Breakthrough in Reasoning Capabilities of Large Language Models (LLMs): Chain-of-Thought and Self-Consistency
From Memory to Reasoning: How Chain-of-Thought and Self-Consistency Reshape LLM Reasoning Capabilities
Background Introduction
The Reasoning Dilemma of Large Language Models
Since the launch of ChatGPT at the end of 2022, large language models (LLMs) have demonstrated astonishing language generation capabilities. However, as application scenarios shift from simple conversations to complex reasoning tasks, a fundamental issue has gradually surfaced: Do LLMs truly possess reasoning abilities?
The traditional LLM training paradigm is based on “next word prediction,” where the model essentially learns statistical patterns from the corpus. When faced with math problems, logic puzzles, or multi-step reasoning tasks, this pattern reveals clear deficiencies. For example, for the question “Xiao Ming has 5 apples, gives 2 to Xiao Hong, then gets 3 from Xiao Li, how many does he have now?”, a standard LLM might directly output the wrong answer “6” because it merely matches the answer pattern of similar problems from training data, rather than truly understanding the calculation process.
Metrics for Reasoning Capability
The evaluation of LLM reasoning capabilities by academia and industry primarily relies on the following benchmark tests:
- Mathematical Reasoning: GSM8K (elementary school math problems), MATH (competition math problems)
- Logical Reasoning: LogiQA, BBH (Big-Bench Hard)
- Common Sense Reasoning: CSQA (CommonsenseQA), StrategyQA
- Symbolic Reasoning: Last Letter Concatenation, Coin Flip
Early models performed disappointingly on these benchmarks. For instance, GPT-3 achieved only about 20% accuracy on GSM8K, far below human levels. This sparked deep reflection within the industry on LLM reasoning capabilities.
The Birth of Chain-of-Thought
In January 2022, Google Research published the paper “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” introducing the concept of Chain-of-Thought (CoT) for the first time. This groundbreaking work discovered that by demonstrating intermediate reasoning steps in prompts, the performance of LLMs on multi-step reasoning tasks could be significantly improved.
The key insight is: When humans solve complex problems, they typically undergo a step-by-step reasoning process, rather than arriving at the answer in one go. Chain-of-thought prompting simulates this cognitive process, guiding the model to generate intermediate reasoning steps to reach the final answer.
From CoT to Self-Consistency
Although chain-of-thought achieved remarkable results, a critical issue remained: The model might proceed along incorrect reasoning paths. For the same problem, an LLM could generate multiple different reasoning paths, some of which could be wrong.
In December 2022, Wang et al. proposed the Self-Consistency strategy, which further improved reasoning robustness by sampling multiple reasoning paths and selecting the most consistent answer. The core idea of this method is: Correct answers tend to have higher path consistency, meaning that most reasoning paths converge to the same answer.
Technical Principles
The Working Mechanism of Chain-of-Thought
The core of chain-of-thought lies in changing the LLM’s reasoning mode from “directly outputting the answer” to “generating reasoning steps before outputting the answer.” This seemingly simple shift embodies profound cognitive science principles.
Zero-shot CoT
The simplest implementation involves adding an instruction like “Let’s think step by step” to the prompt. This method requires no examples to activate the model’s reasoning ability.
Question: Xiao Ming has 5 apples, gives 2 to Xiao Hong, then gets 3 from Xiao Li, how many does he have now?
Let's think step by step.
The model generates a reasoning process similar to:
Initially has 5 apples.
Gives 2 to Xiao Hong, so remaining: 5 - 2 = 3.
Gets 3 from Xiao Li, so now has: 3 + 3 = 6.
Therefore, Xiao Ming now has 6 apples.
Few-shot CoT
Provide examples containing reasoning steps to teach the model how to reason step by step. This method generally yields better results but requires carefully designed examples.
Example 1:
Question: A store has 10 apples, sells 3, then restocks 5, how many are there now?
Reasoning: Initially 10, sell 3 left with 7, restock 5 gives 12.
Answer: 12
Example 2:
Question: Xiao Ming has 5 apples, gives 2 to Xiao Hong, then gets 3 from Xiao Li, how many does he have now?
Reasoning: Initially 5, give 2 to Xiao Hong left with 3, get 3 from Xiao Li gives 6.
Answer: 6
The Mathematical Foundation of Self-Consistency
Self-consistency is based on a simple statistical principle: For correct answers, different reasoning paths tend to converge; for incorrect answers, reasoning paths often diverge.
Formally, assume we have n independent reasoning paths, each producing an answer a_i. The self-consistency strategy selects the answer with the highest frequency:
a_final = argmax_a count(a_i = a)
This process can be viewed as a form of ensemble learning, but unlike traditional ensembles:
- Traditional Ensemble: Train multiple models, average or vote
- Self-Consistency: Same model, multiple samplings, select consistent answer
The Role of the Temperature Parameter
The effectiveness of self-consistency heavily depends on the sampling strategy. The temperature parameter controls the randomness of generated text:
- Low Temperature (0.1-0.3): Generates results close to deterministic, low diversity
- Medium Temperature (0.5-0.7): Moderate randomness, balances exploration and exploitation
- High Temperature (0.8-1.0): High randomness, explores more possibilities
For self-consistency, medium temperatures (0.5-0.7) are typically used to obtain diverse reasoning paths while maintaining quality.
The Synergistic Effect of the Two Methods
Chain-of-thought and self-consistency are not isolated techniques but complement each other:
- Chain-of-Thought Provides a Reasoning Framework: Guides the model to generate structured reasoning steps
- Self-Consistency Enhances Robustness: Eliminates chance errors through multiple samplings
Experiments show that combining both methods can improve accuracy on GSM8K from about 60% with single chain-of-thought to over 75%, an increase of more than 15 percentage points.
System Architecture Design
Overall Architecture
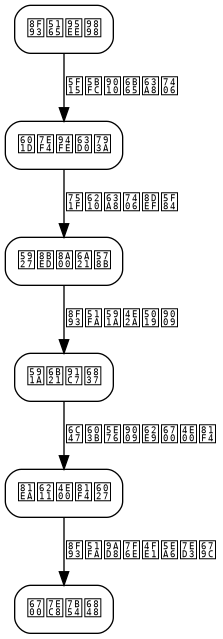
The above diagram shows the reasoning system architecture based on chain-of-thought and self-consistency. The system consists of the following core components:
- Input Preprocessing Layer: Responsible for question parsing and prompt template construction
- Reasoning Engine: Calls the LLM for multiple sampling inferences
- Path Aggregator: Collects and analyzes multiple reasoning paths
- Answer Selector: Selects the final answer based on consistency strategy
- Result Validator: Performs post-processing validation on the output
Data Flow Design
User Input → Prompt Construction → Multiple Sampling → Path Collection → Consistency Voting → Answer Output
Key Design Decisions:
- Parallel Sampling: Utilize goroutines for concurrent LLM calls to reduce latency
- Streaming Processing: Support progressive output of reasoning processes to enhance user experience
- Cache Mechanism: Cache reasoning results for identical questions to avoid redundant computation
Module Responsibility Breakdown
| Module | Responsibility | Key Technology |
|---|---|---|
| Prompt Engineering | Build CoT prompt templates | Template engine, Few-shot example management |
| Sampling Manager | Control sampling parameters (temperature, sample count) | Configuration management, Dynamic adjustment |
| LLM Client | Call underlying model API | HTTP client, Retry mechanism |
| Path Analyzer | Extract answers, analyze consistency | Regex matching, Statistical computation |
| Voter | Calculate majority answer | Frequency statistics, Confidence calculation |
Core Implementation
Basic Data Structure Definitions
package cot
import (
"context"
"fmt"
"math"
"strings"
"sync"
"time"
)
// ReasoningPath represents a complete reasoning path
type ReasoningPath struct {
Steps []string // Reasoning steps
FinalAnswer string // Final answer
Confidence float64 // Confidence score (0-1)
Latency time.Duration // Generation time
}
// CoTConfig Chain-of-Thought configuration
type CoTConfig struct {
Temperature float64 // Sampling temperature
TopP float64 // Top-p sampling
MaxTokens int // Maximum generation length
SampleCount int // Number of samplings
StopTokens []string // Stop tokens
}
// SelfConsistencyResult Self-consistency result
type SelfConsistencyResult struct {
FinalAnswer string // Final answer
AnswerCounts map[string]int // Frequency of each answer
TotalPaths int // Total reasoning paths
Consistency float64 // Consistency score (0-1)
AllPaths []ReasoningPath // All reasoning paths
}
// LLMClient LLM call interface
type LLMClient interface {
Generate(ctx context.Context, prompt string, config CoTConfig) (string, error)
}
Chain-of-Thought Prompt Builder
// PromptBuilder Chain-of-Thought prompt builder
type PromptBuilder struct {
fewShotExamples []FewShotExample // Few-shot examples
systemPrompt string // System prompt
}
// FewShotExample Few-shot example
type FewShotExample struct {
Question string `json:"question"`
Steps []string `json:"steps"`
Answer string `json:"answer"`
}
// NewPromptBuilder Creates a prompt builder
func NewPromptBuilder() *PromptBuilder {
return &PromptBuilder{
systemPrompt: "You are an AI assistant skilled in step-by-step reasoning. Please think through the problem step by step, then provide the final answer.",
fewShotExamples: []FewShotExample{
{
Question: "A basket has 15 eggs, 3 are broken, and 8 more are added. How many are there now?",
Steps: []string{
"Initially there are 15 eggs",
"3 are broken, remaining: 15 - 3 = 12",
"8 more are added, now there are: 12 + 8 = 20",
},
Answer: "20",
},
{
Question: "Xiao Ming is 8 years old. His father is 28 years older than him. How old will his father be in 5 years?",
Steps: []string{
"Xiao Ming is now 8, his father is 28 years older",
"Father's current age: 8 + 28 = 36",
"Father's age in 5 years: 36 + 5 = 41",
},
Answer: "41",
},
},
}
}
// BuildPrompt Builds a complete prompt
func (pb *PromptBuilder) BuildPrompt(question string, useZeroShot bool) string {
var builder strings.Builder
// Add system prompt
builder.WriteString(pb.systemPrompt)
builder.WriteString("\n\n")
if !useZeroShot {
// Add few-shot examples
for i, example := range pb.fewShotExamples {
builder.WriteString(fmt.Sprintf("Example %d:\n", i+1))
builder.WriteString(fmt.Sprintf("Question: %s\n", example.Question))
builder.WriteString("Reasoning:\n")
for _, step := range example.Steps {
builder.WriteString(fmt.Sprintf("- %s\n", step))
}
builder.WriteString(fmt.Sprintf("Answer: %s\n\n", example.Answer))
}
}
// Add target question
builder.WriteString(fmt.Sprintf("Question: %s\n", question))
if useZeroShot {
builder.WriteString("Let's think step by step.\n")
} else {
builder.WriteString("Reasoning:\n")
}
return builder.String()
}
Reasoning Path Parser
// PathParser Reasoning path parser
type PathParser struct {
answerPattern string // Answer extraction regex
}
// NewPathParser Creates a path parser
func NewPathParser() *PathParser {
return &PathParser{
answerPattern: `Answer[::]\s*(\d+\.?\d*)`, // Matches "Answer: number" pattern
}
}
// ParseResponse Parses model response
func (pp *PathParser) ParseResponse(response string) (*ReasoningPath, error) {
// Split reasoning steps
steps := pp.extractSteps(response)
// Extract final answer
answer := pp.extractAnswer(response)
if answer == "" {
return nil, fmt.Errorf("unable to extract answer from response: %s", response)
}
// Calculate confidence (based on step count and quality)
confidence := pp.calculateConfidence(steps)
return &ReasoningPath{
Steps: steps,
FinalAnswer: answer,
Confidence: confidence,
}, nil
}
// extractSteps Extracts reasoning steps
func (pp *PathParser) extractSteps(response string) []string {
var steps []string
lines := strings.Split(response, "\n")
for _, line := range lines {
line = strings.TrimSpace(line)
// Identify reasoning step lines (starting with numbers, hyphens, asterisks)
if strings.HasPrefix(line, "-") ||
strings.HasPrefix(line, "*") ||
strings.HasPrefix(line, "Step") ||
strings.HasPrefix(line, "步骤") {
steps = append(steps, line)
}
}
return steps
}
// extractAnswer Extracts final answer
func (pp *PathParser) extractAnswer(response string) string {
// Simple implementation: find content after "Answer:"
idx := strings.Index(response, "Answer")
if idx == -1 {
return ""
}
// Extract number after colon
after := response[idx+len("Answer"):]
if strings.HasPrefix(after, ":") {
after = after[1:]
}
// Trim whitespace
after = strings.TrimSpace(after)
// Extract numeric part
var answer strings.Builder
for _, ch := range after {
if ch >= '0' && ch <= '9' || ch == '.' || ch == '-' {
answer.WriteRune(ch)
} else {
break
}
}
return answer.String()
}
// calculateConfidence Calculates confidence
func (pp *PathParser) calculateConfidence(steps []string) float64 {
if len(steps) == 0 {
return 0.1
}
// Calculate base confidence based on step count
baseConfidence := math.Min(0.9, 0.3+float64(len(steps))*0.1)
// Check step quality
qualityScore := 1.0
for _, step := range steps {
// Steps containing numbers are more reliable
if strings.ContainsAny(step, "0123456789") {
qualityScore += 0.1
}
// Very short steps may be incomplete
if len(step) < 5 {
qualityScore -= 0.2
}
}
return math.Min(1.0, baseConfidence*qualityScore)
}
Self-Consistency Engine
// SelfConsistencyEngine Self-consistency engine
type SelfConsistencyEngine struct {
client LLMClient
config CoTConfig
promptBuilder *PromptBuilder
parser *PathParser
}
// NewSelfConsistencyEngine Creates an engine
func NewSelfConsistencyEngine(client LLMClient, config CoTConfig) *SelfConsistencyEngine {
return &SelfConsistencyEngine{
client: client,
config: config,
promptBuilder: NewPromptBuilder(),
parser: NewPathParser(),
}
}
// Solve Solves a problem
func (engine *SelfConsistencyEngine) Solve(ctx context.Context, question string) (*SelfConsistencyResult, error) {
// Build prompt
prompt := engine.promptBuilder.BuildPrompt(question, false)
// Concurrent sampling
paths := engine.samplePaths(ctx, prompt, engine.config.SampleCount)
// Count answer frequencies
answerCounts := make(map[string]int)
for _, path := range paths {
answerCounts[path.FinalAnswer]++
}
// Select the most consistent answer
finalAnswer := engine.selectConsistentAnswer(answerCounts)
// Calculate consistency score
totalPaths := len(paths)
maxCount := 0
for _, count := range answerCounts {
if count > maxCount {
maxCount = count
}
}
consistency := float64(maxCount) / float64(totalPaths)
return &SelfConsistencyResult{
FinalAnswer: finalAnswer,
AnswerCounts: answerCounts,
TotalPaths: totalPaths,
Consistency: consistency,
AllPaths: paths,
}, nil
}
// samplePaths Samples multiple reasoning paths in parallel
func (engine *SelfConsistencyEngine) samplePaths(ctx context.Context, prompt string, count int) []ReasoningPath {
paths := make([]ReasoningPath, 0, count)
var mu sync.Mutex
var wg sync.WaitGroup
// Use goroutines for concurrent sampling
for i := 0; i < count; i++ {
wg.Add(1)
go func(sampleIdx int) {
defer wg.Done()
// Set different temperatures for each sampling
config := engine.config
config.Temperature = engine.adjustTemperature(sampleIdx)
startTime := time.Now()
response, err := engine.client.Generate(ctx, prompt, config)
latency := time.Since(startTime)
if err != nil {
fmt.Printf("Sampling %d failed: %v\n", sampleIdx, err)
return
}
path, err := engine.parser.ParseResponse(response)
if err != nil {
fmt.Printf("Parsing failed: %v\n", err)
return
}
path.Latency = latency
mu.Lock()
paths = append(paths, *path)
mu.Unlock()
}(i)
}
wg.Wait()
return paths
}
// adjustTemperature Dynamically adjusts temperature
func (engine *SelfConsistencyEngine) adjustTemperature(sampleIdx int) float64 {
// Add random perturbations around the base temperature for increased diversity
baseTemp := engine.config.Temperature
perturbation := float64(sampleIdx%3-1) * 0.1 // -0.1, 0, 0.1
return math.Max(0.1, math.Min(1.0, baseTemp+perturbation))
}
// selectConsistentAnswer Selects the most consistent answer
func (engine *SelfConsistencyEngine) selectConsistentAnswer(counts map[string]int) string {
maxCount := 0
bestAnswer := ""
for answer, count := range counts {
if count > maxCount {
maxCount = count
bestAnswer = answer
}
}
return bestAnswer
}
Complete Reasoning Service
// ReasoningService Reasoning service
type ReasoningService struct {
engine *SelfConsistencyEngine
cache map[string]*SelfConsistencyResult
mu sync.RWMutex
}
// NewReasoningService Creates a reasoning service
func NewReasoningService(client LLMClient, config CoTConfig) *ReasoningService {
return &ReasoningService{
engine: NewSelfConsistencyEngine(client, config),
cache: make(map[string]*SelfConsistencyResult),
}
}
// Reason Performs reasoning
func (s *ReasoningService) Reason(ctx context.Context, question string) (*SelfConsistencyResult, error) {
// Check cache
cacheKey := strings.TrimSpace(strings.ToLower(question))
s.mu.RLock()
if result, ok := s.cache[cacheKey]; ok {
s.mu.RUnlock()
return result, nil
}
s.mu.RUnlock()
// Perform reasoning
result, err := s.engine.Solve(ctx, question)
if err != nil {
return nil, fmt.Errorf("reasoning failed: %w", err)
}
// Cache result
s.mu.Lock()
s.cache[cacheKey] = result
s.mu.Unlock()
return result, nil
}
// BatchReason Batch reasoning
func (s *ReasoningService) BatchReason(ctx context.Context, questions []string) ([]*SelfConsistencyResult, error) {
results := make([]*SelfConsistencyResult, len(questions))
var wg sync.WaitGroup
for i, question := range questions {
wg.Add(1)
go func(idx int, q string) {
defer wg.Done()
result, err := s.Reason(ctx, q)
if err != nil {
fmt.Printf("Reasoning failed for question '%s': %v\n", q, err)
return
}
results[idx] = result
}(i, question)
}
wg.Wait()
return results, nil
}
Performance Optimization
Sampling Strategy Optimization
The performance bottleneck of the self-consistency strategy lies in multiple LLM calls. Here are several optimization strategies:
1. Adaptive Sampling
Not all problems require a fixed number of samplings. For simple problems, a small number of samplings can yield a highly consistent answer; for complex problems, more samplings are needed.
// AdaptiveSampler Adaptive sampler
type AdaptiveSampler struct {
minSamples int
maxSamples int
threshold float64 // Consistency threshold
}
// DetermineSampleCount Determines the number of samplings
func (as *AdaptiveSampler) DetermineSampleCount(ctx context.Context, question string) int {
// Evaluate problem complexity
complexity := as.evaluateComplexity(question)
// Reduce samplings for simple problems
if complexity < 0.3 {
return as.minSamples
}
// Increase samplings for complex problems
if complexity > 0.7 {
return as.maxSamples
}
// Dynamically adjust for medium complexity
return as.minSamples + int(float64(as.maxSamples-as.minSamples)*complexity)
}
// evaluateComplexity Evaluates problem complexity
func (as *AdaptiveSampler) evaluateComplexity(question string) float64 {
// Evaluate based on question length, digit count, logical connectors, etc.
complexity := 0.0
// Length factor
complexity += math.Min(0.5, float64(len(question))/500.0)
// Digit count factor
digitCount := strings.Count(question, "0") + strings.Count(question, "1") +
strings.Count(question, "2") + strings.Count(question, "3") +
strings.Count(question, "4") + strings.Count(question, "5")
complexity += math.Min(0.3, float64(digitCount)*0.05)
return math.Min(1.0, complexity)
}
2. Early Termination Strategy
If high consistency is observed during sampling, sampling can be terminated early.
// EarlyStopSampler Early stop sampler
type EarlyStopSampler struct {
minSamples int
maxSamples int
stopThreshold float64 // Consistency threshold for early stop
}
// SampleWithEarlyStop Sampling with early stop
func (es *EarlyStopSampler) SampleWithEarlyStop(ctx context.Context, engine *SelfConsistencyEngine,
prompt string, resultsChan chan<- ReasoningPath) {
answerCounts := make(map[string]int)
for i := 0; i < es.maxSamples; i++ {
// Perform single sampling
path := engine.singleSample(ctx, prompt, i)
resultsChan <- path
// Update statistics
answerCounts[path.FinalAnswer]++
// Check if early stop is possible
if i >= es.minSamples {
maxCount := 0
total := i + 1
for _, count := range answerCounts {
if count > maxCount {
maxCount = count
}
}
consistency := float64(maxCount) / float64(total)
if consistency >= es.stopThreshold {
fmt.Printf("Early stop: reached consistency %.2f after %d samplings\n", consistency, i+1)
return
}
}
}
}
Cache Strategy Optimization
Proper use of caching can significantly reduce redundant computation:
// LRUCache LRU cache implementation
type LRUCache struct {
capacity int
cache map[string]*list.Element
list *list.List
mu sync.RWMutex
}
type cacheEntry struct {
key string
result *SelfConsistencyResult
}
func NewLRUCache(capacity int) *LRUCache {
return &LRUCache{
capacity: capacity,
cache: make(map[string]*list.Element),
list: list.New(),
}
}
func (c *LRUCache) Get(key string) (*SelfConsistencyResult, bool) {
c.mu.RLock()
defer c.mu.RUnlock()
if elem, ok := c.cache[key]; ok {
c.list.MoveToFront(elem)
return elem.Value.(*cacheEntry).result, true
}
return nil, false
}
func (c *LRUCache) Set(key string, result *SelfConsistencyResult) {
c.mu.Lock()
defer c.mu.Unlock()
if elem, ok := c.cache[key]; ok {
c.list.MoveToFront(elem)
elem.Value.(*cacheEntry).result = result
return
}
if c.list.Len() >= c.capacity {
// Evict the least recently used entry
elem := c.list.Back()
if elem != nil {
c.list.Remove(elem)
delete(c.cache, elem.Value.(*cacheEntry).key)
}
}
elem := c.list.PushFront(&cacheEntry{key: key, result: result})
c.cache[key] = elem
}
Concurrency Control Optimization
Proper concurrency control can maximize resource utilization:
// RateLimiter Rate limiter
type RateLimiter struct {
tokens chan struct{}
interval time.Duration
}
func NewRateLimiter(rate int, interval time.Duration) *RateLimiter {
rl := &RateLimiter{
tokens: make(chan struct{}, rate),
interval: interval,
}
// Initialize tokens
for i := 0; i < rate; i++ {
rl.tokens <- struct{}{}
}
// Periodically replenish tokens
go func() {
ticker := time.NewTicker(interval / time.Duration(rate))
defer ticker.Stop()
for range ticker.C {
select {
case rl.tokens <- struct{}{}:
default:
// Token pool full, skip
}
}
}()
return rl
}
func (rl *RateLimiter) Acquire(ctx context.Context) error {
select {
case <-rl.tokens:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
Production Practices
Deployment Architecture
In production environments, chain-of-thought reasoning systems typically adopt the following architecture:
- API Gateway Layer: Responsible for request routing, rate limiting, authentication
- Reasoning Service Layer: Stateless services, horizontally scalable
- Model Service Layer: LLM inference cluster, GPU accelerated
- Cache Layer: Redis cluster, storing inference results
- Monitoring Layer: Prometheus + Grafana, monitoring performance metrics
Key Metrics Monitoring
// MetricsCollector Metrics collector
type MetricsCollector struct {
requestCount *prometheus.CounterVec
latencyHistogram *prometheus.HistogramVec
consistencyGauge *prometheus.GaugeVec
}
func NewMetricsCollector() *MetricsCollector {
return &MetricsCollector{
requestCount: promauto.NewCounterVec(
prometheus.CounterOpts{
Name: "cot_requests_total",
Help: "Total number of CoT reasoning requests",
},
[]string{"status", "question_type"},
),
latencyHistogram: promauto.NewHistogramVec(
prometheus.HistogramOpts{
Name: "cot_latency_seconds",
Help: "Latency of CoT reasoning",
Buckets: prometheus.DefBuckets,
},
[]string{"sample_count"},
),
consistencyGauge: promauto.NewGaugeVec(
prometheus.GaugeOpts{
Name: "cot_consistency_score",
Help: "Consistency score of self-consistency",
},
[]string{"question_type"},
),
}
}
Fault Handling Strategy
// FallbackStrategy Fallback strategy
type FallbackStrategy struct {
maxRetries int
timeout time.Duration
fallbackModel string
}
func (fs *FallbackStrategy) ExecuteWithFallback(ctx context.Context,
primary func(context.Context) (*SelfConsistencyResult, error),
fallback func(context.Context) (*SelfConsistencyResult, error)) (*SelfConsistencyResult, error) {
// Try primary strategy
for i := 0; i < fs.maxRetries; i++ {
result, err := primary(ctx)
if err == nil {
return result, nil
}
// Check if retryable
if !fs.isRetryable(err) {
break
}
// Exponential backoff
time.Sleep(time.Duration(math.Pow(2, float64(i))) * 100 * time.Millisecond)
}
// Fallback to backup strategy
fmt.Println("Primary strategy failed, switching to fallback model")
return fallback(ctx)
}
func (fs *FallbackStrategy) isRetryable(err error) bool {
// Network errors and timeouts are retryable
if strings.Contains(err.Error(), "timeout") ||
strings.Contains(err.Error(), "connection") {
return true
}
return false
}
Cost Optimization
LLM inference cost is an important consideration in production environments:
- Model Selection: Choose appropriate models based on problem complexity
- Batch Processing: Merge multiple requests for batch inference
- Result Caching: Cache inference results for common questions
- Sampling Optimization: Adaptive sampling reduces unnecessary calls
Summary
Chain-of-thought and self-consistency represent significant breakthroughs in LLM reasoning capabilities. By simulating the human step-by-step reasoning process and leveraging the statistical consistency of multiple samplings, these techniques have markedly improved model performance on complex reasoning tasks.
Key Technical Insights
- Chain-of-Thought Activates Reasoning Capability: Guides the model to generate intermediate reasoning steps, transforming implicit reasoning into explicit reasoning
- Self-Consistency Enhances Robustness: Eliminates chance errors from single inferences through multiple samplings and voting mechanisms
- Synergistic Effect is Significant: Accuracy improves by over 15 percentage points on tasks like mathematical and logical reasoning
Future Outlook
- Multimodal Reasoning: Extend CoT to multimodal scenarios such as images and audio
- Structured Reasoning: Combine with knowledge graphs to achieve more complex reasoning chains
- Reasoning Verification: Automatically verify the correctness of reasoning steps to reduce hallucinations
- End-to-End Optimization: Integrate CoT capabilities directly into model training
Practical Recommendations
For teams planning to deploy CoT systems in production environments:
- Start Small: Validate effectiveness in specific domains first
- Establish Evaluation Systems: Continuously monitor metrics like accuracy, latency, and cost
- Incremental Optimization: Implement basic functionality first, then gradually optimize performance
- Focus on User Experience: Provide visualization of reasoning processes to enhance user trust
Chain-of-thought and self-consistency are not just technical breakthroughs; they represent a key shift in AI from “memory” to “reasoning.” As these technologies mature and become widespread, we can expect LLMs to demonstrate stronger capabilities in more complex cognitive tasks.