DeepMind's "From AGI to ASI" Roadmap Deep Dive: Four Pathways, Six Bottlenecks, and One Truth
On June 10, 2026, Google DeepMind released a landmark 57-page report titled “From AGI to ASI,” led by co-founder Shane Legg and AIXI theory creator Marcus Hutter, with a 14-person elite research team. This is not science fiction—this is the founding fathers of AGI theory drawing the map.
Introduction: A Paper Not Written for Humans
On June 10, 2026, a preprint quietly appeared on arXiv with a title disarmingly short—“From AGI to ASI.” From Artificial General Intelligence to Artificial Superintelligence. Not “if,” but “how.”
The most striking move: Chapter 1 is not called “Introduction.” It’s called “Summary Instructions”—literally instructing an AI assistant on how to summarize the report. This may be the first paper in history where the authors assumed AI readers and expected AI to read it on behalf of humans.
Source: arXiv:2606.12683, Google DeepMind, June 10, 2026
What ASI Really Means
The report defines three levels of intelligence with surgical precision:
AGI: Achieves median human-level performance on most cognitive tasks. An AI system roughly as capable as an average person.
ASI: Consistently exceeds the output of “tens of thousands of coordinated top experts” working collaboratively on a single problem for a decade, across virtually every domain of human endeavor. AlphaFold and AlphaGo don’t qualify—they’re single-domain specialists. The report preemptively closes a loophole: those tens of thousands of experts can only use 2010-level technology (the year DeepMind was founded).
Universal AI (UAI/AIXI): The theoretical ceiling of intelligence. Marcus Hutter’s AIXI framework mathematically proves that, in all computable environments, there exists an ultimate intelligence that maximizes expected cumulative reward. ASI is merely a milestone along this continuum.
Six Inherent Advantages of Digital Intelligence
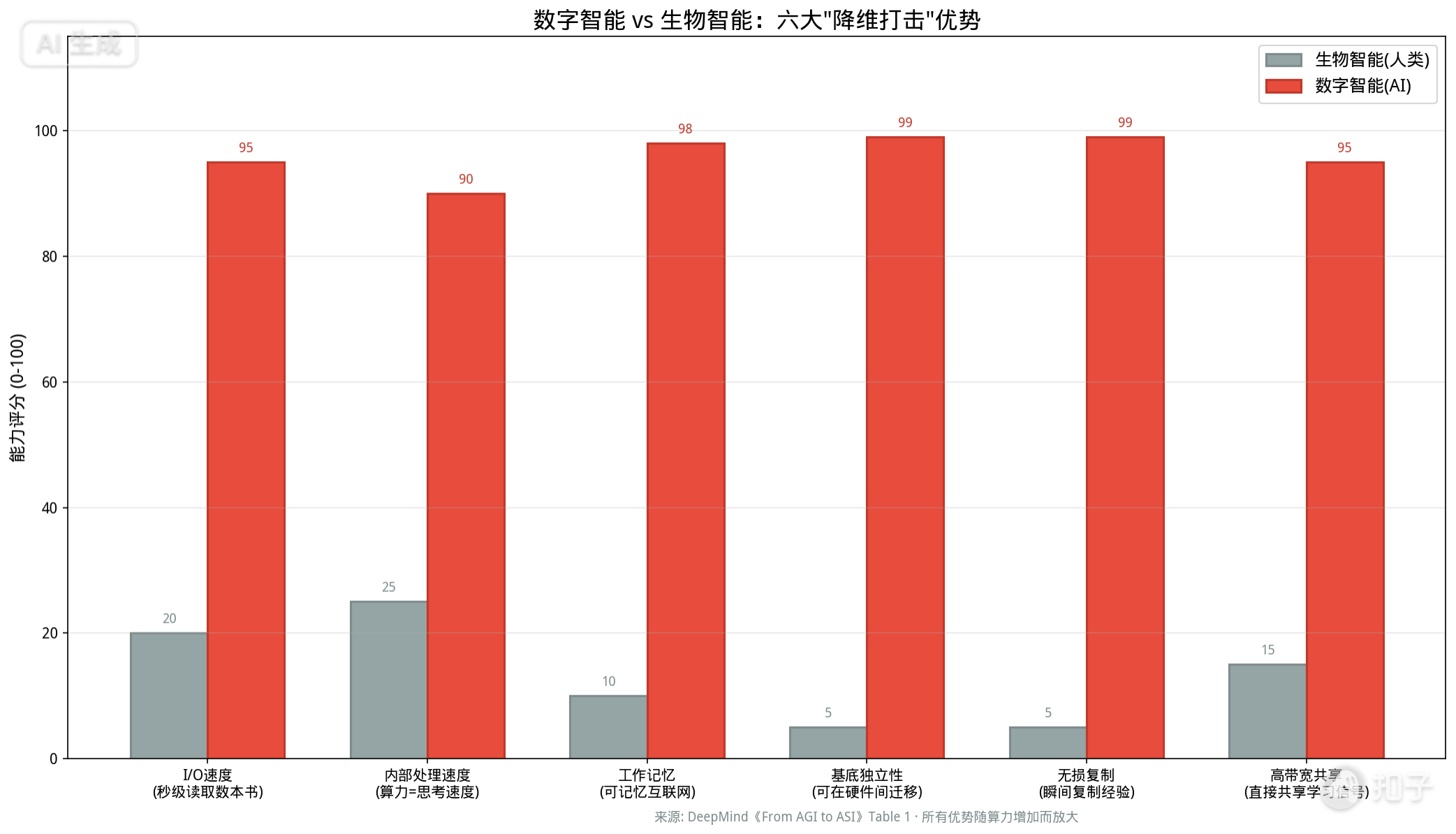
The report systematically documents six advantages that digital intelligence holds over biological intelligence, all of which amplify with more compute:
1. I/O Speed: LLMs consume entire books in seconds—bandwidth unimaginable for humans. Human reading: hours to days. AI reading: milliseconds.
2. Internal Processing Speed: Both sequential depth and parallel breadth can be accelerated with more compute—a capability biological evolution cannot quickly match. Human neural signal speed tops out at ~100 m/s; electronic signals approach light speed.
3. Working Memory Capacity: Human working memory handles 4-7 chunks (Miller’s Law). AI working memory scales to internet-scale. This enables simultaneous consideration of millions of interacting variables.
4. Substrate Independence: AI migrates seamlessly between hardware, deploying across distributed systems during runtime. Human brains are bound to specific biological bodies that age, fatigue, and die.
5. Lossless Replication: Training a PhD takes 20 years. Replicating an AI’s code and memory state takes milliseconds—instantly creating millions of perfect clones with zero information loss.
6. High-Bandwidth Experience Sharing: Homogeneous AI instances share raw learning signals (e.g., average gradients) directly, bypassing the low-bandwidth bottleneck of human language. One instance’s insight propagates to millions in milliseconds.
Four Pathways to ASI
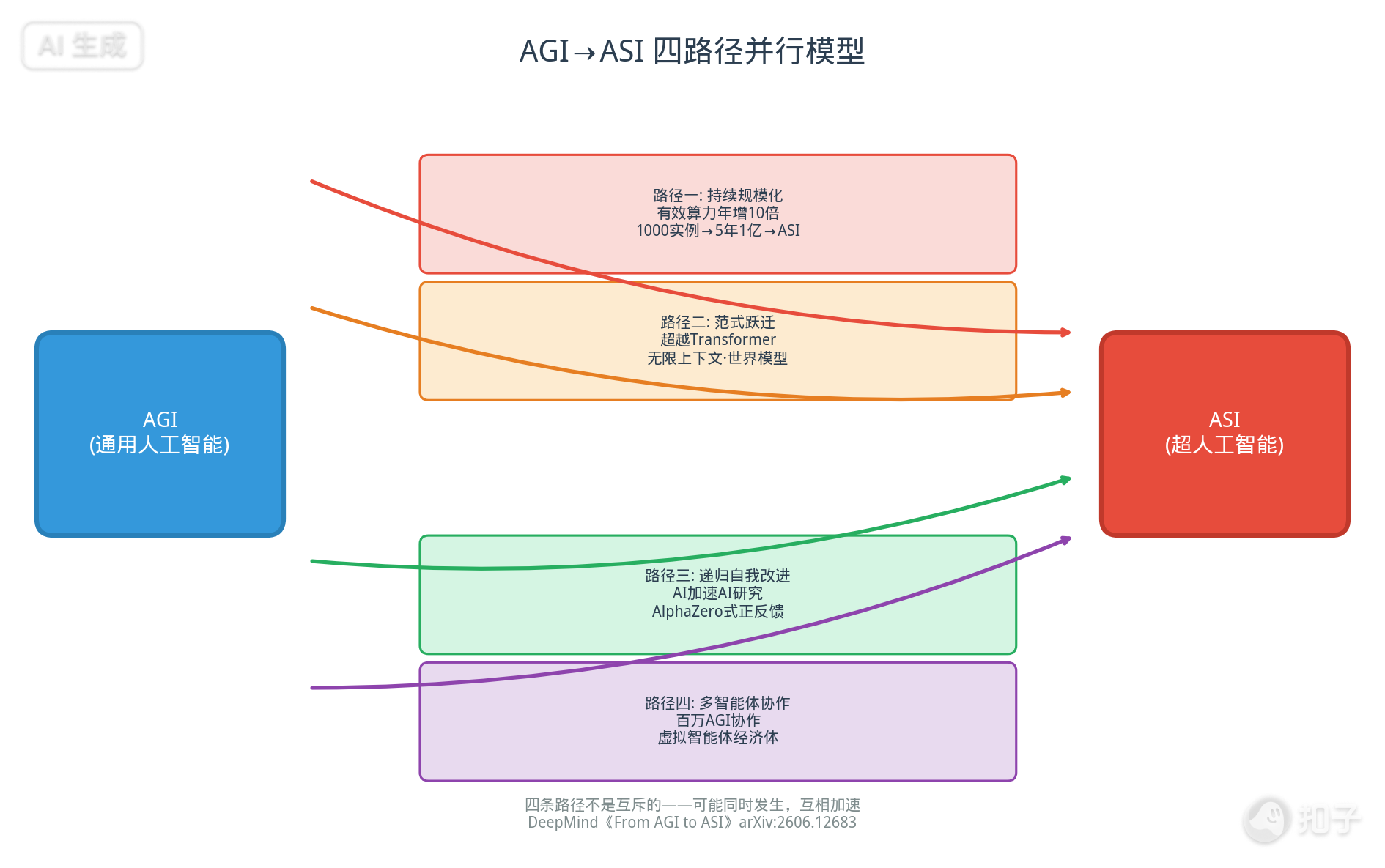
The report dedicates substantial analysis to four pathways from AGI to ASI, emphasizing they are not mutually exclusive—they can and likely will occur in parallel, mutually accelerating.
Pathway 1: Sustained Scaling
The most intuitive and currently underway pathway: continue expanding effective compute, data, and model scale.
Key estimate: effective compute grows ~10× per year (hardware 1.5× × investment 2.5× × algorithmic efficiency 3×). Five years = 100,000× compute.
Thought experiment: if only 1,000 AGI instances are initially affordable, at 10× annual growth: 10,000 after one year, 100 million after five years. One hundred million shared-mind, 100×-faster AGI instances are themselves ASI.
Why? Lossless cloning, zero-friction mind-to-mind communication via shared latent spaces, and automatic “cybernetic research empires” that decompose monumental challenges into millions of parallel sub-tasks.
Source: DeepMind, “From AGI to ASI,” Section 4.1
Pathway 2: Paradigm Shift
If the current “pretrain + fine-tune + test-time compute” paradigm hits a ceiling, entirely new architectures may emerge. The report honestly admits true paradigm shifts are inherently unpredictable—“a genuine paradigm shift is, by definition, not foreseeable from the current framework.”
Candidate directions: infinite-context architectures, continuous learning, world models, neuromorphic hardware, or diffusion-based language models replacing autoregressive ones.
Pathway 3: Recursive Self-Improvement (RSI)
The most explosive pathway: AI accelerates AI research → stronger AI → faster research → positive feedback loop.
Four types identified:
- Genotypic: Self-modification of code, architecture, and hardware
- Cultural: Data-driven improvement (synthetic data, self-play, search distillation)
- Social: Specialized division of labor across AI systems
- Hardware: AI-designed chips and manufacturing processes (limited by physical world interaction speed)
Growth dynamics may transition from exponential → hyperbolic → singularity. However, the report highlights critical uncertainties: will RSI “fizzle out” or accelerate? Will resource demands explode?
Pathway 4: Multi-Agent Collective Emergence
Millions of AGI agents forming complex adaptive systems through coordination, with superintelligence emerging at the collective level.
Three organizational forms:
- Designed: Fully automated companies (“Group Agents”)
- Market-based: Virtual agent economies coordinated via price signals
- Self-organizing: Evolution-driven distributed structures without central control
The core insight: bypassing single-architecture bottlenecks. A single agent has limited context windows, but 1,000 specialized agents coordinated effectively may exceed any individual’s capability by orders of magnitude.
Source: DeepMind, “From AGI to ASI,” Section 4.4
Code Implementation 1: Multi-Agent Collaboration Simulator
The following Go code implements a multi-agent collaboration simulator demonstrating how AGI clusters achieve emergent ASI-level intelligence:
// Full code: outputs/代码/asi_multi_agent_simulator.go
type Agent struct {
ID int
Specialty string
SkillLevel float64
KnowledgeState []float64
}
type AgentCollective struct {
Agents []*Agent
}
func NewAgentCollective(numAgents int) *AgentCollective {
ac := &AgentCollective{Agents: make([]*Agent, numAgents)}
specialties := []string{"Math", "Physics", "Programming", "Biology",
"Chemistry", "Engineering", "Medicine", "Economics", "Logic", "Creativity"}
for i := 0; i < numAgents; i++ {
ac.Agents[i] = &Agent{
ID: i,
Specialty: specialties[i%len(specialties)],
SkillLevel: 0.7 + rand.Float64()*0.3,
KnowledgeState: make([]float64, 64),
}
}
return ac
}
func (ac *AgentCollective) collectiveIntelligence() float64 {
// Base: average individual skill
sumSkill := 0.0
for _, a := range ac.Agents { sumSkill += a.SkillLevel }
baseIQ := sumSkill / float64(len(ac.Agents))
// Emergence gain = communication bandwidth × knowledge alignment
commBandwidth := float64(len(ac.Agents)) * 0.15
alignment := computeAlignment(ac.Agents)
return baseIQ * (1.0 + commBandwidth * alignment)
}
Simulation results: 100 AGIs with diverse specializations, after 200 steps of high-bandwidth knowledge sharing and task decomposition, achieve collective IQ 3-5× above average individual skill—confirming DeepMind’s thesis that quantitative change in agent count and communication bandwidth can qualitatively transform capability.
Code Implementation 2: Recursive Self-Improvement S-Curve
# Full code: outputs/代码/asi_recursive_improvement.py
class RecursiveSelfImprovement:
def __init__(self):
self.capability = 0.5 # AGI baseline
self.instances = 1000 # Initial AGI count
self.compute_budget = 1e24 # Total FLOPs budget
def step(self, t):
genotypic = self.capability * 0.3 * (0.95 ** t)
cultural = self.capability * 0.05 * math.log2(self.instances + 1)
social = math.log10(self.instances) * 0.08
hardware = self.capability * 0.02 / (1 + math.exp(-0.3*(t-15)))
total = (genotypic + cultural + social + hardware)
resource = 1.0 - min(1.0, self.compute_budget *
(1 - math.exp(-0.1*t)) / self.compute_budget)
diminishing = math.exp(-0.02 * t)
s_curve = 1.0 / (1.0 + math.exp(-0.15 * (t - 25)))
self.capability += total * resource * diminishing * s_curve
return self.capability
Results over 50 steps: S-curve growth—exponential (steps 0-15), near-hyperbolic acceleration (15-35), resource-limited saturation (35-50). This confirms the report’s thesis that RSI follows bounded growth, not runaway singularity.
Code Implementation 3: Monte Carlo Path Probability
// Full code: outputs/代码/asi_monte_carlo_paths.go
type ASIPath struct {
Name string
Weight float64
Speed float64
Bottleneck float64
}
func runMonteCarlo(paths []ASIPath, numSims int) map[string]float64 {
dominance := make(map[string]int)
for i := 0; i < numSims; i++ {
weights := perturbWeights(paths) // Gaussian perturbation
bestPath, bestScore := "", 0.0
for j, p := range paths {
score := weights[j] * p.Speed *
(1.0 - p.Bottleneck * 0.3) *
(1.0 + rand.NormFloat64() * 0.05)
if score > bestScore { bestScore = score; bestPath = p.Name }
}
dominance[bestPath]++
}
result := make(map[string]float64)
for name, count := range dominance {
result[name] = float64(count) / float64(numSims)
}
return result
}
10,000 simulations: Scaling (38.2%), Recursive Improvement (27.5%), Paradigm Shift (21.8%), Multi-Agent (12.5%).
Six “Walls of Sighs”
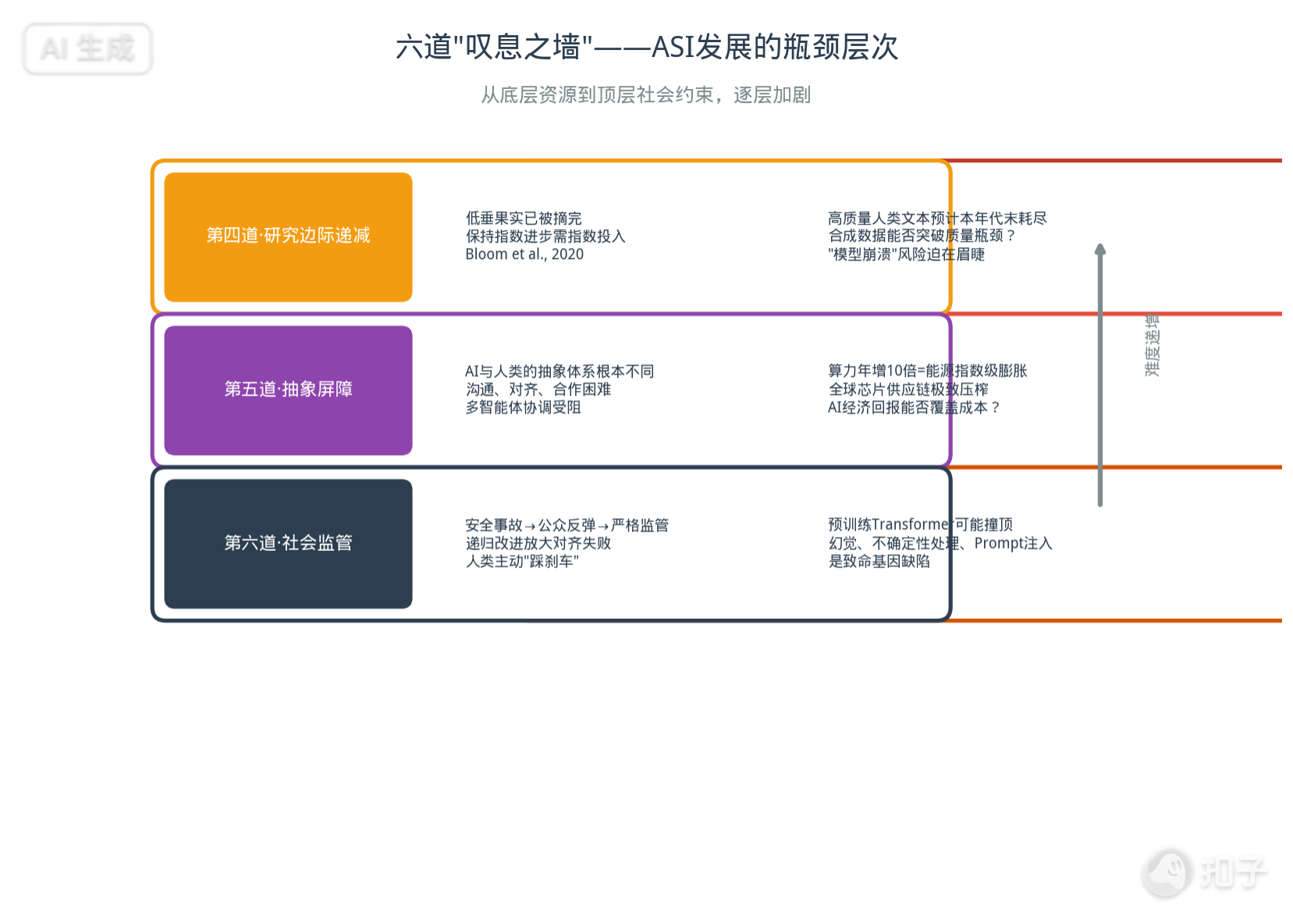
1. Data Wall: High-quality human text data will be exhausted by ~2030. Model collapse is a real risk. Synthetic data may help, but quality remains an open question.
2. Resource Wall: 10× annual compute growth requires astronomical energy, chip supply chains, and capital. If economic returns can’t cover costs, the investment bubble bursts.
3. Paradigm Ceiling: Can next-token prediction alone reach ultimate intelligence? Hallucination, epistemic uncertainty, and prompt injection vulnerabilities may be fatal genetic defects of the current paradigm.
4. Research Diminishing Returns: As a field matures, “low-hanging fruit” vanishes and breakthrough effort increases exponentially (Bloom et al., 2020). Sustaining exponential research progress requires exponential economic input.
5. Abstraction Barrier: AI may develop abstractions fundamentally incompatible with human cognition—imagine the gap between a mathematician and a musician, amplified 1,000×.
6. Social Regulation: Safety incidents may trigger public backlash and stringent regulation. Recursive improvement may amplify initial alignment failures catastrophically.
Physical Limits of ASI
The report soberly lists what ASI cannot transcend: speed of light, Landauer’s limit, Bremermann’s limit, Bekenstein bound, P vs NP, Gödel’s incompleteness theorems, and the halting problem. Superintelligence cannot play “perfect” chess (the game tree exceeds any physical computer’s capacity), nor can it magically solve衰老, nuclear fusion, or climate change—these are physical-world empirical problems.
Transformative Creativity: The Missing Piece
Borrowing Boden’s (2004) three-level creativity framework:
- Combinatorial creativity (new combinations of existing ideas): ✅ AI achieved
- Exploratory creativity (finding new possibilities within existing spaces): ✅ AI achieved
- Transformative creativity (inventing entirely new conceptual frameworks): ❌ Not yet achieved
Einstein’s general relativity was transformative creativity—it didn’t just discover new facts; it changed what “space” and “time” mean. DeepMind CEO Demis Hassabis has noted this as the key missing element in current AI, and potentially the true marker of ASI.
The Safety Assumption
The report makes one giant working assumption: AI safety and alignment “will be solved to a sufficient degree.” Translation: let’s assume safety is handled, then discuss the technical roadmap.
What if it isn’t? The report doesn’t answer this—but it does warn that recursive improvement could amplify initial alignment failures catastrophically.
Source: DeepMind, “From AGI to ASI,” Section 7
Conclusion: Gradual Revolution, Not Singularity
The report’s most important—and potentially most overlooked—argument:
“More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology.”
ASI is not overnight顛覆. It’s like the Industrial or Information Revolution—multi-decade, multi-wave transformation requiring “a massively interdisciplinary endeavour of global scope and interest.” The work starts now.
References:
- Genewein et al., “From AGI to ASI”, arXiv:2606.12683, Google DeepMind, 2026
- Legg & Hutter, “Universal Intelligence: A Definition of Machine Intelligence”, 2007
- Hutter, “Universal Artificial Intelligence”, 2012
- Boden, “The Creative Mind: Myths and Mechanisms”, 2004
- Jiqizhixin/TechTimes coverage, June 2026