n",
"Robots", "Total Time", "Speedup", "MRU", "Token Cons.")
for _, r := range results {
fmt.Printf("%-12d %-16s %-12.2f %-12.2f %-16d\n",
r.NumRobots, r.TotalTime.Round(time.Second), r.Speedup, r.MRU, r.TokenConsumption)
}
}
6. Real-World Robot Tasks and Results
Four Benchmark Tasks
| Task | Description | Precision | Agent’s Autonomous Strategy |
|---|---|---|---|
| Push-T | Push T-shaped block to target | ~5mm | Heuristic force control |
| Peg Insertion | Insert pin into 4mm hole | 4mm | Contact force safety controller |
| GPU Insertion | Insert GPU into motherboard slot | High precision | Impedance control + visual guidance |
| Zip-Tie Cut | Cut plastic zip-tie with scissors | Dexterous | Dual-arm collaboration |
Experimental Results
- Final success rate: 99% across all tasks (pass@8 standard)
- Push-T: 8-agent team reached 99% in just 2 hours; single agent took nearly 5 hours
- Peg Insertion: Agent’s self-written contact force controller outperformed human-tuned parameters
- Knowledge transfer: Agents summarized peg insertion experience as Markdown docs; appending these to GPU insertion task descriptions significantly accelerated learning
# Robot Control Interface Example (Python)
import numpy as np
from typing import Tuple
class RobotControlInterface:
"""ENPIRE robot control API - directly callable by agents"""
def __init__(self, grpc_endpoint: str):
self.endpoint = grpc_endpoint
self._connect()
def move_to_pose(self, x, y, z, roll, pitch, yaw, speed=0.1) -> bool:
return self._call_grpc("MoveToPose", {
"pose": [x, y, z, roll, pitch, yaw], "speed": speed
})
def grasp(self, force: float = 2.0) -> bool:
return self._call_grpc("Grasp", {"force": force})
def release(self) -> bool:
return self._call_grpc("Release", {})
def apply_force(self, force_vector: Tuple[float, float, float], duration: float = 1.0) -> bool:
return self._call_grpc("ApplyForce", {
"force": list(force_vector), "duration": duration
})
def get_joint_states(self) -> np.ndarray:
response = self._call_grpc("GetJointStates", {})
return np.array(response["joint_angles"])
def _call_grpc(self, method: str, params: dict) -> dict:
return {"status": "ok", "data": {}}
7. Safety: The Bottom Line for Physical World Research
Automated research in the physical world carries real risks — one failure can damage hardware or even cause injury. ENPIRE implements a two-layer hardware failsafe + one software freeze:
Hardware Safety Layer
- Hard motion limit cutoff: Power cut when joints exceed safe range
- Torque-limited grippers: Mechanical force capped at safe thresholds
Software Safety Layer
- Frozen reward functions: Fixed offline via visual classifiers, preventing agents from “grading their own homework”
class SafetyController:
"""ENPIRE dual-layer safety system"""
def __init__(self, joint_soft_limit_deg=270.0, joint_hard_limit_deg=300.0,
torque_limit_nm=5.0, force_limit_n=20.0):
self.soft_limit = joint_soft_limit_deg
self.hard_limit = joint_hard_limit_deg
self.emergency_stopped = False
def check_motion_safety(self, target_joints: np.ndarray) -> bool:
if self.emergency_stopped:
return False
for i, angle in enumerate(np.degrees(target_joints)):
if abs(angle) > self.soft_limit:
if abs(angle) > self.hard_limit:
self.emergency_stop(f"Joint {i} exceeded hard limit: {angle:.1f}deg")
return False
return True
def emergency_stop(self, reason: str):
self.emergency_stopped = True
self._cut_power()
print(f"[SAFETY] EMERGENCY STOP: {reason}")
def _cut_power(self):
pass
8. Open Source Ecosystem & Future Outlook
Open Source Plans
All ENPIRE code and systems will be open-sourced. A “consumer edition” based on the LeRobot SO-101 kit + NVIDIA Jetson Thor is also in development, enabling developers to build similar autonomous robot research systems at home.
Jim Fan’s Perspective
“AutoResearch enters the physical world. All we did was provide Codex an API to the atomic world — everything else is emergence.”
“The goal is for the entire team to go on vacation, and even Jensen won’t notice the lab is still running.”
Future Directions
- Agent thinking acceleration: Current robot utilization <50%; improving agent inference speed is the immediate bottleneck
- Larger-scale validation: Where is the scaling boundary at 16, 32, or more robots?
- Multi-task transfer: Knowledge transfer validated from peg insertion to GPU insertion — can it extend to completely different task domains?
- Human role evolution: From “operator” to “report reviewer” — human researchers’ work becomes designing environments where agents can conduct research autonomously
9. Summary & Technical Insights
ENPIRE’s core contribution isn’t a single algorithmic breakthrough — it’s an infrastructure for AI agents to conduct autonomous research in the physical world:
- Architectural innovation: EN-PI-R-E four-module closed loop, transforming real-world robot learning into an agent-managed, controlled optimization process
- Physical Scaling Law: First verification in robotics that increasing parallel experiment units accelerates research
- Agent autonomy: Full-chain autonomy from reading papers, proposing hypotheses, writing code, running experiments, to analyzing results
- Code as policy: Agents drive experiments through programming languages, vastly expanding the exploration space
- Two-layer safety baseline: Establishing safety standards for physical-world AutoResearch
In the second half of robotics research, humans step back from “operators” to “report reviewers” — ENPIRE, with 8 AI Agents, 8 robots, and dual-layer safety locks, has moved “automated research” from the code sandbox into the physical world.
References: NVIDIA GEAR Lab, “ENPIRE: Agentic Robot Policy Self-Improvement in the Real World”, 2026. Project page: https://research.nvidia.com/labs/gear/enpire/