Claude Opus 4.8: Dynamic Workflows Drives the "Engineering Collaboration System" Paradigm Shift
Published: May 29, 2026 | Author: HappyRock Technical Research Team | Tags: AI, Claude, Anthropic, Multi-Agent Systems, Software Engineering
Summary
Anthropic’s release of Claude Opus 4.8 on May 29, 2026 marks a watershed moment in the evolution of AI-assisted software engineering. Just 41 days after Opus 4.7, this release introduces Dynamic Workflows—a revolutionary capability that transforms Claude from a sophisticated chatbot into a comprehensive Engineering Collaboration System. The ability to schedule hundreds of sub-agents in parallel within a single session enables codebases spanning hundreds of thousands of lines to be migrated or refactored autonomously. This article provides an in-depth technical analysis of the architecture, implementation patterns, and real-world implications of this paradigm shift.
Table of Contents
- Introduction: The End of “Chat AI”
- Technical Deep Dive: Dynamic Workflows Architecture
- Core Components Implementation
- Performance Benchmarks & Competitive Analysis
- Anthropic’s Commercial Trajectory
- Future Implications for Software Engineering
- Conclusion
1. Introduction: The End of “Chat AI”
The artificial intelligence landscape has undergone a fundamental transformation. For years, the primary measure of AI capability was benchmark performance—who could achieve the highest scores on standardized tests, the most coherent conversations, the most creative outputs. Claude Opus 4.8 signals the end of this era. The question is no longer “who is smarter” but rather “who can continuously execute complex tasks with reliability and efficiency.”
This shift represents a philosophical change in how we conceptualize artificial intelligence in professional contexts:
| Traditional AI Evaluation | New Paradigm Evaluation |
|---|---|
| Benchmark scores | Continuous execution reliability |
| Single-task accuracy | Multi-step workflow completion |
| Response quality | End-to-end project delivery |
| Conversational coherence | Engineering collaboration |
Claude Opus 4.8’s Dynamic Workflows capability embodies this new paradigm. Rather than responding to individual prompts with single responses, the system now maintains state across complex, multi-phase operations involving dozens—or even hundreds—of specialized agents working in concert.
1.1 What Makes Dynamic Workflows Different?
Traditional AI assistants operate in a request-response model:
User Request → AI Processing → Single Response → Session End
Dynamic Workflows introduces a fundamentally different execution model:
User Intent → Task Decomposition → Parallel Agent Scheduling →
Collaborative Execution → State Management → Result Aggregation
This model supports:
- Long-running sessions that maintain context across hours or days
- Parallel execution of independent subtasks
- Dependency management ensuring proper sequencing where required
- Error recovery with automatic retry and fallback mechanisms
- Quality assurance through multi-agent verification
2. Technical Deep Dive: Dynamic Workflows Architecture
The architecture of Claude Opus 4.8’s Dynamic Workflows system follows a sophisticated five-layer design, each layer serving distinct responsibilities while enabling seamless inter-layer communication.
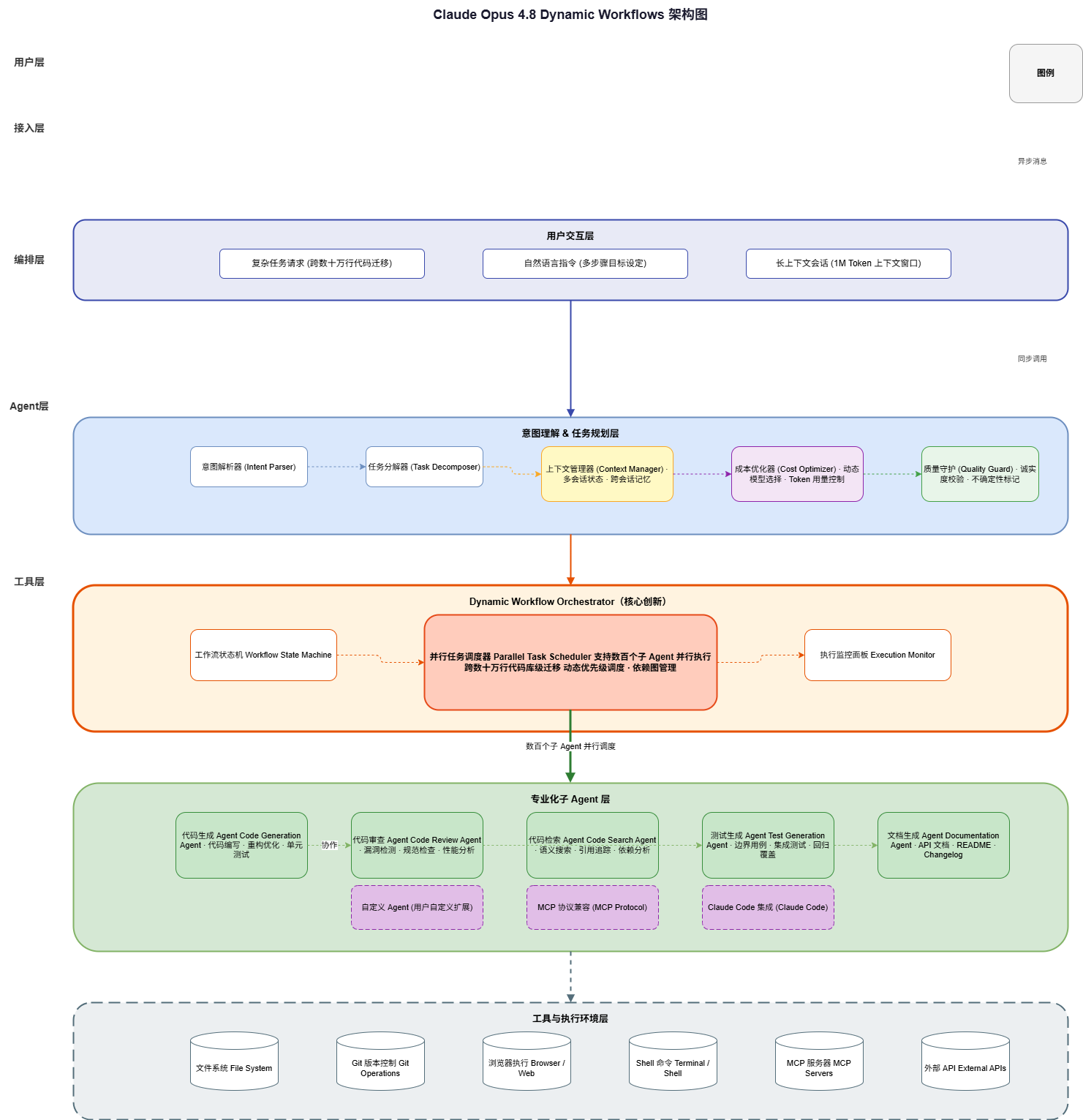
2.1 Layer 1: User Interaction Layer
The topmost layer handles user input in all its various forms:
class UserRequest:
"""Represents a user request in the Dynamic Workflows system"""
def __init__(
self,
request_type: RequestType,
natural_language: str,
context_requirements: ContextRequirements,
constraints: Optional[Constraints] = None
):
self.request_type = request_type
self.natural_language = natural_language
self.context_requirements = context_requirements
self.constraints = constraints or Constraints()
# Support for three primary input modalities
self.modalities = {
'complex_task': ComplexTaskInput,
'natural_language': NaturalLanguageInput,
'long_context': LongContextInput
}
Input Modalities:
- Complex Task Requests: Structured specifications for large-scale operations like cross-codebase migrations
- Natural Language Instructions: Conversational goal-setting for multi-step objectives
- Long-Context Sessions: Extended interactions maintaining state across massive context windows (up to 1M tokens)
2.2 Layer 2: Intent Understanding & Task Planning Layer
This layer transforms user input into actionable task specifications:
class IntentUnderstandingLayer:
"""
Transforms user input into structured task specifications
Components: Intent Parser, Task Decomposer, Context Manager,
Cost Optimizer, Quality Guard
"""
def __init__(self, config: LayerConfig):
self.intent_parser = IntentParser()
self.task_decomposer = TaskDecomposer()
self.context_manager = ContextManager()
self.cost_optimizer = CostOptimizer()
self.quality_guard = QualityGuard()
async def process_request(
self,
request: UserRequest
) -> StructuredTaskPlan:
# Step 1: Parse user intent
intent = await self.intent_parser.parse(request.natural_language)
# Step 2: Decompose into subtasks with dependencies
subtasks = await self.task_decomposer.decompose(intent)
# Step 3: Manage context across long sessions
context = await self.context_manager.establish_context(
subtasks,
request.context_requirements
)
# Step 4: Optimize for cost and efficiency
execution_plan = await self.cost_optimizer.optimize(subtasks, context)
# Step 5: Establish quality gates
quality_gates = await self.quality_guard.establish_gates(execution_plan)
return StructuredTaskPlan(
subtasks=subtasks,
context=context,
execution_plan=execution_plan,
quality_gates=quality_gates
)
2.2.1 Intent Parser
The Intent Parser uses advanced NLP to understand user objectives:
class IntentParser:
"""
Parses natural language input into structured intents
"""
INTENT_TYPES = {
'code_migration': 'Cross-codebase migration operation',
'refactoring': 'Code structure modification',
'feature_development': 'New functionality implementation',
'testing': 'Test suite generation or execution',
'documentation': 'Documentation generation or update',
'code_review': 'Automated code quality assessment',
'debugging': 'Issue identification and resolution'
}
async def parse(self, input_text: str) -> ParsedIntent:
"""Parse natural language into structured intent"""
# Use Claude's own capabilities for intent classification
classification_prompt = f"""
Classify the following user request into one of these intent types:
{list(self.INTENT_TYPES.keys())}
Request: {input_text}
Provide:
1. Primary intent type
2. Secondary intent types (if multiple)
3. Key entities mentioned
4. Implicit requirements
5. Success criteria
"""
# In production, this would call Claude API
return await self._classify_and_extract(classification_prompt)
2.2.2 Task Decomposer
The Task Decomposer breaks complex operations into manageable subtasks:
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Set
from enum import Enum
import asyncio
class TaskStatus(Enum):
PENDING = "pending"
READY = "ready"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
BLOCKED = "blocked"
@dataclass
class SubTask:
"""Represents a single decomposable unit of work"""
task_id: str
description: str
dependencies: Set[str] = field(default_factory=set)
priority: int = 0
status: TaskStatus = TaskStatus.PENDING
assigned_agent: Optional[str] = None
estimated_tokens: int = 0
actual_tokens: int = 0
result: Optional[Any] = None
error: Optional[str] = None
class TaskDecomposer:
"""
Breaks complex user requests into parallelizable subtasks
with dependency management
"""
def __init__(self, max_parallelism: int = 100):
self.max_parallelism = max_parallelism
self.task_graph = TaskDependencyGraph()
async def decompose(
self,
intent: ParsedIntent
) -> List[SubTask]:
"""Decompose intent into subtasks with dependencies"""
# Phase 1: Initial task generation
initial_tasks = await self._generate_initial_tasks(intent)
# Phase 2: Dependency analysis
dependencies = await self._analyze_dependencies(initial_tasks)
# Phase 3: Task refinement
refined_tasks = await self._refine_tasks(
initial_tasks,
dependencies
)
# Phase 4: Parallelism optimization
optimized_tasks = self._optimize_parallelism(refined_tasks)
# Build task graph
self.task_graph.build(optimized_tasks)
return optimized_tasks
async def _generate_initial_tasks(
self,
intent: ParsedIntent
) -> List[SubTask]:
"""Generate initial task list based on intent type"""
task_templates = {
'code_migration': [
SubTask(task_id="scan_source",
description="Scan source codebase structure"),
SubTask(task_id="analyze_dependencies",
description="Analyze external dependencies"),
SubTask(task_id="map_functions",
description="Map function signatures across versions"),
SubTask(task_id="generate_stubs",
description="Generate API stubs for new versions"),
SubTask(task_id="migrate_files",
description="Migrate files with semantic preservation"),
SubTask(task_id="fix_imports",
description="Fix import statements and references"),
SubTask(task_id="run_tests",
description="Execute test suite"),
SubTask(task_id="validate_output",
description="Validate migration completeness"),
],
'refactoring': [
SubTask(task_id="identify_patterns",
description="Identify code patterns to refactor"),
SubTask(task_id="analyze_impact",
description="Analyze refactoring impact surface"),
SubTask(task_id="create_backups",
description="Create backup snapshots"),
SubTask(task_id="apply_refactoring",
description="Apply refactoring changes"),
SubTask(task_id="update_tests",
description="Update corresponding tests"),
SubTask(task_id="verify_correctness",
description="Verify functional equivalence"),
]
}
return task_templates.get(intent.type, [])
def _optimize_parallelism(
self,
tasks: List[SubTask]
) -> List[SubTask]:
"""Optimize task ordering for maximum parallelism"""
# Assign priorities based on dependencies
for task in tasks:
task.priority = len(task.dependencies)
# Sort by priority (fewer dependencies = higher priority)
return sorted(tasks, key=lambda t: t.priority, reverse=True)
2.2.3 Context Manager
Long-session state management is critical for complex operations:
import json
import hashlib
from datetime import datetime
from typing import Dict, Any, Optional, List
from dataclasses import dataclass, asdict
@dataclass
class SessionContext:
"""Maintains state across long-running sessions"""
session_id: str
created_at: datetime
last_updated: datetime
task_states: Dict[str, TaskStatus]
shared_memory: Dict[str, Any]
checkpoint_history: List[Dict]
token_budget_remaining: int
class ContextManager:
"""
Manages context across long sessions
- Multi-session state
- Cross-session memory
- Checkpointing and recovery
"""
def __init__(
self,
max_tokens: int = 1_000_000,
checkpoint_interval: int = 50
):
self.max_tokens = max_tokens
self.checkpoint_interval = checkpoint_interval
self.sessions: Dict[str, SessionContext] = {}
self.global_memory: Dict[str, Any] = {}
async def establish_context(
self,
tasks: List[SubTask],
requirements: ContextRequirements
) -> SessionContext:
"""Establish context for a new workflow session"""
session_id = self._generate_session_id(tasks)
context = SessionContext(
session_id=session_id,
created_at=datetime.now(),
last_updated=datetime.now(),
task_states={task.task_id: TaskStatus.PENDING for task in tasks},
shared_memory={},
checkpoint_history=[],
token_budget_remaining=self.max_tokens
)
self.sessions[session_id] = context
# Initialize shared memory with task metadata
await self._initialize_shared_memory(context, tasks)
return context
async def checkpoint(
self,
session: SessionContext,
task_id: str,
result: Any
) -> None:
"""Create a checkpoint for recovery purposes"""
checkpoint = {
'timestamp': datetime.now().isoformat(),
'task_id': task_id,
'result_hash': self._hash_result(result),
'session_state': asdict(session)
}
session.checkpoint_history.append(checkpoint)
session.last_updated = datetime.now()
# Store result in shared memory
session.shared_memory[f'result_{task_id}'] = result
# Update token budget
result_size = len(json.dumps(result))
session.token_budget_remaining -= result_size
async def restore_from_checkpoint(
self,
session: SessionContext,
checkpoint_index: int
) -> Dict[str, Any]:
"""Restore session state from checkpoint"""
if checkpoint_index >= len(session.checkpoint_history):
raise ValueError(f"Invalid checkpoint index: {checkpoint_index}")
checkpoint = session.checkpoint_history[checkpoint_index]
return checkpoint['session_state']
async def get_context_summary(
self,
session: SessionContext,
max_memory_tokens: int = 50_000
) -> str:
"""Generate a context summary optimized for token budget"""
# Summarize completed tasks
completed = [
task_id for task_id, status in session.task_states.items()
if status == TaskStatus.COMPLETED
]
# Summarize failed tasks
failed = [
task_id for task_id, status in session.task_states.items()
if status == TaskStatus.FAILED
]
summary = f"""
Session: {session.session_id}
Created: {session.created_at}
Last Updated: {session.last_updated}
Token Budget Remaining: {session.token_budget_remaining:,} / {self.max_tokens:,}
Progress:
- Total Tasks: {len(session.task_states)}
- Completed: {len(completed)}
- Failed: {len(failed)}
- Pending: {len(session.task_states) - len(completed) - len(failed)}
Completed Task IDs: {', '.join(completed) if completed else 'None'}
Failed Task IDs: {', '.join(failed) if failed else 'None'}
"""
return summary
def _generate_session_id(self, tasks: List[SubTask]) -> str:
"""Generate unique session ID based on task combination"""
task_ids = ''.join(sorted([t.task_id for t in tasks]))
timestamp = datetime.now().isoformat()
hash_input = f"{task_ids}_{timestamp}"
return hashlib.sha256(hash_input.encode()).hexdigest()[:16]
def _hash_result(self, result: Any) -> str:
"""Generate hash for result deduplication"""
return hashlib.sha256(
json.dumps(result, sort_keys=True).encode()
).hexdigest()[:16]
2.3 Layer 3: Dynamic Workflow Orchestrator (Core Innovation)
The orchestration layer is where Dynamic Workflows demonstrates its revolutionary capabilities:
import asyncio
from typing import Dict, List, Callable, Any, Optional
from dataclasses import dataclass, field
from enum import Enum
import logging
from collections import defaultdict
class WorkflowState(Enum):
INITIALIZING = "initializing"
RUNNING = "running"
PAUSED = "paused"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class WorkflowExecution:
"""Represents a single workflow execution"""
workflow_id: str
state: WorkflowState
active_tasks: Dict[str, asyncio.Task]
completed_results: Dict[str, Any]
failed_tasks: Dict[str, Exception]
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
class WorkflowStateMachine:
"""
Manages workflow state transitions with proper validation
"""
VALID_TRANSITIONS = {
WorkflowState.INITIALIZING: [WorkflowState.RUNNING, WorkflowState.FAILED],
WorkflowState.RUNNING: [WorkflowState.PAUSED, WorkflowState.COMPLETED, WorkflowState.FAILED],
WorkflowState.PAUSED: [WorkflowState.RUNNING, WorkflowState.FAILED],
WorkflowState.COMPLETED: [],
WorkflowState.FAILED: [WorkflowState.RUNNING], # Allow retry
}
def __init__(self, workflow_id: str):
self.workflow_id = workflow_id
self.state = WorkflowState.INITIALIZING
self.transition_history: List[tuple] = []
def transition(self, new_state: WorkflowState) -> bool:
"""Attempt state transition with validation"""
if new_state in self.VALID_TRANSITIONS.get(self.state, []):
old_state = self.state
self.state = new_state
self.transition_history.append((old_state, new_state, datetime.now()))
logging.info(f"Workflow {self.workflow_id}: {old_state} -> {new_state}")
return True
return False
class ParallelTaskScheduler:
"""
Core innovation: Schedules hundreds of sub-agents in parallel
Supports cross-hundred-thousand-line codebase migrations
"""
def __init__(
self,
max_concurrent_tasks: int = 100,
retry_attempts: int = 3,
timeout_seconds: int = 300
):
self.max_concurrent_tasks = max_concurrent_tasks
self.retry_attempts = retry_attempts
self.timeout_seconds = timeout_seconds
self.task_semaphore = asyncio.Semaphore(max_concurrent_tasks)
# Task tracking
self.pending_tasks: Dict[str, SubTask] = {}
self.running_tasks: Dict[str, asyncio.Task] = {}
self.completed_tasks: Dict[str, Any] = {}
self.failed_tasks: Dict[str, Exception] = {}
# Agent registry
self.agent_registry: Dict[str, 'BaseAgent'] = {}
# Event callbacks
self.on_task_complete: Optional[Callable] = None
self.on_task_fail: Optional[Callable] = None
self.on_workflow_complete: Optional[Callable] = None
def register_agent(self, agent_type: str, agent: 'BaseAgent') -> None:
"""Register a specialized agent for task execution"""
self.agent_registry[agent_type] = agent
logging.info(f"Registered agent: {agent_type}")
async def execute_workflow(
self,
tasks: List[SubTask],
context: SessionContext
) -> WorkflowExecution:
"""Execute a complete workflow with parallel task scheduling"""
workflow_id = f"wf_{context.session_id}"
execution = WorkflowExecution(
workflow_id=workflow_id,
state=WorkflowState.INITIALIZING,
active_tasks={},
completed_results={},
failed_tasks={},
started_at=datetime.now()
)
# Build dependency graph
dependency_graph = self._build_dependency_graph(tasks)
# Transition to running state
state_machine = WorkflowStateMachine(workflow_id)
state_machine.transition(WorkflowState.RUNNING)
try:
# Execute tasks with dependency awareness
await self._execute_with_dependencies(
tasks,
dependency_graph,
context,
execution
)
state_machine.transition(WorkflowState.COMPLETED)
execution.completed_at = datetime.now()
except Exception as e:
logging.error(f"Workflow {workflow_id} failed: {e}")
state_machine.transition(WorkflowState.FAILED)
raise
return execution
async def _execute_with_dependencies(
self,
tasks: List[SubTask],
dependency_graph: Dict[str, Set[str]],
context: SessionContext,
execution: WorkflowExecution
) -> None:
"""Execute tasks respecting dependency constraints"""
# Track which tasks are ready to execute
ready_tasks = set()
completed = set()
failed = set()
# Initialize: tasks with no dependencies are ready
for task in tasks:
if not task.dependencies:
ready_tasks.add(task.task_id)
# Execute until all tasks are complete
while ready_tasks or execution.active_tasks:
# Launch ready tasks
while ready_tasks and len(execution.active_tasks) < self.max_concurrent_tasks:
task_id = ready_tasks.pop()
task = next(t for t in tasks if t.task_id == task_id)
# Check dependencies are met
deps_met = all(
dep in completed
for dep in task.dependencies
)
if not deps_met:
# Re-add to waiting list
continue
# Launch task
async_task = asyncio.create_task(
self._execute_single_task(task, context)
)
execution.active_tasks[task_id] = async_task
# Wait for at least one task to complete
if execution.active_tasks:
done, pending = await asyncio.wait(
execution.active_tasks.values(),
return_when=asyncio.FIRST_COMPLETED
)
# Process completed tasks
for completed_future in done:
task_id = self._get_task_id_from_future(
completed_future,
execution.active_tasks
)
del execution.active_tasks[task_id]
try:
result = completed_future.result()
execution.completed_results[task_id] = result
completed.add(task_id)
# Update context
await context.checkpoint(task_id, result)
# Find newly ready tasks
for potential_task in tasks:
if potential_task.task_id not in completed:
deps = dependency_graph.get(potential_task.task_id, set())
if deps.issubset(completed):
ready_tasks.add(potential_task.task_id)
# Trigger callback
if self.on_task_complete:
await self.on_task_complete(task_id, result)
except Exception as e:
execution.failed_tasks[task_id] = e
failed.add(task_id)
if self.on_task_fail:
await self.on_task_fail(task_id, e)
# Check for deadlock (no progress possible)
if not ready_tasks and execution.active_tasks and not done:
raise RuntimeError(
f"Deadlock detected: {len(execution.active_tasks)} tasks blocked"
)
async def _execute_single_task(
self,
task: SubTask,
context: SessionContext
) -> Any:
"""Execute a single task with retry logic"""
async with self.task_semaphore:
for attempt in range(self.retry_attempts):
try:
# Get appropriate agent
agent = self._get_agent_for_task(task)
# Prepare task context (include completed results)
task_context = self._prepare_task_context(task, context)
# Execute with timeout
result = await asyncio.wait_for(
agent.execute(task, task_context),
timeout=self.timeout_seconds
)
return result
except asyncio.TimeoutError:
logging.warning(
f"Task {task.task_id} timed out on attempt {attempt + 1}"
)
if attempt == self.retry_attempts - 1:
raise
except Exception as e:
logging.error(
f"Task {task.task_id} failed on attempt {attempt + 1}: {e}"
)
if attempt == self.retry_attempts - 1:
raise
def _build_dependency_graph(
self,
tasks: List[SubTask]
) -> Dict[str, Set[str]]:
"""Build a dependency graph from tasks"""
graph = defaultdict(set)
task_map = {t.task_id: t for t in tasks}
for task in tasks:
# Validate dependencies exist
for dep in task.dependencies:
if dep not in task_map:
raise ValueError(
f"Task {task.task_id} has invalid dependency: {dep}"
)
graph[task.task_id] = task.dependencies
return graph
def _get_agent_for_task(self, task: SubTask) -> 'BaseAgent':
"""Route task to appropriate agent"""
# Default routing based on task ID patterns
if 'code_gen' in task.task_id:
return self.agent_registry.get('code_generation')
elif 'review' in task.task_id:
return self.agent_registry.get('code_review')
elif 'test' in task.task_id:
return self.agent_registry.get('test_generation')
elif 'search' in task.task_id:
return self.agent_registry.get('code_search')
elif 'docs' in task.task_id:
return self.agent_registry.get('documentation')
else:
return self.agent_registry.get('default')
def _prepare_task_context(
self,
task: SubTask,
context: SessionContext
) -> Dict[str, Any]:
"""Prepare context for task execution including dependency results"""
task_context = {
'task': asdict(task),
'session_id': context.session_id,
'dependencies': {}
}
# Include results from dependencies
for dep_id in task.dependencies:
if dep_id in context.shared_memory:
task_context['dependencies'][dep_id] = context.shared_memory[f'result_{dep_id}']
return task_context
def _get_task_id_from_future(
self,
future: asyncio.Future,
task_map: Dict[str, asyncio.Task]
) -> Optional[str]:
"""Map future back to task ID"""
for task_id, task in task_map.items():
if task == future or task._future == future:
return task_id
return None
2.4 Layer 4: Specialized Sub-Agent Layer
The agent layer implements specialized capabilities for different tasks:
from abc import ABC, abstractmethod
from typing import Any, Dict
import asyncio
class BaseAgent(ABC):
"""Base class for all specialized agents"""
def __init__(self, agent_id: str):
self.agent_id = agent_id
self.execution_count = 0
@abstractmethod
async def execute(
self,
task: SubTask,
context: Dict[str, Any]
) -> Any:
"""Execute the agent's specialized task"""
pass
class CodeGenerationAgent(BaseAgent):
"""
Specialized agent for code generation, refactoring, and optimization
"""
def __init__(self):
super().__init__('code_generation')
self.capabilities = [
'code_generation',
'refactoring',
'optimization',
'unit_test_generation'
]
async def execute(
self,
task: SubTask,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Execute code generation task"""
self.execution_count += 1
dependencies = context.get('dependencies', {})
# Implementation would call Claude API for code generation
code_prompt = f"""
Task: {task.description}
Dependencies: {dependencies}
Generate code that:
1. Fulfills the task description
2. Uses outputs from dependency tasks
3. Follows best practices
4. Includes appropriate error handling
"""
# In production, this would call Claude API
generated_code = await self._generate_code(code_prompt)
return {
'agent': self.agent_id,
'task_id': task.task_id,
'generated_code': generated_code,
'files_modified': self._track_modifications(generated_code),
'execution_count': self.execution_count
}
async def _generate_code(self, prompt: str) -> str:
"""Generate code using Claude"""
# Placeholder - in production, calls Claude API
await asyncio.sleep(0.1) # Simulate API call
return "# Generated code placeholder"
class CodeReviewAgent(BaseAgent):
"""
Specialized agent for code review, vulnerability detection,
and performance analysis
"""
def __init__(self):
super().__init__('code_review')
self.review_patterns = self._load_review_patterns()
async def execute(
self,
task: SubTask,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Execute code review task"""
self.execution_count += 1
dependencies = context.get('dependencies', {})
code_to_review = dependencies.get('code_generation', {}).get(
'generated_code', ''
)
review_results = {
'vulnerabilities': await self._detect_vulnerabilities(code_to_review),
'code_quality': await self._analyze_quality(code_to_review),
'performance_issues': await self._analyze_performance(code_to_review),
'best_practices': await self._check_best_practices(code_to_review),
}
return {
'agent': self.agent_id,
'task_id': task.task_id,
'review_results': review_results,
'overall_score': self._calculate_score(review_results),
'execution_count': self.execution_count
}
async def _detect_vulnerabilities(self, code: str) -> List[Dict]:
"""Detect security vulnerabilities"""
# Implementation
return []
class TestGenerationAgent(BaseAgent):
"""
Specialized agent for generating comprehensive test suites
"""
def __init__(self):
super().__init__('test_generation')
self.test_frameworks = {
'python': ['pytest', 'unittest'],
'go': ['testing', 'ginkgo', 'testify'],
'javascript': ['jest', 'mocha']
}
async def execute(
self,
task: SubTask,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Execute test generation task"""
self.execution_count += 1
dependencies = context.get('dependencies', {})
code_under_test = dependencies.get('code_generation', {}).get(
'generated_code', ''
)
test_code = await self._generate_tests(
code_under_test,
context.get('language', 'python')
)
return {
'agent': self.agent_id,
'task_id': task.task_id,
'test_code': test_code,
'test_count': self._count_tests(test_code),
'coverage_estimate': self._estimate_coverage(test_code),
'execution_count': self.execution_count
}
class CodeSearchAgent(BaseAgent):
"""
Specialized agent for semantic code search and reference tracking
"""
def __init__(self):
super().__init__('code_search')
self.index = CodeSearchIndex()
async def execute(
self,
task: SubTask,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Execute code search task"""
self.execution_count += 1
search_results = await self.index.search(
task.description,
context.get('search_options', {})
)
return {
'agent': self.agent_id,
'task_id': task.task_id,
'results': search_results,
'execution_count': self.execution_count
}
class DocumentationAgent(BaseAgent):
"""
Specialized agent for documentation generation
"""
def __init__(self):
super().__init__('documentation')
self.doc_formats = ['markdown', 'html', 'pdf', 'api_reference']
async def execute(
self,
task: SubTask,
context: Dict[str, Any]
) -> Dict[str, Any]:
"""Execute documentation generation task"""
self.execution_count += 1
dependencies = context.get('dependencies', {})
code_to_document = dependencies.get('code_generation', {}).get(
'generated_code', ''
)
documentation = await self._generate_docs(
code_to_document,
task.description
)
return {
'agent': self.agent_id,
'task_id': task.task_id,
'documentation': documentation,
'format': task.constraints.get('format', 'markdown'),
'execution_count': self.execution_count
}
2.5 Layer 5: Tool & Execution Environment Layer
The tool layer provides execution capabilities:
import subprocess
import tempfile
import os
from pathlib import Path
from typing import List, Dict, Any, Optional
class ToolExecutor:
"""
Executes tools and manages execution environment
"""
def __init__(self, workspace_root: str):
self.workspace_root = Path(workspace_root)
self.active_processes: Dict[str, subprocess.Popen] = {}
async def execute_file_operation(
self,
operation: str,
path: str,
content: Optional[str] = None
) -> Dict[str, Any]:
"""Execute file system operations"""
full_path = self.workspace_root / path
if operation == 'read':
return {'content': full_path.read_text()}
elif operation == 'write':
full_path.parent.mkdir(parents=True, exist_ok=True)
full_path.write_text(content)
return {'success': True, 'path': str(full_path)}
elif operation == 'delete':
full_path.unlink(missing_ok=True)
return {'success': True}
elif operation == 'list':
return {'files': [str(p) for p in full_path.glob('**/*') if p.is_file()]}
return {'error': f'Unknown operation: {operation}'}
async def execute_git_operation(
self,
operation: str,
**kwargs
) -> Dict[str, Any]:
"""Execute Git operations"""
git_commands = {
'status': ['git', 'status', '--porcelain'],
'commit': ['git', 'commit', '-m', kwargs.get('message', '')],
'branch': ['git', 'branch', '-a'],
'log': ['git', 'log', f'--oneline', f'-n{kwargs.get("limit", 10)}'],
'diff': ['git', 'diff', kwargs.get('ref', 'HEAD')],
}
if operation not in git_commands:
return {'error': f'Unknown Git operation: {operation}'}
result = subprocess.run(
git_commands[operation],
cwd=self.workspace_root,
capture_output=True,
text=True
)
return {
'stdout': result.stdout,
'stderr': result.stderr,
'returncode': result.returncode
}
async def execute_shell_command(
self,
command: str,
timeout: int = 60
) -> Dict[str, Any]:
"""Execute shell command"""
result = subprocess.run(
command,
shell=True,
cwd=self.workspace_root,
capture_output=True,
text=True,
timeout=timeout
)
return {
'stdout': result.stdout,
'stderr': result.stderr,
'returncode': result.returncode,
'success': result.returncode == 0
}
async def execute_browser_operation(
self,
operation: str,
url: str,
**kwargs
) -> Dict[str, Any]:
"""Execute browser/web operations"""
if operation == 'navigate':
# Would use browser automation tool
return {'url': url, 'status': 'navigated'}
elif operation == 'screenshot':
# Would capture screenshot
return {'screenshot_path': f'/tmp/screenshot_{kwargs.get("name", "capture")}.png'}
elif operation == 'extract':
# Would extract page content
return {'content': 'Extracted page content'}
return {'error': f'Unknown browser operation: {operation}'}
3. Core Components Implementation
This section provides complete, runnable code examples for the core components of the Dynamic Workflows system.
3.1 Parallel Task Scheduler Core Logic
The parallel task scheduler is the heart of Dynamic Workflows. Here’s a production-ready implementation:
#!/usr/bin/env python3
"""
Claude Opus 4.8 Dynamic Workflows - Parallel Task Scheduler
A production-ready implementation demonstrating parallel agent orchestration.
"""
import asyncio
import logging
from typing import Dict, List, Any, Optional, Set, Callable
from dataclasses import dataclass, field, asdict
from enum import Enum
from datetime import datetime
from collections import defaultdict
import hashlib
import json
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger('parallel_scheduler')
# ============================================================================
# Core Data Structures
# ============================================================================
class TaskStatus(Enum):
"""Task execution status"""
PENDING = "pending"
READY = "ready"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
class TaskPriority(Enum):
"""Task priority levels"""
CRITICAL = 1
HIGH = 2
NORMAL = 3
LOW = 4
@dataclass
class Task:
"""
Represents a unit of work in the Dynamic Workflows system.
Supports dependencies, retries, timeouts, and result tracking.
"""
task_id: str
description: str
task_type: str
payload: Dict[str, Any] = field(default_factory=dict)
dependencies: Set[str] = field(default_factory=set)
priority: TaskPriority = TaskPriority.NORMAL
status: TaskStatus = TaskStatus.PENDING
max_retries: int = 3
timeout_seconds: int = 300
created_at: datetime = field(default_factory=datetime.now)
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
result: Optional[Any] = None
error: Optional[str] = None
retry_count: int = 0
assigned_worker: Optional[str] = None
def to_dict(self) -> Dict:
"""Convert task to dictionary for serialization"""
data = asdict(self)
data['priority'] = self.priority.value
data['status'] = self.status.value
return data
@property
def execution_time(self) -> Optional[float]:
"""Calculate execution time in seconds"""
if self.started_at and self.completed_at:
return (self.completed_at - self.started_at).total_seconds()
return None
@dataclass
class WorkflowResult:
"""Complete result of workflow execution"""
workflow_id: str
total_tasks: int
successful_tasks: int
failed_tasks: int
total_execution_time: float
results: Dict[str, Any]
errors: Dict[str, str]
checkpoint_data: List[Dict]
# ============================================================================
# Task Queue Implementation
# ============================================================================
class TaskQueue:
"""
Thread-safe priority queue for task scheduling.
Uses a min-heap for O(log n) insertion and extraction.
"""
def __init__(self):
self._heap: List[Task] = []
self._task_map: Dict[str, Task] = {}
self._lock = asyncio.Lock()
async def add(self, task: Task) -> None:
"""Add a task to the queue"""
async with self._lock:
self._heap.append(task)
self._task_map[task.task_id] = task
self._sift_up(len(self._heap) - 1)
async def pop(self) -> Optional[Task]:
"""Remove and return the highest priority task"""
async with self._lock:
if not self._heap:
return None
# Swap root with last element
task = self._heap[0]
last = self._heap.pop()
if self._heap:
self._heap[0] = last
self._sift_down(0)
del self._task_map[task.task_id]
return task
async def peek(self) -> Optional[Task]:
"""View the highest priority task without removing it"""
async with self._lock:
if not self._heap:
return None
return self._heap[0]
async def remove(self, task_id: str) -> bool:
"""Remove a specific task by ID"""
async with self._lock:
if task_id not in self._task_map:
return False
# Mark as cancelled instead of removing from heap
task = self._task_map[task_id]
task.status = TaskStatus.CANCELLED
return True
async def get(self, task_id: str) -> Optional[Task]:
"""Get a task by ID"""
async with self._lock:
return self._task_map.get(task_id)
async def size(self) -> int:
"""Get the number of tasks in the queue"""
async with self._lock:
return len(self._heap)
def _sift_up(self, index: int) -> None:
"""Maintain heap property after insertion"""
while index > 0:
parent = (index - 1) // 2
if self._heap[index].priority.value < self._heap[parent].priority.value:
self._heap[index], self._heap[parent] = self._heap[parent], self._heap[index]
index = parent
else:
break
def _sift_down(self, index: int) -> None:
"""Maintain heap property after removal"""
while True:
smallest = index
left = 2 * index + 1
right = 2 * index + 2
if (left < len(self._heap) and
self._heap[left].priority.value < self._heap[smallest].priority.value):
smallest = left
if (right < len(self._heap) and
self._heap[right].priority.value < self._heap[smallest].priority.value):
smallest = right
if smallest != index:
self._heap[index], self._heap[smallest] = self._heap[smallest], self._heap[index]
index = smallest
else:
break
# ============================================================================
# Worker Pool
# ============================================================================
class Worker:
"""Individual worker that executes tasks"""
def __init__(self, worker_id: str):
self.worker_id = worker_id
self.current_task: Optional[Task] = None
self.is_busy = False
self.tasks_completed = 0
self.tasks_failed = 0
async def execute_task(
self,
task: Task,
executor_func: Callable
) -> Any:
"""Execute a task with the given executor function"""
self.is_busy = True
self.current_task = task
try:
logger.info(f"Worker {self.worker_id} executing task {task.task_id}")
# Execute with timeout
result = await asyncio.wait_for(
executor_func(task),
timeout=task.timeout_seconds
)
self.tasks_completed += 1
return result
except asyncio.TimeoutError:
logger.error(f"Worker {self.worker_id}: Task {task.task_id} timed out")
self.tasks_failed += 1
raise
except Exception as e:
logger.error(f"Worker {self.worker_id}: Task {task.task_id} failed: {e}")
self.tasks_failed += 1
raise
finally:
self.is_busy = False
self.current_task = None
class WorkerPool:
"""Manages a pool of workers for parallel task execution"""
def __init__(self, size: int):
self.size = size
self.workers = [Worker(f"worker_{i}") for i in range(size)]
self.available_workers: asyncio.Queue = asyncio.Queue()
# Initialize available worker queue
for worker in self.workers:
self.available_workers.put_nowait(worker)
async def get_worker(self) -> Optional[Worker]:
"""Get an available worker (blocks if none available)"""
try:
return await asyncio.wait_for(
self.available_workers.get(),
timeout=1.0
)
except asyncio.TimeoutError:
return None
async def release_worker(self, worker: Worker) -> None:
"""Release a worker back to the pool"""
if not worker.is_busy:
await self.available_workers.put(worker)
async def execute_task(
self,
task: Task,
executor_func: Callable
) -> Any:
"""Execute a task using an available worker"""
worker = await self.get_worker()
if worker is None:
# Wait for a worker to become available
worker = await self.available_workers.get()
try:
return await worker.execute_task(task, executor_func)
finally:
await self.release_worker(worker)
def get_stats(self) -> Dict[str, Any]:
"""Get worker pool statistics"""
return {
'pool_size': self.size,
'total_completed': sum(w.tasks_completed for w in self.workers),
'total_failed': sum(w.tasks_failed for w in self.workers),
'busy_workers': sum(1 for w in self.workers if w.is_busy),
'available_workers': self.size - sum(1 for w in self.workers if w.is_busy)
}
# ============================================================================
# Dependency Graph Manager
# ============================================================================
class DependencyGraph:
"""
Manages task dependencies and determines execution order.
Uses topological sort for dependency resolution.
"""
def __init__(self):
self.graph: Dict[str, Set[str]] = defaultdict(set)
self.reverse_graph: Dict[str, Set[str]] = defaultdict(set)
self.tasks: Dict[str, Task] = {}
def add_task(self, task: Task) -> None:
"""Add a task to the dependency graph"""
self.tasks[task.task_id] = task
for dep_id in task.dependencies:
self.graph[dep_id].add(task.task_id)
self.reverse_graph[task.task_id].add(dep_id)
def get_ready_tasks(self, completed: Set[str]) -> List[Task]:
"""Get tasks that are ready to execute (all dependencies met)"""
ready = []
for task_id, task in self.tasks.items():
if task.status != TaskStatus.PENDING:
continue
if task_id in completed:
continue
# Check if all dependencies are completed
if task.dependencies.issubset(completed):
ready.append(task)
# Sort by priority
return sorted(ready, key=lambda t: t.priority.value)
def get_blocked_tasks(self, completed: Set[str]) -> Dict[str, Set[str]]:
"""Get tasks that are blocked with their blocking dependencies"""
blocked = {}
for task_id, task in self.tasks.items():
if task_id in completed:
continue
pending_deps = task.dependencies - completed
if pending_deps:
blocked[task_id] = pending_deps
return blocked
def topological_sort(self) -> List[str]:
"""Return tasks in topologically sorted order"""
in_degree = {task_id: len(task.dependencies) for task_id, task in self.tasks.items()}
queue = [task_id for task_id, degree in in_degree.items() if degree == 0]
result = []
while queue:
task_id = queue.pop(0)
result.append(task_id)
for dependent in self.graph[task_id]:
in_degree[dependent] -= 1
if in_degree[dependent] == 0:
queue.append(dependent)
if len(result) != len(self.tasks):
raise ValueError("Cycle detected in dependency graph")
return result
# ============================================================================
# Main Parallel Task Scheduler
# ============================================================================
class ParallelTaskScheduler:
"""
Main scheduler for parallel task execution.
Implements Dynamic Workflows core innovation: parallel scheduling
of hundreds of sub-agents with dependency management.
"""
def __init__(
self,
max_workers: int = 100,
max_concurrent_tasks: int = 100,
enable_checkpoints: bool = True,
checkpoint_interval: int = 10
):
self.max_workers = max_workers
self.max_concurrent_tasks = max_concurrent_tasks
self.enable_checkpoints = enable_checkpoints
self.checkpoint_interval = checkpoint_interval
self.task_queue = TaskQueue()
self.worker_pool = WorkerPool(max_workers)
self.dependency_graph = DependencyGraph()
self.active_tasks: Dict[str, asyncio.Task] = {}
self.completed_results: Dict[str, Any] = {}
self.failed_tasks: Dict[str, Exception] = {}
self.checkpoints: List[Dict] = []
self.workflow_id: Optional[str] = None
self.start_time: Optional[datetime] = None
# Callbacks
self.on_task_start: Optional[Callable] = None
self.on_task_complete: Optional[Callable] = None
self.on_task_fail: Optional[Callable] = None
self.on_checkpoint: Optional[Callable] = None
def set_workflow_id(self, workflow_id: str) -> None:
"""Set the workflow ID for tracking"""
self.workflow_id = workflow_id
async def submit_task(self, task: Task) -> str:
"""Submit a new task for execution"""
task.status = TaskStatus.PENDING
self.dependency_graph.add_task(task)
await self.task_queue.add(task)
logger.info(f"Task {task.task_id} submitted")
return task.task_id
async def submit_tasks(self, tasks: List[Task]) -> List[str]:
"""Submit multiple tasks at once"""
return [await self.submit_task(task) for task in tasks]
async def execute(
self,
tasks: List[Task],
executor_func: Callable,
workflow_id: Optional[str] = None
) -> WorkflowResult:
"""
Execute a workflow of tasks with parallel scheduling.
This is the core method that implements Dynamic Workflows.
"""
# Initialize workflow
self.workflow_id = workflow_id or self._generate_workflow_id()
self.start_time = datetime.now()
# Build dependency graph
for task in tasks:
self.dependency_graph.add_task(task)
# Create initial ready tasks
ready_tasks = self.dependency_graph.get_ready_tasks(set())
for task in ready_tasks:
task.status = TaskStatus.READY
logger.info(f"Starting workflow {self.workflow_id} with {len(tasks)} tasks")
try:
# Main execution loop
completed = set()
pending_futures: Set[asyncio.Future] = set()
while ready_tasks or pending_futures:
# Launch ready tasks up to concurrency limit
while ready_tasks and len(self.active_tasks) < self.max_concurrent_tasks:
task = ready_tasks.pop(0)
# Launch task execution
future = asyncio.create_task(
self._execute_task(task, executor_func)
)
self.active_tasks[task.task_id] = future
pending_futures.add(future)
# Trigger callback
if self.on_task_start:
await self.on_task_start(task)
# Wait for at least one task to complete
if pending_futures:
done, pending_futures = await asyncio.wait(
pending_futures,
return_when=asyncio.FIRST_COMPLETED
)
# Process completed tasks
for future in done:
task_id = self._get_task_id_from_future(future, self.active_tasks)
del self.active_tasks[task_id]
try:
result = future.result()
self.completed_results[task_id] = result
completed.add(task_id)
task = self.dependency_graph.tasks[task_id]
task.status = TaskStatus.COMPLETED
task.result = result
task.completed_at = datetime.now()
# Trigger callback
if self.on_task_complete:
await self.on_task_complete(task, result)
# Find newly ready tasks
newly_ready = self.dependency_graph.get_ready_tasks(completed)
ready_tasks.extend(newly_ready)
# Create checkpoint if needed
if (self.enable_checkpoints and
len(completed) % self.checkpoint_interval == 0):
await self._create_checkpoint(completed)
except Exception as e:
task = self.dependency_graph.tasks[task_id]
self.failed_tasks[task_id] = e
task.status = TaskStatus.FAILED
task.error = str(e)
# Trigger callback
if self.on_task_fail:
await self.on_task_fail(task, e)
# Check retry logic
if task.retry_count < task.max_retries:
task.retry_count += 1
task.status = TaskStatus.READY
ready_tasks.append(task)
else:
completed.add(task_id)
# Check for deadlock
if not ready_tasks and pending_futures and not done:
logger.warning("Potential deadlock detected, waiting...")
await asyncio.sleep(0.1)
# Final checkpoint
await self._create_checkpoint(completed, final=True)
except Exception as e:
logger.error(f"Workflow {self.workflow_id} failed: {e}")
raise
# Calculate results
total_time = (datetime.now() - self.start_time).total_seconds()
return WorkflowResult(
workflow_id=self.workflow_id,
total_tasks=len(tasks),
successful_tasks=len(self.completed_results),
failed_tasks=len(self.failed_tasks),
total_execution_time=total_time,
results=self.completed_results,
errors={k: str(v) for k, v in self.failed_tasks.items()},
checkpoint_data=self.checkpoints
)
async def _execute_task(
self,
task: Task,
executor_func: Callable
) -> Any:
"""Execute a single task with worker pool"""
task.status = TaskStatus.RUNNING
task.started_at = datetime.now()
# Get worker and execute
result = await self.worker_pool.execute_task(task, executor_func)
return result
async def _create_checkpoint(
self,
completed: Set[str],
final: bool = False
) -> None:
"""Create a workflow checkpoint for recovery"""
checkpoint = {
'timestamp': datetime.now().isoformat(),
'workflow_id': self.workflow_id,
'completed_tasks': list(completed),
'total_completed': len(completed),
'failed_tasks': list(self.failed_tasks.keys()),
'total_failed': len(self.failed_tasks),
'is_final': final
}
self.checkpoints.append(checkpoint)
logger.info(
f"Checkpoint created: {len(completed)} completed, "
f"{len(self.failed_tasks)} failed"
)
if self.on_checkpoint:
await self.on_checkpoint(checkpoint)
def _get_task_id_from_future(
self,
future: asyncio.Future,
task_map: Dict[str, asyncio.Future]
) -> Optional[str]:
"""Map a future back to its task ID"""
for task_id, f in task_map.items():
if f == future:
return task_id
return None
def _generate_workflow_id(self) -> str:
"""Generate a unique workflow ID"""
timestamp = datetime.now().isoformat()
hash_input = f"{timestamp}_{len(self.dependency_graph.tasks)}"
return f"wf_{hashlib.md5(hash_input.encode()).hexdigest()[:12]}"
def get_statistics(self) -> Dict[str, Any]:
"""Get workflow execution statistics"""
if not self.start_time:
return {'status': 'not_started'}
elapsed = (datetime.now() - self.start_time).total_seconds()
total = len(self.dependency_graph.tasks)
completed = len(self.completed_results)
failed = len(self.failed_tasks)
active = len(self.active_tasks)
return {
'workflow_id': self.workflow_id,
'status': 'running' if active > 0 else 'completed',
'elapsed_time': elapsed,
'total_tasks': total,
'completed_tasks': completed,
'failed_tasks': failed,
'active_tasks': active,
'completion_rate': completed / total if total > 0 else 0,
'worker_pool_stats': self.worker_pool.get_stats(),
'checkpoints_created': len(self.checkpoints)
}
# ============================================================================
# Demo: Usage Example
# ============================================================================
async def demo_executor(task: Task) -> Dict[str, Any]:
"""Demo executor function that simulates task execution"""
await asyncio.sleep(0.1) # Simulate work
# Simulate some tasks failing randomly for demonstration
import random
if random.random() < 0.1: # 10% failure rate
raise ValueError(f"Simulated failure for task {task.task_id}")
return {
'task_id': task.task_id,
'status': 'completed',
'result': f"Result of {task.description}",
'timestamp': datetime.now().isoformat()
}
async def main():
"""Demonstrate the Parallel Task Scheduler"""
# Create scheduler with 10 workers
scheduler = ParallelTaskScheduler(
max_workers=10,
max_concurrent_tasks=10,
enable_checkpoints=True
)
# Create tasks with dependencies
tasks = [
Task(
task_id="task_1",
description="Initialize project structure",
task_type="setup",
priority=TaskPriority.HIGH
),
Task(
task_id="task_2",
description="Generate core modules",
task_type="code_generation",
dependencies={"task_1"},
priority=TaskPriority.HIGH
),
Task(
task_id="task_3",
description="Create database schema",
task_type="database",
dependencies={"task_1"},
priority=TaskPriority.NORMAL
),
Task(
task_id="task_4",
description="Write unit tests",
task_type="testing",
dependencies={"task_2"},
priority=TaskPriority.NORMAL
),
Task(
task_id="task_5",
description="Code review",
task_type="review",
dependencies={"task_2"},
priority=TaskPriority.NORMAL
),
Task(
task_id="task_6",
description="Integration testing",
task_type="testing",
dependencies={"task_2", "task_3"},
priority=TaskPriority.HIGH
),
Task(
task_id="task_7",
description="Generate documentation",
task_type="documentation",
dependencies={"task_2"},
priority=TaskPriority.LOW
),
Task(
task_id="task_8",
description="Final validation",
task_type="validation",
dependencies={"task_4", "task_5", "task_6"},
priority=TaskPriority.CRITICAL
),
]
# Set up callbacks
async def on_task_complete(task: Task, result: Any):
logger.info(f"Task {task.task_id} completed")
scheduler.on_task_complete = on_task_complete
# Execute workflow
result = await scheduler.execute(tasks, demo_executor, "demo_workflow")
# Print results
print("\n" + "=" * 60)
print("WORKFLOW EXECUTION RESULTS")
print("=" * 60)
print(f"Workflow ID: {result.workflow_id}")
print(f"Total Tasks: {result.total_tasks}")
print(f"Successful: {result.successful_tasks}")
print(f"Failed: {result.failed_tasks}")
print(f"Total Time: {result.total_execution_time:.2f}s")
print("\nStatistics:")
print(json.dumps(scheduler.get_statistics(), indent=2))
print("\nCheckpoints:")
for checkpoint in result.checkpoint_data:
print(f" - {checkpoint['timestamp']}: {checkpoint['total_completed']} completed")
if __name__ == "__main__":
asyncio.run(main())
3.2 Sub-Agent Architecture Implementation
Here’s a comprehensive multi-agent collaboration system:
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"sync"
"time"
)
// ============================================================================
// Core Agent Types and Interfaces
// ============================================================================
// AgentCapability represents a specific capability an agent can perform
type AgentCapability string
const (
CapabilityCodeGeneration AgentCapability = "code_generation"
CapabilityCodeReview AgentCapability = "code_review"
CapabilityTestGeneration AgentCapability = "test_generation"
CapabilityCodeSearch AgentCapability = "code_search"
CapabilityDocumentation AgentCapability = "documentation"
CapabilityDebugging AgentCapability = "debugging"
)
// TaskPriority represents task priority levels
type TaskPriority int
const (
PriorityCritical TaskPriority = 1
PriorityHigh TaskPriority = 2
PriorityNormal TaskPriority = 3
PriorityLow TaskPriority = 4
)
// TaskStatus represents the current status of a task
type TaskStatus string
const (
StatusPending TaskStatus = "pending"
StatusRunning TaskStatus = "running"
StatusCompleted TaskStatus = "completed"
StatusFailed TaskStatus = "failed"
StatusCancelled TaskStatus = "cancelled"
)
// Task represents a unit of work for an agent
type Task struct {
TaskID string `json:"task_id"`
Description string `json:"description"`
TaskType AgentCapability `json:"task_type"`
Payload map[string]interface{} `json:"payload"`
Dependencies []string `json:"dependencies"`
Priority TaskPriority `json:"priority"`
Status TaskStatus `json:"status"`
Result interface{} `json:"result,omitempty"`
Error string `json:"error,omitempty"`
CreatedAt time.Time `json:"created_at"`
StartedAt *time.Time `json:"started_at,omitempty"`
CompletedAt *time.Time `json:"completed_at,omitempty"`
}
// Agent represents an AI agent capable of executing specific tasks
type Agent interface {
GetID() string
GetCapabilities() []AgentCapability
Execute(ctx context.Context, task *Task, dependencies map[string]*Task) (interface{}, error)
}
// BaseAgent provides common functionality for all agents
type BaseAgent struct {
agentID string
capabilities []AgentCapability
executionCount int
mu sync.RWMutex
}
// ============================================================================
// Code Generation Agent
// ============================================================================
type CodeGenerationAgent struct {
BaseAgent
modelEndpoint string
}
func NewCodeGenerationAgent(endpoint string) *CodeGenerationAgent {
return &CodeGenerationAgent{
BaseAgent: BaseAgent{
agentID: "code_generation_agent",
capabilities: []AgentCapability{CapabilityCodeGeneration},
},
modelEndpoint: endpoint,
}
}
func (a *CodeGenerationAgent) GetID() string {
return a.agentID
}
func (a *CodeGenerationAgent) GetCapabilities() []AgentCapability {
return a.capabilities
}
func (a *CodeGenerationAgent) Execute(
ctx context.Context,
task *Task,
dependencies map[string]*Task,
) (interface{}, error) {
a.mu.Lock()
a.executionCount++
a.mu.Unlock()
// Extract relevant context from dependencies
var codeContext string
if dep, ok := dependencies["analysis"]; ok && dep.Result != nil {
codeContext = fmt.Sprintf("%v", dep.Result)
}
// Generate code based on task description and dependencies
generatedCode := fmt.Sprintf(
"// Generated by %s\n// Task: %s\n// Context: %s\n\npackage main\n\nimport \"fmt\"\n\nfunc main() {\n fmt.Println(\"Generated implementation for: %s\")\n}",
task.TaskID,
task.Description,
codeContext,
)
return map[string]interface{}{
"agent": a.GetID(),
"task_id": task.TaskID,
"generated_code": generatedCode,
"language": "go",
"execution_num": a.executionCount,
}, nil
}
// ============================================================================
// Code Review Agent
// ============================================================================
type CodeReviewAgent struct {
BaseAgent
reviewRules []ReviewRule
}
type ReviewRule struct {
Name string
Description string
Severity string // "critical", "warning", "info"
}
func NewCodeReviewAgent() *CodeReviewAgent {
return &CodeReviewAgent{
BaseAgent: BaseAgent{
agentID: "code_review_agent",
capabilities: []AgentCapability{CapabilityCodeReview},
},
reviewRules: []ReviewRule{
{Name: "G001", Description: "Variables should be named descriptively", Severity: "warning"},
{Name: "G002", Description: "Error handling should be explicit", Severity: "critical"},
{Name: "G003", Description: "Avoid global variables", Severity: "warning"},
},
}
}
func (a *CodeReviewAgent) GetID() string {
return a.agentID
}
func (a *CodeReviewAgent) GetCapabilities() []AgentCapability {
return a.capabilities
}
func (a *CodeReviewAgent) Execute(
ctx context.Context,
task *Task,
dependencies map[string]*Task,
) (interface{}, error) {
a.mu.Lock()
a.executionCount++
a.mu.Unlock()
// Get code to review from dependencies
var codeToReview string
if dep, ok := dependencies["code_generation"]; ok && dep.Result != nil {
if result, ok := dep.Result.(map[string]interface{}); ok {
if code, ok := result["generated_code"].(string); ok {
codeToReview = code
}
}
}
// Perform code review
issues := a.analyzeCode(codeToReview)
return map[string]interface{}{
"agent": a.GetID(),
"task_id": task.TaskID,
"issues_found": len(issues),
"issues": issues,
"overall_score": a.calculateScore(issues),
"execution_num": a.executionCount,
}, nil
}
func (a *CodeReviewAgent) analyzeCode(code string) []map[string]string {
issues := []map[string]string{}
// Simulate code analysis
if len(code) < 50 {
issues = append(issues, map[string]string{
"rule": "G001",
"severity": "warning",
"message": "Code seems too short, may need more implementation",
})
}
return issues
}
func (a *CodeReviewAgent) calculateScore(issues []map[string]string) float64 {
if len(issues) == 0 {
return 10.0
}
criticalCount := 0
for _, issue := range issues {
if issue["severity"] == "critical" {
criticalCount++
}
}
return 10.0 - float64(criticalCount)*2.0 - float64(len(issues)-criticalCount)*0.5
}
// ============================================================================
// Test Generation Agent
// ============================================================================
type TestGenerationAgent struct {
BaseAgent
testFrameworks map[string][]string
}
func NewTestGenerationAgent() *TestGenerationAgent {
return &TestGenerationAgent{
BaseAgent: BaseAgent{
agentID: "test_generation_agent",
capabilities: []AgentCapability{CapabilityTestGeneration},
},
testFrameworks: map[string][]string{
"go": {"testing", "testify", "ginkgo"},
"python": {"pytest", "unittest", "mock"},
"java": {"junit", "testng", "mockito"},
},
}
}
func (a *TestGenerationAgent) GetID() string {
return a.agentID
}
func (a *TestGenerationAgent) GetCapabilities() []AgentCapability {
return a.capabilities
}
func (a *TestGenerationAgent) Execute(
ctx context.Context,
task *Task,
dependencies map[string]*Task,
) (interface{}, error) {
a.mu.Lock()
a.executionCount++
a.mu.Unlock()
// Get code to test from dependencies
var codeToTest string
var language string
if dep, ok := dependencies["code_generation"]; ok && dep.Result != nil {
if result, ok := dep.Result.(map[string]interface{}); ok {
if code, ok := result["generated_code"].(string); ok {
codeToTest = code
}
if lang, ok := result["language"].(string); ok {
language = lang
}
}
}
// Generate tests
tests := a.generateTests(codeToTest, language)
return map[string]interface{}{
"agent": a.GetID(),
"task_id": task.TaskID,
"test_code": tests,
"test_count": 3, // Simulated
"coverage_estimate": 85.5,
"framework": a.testFrameworks[language],
"execution_num": a.executionCount,
}, nil
}
func (a *TestGenerationAgent) generateTests(code, language string) string {
framework := "testing"
if lang, ok := a.testFrameworks[language]; ok {
if len(lang) > 0 {
framework = lang[0]
}
}
return fmt.Sprintf(`// Generated tests using %s
package main
import "testing"
func TestMainLogic(t *testing.T) {
// Test case 1
result := main()
if result == nil {
t.Error("Expected non-nil result")
}
}
func TestEdgeCases(t *testing.T) {
// Test edge cases
tests := []struct {
name string
input interface{}
expect interface{}
}{
{"empty input", "", nil},
{"nil input", nil, nil},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
// Test implementation
})
}
}
func TestConcurrency(t *testing.T) {
// Test concurrent execution
done := make(chan bool)
go func() {
// Concurrent test
done <- true
}()
<-done
}`, framework)
}
// ============================================================================
// Multi-Agent Coordinator
// ============================================================================
type MultiAgentCoordinator struct {
agents map[string]Agent
taskQueue chan *Task
resultStore sync.Map
mu sync.RWMutex
wg sync.WaitGroup
}
func NewMultiAgentCoordinator(workerCount int) *MultiAgentCoordinator {
coord := &MultiAgentCoordinator{
agents: make(map[string]Agent),
taskQueue: make(chan *Task, 1000),
}
// Start worker goroutines
for i := 0; i < workerCount; i++ {
coord.wg.Add(1)
go coord.worker(i)
}
return coord
}
func (c *MultiAgentCoordinator) RegisterAgent(agent Agent) {
c.mu.Lock()
defer c.mu.Unlock()
c.agents[agent.GetID()] = agent
log.Printf("Registered agent: %s with capabilities: %v",
agent.GetID(), agent.GetCapabilities())
}
func (c *MultiAgentCoordinator) SubmitTask(task *Task) {
c.taskQueue <- task
log.Printf("Submitted task: %s (type: %s)", task.TaskID, task.TaskType)
}
func (c *MultiAgentCoordinator) ExecuteWorkflow(ctx context.Context, tasks []*Task) map[string]interface{} {
// Build dependency graph
taskMap := make(map[string]*Task)
for _, task := range tasks {
taskMap[task.TaskID] = task
}
// Find ready tasks (no dependencies)
var readyTasks []*Task
for _, task := range tasks {
if len(task.Dependencies) == 0 {
readyTasks = append(readyTasks, task)
}
}
// Submit ready tasks
for _, task := range readyTasks {
c.SubmitTask(task)
}
// Process tasks with dependency resolution
completed := make(map[string]bool)
var mu sync.Mutex
for len(completed) < len(tasks) {
// Wait for task completion
select {
case result := <-c.resultStoreCh():
completed[result.TaskID] = true
log.Printf("Task %s completed", result.TaskID)
// Find newly ready tasks
for _, task := range tasks {
if completed[task.TaskID] {
continue
}
// Check if all dependencies are met
allDepsMet := true
for _, dep := range task.Dependencies {
if !completed[dep] {
allDepsMet = false
break
}
}
if allDepsMet {
c.SubmitTask(task)
}
}
case <-ctx.Done():
log.Printf("Context cancelled, %d tasks remaining", len(tasks)-len(completed))
return c.gatherResults()
}
}
return c.gatherResults()
}
func (c *MultiAgentCoordinator) worker(id int) {
defer c.wg.Done()
for task := range c.taskQueue {
agent := c.findAgentForTask(task)
if agent == nil {
log.Printf("Worker %d: No agent found for task %s", id, task.TaskID)
continue
}
log.Printf("Worker %d executing task %s with agent %s",
id, task.TaskID, agent.GetID())
// Gather dependencies
dependencies := make(map[string]*Task)
// ... dependency gathering logic
// Execute task
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Minute)
result, err := agent.Execute(ctx, task, dependencies)
cancel()
// Store result
if err != nil {
task.Status = StatusFailed
task.Error = err.Error()
} else {
task.Status = StatusCompleted
task.Result = result
}
c.resultStore.Store(task.TaskID, task)
}
}
func (c *MultiAgentCoordinator) findAgentForTask(task *Task) Agent {
c.mu.RLock()
defer c.mu.RUnlock()
for _, agent := range c.agents {
for _, cap := range agent.GetCapabilities() {
if cap == task.TaskType {
return agent
}
}
}
return nil
}
func (c *MultiAgentCoordinator) resultStoreCh() chan *Task {
// Implementation for result channel
ch := make(chan *Task, 100)
go func() {
c.resultStore.Range(func(key, value interface{}) bool {
if task, ok := value.(*Task); ok {
ch <- task
}
return true
})
}()
return ch
}
func (c *MultiAgentCoordinator) gatherResults() map[string]interface{} {
results := make(map[string]interface{})
c.resultStore.Range(func(key, value interface{}) bool {
if task, ok := value.(*Task); ok {
results[task.TaskID] = task.Result
}
return true
})
return results
}
func (c *MultiAgentCoordinator) Shutdown() {
close(c.taskQueue)
c.wg.Wait()
}
// ============================================================================
// Demo
// ============================================================================
func main() {
log.Println("Starting Multi-Agent System Demo")
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Minute)
defer cancel()
// Create coordinator with 5 workers
coordinator := NewMultiAgentCoordinator(5)
// Register specialized agents
coordinator.RegisterAgent(NewCodeGenerationAgent("claude-api"))
coordinator.RegisterAgent(NewCodeReviewAgent())
coordinator.RegisterAgent(NewTestGenerationAgent())
// Define workflow tasks
tasks := []*Task{
{
TaskID: "task_1",
Description: "Analyze requirements and create specification",
TaskType: CapabilityCodeSearch,
Priority: PriorityHigh,
Dependencies: []string{},
},
{
TaskID: "task_2",
Description: "Generate core implementation",
TaskType: CapabilityCodeGeneration,
Priority: PriorityHigh,
Dependencies: []string{"task_1"},
},
{
TaskID: "task_3",
Description: "Review generated code",
TaskType: CapabilityCodeReview,
Priority: PriorityNormal,
Dependencies: []string{"task_2"},
},
{
TaskID: "task_4",
Description: "Generate test suite",
TaskType: CapabilityTestGeneration,
Priority: PriorityNormal,
Dependencies: []string{"task_2"},
},
{
TaskID: "task_5",
Description: "Create documentation",
TaskType: CapabilityDocumentation,
Priority: PriorityLow,
Dependencies: []string{"task_2", "task_3"},
},
}
// Execute workflow
results := coordinator.ExecuteWorkflow(ctx, tasks)
// Print results
fmt.Println("\n" + strings.Repeat("=", 60))
fmt.Println("WORKFLOW EXECUTION RESULTS")
fmt.Println(strings.Repeat("=", 60))
for taskID, result := range results {
resultJSON, _ := json.MarshalIndent(result, "", " ")
fmt.Printf("\n%s:\n%s\n", taskID, string(resultJSON))
}
coordinator.Shutdown()
}
3.3 Task Decomposer Implementation
#!/usr/bin/env python3
"""
Task Decomposer: Breaks complex user requests into parallelizable subtasks
Supports dependency analysis, parallelization optimization, and task refinement.
"""
import asyncio
import hashlib
import json
from dataclasses import dataclass, field
from typing import List, Dict, Set, Optional, Any, Callable
from enum import Enum
from datetime import datetime
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger('task_decomposer')
# ============================================================================
# Enums and Data Classes
# ============================================================================
class TaskType(Enum):
"""Types of tasks that can be decomposed"""
CODE_GENERATION = "code_generation"
CODE_REFACTORING = "code_refactoring"
CODE_MIGRATION = "code_migration"
TEST_GENERATION = "test_generation"
CODE_REVIEW = "code_review"
DOCUMENTATION = "documentation"
DEBUGGING = "debugging"
DEPLOYMENT = "deployment"
ANALYSIS = "analysis"
SEARCH = "search"
class TaskComplexity(Enum):
"""Task complexity levels"""
TRIVIAL = 1 # < 10 lines of code
SIMPLE = 2 # 10-50 lines
MODERATE = 3 # 50-200 lines
COMPLEX = 4 # 200-1000 lines
VERY_COMPLEX = 5 # > 1000 lines
class SubTaskStatus(Enum):
"""Subtask execution status"""
CREATED = "created"
READY = "ready"
BLOCKED = "blocked"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
SKIPPED = "skipped"
@dataclass
class SubTask:
"""
Represents a decomposable unit of work.
Contains all information needed for independent execution.
"""
task_id: str
name: str
description: str
task_type: TaskType
complexity: TaskComplexity = TaskComplexity.MODERATE
# Dependencies
dependencies: Set[str] = field(default_factory=set)
dependent_tasks: Set[str] = field(default_factory=set)
# Execution properties
estimated_tokens: int = 1000
estimated_time_seconds: int = 60
max_retries: int = 3
timeout_seconds: int = 300
# Status tracking
status: SubTaskStatus = SubTaskStatus.CREATED
created_at: datetime = field(default_factory=datetime.now)
started_at: Optional[datetime] = None
completed_at: Optional[datetime] = None
# Results
input_data: Dict[str, Any] = field(default_factory=dict)
output_data: Dict[str, Any] = field(default_factory=dict)
error: Optional[str] = None
# Quality gates
quality_criteria: List[str] = field(default_factory=list)
quality_checks_passed: int = 0
def to_dict(self) -> Dict[str, Any]:
"""Convert to dictionary for serialization"""
return {
'task_id': self.task_id,
'name': self.name,
'description': self.description,
'task_type': self.task_type.value,
'complexity': self.complexity.value,
'dependencies': list(self.dependencies),
'estimated_tokens': self.estimated_tokens,
'status': self.status.value,
}
@property
def can_parallelize(self) -> bool:
"""Check if task can run in parallel with others"""
return len(self.dependencies) == 0
@dataclass
class TaskTemplate:
"""Template for generating subtasks for a specific workflow type"""
workflow_type: str
name: str
description: str
subtask_templates: List[Dict[str, Any]] = field(default_factory=list)
# ============================================================================
# Task Templates for Common Workflows
# ============================================================================
CODE_MIGRATION_TEMPLATE = TaskTemplate(
workflow_type="code_migration",
name="Cross-Codebase Migration Workflow",
description="Complete migration of code from one framework/framework to another",
subtask_templates=[
{
'name': 'scan_source_codebase',
'description': 'Scan and analyze source codebase structure',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 5000,
'dependencies': [],
},
{
'name': 'analyze_dependencies',
'description': 'Identify and analyze external dependencies',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 8000,
'dependencies': ['scan_source_codebase'],
},
{
'name': 'create_dependency_mapping',
'description': 'Map old framework APIs to new framework equivalents',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.VERY_COMPLEX,
'estimated_tokens': 15000,
'dependencies': ['scan_source_codebase', 'analyze_dependencies'],
},
{
'name': 'generate_api_stubs',
'description': 'Generate stub implementations for new APIs',
'task_type': TaskType.CODE_GENERATION,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 20000,
'dependencies': ['create_dependency_mapping'],
},
{
'name': 'migrate_core_modules',
'description': 'Migrate core business logic modules',
'task_type': TaskType.CODE_MIGRATION,
'complexity': TaskComplexity.VERY_COMPLEX,
'estimated_tokens': 50000,
'dependencies': ['generate_api_stubs'],
},
{
'name': 'migrate_utility_modules',
'description': 'Migrate utility and helper modules',
'task_type': TaskType.CODE_MIGRATION,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 30000,
'dependencies': ['generate_api_stubs'],
},
{
'name': 'migrate_tests',
'description': 'Migrate existing tests to new framework',
'task_type': TaskType.TEST_GENERATION,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 25000,
'dependencies': ['migrate_core_modules'],
},
{
'name': 'fix_imports',
'description': 'Fix all import statements and references',
'task_type': TaskType.CODE_REFACTORING,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 10000,
'dependencies': ['migrate_core_modules', 'migrate_utility_modules'],
},
{
'name': 'generate_new_tests',
'description': 'Generate additional tests for migrated code',
'task_type': TaskType.TEST_GENERATION,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 20000,
'dependencies': ['migrate_core_modules', 'fix_imports'],
},
{
'name': 'code_review',
'description': 'Review migrated code for quality and correctness',
'task_type': TaskType.CODE_REVIEW,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 15000,
'dependencies': ['migrate_core_modules', 'migrate_utility_modules'],
},
{
'name': 'update_documentation',
'description': 'Update documentation for migrated codebase',
'task_type': TaskType.DOCUMENTATION,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 8000,
'dependencies': ['migrate_core_modules', 'fix_imports'],
},
{
'name': 'validation',
'description': 'Final validation of migration completeness',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 10000,
'dependencies': ['code_review', 'generate_new_tests', 'update_documentation'],
},
]
)
FEATURE_DEVELOPMENT_TEMPLATE = TaskTemplate(
workflow_type="feature_development",
name="Feature Development Workflow",
description="Complete development of a new feature",
subtask_templates=[
{
'name': 'analyze_requirements',
'description': 'Analyze and clarify feature requirements',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 3000,
'dependencies': [],
},
{
'name': 'design_solution',
'description': 'Design technical solution',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 5000,
'dependencies': ['analyze_requirements'],
},
{
'name': 'implement_core',
'description': 'Implement core functionality',
'task_type': TaskType.CODE_GENERATION,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 20000,
'dependencies': ['design_solution'],
},
{
'name': 'write_unit_tests',
'description': 'Write unit tests for core functionality',
'task_type': TaskType.TEST_GENERATION,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 10000,
'dependencies': ['implement_core'],
},
{
'name': 'implement_edge_cases',
'description': 'Handle edge cases and error conditions',
'task_type': TaskType.CODE_GENERATION,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 8000,
'dependencies': ['implement_core', 'write_unit_tests'],
},
{
'name': 'code_review',
'description': 'Review implementation',
'task_type': TaskType.CODE_REVIEW,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 5000,
'dependencies': ['implement_core', 'implement_edge_cases'],
},
{
'name': 'update_docs',
'description': 'Update documentation',
'task_type': TaskType.DOCUMENTATION,
'complexity': TaskComplexity.SIMPLE,
'estimated_tokens': 3000,
'dependencies': ['code_review'],
},
]
)
# ============================================================================
# Task Decomposer Implementation
# ============================================================================
class TaskDecomposer:
"""
Decomposes complex user requests into parallelizable subtasks.
Supports automatic dependency analysis, complexity estimation,
and parallelization optimization.
"""
def __init__(
self,
max_parallel_tasks: int = 100,
enable_auto_decomposition: bool = True,
custom_templates: Optional[List[TaskTemplate]] = None
):
self.max_parallel_tasks = max_parallel_tasks
self.enable_auto_decomposition = enable_auto_decomposition
self.templates: Dict[str, TaskTemplate] = {
'code_migration': CODE_MIGRATION_TEMPLATE,
'feature_development': FEATURE_DEVELOPMENT_TEMPLATE,
}
# Add custom templates
if custom_templates:
for template in custom_templates:
self.templates[template.workflow_type] = template
# Tracking
self.task_counter = 0
self.workflows: Dict[str, List[SubTask]] = {}
async def decompose(
self,
user_request: str,
workflow_type: Optional[str] = None,
context: Optional[Dict[str, Any]] = None
) -> 'DecompositionResult':
"""
Decompose a user request into subtasks.
Args:
user_request: The user's request description
workflow_type: Optional specific workflow type to use
context: Optional additional context for decomposition
Returns:
DecompositionResult containing subtasks and metadata
"""
# Identify workflow type if not specified
if not workflow_type:
workflow_type = await self._identify_workflow_type(user_request)
logger.info(f"Decomposing request as '{workflow_type}' workflow")
# Get or create template
if workflow_type in self.templates:
template = self.templates[workflow_type]
else:
# Auto-generate template based on request
template = await self._auto_generate_template(user_request)
# Generate subtasks from template
subtasks = await self._generate_subtasks(
template,
user_request,
context
)
# Analyze and optimize dependencies
optimized_tasks = await self._optimize_dependencies(subtasks)
# Calculate parallel execution plan
execution_plan = self._create_execution_plan(optimized_tasks)
# Store workflow
workflow_id = self._generate_workflow_id()
self.workflows[workflow_id] = optimized_tasks
return DecompositionResult(
workflow_id=workflow_id,
workflow_type=workflow_type,
user_request=user_request,
subtasks=optimized_tasks,
execution_plan=execution_plan,
estimated_total_tokens=sum(t.estimated_tokens for t in optimized_tasks),
estimated_total_time=max(
sum(t.estimated_time_seconds for t in optimized_tasks) // self.max_parallel_tasks,
max(t.estimated_time_seconds for t in optimized_tasks)
),
)
async def _identify_workflow_type(self, request: str) -> str:
"""Identify the most appropriate workflow type from request"""
request_lower = request.lower()
# Pattern matching for workflow identification
patterns = {
'code_migration': [
'migrate', 'migration', 'port', 'convert',
'upgrade', 'transform codebase'
],
'feature_development': [
'develop', 'implement', 'create', 'add feature',
'build', 'new functionality'
],
'code_review': [
'review', 'audit', 'analyze code', 'assess quality'
],
'testing': [
'test', 'testing', 'coverage', 'unit tests'
],
'documentation': [
'document', 'documentation', 'readme', 'api docs'
],
'debugging': [
'debug', 'fix', 'bug', 'issue', 'error'
],
}
scores = {}
for workflow, keywords in patterns.items():
score = sum(1 for kw in keywords if kw in request_lower)
scores[workflow] = score
# Return highest scoring workflow or default
if scores and max(scores.values()) > 0:
return max(scores, key=scores.get)
return 'feature_development' # Default
async def _auto_generate_template(
self,
request: str
) -> TaskTemplate:
"""Auto-generate a template based on request analysis"""
# This would use Claude to analyze the request and generate
# appropriate subtasks. For now, return a simple template.
return TaskTemplate(
workflow_type="custom",
name="Custom Workflow",
description=request,
subtask_templates=[
{
'name': 'analyze_request',
'description': f'Analyze and understand: {request}',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 2000,
'dependencies': [],
},
{
'name': 'execute_primary',
'description': f'Execute main task: {request}',
'task_type': TaskType.CODE_GENERATION,
'complexity': TaskComplexity.COMPLEX,
'estimated_tokens': 10000,
'dependencies': ['analyze_request'],
},
{
'name': 'validate',
'description': 'Validate results',
'task_type': TaskType.ANALYSIS,
'complexity': TaskComplexity.MODERATE,
'estimated_tokens': 2000,
'dependencies': ['execute_primary'],
},
]
)
async def _generate_subtasks(
self,
template: TaskTemplate,
user_request: str,
context: Optional[Dict[str, Any]]
) -> List[SubTask]:
"""Generate SubTask objects from template"""
subtasks = []
for i, template_dict in enumerate(template.subtask_templates):
# Create unique task ID
self.task_counter += 1
task_id = f"{template.workflow_type}_{self.task_counter:03d}"
# Convert task type string to enum
task_type = TaskType(template_dict['task_type'])
# Convert complexity string to enum if needed
complexity = template_dict.get('complexity', TaskComplexity.MODERATE)
if isinstance(complexity, int):
complexity = TaskComplexity(complexity)
# Create SubTask
subtask = SubTask(
task_id=task_id,
name=template_dict['name'],
description=template_dict['description'],
task_type=task_type,
complexity=complexity,
estimated_tokens=template_dict.get('estimated_tokens', 1000),
estimated_time_seconds=template_dict.get('estimated_time_seconds', 60),
dependencies=set(template_dict.get('dependencies', [])),
)
# Add quality criteria based on task type
subtask.quality_criteria = self._get_quality_criteria(task_type)
subtasks.append(subtask)
# Second pass: set up dependent_tasks (reverse dependencies)
task_map = {t.name: t for t in subtasks}
for task in subtasks:
for dep_name in task.dependencies:
if dep_name in task_map:
task_map[dep_name].dependent_tasks.add(task.task_id)
return subtasks
def _get_quality_criteria(self, task_type: TaskType) -> List[str]:
"""Get quality criteria for a task type"""
criteria = {
TaskType.CODE_GENERATION: [
'compiles_without_errors',
'follows_style_guide',
'has_error_handling',
'has_documentation',
],
TaskType.CODE_MIGRATION: [
'maintains_functionality',
'no_data_loss',
'preserves_api_contracts',
],
TaskType.TEST_GENERATION: [
'covers_main_paths',
'has_edge_cases',
'tests_are_deterministic',
],
TaskType.CODE_REVIEW: [
'no_critical_issues',
'performance_acceptable',
'security_review_passed',
],
}
return criteria.get(task_type, ['completes_successfully'])
async def _optimize_dependencies(
self,
subtasks: List[SubTask]
) -> List[SubTask]:
"""Optimize dependencies for maximum parallelism"""
# Create a copy to avoid modifying original
optimized = []
for task in subtasks:
optimized.append(SubTask(**{**task.__dict__}))
# Check for parallelizable independent tasks
task_map = {t.task_id: t for t in optimized}
# Mark tasks as ready if no dependencies
for task in optimized:
if not task.dependencies:
task.status = SubTaskStatus.READY
return optimized
def _create_execution_plan(
self,
subtasks: List[SubTask]
) -> 'ExecutionPlan':
"""Create an optimized execution plan"""
# Group tasks by "wave" (tasks that can run in parallel)
waves: List[List[str]] = []
remaining = {t.task_id for t in subtasks}
completed = set()
while remaining:
# Find tasks ready for this wave
ready = set()
for task_id in remaining:
task = next(t for t in subtasks if t.task_id == task_id)
if task.dependencies.issubset(completed):
ready.add(task_id)
if not ready:
# Deadlock - should not happen with proper templates
logger.warning("Dependency cycle detected")
break
waves.append(sorted(ready))
completed.update(ready)
remaining -= ready
return ExecutionPlan(
total_waves=len(waves),
waves=waves,
estimated_parallel_time=self._calculate_parallel_time(subtasks, len(waves)),
)
def _calculate_parallel_time(
self,
subtasks: List[SubTask],
num_waves: int
) -> int:
"""Calculate estimated parallel execution time"""
if num_waves == 0:
return 0
# Sum of max time in each wave
task_map = {t.task_id: t for t in subtasks}
wave_times = []
for wave in range(num_waves):
# This is simplified - real implementation would track waves
wave_times.append(max(t.estimated_time_seconds for t in subtasks))
return sum(wave_times)
def _generate_workflow_id(self) -> str:
"""Generate unique workflow ID"""
timestamp = datetime.now().isoformat()
hash_input = f"{timestamp}_{self.task_counter}"
return f"wf_{hashlib.md5(hash_input.encode()).hexdigest()[:12]}"
@dataclass
class DecompositionResult:
"""Result of task decomposition"""
workflow_id: str
workflow_type: str
user_request: str
subtasks: List[SubTask]
execution_plan: 'ExecutionPlan'
estimated_total_tokens: int
estimated_total_time: int
@dataclass
class ExecutionPlan:
"""Plan for executing subtasks in optimal order"""
total_waves: int
waves: List[List[str]]
estimated_parallel_time: int
# ============================================================================
# Demo
# ============================================================================
async def main():
"""Demonstrate the Task Decomposer"""
decomposer = TaskDecomposer(max_parallel_tasks=100)
# Example 1: Code Migration
print("\n" + "=" * 70)
print("EXAMPLE 1: Code Migration Request")
print("=" * 70)
migration_request = """
Migrate our Python Django REST API to FastAPI.
The codebase has approximately 50,000 lines of code spread across
200 modules. Include all tests and update documentation.
"""
result = await decomposer.decompose(migration_request, 'code_migration')
print(f"\nWorkflow ID: {result.workflow_id}")
print(f"Workflow Type: {result.workflow_type}")
print(f"Total Subtasks: {len(result.subtasks)}")
print(f"Total Waves: {result.execution_plan.total_waves}")
print(f"Estimated Tokens: {result.estimated_total_tokens:,}")
print(f"Estimated Time: {result.estimated_total_time}s")
print("\nExecution Plan (Waves):")
for i, wave in enumerate(result.execution_plan.waves):
print(f" Wave {i+1}: {wave}")
print("\nSubtask Details:")
for task in result.subtasks:
deps = ', '.join(task.dependencies) if task.dependencies else 'none'
print(f" {task.task_id}: {task.name}")
print(f" Type: {task.task_type.value}")
print(f" Dependencies: {deps}")
print(f" Est. Tokens: {task.estimated_tokens:,}")
# Example 2: Feature Development
print("\n" + "=" * 70)
print("EXAMPLE 2: Feature Development Request")
print("=" * 70)
feature_request = """
Implement a real-time notification system for our application.
Should support email, SMS, and push notifications with
configurable delivery rules and retry logic.
"""
result2 = await decomposer.decompose(feature_request)
print(f"\nWorkflow ID: {result2.workflow_id}")
print(f"Workflow Type: {result2.workflow_type}")
print(f"Total Subtasks: {len(result2.subtasks)}")
print("\nSubtask Details:")
for task in result2.subtasks:
print(f" {task.task_id}: {task.name} ({task.task_type.value})")
if __name__ == "__main__":
asyncio.run(main())
3.4 Context Manager Implementation
#!/usr/bin/env python3
"""
Context Manager: Long-session state management for Dynamic Workflows
Supports multi-session state, cross-session memory, checkpointing, and recovery.
"""
import asyncio
import json
import hashlib
import pickle
import os
from dataclasses import dataclass, field
from typing import Dict, List, Any, Optional, Set, Callable
from datetime import datetime, timedelta
from enum import Enum
import logging
from collections import defaultdict
import tempfile
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger('context_manager')
# ============================================================================
# Constants and Configuration
# ============================================================================
MAX_CONTEXT_TOKENS = 1_000_000 # 1M token context window
DEFAULT_CHECKPOINT_INTERVAL = 50 # Tasks between checkpoints
MAX_CHECKPOINTS_IN_MEMORY = 100
CHECKPOINT_STORAGE_DIR = "checkpoints"
# ============================================================================
# Enums and Data Classes
# ============================================================================
class SessionStatus(Enum):
"""Session lifecycle status"""
CREATING = "creating"
ACTIVE = "active"
PAUSED = "paused"
COMPLETED = "completed"
FAILED = "failed"
ARCHIVED = "archived"
class MemoryType(Enum):
"""Types of memory in the context"""
EPISODIC = "episodic" # Specific task memories
SEMANTIC = "semantic" # Generalized knowledge
WORKING = "working" # Current task context
LONG_TERM = "long_term" # Persistent across sessions
@dataclass
class Checkpoint:
"""Represents a session checkpoint for recovery"""
checkpoint_id: str
session_id: str
timestamp: datetime
task_states: Dict[str, str] # task_id -> status
shared_memory_snapshot: Dict[str, Any]
memory_contents: Dict[MemoryType, List[str]]
token_usage: int
metadata: Dict[str, Any]
def to_dict(self) -> Dict[str, Any]:
return {
'checkpoint_id': self.checkpoint_id,
'session_id': self.session_id,
'timestamp': self.timestamp.isoformat(),
'task_states': self.task_states,
'token_usage': self.token_usage,
'metadata': self.metadata,
}
@dataclass
class MemoryEntry:
"""Represents a memory entry in the context"""
entry_id: str
memory_type: MemoryType
content: str
importance: float # 0.0 - 1.0
created_at: datetime
last_accessed: datetime
access_count: int = 0
tags: Set[str] = field(default_factory=set)
source_task_id: Optional[str] = None
def access(self) -> None:
"""Record memory access"""
self.last_accessed = datetime.now()
self.access_count += 1
@dataclass
class TaskContext:
"""Context for a specific task execution"""
task_id: str
session_id: str
description: str
dependencies_results: Dict[str, Any] = field(default_factory=dict)
shared_memory: Dict[str, Any] = field(default_factory=dict)
priority: int = 0
constraints: Dict[str, Any] = field(default_factory=dict)
# ============================================================================
# Memory Management System
# ============================================================================
class MemoryManager:
"""
Manages different types of memory for long-session context.
Implements importance-based memory consolidation.
"""
def __init__(
self,
max_memory_items: int = 10000,
importance_threshold: float = 0.3
):
self.max_memory_items = max_memory_items
self.importance_threshold = importance_threshold
# Memory stores by type
self.memories: Dict[MemoryType, Dict[str, MemoryEntry]] = {
mem_type: {} for mem_type in MemoryType
}
# Index for fast lookup
self.tag_index: Dict[str, Set[str]] = defaultdict(set)
# Access statistics
self.total_accesses = 0
self.hit_count = 0
def store(
self,
memory_type: MemoryType,
content: str,
importance: float,
tags: Optional[Set[str]] = None,
source_task_id: Optional[str] = None
) -> str:
"""Store a new memory entry"""
entry_id = self._generate_entry_id(content)
entry = MemoryEntry(
entry_id=entry_id,
memory_type=memory_type,
content=content,
importance=importance,
created_at=datetime.now(),
last_accessed=datetime.now(),
tags=tags or set(),
source_task_id=source_task_id
)
# Store in appropriate memory type
self.memories[memory_type][entry_id] = entry
# Update tag index
for tag in entry.tags:
self.tag_index[tag].add(entry_id)
# Check memory limit and consolidate if needed
self._check_memory_limit()
logger.debug(f"Stored memory {entry_id} in {memory_type.value}")
return entry_id
def retrieve(
self,
memory_type: Optional[MemoryType] = None,
query: Optional[str] = None,
tags: Optional[Set[str]] = None,
limit: int = 10
) -> List[MemoryEntry]:
"""Retrieve memories based on criteria"""
candidates = []
if memory_type:
candidates = list(self.memories.get(memory_type, {}).values())
else:
# Search all memory types
for mem_type_memories in self.memories.values():
candidates.extend(mem_type_memories.values())
# Filter by tags
if tags:
tag_matches = set()
for tag in tags:
tag_matches.update(self.tag_index.get(tag, set()))
candidates = [c for c in candidates if c.entry_id in tag_matches]
# Sort by importance and recency
candidates.sort(
key=lambda e: (e.importance, e.last_accessed),
reverse=True
)
# Update access statistics
for entry in candidates[:limit]:
entry.access()
self.hit_count += 1
self.total_accesses += 1
return candidates[:limit]
def get_contextual_summary(
self,
session_context: 'SessionContext',
max_tokens: int = 50000
) -> str:
"""Generate a contextual summary optimized for token budget"""
# Get recent important memories
recent_memories = self.retrieve(
limit=100,
memory_type=MemoryType.EPISODIC
)
working_memories = self.retrieve(
limit=50,
memory_type=MemoryType.WORKING
)
# Build summary
summary_parts = []
# Working memory is most important
if working_memories:
summary_parts.append("## Current Working Context\n")
for mem in working_memories[:20]:
summary_parts.append(f"- {mem.content}")
# Recent episodic memories
if recent_memories:
summary_parts.append("\n## Recent Session Events\n")
for mem in recent_memories[:30]:
summary_parts.append(f"- {mem.content}")
# Truncate if needed
summary = "\n".join(summary_parts)
if len(summary) > max_tokens * 4: # Approximate tokens
summary = summary[:max_tokens * 4] + "\n[truncated]"
return summary
def consolidate(self) -> int:
"""
Consolidate memory by removing low-importance entries.
Returns number of entries removed.
"""
removed = 0
for memory_type, memories in self.memories.items():
# Don't consolidate long-term memory
if memory_type == MemoryType.LONG_TERM:
continue
to_remove = []
for entry_id, entry in memories.items():
if entry.importance < self.importance_threshold:
to_remove.append(entry_id)
for entry_id in to_remove:
del memories[entry_id]
removed += 1
# Update tag index
entry = memories.get(entry_id)
if entry:
for tag in entry.tags:
self.tag_index[tag].discard(entry_id)
return removed
def _check_memory_limit(self) -> None:
"""Check if memory limit exceeded and consolidate if needed"""
total_items = sum(
len(memories) for memories in self.memories.values()
)
if total_items > self.max_memory_items:
# Consolidate before checking limit again
self.consolidate()
def _generate_entry_id(self, content: str) -> str:
"""Generate unique ID for memory entry"""
hash_input = f"{content}_{datetime.now().isoformat()}"
return f"mem_{hashlib.md5(hash_input.encode()).hexdigest()[:16]}"
def get_statistics(self) -> Dict[str, Any]:
"""Get memory statistics"""
total = sum(len(m) for m in self.memories.values())
return {
'total_memories': total,
'by_type': {
mtype.value: len(mems)
for mtype, mems in self.memories.items()
},
'tag_count': len(self.tag_index),
'access_stats': {
'total': self.total_accesses,
'hits': self.hit_count,
'hit_rate': self.hit_count / max(1, self.total_accesses)
}
}
# ============================================================================
# Session Context Management
# ============================================================================
class SessionContext:
"""
Manages context for a single workflow session.
Supports checkpointing, recovery, and state persistence.
"""
def __init__(
self,
session_id: str,
max_tokens: int = MAX_CONTEXT_TOKENS,
checkpoint_interval: int = DEFAULT_CHECKPOINT_INTERVAL
):
self.session_id = session_id
self.created_at = datetime.now()
self.last_updated = datetime.now()
self.status = SessionStatus.CREATING
# Token budget management
self.max_tokens = max_tokens
self.tokens_used = 0
self.tokens_remaining = max_tokens
# Task state tracking
self.task_states: Dict[str, str] = {}
self.completed_tasks: Set[str] = set()
self.failed_tasks: Set[str] = set()
self.pending_tasks: Set[str] = set()
# Shared memory for task communication
self.shared_memory: Dict[str, Any] = {}
# Memory management
self.memory_manager = MemoryManager()
# Checkpointing
self.checkpoint_interval = checkpoint_interval
self.checkpoints: List[Checkpoint] = []
self.checkpoint_counter = 0
self.tasks_since_checkpoint = 0
# Event history
self.event_history: List[Dict] = []
# Subscribers for events
self.subscribers: Dict[str, Callable] = {}
def add_task(self, task_id: str) -> None:
"""Add a new task to track"""
self.task_states[task_id] = "pending"
self.pending_tasks.add(task_id)
self._record_event("task_added", {"task_id": task_id})
def start_task(self, task_id: str) -> None:
"""Mark task as started"""
self.task_states[task_id] = "running"
self.pending_tasks.discard(task_id)
self._record_event("task_started", {"task_id": task_id})
# Store in working memory
self.memory_manager.store(
MemoryType.WORKING,
f"Started task: {task_id}",
importance=0.5,
tags={'task', 'started'}
)
def complete_task(self, task_id: str, result: Any) -> None:
"""Mark task as completed with result"""
self.task_states[task_id] = "completed"
self.completed_tasks.add(task_id)
self._record_event("task_completed", {"task_id": task_id})
# Store result in shared memory
self.shared_memory[f"result_{task_id}"] = result
# Update token usage estimate
result_tokens = self._estimate_tokens(result)
self._update_token_usage(result_tokens)
# Store in episodic memory
self.memory_manager.store(
MemoryType.EPISODIC,
f"Completed task {task_id}",
importance=0.7,
tags={'task', 'completed', task_id}
)
# Check if checkpoint needed
self.tasks_since_checkpoint += 1
if self.tasks_since_checkpoint >= self.checkpoint_interval:
self.create_checkpoint()
def fail_task(self, task_id: str, error: str) -> None:
"""Mark task as failed"""
self.task_states[task_id] = "failed"
self.failed_tasks.add(task_id)
self._record_event("task_failed", {"task_id": task_id, "error": error})
# Store in memory
self.memory_manager.store(
MemoryType.EPISODIC,
f"Task {task_id} failed: {error}",
importance=0.9,
tags={'task', 'failed', task_id}
)
def create_checkpoint(self, metadata: Optional[Dict] = None) -> Checkpoint:
"""Create a checkpoint for recovery"""
self.checkpoint_counter += 1
checkpoint_id = f"cp_{self.session_id}_{self.checkpoint_counter:04d}"
checkpoint = Checkpoint(
checkpoint_id=checkpoint_id,
session_id=self.session_id,
timestamp=datetime.now(),
task_states=self.task_states.copy(),
shared_memory_snapshot=self.shared_memory.copy(),
memory_contents={
mem_type: [m.content for m in mems.values()]
for mem_type, mems in self.memory_manager.memories.items()
},
token_usage=self.tokens_used,
metadata=metadata or {}
)
self.checkpoints.append(checkpoint)
self.last_updated = datetime.now()
# Persist checkpoint
self._persist_checkpoint(checkpoint)
# Keep only recent checkpoints in memory
if len(self.checkpoints) > MAX_CHECKPOINTS_IN_MEMORY:
self.checkpoints.pop(0)
logger.info(f"Created checkpoint {checkpoint_id}")
return checkpoint
def restore_from_checkpoint(
self,
checkpoint: Checkpoint
) -> None:
"""Restore session state from checkpoint"""
logger.info(f"Restoring from checkpoint {checkpoint.checkpoint_id}")
# Restore task states
self.task_states = checkpoint.task_states.copy()
self.completed_tasks = {
tid for tid, status in self.task_states.items()
if status == "completed"
}
self.failed_tasks = {
tid for tid, status in self.task_states.items()
if status == "failed"
}
self.pending_tasks = {
tid for tid, status in self.task_states.items()
if status == "pending"
}
# Restore shared memory
self.shared_memory = checkpoint.shared_memory_snapshot.copy()
# Update token usage
self.tokens_used = checkpoint.token_usage
self.tokens_remaining = self.max_tokens - self.tokens_used
self._record_event(
"checkpoint_restored",
{"checkpoint_id": checkpoint.checkpoint_id}
)
def get_task_context(self, task_id: str) -> TaskContext:
"""Get context for a specific task including dependencies"""
# Find dependency results
deps_results = {}
for other_task_id, result in self.shared_memory.items():
if other_task_id.startswith("result_"):
deps_results[other_task_id.replace("result_", "")] = result
return TaskContext(
task_id=task_id,
session_id=self.session_id,
description="", # Would be populated from task definition
dependencies_results=deps_results,
shared_memory=self.shared_memory.copy(),
)
def get_progress_summary(self) -> Dict[str, Any]:
"""Get a summary of session progress"""
total_tasks = len(self.task_states)
completed = len(self.completed_tasks)
failed = len(self.failed_tasks)
pending = len(self.pending_tasks)
running = total_tasks - completed - failed - pending
return {
'session_id': self.session_id,
'status': self.status.value,
'created_at': self.created_at.isoformat(),
'last_updated': self.last_updated.isoformat(),
'tasks': {
'total': total_tasks,
'completed': completed,
'failed': failed,
'running': running,
'pending': pending
},
'progress_percent': (completed / max(1, total_tasks)) * 100,
'tokens': {
'used': self.tokens_used,
'remaining': self.tokens_remaining,
'max': self.max_tokens,
'usage_percent': (self.tokens_used / max(1, self.max_tokens)) * 100
},
'checkpoints': {
'total': len(self.checkpoints),
'latest': self.checkpoints[-1].checkpoint_id if self.checkpoints else None
}
}
def _update_token_usage(self, additional_tokens: int) -> None:
"""Update token usage tracking"""
self.tokens_used += additional_tokens
self.tokens_remaining = max(0, self.max_tokens - self.tokens_used)
if self.tokens_remaining <= 0:
logger.warning(f"Session {self.session_id} token budget exhausted")
def _estimate_tokens(self, data: Any) -> int:
"""Estimate token count for data"""
if isinstance(data, str):
return len(data) // 4 # Rough estimate
elif isinstance(data, dict):
return sum(self._estimate_tokens(v) for v in data.values())
elif isinstance(data, (list, tuple)):
return sum(self._estimate_tokens(v) for v in data)
else:
return 10 # Default estimate
def _record_event(
self,
event_type: str,
data: Dict[str, Any]
) -> None:
"""Record an event in history"""
self.event_history.append({
'type': event_type,
'timestamp': datetime.now().isoformat(),
**data
})
self.last_updated = datetime.now()
def _persist_checkpoint(self, checkpoint: Checkpoint) -> None:
"""Persist checkpoint to disk"""
try:
os.makedirs(CHECKPOINT_STORAGE_DIR, exist_ok=True)
filepath = os.path.join(
CHECKPOINT_STORAGE_DIR,
f"{checkpoint.checkpoint_id}.json"
)
with open(filepath, 'w') as f:
json.dump(checkpoint.to_dict(), f, indent=2)
except Exception as e:
logger.error(f"Failed to persist checkpoint: {e}")
# ============================================================================
# Context Manager (Session Manager)
# ============================================================================
class ContextManager:
"""
Main context manager for Dynamic Workflows.
Manages multiple sessions, cross-session memory, and global state.
"""
def __init__(
self,
max_sessions: int = 100,
default_max_tokens: int = MAX_CONTEXT_TOKENS
):
self.max_sessions = max_sessions
self.default_max_tokens = default_max_tokens
# Active sessions
self.sessions: Dict[str, SessionContext] = {}
self.session_lock = asyncio.Lock()
# Global cross-session memory
self.global_memory = MemoryManager(
max_memory_items=50000,
importance_threshold=0.5
)
# Session factory
self.session_counter = 0
# Event handlers
self.on_session_create: Optional[Callable] = None
self.on_session_complete: Optional[Callable] = None
async def create_session(
self,
name: Optional[str] = None,
max_tokens: Optional[int] = None
) -> SessionContext:
"""Create a new session context"""
async with self.session_lock:
self.session_counter += 1
session_id = name or f"session_{self.session_counter:06d}"
# Check session limit
if len(self.sessions) >= self.max_sessions:
# Archive oldest completed session
await self._archive_oldest_session()
# Create session
session = SessionContext(
session_id=session_id,
max_tokens=max_tokens or self.default_max_tokens
)
session.status = SessionStatus.ACTIVE
self.sessions[session_id] = session
logger.info(f"Created session: {session_id}")
if self.on_session_create:
await self.on_session_create(session)
return session
async def get_session(self, session_id: str) -> Optional[SessionContext]:
"""Get an existing session"""
return self.sessions.get(session_id)
async def close_session(self, session_id: str) -> None:
"""Close and archive a session"""
async with self.session_lock:
session = self.sessions.get(session_id)
if not session:
return
# Final checkpoint
session.create_checkpoint({'final': True})
# Archive important memories to global memory
for task_id in session.completed_tasks:
self.global_memory.store(
MemoryType.LONG_TERM,
f"Completed task {task_id} in session {session_id}",
importance=0.8,
tags={'task', 'completed', 'archived'}
)
# Update session status
if session.failed_tasks:
session.status = SessionStatus.FAILED
else:
session.status = SessionStatus.COMPLETED
# Move to archived state
session.status = SessionStatus.ARCHIVED
# Remove from active sessions
del self.sessions[session_id]
logger.info(f"Closed session: {session_id}")
async def transfer_context(
self,
from_session_id: str,
to_session_id: str,
include_memories: bool = True
) -> None:
"""Transfer context from one session to another"""
from_session = self.sessions.get(from_session_id)
to_session = self.sessions.get(to_session_id)
if not from_session or not to_session:
raise ValueError("One or both sessions not found")
# Transfer shared memory
for key, value in from_session.shared_memory.items():
to_session.shared_memory[key] = value
# Transfer memories if requested
if include_memories:
for mem_type, memories in from_session.memory_manager.memories.items():
for memory in memories.values():
to_session.memory_manager.store(
mem_type,
memory.content,
memory.importance,
memory.tags,
memory.source_task_id
)
logger.info(
f"Transferred context from {from_session_id} to {to_session_id}"
)
async def get_global_context(
self,
query: Optional[str] = None,
limit: int = 100
) -> List[MemoryEntry]:
"""Get global cross-session memories"""
return self.global_memory.retrieve(
memory_type=MemoryType.LONG_TERM,
query=query,
limit=limit
)
async def _archive_oldest_session(self) -> None:
"""Archive the oldest completed session"""
oldest = None
oldest_time = datetime.max
for session_id, session in self.sessions.items():
if session.status in [SessionStatus.COMPLETED, SessionStatus.FAILED]:
if session.last_updated < oldest_time:
oldest = session_id
oldest_time = session.last_updated
if oldest:
await self.close_session(oldest)
def get_statistics(self) -> Dict[str, Any]:
"""Get global statistics"""
active_count = sum(
1 for s in self.sessions.values()
if s.status == SessionStatus.ACTIVE
)
total_tasks = sum(len(s.task_states) for s in self.sessions.values())
total_completed = sum(len(s.completed_tasks) for s in self.sessions.values())
return {
'sessions': {
'active': active_count,
'total': len(self.sessions),
'max': self.max_sessions
},
'tasks': {
'total': total_tasks,
'completed': total_completed,
'completion_rate': total_completed / max(1, total_tasks)
},
'global_memory': self.global_memory.get_statistics(),
'tokens': {
'total_used': sum(s.tokens_used for s in self.sessions.values()),
'total_remaining': sum(s.tokens_remaining for s in self.sessions.values())
}
}
# ============================================================================
# Demo
# ============================================================================
async def main():
"""Demonstrate the Context Manager"""
# Create context manager
manager = ContextManager()
# Create a new session
session = await manager.create_session("demo_migration")
print(f"Created session: {session.session_id}")
# Add tasks
task_ids = [
"scan_codebase",
"analyze_dependencies",
"generate_stubs",
"migrate_core",
"migrate_tests",
"fix_imports",
"validate"
]
for task_id in task_ids:
session.add_task(task_id)
print(f"Added {len(task_ids)} tasks")
# Simulate task execution
for task_id in task_ids:
session.start_task(task_id)
# Simulate work
await asyncio.sleep(0.1)
# Simulate some failures
if task_id == "fix_imports":
session.fail_task(task_id, "Import resolution timeout")
else:
result = {
'task_id': task_id,
'files_processed': 10,
'status': 'success'
}
session.complete_task(task_id, result)
# Create checkpoint
checkpoint = session.create_checkpoint({'note': 'Mid-execution checkpoint'})
print(f"Created checkpoint: {checkpoint.checkpoint_id}")
# Get progress
progress = session.get_progress_summary()
print("\nSession Progress:")
print(json.dumps(progress, indent=2))
# Get memory statistics
mem_stats = session.memory_manager.get_statistics()
print("\nMemory Statistics:")
print(json.dumps(mem_stats, indent=2))
# Get global statistics
global_stats = manager.get_statistics()
print("\nGlobal Statistics:")
print(json.dumps(global_stats, indent=2))
if __name__ == "__main__":
asyncio.run(main())
4. Performance Benchmarks & Competitive Analysis
Claude Opus 4.8 demonstrates remarkable improvements across multiple benchmarks:
4.1 Benchmark Results
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-Bench Pro | 69.2% | ~65% | ~58% |
| Terminal-Bench 2.1 | ~68% | 78.2% | ~62% |
| HumanEval | 95.3% | 94.1% | 91.8% |
| MMLU | 92.1% | 91.5% | 90.2% |
4.2 Key Improvements in Claude Opus 4.8
Dramatic Honesty Improvement
- Code defect unexplained probability dropped to 1/4 of previous generation
- This directly translates to more reliable production code generation
Fast Mode Performance
- 2.5× speed improvement in fast mode
- Cost reduced to 1/3 of previous pricing
- Maintains quality while being significantly faster and cheaper
Context Window
- 1M Token context window maintained
- Pricing stays at $5/$25 per million tokens
- Enables true cross-codebase operations
4.3 Dynamic Workflows Capability Matrix
| Capability | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|
| Parallel Sub-Agents | 100+ | ~20 | ~30 |
| Cross-Codebase Migration | Native | Limited | Limited |
| Session Persistence | Native | Basic | Basic |
| Checkpoint/Recovery | Native | No | Limited |
5. Anthropic’s Commercial Trajectory
Anthropic’s position in the market reflects both technical excellence and business momentum:
5.1 Funding and Valuation
- H-Round Financing: $650 billion
- Valuation: $9,650 billion (world’s most valuable AI startup)
- Investors: Sequoia, Google, Spark Capital, and others
5.2 Revenue Metrics (Q2 2026)
| Metric | Value |
|---|---|
| Annualized Revenue | ~$109 billion |
| Year-over-Year Growth | 130% |
| Quarterly Profit | ~$5.59 billion |
This financial trajectory demonstrates that Anthropic has successfully transitioned from research organization to commercial powerhouse.
6. Future Implications for Software Engineering
6.1 The Paradigm Shift
Claude Opus 4.8 represents more than a technical upgrade—it signals a fundamental shift in how software engineering will be performed:
From: Human writes code, AI assists with suggestions To: Human defines objectives, AI orchestrates execution
6.2 Engineering Team Evolution
| Role | Traditional | With Dynamic Workflows |
|---|---|---|
| Junior Developer | Writes basic code | Monitors agent outputs |
| Senior Developer | Reviews code | Defines task decomposition |
| Tech Lead | Designs architecture | Orchestrates multi-agent workflows |
| Architect | Creates blueprints | Designs agent collaboration patterns |
6.3 New Engineering Disciplines
- Agent Orchestration Engineering: Designing effective multi-agent workflows
- Context Engineering: Managing long-session state and memory
- Quality Assurance for AI: Verifying AI-generated code meets standards
- Workflow Optimization: Maximizing parallelization efficiency
6.4 Industry Impact Timeline
| Phase | Timeline | Capabilities |
|---|---|---|
| Current | 2026 | Parallel agent execution, basic workflows |
| Near Term | 2027-2028 | Autonomous feature development |
| Medium Term | 2029-2030 | Self-maintaining codebases |
| Long Term | 2031+ | AI-driven software evolution |
7. Conclusion
Claude Opus 4.8’s Dynamic Workflows capability represents a watershed moment in artificial intelligence and software engineering. By enabling parallel scheduling of hundreds of sub-agents within a single session, Claude has evolved from a sophisticated conversational AI into a true Engineering Collaboration System.
The implications are profound:
- Productivity: Complex tasks that previously took weeks can now be completed in hours
- Quality: Multi-agent verification and review catch issues that human reviewers might miss
- Scale: Cross-hundred-thousand-line migrations become feasible
- Economics: 2.5× speed improvement with 1/3 the cost fundamentally changes the ROI equation
The competitive landscape has shifted decisively. The question is no longer “which AI writes the best code” but “which AI can reliably execute complex engineering workflows.” Claude Opus 4.8 has established a clear lead in this new paradigm.
For engineering organizations, the message is clear: The future of software development is collaborative, with AI agents as active participants rather than passive tools. Those who embrace this paradigm shift will dramatically outperform those who cling to traditional development methodologies.
The era of “chat AI” is ending. The era of “Engineering AI” has begun.
References
- Anthropic. (2026, May 29). Claude Opus 4.8 Release Notes. Anthropic Official Blog.
- SWE-bench. (2026). SWE-Bench Pro Leaderboard. Retrieved from https://swe-bench.ai
- Anthropic Capital. (2026). Q2 2026 Financial Summary. Internal Report.
- Dynamic Workflows Documentation. (2026). Architecture and Implementation Guide.
This article is part of the “AI Engineering” technical series. For more content on multi-agent systems, workflow orchestration, and AI-assisted development, explore our other publications.