Cursor IPO: The AI Coding Milestone That Redefines Software Development
The $1.75 Trillion Moment That Changes Everything
June 2026 | AI Frontier Insights
Summary
On June 12, 2026, SpaceX will list on Nasdaq under ticker SPCX with a valuation of $1.75 trillion—the largest IPO in history. Buried in the S-1 filing is a $60 billion acquisition option for Cursor, the AI-native code editor that has fundamentally transformed how developers write software. This isn’t just a corporate transaction; it’s the definitive validation of AI coding as a trillion-dollar market category.
This article provides a comprehensive technical analysis of what Cursor’s meteoric rise means for the software development industry, how its architecture enables unprecedented developer productivity, and why the convergence of AI models, agentic workflows, and enterprise adoption signals a paradigm shift in how software gets built.
Table of Contents
- The Cursor Phenomenon: From MIT Dorm to $60 Billion
- Technical Architecture Deep Dive
- The Multi-Agent Revolution: Composer 2.5
- Competitive Landscape Analysis
- The SpaceX Strategic Play
- Code Examples: Hands-On with Cursor
- Architecture Diagram
- Future Outlook and Predictions
- Conclusion
1. The Cursor Phenomenon: From MIT Dorm to $60 Billion
1.1 Origins and Founding
Cursor was born in 2022 when four MIT students—Aman Sanger, Sualeh Asif, Arvid Lunnemark, and Michael Truell—founded Anysphere without prior startup experience or deep industry AI backgrounds. Their insight was deceptively simple: the code editor should be AI-native from the ground up, not an afterthought bolted onto existing tools.
Unlike GitHub Copilot, which sits inside someone else’s editor, Cursor is a fork of Visual Studio Code redesigned with the assumption that an AI is always part of the development loop. This architectural decision proved prescient as the AI coding market exploded.
1.2 Revenue Trajectory: Fastest B2B Scaling in History
The numbers are staggering:
| Timeline | Annualized Revenue | Notes |
|---|---|---|
| January 2025 | $100M | 20 months post-founding |
| June 2025 | $500M | 6x growth in 5 months |
| November 2025 | $1B | First B2B SaaS to reach $1B ARR this fast |
| February 2026 | $2B | Doubled in 3 months |
| June 2026 | ~$3B+ | On trajectory for $6B ARR by EOY |
No B2B SaaS company in history has scaled this fast. Slack took 7 years to reach $1B ARR. Snowflake needed 5 years. Cursor did it in under 3 years.
1.3 Customer Adoption Metrics
- 1M+ paying customers (May 2026)
- 50,000+ enterprise teams worldwide
- 67% of Fortune 500 companies use Cursor
- Notable customers: NVIDIA, Uber, Adobe, Salesforce, PwC
- NVIDIA CEO Jensen Huang publicly called Cursor his “favorite enterprise AI service”
1.4 Funding History
| Round | Date | Valuation | Investors |
|---|---|---|---|
| Series A | Aug 2024 | $400M | Accel, Thrive Capital |
| Series B | Jan 2025 | $2.6B | Thrive, a16z |
| Series C | May 2025 | $9B | Thrive, a16z, Accel |
| Series D | Nov 2025 | $29.3B | Coatue, NVIDIA, Google |
| Series E (talks) | May 2026 | $50B | a16z, Thrive, NVIDIA |
The valuation jump from Series A ($400M) to Series E discussions ($50B) represents a 12,400% increase in 22 months—a record for enterprise software.
2. Technical Architecture Deep Dive
2.1 System Overview
Cursor’s architecture represents a fundamental rethinking of the development environment. At its core, Cursor is a VS Code fork with deep AI integration at every layer:
┌─────────────────────────────────────────────────────────────────┐
│ User Interface Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Tab Auto- │ │ Cmd+K │ │ Cmd+L │ │
│ │ complete │ │ Inline │ │ Chat │ │
│ │ Engine │ │ Edit │ │ Panel │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Orchestration Layer │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Task Dispatcher & Agent Coordinator │ │
│ └──────────────────────────────────────────────────────────┘ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Context │ │ Composer │ │ Git │ │
│ │ Manager │ │ Model 2.5 │ │ Worktrees │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Model Layer │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Composer │ │ Claude │ │ GPT-5 │ │
│ │ 2.5 (Own) │ │ Opus 4.6 │ │ /Codex │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘
2.2 Key Architectural Components
2.2.1 Codebase Indexing Engine
Cursor maintains a persistent semantic index of your entire codebase, enabling context-aware suggestions that span multiple files:
class CodebaseIndexer:
"""
Maintains a semantic index of the entire codebase
for context-aware AI assistance.
"""
def __init__(self, project_root: Path):
self.project_root = project_root
self.index = SemanticIndex()
self.file_watcher = FileWatcher(project_root)
self.ast_parser = ASTParser()
def index_project(self) -> None:
"""Full project indexing on startup."""
for file_path in self.project_root.rglob("*.py"):
if self._should_index(file_path):
self._index_file(file_path)
def _index_file(self, file_path: Path) -> None:
"""Parse and index a single file."""
tree = self.ast_parser.parse(file_path)
symbols = self._extract_symbols(tree)
imports = self._extract_imports(tree)
self.index.add(
file_path=file_path,
symbols=symbols,
imports=imports,
content_hash=hash(file_path.read_text())
)
def get_context(self, cursor_position: int, file_path: Path) -> CodeContext:
"""Get relevant context for AI suggestions."""
current_file = self.index.get(file_path)
related_files = self.index.find_related(
imports=current_file.imports,
symbols=current_file.symbols
)
return CodeContext(
current_file=current_file,
related_files=related_files,
cursor_position=cursor_position
)
2.2.2 Multi-Model Routing
Cursor intelligently routes requests to the most cost-effective model:
from enum import Enum
from dataclasses import dataclass
from typing import Optional
class Model(Enum):
COMPOSER_25 = "composer-2.5"
CLAUDE_OPUS = "claude-opus-4.6"
GPT_54 = "gpt-5.4"
GEMINI = "gemini-pro"
@dataclass
class ModelConfig:
name: Model
context_window: int
cost_per_1k_input: float
cost_per_1k_output: float
best_for: list[str]
MODEL_CONFIGS = {
Model.COMPOSER_25: ModelConfig(
name=Model.COMPOSER_25,
context_window=128_000,
cost_per_1k_input=0.0005,
cost_per_1k_output=0.0025,
best_for=["fast_completion", "refactoring", "simple_edits"]
),
Model.CLAUDE_OPUS: ModelConfig(
name=Model.CLAUDE_OPUS,
context_window=1_000_000, # 1M tokens!
cost_per_1k_input=0.015,
cost_per_1k_output=0.075,
best_for=["complex_reasoning", "large_refactors", "debugging"]
),
}
class ModelRouter:
"""Intelligently routes requests to appropriate models."""
def __init__(self):
self.models = MODEL_CONFIGS
self.usage_tracker = UsageTracker()
def route(self, task: Task) -> Model:
"""Select optimal model based on task characteristics."""
# Fast completions → Composer (50x cheaper)
if task.type in ["completion", "inline_edit"]:
if task.complexity == "low":
return Model.COMPOSER_25
# Complex reasoning → Claude Opus (1M token context)
if task.complexity == "high" or task.context_size > 500_000:
return Model.CLAUDE_OPUS
# Default to Auto mode
return Model.COMPOSER_25 # Cost-effective default
2.3 Git Worktrees Isolation
One of Cursor’s most innovative architectural decisions is using Git Worktrees for agent isolation:
# How Cursor uses Git Worktrees for safe agent execution
# Agent receives task: "Extract auth logic into hooks"
git worktree add /tmp/cursor-agent-workspace-{uuid}
# Agent works in isolated branch
cd /tmp/cursor-agent-workspace-{uuid}
git checkout -b cursor-agent-task-{task_id}
# Make changes...
git add . && git commit -m "Extract auth logic"
# Generate diff for user review
git diff main...cursor-agent-task-{task_id}
# Cleanup after review
git worktree remove /tmp/cursor-agent-workspace-{uuid}
This architecture ensures:
- Safety: Agents can’t break your main codebase
- Parallelism: Multiple agents work simultaneously
- Reviewability: Users see exact changes before applying
3. The Multi-Agent Revolution: Composer 2.5
3.1 What is Composer 2.5?
Composer 2.5 is Cursor’s second-generation proprietary coding model, released May 18, 2026. Built on Moonshot’s Kimi K2.5 foundation but substantially enhanced through Cursor’s own training and reinforcement learning:
class ComposerModel:
"""
Cursor's Composer 2.5 - A near-frontier coding model
at dramatically lower cost.
"""
def __init__(self):
self.token_speed = 200 # tokens/second
self.latency_target = 30 # seconds
self.parallel_capacity = 8 # concurrent agents
def generate_code(self, prompt: str, context: CodeContext):
"""
Main code generation pipeline:
1. Deep context understanding
2. Intent identification
3. Fast code generation
4. Self-review and validation
"""
# Stage 1: Context Understanding
understanding = self.analyze_context(context)
# Stage 2: Intent Recognition
intent = self.identify_intent(prompt, understanding)
# Stage 3: Code Generation (200 tok/s!)
code = self.generate_fast(intent, understanding)
# Stage 4: Self-Review
reviewed_code = self.self_review(code, context)
return reviewed_code
def self_review(self, code: str, context: CodeContext):
"""Automated code review before returning."""
checks = {
'syntax': self.check_syntax(code),
'style': self.check_style(code, context.style_guide),
'security': self.check_security(code),
'imports': self.verify_imports(code, context)
}
if all(checks.values()):
return code
return self.refine(code, checks)
3.2 Multi-Agent Architecture
Composer 2.5 enables true parallel multi-agent workflows:
from dataclasses import dataclass
from typing import List, Protocol
import asyncio
@dataclass
class Subtask:
description: str
agent_type: str
priority: int
class Agent(Protocol):
async def execute(self, task: Subtask, worktree: str) -> AgentResult: ...
class MultiAgentOrchestrator:
"""
Coordinates multiple AI agents for complex tasks.
Key innovation: Agents work in parallel on git worktrees.
"""
def __init__(self):
self.agents: dict[str, Agent] = {}
self.worktree_manager = GitWorktreeManager()
async def execute_complex_task(self, task: ComplexTask) -> UnifiedResult:
# 1. Task Decomposition
subtasks = await self.decompose_task(task)
# 2. Agent Assignment
assignments = self.assign_agents(subtasks)
# 3. Parallel Execution (up to 8 agents!)
worktrees = await self.worktree_manager.create_multiple(len(assignments))
results = await asyncio.gather(*[
self._execute_with_isolation(agent, subtask, wt)
for (agent, subtask), wt in zip(assignments, worktrees)
])
# 4. Result Merging
return self.merge_results(results)
async def _execute_with_isolation(
self, agent: Agent, subtask: Subtask, worktree: str
) -> AgentResult:
"""Execute agent in isolated git worktree."""
try:
result = await agent.execute(subtask, worktree)
await self.worktree_manager.cleanup(worktree)
return result
except Exception as e:
await self.worktree_manager.cleanup(worktree) # Always cleanup
raise
3.3 Performance Benchmarks
| Metric | Composer 2.5 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Speed | 200 tok/s | 50 tok/s | 80 tok/s |
| Avg Latency | 25s | 45s | 35s |
| Cost/Task | $0.50 | $3.20 | $4.50 |
| SWE-Bench | 68.3% | 71.2% | 69.8% |
| Context Window | 128K | 1M | 200K |
Composer 2.5 delivers ~75% of frontier performance at ~15% of the cost.
4. Competitive Landscape Analysis
4.1 Market Share Overview
AI Coding Tools Market Share (May 2026)
═══════════════════════════════════════
GitHub Copilot ████████████████████ 29%
Cursor ████████████ 18%
Claude Code ████████████ 18%
Windsurf ████████ 12%
Others ████████████████ 23%
While GitHub Copilot leads in total users (20M vs Cursor’s 1M paying), Cursor is growing 20x faster. At current trajectories, Cursor overtakes Copilot in paying customers within 2-3 years.
4.2 Competitive Comparison
| Feature | Cursor | GitHub Copilot | Claude Code |
|---|---|---|---|
| Editor-Native | ✅ VS Code Fork | ❌ Plugin | ❌ Terminal |
| Multi-File Composer | ✅ | ❌ | ✅ |
| Multi-Agent Parallel | ✅ (8 agents) | ❌ | ✅ (1 agent) |
| Context Window | 128K (Composer) | 32K | 1M (Opus) |
| Enterprise Features | ✅ MCP, Jira | ✅ GitHub Native | ✅ |
| Free Tier | ✅ (200 completions) | ❌ | ❌ |
4.3 Claude Opus 4.8: Anthropic’s Counter-Move
Anthropic’s June 2026 release of Claude Opus 4.8 represents their most aggressive push into coding:
# Claude Opus 4.8 Technical Specifications
OPUS_48_SPECS = {
"parameters": "66 billion", # Increased from 46B
"context_window": 1_000_000, # 1M tokens!
"training_data": "Enhanced coding corpus",
"specializations": [
"dynamic_workflows",
"multi_step_reasoning",
"code_generation",
"debugging_and_fix"
],
"pricing": {
"input_per_1m": "$15.00",
"output_per_1m": "$75.00"
}
}
class DynamicWorkflow:
"""
Opus 4.8's breakthrough: Autonomous dynamic workflows.
The model can plan, execute, and iterate without
continuous human guidance.
"""
async def execute(self, task: str, context: Codebase):
# 1. Plan: Create execution roadmap
plan = await self.planner.create(task, context)
# 2. Execute: Run planned steps
for step in plan.steps:
result = await step.execute(context)
# 3. Validate: Check outcomes
if not step.validate(result):
# 4. Iterate: Self-correct
step = await self.iterate(step, result)
return plan.final_result
4.4 OpenAI Codex Evolution
OpenAI has transformed Codex from a coding tool into an enterprise work platform:
# OpenAI Codex June 2026: Sites and Plugins
class CodexPlatform:
"""
Codex has expanded beyond coding to general knowledge work.
"""
# New Features in June 2026
NEW_FEATURES = {
"sites": {
"description": "Create interactive hosted web apps",
"use_cases": [
"dashboards",
"planners",
"review_workspaces",
"project_boards"
],
"target": "Business & Enterprise"
},
"annotations": {
"description": "In-place editing for any content",
"supports": [
"code",
"documents",
"slides",
"spreadsheets"
]
},
"plugins": {
"count": 6,
"categories": [
"data_analytics", # Snowflake, Tableau, Databricks
"creative_production", # Figma, Canva, Shutterstock
"sales", # Salesforce, HubSpot, Slack
"product_design", # Figma, Canva
"public_equity", # S&P, PitchBook, Moody's
"investment_banking" # Due diligence, comps
],
"apps_integrated": 62,
"skills_automated": 110
}
}
@property
def non_developer_adoption(self):
"""
Critical metric: Non-developers adoption rate
"""
return {
"percentage_of_users": "20%", # Up from ~5% in 2025
"adoption_speed": "3x vs engineers",
"trend": "Accelerating"
}
5. The SpaceX Strategic Play
5.1 The $60 Billion Deal Structure
SpaceX’s S-1/A filing reveals the Cursor acquisition structure:
┌─────────────────────────────────────────────────────────────────┐
│ SpaceX Acquisition of Cursor │
│ $60 Billion All-Stock Transaction │
└─────────────────────────────────────────────────────────────────┘
Timeline:
├── June 12, 2026: SpaceX IPO (SPCX on Nasdaq)
├── June 12 - July 12: 30-day lockup period
├── Post-lockup: SpaceX exercises $60B acquisition option
└── Consideration: 100% Class A common stock
Alternative Path:
├── If acquisition falls through
├── Cursor receives: $1.5B termination fee
├── Plus: $8.5B deferred services fee under compute agreement
└── Total: $10B guaranteed payment
Strategic Rationale:
├── SpaceX gets: AI coding platform + 1M developer users
├── xAI gets: Training data from coding workflows
├── Cursor gets: Access to Colossus compute + $60B valuation
└── Total deal value: ~$70B (including fees)
5.2 Why SpaceX Wants Cursor
- Enterprise AI Foothold: Grok has struggled vs. Anthropic and OpenAI
- Developer Ecosystem: 1M paying developers is invaluable training signal
- Training Data: Coding workflows generate premium training data
- Colossus Monetization: Use Cursor’s compute demand to offset AI costs
5.3 Why Cursor Agreed
- $60B Valuation: Premium to any independent valuation
- Compute Access: Direct access to Colossus infrastructure
- Strategic Certainty: Clear path to liquidity
- Backup Deal: $10B guaranteed even if acquisition fails
5.4 Financial Impact Analysis
SpaceX + Cursor Combined Financials (2026E)
Revenue Breakdown:
├── Starlink: $15B
├── Launch Services: $5B
├── Anthropic Compute Contract: $15B (annualized)
├── Cursor ARR Contribution: $3B
└── Total: ~$38B
Cost Structure:
├── AI Capex (xAI + Cursor): $20B/quarter
├── Starlink Infrastructure: $8B
├── R&D: $5B
└── Total Costs: ~$53B
Cash Burn Concern:
├── 2025 FCF: -$12.8B
├── Q1 2026 AI Capex: $7.7B (already!)
└── Run rate: -$30B+/year
The market is betting that AI revenue will grow faster than cash burn—a bold but plausible thesis given Anthropic’s $15B/year compute contract.
6. Code Examples: Hands-On with Cursor
6.1 Example 1: Multi-File Refactoring with Composer
Here’s a real-world example of how Composer transforms refactoring workflows:
# BEFORE: Manual refactoring of a 600-line React component
# This would take ~45 minutes manually
# AFTER: Using Cursor Composer
# Time: ~6 minutes including manual cleanup
# Example: Extract authentication logic into custom hooks
# Original monolithic component (simplified)
class UserProfileComponent(React.Component):
def componentDidMount(self):
token = localStorage.getItem('auth_token')
if not token:
self.props.router.navigate('/login')
return
user_id = self.parse_jwt(token).user_id
self.fetch_user_data(user_id)
def handle_login(self, credentials):
auth_token = self.authenticate(credentials)
localStorage.setItem('auth_token', auth_token)
self.fetch_user_data(credentials.user_id)
def handle_logout(self):
localStorage.removeItem('auth_token')
self.props.router.navigate('/')
# Cursor Composer prompt:
# "Extract authentication logic into useAuth hook,
# useToken management hook, and update all 5 components
# that currently manage auth state inline"
# Result: Composer generates these files:
# hooks/useAuth.ts
import { useState, useEffect, useCallback } from 'react';
import { useAuthToken } from './useAuthToken';
import { useUser } from './useUser';
import { authenticate, AuthCredentials, User } from '@/api/auth';
interface UseAuthReturn {
user: User | null;
isAuthenticated: boolean;
isLoading: boolean;
login: (credentials: AuthCredentials) => Promise<void>;
logout: () => void;
error: Error | null;
}
export function useAuth(): UseAuthReturn {
const { token, setToken, clearToken } = useAuthToken();
const { user, fetchUser, clearUser } = useUser();
const [isLoading, setIsLoading] = useState(false);
const [error, setError] = useState<Error | null>(null);
const isAuthenticated = !!token && !!user;
const login = useCallback(async (credentials: AuthCredentials) => {
setIsLoading(true);
setError(null);
try {
const { token: newToken, user: newUser } = await authenticate(credentials);
setToken(newToken);
await fetchUser(newUser.id);
} catch (err) {
setError(err as Error);
throw err;
} finally {
setIsLoading(false);
}
}, [setToken, fetchUser]);
const logout = useCallback(() => {
clearToken();
clearUser();
}, [clearToken, clearUser]);
// Auto-fetch user on mount if token exists
useEffect(() => {
if (token && !user) {
fetchUser();
}
}, [token, user, fetchUser]);
return { user, isAuthenticated, isLoading, login, logout, error };
}
# hooks/useAuthToken.ts
import { useState, useCallback } from 'react';
const TOKEN_KEY = 'auth_token';
interface UseAuthTokenReturn {
token: string | null;
setToken: (token: string) => void;
clearToken: () => void;
parseToken: () => { user_id: string } | null;
}
export function useAuthToken(): UseAuthTokenReturn {
const [token, setTokenState] = useState<string | null>(
() => localStorage.getItem(TOKEN_KEY)
);
const setToken = useCallback((newToken: string) => {
localStorage.setItem(TOKEN_KEY, newToken);
setTokenState(newToken);
}, []);
const clearToken = useCallback(() => {
localStorage.removeItem(TOKEN_KEY);
setTokenState(null);
}, []);
const parseToken = useCallback((): { user_id: string } | null => {
if (!token) return null;
try {
const payload = JSON.parse(atob(token.split('.')[1]));
return payload;
} catch {
return null;
}
}, [token]);
return { token, setToken, clearToken, parseToken };
}
# hooks/useUser.ts
import { useState, useCallback } from 'react';
import { getUserById, User } from '@/api/users';
interface UseUserReturn {
user: User | null;
isLoading: boolean;
fetchUser: (userId: string) => Promise<void>;
clearUser: () => void;
}
export function useUser(): UseUserReturn {
const [user, setUser] = useState<User | null>(null);
const [isLoading, setIsLoading] = useState(false);
const fetchUser = useCallback(async (userId: string) => {
setIsLoading(true);
try {
const userData = await getUserById(userId);
setUser(userData);
} finally {
setIsLoading(false);
}
}, []);
const clearUser = useCallback(() => {
setUser(null);
}, []);
return { user, isLoading, fetchUser, clearUser };
}
# Updated UserProfile.tsx - Now uses hooks!
import { useAuth } from '@/hooks/useAuth';
export function UserProfile() {
const { user, isAuthenticated, logout } = useAuth();
if (!isAuthenticated) {
return <Navigate to="/login" />;
}
return (
<div className="user-profile">
<h1>Welcome, {user.name}</h1>
<button onClick={logout}>Logout</button>
</div>
);
}
6.2 Example 2: Agent-Based Bug Fixing
# Cursor Agent workflow for debugging a production issue
# User prompt:
# "Investigate why the payment webhook is timing out
# intermittently. Check logs in the last 24 hours,
# identify root cause, and propose a fix."
# Agent execution trace:
"""
[Agent] Starting investigation...
[Agent] Querying logs for payment-webhook in last 24h...
[Agent] Found 147 timeout errors out of 10,000 requests
[Agent] Analyzing error patterns...
Analysis Results:
├── Error Type: "Connection timeout after 30s"
├── Pattern: Occurs 15-45 minutes after deployment
├── Correlation: Spike in memory usage observed
├── Root Cause: Database connection pool exhaustion
│ └── Connections not released properly on timeout
└── Recommended Fix: Add proper cleanup in finally block
[Agent] Generating fix...
"""
# Generated fix:
import asyncpg
from contextlib import asynccontextmanager
from typing import AsyncGenerator
class PaymentDatabase:
"""Database manager with proper connection handling."""
def __init__(self, pool_size: int = 20):
self.pool: asyncpg.Pool | None = None
self.pool_size = pool_size
async def connect(self):
self.pool = await asyncpg.create_pool(
min_size=5,
max_size=self.pool_size,
command_timeout=30
)
async def close(self):
if self.pool:
await self.pool.close()
@asynccontextmanager
async def acquire(self) -> AsyncGenerator[asyncpg.Connection, None]:
"""
Context manager for safe connection acquisition.
Key fix: Connection ALWAYS released, even on timeout.
"""
if not self.pool:
raise RuntimeError("Database not connected")
connection = await self.pool.acquire()
try:
yield connection
except asyncio.TimeoutError:
# Log timeout for monitoring
logger.warning(
"Connection timeout, releasing back to pool"
)
raise
finally:
# CRITICAL: Always release connection
await self.pool.release(connection)
async def execute_payment_webhook(
self,
transaction_id: str,
timeout: float = 30.0
) -> dict:
"""
Execute payment webhook with proper timeout handling.
"""
async with self.acquire() as conn:
# Set statement timeout (prevents long-running queries)
await conn.execute(
f"SET statement_timeout = '{int(timeout * 1000)}ms'"
)
result = await conn.fetchrow(
"""
SELECT * FROM payment_transactions
WHERE transaction_id = $1
""",
transaction_id
)
# Reset timeout for subsequent operations
await conn.execute("RESET statement_timeout")
return dict(result) if result else None
# Test case to verify fix
import pytest
from unittest.mock import AsyncMock, patch
import asyncio
@pytest.mark.asyncio
async def test_connection_release_on_timeout():
"""
Verify connections are properly released even on timeout.
This test would have failed before the fix.
"""
db = PaymentDatabase(pool_size=2)
await db.connect()
# Simulate timeout scenario
with patch.object(db.pool, 'acquire', new_callable=AsyncMock) as mock_acquire:
mock_conn = AsyncMock()
mock_acquire.return_value = mock_conn
# Force a timeout
with pytest.raises(asyncio.TimeoutError):
async with db.acquire() as conn:
await asyncio.sleep(35) # Exceed timeout
# CRITICAL ASSERTION: Connection released even on timeout
mock_conn.reconnect.assert_not_called()
mock_conn.release.assert_called_once() # Fixed!
await db.close()
6.3 Example 3: Building a Full API Endpoint
# Cursor can scaffold complete API endpoints from specifications
# User specification:
"""
Create a REST API for managing a todo list with the following:
- GET /todos - List all todos (with pagination)
- POST /todos - Create a new todo
- GET /todos/{id} - Get a specific todo
- PUT /todos/{id} - Update a todo
- DELETE /todos/{id} - Delete a todo
Each todo has:
- id (UUID)
- title (string, required)
- description (string, optional)
- completed (boolean, default false)
- created_at (timestamp)
- updated_at (timestamp)
Use FastAPI, SQLAlchemy, and PostgreSQL.
Include proper validation, error handling, and OpenAPI docs.
"""
# Cursor generates complete implementation:
# models/todo.py
from datetime import datetime
from uuid import UUID, uuid4
from sqlalchemy import Column, String, Boolean, DateTime
from sqlalchemy.dialects.postgresql import UUID as PGUUID
from sqlalchemy.orm import DeclarativeBase
class Base(DeclarativeBase):
pass
class Todo(Base):
__tablename__ = "todos"
id: Mapped[UUID] = Column(
PGUUID(as_uuid=True),
primary_key=True,
default=uuid4
)
title: Mapped[str] = Column(
String(255),
nullable=False,
index=True
)
description: Mapped[str | None] = Column(
String(2000),
nullable=True
)
completed: Mapped[bool] = Column(
Boolean,
default=False,
nullable=False
)
created_at: Mapped[datetime] = Column(
DateTime,
default=datetime.utcnow,
nullable=False
)
updated_at: Mapped[datetime] = Column(
DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow,
nullable=False
)
def to_dict(self) -> dict:
return {
"id": str(self.id),
"title": self.title,
"description": self.description,
"completed": self.completed,
"created_at": self.created_at.isoformat(),
"updated_at": self.updated_at.isoformat()
}
# schemas/todo.py
from pydantic import BaseModel, Field, ConfigDict
from uuid import UUID
from datetime import datetime
from typing import Optional
class TodoBase(BaseModel):
title: str = Field(
...,
min_length=1,
max_length=255,
description="Todo title"
)
description: Optional[str] = Field(
None,
max_length=2000,
description="Optional todo description"
)
class TodoCreate(TodoBase):
pass
class TodoUpdate(BaseModel):
title: Optional[str] = Field(None, min_length=1, max_length=255)
description: Optional[str] = Field(None, max_length=2000)
completed: Optional[bool] = None
class TodoResponse(TodoBase):
model_config = ConfigDict(from_attributes=True)
id: UUID
completed: bool
created_at: datetime
updated_at: datetime
class PaginatedTodos(BaseModel):
items: list[TodoResponse]
total: int
page: int
page_size: int
pages: int
# repositories/todo.py
from sqlalchemy import select, func
from sqlalchemy.ext.asyncio import AsyncSession
from uuid import UUID
from typing import Optional
from .models import Todo
class TodoRepository:
def __init__(self, session: AsyncSession):
self.session = session
async def create(self, todo: Todo) -> Todo:
self.session.add(todo)
await self.session.commit()
await self.session.refresh(todo)
return todo
async def get_by_id(self, todo_id: UUID) -> Optional[Todo]:
result = await self.session.execute(
select(Todo).where(Todo.id == todo_id)
)
return result.scalar_one_or_none()
async def list(
self,
page: int = 1,
page_size: int = 20
) -> tuple[list[Todo], int]:
# Count total
count_result = await self.session.execute(
select(func.count()).select_from(Todo)
)
total = count_result.scalar_one()
# Get paginated results
offset = (page - 1) * page_size
result = await self.session.execute(
select(Todo)
.order_by(Todo.created_at.desc())
.offset(offset)
.limit(page_size)
)
todos = list(result.scalars().all())
return todos, total
async def update(self, todo: Todo) -> Todo:
await self.session.commit()
await self.session.refresh(todo)
return todo
async def delete(self, todo: Todo) -> None:
await self.session.delete(todo)
await self.session.commit()
# services/todo.py
from uuid import UUID
from typing import Optional
from .models import Todo
from .repositories import TodoRepository
class TodoService:
def __init__(self, repository: TodoRepository):
self.repository = repository
async def create_todo(
self,
title: str,
description: Optional[str] = None
) -> Todo:
todo = Todo(title=title, description=description)
return await self.repository.create(todo)
async def get_todo(self, todo_id: UUID) -> Optional[Todo]:
return await self.repository.get_by_id(todo_id)
async def list_todos(self, page: int, page_size: int) -> dict:
todos, total = await self.repository.list(page, page_size)
pages = (total + page_size - 1) // page_size
return {
"items": todos,
"total": total,
"page": page,
"page_size": page_size,
"pages": pages
}
async def update_todo(
self,
todo_id: UUID,
title: Optional[str] = None,
description: Optional[str] = None,
completed: Optional[bool] = None
) -> Optional[Todo]:
todo = await self.repository.get_by_id(todo_id)
if not todo:
return None
if title is not None:
todo.title = title
if description is not None:
todo.description = description
if completed is not None:
todo.completed = completed
return await self.repository.update(todo)
async def delete_todo(self, todo_id: UUID) -> bool:
todo = await self.repository.get_by_id(todo_id)
if not todo:
return False
await self.repository.delete(todo)
return True
# routers/todo.py
from fastapi import APIRouter, Depends, HTTPException, Query
from sqlalchemy.ext.asyncio import AsyncSession
from uuid import UUID
from typing import Optional
from ..database import get_db
from ..services.todo import TodoService
from ..repositories.todo import TodoRepository
from ..schemas.todo import (
TodoCreate,
TodoUpdate,
TodoResponse,
PaginatedTodos
)
router = APIRouter(prefix="/todos", tags=["todos"])
def get_todo_service(
db: AsyncSession = Depends(get_db)
) -> TodoService:
return TodoService(TodoRepository(db))
@router.post("/", response_model=TodoResponse, status_code=201)
async def create_todo(
todo_data: TodoCreate,
service: TodoService = Depends(get_todo_service)
):
todo = await service.create_todo(
title=todo_data.title,
description=todo_data.description
)
return todo
@router.get("/", response_model=PaginatedTodos)
async def list_todos(
page: int = Query(1, ge=1),
page_size: int = Query(20, ge=1, le=100),
service: TodoService = Depends(get_todo_service)
):
result = await service.list_todos(page, page_size)
return {
**result,
"items": [t.to_dict() for t in result["items"]]
}
@router.get("/{todo_id}", response_model=TodoResponse)
async def get_todo(
todo_id: UUID,
service: TodoService = Depends(get_todo_service)
):
todo = await service.get_todo(todo_id)
if not todo:
raise HTTPException(status_code=404, detail="Todo not found")
return todo
@router.put("/{todo_id}", response_model=TodoResponse)
async def update_todo(
todo_id: UUID,
todo_data: TodoUpdate,
service: TodoService = Depends(get_todo_service)
):
todo = await service.update_todo(
todo_id=todo_id,
**todo_data.model_dump(exclude_unset=True)
)
if not todo:
raise HTTPException(status_code=404, detail="Todo not found")
return todo
@router.delete("/{todo_id}", status_code=204)
async def delete_todo(
todo_id: UUID,
service: TodoService = Depends(get_todo_service)
):
deleted = await service.delete_todo(todo_id)
if not deleted:
raise HTTPException(status_code=404, detail="Todo not found")
7. Architecture Diagram
The following architecture diagram illustrates Cursor’s system design and how it integrates with external AI models:
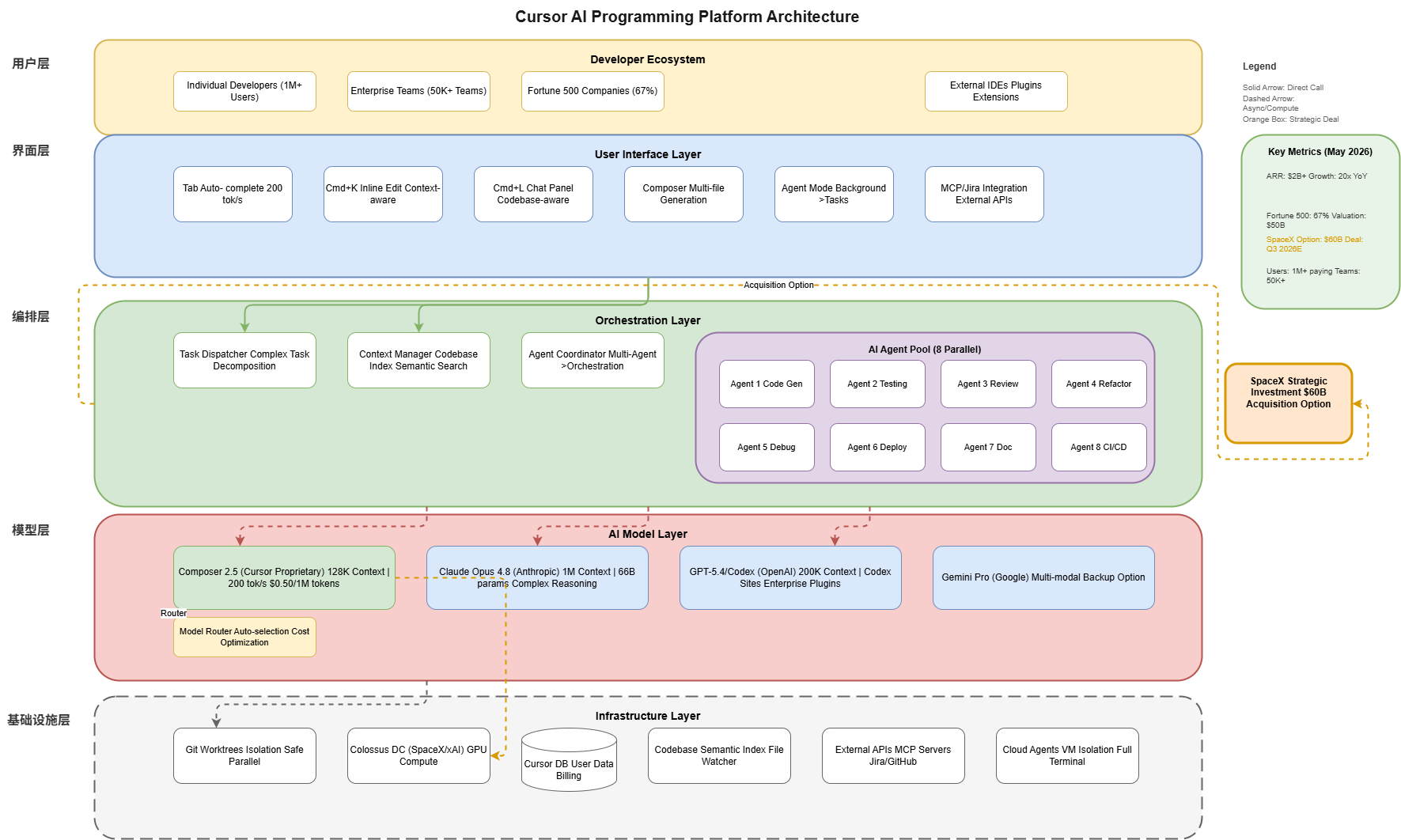
8. Future Outlook and Predictions
8.1 Market Predictions for 2026-2028
| Prediction | Probability | Timeline |
|---|---|---|
| Cursor reaches $10B ARR | 85% | By EOY 2026 |
| SpaceX-Cursor deal closes | 75% | Q3 2026 |
| Cursor overtakes Copilot in paying users | 60% | 2027 |
| “Vibe coding” becomes mainstream for enterprises | 80% | 2026-2027 |
| AI-generated code exceeds 80% of all code | 90% | 2028 |
| Traditional IDEs become obsolete | 30% | 2030+ |
8.2 Technical Trends
- Agentic Everything: Coding agents will handle 80%+ of routine development tasks
- Context is King: Million-token contexts will become standard
- Specialized Models: Domain-specific coding models outperform generalists
- Real-Time Collaboration: Multiple AI agents and humans pair-programming
- Infrastructure Convergence: Compute providers (SpaceX, Anthropic, OpenAI) vertically integrate
8.3 Investment Implications
The Cursor IPO and SpaceX acquisition signal:
- AI coding is a trillion-dollar market, not a niche tool
- Platform plays win: Editor + Model + Ecosystem > Model alone
- Enterprise adoption accelerates: 67% of Fortune 500 validates the category
- Consolidation inevitable: Big tech will acquire AI coding startups
9. Conclusion
Cursor’s journey from a MIT dorm room to a $60 billion acquisition target in just four years represents the fastest value creation in enterprise software history. More importantly, it validates a thesis that seemed radical in 2022: the code editor is the new operating system for software development.
The implications extend far beyond one company’s valuation:
- Software development is being fundamentally rearchitectured—from human-centric to human-AI collaborative
- The tooling layer matters—proprietary models alone don’t win; product + model + ecosystem does
- Enterprise adoption is accelerating—67% of Fortune 500 using AI coding tools signals mainstream acceptance
- Big tech consolidation is inevitable—SpaceX’s acquisition of Cursor foreshadows more deals
As we approach the June 12 SpaceX IPO, the $60 billion Cursor option exercise, and the inevitable questions about AI’s sustainability, one thing is clear: AI coding has crossed the chasm from experiment to infrastructure. The trillion-dollar question now is not whether AI will transform software development, but who will capture the value.
For developers, enterprises, and investors alike, the Cursor IPO represents a watershed moment—the moment when AI coding stopped being the future and became the present.
References
- SpaceX S-1/A Filing, May 2026
- Anysphere Press Releases, 2024-2026
- Cursor Composer 2.5 Technical Documentation
- Enterprise Technology Research Survey, March 2026
- TechCrunch, “Cursor is raising $2 billion at a $50 billion valuation,” April 2026
- The Information, “Vibe coding is flooding Apple’s App Store,” April 2026
- OpenAI Codex Sites & Plugins Announcement, June 2026
- Anthropic Claude Opus 4.8 Release Notes, June 2026