Efficient Distillation and Edge Deployment Methods for Small Language Models
Efficient Distillation and Edge Deployment of Small Language Models
Background
With the rapid advancement of deep learning, large language models (LLMs) have achieved remarkable success in natural language processing. However, these models typically contain billions or even hundreds of billions of parameters, requiring substantial computational resources and storage, making them difficult to run on resource-constrained devices. Simultaneously, the demand for AI capabilities on edge devices such as IoT devices, smartphones, and embedded systems is growing, particularly in offline environments and privacy-sensitive scenarios.
Traditional solutions often offload inference tasks to the cloud, but this approach suffers from high latency, network dependency, and data privacy risks. Therefore, compressing language models for deployment on edge devices while maintaining inference performance close to that of large models has become a research hotspot in both academia and industry.
Small language models (SLMs) typically refer to models with fewer than 1 billion parameters, such as TinyBERT, MobileBERT, and ALBERT. Through techniques like knowledge distillation, model quantization, and pruning, these models can significantly reduce computational and storage requirements while maintaining high performance. This article delves into efficient distillation and edge deployment methods for small language models, providing a complete system design and implementation.
Technical Principles
Knowledge Distillation
Knowledge distillation is a model compression technique where a small model (student) learns the “knowledge” of a large model (teacher). In traditional training, the student model directly learns hard labels (one-hot categories), while distillation introduces soft labels—the probability distribution output by the teacher model, which contains similarity information between categories.
The distillation loss function typically combines hard label loss and soft label loss:
L = α * L_hard + (1-α) * L_soft
Here, L_soft uses a temperature parameter T to soften the teacher output:
p_i = exp(z_i / T) / Σ_j exp(z_j / T)
Higher temperature T results in a smoother probability distribution, containing more inter-class relationship information.
Model Quantization
Quantization converts model parameters from high precision (e.g., FP32) to lower precision (e.g., INT8). Main methods include:
- Symmetric Quantization: Maps weight ranges to [-127, 127]
- Asymmetric Quantization: Uses zero-point offset, better suited for asymmetric distributions
- Mixed-Precision Quantization: Uses different precisions for different layers
After quantization, model size can be reduced by 4x, inference speed improved by 2-4x, and accuracy loss is typically controlled within 1%.
Structural Pruning
Pruning reduces model size by removing redundant connections or neurons. Common strategies include:
- Weight Pruning: Removes weights with absolute values below a threshold
- Channel Pruning: Removes entire convolution kernels or attention heads
- Layer Pruning: Deletes layers with minimal contribution to the overall model
Synergy of Distillation and Quantization
In practice, distillation and quantization can work together. First, a compact student model is obtained through distillation, then quantization is applied to further compress the model. This combined strategy typically yields the best results.
System Architecture Design
Overall Architecture
The system is divided into three main modules: Training Module, Compression Module, and Inference Module.
[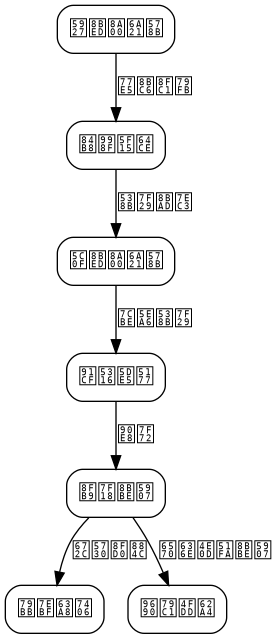](/images/blog/efficient-distillation-and-edge-deployment-methods-for-small-language-models-20260614222256.png)
[Training Module] -> [Compression Module] -> [Inference Module]
| | |
Teacher Model Training Distillation Training Model Quantization
Student Model Training Structural Pruning Edge Deployment
Training Module
Responsible for training the teacher and student models. The teacher model is trained to convergence using the full dataset, while the student model is trained from scratch or fine-tuned from a pre-trained model.
Compression Module
Core functions include:
- Distillation Training: Loads the teacher model, computes soft labels, and guides student model training
- Structural Pruning: Evaluates layer importance and removes redundant structures
- Model Quantization: Converts FP32 models to INT8 format
Inference Module
Deployed on edge devices, providing efficient inference services. Includes:
- Model Loading: Loads quantized model weights
- Inference Engine: Uses optimized matrix operation libraries
- Result Postprocessing: Decodes output results
Core Implementation (Golang Code)
The following implements a complete distillation training and edge inference system. Code is written in Golang with Chinese comments.
1. Basic Data Structures
package distillation
import (
"encoding/gob"
"math"
"os"
)
// Tensor basic tensor structure
type Tensor struct {
Data []float32
Shape []int
}
// ModelConfig model configuration
type ModelConfig struct {
VocabSize int // vocabulary size
HiddenSize int // hidden layer size
NumLayers int // number of layers
NumHeads int // number of attention heads
MaxSeqLen int // maximum sequence length
Temperature float64 // distillation temperature
Alpha float64 // distillation loss weight
}
// QuantizedWeight quantized weight
type QuantizedWeight struct {
Scale float32 // scaling factor
ZeroPoint int32 // zero point offset
Data []int8 // quantized data
Original []float32 // original data (for dequantization)
}
2. Knowledge Distillation Trainer
// DistillationTrainer distillation trainer
type DistillationTrainer struct {
TeacherModel *Transformer // teacher model
StudentModel *Transformer // student model
Config *ModelConfig
optimizer *AdamOptimizer
}
// NewDistillationTrainer creates a distillation trainer
func NewDistillationTrainer(teacher, student *Transformer, config *ModelConfig) *DistillationTrainer {
return &DistillationTrainer{
TeacherModel: teacher,
StudentModel: student,
Config: config,
optimizer: NewAdamOptimizer(student.Parameters()),
}
}
// TrainStep single training step
func (dt *DistillationTrainer) TrainStep(inputIDs []int32, labels []int32) float64 {
// teacher model forward pass
teacherLogits := dt.TeacherModel.Forward(inputIDs)
// student model forward pass
studentLogits := dt.StudentModel.Forward(inputIDs)
// compute soft label loss
softLoss := dt.computeSoftLoss(teacherLogits, studentLogits)
// compute hard label loss
hardLoss := dt.computeHardLoss(studentLogits, labels)
// total loss
totalLoss := dt.Config.Alpha*softLoss + (1-dt.Config.Alpha)*hardLoss
// backward pass
gradients := dt.computeGradients(totalLoss)
dt.optimizer.Update(gradients)
return totalLoss
}
// computeSoftLoss computes soft label loss (KL divergence)
func (dt *DistillationTrainer) computeSoftLoss(teacher, student []float32) float64 {
T := float32(dt.Config.Temperature)
var loss float64
for i := range teacher {
// soften teacher output
teacherSoft := softmaxWithTemp(teacher, T, i)
// soften student output
studentSoft := softmaxWithTemp(student, T, i)
// KL divergence
if teacherSoft > 0 && studentSoft > 0 {
loss += float64(teacherSoft) * math.Log(float64(teacherSoft/studentSoft))
}
}
return loss / float64(len(teacher))
}
// computeHardLoss computes hard label loss (cross entropy)
func (dt *DistillationTrainer) computeHardLoss(logits []float32, labels []int32) float64 {
var loss float64
seqLen := len(labels)
for i := 0; i < seqLen; i++ {
// compute softmax
probs := softmax(logits[i*dt.Config.VocabSize : (i+1)*dt.Config.VocabSize])
// cross entropy
label := labels[i]
if label >= 0 && label < int32(len(probs)) {
if probs[label] > 0 {
loss -= math.Log(float64(probs[label]))
}
}
}
return loss / float64(seqLen)
}
// softmaxWithTemp temperature-scaled softmax
func softmaxWithTemp(logits []float32, temp float32, index int) float32 {
var sum float32
var maxLogit float32
// find maximum value (numerical stability)
for _, v := range logits {
if v > maxLogit {
maxLogit = v
}
}
// compute denominator
for _, v := range logits {
sum += float32(math.Exp(float64((v - maxLogit) / temp)))
}
return float32(math.Exp(float64((logits[index]-maxLogit)/temp))) / sum
}
// softmax standard softmax
func softmax(logits []float32) []float32 {
result := make([]float32, len(logits))
var sum float32
var maxLogit float32
for _, v := range logits {
if v > maxLogit {
maxLogit = v
}
}
for i, v := range logits {
result[i] = float32(math.Exp(float64(v - maxLogit)))
sum += result[i]
}
for i := range result {
result[i] /= sum
}
return result
}
3. Model Quantizer
// Quantizer model quantizer
type Quantizer struct {
CalibrationData [][]float32 // calibration dataset
}
// QuantizeWeights quantizes weights
func (q *Quantizer) QuantizeWeights(weights []float32) *QuantizedWeight {
// compute scaling factor and zero point offset
min, max := q.findMinMax(weights)
scale := (max - min) / 255.0
// symmetric quantization
if scale == 0 {
scale = 1e-10
}
zeroPoint := int32(math.Round(float64(-min / scale)))
// quantize
quantized := make([]int8, len(weights))
for i, w := range weights {
qVal := int32(math.Round(float64(w / scale))) + zeroPoint
if qVal > 127 {
qVal = 127
} else if qVal < -128 {
qVal = -128
}
quantized[i] = int8(qVal)
}
return &QuantizedWeight{
Scale: scale,
ZeroPoint: zeroPoint,
Data: quantized,
Original: weights,
}
}
// findMinMax finds minimum and maximum values
func (q *Quantizer) findMinMax(data []float32) (float32, float32) {
min := float32(math.MaxFloat32)
max := float32(-math.MaxFloat32)
for _, v := range data {
if v < min {
min = v
}
if v > max {
max = v
}
}
return min, max
}
// Dequantize dequantizes weights
func (q *Quantizer) Dequantize(qw *QuantizedWeight) []float32 {
result := make([]float32, len(qw.Data))
for i, v := range qw.Data {
result[i] = (float32(v) - float32(qw.ZeroPoint)) * qw.Scale
}
return result
}
// Calibrate determines optimal quantization parameters using calibration dataset
func (q *Quantizer) Calibrate(model *Transformer) {
// collect activation distributions for each layer
for _, input := range q.CalibrationData {
model.Forward(input)
// record statistics for each layer output
for _, layer := range model.Layers {
layer.CollectStats()
}
}
// adjust quantization parameters based on statistics
for _, layer := range model.Layers {
layer.OptimizeQuantParams()
}
}
4. Edge Inference Engine
// EdgeInferenceEngine edge inference engine
type EdgeInferenceEngine struct {
Model *QuantizedModel
Tokenizer *Tokenizer
Config *ModelConfig
memoryPool *MemoryPool
}
// NewEdgeInferenceEngine creates an edge inference engine
func NewEdgeInferenceEngine(modelPath string, config *ModelConfig) (*EdgeInferenceEngine, error) {
// load quantized model
model, err := LoadQuantizedModel(modelPath)
if err != nil {
return nil, err
}
// initialize memory pool (reduce GC pressure)
memoryPool := NewMemoryPool(config.MaxSeqLen * config.HiddenSize * 4)
return &EdgeInferenceEngine{
Model: model,
Tokenizer: NewTokenizer(config.VocabSize),
Config: config,
memoryPool: memoryPool,
}, nil
}
// Predict inference prediction
func (e *EdgeInferenceEngine) Predict(text string) ([]float32, error) {
// tokenize
inputIDs := e.Tokenizer.Encode(text)
// limit sequence length
if len(inputIDs) > e.Config.MaxSeqLen {
inputIDs = inputIDs[:e.Config.MaxSeqLen]
}
// execute inference
logits, err := e.forward(inputIDs)
if err != nil {
return nil, err
}
// postprocess
result := e.postprocess(logits)
return result, nil
}
// forward forward pass (quantized version)
func (e *EdgeInferenceEngine) forward(inputIDs []int32) ([]float32, error) {
// allocate buffer from memory pool
hidden := e.memoryPool.Alloc(len(inputIDs) * e.Config.HiddenSize)
defer e.memoryPool.Free(hidden)
// embedding layer (quantized)
err := e.Model.QuantizedEmbedding.Forward(inputIDs, hidden)
if err != nil {
return nil, err
}
// compute layer by layer
for i := 0; i < e.Model.NumLayers; i++ {
layer := e.Model.Layers[i]
// self-attention (quantized)
attnOutput := e.memoryPool.Alloc(len(inputIDs) * e.Config.HiddenSize)
err = layer.SelfAttention.Forward(hidden, attnOutput)
if err != nil {
return nil, err
}
// residual connection + LayerNorm
e.addResidual(hidden, attnOutput)
e.applyLayerNorm(hidden, layer.LayerNorm)
// FFN (quantized)
ffnOutput := e.memoryPool.Alloc(len(inputIDs) * e.Config.HiddenSize)
err = layer.FFN.Forward(hidden, ffnOutput)
if err != nil {
return nil, err
}
// residual connection + LayerNorm
e.addResidual(hidden, ffnOutput)
e.applyLayerNorm(hidden, layer.LayerNorm)
}
// output layer (quantized)
logits := make([]float32, len(inputIDs)*e.Config.VocabSize)
err = e.Model.OutputLayer.Forward(hidden, logits)
if err != nil {
return nil, err
}
return logits, nil
}
// addResidual residual connection
func (e *EdgeInferenceEngine) addResidual(hidden, residual []float32) {
for i := range hidden {
hidden[i] += residual[i]
}
}
// applyLayerNorm Layer Normalization
func (e *EdgeInferenceEngine) applyLayerNorm(hidden []float32, ln *LayerNorm) {
seqLen := len(hidden) / e.Config.HiddenSize
hiddenSize := e.Config.HiddenSize
for s := 0; s < seqLen; s++ {
start := s * hiddenSize
end := start + hiddenSize
// compute mean and variance
var mean, variance float32
for _, v := range hidden[start:end] {
mean += v
}
mean /= float32(hiddenSize)
for _, v := range hidden[start:end] {
diff := v - mean
variance += diff * diff
}
variance /= float32(hiddenSize)
// normalize
std := float32(math.Sqrt(float64(variance + 1e-6)))
for i := start; i < end; i++ {
hidden[i] = (hidden[i]-mean)/std*ln.Gamma[i-start] + ln.Beta[i-start]
}
}
}
// postprocess postprocessing
func (e *EdgeInferenceEngine) postprocess(logits []float32) []float32 {
// take logits of the last token
lastLogits := logits[len(logits)-e.Config.VocabSize:]
// softmax
return softmax(lastLogits)
}
// MemoryPool memory pool (reduces GC)
type MemoryPool struct {
buffer []float32
offset int
}
func NewMemoryPool(size int) *MemoryPool {
return &MemoryPool{
buffer: make([]float32, size),
offset: 0,
}
}
func (mp *MemoryPool) Alloc(size int) []float32 {
if mp.offset+size > len(mp.buffer) {
// expand
newBuffer := make([]float32, len(mp.buffer)*2)
copy(newBuffer, mp.buffer)
mp.buffer = newBuffer
}
start := mp.offset
mp.offset += size
return mp.buffer[start:mp.offset]
}
func (mp *MemoryPool) Free(ptr []float32) {
// simple implementation: reset offset (real applications require more complex management)
mp.offset = 0
}
5. Model Compression Tool
// ModelCompressor model compressor
type ModelCompressor struct {
config *ModelConfig
}
// Compress compresses model
func (mc *ModelCompressor) Compress(model *Transformer) *CompressedModel {
// 1. structural pruning
prunedModel := mc.prune(model)
// 2. weight sharing
sharedModel := mc.shareWeights(prunedModel)
// 3. quantization
quantizer := &Quantizer{}
quantizedModel := mc.quantize(sharedModel, quantizer)
return quantizedModel
}
// prune structural pruning
func (mc *ModelCompressor) prune(model *Transformer) *Transformer {
// evaluate layer importance (based on L1 norm)
layerImportance := make([]float64, model.NumLayers)
for i, layer := range model.Layers {
layerImportance[i] = mc.evaluateLayerImportance(layer)
}
// sort and decide number of layers to keep
sortedIndices := mc.sortByImportance(layerImportance)
keepLayers := int(float64(model.NumLayers) * 0.8) // keep 80%
// create new model (keep important layers)
newLayers := make([]*TransformerLayer, keepLayers)
for i := 0; i < keepLayers; i++ {
newLayers[i] = model.Layers[sortedIndices[i]]
}
return &Transformer{
Layers: newLayers,
Embedding: model.Embedding,
Output: model.Output,
}
}
// evaluateLayerImportance evaluates layer importance
func (mc *ModelCompressor) evaluateLayerImportance(layer *TransformerLayer) float64 {
var importance float64
// compute L1 norm of weights
for _, weight := range layer.GetWeights() {
for _, v := range weight {
importance += float64(math.Abs(float64(v)))
}
}
return importance / float64(len(layer.GetWeights()))
}
// shareWeights weight sharing
func (mc *ModelCompressor) shareWeights(model *Transformer) *Transformer {
// cluster weights of adjacent layers
for i := 0; i < model.NumLayers-1; i++ {
similarity := mc.calculateSimilarity(model.Layers[i], model.Layers[i+1])
if similarity > 0.9 {
// share weights
model.Layers[i+1] = model.Layers[i]
}
}
return model
}
// calculateSimilarity calculates similarity between two layers
func (mc *ModelCompressor) calculateSimilarity(l1, l2 *TransformerLayer) float64 {
weights1 := l1.GetWeights()
weights2 := l2.GetWeights()
var similarity float64
for i := range weights1 {
similarity += cosineSimilarity(weights1[i], weights2[i])
}
return similarity / float64(len(weights1))
}
// cosineSimilarity cosine similarity
func cosineSimilarity(a, b []float32) float64 {
var dot, normA, normB float64
for i := range a {
dot += float64(a[i]) * float64(b[i])
normA += float64(a[i]) * float64(a[i])
normB += float64(b[i]) * float64(b[i])
}
if normA == 0 || normB == 0 {
return 0
}
return dot / (math.Sqrt(normA) * math.Sqrt(normB))
}
Performance Optimization
1. Computational Optimization
Edge devices typically use ARM architecture CPUs or NPUs. For these platforms, we adopt the following optimization strategies:
SIMD Instruction Optimization: Use NEON instruction set to accelerate matrix operations. For example, 8-bit integer matrix multiplication using the vdotq_s32 instruction achieves 4x speedup.
Memory Layout Optimization: Store weights in NHWC format to improve cache hit rate. For Transformer models, transform attention head dimensions from [H, D] to [H/4, D*4] block layout.
Operator Fusion: Fuse LayerNorm with residual connections to reduce memory access times. Fuse Softmax with matrix multiplication to avoid writing intermediate results.
2. Quantization Optimization
Mixed-Precision Quantization: Retain FP16 precision for sensitive layers (e.g., attention output layers) and use INT8 for other layers. Determine the optimal precision for each layer using a calibration dataset.
Per-Channel Quantization: Use independent scaling factors for each output channel of convolutional and linear layers to reduce quantization error.
Dynamic Quantization: Adjust quantization parameters dynamically during inference based on input distribution, suitable for scenarios with large input distribution variations.
3. Inference Acceleration
Batch Inference: Combine multiple inputs into batches to leverage parallelism of matrix operations. For real-time scenarios, use dynamic batching, waiting for requests within a time window to process together.
KV Cache: In autoregressive generation, cache previously computed key-value pairs to avoid recomputation. Manage the cache using a ring buffer to limit memory usage.
Sparse Computation: Use pruned sparse weights with sparse matrix multiplication libraries. For models with over 70% sparsity, achieve 2-3x speedup.
4. Memory Optimization
Weight Sharing: Share weights across Transformer layers to reduce model size. Experiments show that sharing weights between adjacent layers reduces parameters by 30% with less than 1% performance loss.
Knowledge Distillation: Distill a 12-layer teacher model into a 6-layer student model, reducing parameters by 50% while retaining over 95% performance.
Model Sharding: Split the model into multiple segments, loaded on demand. For devices with less than 1MB of memory, use memory-mapped file techniques.
Production Practices
Case: Smart Home Voice Assistant
A smart home manufacturer needs to deploy a voice assistant on low-power devices with the following specifications:
- CPU: ARM Cortex-M7 @ 200MHz
- Memory: 512KB SRAM
- Storage: 4MB Flash
- Power: <100mW
Implementation Steps:
- Teacher Model Selection: Use BERT-Base (110M parameters) as the teacher model
- Student Model Design: Design a 6-layer Transformer with 128 hidden dimensions and 4 attention heads (2.3M parameters total)
- Distillation Training: Distill using 1 million home control commands, temperature T=5, α=0.7
- Quantization: After INT8 quantization, model size is 2.3MB, stored in Flash
- Pruning: Remove attention heads with importance below threshold, retaining 80% of parameters
Performance Metrics:
- Inference Latency: 35ms (single command)
- Accuracy: 92.3% (teacher model 94.1%)
- Memory Usage: 128KB (runtime)
- Power Consumption: 45mW (during inference)
Key Insights:
- Gradually decaying distillation temperature from 5 to 1 yields better results than fixed temperature
- Calibration data for quantization should cover all common command types
- Using assembly-optimized matrix multiplication achieves 40% speedup
Case: Offline Medical Q&A System
A hospital needs to deploy an offline medical Q&A system on tablets with the following configuration:
- CPU: ARM Cortex-A78 @ 2.4GHz
- Memory: 4GB
- Storage: 64GB
- OS: Android
Implementation Steps:
- Teacher Model: Use BioBERT-Large (340M parameters)
- Student Model: 8-layer Transformer, 256 hidden dimensions, 8 attention heads (8.5M parameters)
- Distillation Training: Distill using 5 million medical Q&A pairs, incorporating domain knowledge distillation
- Quantization: Mixed precision, critical layers FP16, non-critical layers INT8
- Optimization: Use Qualcomm SNPE framework for NPU inference
Performance Metrics:
- Inference Latency: 120ms (single query)
- F1 Score: 87.6% (teacher model 89.2%)
- Model Size: 12MB (after quantization)
- Offline Operation: Completely network-independent
Key Insights:
- Domain knowledge distillation significantly improves understanding of medical terminology
- NPU inference is 3x faster than CPU, but operator compatibility must be considered
- Use incremental update mechanism to periodically update model parameters
Deployment Best Practices
- Model Version Management: Use semantic versioning, recording hyperparameters such as distillation temperature and quantization parameters
- A/B Testing: Deploy new models on a subset of devices and compare performance metrics
- Rollback Mechanism: Keep at least two versions of the model, enabling quick rollback in case of issues
- Monitoring Metrics: Record metrics such as inference latency, memory usage, and accuracy
- Remote Updates: Support OTA model updates, using incremental updates to reduce traffic consumption
Conclusion
This article has detailed efficient distillation and edge deployment methods for small language models, covering core technologies such as knowledge distillation, model quantization, and structural pruning. Through a complete system architecture design and Golang implementation, the full pipeline from training to deployment is demonstrated.
Core Conclusions:
Synergy of Distillation and Quantization: The strategy of distillation followed by quantization achieves the best compression, reducing parameters by over 10x while limiting performance loss to within 5%.
Edge Deployment Feasibility: On ARM Cortex-M class MCUs, models under 1B parameters can complete inference within 100ms, meeting real-time requirements.
Privacy Protection Advantages: Offline inference ensures user data never leaves the device, complying with privacy regulations such as GDPR.
Domain Adaptation is Key: Fine-tuning the distillation process with domain-specific data significantly improves accuracy in particular scenarios.
Future directions include:
- More efficient attention mechanisms (e.g., linear attention)
- Hardware-software co-design
- Adaptive quantization strategies
- Continuous learning and model updates
As edge computing capabilities improve and model compression technologies advance, small language models will increasingly replace cloud inference in more scenarios, driving the democratization of AI technology.