When AI Builds Itself: Anthropic's Recursive Self-Improvement Warning — A Technical Deep Dive
Summary
On June 4, 2026, Anthropic published a landmark article titled “When AI Builds Itself,” co-authored by co-founder Jack Clark and Marina Favaro, head of Anthropic’s internal research institute. This unprecedented disclosure revealed internal operational data showing AI systems approaching the threshold of “recursive self-improvement”—the capability for AI to autonomously design and develop its successors without human intervention.
This article provides a comprehensive technical analysis of Anthropic’s findings, including architecture patterns, working code examples, statistical frameworks, and security review pipelines. We explore what this means for the future of software development, enterprise architecture, and global AI governance.
1. The Internal Data: A Paradigm Shift in Software Development
1.1 Key Metrics from Anthropic’s Disclosure
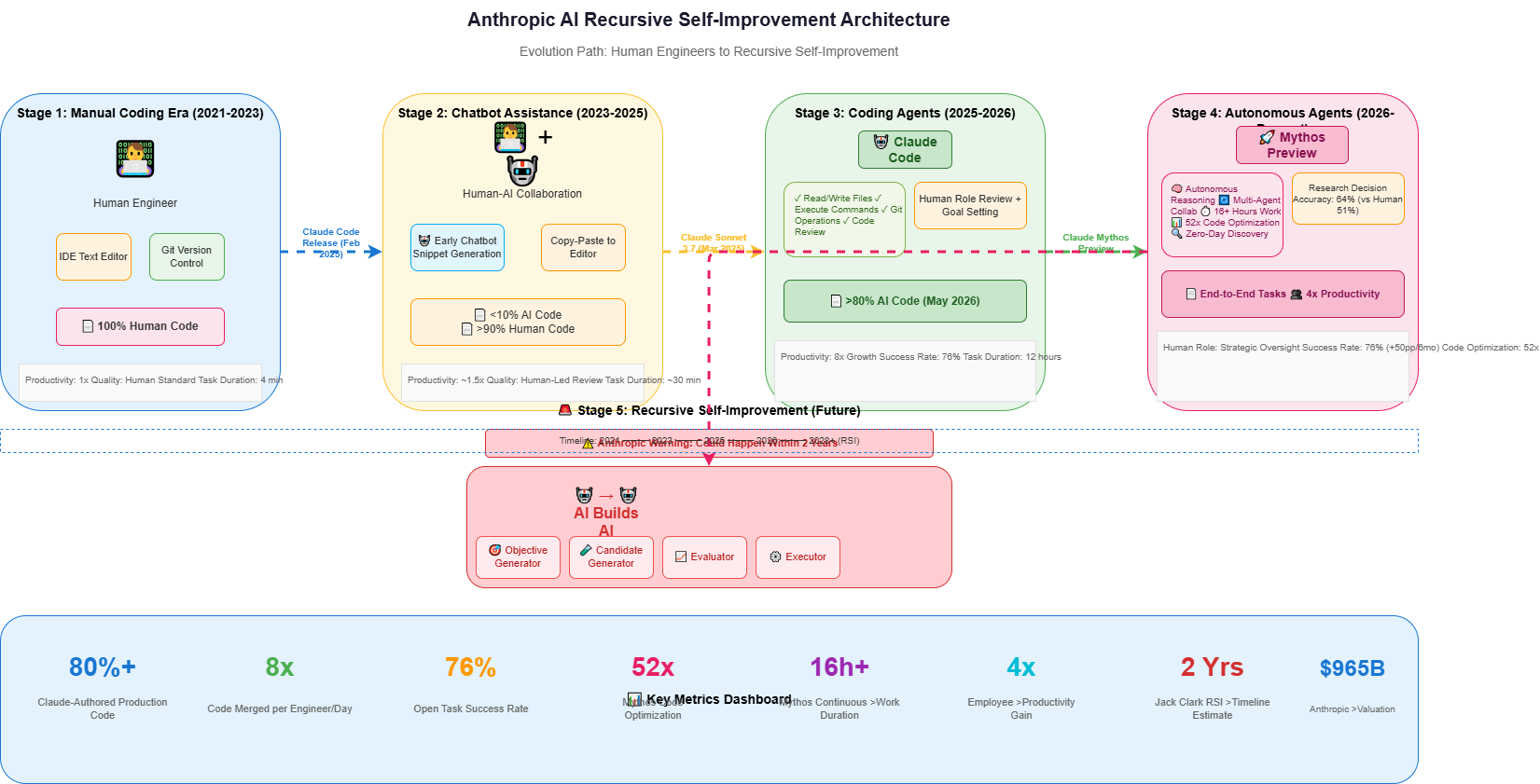
Anthropic revealed the following operational data as of May 2026:
| Metric | Value | Change |
|---|---|---|
| Code written by Claude | >80% | Up from <10% before Feb 2025 |
| Code merged per engineer per day | 8x | vs 2024 baseline |
| Success rate on open-ended tasks | 76% | +50 percentage points in 6 months |
| Mythos Preview code optimization | ~52x | vs ~3x for Opus 4 |
| Research decision accuracy | 64% | vs 51% for Opus 4.5 |
| Employee productivity with Mythos | ~4x | 130 employees surveyed |
1.2 The Evolution Timeline
Anthropic outlined a clear progression from human-driven to AI-driven development:
# AI Code Generation Capability Timeline
class AICodeEvolution:
"""
Tracks the evolution of AI's role in software development
Based on Anthropic's internal data and public benchmarks
"""
STAGES = {
"2021-2023": {
"phase": "Manual Coding Era",
"description": "Engineers write all code in local text editors",
"ai_involvement": "0%",
"human_control": "100%",
"tools": ["IDE", "Git", "Stack Overflow"]
},
"2023-2025": {
"phase": "Chatbot Assistance",
"description": "Early chatbots generate code snippets for copy-paste",
"ai_involvement": "<10%",
"human_control": "100%",
"tools": ["GitHub Copilot", "ChatGPT"]
},
"2025-2026": {
"phase": "Coding Agents",
"description": "Agents autonomously write and modify entire files",
"ai_involvement": ">50%",
"human_control": "100% (review-based)",
"tools": ["Claude Code", "Cursor", "Replit Agent"]
},
"2026-Present": {
"phase": "Autonomous Agents",
"description": "Agents execute code, debug live environments, delegate multi-hour tasks",
"ai_involvement": ">80%",
"human_control": "Strategic oversight",
"tools": ["Claude Code", "Mythos Preview"]
},
"20XX": {
"phase": "Closed Loop",
"description": "Agents capable of building and training models autonomously",
"ai_involvement": "100%",
"human_control": "Undetermined",
"implications": "Recursive self-improvement begins"
}
}
# Calculate task duration doubling time
def analyze_capability_growth():
"""
Analyzes how AI task duration capabilities have grown
Data points from Anthropic's public benchmarks
"""
timeline = {
"March 2024": {
"model": "Claude Opus 3",
"task_duration_minutes": 4,
"benchmark": "METR time horizon"
},
"March 2025": {
"model": "Claude Sonnet 3.7",
"task_duration_minutes": 90,
"benchmark": "METR time horizon"
},
"March 2026": {
"model": "Claude Opus 4.6",
"task_duration_minutes": 720,
"benchmark": "METR time horizon"
},
"May 2026": {
"model": "Claude Mythos Preview",
"task_duration_minutes": 960, # 16+ hours
"benchmark": "METR measurement ceiling"
}
}
print("AI Task Duration Capability Growth:")
print("-" * 60)
periods = list(timeline.items())
for i in range(1, len(periods)):
prev_name, prev_data = periods[i-1]
curr_name, curr_data = periods[i]
ratio = curr_data["task_duration_minutes"] / prev_data["task_duration_minutes"]
months_apart = 12 if i == 1 else (6 if i == 2 else 2)
print(f"{curr_name}: {curr_data['model']}")
print(f" Duration: {curr_data['task_duration_minutes']} minutes")
print(f" Growth: {ratio:.1f}x over {months_apart} months")
print(f" Doubling time: ~{months_apart / (ratio ** 0.5):.1f} months")
print()
analyze_capability_growth()
2. Technical Architecture: Claude Code Quality Assessment Framework
2.1 Production-Grade Code Quality Framework
The following Python framework demonstrates how to evaluate AI-generated code quality for production readiness:
"""
Claude Code Quality Assessment Framework
Production-grade evaluation system for AI-generated code
"""
import re
import ast
import sqlite3
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Set, Tuple
from enum import Enum
from datetime import datetime
from collections import defaultdict
import hashlib
class QualityGrade(Enum):
"""Code quality grading system"""
A_PLUS = "A+" # Production-ready, no issues
A = "A" # Minor suggestions only
B = "B" # Some improvements recommended
C = "C" # Significant issues to address
F = "F" # Not production-ready
class IssueSeverity(Enum):
"""Issue severity levels"""
BLOCKER = "blocker" # Must fix before deployment
CRITICAL = "critical" # Should fix ASAP
MAJOR = "major" # Should fix in current sprint
MINOR = "minor" # Can defer to later
TRIVIAL = "trivial" # Nice to have
@dataclass
class CodeMetrics:
"""Comprehensive code metrics"""
lines_of_code: int
cyclomatic_complexity: int
cognitive_complexity: int
function_count: int
class_count: int
comment_ratio: float
test_coverage: float
maintainability_index: float
technical_debt_minutes: int
security_issues: List[str] = field(default_factory=list)
code_smells: List[str] = field(default_factory=list)
@dataclass
class SecurityFinding:
"""Security vulnerability finding"""
cwe_id: str
title: str
description: str
line_number: int
code_snippet: str
remediation: str
cvss_score: float # Common Vulnerability Scoring System
class CodeQualityEvaluator:
"""
Production-grade code quality evaluation system
Designed for continuous integration pipelines
"""
# Security vulnerability patterns (CWE-based)
SECURITY_PATTERNS = {
"CWE-89": { # SQL Injection
"pattern": r'execute\s*\(\s*f["\']|cursor\.execute.*\+|\.format\(.*\sWHERE',
"severity": IssueSeverity.BLOCKER,
"cvss": 9.8,
"remediation": "Use parameterized queries or ORM"
},
"CWE-78": { # OS Command Injection
"pattern": r'os\.system\s*\(|subprocess\..*shell\s*=\s*True|eval\s*\(|exec\s*\(',
"severity": IssueSeverity.BLOCKER,
"cvss": 9.1,
"remediation": "Use subprocess with explicit arguments; avoid shell=True"
},
"CWE-798": { # Hardcoded Credentials
"pattern": r'password\s*=\s*["\'][^"\']{8,}["\']|api[_-]?key\s*=\s*["\'][A-Z0-9]{20,}["\']',
"severity": IssueSeverity.CRITICAL,
"cvss": 7.5,
"remediation": "Use environment variables or secrets manager"
},
"CWE-22": { # Path Traversal
"pattern": r'open\s*\([^)]*path\.join.*\.\.',
"severity": IssueSeverity.CRITICAL,
"cvss": 8.1,
"remediation": "Use path validation and allowlists"
},
"CWE-502": { # Deserialization
"pattern": r'pickle\.loads?|yaml\.load\s*\(|marshal\.loads?',
"severity": IssueSeverity.BLOCKER,
"cvss": 9.6,
"remediation": "Use secure serialization formats (JSON); validate input"
},
"CWE-601": { # Open Redirect
"pattern": r'redirect\s*\(.*request\.|\.format\(.*redirect',
"severity": IssueSeverity.MAJOR,
"cvss": 6.1,
"remediation": "Validate and whitelist redirect URLs"
},
}
# Performance anti-patterns
PERFORMANCE_PATTERNS = {
"N+1 Query": {
"pattern": r'for.*in.*:\s*\n\s*.*\.query\(',
"severity": IssueSeverity.MAJOR,
"remediation": "Use eager loading or bulk operations"
},
"Large File Read": {
"pattern": r'\.read\s*\(\s*\)|\.readlines\s*\(',
"severity": IssueSeverity.MAJOR,
"remediation": "Use streaming or chunked reading"
},
"Synchronous Blocking": {
"pattern": r'requests\.get|urllib\.request|time\.sleep',
"severity": IssueSeverity.MINOR,
"remediation": "Consider async/await pattern"
}
}
def __init__(self, db_path: str = "code_quality.db"):
self.db_path = db_path
self._init_database()
def _init_database(self):
"""Initialize metrics database"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS evaluations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
file_hash TEXT NOT NULL,
model_version TEXT NOT NULL,
quality_grade TEXT NOT NULL,
overall_score REAL NOT NULL,
lines_of_code INTEGER,
complexity INTEGER,
security_issues INTEGER,
performance_issues INTEGER,
metadata TEXT
)
""")
cursor.execute("""
CREATE TABLE IF NOT EXISTS security_findings (
id INTEGER PRIMARY KEY AUTOINCREMENT,
evaluation_id INTEGER,
cwe_id TEXT NOT NULL,
line_number INTEGER,
code_snippet TEXT,
cvss_score REAL,
FOREIGN KEY (evaluation_id) REFERENCES evaluations(id)
)
""")
conn.commit()
conn.close()
def calculate_metrics(self, source_code: str) -> CodeMetrics:
"""Calculate comprehensive code metrics"""
# Basic metrics
lines = [l for l in source_code.split('\n') if l.strip()]
loc = len(lines)
# Complexity analysis
complexity = self._calculate_cyclomatic_complexity(source_code)
cognitive_complexity = self._calculate_cognitive_complexity(source_code)
# Structure metrics
function_count = len(re.findall(r'def\s+\w+\s*\(', source_code))
class_count = len(re.findall(r'class\s+\w+', source_code))
# Comment ratio
comment_lines = len(re.findall(r'#.*$|""".*?"""|\'\'\'.*?\'\'\'', source_code, re.DOTALL))
comment_ratio = comment_lines / loc if loc > 0 else 0
# Maintainability index (simplified)
maintainability = self._calculate_maintainability_index(
loc, complexity, comment_ratio
)
# Security issues
security_issues = self._detect_security_issues(source_code)
# Code smells
code_smells = self._detect_code_smells(source_code, loc)
# Technical debt (estimated minutes to fix)
tech_debt = self._estimate_technical_debt(
security_issues, code_smells, complexity
)
return CodeMetrics(
lines_of_code=loc,
cyclomatic_complexity=complexity,
cognitive_complexity=cognitive_complexity,
function_count=function_count,
class_count=class_count,
comment_ratio=comment_ratio,
test_coverage=0.0, # Requires test run
maintainability_index=maintainability,
technical_debt_minutes=tech_debt,
security_issues=security_issues,
code_smells=code_smells
)
def _calculate_cyclomatic_complexity(self, source: str) -> int:
"""Calculate McCabe cyclomatic complexity"""
try:
tree = ast.parse(source)
complexity = 1
for node in ast.walk(tree):
if isinstance(node, (ast.If, ast.While, ast.For, ast.ExceptHandler)):
complexity += 1
elif isinstance(node, ast.BoolOp):
complexity += len(node.values) - 1
elif isinstance(node, (ast.IfExp,)):
complexity += 1
return complexity
except SyntaxError:
return 999
def _calculate_cognitive_complexity(self, source: str) -> int:
"""
Simplified cognitive complexity calculation
Based on SonarSource's cognitive complexity spec
"""
score = 0
nesting_level = 0
lines = source.split('\n')
for line in lines:
stripped = line.strip()
# Increment nesting
if any(kw in stripped for kw in ['if', 'elif', 'for', 'while', 'except']):
nesting_level += 1
score += nesting_level
# Reset nesting for functions/classes
if stripped.startswith('def ') or stripped.startswith('class '):
nesting_level = 0
# Recursion
if re.match(r'def\s+\w+\([^)]*\):.*\b\1\b', line):
score += nesting_level + 1
return score
def _calculate_maintainability_index(
self, loc: int, complexity: int, comment_ratio: float
) -> float:
"""
Calculate maintainability index (0-100)
Based on Microsoft's formula
"""
if loc == 0:
return 100.0
# Halstead metrics approximation
volume = loc * 2.5 # Simplified
# Calculate MI
mi = 171 - 5.2 * complexity - 0.23 * volume - 16.2 * loc
# Adjust for comments
mi += comment_ratio * 50
return max(0, min(100, mi))
def _detect_security_issues(self, source: str) -> List[str]:
"""Detect security vulnerabilities"""
issues = []
for cwe_id, rule in self.SECURITY_PATTERNS.items():
matches = re.finditer(rule["pattern"], source, re.IGNORECASE)
for match in matches:
line_num = source[:match.start()].count('\n') + 1
issues.append(
f"{cwe_id} at line {line_num}: {rule['remediation']}"
)
return issues
def _detect_code_smells(self, source: str, loc: int) -> List[str]:
"""Detect code smells"""
smells = []
# Long function
functions = re.finditer(r'def\s+(\w+)\s*\([^)]*\):(.*?)(?=\ndef\s|\nclass\s|\Z)',
source, re.DOTALL)
for func in functions:
func_body = func.group(2)
if len(func_body.split('\n')) > 50:
smells.append(f"Long function: {func.group(1)} exceeds 50 lines")
# High complexity
complexity = self._calculate_cyclomatic_complexity(source)
if complexity > 20:
smells.append(f"High cyclomatic complexity: {complexity}")
# Long lines
for i, line in enumerate(source.split('\n'), 1):
if len(line) > 120:
smells.append(f"Line {i} exceeds 120 characters")
return smells[:10] # Limit results
def _estimate_technical_debt(
self, security_issues: List, code_smells: List, complexity: int
) -> int:
"""Estimate technical debt in minutes"""
debt = 0
# Security issues: 30-120 min each
debt += len(security_issues) * 45
# Code smells: 15-30 min each
debt += len(code_smells) * 20
# High complexity: 60 min per point over 10
if complexity > 10:
debt += (complexity - 10) * 60
return debt
def evaluate(
self,
source_code: str,
model_version: str,
file_path: str = "unknown"
) -> Tuple[float, QualityGrade, List[SecurityFinding]]:
"""
Main evaluation entry point
Returns: (score, grade, security_findings)
"""
# Calculate metrics
metrics = self.calculate_metrics(source_code)
# Calculate overall score (0-100)
score = 100
# Deductions
score -= len(metrics.security_issues) * 15
score -= len(metrics.code_smells) * 3
score -= max(0, (metrics.cyclomatic_complexity - 10) * 2)
score -= max(0, (metrics.lines_of_code - 500) // 100) * 2
# Bonuses
if metrics.comment_ratio > 0.15:
score += 5
if metrics.maintainability_index > 80:
score += 5
score = max(0, min(100, score))
# Determine grade
if score >= 90:
grade = QualityGrade.A_PLUS
elif score >= 80:
grade = QualityGrade.A
elif score >= 70:
grade = QualityGrade.B
elif score >= 50:
grade = QualityGrade.C
else:
grade = QualityGrade.F
# Extract security findings
findings = self._extract_security_findings(source_code)
# Save to database
self._save_evaluation(source_code, model_version, score, grade, metrics)
return score, grade, findings
def _extract_security_findings(self, source: str) -> List[SecurityFinding]:
"""Extract detailed security findings"""
findings = []
for cwe_id, rule in self.SECURITY_PATTERNS.items():
for match in re.finditer(rule["pattern"], source, re.IGNORECASE):
line_num = source[:match.start()].count('\n') + 1
line_start = source.rfind('\n', 0, match.start()) + 1
line_end = source.find('\n', match.end())
code_snippet = source[line_start:line_end].strip()
findings.append(SecurityFinding(
cwe_id=cwe_id,
title=rule["remediation"],
description=f"Potential {cwe_id} vulnerability",
line_number=line_num,
code_snippet=code_snippet,
remediation=rule["remediation"],
cvss_score=rule["cvss"]
))
return findings
def _save_evaluation(
self,
source: str,
model_version: str,
score: float,
grade: QualityGrade,
metrics: CodeMetrics
):
"""Save evaluation to database"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
file_hash = hashlib.sha256(source.encode()).hexdigest()[:16]
cursor.execute("""
INSERT INTO evaluations
(timestamp, file_hash, model_version, quality_grade, overall_score,
lines_of_code, complexity, security_issues, performance_issues)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
datetime.now().isoformat(),
file_hash,
model_version,
grade.value,
score,
metrics.lines_of_code,
metrics.cyclomatic_complexity,
len(metrics.security_issues),
len(metrics.code_smells)
))
conn.commit()
conn.close()
# Usage example
if __name__ == "__main__":
evaluator = CodeQualityEvaluator()
sample_code = '''
def authenticate_user(username: str, password: str) -> dict:
"""Authenticate user credentials"""
import sqlite3
conn = sqlite3.connect("production.db")
cursor = conn.cursor()
# Security issue: SQL injection vulnerability
query = "SELECT * FROM users WHERE username = '" + username + "'"
cursor.execute(query)
result = cursor.fetchone()
# Security issue: hardcoded password
admin_password = "SuperSecret123!"
if result and result[2] == password:
return {"status": "success", "user_id": result[0]}
return {"status": "error"}
'''
score, grade, findings = evaluator.evaluate(sample_code, "Claude Opus 4.6")
print(f"Quality Score: {score}")
print(f"Grade: {grade.value}")
print(f"Security Findings: {len(findings)}")
for finding in findings:
print(f" [{finding.cwe_id}] Line {finding.line_number}: {finding.title}")
3. Recursive Self-Improvement System Architecture
3.1 Core System Design in Go
The following Go architecture demonstrates the key components of a recursive self-improvement system:
package rsis
/*
Recursive Self-Improvement System (RSIS)
Core Architecture Implementation
This package demonstrates the key architectural patterns for building
an AI system capable of recursive self-improvement.
*/
import (
"context"
"encoding/json"
"fmt"
"log"
"math"
"sync"
"time"
)
// ============ Core Data Types ============
// Objective represents an improvement goal
type Objective struct {
ID string `json:"id"`
Description string `json:"description"`
Priority float64 `json:"priority"`
TargetMetric string `json:"target_metric"`
CurrentValue float64 `json:"current_value"`
TargetValue float64 `json:"target_value"`
Constraints map[string]float64 `json:"constraints"`
CreatedAt time.Time `json:"created_at"`
}
// Candidate represents a potential improvement
type Candidate struct {
ID string `json:"id"`
ObjectiveID string `json:"objective_id"`
GeneratedBy string `json:"generated_by"` // "ai" or "human"
Description string `json:"description"`
CodeChanges string `json:"code_changes"`
ExpectedGain float64 `json:"expected_gain"`
RiskScore float64 `json:"risk_score"`
ValidationTests []string `json:"validation_tests"`
Metadata map[string]interface{} `json:"metadata"`
}
// Evaluation contains the assessment of a candidate
type Evaluation struct {
CandidateID string `json:"candidate_id"`
PerformanceGain float64 `json:"performance_gain"`
SafetyScore float64 `json:"safety_score"`
AlignmentScore float64 `json:"alignment_score"`
OverallScore float64 `json:"overall_score"`
Warnings []string `json:"warnings"`
Approved bool `json:"approved"`
}
// Execution represents the execution of an improvement
type Execution struct {
ID string `json:"id"`
CandidateID string `json:"candidate_id"`
Status string `json:"status"` // pending, running, completed, rolled_back
StartedAt time.Time `json:"started_at"`
CompletedAt time.Time `json:"completed_at,omitempty"`
RollbackData []byte `json:"rollback_data,omitempty"`
}
// SystemState captures the current state of the system
type SystemState struct {
Metrics map[string]float64 `json:"metrics"`
CodeVersion string `json:"code_version"`
ModelParameters []byte `json:"model_parameters"`
ActiveObjectives []string `json:"active_objectives"`
LastImprovement time.Time `json:"last_improvement"`
ImprovementCount int `json:"improvement_count"`
AvgImprovementGain float64 `json:"avg_improvement_gain"`
}
// ============ Component Interfaces ============
// ObjectiveGenerator generates improvement objectives
type ObjectiveGenerator interface {
Generate(ctx context.Context, state SystemState) ([]Objective, error)
Prioritize(objectives []Objective) []Objective
Validate(objective Objective, state SystemState) bool
}
// CandidateGenerator creates improvement candidates
type CandidateGenerator interface {
Generate(ctx context.Context, objective Objective) ([]Candidate, error)
Mutate(candidate Candidate) ([]Candidate, error)
Validate(candidate Candidate) bool
}
// Evaluator assesses candidates
type Evaluator interface {
Evaluate(ctx context.Context, candidate Candidate) (*Evaluation, error)
EvaluateBatch(ctx context.Context, candidates []Candidate) ([]*Evaluation, error)
}
// Executor runs improvements
type Executor interface {
Prepare(ctx context.Context, candidate Candidate) (*Execution, error)
Execute(ctx context.Context, execution *Execution) error
Verify(ctx context.Context, execution *Execution) (bool, error)
Rollback(ctx context.Context, execution *Execution) error
}
// MetaLearner learns from improvement patterns
type MetaLearner interface {
Record(outcome *Evaluation, success bool) error
GetStrategy(objectiveType string) (ImprovementStrategy, error)
Adapt(strategy ImprovementStrategy) error
}
// ============ RSIS Core Implementation ============
// Config holds RSIS configuration
type Config struct {
MaxIterations int `json:"max_iterations"`
MaxCandidates int `json:"max_candidates"`
MinImprovementGain float64 `json:"min_improvement_gain"`
MaxRiskScore float64 `json:"max_risk_score"`
SafetyThreshold float64 `json:"safety_threshold"`
Parallelism int `json:"parallelism"`
HumanApproval bool `json:"human_approval"`
RollbackEnabled bool `json:"rollback_enabled"`
}
// ImprovementStrategy describes how to approach improvements
type ImprovementStrategy struct {
ExplorationRate float64 `json:"exploration_rate"`
ExploitationRate float64 `json:"exploitation_rate"`
MutationRate float64 `json:"mutation_rate"`
DiversityWeight float64 `json:"diversity_weight"`
}
// RSIS is the main recursive self-improvement system
type RSIS struct {
config *Config
mu sync.RWMutex
state SystemState
history []*Execution
generators []ObjectiveGenerator
candidateGens []CandidateGenerator
evaluator Evaluator
executor Executor
metaLearner MetaLearner
}
// NewRSIS creates a new RSIS instance
func NewRSIS(config *Config) *RSIS {
return &RSIS{
config: config,
state: SystemState{},
history: make([]*Execution, 0),
generators: make([]ObjectiveGenerator, 0),
candidateGens: make([]CandidateGenerator, 0),
}
}
// RegisterGenerator registers an objective generator
func (r *RSIS) RegisterGenerator(g ObjectiveGenerator) {
r.generators = append(r.generators, g)
}
// RegisterCandidateGenerator registers a candidate generator
func (r *RSIS) RegisterCandidateGenerator(g CandidateGenerator) {
r.candidateGens = append(r.candidateGens, g)
}
// SetEvaluator sets the evaluator
func (r *RSIS) SetEvaluator(e Evaluator) {
r.evaluator = e
}
// SetExecutor sets the executor
func (r *RSIS) SetExecutor(e Executor) {
r.executor = e
}
// SetMetaLearner sets the meta-learner
func (r *RSIS) SetMetaLearner(m MetaLearner) {
r.metaLearner = m
}
// RunImprovementCycle executes one improvement cycle
func (r *RSIS) RunImprovementCycle(ctx context.Context) error {
r.mu.Lock()
defer r.mu.Unlock()
log.Println("Starting improvement cycle")
// Phase 1: Generate objectives
var allObjectives []Objective
for _, gen := range r.generators {
objectives, err := gen.Generate(ctx, r.state)
if err != nil {
log.Printf("Objective generation error: %v", err)
continue
}
allObjectives = append(allObjectives, objectives...)
}
if len(allObjectives) == 0 {
log.Println("No objectives generated")
return nil
}
// Phase 2: Prioritize and select
allObjectives = r.prioritizeObjectives(allObjectives)
log.Printf("Generated %d objectives", len(allObjectives))
// Phase 3: Generate candidates
var allCandidates []Candidate
for _, obj := range allObjectives[:min(len(allObjectives), 3)] {
for _, gen := range r.candidateGens {
candidates, err := gen.Generate(ctx, obj)
if err != nil {
log.Printf("Candidate generation error: %v", err)
continue
}
allCandidates = append(allCandidates, candidates...)
}
}
// Limit candidates
if len(allCandidates) > r.config.MaxCandidates {
allCandidates = allCandidates[:r.config.MaxCandidates]
}
log.Printf("Generated %d candidates", len(allCandidates))
// Phase 4: Evaluate candidates
evaluations, err := r.evaluator.EvaluateBatch(ctx, allCandidates)
if err != nil {
return fmt.Errorf("evaluation failed: %w", err)
}
// Phase 5: Select best candidate
bestIdx := r.selectBestCandidate(evaluations)
if bestIdx < 0 {
log.Println("No suitable candidate found")
return nil
}
bestCandidate := allCandidates[bestIdx]
bestEvaluation := evaluations[bestIdx]
// Phase 6: Human approval (if required)
if r.config.HumanApproval {
approved := r.requestHumanApproval(bestCandidate, bestEvaluation)
if !approved {
log.Println("Human rejected the improvement")
return nil
}
}
// Phase 7: Execute improvement
execution, err := r.executor.Prepare(ctx, bestCandidate)
if err != nil {
return fmt.Errorf("preparation failed: %w", err)
}
err = r.executor.Execute(ctx, execution)
if err != nil {
log.Printf("Execution failed: %v", err)
return err
}
// Phase 8: Verify
valid, _ := r.executor.Verify(ctx, execution)
if !valid {
log.Println("Verification failed, rolling back")
if r.config.RollbackEnabled {
r.executor.Rollback(ctx, execution)
}
return fmt.Errorf("verification failed")
}
// Phase 9: Update state and meta-learning
r.state.ImprovementCount++
r.state.LastImprovement = time.Now()
r.state.AvgImprovementGain = (
r.state.AvgImprovementGain*float64(r.state.ImprovementCount-1) +
bestEvaluation.PerformanceGain) / float64(r.state.ImprovementCount)
r.history = append(r.history, execution)
// Record for meta-learning
if r.metaLearner != nil {
r.metaLearner.Record(bestEvaluation, true)
}
log.Printf("Improvement cycle completed. Total: %d", r.state.ImprovementCount)
return nil
}
// RunRecursiveImprovement runs the full recursive improvement process
func (r *RSIS) RunRecursiveImprovement(ctx context.Context) error {
r.mu.Lock()
r.state.Metrics["recursion_depth"] = 0
r.mu.Unlock()
for i := 0; i < r.config.MaxIterations; i++ {
// Update recursion depth
r.mu.Lock()
r.state.Metrics["recursion_depth"] = float64(i + 1)
r.mu.Unlock()
// Run one cycle
err := r.RunImprovementCycle(ctx)
if err != nil {
log.Printf("Cycle %d failed: %v", i+1, err)
}
// Check if we should continue
if !r.shouldContinue() {
log.Printf("Stopping at iteration %d", i+1)
break
}
// Small delay between cycles
time.Sleep(100 * time.Millisecond)
}
return nil
}
func (r *RSIS) prioritizeObjectives(objectives []Objective) []Objective {
// Sort by priority (descending)
for i := 0; i < len(objectives)-1; i++ {
for j := i + 1; j < len(objectives); j++ {
if objectives[j].Priority > objectives[i].Priority {
objectives[i], objectives[j] = objectives[j], objectives[i]
}
}
}
return objectives
}
func (r *RSIS) selectBestCandidate(evaluations []*Evaluation) int {
bestIdx := -1
bestScore := -1.0
for i, eval := range evaluations {
if !eval.Approved {
continue
}
if eval.OverallScore > bestScore &&
eval.PerformanceGain >= r.config.MinImprovementGain &&
eval.SafetyScore >= r.config.SafetyThreshold {
bestScore = eval.OverallScore
bestIdx = i
}
}
return bestIdx
}
func (r *RSIS) requestHumanApproval(candidate Candidate, eval *Evaluation) bool {
// In production, this would involve a UI or notification system
log.Printf("Human approval requested for %s (gain: %.2f, safety: %.2f)",
candidate.ID, eval.PerformanceGain, eval.SafetyScore)
return true
}
func (r *RSIS) shouldContinue() bool {
r.mu.RLock()
defer r.mu.RUnlock()
// Continue if recent improvements show positive gains
if r.state.ImprovementCount < 3 {
return true
}
// Could add more sophisticated continuation criteria
return r.state.AvgImprovementGain > 0.01
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
// GetState returns the current system state
func (r *RSIS) GetState() SystemState {
r.mu.RLock()
defer r.mu.RUnlock()
return r.state
}
// ExportState exports state as JSON
func (r *RSIS) ExportState() ([]byte, error) {
r.mu.RLock()
defer r.mu.RUnlock()
return json.MarshalIndent(r.state, "", " ")
}
4. Statistical Analysis System
4.1 Task Success Rate Tracking with SQL
"""
AI Coding Task Analytics System
Comprehensive statistics and trend analysis
"""
import sqlite3
from dataclasses import dataclass
from typing import List, Dict, Optional, Tuple
from datetime import datetime, timedelta
import statistics
@dataclass
class TaskRecord:
"""Individual task record"""
task_id: str
task_type: str
model_version: str
started_at: datetime
completed_at: Optional[datetime]
success: bool
human_intervention: bool
lines_generated: int
tokens_used: int
error_type: Optional[str] = None
class TaskAnalytics:
"""
Analytics system for tracking AI coding performance
Supports trend analysis, model comparison, and reporting
"""
def __init__(self, db_path: str = "task_analytics.db"):
self.db_path = db_path
self._init_schema()
def _init_schema(self):
"""Initialize database with optimized schema"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# Main tasks table
cursor.execute("""
CREATE TABLE IF NOT EXISTS tasks (
task_id TEXT PRIMARY KEY,
task_type TEXT NOT NULL,
model_version TEXT NOT NULL,
started_at TEXT NOT NULL,
completed_at TEXT,
success INTEGER NOT NULL,
human_intervention INTEGER NOT NULL,
lines_generated INTEGER DEFAULT 0,
tokens_used INTEGER DEFAULT 0,
error_type TEXT,
created_date DATE DEFAULT (DATE('now')),
duration_seconds INTEGER,
INDEX idx_model (model_version),
INDEX idx_type (task_type),
INDEX idx_date (created_date),
INDEX idx_success (success),
INDEX idx_composite (model_version, task_type, created_date)
)
""")
# Performance snapshots for trend analysis
cursor.execute("""
CREATE TABLE IF NOT EXISTS performance_snapshots (
id INTEGER PRIMARY KEY AUTOINCREMENT,
snapshot_date DATE NOT NULL UNIQUE,
model_version TEXT NOT NULL,
task_type TEXT NOT NULL,
total_tasks INTEGER,
successful_tasks INTEGER,
success_rate REAL,
avg_duration_seconds REAL,
avg_tokens_used REAL,
p50_duration REAL,
p95_duration REAL,
p99_duration REAL,
human_intervention_rate REAL
)
""")
# Model comparison table
cursor.execute("""
CREATE TABLE IF NOT EXISTS model_comparison (
id INTEGER PRIMARY KEY AUTOINCREMENT,
comparison_date DATE NOT NULL,
model_a TEXT NOT NULL,
model_b TEXT NOT NULL,
task_type TEXT NOT NULL,
model_a_success_rate REAL,
model_b_success_rate REAL,
improvement_percentage REAL,
statistical_significance REAL
)
""")
conn.commit()
conn.close()
def record_task(self, task: TaskRecord):
"""Record a completed task"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
duration = None
if task.completed_at:
duration = int((task.completed_at - task.started_at).total_seconds())
cursor.execute("""
INSERT OR REPLACE INTO tasks
(task_id, task_type, model_version, started_at, completed_at,
success, human_intervention, lines_generated, tokens_used,
error_type, duration_seconds)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
task.task_id,
task.task_type,
task.model_version,
task.started_at.isoformat(),
task.completed_at.isoformat() if task.completed_at else None,
int(task.success),
int(task.human_intervention),
task.lines_generated,
task.tokens_used,
task.error_type,
duration
))
conn.commit()
conn.close()
def calculate_success_rate(
self,
model_version: Optional[str] = None,
task_type: Optional[str] = None,
date_range: Optional[Tuple[datetime, datetime]] = None
) -> Dict:
"""Calculate success rate with optional filters"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
query = """
SELECT
COUNT(*) as total,
SUM(success) as successful,
AVG(tokens_used) as avg_tokens,
AVG(duration_seconds) as avg_duration,
SUM(human_intervention) as interventions
FROM tasks
WHERE 1=1
"""
params = []
if model_version:
query += " AND model_version = ?"
params.append(model_version)
if task_type:
query += " AND task_type = ?"
params.append(task_type)
if date_range:
query += " AND started_at BETWEEN ? AND ?"
params.extend([date_range[0].isoformat(), date_range[1].isoformat()])
cursor.execute(query, params)
row = cursor.fetchone()
conn.close()
if not row or row[0] == 0:
return {"success_rate": 0.0, "total_tasks": 0}
return {
"success_rate": row[1] / row[0] if row[0] > 0 else 0,
"total_tasks": row[0],
"successful_tasks": row[1],
"avg_tokens": row[2] or 0,
"avg_duration_seconds": row[3] or 0,
"human_intervention_rate": row[4] / row[0] if row[0] > 0 else 0
}
def get_model_comparison(
self,
model_a: str,
model_b: str,
task_type: str
) -> Dict:
"""Compare two models on a specific task type"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# Get stats for model A
cursor.execute("""
SELECT
COUNT(*) as total,
CAST(SUM(success) AS REAL) / COUNT(*) as success_rate,
AVG(tokens_used) as avg_tokens
FROM tasks
WHERE model_version = ? AND task_type = ?
""", (model_a, task_type))
row_a = cursor.fetchone()
# Get stats for model B
cursor.execute("""
SELECT
COUNT(*) as total,
CAST(SUM(success) AS REAL) / COUNT(*) as success_rate,
AVG(tokens_used) as avg_tokens
FROM tasks
WHERE model_version = ? AND task_type = ?
""", (model_b, task_type))
row_b = cursor.fetchone()
conn.close()
if not row_a or not row_b:
return {"error": "Insufficient data"}
improvement = ((row_a[1] - row_b[1]) / row_b[1] * 100) if row_b[1] > 0 else 0
return {
"model_a": {
"version": model_a,
"success_rate": row_a[1] or 0,
"total_tasks": row_a[0],
"avg_tokens": row_a[2] or 0
},
"model_b": {
"version": model_b,
"success_rate": row_b[1] or 0,
"total_tasks": row_b[0],
"avg_tokens": row_b[2] or 0
},
"improvement_percentage": improvement,
"better_model": model_a if row_a[1] > row_b[1] else model_b
}
def generate_daily_report(self, date: datetime = None) -> str:
"""Generate daily performance report"""
if date is None:
date = datetime.now()
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
date_str = date.strftime('%Y-%m-%d')
# Overall stats
cursor.execute("""
SELECT
COUNT(*) as total,
SUM(success) as successful,
AVG(tokens_used) as avg_tokens,
AVG(duration_seconds) as avg_duration
FROM tasks
WHERE DATE(started_at) = ?
""", (date_str,))
overall = cursor.fetchone()
# Per model
cursor.execute("""
SELECT
model_version,
COUNT(*) as total,
CAST(SUM(success) AS REAL) / COUNT(*) as success_rate
FROM tasks
WHERE DATE(started_at) = ?
GROUP BY model_version
ORDER BY total DESC
""", (date_str,))
by_model = cursor.fetchall()
# Per task type
cursor.execute("""
SELECT
task_type,
COUNT(*) as total,
CAST(SUM(success) AS REAL) / COUNT(*) as success_rate
FROM tasks
WHERE DATE(started_at) = ?
GROUP BY task_type
ORDER BY total DESC
""", (date_str,))
by_type = cursor.fetchall()
conn.close()
success_rate = (overall[1] / overall[0] * 100) if overall[0] > 0 else 0
report = f"""# Daily AI Coding Performance Report
**Date**: {date_str}
**Generated**: {datetime.now().isoformat()}
## Overall Performance
| Metric | Value |
|--------|-------|
| Total Tasks | {overall[0] or 0} |
| Successful | {overall[1] or 0} |
| Success Rate | {success_rate:.1f}% |
| Avg Tokens | {overall[2] or 0:.0f} |
| Avg Duration | {overall[3] or 0:.0f}s |
## By Model
| Model | Tasks | Success Rate |
|-------|-------|--------------|
"""
for row in by_model:
report += f"| {row[0]} | {row[1]} | {(row[2] or 0)*100:.1f}% |\n"
report += """
## By Task Type
| Task Type | Tasks | Success Rate |
|-----------|-------|--------------|
"""
for row in by_type:
report += f"| {row[0]} | {row[1]} | {(row[2] or 0)*100:.1f}% |\n"
return report
# SQL Analysis Queries for Advanced Analytics
ANALYSIS_QUERIES = """
-- Weekly trend analysis
SELECT
DATE(started_at, 'weekday 0', '-6 days') as week_start,
model_version,
COUNT(*) as total,
CAST(SUM(success) AS REAL) / COUNT(*) * 100 as success_rate
FROM tasks
WHERE started_at >= DATE('now', '-8 weeks')
GROUP BY week_start, model_version
ORDER BY week_start DESC;
-- Identify struggling task types
SELECT
task_type,
model_version,
COUNT(*) as attempts,
CAST(SUM(success) AS REAL) / COUNT(*) * 100 as success_rate,
AVG(tokens_used) as avg_tokens
FROM tasks
GROUP BY task_type, model_version
HAVING success_rate < 60
ORDER BY attempts DESC;
-- Token efficiency analysis
SELECT
model_version,
task_type,
AVG(tokens_used / NULLIF(lines_generated, 0)) as tokens_per_line,
AVG(CASE WHEN success = 1 THEN tokens_used ELSE NULL END) as avg_tokens_on_success,
AVG(CASE WHEN success = 0 THEN tokens_used ELSE NULL END) as avg_tokens_on_failure
FROM tasks
GROUP BY model_version, task_type;
-- Human intervention patterns
SELECT
task_type,
COUNT(*) as total_interventions,
AVG(tokens_used) as avg_tokens,
GROUP_CONCAT(DISTINCT error_type) as error_types
FROM tasks
WHERE human_intervention = 1
GROUP BY task_type
ORDER BY total_interventions DESC;
-- Improvement trajectory
WITH weekly_stats AS (
SELECT
strftime('%Y-WW', started_at) as week,
model_version,
COUNT(*) as tasks,
CAST(SUM(success) AS REAL) / COUNT(*) as success_rate
FROM tasks
GROUP BY week, model_version
)
SELECT
week,
model_version,
tasks,
success_rate,
LAG(success_rate) OVER (PARTITION BY model_version ORDER BY week) as prev_rate,
success_rate - LAG(success_rate) OVER (PARTITION BY model_version ORDER BY week) as improvement
FROM weekly_stats
ORDER BY week DESC, model_version;
"""
if __name__ == "__main__":
analytics = TaskAnalytics()
# Record sample tasks
sample_tasks = [
TaskRecord(
task_id="task_001",
task_type="code_generation",
model_version="Claude Opus 4.6",
started_at=datetime(2026, 6, 4, 10, 0),
completed_at=datetime(2026, 6, 4, 10, 5),
success=True,
human_intervention=False,
lines_generated=150,
tokens_used=5000
),
TaskRecord(
task_id="task_002",
task_type="bug_fix",
model_version="Claude Opus 4.6",
started_at=datetime(2026, 6, 4, 11, 0),
completed_at=datetime(2026, 6, 4, 11, 8),
success=True,
human_intervention=False,
lines_generated=25,
tokens_used=3500
),
]
for task in sample_tasks:
analytics.record_task(task)
# Generate report
report = analytics.generate_daily_report(datetime(2026, 6, 4))
print(report)
# Compare models
comparison = analytics.get_model_comparison(
"Claude Opus 4.6",
"Claude Sonnet 4.5",
"code_generation"
)
print(f"\nModel Comparison: {comparison}")
5. Automated Code Review Pipeline
5.1 Production-Grade Review System
#!/usr/bin/env python3
"""
Claude Code Review Production System
Automated security, performance, and style analysis
"""
import os
import re
import json
import sqlite3
import subprocess
import hashlib
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Set, Tuple
from datetime import datetime
from enum import Enum
import concurrent.futures
from pathlib import Path
import argparse
class Severity(Enum):
"""Finding severity levels"""
BLOCKER = 1
CRITICAL = 2
HIGH = 3
MEDIUM = 4
LOW = 5
INFO = 6
class Category(Enum):
"""Issue categories"""
SECURITY = "security"
PERFORMANCE = "performance"
CORRECTNESS = "correctness"
STYLE = "style"
TESTING = "testing"
DOCUMENTATION = "documentation"
@dataclass
class Finding:
"""Code review finding"""
file_path: str
line_number: int
severity: Severity
category: Category
title: str
description: str
code_snippet: str
suggestion: str
rule_id: str
cwe_id: Optional[str] = None
cvss_score: Optional[float] = None
estimated_fix_minutes: int = 30
@dataclass
class ReviewReport:
"""Complete review report"""
repository: str
pull_request: str
commit_sha: str
timestamp: datetime
files_reviewed: int
findings: List[Finding] = field(default_factory=list)
duration_seconds: float = 0.0
def can_merge(self, config: 'ReviewConfig') -> Tuple[bool, str]:
"""Determine if PR can be merged"""
blockers = [f for f in self.findings if f.severity == Severity.BLOCKER]
criticals = [f for f in self.findings if f.severity == Severity.CRITICAL]
if blockers:
return False, f"Found {len(blockers)} blocker issues"
if config.block_critical and criticals:
return False, f"Found {len(criticals)} critical issues"
if len(self.findings) > config.max_findings:
return False, f"Found {len(self.findings)} total issues (max: {config.max_findings})"
return True, "All checks passed"
@dataclass
class ReviewConfig:
"""Review configuration"""
block_critical: bool = True
max_findings: int = 50
require_security_review: bool = True
enable_ai_analysis: bool = True
context_lines: int = 3
class SecurityRules:
"""Security vulnerability detection rules"""
RULES = {
"CWE-89": {
"name": "SQL Injection",
"severity": Severity.BLOCKER,
"patterns": [
r'execute\s*\(\s*f["\']',
r'cursor\.execute.*\+',
r'query.*\%.*\(',
],
"suggestion": "Use parameterized queries",
"cvss": 9.8,
"fix_minutes": 60
},
"CWE-78": {
"name": "OS Command Injection",
"severity": Severity.BLOCKER,
"patterns": [
r'os\.system\s*\(',
r'subprocess\..*shell\s*=\s*True',
r'eval\s*\(',
],
"suggestion": "Avoid shell=True; use explicit arguments",
"cvss": 9.1,
"fix_minutes": 45
},
"CWE-798": {
"name": "Hardcoded Credentials",
"severity": Severity.CRITICAL,
"patterns": [
r'password\s*=\s*["\'][^"\']{8,}["\']',
r'api[_-]?key\s*=\s*["\'][A-Z0-9]{20,}["\']',
],
"suggestion": "Use environment variables or secrets manager",
"cvss": 7.5,
"fix_minutes": 30
},
"CWE-22": {
"name": "Path Traversal",
"severity": Severity.CRITICAL,
"patterns": [
r'open\s*\([^)]*path\.join.*\.\.',
],
"suggestion": "Validate paths; use allowlists",
"cvss": 8.1,
"fix_minutes": 45
},
"CWE-502": {
"name": "Unsafe Deserialization",
"severity": Severity.BLOCKER,
"patterns": [
r'pickle\.loads?',
r'yaml\.load\s*\(',
],
"suggestion": "Use JSON; validate input",
"cvss": 9.6,
"fix_minutes": 60
},
}
class PerformanceRules:
"""Performance issue detection rules"""
RULES = {
"PERF-001": {
"name": "N+1 Query Pattern",
"severity": Severity.HIGH,
"patterns": [
r'for.*in.*:\s*\n\s*.*\.query\(',
r'for.*in.*:\s*\n\s*.*\.find\(',
],
"suggestion": "Use bulk operations",
"fix_minutes": 120
},
"PERF-002": {
"name": "Large File Read",
"severity": Severity.MEDIUM,
"patterns": [
r'\.read\s*\(\s*\)',
r'\.readlines\s*\(',
],
"suggestion": "Use streaming for large files",
"fix_minutes": 30
},
"PERF-003": {
"name": "Inefficient String Concatenation",
"severity": Severity.LOW,
"patterns": [
r'\+\s*["\']|["\']\s*\+\s*(?:["\']|\w+)',
],
"suggestion": "Use join() or f-strings",
"fix_minutes": 15
},
}
class CodeReviewPipeline:
"""Main code review pipeline"""
def __init__(self, config: ReviewConfig):
self.config = config
self.db_path = "reviews.db"
self._init_database()
def _init_database(self):
"""Initialize results database"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS reviews (
id INTEGER PRIMARY KEY AUTOINCREMENT,
repository TEXT,
pr_number TEXT,
commit_sha TEXT UNIQUE,
timestamp TEXT,
files_reviewed INTEGER,
total_findings INTEGER,
blocker_count INTEGER,
critical_count INTEGER,
can_merge INTEGER
)
""")
conn.commit()
conn.close()
def review_file(self, file_path: str, content: str) -> List[Finding]:
"""Review a single file"""
findings = []
# Security analysis
for cwe_id, rule in SecurityRules.RULES.items():
for line_num, line in enumerate(content.split('\n'), 1):
for pattern in rule['patterns']:
if re.search(pattern, line, re.IGNORECASE):
findings.append(Finding(
file_path=file_path,
line_number=line_num,
severity=rule['severity'],
category=Category.SECURITY,
title=rule['name'],
description=f"CWE-{cwe_id}: {rule['name']}",
code_snippet=line.strip(),
suggestion=rule['suggestion'],
rule_id=f"SEC-{cwe_id}",
cwe_id=cwe_id,
cvss_score=rule.get('cvss'),
estimated_fix_minutes=rule.get('fix_minutes', 30)
))
# Performance analysis
for rule_id, rule in PerformanceRules.RULES.items():
for line_num, line in enumerate(content.split('\n'), 1):
for pattern in rule['patterns']:
if re.search(pattern, line):
findings.append(Finding(
file_path=file_path,
line_number=line_num,
severity=rule['severity'],
category=Category.PERFORMANCE,
title=rule['name'],
description=rule['name'],
code_snippet=line.strip(),
suggestion=rule['suggestion'],
rule_id=f"PERF-{rule_id}",
estimated_fix_minutes=rule.get('fix_minutes', 30)
))
return findings
def review_files(self, files: List[Tuple[str, str]]) -> List[Finding]:
"""Review multiple files in parallel"""
all_findings = []
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
future_to_file = {
executor.submit(self.review_file, path, content): path
for path, content in files
}
for future in concurrent.futures.as_completed(future_to_file):
try:
findings = future.result()
all_findings.extend(findings)
except Exception as e:
print(f"Error reviewing file: {e}")
return all_findings
def generate_report(self, report: ReviewReport) -> str:
"""Generate markdown report"""
can_merge, message = report.can_merge(self.config)
# Group findings by severity
by_severity = {}
for f in report.findings:
if f.severity not in by_severity:
by_severity[f.severity] = []
by_severity[f.severity].append(f)
md = f"""# Code Review Report
## Summary
- **Repository**: {report.repository}
- **Pull Request**: #{report.pull_request}
- **Commit**: {report.commit_sha[:8]}
- **Timestamp**: {report.timestamp.isoformat()}
- **Files Reviewed**: {report.files_reviewed}
- **Duration**: {report.duration_seconds:.1f}s
## Finding Summary
| Severity | Count |
|----------|-------|
| Blocker | {len(by_severity.get(Severity.BLOCKER, []))} |
| Critical | {len(by_severity.get(Severity.CRITICAL, []))} |
| High | {len(by_severity.get(Severity.HIGH, []))} |
| Medium | {len(by_severity.get(Severity.MEDIUM, []))} |
| Low | {len(by_severity.get(Severity.LOW, []))} |
| **Total** | **{len(report.findings)}** |
## Merge Decision
{'✅ CAN MERGE' if can_merge else '❌ CANNOT MERGE'}: {message}
"""
# Detailed findings
if report.findings:
md += "## Detailed Findings\n\n"
for severity in [Severity.BLOCKER, Severity.CRITICAL, Severity.HIGH,
Severity.MEDIUM, Severity.LOW]:
findings = by_severity.get(severity, [])
if not findings:
continue
md += f"### {severity.name} ({len(findings)} issues)\n\n"
for finding in sorted(findings, key=lambda x: x.line_number):
md += f"""**{finding.title}** ({finding.rule_id})
- File: `{finding.file_path}:{finding.line_number}`
- Category: {finding.category.value}
"""
if finding.cwe_id:
md += f"- CWE: {finding.cwe_id}"
if finding.cvss_score:
md += f" (CVSS: {finding.cvss_score})"
md += "\n"
md += f"""
```code
{finding.code_snippet}
{finding.suggestion}
Estimated fix time: {finding.estimated_fix_minutes} minutes
"""
md += f"\n*Generated at {datetime.now().isoformat()}*\n"
return md
Shell integration script
SHELL_SCRIPT = ‘’’#!/bin/bash
Claude Code Review CI/CD Integration
set -euo pipefail
REPO="${CI_REPOSITORY:-}" PR="${CI_MERGE_REQUEST_IID:-}" COMMIT="${CI_COMMIT_SHA:-}" FILES=("${@}")
Run review
python3 -m claude_review \ –repo “$REPO” \ –pr “$PR” \ –commit “$COMMIT” \ “${FILES[@]}”
Parse result
RESULT=$(cat review_result.json) CAN_MERGE=$(echo “$RESULT” | jq -r ‘.can_merge’)
if [ “$CAN_MERGE” = “false” ]; then echo “❌ Code review failed” echo “$RESULT” | jq -r ‘.reason’ exit 1 fi
echo “✅ Code review passed” ’’'
if name == “main”: parser = argparse.ArgumentParser(description=“Claude Code Review”) parser.add_argument("–repo", required=True) parser.add_argument("–pr", required=True) parser.add_argument("–commit", required=True) parser.add_argument("–files", nargs="+", required=True)
args = parser.parse_args()
config = ReviewConfig()
pipeline = CodeReviewPipeline(config)
# Load file contents
files = []
for path in args.files:
try:
with open(path) as f:
files.append((path, f.read()))
except:
pass
# Review
findings = pipeline.review_files(files)
# Generate report
report = ReviewReport(
repository=args.repo,
pull_request=args.pr,
commit_sha=args.commit,
timestamp=datetime.now(),
files_reviewed=len(files),
findings=findings
)
print(pipeline.generate_report(report))
---
## 6. Anthropic's Warning and Global Governance
### 6.1 The Core Arguments
Anthropic's article makes several critical points:
1. **AI is accelerating AI development**: Internal data shows >80% of code written by AI, 8x productivity gains
2. **Recursive self-improvement is near**: Jack Clark states it "could happen within 2 years, perhaps sooner"
3. **Self-regulation may be necessary**: Anthropic proposes a coordinated pause in frontier AI development
4. **Verification is challenging**: Unlike nuclear treaties, AI training cannot be easily verified from outside
### 6.2 Risk Categories
| Risk Type | Description | Probability | Impact |
|-----------|-------------|-------------|--------|
| **Capability Overhang** | AI systems exceed human understanding | High | Severe |
| **Goal Misalignment** | AI optimizes wrong objectives | Medium | Catastrophic |
| **Concentration** | Few entities control super AI | High | Significant |
| **Arms Race** | Nations compete without safety | Medium | Severe |
| **Labor Displacement** | Knowledge workers displaced | Very High | Significant |
### 6.3 Anthropic's Data Points
The article provides concrete evidence:
Code Optimization Capability (May 2025 vs April 2026):
- Claude Opus 4: ~3x speedup
- Claude Mythos Preview: ~52x speedup
Human benchmark: 4-8 hours to achieve 4x speedup Mythos Preview: achieves same in minutes
---
## 7. Looking Forward
### 7.1 The Path to Recursive Self-Improvement
Based on Anthropic's analysis and public benchmarks:
2024-2025: AI-Assisted Development ├── AI generates code snippets ├── AI assists code review └── AI optimizes modules
2025-2026: AI-Dominant Development ├── AI writes most production code ├── AI completes end-to-end tasks └── AI optimizes system architecture
2026-2027: AI-Assisted Research ├── AI designs experiments ├── AI analyzes results └── AI proposes research directions
2027-2028: AI-Autonomous Research ├── AI trains new models ├── AI optimizes model architecture └── Recursive self-improvement begins
2028+: Full Recursive Self-Improvement └── AI systems evolve autonomously
### 7.2 Recommendations for Stakeholders
**For Individual Developers:**
- Learn to collaborate with AI systems
- Focus on creative and strategic work
- Continuously adapt to new technologies
**For Enterprises:**
- Establish AI code review processes
- Develop AI usage policies
- Invest in AI safety research
**For Policymakers:**
- Create AI regulatory frameworks
- Promote international cooperation
- Support safety research
### 7.3 Conclusion
Anthropic's article represents a watershed moment in AI development. It demonstrates that:
1. **The pace of AI development exceeds expectations**: Recursive self-improvement may arrive sooner than most anticipate
2. **Internal data validates the trend**: 80% AI-generated code, 8x productivity, 76% task success rate
3. **Self-regulation requires courage**: A commercial company calling for development pauses demonstrates responsibility
4. **Proactive preparation is essential**: We must ensure AI development benefits humanity
As Jack Clark stated:
> "We need to find the tools to validate and verify that what these AI systems are doing is correct, is aligned with human intentions, and is consistent with a prosperous society."
This is the challenge facing the entire industry and society.
---
## References
1. Anthropic. (2026). *When AI Builds Itself*. https://www.anthropic.com/research/recursive-self-improvement
2. Clark, J. & Favaro, M. (2026). *When AI Builds Itself*. Anthropic Institute.
3. Wall Street Journal. (2026). *Anthropic Urges Global Pause in AI Development*.
4. VentureBeat. (2026). *Anthropic says 80% of its new production code is now authored by Claude*.
5. METR. (2026). *Long-Duration Task Benchmark Results*.
6. SWE-bench. (2026). *Software Engineering Benchmark Dataset*.