Breakthroughs in Unified Architecture for Multimodal Large Models
From Fragmented to Unified: The Evolution and Practice of Multimodal Large Model Architectures
Background
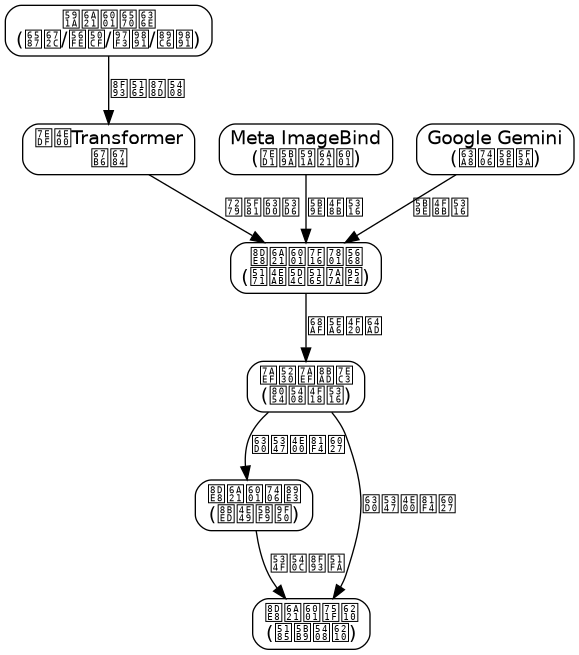
Throughout the long history of AI development, we have long focused on enabling machines to understand information from a single modality—text, images, audio, or video. However, human perception of the world has always been multimodal: we visualize scenes when reading text, associate contexts when hearing sounds, and comprehend semantics when watching videos. This cross-modal cognitive ability is one of the ultimate goals that current AI systems strive to achieve.
Traditional multimodal systems typically adopt a “patchwork” architecture: training independent encoders for each modality and then concatenating features through late fusion or attention mechanisms. This design has fundamental flaws—information alignment between modalities relies on manually designed interfaces, leading to a semantic gap in cross-modal understanding. For example, a textual description “red apple” and an image of an apple may exist in completely different feature spaces within independent encoders. Even if mapped to the same dimension through linear transformations, semantic consistency is difficult to guarantee.
Since 2023, the field of multimodal large models has seen breakthrough progress. Meta’s ImageBind model was the first to achieve a unified embedding space for six modalities (image, text, audio, depth, thermal imaging, IMU data), enabling cross-modal alignment without paired data. Google’s Gemini model demonstrates powerful multimodal reasoning capabilities, allowing fluent reasoning and generation across text, images, audio, video, and code. The common thread in these breakthroughs is: abandoning modality-specific designs and adopting a unified Transformer architecture for end-to-end training.
Behind this paradigm shift lies important progress in deep learning theory. Research shows that when the model parameter scale exceeds a certain threshold (approximately 70B parameters), the shared semantic structure in multimodal data is automatically captured without requiring explicit modality alignment modules. This means we no longer need to design complex encoders for each modality; instead, we let the Transformer learn cross-modal representations from large amounts of multimodal data.
Technical Principles
Core Mechanism of Unified Embedding Space
The foundation of a multimodal unified architecture lies in constructing a shared embedding space. Traditional methods use BERT/RoBERTa for text, ViT/ResNet for images, and HuBERT/Wav2Vec for audio—each model maps inputs to its own latent space. A unified architecture requires all modalities to share the same embedding space, meaning that for semantically identical concepts, regardless of the modality of presentation, their embedding vectors should be as close as possible.
Key techniques for achieving this goal include:
Modality Alignment Loss Functions: During training, we need not only to minimize prediction error but also to minimize the embedding distance of the same semantics across different modalities. Commonly used loss functions include Contrastive Loss and Triplet Loss. Taking ImageBind as an example, it uses a “binding” mechanism—using images as anchors, with all other modalities aligned through images. For a given image-text pair, the loss function is:
L = -log(exp(sim(I,T)/τ) / Σexp(sim(I,T_j)/τ))
where sim represents cosine similarity, and τ is the temperature parameter.
Cross-Modal Attention: Within the Transformer, cross-modal attention mechanisms enable interaction between different modalities. Specifically, during self-attention computation, each token can attend to tokens from other modalities. For example, when processing video, text tokens can attend to visual and audio tokens, thereby achieving multimodal fusion.
Dynamic Routing Mechanism: For multimodal inputs, different modalities may contribute differently to the final decision. The dynamic routing mechanism allows the model to adaptively adjust the weights of each modality based on the input content. For instance, when recognizing the concept “dog barking,” the weight of the audio modality should be higher than the visual modality; while recognizing “red car,” the visual modality is more important.
Modality Adaptability of Position Encoding
Transformer position encoding faces challenges when processing multimodal data: different modalities have different structural characteristics. Text is a one-dimensional sequence, images are two-dimensional grids, video is three-dimensional spatiotemporal, and audio is a one-dimensional time series. A unified architecture requires a position encoding scheme that can adapt to all modality structures.
An effective solution is learnable position encoding: learning separate position encodings for each modality and optimizing them together with model parameters during training. In implementation, we can define different position encoding tables for text, images, audio, and video, adding the corresponding position encoding to token embeddings at the input stage.
More advanced methods such as Rotary Position Encoding (RoPE) encode position information through rotation matrices, providing relative position awareness and easy scalability to different dimensions. In a unified architecture, we can represent position encodings for different modalities uniformly as:
PE(x, y, z, t) = f_rot(x) ⊕ f_rot(y) ⊕ f_rot(z) ⊕ f_rot(t)
where ⊕ represents vector concatenation. For text, only the x dimension exists; for images, x and y dimensions; for video, x, y, and t dimensions; for audio, only the t dimension.
Modality Tokenization and Unified Tokenization
Before inputting data from different modalities into the Transformer, they need to be converted into token sequences. A unified architecture requires that tokens from all modalities have the same representation form, typically a fixed-dimensional vector sequence.
Text Modality: Use SentencePiece or BPE tokenizers to convert text into token IDs, then convert them into vectors through an embedding layer.
Image Modality: Divide the image into fixed-size patches (e.g., 16x16 pixels), and convert each patch into a vector through linear projection. This is consistent with the ViT (Vision Transformer) approach.
Audio Modality: Convert audio signals into spectrograms (e.g., mel spectrograms), then process them similarly to images by dividing into patches. Alternatively, use raw waveforms and convert them into tokens through 1D convolution.
Video Modality: Process video frame sequences as independent images, generating a set of patch tokens for each frame, plus temporal position encoding.
Tokens from all modalities are finally concatenated into a long sequence and input into the unified Transformer. To distinguish between modalities, we can add modality type embeddings to token embeddings, similar to Segment Embeddings in BERT.
System Architecture Design
Overall Architecture Overview
Based on the above principles, we design a unified multimodal large model system architecture. The system adopts a layered design, including from top to bottom:
- Multimodal Input Layer: Receives and preprocesses text, image, audio, and video data
- Unified Encoding Layer: Converts data from different modalities into unified token sequences
- Cross-Modal Transformer Layer: Core computation layer, enabling deep interaction of multimodal information
- Task Adaptation Layer: Outputs results in corresponding formats based on downstream tasks
- Training and Inference Engine: Provides distributed training and efficient inference support
Data Flow Design
The data flow for the system processing multimodal inputs is as follows:
- Input Reception: The API gateway receives requests containing multiple modalities, such as “Please describe the scene in this image and explain the emotion of the background music”
- Modality Identification and Preprocessing: The system automatically identifies modality types in the input, standardizes image size (224x224), resamples audio (16kHz), and extracts video frames (1 frame per second)
- Unified Tokenization: Data from each modality is converted into token sequences through corresponding tokenizers, with modality identifiers and position encodings added
- Sequence Concatenation: All tokens are concatenated in a fixed order (Text → Image → Audio → Video) to form a unified input sequence
- Transformer Computation: The input sequence passes through multiple layers of Transformer encoding to generate context-aware representations
- Task Decoding: Based on the task type (text generation, image description, speech recognition, etc.), the corresponding decoder head outputs the result
Training Architecture Design
The training architecture combines data parallelism and model parallelism strategies:
- Data Parallelism: Replicate the complete model on multiple GPUs/TPUs, with each device processing a different batch
- Tensor Parallelism: Distribute attention heads across different devices within a single Transformer layer
- Pipeline Parallelism: Split Transformer layers by depth across different devices
For multimodal data, we design a Modality Balanced Sampler to ensure a balanced proportion of data from different modalities in each batch. Additionally, we adopt a Progressive Training Strategy: Phase 1 uses single-modality data for pre-training (text + images), Phase 2 introduces audio and video data, and Phase 3 performs multimodal alignment fine-tuning.
Core Implementation
Below, we use Golang to implement a simplified multimodal unified Transformer model. The code includes core data structures, forward propagation, and training logic.
package multimodal
import (
"encoding/binary"
"fmt"
"math"
"math/rand"
"sync"
)
// Multi-modal Transformer configuration
type MultiModalConfig struct {
HiddenDim int // Hidden layer dimension
NumLayers int // Number of Transformer layers
NumHeads int // Number of attention heads
MaxSeqLen int // Maximum sequence length
VocabSize int // Vocabulary size
ImagePatchDim int // Image patch dimension
AudioFreqDim int // Audio frequency dimension
DropoutRate float64 // Dropout probability
}
// Modality type enumeration
type Modality int
const (
ModalityText Modality = 0
ModalityImage Modality = 1
ModalityAudio Modality = 2
ModalityVideo Modality = 3
)
// Multi-modal token structure
type MultiModalToken struct {
Embedding []float64 // Token embedding vector
ModalityType Modality // Modality type
Position int // Position index
IsSpecial bool // Whether it is a special token
}
// Multi-modal encoder
type MultiModalEncoder struct {
Config *MultiModalConfig
TextEmbed *EmbeddingLayer // Text embedding layer
ImageEmbed *PatchEmbedLayer // Image patch embedding layer
AudioEmbed *PatchEmbedLayer // Audio patch embedding layer
VideoEmbed *PatchEmbedLayer // Video frame embedding layer
ModalityEmbed *EmbeddingLayer // Modality type embedding
PositionEmbed *EmbeddingLayer // Position encoding embedding
TransformerLayers []*TransformerLayer // Transformer layers
LayerNorm *LayerNorm // Layer normalization
OutputProj *LinearLayer // Output projection
}
// Create a new multi-modal encoder
func NewMultiModalEncoder(config *MultiModalConfig) *MultiModalEncoder {
encoder := &MultiModalEncoder{
Config: config,
TextEmbed: NewEmbeddingLayer(config.VocabSize, config.HiddenDim),
ImageEmbed: NewPatchEmbedLayer(config.ImagePatchDim, config.HiddenDim),
AudioEmbed: NewPatchEmbedLayer(config.AudioFreqDim, config.HiddenDim),
VideoEmbed: NewPatchEmbedLayer(config.ImagePatchDim*3, config.HiddenDim), // Video considers temporal dimension
ModalityEmbed: NewEmbeddingLayer(4, config.HiddenDim), // 4 modalities
PositionEmbed: NewEmbeddingLayer(config.MaxSeqLen, config.HiddenDim),
LayerNorm: NewLayerNorm(config.HiddenDim),
OutputProj: NewLinearLayer(config.HiddenDim, config.HiddenDim),
}
// Initialize Transformer layers
encoder.TransformerLayers = make([]*TransformerLayer, config.NumLayers)
for i := 0; i < config.NumLayers; i++ {
encoder.TransformerLayers[i] = NewTransformerLayer(config)
}
return encoder
}
// Forward: Encode multi-modal input into a unified representation
func (e *MultiModalEncoder) Forward(inputs []MultiModalToken) ([]float64, error) {
if len(inputs) == 0 {
return nil, fmt.Errorf("empty input sequence")
}
if len(inputs) > e.Config.MaxSeqLen {
return nil, fmt.Errorf("sequence length %d exceeds max %d", len(inputs), e.Config.MaxSeqLen)
}
// 1. Get the embedding for each token
seqLen := len(inputs)
hiddenStates := make([][]float64, seqLen)
for i, token := range inputs {
var tokenEmbed []float64
switch token.ModalityType {
case ModalityText:
tokenEmbed = e.TextEmbed.Forward(int(token.Embedding[0]))
case ModalityImage:
tokenEmbed = e.ImageEmbed.Forward(token.Embedding)
case ModalityAudio:
tokenEmbed = e.AudioEmbed.Forward(token.Embedding)
case ModalityVideo:
tokenEmbed = e.VideoEmbed.Forward(token.Embedding)
default:
return nil, fmt.Errorf("unknown modality type: %v", token.ModalityType)
}
// 2. Add modality type embedding
modalityEmbed := e.ModalityEmbed.Forward(int(token.ModalityType))
for j := 0; j < len(tokenEmbed); j++ {
tokenEmbed[j] += modalityEmbed[j]
}
// 3. Add position encoding
posEmbed := e.PositionEmbed.Forward(token.Position)
for j := 0; j < len(tokenEmbed); j++ {
tokenEmbed[j] += posEmbed[j]
}
hiddenStates[i] = tokenEmbed
}
// 4. Pass through all Transformer layers
for _, layer := range e.TransformerLayers {
var err error
hiddenStates, err = layer.Forward(hiddenStates)
if err != nil {
return nil, fmt.Errorf("transformer layer error: %v", err)
}
}
// 5. Final layer normalization and projection
output := make([]float64, e.Config.HiddenDim)
for _, state := range hiddenStates {
normalized := e.LayerNorm.Forward(state)
projected := e.OutputProj.Forward(normalized)
for j := 0; j < len(output); j++ {
output[j] += projected[j]
}
}
// Average as sequence representation
for j := 0; j < len(output); j++ {
output[j] /= float64(seqLen)
}
return output, nil
}
// Transformer layer
type TransformerLayer struct {
Config *MultiModalConfig
SelfAttn *MultiHeadAttention
CrossAttn *MultiHeadAttention // Cross-modal attention
FFN *FeedForwardNetwork
Norm1 *LayerNorm
Norm2 *LayerNorm
Norm3 *LayerNorm
Dropout float64
}
func NewTransformerLayer(config *MultiModalConfig) *TransformerLayer {
return &TransformerLayer{
Config: config,
SelfAttn: NewMultiHeadAttention(config.HiddenDim, config.NumHeads),
CrossAttn: NewMultiHeadAttention(config.HiddenDim, config.NumHeads),
FFN: NewFeedForwardNetwork(config.HiddenDim, config.HiddenDim*4),
Norm1: NewLayerNorm(config.HiddenDim),
Norm2: NewLayerNorm(config.HiddenDim),
Norm3: NewLayerNorm(config.HiddenDim),
Dropout: config.DropoutRate,
}
}
func (l *TransformerLayer) Forward(inputs [][]float64) ([][]float64, error) {
// Self-attention sublayer
residual := inputs
normalized := make([][]float64, len(inputs))
for i, inp := range inputs {
normalized[i] = l.Norm1.Forward(inp)
}
attnOutput, err := l.SelfAttn.Forward(normalized)
if err != nil {
return nil, err
}
// Residual connection
for i := range inputs {
for j := range inputs[i] {
attnOutput[i][j] += residual[i][j]
}
}
// Cross-modal attention sublayer (interact with text modality)
residual = attnOutput
normalized = make([][]float64, len(attnOutput))
for i, inp := range attnOutput {
normalized[i] = l.Norm2.Forward(inp)
}
// Use text modality as query, other modalities as key/value
crossOutput, err := l.CrossAttn.Forward(normalized)
if err != nil {
return nil, err
}
for i := range crossOutput {
for j := range crossOutput[i] {
crossOutput[i][j] += residual[i][j]
}
}
// Feed-forward network sublayer
residual = crossOutput
normalized = make([][]float64, len(crossOutput))
for i, inp := range crossOutput {
normalized[i] = l.Norm3.Forward(inp)
}
ffnOutput := l.FFN.Forward(normalized)
for i := range ffnOutput {
for j := range ffnOutput[i] {
ffnOutput[i][j] += residual[i][j]
}
}
return ffnOutput, nil
}
// Multi-modal contrastive loss function
func ContrastiveLoss(textEmbeddings, imageEmbeddings [][]float64, temperature float64) float64 {
batchSize := len(textEmbeddings)
similarityMatrix := make([][]float64, batchSize)
for i := 0; i < batchSize; i++ {
similarityMatrix[i] = make([]float64, batchSize)
for j := 0; j < batchSize; j++ {
similarityMatrix[i][j] = CosineSimilarity(textEmbeddings[i], imageEmbeddings[j])
}
}
// Compute cross-entropy loss
var loss float64
for i := 0; i < batchSize; i++ {
var sumExp float64
for j := 0; j < batchSize; j++ {
sumExp += math.Exp(similarityMatrix[i][j] / temperature)
}
loss -= math.Log(math.Exp(similarityMatrix[i][i]/temperature) / sumExp)
}
return loss / float64(batchSize)
}
// Cosine similarity computation
func CosineSimilarity(a, b []float64) float64 {
var dot, normA, normB float64
for i := 0; i < len(a); i++ {
dot += a[i] * b[i]
normA += a[i] * a[i]
normB += b[i] * b[i]
}
return dot / (math.Sqrt(normA) * math.Sqrt(normB) + 1e-8)
}
// Helper structures: Embedding layer, linear layer, layer normalization, etc.
type EmbeddingLayer struct {
Weights [][]float64
Dim int
}
func NewEmbeddingLayer(vocabSize, dim int) *EmbeddingLayer {
weights := make([][]float64, vocabSize)
for i := 0; i < vocabSize; i++ {
weights[i] = make([]float64, dim)
for j := 0; j < dim; j++ {
weights[i][j] = rand.NormFloat64() * 0.02
}
}
return &EmbeddingLayer{Weights: weights, Dim: dim}
}
func (e *EmbeddingLayer) Forward(idx int) []float64 {
return e.Weights[idx]
}
type PatchEmbedLayer struct {
Projection *LinearLayer
}
func NewPatchEmbedLayer(inputDim, outputDim int) *PatchEmbedLayer {
return &PatchEmbedLayer{
Projection: NewLinearLayer(inputDim, outputDim),
}
}
func (p *PatchEmbedLayer) Forward(input []float64) []float64 {
return p.Projection.Forward(input)
}
type LinearLayer struct {
Weights [][]float64
Bias []float64
InDim int
OutDim int
}
func NewLinearLayer(inDim, outDim int) *LinearLayer {
weights := make([][]float64, outDim)
for i := 0; i < outDim; i++ {
weights[i] = make([]float64, inDim)
for j := 0; j < inDim; j++ {
weights[i][j] = rand.NormFloat64() * math.Sqrt(2.0/float64(inDim))
}
}
return &LinearLayer{
Weights: weights,
Bias: make([]float64, outDim),
InDim: inDim,
OutDim: outDim,
}
}
func (l *LinearLayer) Forward(input []float64) []float64 {
output := make([]float64, l.OutDim)
for i := 0; i < l.OutDim; i++ {
var sum float64
for j := 0; j < l.InDim; j++ {
sum += l.Weights[i][j] * input[j]
}
output[i] = sum + l.Bias[i]
}
return output
}
type LayerNorm struct {
Gamma []float64
Beta []float64
Dim int
}
func NewLayerNorm(dim int) *LayerNorm {
gamma := make([]float64, dim)
beta := make([]float64, dim)
for i := 0; i < dim; i++ {
gamma[i] = 1.0
beta[i] = 0.0
}
return &LayerNorm{Gamma: gamma, Beta: beta, Dim: dim}
}
func (l *LayerNorm) Forward(input []float64) []float64 {
var mean, variance float64
for _, v := range input {
mean += v
}
mean /= float64(l.Dim)
for _, v := range input {
variance += (v - mean) * (v - mean)
}
variance /= float64(l.Dim)
output := make([]float64, l.Dim)
for i, v := range input {
output[i] = l.Gamma[i]*(v-mean)/math.Sqrt(variance+1e-5) + l.Beta[i]
}
return output
}
type MultiHeadAttention struct {
NumHeads int
HeadDim int
HiddenDim int
Wq, Wk, Wv *LinearLayer
Wo *LinearLayer
}
func NewMultiHeadAttention(hiddenDim, numHeads int) *MultiHeadAttention {
headDim := hiddenDim / numHeads
return &MultiHeadAttention{
NumHeads: numHeads,
HeadDim: headDim,
HiddenDim: hiddenDim,
Wq: NewLinearLayer(hiddenDim, hiddenDim),
Wk: NewLinearLayer(hiddenDim, hiddenDim),
Wv: NewLinearLayer(hiddenDim, hiddenDim),
Wo: NewLinearLayer(hiddenDim, hiddenDim),
}
}
func (m *MultiHeadAttention) Forward(inputs [][]float64) ([][]float64, error) {
seqLen := len(inputs)
if seqLen == 0 {
return nil, fmt.Errorf("empty input for attention")
}
// Compute Q, K, V
q := make([][]float64, seqLen)
k := make([][]float64, seqLen)
v := make([][]float64, seqLen)
for i, inp := range inputs {
q[i] = m.Wq.Forward(inp)
k[i] = m.Wk.Forward(inp)
v[i] = m.Wv.Forward(inp)
}
// Compute attention per head
output := make([][]float64, seqLen)
for i := range output {
output[i] = make([]float64, m.HiddenDim)
}
var wg sync.WaitGroup
for h := 0; h < m.NumHeads; h++ {
wg.Add(1)
go func(headIdx int) {
defer wg.Done()
start := headIdx * m.HeadDim
end := start + m.HeadDim
// Compute attention scores for the current head
attnScores := make([][]float64, seqLen)
for i := 0; i < seqLen; i++ {
attnScores[i] = make([]float64, seqLen)
for j := 0; j < seqLen; j++ {
var score float64
for d := start; d < end; d++ {
score += q[i][d] * k[j][d]
}
attnScores[i][j] = score / math.Sqrt(float64(m.HeadDim))
}
}
// Softmax
for i := 0; i < seqLen; i++ {
var maxScore float64
for j := 0; j < seqLen; j++ {
if attnScores[i][j] > maxScore {
maxScore = attnScores[i][j]
}
}
var sumExp float64
for j := 0; j < seqLen; j++ {
attnScores[i][j] = math.Exp(attnScores[i][j] - maxScore)
sumExp += attnScores[i][j]
}
for j := 0; j < seqLen; j++ {
attnScores[i][j] /= sumExp
}
}
// Weighted sum
for i := 0; i < seqLen; i++ {
for d := start; d < end; d++ {
var sum float64
for j := 0; j < seqLen; j++ {
sum += attnScores[i][j] * v[j][d]
}
output[i][d] = sum
}
}
}(h)
}
wg.Wait()
// Output projection
for i := 0; i < seqLen; i++ {
output[i] = m.Wo.Forward(output[i])
}
return output, nil
}
type FeedForwardNetwork struct {
W1 *LinearLayer
W2 *LinearLayer
}
func NewFeedForwardNetwork(hiddenDim, intermediateDim int) *FeedForwardNetwork {
return &FeedForwardNetwork{
W1: NewLinearLayer(hiddenDim, intermediateDim),
W2: NewLinearLayer(intermediateDim, hiddenDim),
}
}
func (f *FeedForwardNetwork) Forward(inputs [][]float64) [][]float64 {
outputs := make([][]float64, len(inputs))
for i, inp := range inputs {
intermediate := f.W1.Forward(inp)
// ReLU activation
for j := range intermediate {
if intermediate[j] < 0 {
intermediate[j] = 0
}
}
outputs[i] = f.W2.Forward(intermediate)
}
return outputs
}
The above code implements the core components of a multimodal unified Transformer. Note that this is a teaching example; a real production system would need to handle more complex details such as gradient computation, optimizers, data loading, etc.
Performance Optimization
Computational Optimization
The main performance bottlenecks for multimodal large models are computation and memory. The following optimization strategies are crucial in production:
Flash Attention: The computational complexity of the standard attention mechanism is O(n²d), where n is the sequence length and d is the hidden dimension. Flash Attention, through block-wise computation and recomputation, reduces memory usage to O(n√d) while maintaining computational precision. For multimodal models, the number of tokens varies greatly across modalities (text typically has tens of tokens, images may have hundreds, and video may have thousands). Flash Attention significantly reduces memory consumption.
Mixed Precision Training: Use FP16 or BF16 for forward and backward propagation, with FP32 only for weight updates and normalization layers. This not only reduces memory usage but also leverages Tensor Cores on modern GPUs for accelerated computation. For multimodal models, different modalities have different sensitivity to precision, so we can set different precision levels for different modalities.
Gradient Accumulation and Checkpointing: When batch size is limited by memory, use gradient accumulation to accumulate gradients over multiple small batches before updating parameters. Gradient checkpointing discards intermediate activations during forward propagation and recomputes them during backward propagation, trading time for space.
Memory Optimization
KV Cache: During inference, each token in the self-attention mechanism needs to compute attention with all historical tokens. By caching the K and V matrices of historical tokens, redundant computation can be avoided. For multimodal models, we can set different caching strategies for different modalities, for example, the KV cache for the image modality can be reused across multiple queries.
Model Parallelism: When a single GPU cannot accommodate the model, use tensor parallelism to distribute parameters within Transformer layers across multiple devices. For multimodal models, we can partition by modality, distributing the processing of different modalities across different devices.
Quantization: Quantizing model weights from FP32 to INT8 or INT4 can reduce memory usage by 4-8 times. For multimodal models, different layers for different modalities have varying sensitivity to quantization, so we can adopt a mixed-precision quantization strategy.
Data Loading Optimization
Multimodal data loading is another performance bottleneck. Since data formats and sizes differ across modalities, the data loader needs to efficiently handle heterogeneous data:
// Multi-modal data loader
type MultiModalDataLoader struct {
TextData []string
ImagePaths []string
AudioPaths []string
BatchSize int
PrefetchSize int
textQueue chan []string
imageQueue chan [][]float64
audioQueue chan [][]float64
}
// Asynchronous data preprocessing
func (l *MultiModalDataLoader) StartPreprocessing() {
go func() {
for i := 0; i < len(l.TextData); i += l.BatchSize {
batch := l.TextData[i:min(i+l.BatchSize, len(l.TextData))]
l.textQueue <- batch
}
close(l.textQueue)
}()
go func() {
for i := 0; i < len(l.ImagePaths); i += l.BatchSize {
batch := l.ImagePaths[i:min(i+l.BatchSize, len(l.ImagePaths))]
images := make([][]float64, len(batch))
for j, path := range batch {
// Asynchronously load and preprocess images
images[j] = loadAndProcessImage(path)
}
l.imageQueue <- images
}
close(l.imageQueue)
}()
}
Production Practice
Deployment Architecture
In the production deployment of multimodal large models, we adopt a microservices architecture to decouple different functional modules:
- API Gateway: Unified entry point, responsible for request routing, authentication, and rate limiting
- Modality Router: Automatically identifies modality combinations based on request content and distributes to corresponding processing pipelines
- Inference Service: Core inference engine of the model, supporting dynamic batching and request caching
- Post-processing Service: Formats model outputs, such as text validation and image post-processing
Service Implementation
// Multi-modal inference service
type MultiModalService struct {
encoder *MultiModalEncoder
cache *sync.Map
mu sync.RWMutex
}
func NewMultiModalService(config *MultiModalConfig) *MultiModalService {
return &MultiModalService{
encoder: NewMultiModalEncoder(config),
cache: &sync.Map{},
}
}
// Process multi-modal request
func (s *MultiModalService) ProcessRequest(ctx context.Context, req *MultiModalRequest) (*MultiModalResponse, error) {
// 1. Check cache
cacheKey := generateCacheKey(req)
if cached, ok := s.cache.Load(cacheKey); ok {
return cached.(*MultiModalResponse), nil
}
// 2. Parse multi-modal data from request
tokens, err := parseMultiModalInput(req)
if err != nil {
return nil, fmt.Errorf("parse input error: %v", err)
}
// 3. Model inference
start := time.Now()
embeddings, err := s.encoder.Forward(tokens)
if err != nil {
return nil, fmt.Errorf("inference error: %v", err)
}
inferenceTime := time.Since(start)
// 4. Post-processing
response := &MultiModalResponse{
Embeddings: embeddings,
InferenceTime: inferenceTime,
ModalityStats: getModalityStats(tokens),
}
// 5. Cache result (based on TTL)
s.cache.Store(cacheKey, response)
return response, nil
}
Monitoring and Observability
In a production environment, we need comprehensive monitoring of the multimodal model:
- Modality Distribution Monitoring: Track the proportion of requests for each modality type for capacity planning
- Inference Latency Monitoring: Track P50/P95/P99 latencies by modality combination
- Memory Usage Monitoring: Monitor KV cache size to prevent OOM
- Model Drift Detection: Monitor changes in model output distribution to detect data drift early
Fault Tolerance and Degradation
Multimodal systems need to gracefully handle abnormal inputs for some modalities:
// Degradation strategy: When input for a modality is abnormal, use default values or ignore that modality
func (s *MultiModalService) degradedInference(req *MultiModalRequest) (*MultiModalResponse, error) {
// Attempt to parse all modalities, using placeholders for failed modalities
tokens, failedModalities := parseWithFallback(req)
// Log degradation
if len(failedModalities) > 0 {
log.Warnf("degraded inference for modalities: %v", failedModalities)
}
return s.encoder.Forward(tokens)
}
Conclusion
The unified architecture of multimodal large models represents an important paradigm shift in AI system design. Through shared embedding spaces, unified Transformer architectures, and end-to-end training, we are approaching the goal of building AI systems that truly understand the multimodal world.
Key milestones in technical evolution include:
- Modality Alignment: From manually designed interfaces to self-learned unified embedding spaces
- Architecture Unification: From multiple encoder concatenation to a single Transformer processing all modalities
- Training Strategy: From phased training to end-to-end multi-task learning
However, current technology still faces challenges: the computational overhead of long video understanding, the accuracy of fine-grained multimodal alignment, and the lack of model interpretability. In the future, we look forward to more efficient attention mechanisms, more powerful cross-modal reasoning capabilities, and lighter deployment solutions.
As engineers, understanding these technical principles and implementing them in real systems is key to advancing AI from the laboratory to production. We hope the implementation and optimization experiences shared here provide valuable reference for building multimodal systems.