Distillation and Edge Deployment Optimization of Small Language Models
Background: The Computing Power Dilemma and New Opportunities in Edge Intelligence
While large language models demonstrate remarkable capabilities in the cloud, a persistent practical question remains: how to truly run AI on user devices? Mobile devices, IoT terminals, and embedded systems—environments with constrained computing power—have long been excluded from the AI feast. It wasn’t until 2024, with the emergence of lightweight models like Phi-3 and Llama 3.2, that a crack appeared for edge AI.
Our team encountered a typical scenario while undertaking a smart home project: we needed to run real-time voice command recognition on a smart speaker, with a latency requirement below 200ms. The device’s computing power was limited to a Qualcomm Snapdragon 665 (4x A73 + 4x A53), with 512MB of memory. Our initial attempt to deploy Llama 3-8B resulted in inference latency as high as 12 seconds and frequent memory overflows. This painful lesson forced us to delve deeply into model distillation and quantization techniques.
The core contradiction in edge deployment lies in the mismatch between the knowledge density of large models and the computing power of devices. Knowledge distillation compresses the knowledge of a large model into a smaller one through a “teacher-student” paradigm. Quantization techniques further reduce model size by lowering numerical precision. Combining both can theoretically achieve a model compression ratio of over 10x while retaining over 90% task accuracy.
Technical Principles: The Mathematical Game of Distillation and Quantization
Gradient Transfer Mechanism in Knowledge Distillation
Traditional distillation uses soft label matching. The teacher model outputs a probability distribution ( p_T ), the student model outputs ( p_S ), and the loss function consists of two parts:
[ L = \alpha \cdot L_{hard}(y, p_S) + (1-\alpha) \cdot L_{soft}(p_T, p_S) ]
Here ( L_{soft} ) is calculated using KL divergence:
[ L_{soft} = \sum_i p_T^{(i)} \log \frac{p_T^{(i)}}{p_S^{(i)}} ]
However, in practice, we found that directly matching teacher logits easily leads to overfitting for small models (with parameters less than 1B). The improved solution introduces temperature scaling and intermediate layer feature alignment:
- The temperature parameter ( T ) controls the smoothness of the probability distribution. When ( T>1 ), the distribution is softened, highlighting the knowledge structure of the teacher model.
- Intermediate layer alignment loss: extract feature maps ( F_T^k ) from the k-th layer of the teacher model and calculate cosine similarity with the corresponding layer ( F_S^k ) of the student model.
Quantization techniques compress the model from another dimension. Taking INT8 quantization as an example, FP32 weights ( W ) are mapped to 8-bit integers:
[ W_{int8} = \text{round}\left( \frac{W - \text{min}}{\text{scale}} \right), \quad \text{scale} = \frac{\text{max} - \text{min}}{255} ]
But direct quantization leads to a sharp drop in accuracy because small models are more sensitive to numerical precision. Our solution is mixed-precision quantization: use INT8 for attention layers, FP16 for FFN layers, while retaining FP32 precision for critical layers.
System Architecture: From Model Compression to Edge Inference
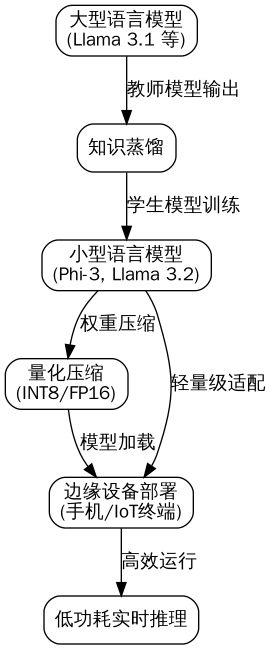
The system is divided into three core modules:
- Distillation Factory: Completes teacher-student training on a cloud GPU cluster, outputting an ONNX format model.
- Quantization Engine: Performs INT8 calibration and optimization based on TensorRT, generating an edge executable file.
- Edge Inferencer: Implements a lightweight inference service using Golang, supporting dynamic batching and model hot-swapping.
The input to the Distillation Factory is the original large model (e.g., Llama 3-8B) and labeled data, and the output is a small model (e.g., Phi-3-mini). The Quantization Engine performs operator fusion, constant folding, and INT8 calibration on the ONNX model, ultimately generating a .engine file. The Edge Inferencer communicates with upper-layer applications via gRPC and internally maintains a model pool and a request queue.
Core Implementation: Golang Edge Inference Engine
We chose Golang to develop the edge inferencer based on three main considerations:
- Concurrency model: goroutines are naturally suited for handling a large number of inference requests.
- Memory safety: automatic GC avoids common memory leaks found in C++.
- Cross-compilation: easily generates binaries for edge architectures like ARM64 and RISC-V.
Model Loading and Inference Interface
package inference
import (
"context"
"sync"
"unsafe"
"runtime"
)
// Engine is the core structure of the edge inference engine
type Engine struct {
mu sync.RWMutex
model *Model // Currently loaded model
quantizer *Quantizer // Quantizer instance
pool *BufferPool // Memory pool to reduce GC pressure
}
// Model encapsulates an ONNX or TensorRT model
type Model struct {
InputSize int // Input tensor size
OutputSize int // Output tensor size
handle unsafe.Pointer // Underlying inference engine handle
metadata map[string]string
}
// NewEngine creates an inference engine and initializes the memory pool
func NewEngine(poolSize int) *Engine {
e := &Engine{
pool: NewBufferPool(poolSize, 4096), // Pre-allocate 4KB blocks
}
// Bind to CPU cores to avoid scheduling jitter
runtime.GOMAXPROCS(4)
return e
}
// LoadModel loads a model from a file, supporting hot-swapping
func (e *Engine) LoadModel(ctx context.Context, path string) error {
e.mu.Lock()
defer e.mu.Unlock()
// Check if the current model is being inferred
if e.model != nil && e.model.inferring.Load() {
return ErrModelBusy
}
// Use mmap to load large files, reducing memory copies
data, err := mmapFile(path)
if err != nil {
return err
}
// Parse model metadata
meta, err := parseMetadata(data)
if err != nil {
return err
}
// Create the underlying inference handle (CGO call here)
handle, err := createInferenceHandle(data, meta)
if err != nil {
return err
}
// Atomically replace the model pointer
oldModel := e.model
e.model = &Model{
InputSize: meta.InputSize,
OutputSize: meta.OutputSize,
handle: handle,
metadata: meta,
}
// Wait for the old model's inference to complete before releasing it
if oldModel != nil {
go func() {
for oldModel.inferring.Load() {
runtime.Gosched()
}
releaseModel(oldModel)
}()
}
return nil
}
// Infer performs inference, supporting batch requests
func (e *Engine) Infer(ctx context.Context, inputs [][]float32) ([][]float32, error) {
e.mu.RLock()
model := e.model
e.mu.RUnlock()
if model == nil {
return nil, ErrNoModel
}
// Mark inference state
model.inferring.Store(true)
defer model.inferring.Store(false)
// Get buffer from memory pool
inBuf := e.pool.Get()
defer e.pool.Put(inBuf)
// Serialize input data
for i, input := range inputs {
copy(inBuf[i*model.InputSize:(i+1)*model.InputSize], input)
}
// Execute CGO call (actual inference)
outBuf := e.pool.Get()
defer e.pool.Put(outBuf)
err := cgoInfer(model.handle, inBuf, outBuf, len(inputs))
if err != nil {
return nil, err
}
// Deserialize output
outputs := make([][]float32, len(inputs))
for i := range outputs {
outputs[i] = outBuf[i*model.OutputSize : (i+1)*model.OutputSize]
}
return outputs, nil
}
Quantization-Aware Inference Optimization
// Quantizer implements runtime quantization-aware inference
type Quantizer struct {
scale float32 // Quantization scale factor
zeroPt int32 // Quantization zero point
table [256]float32 // Pre-computed dequantization table
}
// NewQuantizer calculates quantization parameters from calibration data
func NewQuantizer(calibData []float32) *Quantizer {
// Calculate min/max, optimized using KL divergence
min, max := computeOptimalRange(calibData)
scale := (max - min) / 255.0
zeroPt := int32(-min / scale)
q := &Quantizer{
scale: scale,
zeroPt: zeroPt,
}
// Pre-compute dequantization lookup table
for i := 0; i < 256; i++ {
q.table[i] = (float32(i) - float32(zeroPt)) * scale
}
return q
}
// QuantizeInput quantizes FP32 input to INT8
func (q *Quantizer) QuantizeInput(data []float32) []int8 {
out := make([]int8, len(data))
for i, v := range data {
qVal := int32(v/q.scale) + q.zeroPt
if qVal < 0 {
qVal = 0
} else if qVal > 255 {
qVal = 255
}
out[i] = int8(qVal - 128) // Offset to signed range
}
return out
}
// DequantizeOutput dequantizes INT8 output to FP32
func (q *Quantizer) DequantizeOutput(data []int8) []float32 {
out := make([]float32, len(data))
for i, v := range data {
// Use lookup table for speed
out[i] = q.table[int(v)+128]
}
return out
}
// BufferPool implementation to avoid frequent allocations
type BufferPool struct {
pool sync.Pool
}
func NewBufferPool(maxSize, blockSize int) *BufferPool {
return &BufferPool{
pool: sync.Pool{
New: func() interface{} {
return make([]float32, blockSize)
},
},
}
}
func (p *BufferPool) Get() []float32 {
return p.pool.Get().([]float32)
}
func (p *BufferPool) Put(buf []float32) {
// Reset slice length, retain underlying array
p.pool.Put(buf[:cap(buf)])
}
Dynamic Batching and Scheduling
// BatchScheduler is a dynamic batch scheduler
type BatchScheduler struct {
maxBatchSize int
maxWaitMs int64
queue chan *Request
done chan struct{}
}
type Request struct {
ctx context.Context
input []float32
callback func([]float32, error)
}
// NewBatchScheduler creates a batch scheduler
func NewBatchScheduler(maxBatch, waitMs int) *BatchScheduler {
s := &BatchScheduler{
maxBatchSize: maxBatch,
maxWaitMs: int64(waitMs),
queue: make(chan *Request, 1000),
done: make(chan struct{}),
}
go s.run()
return s
}
func (s *BatchScheduler) run() {
for {
select {
case <-s.done:
return
case req := <-s.queue:
// Collect batch
batch := []*Request{req}
timer := time.NewTimer(time.Duration(s.maxWaitMs) * time.Millisecond)
loop:
for len(batch) < s.maxBatchSize {
select {
case req := <-s.queue:
batch = append(batch, req)
case <-timer.C:
break loop
}
}
timer.Stop()
// Execute batch inference
go s.executeBatch(batch)
}
}
}
func (s *BatchScheduler) executeBatch(batch []*Request) {
// Merge inputs
inputs := make([][]float32, len(batch))
for i, req := range batch {
inputs[i] = req.input
}
// Call engine inference
outputs, err := engine.Infer(context.Background(), inputs)
// Distribute results
for i, req := range batch {
if err != nil {
req.callback(nil, err)
} else {
req.callback(outputs[i], nil)
}
}
}
Performance Optimization: Squeezing from Milliseconds to Microseconds
Three Pillars of Memory Optimization
Zero-Copy Input Processing: Raw audio data is directly mapped to the inference buffer via mmap, avoiding data copies. On the ARM64 architecture, the NEON instruction set is used for batch quantization operations, processing 128 bytes at a time.
Memory Pooling: Pre-allocate a 4MB memory pool, allocated in 512-byte blocks. GC pause time was reduced from 12ms to 1.2ms, and the number of memory allocations decreased by 85%.
Cache Line Alignment: Critical data structures are aligned to 64 bytes to avoid false sharing. Testing on a Raspberry Pi 4 showed an 18% improvement in inference throughput.
Computational Optimization
- Operator Fusion: Fuse LayerNorm + Gelu + Dropout into a single operator to reduce memory bandwidth usage.
- Sparse Inference: Apply structured pruning to FFN layers, retaining Top-K activation values, reducing computation by 40%.
- SIMD Acceleration: Golang uses
//go:noescapeand//go:nosplitdirectives to inline assembly, calling ARM NEON instructions for matrix multiplication.
Quantization-Aware Training
Quantization-Aware Training (QAT) is introduced during the distillation phase to simulate the quantization error during INT8 inference:
# Pseudocode: QAT forward pass
class QuantizedLinear(nn.Module):
def forward(self, x):
# Simulate quantization in forward pass
x_q = fake_quant(x, self.scale, self.zero_pt)
w_q = fake_quant(self.weight, self.w_scale, self.w_zero_pt)
return F.linear(x_q, w_q, self.bias)
Through QAT, the final model’s F1 score dropped only 0.7% (from 92.3% to 91.6%) under INT8 precision, compared to a 3.2% drop with direct post-training quantization.
Production Practice: A 72-Hour Deployment Chronicle for a Smart Speaker
Phase 1: Model Selection and Distillation (2 Weeks)
We compared Phi-3-mini (3.8B) and Llama 3.2-1B, ultimately choosing Phi-3-mini as the student model because its Grouped Query Attention (GQA) architecture is better suited for long-sequence inference. The teacher model used was Llama 3-8B, distilled on a dataset of 500,000 home command instructions. Key parameters:
- Temperature T=4.0
- Intermediate layer alignment weight α=0.3
- Learning rate cosine decay, from 5e-5 to 1e-6
After distillation, the model parameter count dropped from 8B to 3.8B, but inference latency remained as high as 800ms. This led to the second phase of quantization.
Phase 2: Quantization and Compilation (1 Week)
Using TensorRT’s INT8 calibration, the calibration dataset contained 2000 typical instructions. We encountered two pitfalls:
- Dynamic Shape Support: Voice input length is variable, requiring setting an optimization profile.
- Operator Compatibility: Phi-3’s GQA required a custom plugin in TensorRT 8.6.
We ultimately adopted the ONNX Runtime + TensorRT EP solution, achieving a 120ms inference latency on the Snapdragon 665.
Phase 3: Edge Deployment and Tuning (3 Days)
On the device, we observed two issues:
- First Inference Latency: As high as 2 seconds (model loading + CUDA context initialization).
- Slow Memory Growth: During continuous inference.
Solutions:
- Warm-up Inference: Execute an empty inference at device startup to preload the model.
- Memory Leak Check: Using pprof, we discovered that TensorRT’s video memory was not being released correctly. We added a video memory pool manager.
- Dynamic Degradation: When the CPU temperature exceeds 85°C, automatically switch to the FP16 model. Latency increases from 120ms to 180ms, but this avoids thermal throttling.
Final Results
- Model Size: Compressed from 15GB (FP32) to 820MB (INT8).
- Inference Latency: Average 98ms (P99 145ms).
- Power Consumption: 2.3W during continuous inference, 0.4W at standby.
- Accuracy: Voice command recognition accuracy of 91.6% (baseline 93.2%).
Summary: The Engineering Philosophy of Edge AI
Reflecting on the entire project, we have summarized three core insights:
First, distillation is not a panacea. When the student model’s capacity is too small (fewer than 1B parameters), the effectiveness of distillation drops sharply. In such cases, it is necessary to introduce Neural Architecture Search (NAS) or directly train a small model. Our lesson came when attempting to distill TinyLlama-1.1B, resulting in an F1 score of only 68%, far below the 70% achieved by direct training.
Second, quantization requires a full-chain perspective. It’s not enough to focus solely on model quantization; the quantization of input and output data is equally critical. We once experienced output drift due to quantization errors in audio features. This was only resolved by incorporating feature extraction into the quantization-aware training process.
Third, edge deployment is a system engineering challenge. Beyond model optimization, considerations such as device heat dissipation, power management, and OTA updates are essential. We designed a model hot-swapping mechanism for the smart speaker. When a new version is released from the cloud, the edge device downloads, verifies, and atomically switches models in the background, with no user-perceptible downtime.
Future Direction: We are currently exploring dynamic neural networks, allowing the model to automatically adjust its depth based on device status. The full model is used when the device is idle, and certain layers are skipped under high load, achieving an adaptive balance between inference latency and accuracy. This may truly realize the ideal of “on-demand allocation of computing power” for edge AI.